![]()
Table des matières cliquable
pour la partie 1 : Stockage énoncé solution pour la partie 2 : Archivage énoncé solution pour la partie 3 : Compression énoncé solution Solutions des exercices pour la partie 1 : Stockage
La chaine "Bon courage à tous et à toutes." (guillemets non compris) contient 31 caractères exactement : "B" en est le premier et le symbole "." (le point) en est le 31 ième et dernier. Si on met telle quelle cette chaine dans un fichier on a alors 32 octets pour Unix et 33 octets pour Windows comme le montrent les copies de commandes qui suivent : (attention sous Windows à coller le symbole > juste après le point sinon le fichier contiendra un ou plusieurs espaces avant la fin de fichier).
# Unix gh@sirius>echo Bon courage à tous et à toutes.> boncourage.txt gh@sirius> ls -al boncourage.txt -rw-r--r-- 1 gh info 32 oct 19 11:52 boncourage.txt gh@sirius> cat boncourage.txt Bon courage à tous et à toutes. gh@sirius> # Windows Z:\>echo Bon courage à tous et à toutes.> boncourage.txt Z:\>dir boncourage.txt 19/10/2003 11:50 33 boncourage.txt Z:\>type boncourage.txt Bon courage à tous et à toutes. Z:\>Pour rajouter un retour charriot en plus, on peut pour Unix utiliser la commande echo avec la chaine vide et la redirection de sortie avec concaténation. Par contre sous Windows, il faut utiliser la commande echo. (le symbole . doit être collé au mot echo). Voici ce qu'on obtient
# Unix gh@sirius>echo "" >> boncourage.txt gh@sirius> ls -al boncourage.txt -rw-r--r-- 1 gh info 33 oct 19 11:54 boncourage.txt gh@sirius> cat boncourage.txt Bon courage à tous et à toutes. gh@sirius> # Windows Z:\>echo. >> boncourage.txt Z:\>dir boncourage.txt 19/10/2008 11:52 35 boncourage.txt Z:\>type boncourage.txt Bon courage à tous et à toutes. Z:\>On obtient exactement la même taille Windows avec notepad, sous unix avec vi ou emacs car ces éditeurs n'insérent aucun autre caractère.
Avec notre version de Word 2002 pour Windows pour stocker la phrase et le retour charriot les tailles vont croissant si on stocke en HTML, RTF et DOC (pas de XML disponible) :
35 boncourage.txt 2 893 boncourage.htm 4 062 boncourage.rtf 19 968 boncourage.docalors qu'avec openoffice/write 1.1 pour unix on dispose du format standard (sxw) et d'une possibilité XML (DocBook) ainsi qu'un ordre différent pour les tailles :
612 boncourage.html 252 boncourage.xml 1961 boncourage.rtf 5402 boncourage.sxw 8192 boncourage.docPour passer à XHTML, il suffit d'enlever les particularités des balises <STYLE> d'OpenOffice.org 1.1.4 (Linux) ou des balises <o:> et <style:> de Microsoft Word 2002 version 10 ( Windows ) ce qui donne donc des fichiers plus petits.
Pour Unicode, la question est compliquée car il faut savoir de quel encodage on part et vers quel encodage on veut arriver. Il suffit d'essayer sous Unix les commandes iconv --list ou recode --list pour s'en rendre compte. Toutefois, en admettant qu'on veuille obtenir un encodage UTF8 à partir d'un encodage ISO8859-15, voici qu'on peut écrire :
gh@sirius>iconv -f ISO_8859-1 -t UTF-8 boncourage.txt > boncourage.unicode gh@sirius>ls -al boncourage.* -rw-r--r-- 1 gh info 32 oct 19 12:39 boncourage.txt -rw-r--r-- 1 gh info 34 oct 19 12:43 boncourage.unicodeAvec recode, il aurait fallu écrire :
recode ISO-8859-15..UTF8 boncourage.txt2On préferera donc recode qui écrit in situ alors que iconv oblige à recourir à la redirection des sorties.
On peut tirer de nombreuses conclusions de ces manipulations :
...
