Tuteur pour le langage XML (partie 1 / 3)
Texte du Tuteur écrit par Gilles HUNAULT
Liste des autres tuteurs (langages, logiciels, systèmes d'exploitations...)
![]()
Dans ce document :
1. Qu'est-ce que XML ?
1.1 Pourquoi XML ?
1.2 Le méta-langage XML
1.3 Importance de la "technologie" XML
2. Structure des documents XML
3. Les grammaires DTD ou définitions de balises
4. Les grammaires XSD ou schémas de balises
5. Les XSL ou feuilles de styles généralisées et transformations
retour à la table des matières principales
1. Qu'est-ce que XML ?
1.1 Pourquoi XML ?
Tout transfert d'information (entre humains, entre ordinateurs ou entre ordinateurs et humains) devrait être un «bon» transfert de «bonnes» informations. XML vise justement à permettre l'écriture et le transport de bonnes informations.
Mais qu'est-ce qu'une bonne information ?
Une bonne information est une information structurée.
Une information structurée hiérarchiquement en arbre est une bonne information car elle est non ambigue, facile à manipuler et rapide à traiter.
Une structure hiérarchique en arbre est une bonne structure pour les informations car elle admet entre autres les tableaux rectangulaires classiques en lignes et en colonne comme sous-arbres, ce qui permet d'«intégrer» les bases de données existantes.
Une bonne information est une information qui est vérifiée et validée dans toutes les étapes de transport et de traitement.
Une bonne information est à la fois syntaxique et sémantique.
Une bonne information est unique. On la convertit dans le format requis à la demande.
XML répond à toutes ces attentes, notamment grâce à ses grammaires DTD et XSD mais aussi grâce à son langage XSL. De plus, XML utilise des fichiers-textes sans format particulier et il s'intégre donc bien aux démarches qualité et open source. Il est bien sûr inter-opérable, c'est-à-dire indépendant des systèmes d'exploitation.
1.2 Le méta-langage XML
XML est l'abbréviation de eXtensible Markup Language. Ce n'est PAS un langage à marqueurs mais un meta-langage, qui permet de définir des éléments, des attributs et des entités, ce qui permet de définir des balises (on dit aussi "tags"), comme celles de HTML. XML est un sous-langage de SGML qui est beaucoup plus général mais aussi beaucoup plus complexe. XML ne sert pas à indiquer comment présenter le texte (en bleu, en gras, à droite, etc.) mais à structurer et décrire le contenu.
Schématiquement, on peut dire que XML permet de passer d'une vision plate ou minimale comme
Jean Xavier Martin Pierre Durans Al Gordon Jean Michel
à une vision structurée comme
Prénom Nom Jean Xavier Martin Pierre Durans Al Gordon Jean Michel ou
Nom Prénom Martin Jean Xavier Durans Pierre Gordon Al Michel Jean
Contrairement à HTML, il est eXtensible (doù le X de XML) ce qui signifie qu'il permet d'inventer ses propres balises et qu'elles peuvent donc tout décrire : les contenus, les protocoles, les transformations de balises en affichage, le codage de sécurité, le langage des nouvelles balises etc. Comme XML permet d'écrire les grammaires qui définissent les documents, XML est donc bien de facto un auto-méta-langage (sic) car il peut se définir lui même !
Prenons un exemple : le texte suivant (qui est un extrait de page Web, y compris la faute d'orthographe)
Les Histoires extraordinaires de Poe fures traduites en français en 1848 par Baudelaire qui publia les Fleurs du Mal en 1857 et trois ans plus tard les Paradis artificiels.
correspond à l'interprétation du code HTML suivant
Les <b><font color="#880000">Histoires extraordinaires</font></b> de <b><font color="#880000">Poe</font></b> furent traduites en français en 1848 par <b><font color="#880000">Baudelaire</font></b> qui publia <b><font color="#880000">les Fleurs du Mal</font></b> en 1857 et trois ans plus tard <b><font color="#880000">les Paradis artificiels </font></b>.
Les balises du code HTML ne servent qu'à présenter le texte : <b> passe en gras (à cause du mot "bold" en anglais), <font color=...> permet de choisir la couleur de la police de caractères. Par contre, on peut remarquer que le texte ne dit rien quant à qui est auteur, qui est oeuvre, qui est date. XML, quant à lui, permet d'écrire l'extrait de texte suivant :
Les <oeuvre>Histoires extraordinaires</oeuvre> de <auteur>Poe</auteur> furent traduites en français en <date>1848</date> par <auteur>Baudelaire</auteur> qui publia <oeuvre>les Fleurs du Mal</oeuvre> en <date>1857</date> et trois ans plus tard <oeuvre>les Paradis artificiels</oeuvre>.
Les balises XML définies pour ce document ne décrivent pas la forme mais le contenu. Ainsi le titre d'une oeuvre est contenu entre le début de balise <oeuvre> et la fin de balise </oeuvre> ; de même les balises <date> et <auteur> permettent de dresser une liste des auteurs et des dates.XML permet de convertir les balises définies pour effectuer la mise en forme avec XSLT ; cela va plus loin que ce que vous pensez : si on peut naturellement convertir les balises en code HTML, il est également possible d'en faire des expressions rich text, acrobat, ou encore postscript. Un même document XML associé à des fichiers XSLT différents sera donc automatiquement converti en un document HTML, XML (avec d'autres balises), WML, et avec XSL-FO il sera converti en RTF, PDF ou PS. Voici un exemple de conversion pour passer en gras en HTML le nom de l'auteur : les mots template match indiquent quelle balise il faut détecter et le mot apply-templates signifie qu'il faut déclencher les règles par défaut (ici, afficher le contenu) à cet endroit.
<xsl:template match="auteur"> <b> <xsl:apply-templates/> </b> </xsl:template>
Pour utiliser un fichier XML, il faut au minimum que le document soit bien formé, c'est à dire qu'à une ouverture de balise corresponde bien sa fermeture, que chaque balise ne comporte qu'un mot qui commence par une lettre...