- la plupart des logiciels savent enregistrer sous divers formats,
- certains formats sont plus gourmands en taille que d'autres,
- certains formats sont plus lisibles que d'autres par les humains,
- les logiciels rajoutent leurs options, leur "meta-tags" dans les formats,
- un simple retour-charriot n'est pas codé de la même façon sous Unix et sous Windows,
- la gestion des documents multilingues est très technique,
Si on ne peut pas ouvrir les fichiers boncourage.docx et boncourage.odt avec un simple éditeur, c'est parce que ce sont des archives. On peut voir ce qu'ils contiennent avec un archiveur quelconque ; on peut aussi les renommer pour utiliser un explorateur de fichiers :
ls -al boncourage.* -rwxrwx--- 1 gh gh 10258 2008-12-06 19:57 boncourage.docx -rwxrwx--- 1 gh gh 7469 2008-12-06 19:34 boncourage.odt zip -v boncourage.docx Archive: boncourage.docx Length Method Size Ratio Date Time CRC-32 Name -------- ------ ------- ----- ---- ---- ------ ---- 1312 Defl:S 358 73% 01-01-80 00:00 3795fcdd [Content_Types].xml 590 Defl:S 243 59% 01-01-80 00:00 b71a911e _rels/.rels 817 Defl:S 250 69% 01-01-80 00:00 51b364d6 word/_rels/document.xml.rels 1181 Defl:S 523 56% 01-01-80 00:00 fdee1e08 word/document.xml 6992 Defl:S 1686 76% 01-01-80 00:00 e2adb596 word/theme/theme1.xml 2108 Defl:S 985 53% 01-01-80 00:00 fb5bc572 word/settings.xml 1031 Defl:S 382 63% 01-01-80 00:00 144bc8aa word/fontTable.xml 260 Defl:S 187 28% 01-01-80 00:00 928ad84a word/webSettings.xml 742 Defl:S 403 46% 01-01-80 00:00 239b0bf3 docProps/app.xml 787 Defl:S 401 49% 01-01-80 00:00 54f97c77 docProps/core.xml 14768 Defl:S 1752 88% 01-01-80 00:00 4d75182d word/styles.xml -------- ------- --- ------- 30588 7170 77% 11 files unzip -v boncourage.odt Archive: boncourage.odt Length Method Size Ratio Date Time CRC-32 Name -------- ------ ------- ----- ---- ---- ------ ---- 39 Stored 39 0% 12-06-08 18:33 0c32c65e mimetype 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/statusbar/ 0 Defl:N 2 0% 12-06-08 18:33 00000000 Configurations2/accelerator/current.xml 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/floater/ 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/popupmenu/ 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/progressbar/ 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/menubar/ 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/toolbar/ 0 Stored 0 0% 12-06-08 18:33 00000000 Configurations2/images/Bitmaps/ 3130 Defl:N 805 74% 12-06-08 18:33 38fa86f2 content.xml 10752 Defl:N 1927 82% 12-06-08 18:33 cd43d6ab styles.xml 971 Stored 971 0% 12-06-08 18:33 4ffa4f22 meta.xml 846 Defl:N 236 72% 12-06-08 18:33 1cfa5a26 Thumbnails/thumbnail.png 7992 Defl:N 1275 84% 12-06-08 18:33 3ddba80a settings.xml 1889 Defl:N 324 83% 12-06-08 18:33 da488265 META-INF/manifest.xml -------- ------- --- ------- 25619 5579 78% 15 filesPour convertir le fichier agenda.txt en UTF-8 sous Linux, on peut utiliser la commande iconv présentée à la question précédente.
Pour windows, on peut recompiler iconv à partir des sources disponibles sur Internet via openwebmail-libiconv ou encore plus simplement éditer le fichier avec XMLSPY et l'enregistrer car XMLSPY convertit automatiquement lorsqu'il voit l'attribut d'encoding dans l'en-tête XML (je l'avais bien dit qu'il était excellent !). Le logiciel Notepad++, entre autres, sait aussi enregistrer en changeant d'encodage. Voici la taille des fichiers avec les deux encodages :
-rw-r--r-- 1 gh gh 125 2010-11-15 11:35 agenda.txt.iso -rw-r--r-- 1 gh gh 133 2010-11-15 11:36 agenda.txt.utfEn ce qui concerne une URL avec accent, à défaut d'apprendre les encodages par coeur ou de garder un lien vers par exemple la page de w3schools associée, on peut utiliser le formulaire de la page urlencode qui est souvent le premier lien qu'on trouve avec un moteur de recherche si on cherche urlencode... Donc ici il faut remplacer é par %E9 d'où l'URL xhtml valide suivante : http://fr.wikipedia.org/wiki/M%E9tamoteur. On pourra profiter de cet exercice pour consulter les reference pages de w3schools.
La première chose à faire est d'apprendre vite fait Perl (ou d'essayer d'adapter des programmes déja écrits) par exemple avec notre tuteur Perl.
Ensuite il faut réfléchir à l'usage du programme pour savoir quels paramètres lui passer. A priori, un seul paramètre (obligatoire), doit être suffisant : le répertoire où chercher les fichiers DSC. Sans paramètre, le script Perl, disons alldsc.pl, rappelera la syntaxe à utiliser.
Si on ne connait pas bien Perl, on pourrait être tenté d'utiliser les redirections précédentes et donc d'effectuer quelquechose comme
dir /on *.dsc > liste1.fic dir /od *.dsc > liste2.ficsous Windows et quelquechose commels -aln *.dsc > liste1.fic ls -alt *.dsc > liste1.ficsous Unix mais heureusement Perl dispose de fonctions suffisamment générales pour ignorer (au niveau de cet exercice) le système d'exploitation sous-jacent. De plus savoir trier en Perl est très formatteur pour progresser en Perl.
On trouvera dans le fichier alldsc1.txt un programme Perl qui affiche dans la session Dos ou Xterm les listes demandées (sans gestion RTF).
Pour mettre en forme les listes dans un document RTF, deux options sont possibles : écrire "à la main" les ordres RTF ou utiliser un module perl tout fait (attention la liste est longue et parfois lente à charger) comme RTF-Writer qui contient RTF-CookBook. Nous utiliserons la première option ce qui permettra de découvrir ou d'approfondir RTF : en voici les spécifications pour la version 1.5 (c'est encore un texte long et parfois lent à charger).
Le prologue (début) du fichier RTF est assez facile à écrire puisqu'on n'a que deux styles de paragraphes : les "Nom de liste" et les "Description de fichier" avec chacune une police de caractère, disons "Arial" et "Courier New". Ce début ressemble donc à :
{\rtf1 {\fonttbl {\f0\fswiss Arial;} {\f1\fmodern Courier New;} } {\stylesheet {\s0 Nom de liste;} {\s1 Description de fichier;} }Pour écrire les noms de listes en gras avec la police 0 (Arial) et en taille 14 (soit en points 2*14=28) et les descriptions de fichier en police 1 non proportionnelle (Courier New) en taille 10, on peut se contenter de
\par\s0\f0\fs28{\b ...ici le nom de liste \par\s1\f1\fs20{ ...ici une description de fichierOn trouvera dans le fichier alldsc2.txt le programme Perl qui produit le fichier RTF avec les listes demandées ; un exemple de fichier RTF est alldsc_rtf.txt et si votre navigateur est configuré pour cela, vous pouvez directement voir alldsc.rtf. Le programme perl est nommé alldsc.pl.
Une solution PHP qui produit des fichiers RTF (pour Word et assimilés) ou CSV (pour Excel et assimilés) est également disponible, c'est alldsc.php.
Pour tester les commandes mysql, on peut utiliser à l'Université le serveur de base de données nommé forge forge. Voici une partie la session mysql :
gh@forge>mysql -h forge -u anonymous -p statdata ... ici on tape le mot de passe qui est "anonymous" (sans les guillemets) mysql>describe stagesMaitrise ; +-------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------+-------------+------+-----+---------+-------+ | nom | varchar(60) | | MUL | | | | an | int(4) | | | 0 | | | categorie | text | | | | | | titre | text | | | | | | entreprise | text | | | | | | adresse | text | | | | | | codepost | text | | | | | | responsable | text | | | | | | tel | text | YES | | NULL | | | telstd | text | YES | | NULL | | | telstg | text | YES | | NULL | | | fax | text | YES | | NULL | | +-------------+-------------+------+-----+---------+-------+ mysql> select categorie, count(*) from stagesMaitrise group by categorie ; +-----------+----------+ | categorie | count(*) | +-----------+----------+ | ? | 3 | | gp | 8 | | info | 92 | | info | 1 | | infos | 1 | | mkg | 5 | | rh | 3 | | stat | 35 | +-----------+----------+Cette session montre que le champ categorie de la table stagesMaitrise est celui qui nous intéresse et qu'il y a plus de valeurs de catégorie que n'indique l'énoncé. Afficher ces valeurs dans une page Web avec PHP ne pose aucun problème, comme on pourra s'en rendre compte en cliquant sur le lien categstages.php dont le code source lisible est categstages.php. On remarquera au passage que le code PHP est "conceptuel" c'est-à-dire sans aucune balise HTML explicite et qu'en conséquence il produit un code XHTML valide (pour quelle grammaire ?).
Dans le même genre d'idées, vous pourriez masquer les requêtes SQL à l'aide d'objets et de fonctions, comme on le préconise en Mapping objet relationnel.
Un exemple de formulaire qui construit dynamiquement la liste des catégories est testable à la page choixcateg.php dont le code source est fourni par choixcateg.txt. Il est perfectible (laissé en exercice) car on peut entrer "à la main" avec l'URL une catégorie qui n'existe pas et le programme le gère mal, de même que les antislash dans certaines chaines de caractère...
Pour automatiser ce traitement, comme PHP est disponible en ligne de commande sur la machine Deneb de l'Université, on peut écrire le programme suivant categstagesautom.php qui produit le fichier PDF nommé categstagesautom_org.pdf
La discussion et le code PHP pour l'export en XML se trouvent dans les exercices 8 à 11 de mon cours numéro 7 de "Technologie Internet" dont les corrigés sont ici.
Une copie lisible de la feuille de style XSL pour transformer le fichier XML nommé allstages.xml en une page HTML qui affiche le nombre de stages par catégorie est categstages_xsl.txt et on peut vérifier avec la page categallstages.xml qu'on obtient ce qu'il faut. Rappel : afficher le "code source" de la page web ou du fichier XML montre la page sans transformation.
La mise en forme avec tableau HTML est dans allstages2.xsl et le rendu s'obtient avec allstages2.xml
Pour reproduire le dessin

On peut écrire :
<?xml version="1.0" ?> <svg xmlns="http://www.w3.org/2000/svg" width="500px" height="300px"> <g id="etvoila"> <rect x="0" y="0" width="150" height="120" fill="yellow" stroke="blue" stroke-width="12"/> <path fill="red" d="M 75,10 L 25,90 L 125,90 z"/> <text x="20" y="60" font-size="25" font-family="Palatino"> Et </text> <text x="60" y="60" font-size="25" font-family="Palatino"> voilà ! </text> </g> </svg>On peut ensuite l'utiliser seul comme ici soit l'intégrer dans la page comme ci-dessous avec une balise object (lire le code source de cette page pour voir les attributs utilisés avec cette balise object). Attention : certains navigateurs ne "supportent" pas SVG...