Définir des balises, c'est inventer une grammaire formelle. On peut donner explicitement cette grammaire sous forme de XSD (schéma XML) ou de DTD (définition de balises). Il est alors possible de tester si le document est valide, c'est à dire s'il respecte la grammaire (s'il est conforme à cette grammaire). C'est particulièrement important lorsqu'on veut transmettre beaucoup d'informations structurées, si on veut imposer une structure de balises (par exemple : à une oeuvre est toujours associée une date fournie après le titre de l'oeuvre), ou si on veut être sur qu'on n'utilise qu'un certain jeu de balises.
Les grandes organisations internationales, les ministères définissent leurs balises à travers des grammaires officielles mises à disposition sur leurs sites. Tout organisme, association, communauté peut donc savoir quelle structuration donner aux documents pour communiquer. En interne, une entreprise peut soit utiliser ces balises soit s'inventer ses propres balises et les outils de conversion associés.
On trouve notamment aujourd'hui de telles spécifications de balises XML pour
- écrire des mathématiques avec MATHML,
- gérer des pages multimedia interactives avec SMIL,
- gérer dynamiquement des graphiques avec SVG (voir notre page sur SVG),
- utiliser des balises normalisées dans les pages HTML avec XHTML,
- avoir des feuilles de styles avec XSL,
- gèrer les sons et les voix avec VXML,
- convertir en PDF ou PS avec XSL-FO.
Pour éviter les conflits dans les noms de balises (qui sont principalement des problèmes d'homonymie), XML met en jeu des espaces de noms ou plutot des espaces de nommage ("name spaces").
1.3 Importance de la "technologie" XML
Il ne faudrait pas trop vite ranger XML comme un langage pour le Web. En fait, XML est un plus qu'un langage : il tend à devenir le seul support du format d'échange [en mode texte] pour toutes les informations d'un système d'informations. Il correspond à la philosophie Open Source et à ses impératifs de qualité, fiabilité et validité des informations. En particulier pour la France, tout ce qui tourne autour