Solutions des exercices pour la partie 2 : Archivage
Pour se déplacer rapidement d'un répertoire à l'autre, le plus simple dans un premier temps est d'utiliser les signets (ou "Favoris" ou encore "Marque-pages") des divers logiciels, navigateurs et explorateurs quand les logiciels offrent cette possibilité.
Si par contre on veut aller dans un répertoire avant d'effectuer des manipulations sur les fichiers du répertoire, il faut certainement avoir recours à la ligne de commande et à la commande cd. Les chemins des répertoires proposés pour l'exercice sont longs, comme souvent. Une macro-commande ou un script permettent alors de diminuer la frappe. Ainsi définir la macro-commande log comme étant cd /usr/bin/installations/lastsofts/logs/ permet en tapant les trois lettres l, o et g suivi de <entrée> d'aller dans le répertoire considéré.
Par exemple, avec alias en shell Bash, on définit rapidement ces changements de cd :
alias monsac='cd ~/public_html/Farcompr' # mettre cet alias dans .bashrc pour le rendre permanentSi avec le temps on se rend-compte qu'on dépasse la dizaine de raccourcis et qu'on risque de les oublier, il faut programmer une commande (que l'on pourra nommer icd ou gocd ou go) qui permet de rappeler la liste des raccourcis, de définir un nouveau raccouri. Une simple table de hachage liée à un fichier avec deux colonnes (le raccourci et le chemin) permet alors de se déplacer en toute sécurité. Voici un exemple d'une telle table, mis dans le fichier demoicd.txt
Bin /home/info/gh/Bin Mia /home/info/gh/public_html/Projets/Mia aa /home/info/gh/Rch/Aa ad /home/info/gh/Crs/Dossiers_AD algoc /home/info/gh/Crs/Als/Alg/Algo_C algocpp /home/info/gh/Crs/Als/Alg/Algo_Cpp algoj /home/info/gh/Crs/Als/Alg/Algo_Java algop /home/info/gh/Crs/Als/Alg/Algo_Perl algopa /home/info/gh/Crs/Als/Alg/Algo_Pascal algope /home/info/gh/Crs/Als/Alg/Algo_Perl algot /home/info/gh/Crs/Als/Alg/Algo_Tcl ali /home/info/gh/Rch/Align alid /home/info/gh/Rch/AlignDistance align /home/info/gh/Rch/Align alio /home/info/gh/Rch/Ali_old allps /home/info/gh/Rch/nbref/allps als /home/info/gh/Crs/Als ap /home/info/gh/Rch/pontsDis/ap apd /home/info/gh/Rch/pontsDis/Articles aps /home/info/gh/Crs/Stat/Aps aql /home/info/gh/Crs/Projets/Plm/Aql aqt /home/info/gh/Crs/Projets/Plm/Aqt asi /home/info/gh/Crs/Stat/Asi ...On trouvera dans le fichier gocd.rex une implémentation en Rexx de la gestion de ces raccourcis. Voici des exemples d'utilisation :
# quels sont les chemins "courts" qui contiennent stat ? @sirius~/public_html/Projets/Mia|(~gH) > go /n | grep stat flag /home/info/gh/public_html/wstat/Flagrant stat /home/info/gh/Crs/Stat wapplis /home/info/gh/public_html/wstat/applis wasi /home/info/gh/public_html/wstat/wasi wd /home/info/gh/public_html/wstat/Dossiers wsa /home/info/gh/public_html/wstat/applis wstat /home/info/gh/public_html/wstat # allons dans wasi (!) @sirius~/public_html/Projets/Mia|(~gH) > go wasi go (gH) version 3.62 (linux-sirius) # comme le "prompt" le montre, nous y sommes # on crée un nouveau répertoire et on va dans ce répertoire @sirius~/public_html/wstat/wasi|(~gH) > mkdir Statx @sirius~/public_html/wstat/wasi|(~gH) > cd Statx # regardons si l'alias statx existe déjà @sirius~/public_html/wstat/wasi/Statx|(~gH) > go statx go (gH) version 3.62 (linux-sirius) Désolé, aucune ligne ne commence par le mot statx que vous recherchez. Utilisez l'option -l pour voir la liste des abbréviations. Copyright 2000 - Gilles.HUNAULT@univ-angers.fr http://www.info.univ-angers.fr/~gh/gh.html # il n'existe pas, alors on le crée @sirius~/public_html/wstat/wasi/Statx|(~gH) > go -a statx . go (gH) version 3.62 (linux-sirius) (gH) go.rex : changements de répertoire. Abbréviation statx (pour /home/info/gh/public_html/wstat/wasi/Statx) ajoutée à /home/info/gh/Bin/gil.cds Tri des 282 abbréviations dans /home/info/gh/Bin/gil.cds ....+....+....+....+....+... # changeons de répertoire @sirius~/public_html/wstat/wasi/Statx|(~gH) > go tmp go (gH) version 3.62 (linux-sirius) @sirius~/Tmp|(~gH) > go statx # et revenons à Statx @sirius~/Tmp|(~gH) > go statx go (gH) version 3.62 (linux-sirius) @sirius~/public_html/wstat/wasi/Statx|(~gH) > # et voilà !Pour trouver des noms de fichier, Unix est plus riche en commandes que Windows. Ainsi find et [s]locate disposent de nombreuses options de recherche et de tri, grep permet de filtrer les sorties de ces commandes ce qui permet de trouver rapidement des solutions aux questions posées.