de l'administration électronique, de la dématérialisation des marchés publics et du cadre commun d'interopérabilité passe par un codage en XML des informations.
De plus, XML est indépendant de tout système d'exploitation et aussi indépendant de tout langage de programmation. C'est donc un outil universel et libre. La preuve en est que la société Microsoft, avec ses nouveaux formats de fichier docx, pptx et xlsx est passée à XML, sans doute parce que Open Office l'utilisait déjà. Pour un exemple de tels fichiers, voir l'exercice 1 de la partie 1 de mon cours sur le stockage, l'archivage et la compression.
Signalons au passage que tout navigateur sait afficher un document XML et même masquer/révéler les contenus des éléments. Le minimum requis pour cela est que le document soit bien formé. Par contre, les navigateurs ne seront sans doute jamais validants car on peut être bien formé et valide pour une grammaire mais invalide pour une autre grammaire...
La page française du Wiki sur XML et le schéma cliquable nommé "big picture of the XML family" devraient permettre de se rendre compte de l'universalité de XML et de son importance dans tous les domaines du tranfert d'informations. On pourra aussi utiliser notre recherche via google de certains mots-clés pour suivre "le phénomène XML".
Il est difficile de se faire une idée précise de la "galaxie" XML mais quelques graphiques permettent d'en saisir les grandes lignes (cliquer sur un graphique pour l'aggrandir).
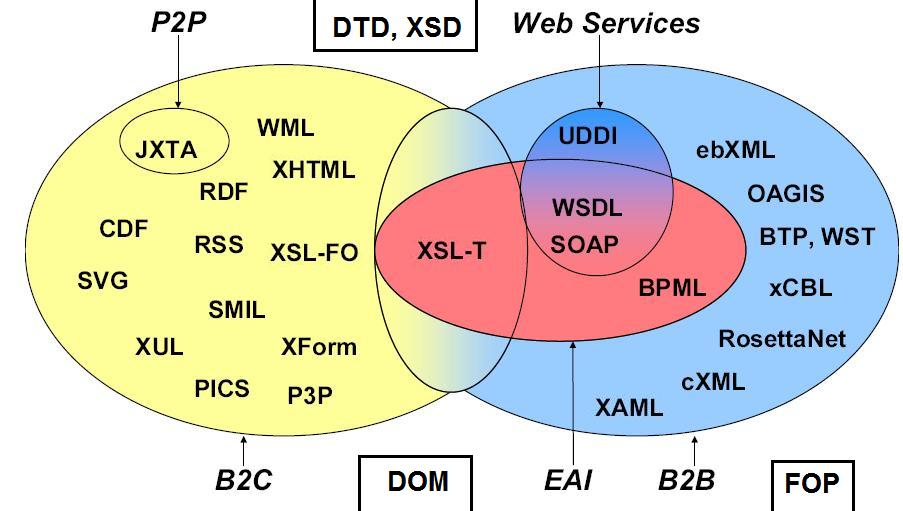

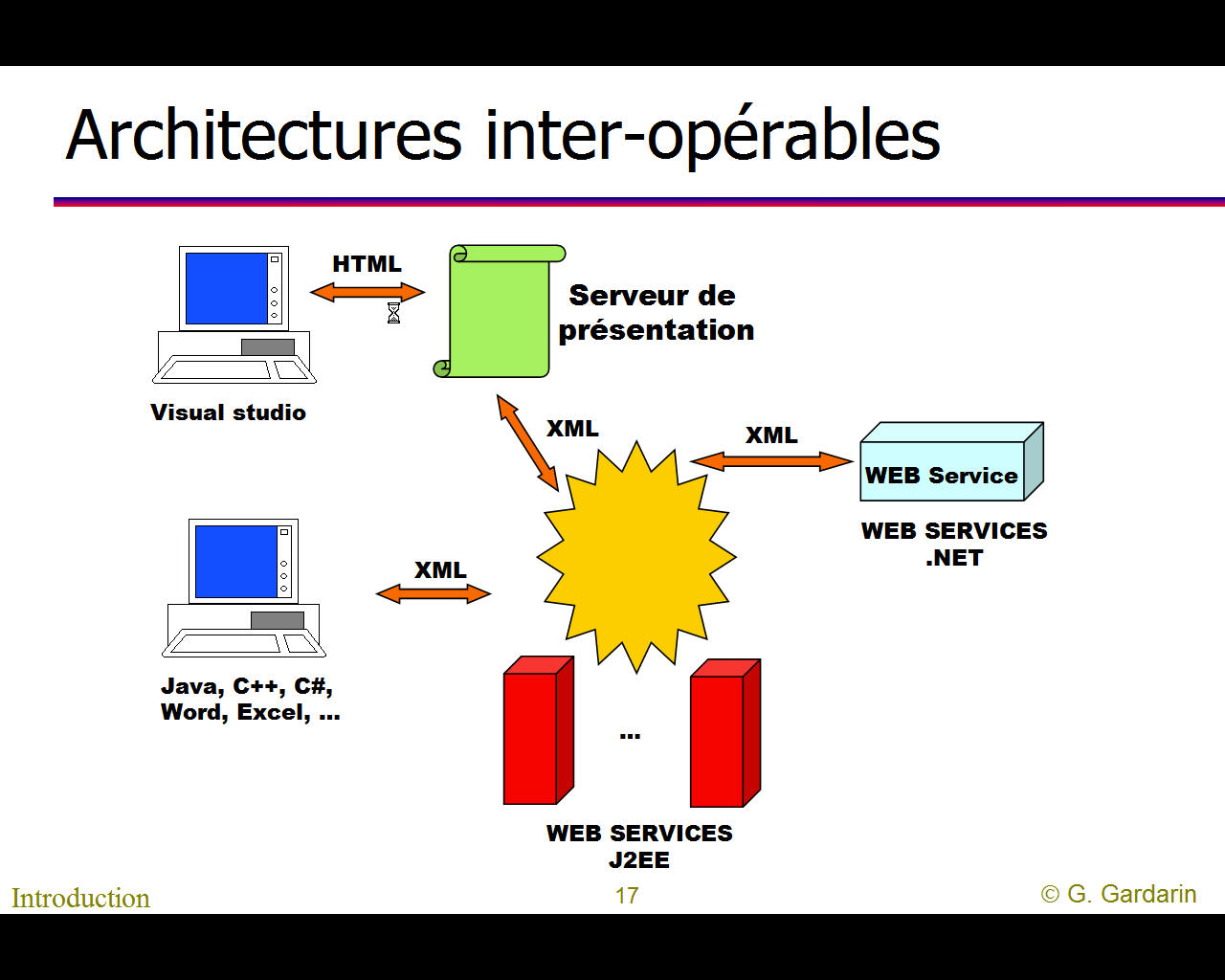
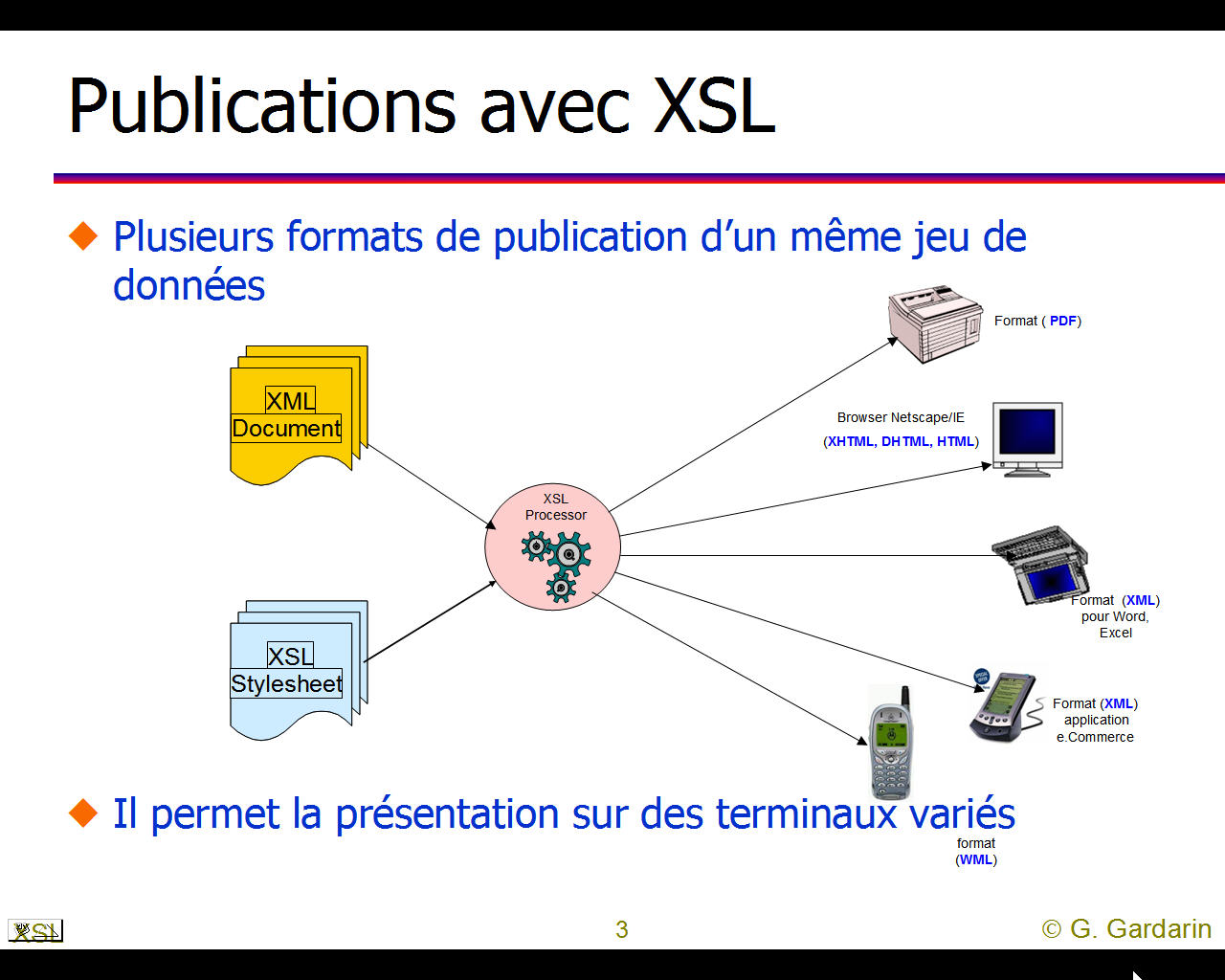
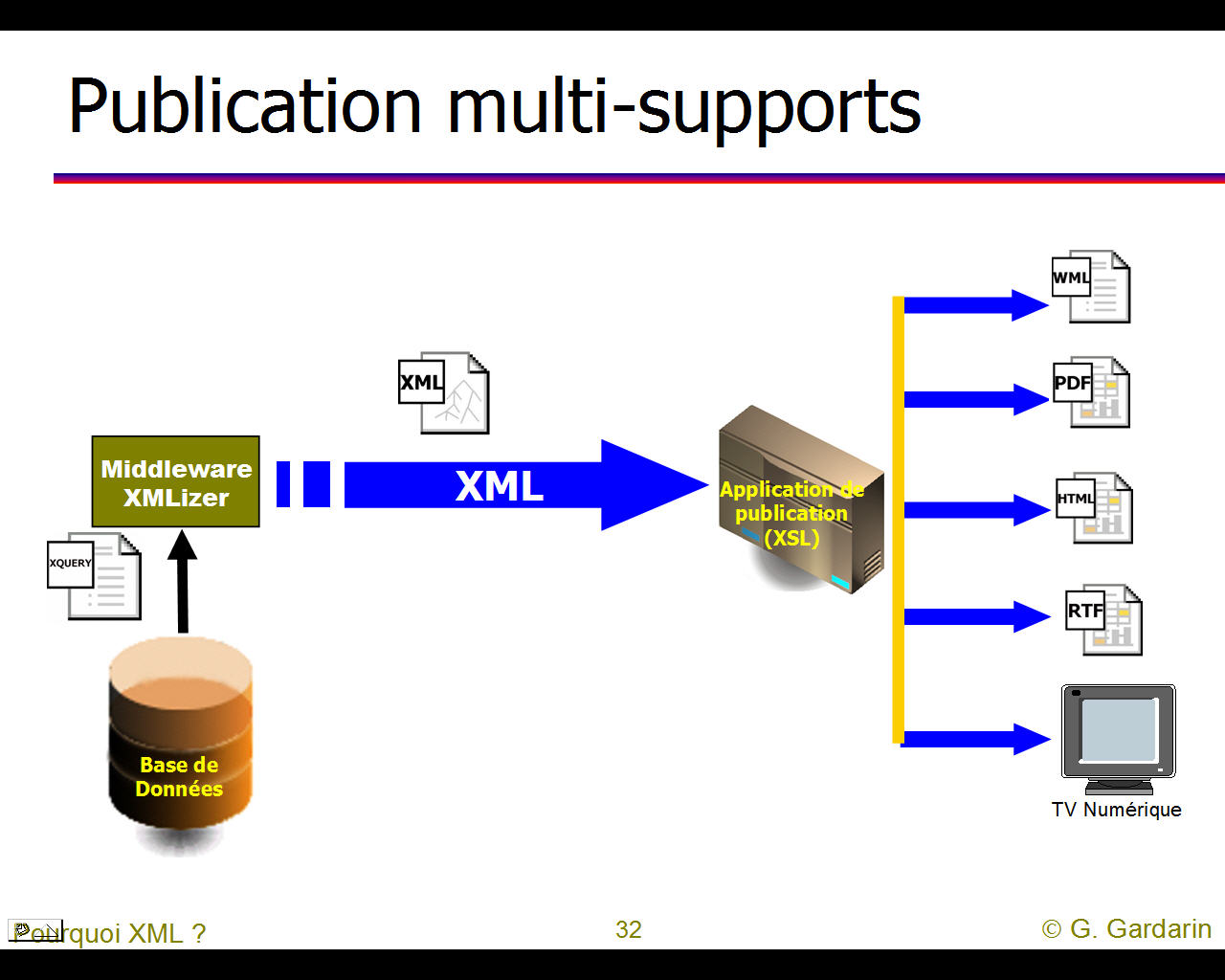
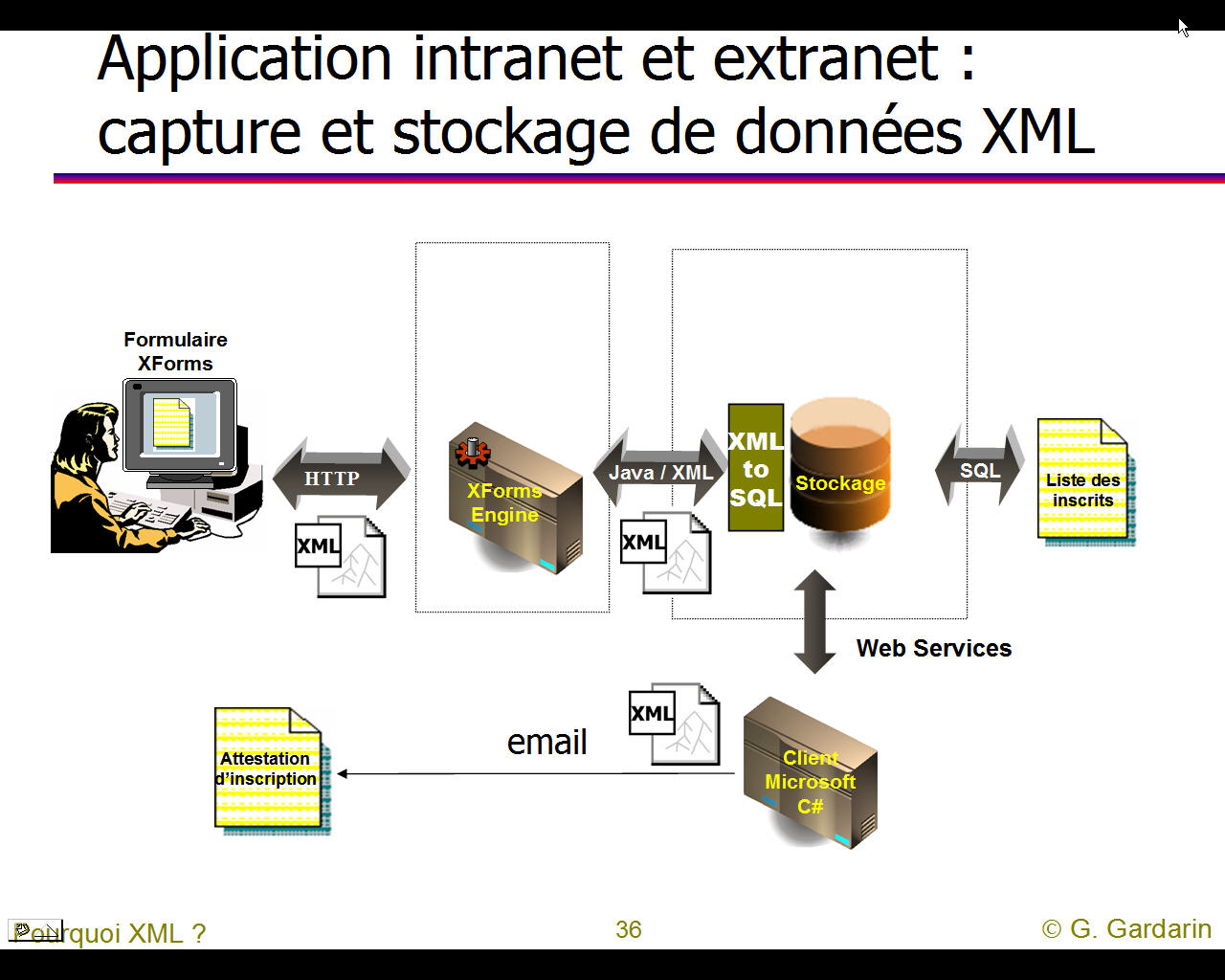
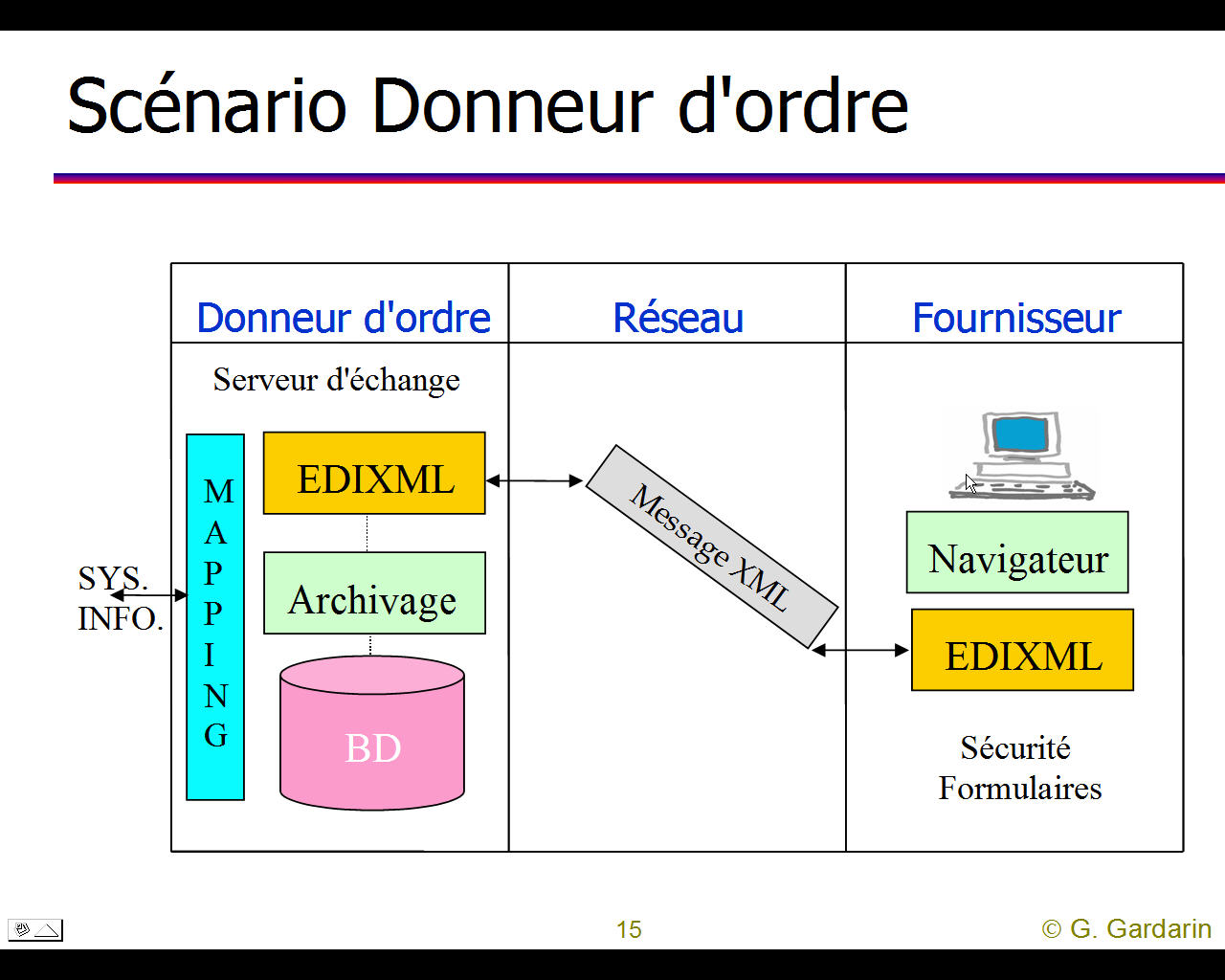
Pour le détail des rapports entre Intranet, Internet, Services (ou applications) Web, les bases de données et XML on pourra se reporter au site français de Georges GARDARIN car son livre intitulé "XML, des bases de données aux services Web" est devenu la référence en la matière. On y trouve pour chaque thèmes traités une vingtaine de transparents en moyenne.