Ainsi pour obtenier le nom des 5 derniers fichiers écrits dans le répertoire courant on peut se contenter de
ls -al -t | head -n 5et pour les 10 plus gros :
ls -al | sort -n -r -k 5,5 | head -n 10Pour obtenir les 10 plus gros en tenant compte des sous-répertoires, nous vous conseillons d'utiliser la commande
lister . | sort -r -n -k 2 | head -n 10où lister renvoie à notre programme Perl nommé lister.pl (source) qui liste de façon "sympathique" les fichiers que ce soit sous Linux ou Windows.
Pour trouver tous les fichiers modifiés depuis hier, on peut écrire
find . -daystart -mtime -2mais pour ceux du mois en cours, il faut calculer le paramètre à passer après -mtime (laissé en exercice).
La commande Unix nommé du fournit des statistiques sur le répertoire courant, comme par exemple :
@sirius~/Crs/Projets|(~gH) > du 1200 ./Mpm 104 ./Mse 2160 ./Pi/comparb 2304 ./Pi 7592 ./Pli 72 ./Plm/Aql/XBase 2424 ./Plm/Aql/gnuplot/bin 2432 ./Plm/Aql/gnuplot 4384 ./Plm/Aql 72 ./Plm/Aqt/XBase 576 ./Plm/Aqt 6128 ./Plm 112 ./Pls 20312 .Il est très facile de gérer les sorties de cette commande pour obtenir des affichages plus personnels comme avec notre programme dun.rex écrit en Rexx qui propose des options d'affichage, de filtrage des sous-niveaux :
@sirius~/Crs/Projets|(~gH) > dun syntaxe : dun niveaux [ tri [ chemin] ] exemples : dun 1 dun 2 ~gh/Rch dun 1 A ~gh/Rch options de tri : A pour alphabétique : T pour tri par taille @sirius~/Crs/Projets|(~gH) > dun 1 T (gH) -- dun (en mO) de . profondeur 1 (tri : 2) 1 Mse 1 Pls 2 Mpm 3 Pi 6 Plm 8 Pli 20 -- TOTAL -- @sirius~/Crs/Projets|(~gH) > dun 1 A (gH) -- dun (en mO) de . profondeur 1 (tri : 1) 2 Mpm 1 Mse 3 Pi 8 Pli 6 Plm 1 Pls 20 -- TOTAL --Dans le même genre d'idées, la dizaine de lignes Awk du fichier statdir.awk produisent un comptage des fichiers par extension :
@sirius~/Crs/Projets|(~gH) > ls -al . | awk -f statdir.awk --- ext nb_fich cumul_taille (kO) log 9 31 htm 1 5 ps.old 1 128 ps 13 1538 sty 1 16 maple 1 34 aux 8 4 zip 1 377 dvi 8 111 tex 13 134 tey 1 1 rex 1 0 ham 1 0Nous proposons aussi d'utiliser le programme dfgh.pl qui cumule la place libre sur les différentes partitions :
@sirius~/|(~gH) >perl dfgh.pl on exécute : df --portability --human-readable et on somme : 1 : Sys. de fichiers Taille Occ. Disp. %Occ. Monté sur 2 : /dev/sda5 452G 54G 376G 13% / 3 : none 1,5G 340K 1,5G 1% /dev 4 : none 1,5G 256K 1,5G 1% /dev/shm 5 : none 1,5G 140K 1,5G 1% /var/run 6 : none 1,5G 0 1,5G 0% /var/lock 7 : none 1,5G 0 1,5G 0% /lib/init/rw taille totale : 457.0GPour exploiter ce genre de résultat sous Excel, il suffit d'en faire des fichiers CSV c'est-à-dire séparés par des virgules. Vous pouvez par exemple essayer de charger avec Microsoft Excel ou Open Office Calc le fichier liste.csv qui correspond à la liste précédente dont voici le contenu :
extension , nb_fich , cumul_taille_kO log , 9 , 31 htm , 1 , 5 ps , 13 , 1538 sty , 1 , 16 maple , 1 , 34 aux , 8 , 4 zip , 1 , 377 dvi , 8 , 111 tex , 13 , 134 tey , 1 , 1 rex , 1 , 0 ham , 1 , 0On ne consultera pas la page Web
http://www.info.univ-angers.fr/pub/gh/Projets/Mia/miaweb.php
dont la "source" au format txt est miaweb.txt
Les fichiers .jar sont des archives pour java. Les fichiers .xpi sont des archives pour Mozilla. On peut s'en rendre compte si on les renomme en remplaçant l'extension .jar ou .xpi par .zip ou ,mieux, si on associe ces extensions à l'application zip et ses avatars (gzip, winzip, tkzip etc.)