Dés 2001 la page 163845 de la revue Décision informatique fournissait déjà un aperçu des liens entre SCGBD et XML (copie locale "aménagée" ici).
XML s'étend aussi aux protocoles de transmission, à tout transfert d'information en général. Ainsi
- XKMS soit XML Key Management Specification met en place des spécifications quant aux descriptions de clés pour le cryptage,
- XMLDSIG soit XML Digital Signature assure un bon codage et un bon décodage par les seules personnes autorisées,
- XFORMS soit XML Forms assure une gestion cohérente des formulaires,
- XACML soit eXtensible Access Control Markup Language valide les accés aux informations,
- SOAP soit XML Simple Object Access Protocol permet de définir les manipulations d'objets distants via les transferts HTTP notamment,
- XQUERY permet d'interroger les documents et bases de données XML.
- XLL et XPOINTER permettent définir des liens étendus (bien au-delà des URL et autres URI actuelles) entre documents XML.
Et il y en a de nombreux autres, soit déjà définis soit en cours de normalisation... On pourra par exemple consulter la page xmlApplications (du site xml.coverpages.org).
XML est donc une évolution majeure dans la façon de coder et de transmettre n'importe quelle information pour les arguments suivants : le codage est uniforme, standard, universel, cohérent et vérifiable ce qui permet d'avoir des applications, des serveurs et des systèmes qui coopèrent efficacement (on dit aussi interopérabilité mais c'est un mot long à la sémantique complexe et diffuse).
Voici sur un exemple ce que permettent les balises : depuis longtemps, tout le monde sait que les fichiers-texte sont lisibles et portables. Si on décide de transférer des noms et prénoms de personne dans des fichiers-texte, il est difficile de décider de l'ordre, de la taille de ces informations : dire que le premier mot est le prénom est faux pour Jean Daniel Martin dire que la longueur du nom ou du prénom est de n caractères est contraignant. La réponse XML à ce problème consiste à définir les balises <nom> et <prenom> comme dans
<nom> martin </nom> <prenom> jean daniel </prenom> <nom> dupond </nom> <prenom> paul </prenom>
Plus fort : si on se met d'accord sur des balises simples et non imbriquées, on n'a pas besoin de spécifier l'ordre des balises. Ainsi les deux personnes précédentes peuvent aussi être décrites par
<prenom> jean daniel </prenom> <nom> martin </nom> <prenom> paul </prenom> <nom> dupond </nom>
Enfin, comme remplacer une balise par une autre est un jeu d'enfant en XML, on peut très facilement transmettre une version anglaise au lieu d'une version française, à savoir
<firstName> jean daniel </firstName> <lastName> martin </lastName> <firstName> paul </firstName> <lastName> dupond </lastName>
Un avant-dernier point pour montrer combien XML est important : il est portable et présent sur tous les environnements. Ainsi presque tous les fichiers de configuration de logiciels sont écrits aujourd'hui en XML, que ce soit pour Windows, pour Linux... Voici par exemple une toute petite partie de la configuration du logiciel Statistica en mode serveur :
<?xml version="1.0"?> ... <StatOpts ActiveConfig="Initial"> <Initial Description="Initial User Configuration"> <Location GeneralPath="D:\Statistica\Examples" /> </Initial> </StatOpts> ...
Terminons par 3 fichiers à consulter :
- dmdPC.xml une acte officiel pour un permis de construire en XML (extraite du site pour le service public). - siret.xsd qui est la grammaire INSEE du code SIRET des entreprises, - erele.dtd qui est l'une des grammaires du ministère de l'Equipement.
retour en haut de document

2. Structure des documents XML
Un document XML est au départ un fichier-texte (lisible par un éditeur de textes quelconque) qui comporte du texte structuré en éléments éventuellement imbriqués, éventuellement dotés d'attributs. Les éléments sont repérés par des balises et comportent un contenu alors que les attributs ont des valeurs et sont définis à l'intérieur d'un élément. Un élément commence par une balise ouvrante et se termine par une balise fermante, avec une écriture simplifiée pour les éléments de contenu vide (ce qui ne les empêche pas d'avoir des attributs). Il y a deux grandes différences entre les éléments et les attributs : l'ordre des attributs n'est pas significatif ; de plus un élément ne peut pas contenir deux attributs de même nom.
Un document XML comporte en général une en-tête de document ou "prologue" et un corps de document ou "partie xml propre" ou "body". Les instructions de traitement (PI pour "processing instructions" en anglais) sont généralement dans le prologue.
La structuration du texte vient du choix des éléments, de leur imbrication. Un lecteur non informaticien d'un fichier XML peut donc s'y retrouver. De par la structure en arbre informatique, le programmeur sait de plus comment accéder aux informations et à leur structuration.
Une balise XML est un seul mot (qui commence par une lettre) encadré par < et > alors qu'une balise SGML peut commencer par un symbole. A une balise XML ouvrante doit correspondre une balise fermante qui contient le même mot précédé du symbole /. Ainsi </auteur> est la balise fermante associée à <auteur>. Contrairement aux documents HTML, les documents XML doivent être bien construits (ou bien formés, "well formed" en anglais) avant de pouvoir être utilisés. Cela signifie en particulier que les balises ouvertes doivent être fermées et bien imbriquées. Par exemple
Une <objet> fusée et un <objet>avion</objet> possèdent des caractéristiques semblables.
est incorrect car une balise <objet> n'est pas fermée et
<introduction> Monsieur <personne><client>Dupont</personne></client> </introduction>souhaite rencontrer Madame <personne><agent>Durand</agent> </personne>.
est incorrect car les balises <personne> et <client>sont mal imbriquées.
Les navigateurs (Internet Explorer, Firefox...) savent tester si un document est bien formé. Ils refusent en général d'afficher un document mal formé. Les navigateurs présentent les documents XML en dynamique (on peut cliquer sur les symboles plus et moins en début de ligne). Vous pouvez le vérifier à l'aide du document dbf.xml qui est bien formé et à l'aide du document dmf.xml qui est mal formé (ne pas hésiter à consulter la "source" des documents).
Un élément peut contenir des sous-éléments, comme dans
<client> <nom>Durand</nom> <refArt>TKX243</refArt> </client>
Il peut aussi contenir, mais là encore ce n'est pas obligatoire, des attributs selon la syntaxe attribut="valeur" (noter les guillemets qui sont obligatoires) comme pour
Monsieur <client nom="Dupont"></client> et Madame <client nom="Durand" vip="oui"></client> ont commandé...
On peut bien sur panacher éléments et attributs comme dans
Monsieur <client nom="Dupont"><ref>X25</ref></client> et Madame <client nom="Durand" vip="oui"><ref>TX045</ref></client> ont commandé...
Il est possible de condenser les éléments à contenu vide. Au lieu de
<sautdepage></sautdepage>
on peut écrire
<sautdepage/>
ou, mieux pour des raisons techniques
<sautdepage />
avec un espace devant le symbole /. L'exemple précédent avec attributs mais sans sous-éléments est donc plus souvent écrit
Monsieur <client nom="Dupont" /> et Madame <client nom="Durand" vip="oui" /> ont commandé...
Le choix entre attribut et sous-élément n'est pas facile car les deux solutions présentent des avantages et des inconvénients. Toutefois, comme un document XML ne peut comporter qu'un seul élément incluant les autres et nommée élément-racine (ou "type" du document), il est sans doute un peu plus facile de gérer des sous-éléments que des attributs. On remarquera qu'un élément ne peut contenir qu'un seul attribut de nom fixé alors qu'on peut avoir plusieurs sous-éléments de même nom. De plus l'ordre des attributs est libre. En d'autres termes
<clients> <client> Dupond </client> <client> Durand </client> </clients>
est correct alors que
<clients client="Dupond" client="Durand" />
est interdit.
Signalons qu'un document XML est géré comme un arbre au sens informatique du terme, les sous-balises étant les feuilles et les noeuds...
Lorsqu'on utilise des espaces de nommage, le nom de la balise doit être précédé de la référence de nommage pour lever l'ambiguité. Ainsi on peut écrire
Monsieur <client nom="Dupont" />, Monsieur <csp:client nom="Durand" />, et Madame <cvip:client nom="Durand" vip="oui" /> . ont commandé...
La deuxième balise client fait référence à l'espace de noms désigné symboliquement par csp et la troisième à l'espace cvip.
Un document XML commence toujours par l'en-tête
<?xml version=
L'attribut de version est obligatoire, généralement associé à la valeur 1.0. Il est en général conseillé d'indiquer ensuite la version d'XML qu'on veut utiliser ainsi que le système d'encodage des données (ce qui a de l'importance quand on écrit des mots avec des accents comme en français). L'en-tête n'est pas une balise XML (car après < on ne trouve pas une lettre mais le symbole ?) donc il n'y a pas de </?xml> à écrire mais on la termine quand même par ?> car c'est une balise SGML.
Les commentaires, repérés par <!-- ne sont pas des balises XML mais doivent se terminer par --> car ce sont des balises SGML.
La première balise rencontrée définit la racine de l'arbre induit ou balise-racine. Les balises sont sensibles à la "casse" des caractères et donc </POMME> ne ferme pas la balise <pomme>. Voici un exemple minimal de document XML :
<?xml version="1.0" encoding="ISO-8859-1" ?> <miniDocumentFrancisé> Ceci est mon petit document à moi. </miniDocumentFrancisé>
Il est à noter que ce document serait incorrect si l'encodage (ISO...) du document n'était pas fourni car alors le é de Francisé serait considéré comme une erreur dans le nom de balise.
Un document XML peut contenir, mais ce n'est pas obligatoire, une référence à la définition du type du document (grammaire DTD) comme dans
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE Algo SYSTEM "galg.dtd"> <Algo> <auteur> (gH) </auteur> <cmt>une affectation simple>/cmt> <affecter> <var>somme</var> <valeur>0</valeur> </affecter> </Algo>
Un document XML peut contenir, mais ce n'est pas obligatoire, des références d'espaces de noms, comme par exemple
<?xml version="1.0" encoding="ISO-8859-1"?> <algo xmlns="http://www.mesnoms.fr" xmlns:us="http://www.mynames.com" > <auteur> (gH) </auteur> <cmt> une affectation simple </cmt> <!-- équivalent américain --> <us:cmt> a simple affectation </us:cmt> <affecter var="somme" valeur="0" /> </algo>
Un document XML peut aussi contenir, mais ce n'est pas obligatoire, une indication de schéma (grammaire XSD) pour valider le document comme dans
<?xml version="1.0" encoding="UTF-8"?> <bibliotheque xsi:noNamespaceSchemaLocation="meslivres.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <livre> ... </livre> <livre> ... </livre> ... </bibliotheque>
Un document XML peut aussi, mais ce n'est pas obligatoire, inclure d'autres fichiers XML définis comme des entités, soit par exemple
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE ENCYCLOPEDIE [ <!ENTITY volum1 SYSTEM "volume1.xml"> <!ENTITY volum2 SYSTEM "volume2.xml"> ]> <ENCYCLOPEDIE> <pagedeGarde> ... </pagedeGarde> &volum1; &volum2; </ENCYCLOPEDIE>
Un document XML peut aussi, mais ce n'est pas obligatoire, inclure une feuille de style généralisée XSL pour transformer le document en une page web, un fichier pdf etc. comme par exemple
<?xml version="1.0" encoding="ISO-8859-1"?><?xml-stylesheet type="text/xsl" href="titres.xsl"?><FILMS> <FILM Annee='1958'> <TITRE>Vertigo</TITRE> <GENRE>Drame</GENRE><PAYS>USA</PAYS><MES idref="3"></MES> <ROLES> ...