Toutefois, ces archives .jar et .xpi sont spécifiques pour java et mozilla. Voir par exemple :
Paquetages d'installation XPI
http://xulfr.org/xulplanet/xultu/xpinstall.html
"Sun tutorial" sur les archives jar
http://java.sun.com/docs/books/tutorial/jar/index.html
"Sun jar command reference" (on jurerait la commande tar [!])
http://java.sun.com/j2se/1.5.0/docs/tooldocs/solaris/jar.html
Pour trouver à partir du répertoire courant tous les fichiers dont le nom se termine par .xpi on peut utiliser la commande
find . | grep "\.xpi$"Voici les deux syntaxes à utiliser sous Unix en fonction du protocole utilisé :
firef www.google.fr h firefox http://www.google.fr/ & # on est dans le cd /home/info/gh/Tmp/ firef p1.htm a firefox file:///home/info/gh/Tmp/p1.htm &On a certainement besoin d'un script pour tester les paramètres, pour mettre le bon protocole, pour compléter le nom de fichier relatif en nom de fichier absolu (avec indication du chemin d'accès complet)... Le langage Rexx est certainement un bon choix compte-tenu de son "interoperabilité". Le fichier firef.rex est un exemple de script faisant ce qui est demandé. Il se lance sous Unix par
regina CHEMIN/firefex.rex $*et sous Windows par
regina CHEMIN\firefex.rex %1 %2.Voici les deux URL à transmettre :
# on veut afficher la page de départ de google goog a firefox http://www.google.fr/ & # on veut rechercher les deux mots tuteur et xml goog tuteur xml firefox "http://www.google.fr/search?hl=fr&q=tuteur+xml" &On a certainement besoin d'un script pour tester les paramètres, pour mettre le bon protocole, pour compléter l'url en cas de paramètres... Le langage Rexx est certainement un bon choix compte-tenu de son "interoperabilité". Le fichier goog.rex est un exemple de script sous Unix faisant ce qui est demandé. Le fichier goog.rex est la version pour Windows (on aurait pu n'utiliser qu'un seul fichier mais les différences sont suffisamment faibles pour ne pas compliquer le script...). Le script se lance sous Unix par
regina CHEMIN/goog.rex $*et sous Windows par
regina CHEMIN\goog.rex %1 %2 %3 %4 %5 %6 %7.Pour Google images, il n'y a presque rien à changer, la preuve : googimg.rex.
Une base MySql, un document XML ou un objet (au sens de la programmation objets) ou même un DVD du commerce sont des conteneurs de données hétérogènes : une base contient des tables qui elle-mêmes contiennent des champs, l'élément racine du document XML peut contenir d'autres éléments qui peuvent contenir eux-mêmes d'autres éléments, un objet contient plusieurs variables-mémoires, voire plusieurs tableaux. Un DVD du commerce contient des vidéos, des sous-titres, voire des menus, des images...
Ce qu'apporte en plus XML et l'objet, c'est la possibilité d'agir sur leurs contenus...
En ligne de commande, il faudrait écrire :
history | grep -i $1et
find | grep -i $1Toutefois, un alias (bash) comme
alias 'fetg=(find . | grep -i "$*")'ne fonctionne pas car les arguments "s'arrêtent" à la première commande. Il faut donc écrire des fonctions bash comme les suivantes, qu'on peut mettre dans son fichier .bashrc
heg() { history | grep -i $1 } feg() { find | grep -i $1 }Pour Windows, on peut utiliser les modules de GnuWin ou GnuWin32 ou programmer en Rexx, ou en Perl les solutions... Voici par exemple feg.rex et fed.rex.
Ce sont les sites officiels pour Perl (Comprehensive Perl Archive Network), LaTeX (Comprehensive TeX Archive Network) et R (Comprehensive R Archive Network).
Le nombre de packages ou "modules" croît régulièrement :
Pour le CTAN, le lien le plus «intuitif» est sans doute http://mirrors.ircam.fr/pub/CTAN/help/Catalogue/.
Le programme PHP en cli (ligne de commande) qui donne le nombre de packages via ces URL est nbpackages.php.
Si Microsoft Word et Open Office Write sont similaires en termes d'interface et de fonctionnalités, il y a une différence évidente de prix puisque Open Office est libre. On ne peut pas les comparer avec LaTeX qui est un système professionnel de traitement de textes, développé au départ pour les mathématiques et qui est utilisé dans l'imprimerie. Si LaTeX ne fournit pas d'interface, on en trouve sur le Web comme par exemple Texmaker disponible sous Windows comme sous Linux.
Voici deux exemple de productions en LaTeX qu'aucun *Office ne pourra égaler :
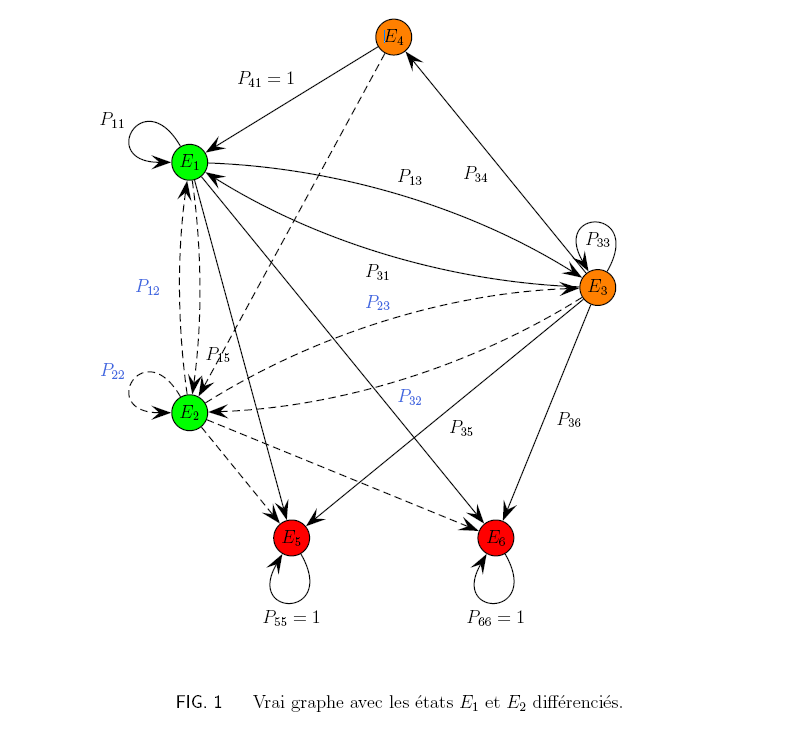

et leurs codes-sources : graphe.tex et formules.tex.
Si Microsoft Excel et Open Office Calc sont similaires en termes d'interface et de fonctionnalités, il y a une différence évidente de prix puisque Open Office est libre. On ne peut pas les comparer avec MySql qui est un gestionnaire de bases de données et non un tableur. Une différence fondamentale est que MySql garantit que dans une colonne de valeurs toutes les valeurs sont de même type (par exemple numérique). Pour un tableur, l'unité de base est la case ou cellule et la notion d'intégrité de type pour une colonne n'a pas de sens. Si MySql ne fournit qu'une interface en ligne de commande, on peut utiliser phpMyAdmin pour disposer d'une interface Web.
Statistica, SAS et R ne sont pas comparables à Microsoft Excel et Open Office Calc car ce sont des logiciels de calculs statistiques, pas des tableurs. Ainsi, comparer deux séries de valeurs en non paramétrique se fait avec un test de Wilcoxon-Mann-Whitney ce qu'Excel et OO Calc ne savent pas faire alors que c'est une commande de base pour Statistica, SAS et R. Pour les performances de Statistica, SAS et R, on pourra consulter les questions et réponses de notre cours 5 à l'école doctorale BS. Un exemple d'interfaçage entre php et R est ici.
Solutions des exercices pour la partie 3 : Compression
La compression en ligne de commande se fait par
zip -u NOMZIP *où -u est mis pour update ; on pourrait ignorer les fichiers .zip par -x *.zip
La décompression avec mise à jour se fait par
unzip -uLao NOMZIP -d .Le script Perl n'a qu'à gérer les paramètres, ce que nous laissons en exercice non corrigé. On pourra consulter sovcd.rex et getcd.rex comme solutions en Rexx.
L'exécution à date et heure fixes se fait sous Windows avec la commande at et le "planificateur de tâches" et sous Linux avec cron.
Pour l'interface graphique, Tk est sans doute un bon choix dans ou hors une page Web (mais il faut alors un plug-in pour Firefox, par exemple). Sinon, on peut recourir à Java avec Swing plutôt que Awt.
Génération des mini-images à la volée : essayez dirimg (ou la version sur forge dirimg ) et regardez le code-source de la page (sic). Le programme php utilisé ressemble à dirimg et produit quelquechose comme listeg.txt. Un script en ligne de commande qui réalise le même travail à l'aide sed est miniatures.txt ; par contre le programme Perl correspondant est laissé en exercice.
Le problème est que la mini-image est en fait l'image entière affichée en petit, d'où un problème de chargement comme pour la page qui suit mais
ATTENTION
cela peut "planter" ou immobiliser longtemps votre navigateur voir même utiliser presque toutes les ressources de votre ordinateur...
La solution est de construire des petites images et de ne charger aucune grande image, comme pour
Imagemagick est sans doute la bonne réponse car sans doute plus rapide que ImageJ.
Un scanner à lames produit de très grosses images (de 2 à 20 Go par image) qu'il faut "tuiler" afin de permettre la navigation rapide par logiciel. Les formats TIFF et JPEG2000 ne sont donc sans doute pas adaptés pour une utilisation courante. Par contre, comme format de stockage et de transport, ils sont utilisables. JPEG2000 pose toutefois un problème de support logiciel et semble peu utilisé.
Puisque 419x83 fait 34777 il faut en gros 34 kO pour stocker les données. Utiliser Excel n'est sans doute pas un bon choix car un tableur ne garantit pas la "cohérence de type" d'une colonne. Le format Dbase est sans doute plus adapté. On peut éventuellement compresser, quoiqu'aujourd'hui 34 kO ne représente pas une grande taille de fichier. Voici la taille des différent fichiers avec divers formats :
08/12/2009 17:30 4 345 pbio_txt.zip 08/12/2009 17:28 35 280 pbio.txt 08/12/2009 17:28 56 320 pbio.xlsIl faut mettre dans le fichier .procmail une "recette" de procmail comme
:0 *^Subject.*miay2k.* * $ ? /home/info/gh/Bin/miarec $DEFAULTet ensuite écrire un script comme miarec
Si on conserve le nombre de valeurs, leur somme et la somme de leur carré c'est suffisant car la moyenne s'obtient avec la somme des valeurs divisée par le nombre de termes et la variance (donc l'écart-type) s'obtient par la différence entre la moyenne des carrés et le carré de la moyenne...
En d'autres termes, la somme s des valeurs vaut n*m. Le cumul jusqu'à la fin de l'année 2002 aboutit donc à la somme 635,42*1235 soit 784743,7 à laquelle il faut rajouter la somme 154*748,98 soit 115342,9 pour l'année 2003 ; la somme totale est donc 900086,6 pour un total de 1235+154 = 1389 articles. La nouvelle moyenne est donc 648,0105.
Si c désigne la somme de carrés et v la variance, v=e*e=(c/n)-m*m. A la somme des carrés précédentes, il faut donc ajouter la somme des carrés de l'année qui se déduit de la formule c=n*(e*e+m*m)...
Pour ceux et celles qui aiment bien les algorithmes, voici la mise à jour de n, m et e si on ajoute na, ma et ea pour l'année en cours :
# mise à jour de n, m, e (nombre, moyenne, écart-type) # avec les données na, ma, ea de l'année en court # calcul de la somme des valeurs passées affecter s <- n*m # calcul de la somme des carrés des valeurs passées affecter c <- n*(m*m+e*e) # calcul de la somme des valeurs de l'année affecter sa <- na*ma # calcul de la somme des carrés des valeurs de l'année affecter ca <- na*(ma*ma+ea*ea) # mise à jour du nombre de valeurs affecter n <- n + na # mise à jour de la somme des valeurs affecter s <- s + sa # mise à jour de la somme des carrés des valeurs affecter c <- c + ca # calcul de la nouvelle moyenne affecter m <- s/n # calcul du la nouvel écart-type affecter e <- racine( (c/n) - m*m )Pour ceux et celles qui préfèrent les formules, voici le calcul du nombre de valeurs n, de la moyenne m et de l'écart-type si on fusionne n1, m1, e1 avec n2, m2, e2 :
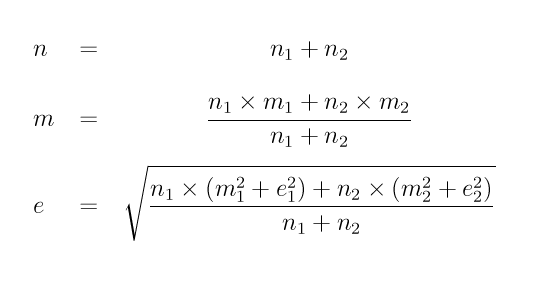
Cette formule se généralise "bien sûr" aux cas de p échantillons définis par ni, mi et ei pour i de 1 à p par :
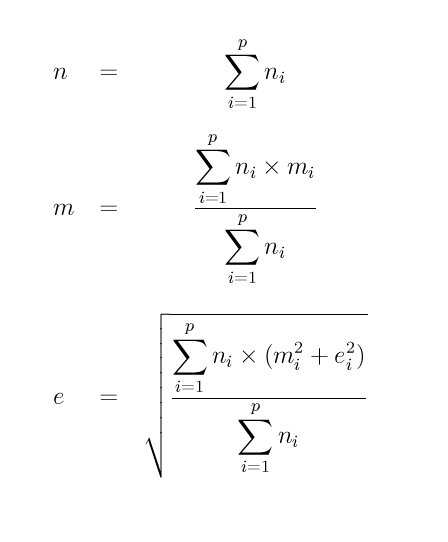
La moyenne n'est pas une bonne compression des données car c'est un résumé trop grossier. Ainsi la moyenne des deux prix 20 € et 180 € aboutit à la même moyenne (100 €) que celles des deux prix 99 € et 101 €. Pourtant dans le premier cas, les deux prix sont très différents de la moyenne alors que dans le second, ils en sont très proches. Il vaut mieux donc systématiquement utiliser la moyenne ET l'écart-type. Pour nos exemples, ceux-ci sont respectivement 80 € et 1 €.
Voir par exemple sovotf.rex (pour unix) et sovotw.pl (pour windows).
Le format de fichier xz est certainement meilleur car il repose sur l'algorithme LZMA2, dérivé de LZMA, connu pour être supérieur à LZW. Xz est toutefois assez peu connu, de même que le logiciel 7z. Pour utiliser le format xz, il faut utiliser des utilitaires libres (pour Unix, Linux comme pour Windows).
La transformation de Burrows-Wheeler est une technique de réorganisation des données initiales de façon à permettre une meilleure compression. En soi, elle ne compresse rien. Voir par exemple l'article français du Wiki à ce sujet.
L'article anglais du Wiki qui traite de cette BWT est plus intéressant car il explique comment elle est utilisée aujourd'hui en bioinformatique.
On peut utiliser ImageJ, qui se programme par "plug-in" Java.
La meilleure solution est sans doute tkdiff. Essayez de l'utiliser sur les fichiers statgh_2.99.r et statgh_311.r et vous l'adopterez !
Je ne vais quand même pas vous donner tous mes secrets de référencement... ! Vous pouvez toutefois remarquer qu'il n'y a aucun "meta" de référencement ni aucun mot-clé dans la partie head de mes pages Web. Donc vive le zurnisme...
Retour à la page principale de (gH)
{kind=link}