Un premier point important à se rappeler est que, comme les bases de données, XML permet les contenus mixtes : dans une implémentation orientée bases de données de salles de cinéma, on aura une base SALLESCINE avec des tables SALLES, FILMS, ARTISTES... Avec XML on pourra avoir trois balises principales SALLES, FILMS, ARTISTES et le document global contiendra l'équivalent de l'ensemble des trois tables. Un deuxième point important à se rappeler est que XML permet de contraindre les documents à être bien écrits et que les grammaires peuvent servir de garde-fous. Il peut y avoir une cellule vide dans une feuille Excel en face d'un service parce qu'on a oublié de mettre le nom du responsable par exemple (ou parce qu'on pensait qu'on le ferait plus tard). Excel ne "réclamera" pas de valeur. Par contre, si le document XML est utilisé avec une grammaire qui interdit les valeurs manquantes on ne pourra pas utiliser le document tant qu'il sera incomplet (on peut bien sur contourner le problème en mettant "toto" ou "?" pour forcer la valeur à ne pas être vide mais alors cela ne sert à rien de définir des grammaires). En d'autres termes, une grammaire et l'outil logiciel de validation associé à la grammaire remplacent un programme de validation des données.
Pour savoir comment on teste si un document XML est bien formé avant de s'en servir, voir la section tester un document XML dans notre page sur les outils logiciels et les langages pour XML.
On trouvera sur le site du W3C, rubrique XML Technology, sous-rubrique XML Essentials les spécifications de XML 1.0 et de XML 1.1. Nous avons regroupé les règles correspondantes, sans commentaires, dans xml_specsv2, triées dans xml_specsv3, exploitables dans le fichier xml_specs.xml.
3. Les grammaires DTD ou définitions de balises
Le métalangage XML n'impose que peu de contraintes à un document XML : les balises doivent être imbriquées, il faut une balise racine, les valeurs des attributs doivent être entre guillemets. Le but d'une DTD est de décrire le vocabulaire et la structure choisie pour un document XML. Une DTD commence par le mot <!DOCTYPE : ce n'est donc pas une balise XML. Elle se termine par >.
Il y a des DTD internes et des DTD externes. Un document XML peut avoir une DTD externe et une DTD interne. Une DTD interne est écrite dans le document XML avant la première balise. Une DTD externe est un fichier de type .DTD. Des exemples de DTD interne et externe sont disponibles sur le site selfhtml.
Une DTD permet de valider un document : un document est valide s'il est conforme à sa DTD c'est à dire s'il n'utilise que les balises de la DTD en respectant les contraintes d'ordre et de nombre imposés par la DTD. Une DTD contient des définitions pour les éléments (qui peuvent être éventuellement enrichis par des attributs), pour les notations et les entités.
Un élément est défini par <!ELEMENT suivi par un nom puis par un modèle qui est soit un type soit une règle de construction de l'élément pour définir les noeuds-enfants, c'est-à-dire les éléments qu'il contient. Le type peut être EMPTY, ANY, MIXED ou #PCDATA qui signifie chaine de caractères quelconques. Les opérateurs de nombre ? * + indiquent que l'élement peut apparaitre respectivement 0 ou 1 fois, 0 fois ou plus, 1 fois ou plus. Si on n'indique rien, la cardinalité est 1. Les parenthèses permettent de faire agir un opérateur de nombre sur une liste d'élements en respectant l'ordre.
Par exemple si on dit
- qu'une liste de films contient des films tout en pouvant être éventuellement vide,
- qu'un film contient un titre et au moins un acteur (dans cet ordre),
- qu'un acteur et un titre sont des chaines de caractères
on écrira la DTD suivante
<!ELEMENT films (film*)> <!ELEMENT film (titre, acteur+)> <!ELEMENT acteur (#PCDATA)> <!ELEMENT titre (#PCDATA)>
Par contre si on veut interdire qu'une liste de films soit vide il faut utiliser la définition
<!ELEMENT films (film+)>
Une notation permet de définir une application par défaut à lancer pour ouvrir des documents non XML. Ainsi
<!NOTATION jpg SYSTEM "monprog.exe">
indique que les images de type JPG seront associées au programme nommé monprog.
Un attribut enrichit un élément à l'aide d'un couple nom-valeur. Pour indiquer quels attributs sont associés à un élément, on utilise la définition <!ATTLIST suivi du nom de l'élément auquel elle s'applique. Si l'attribut est de type chaine, on utilise le mot CDATA. S'il s'agit d'une liste fixe de mots, on utilise une liste entre parenthèses dont le séparateur est |. Il existe d'autres types pour les attributs, comme ID, IDREF, IDREFS, NMTOKEN, NMTOKENS, ENTITY, ENTITIES et NOTATION que nous ne détaillerons pas ici. On peut qualifier la présence de l'attribut par une valeur par défaut ou par les mots #IMPLIED, #REQUIRED ou #FIXED qui signifient respectivement optionnel, obligatoire, remplacé par une valeur par défaut. Voici un exemple qui regroupe ces définitions :
<!ELEMENT service (#PCDATA) > <!ATTLIST service nomservice CDATA #REQUIRED > <!ATTLIST service consulaire (oui|non) "non" >
Une entité permet de déclarer un groupe d'éléments sous un nom, d'où une meilleure lisibilité, un contrôle accru sur le contenu et une plus grande facilité de mise à jour. On peut écrire des entités générales, des entités paramètres et des entités caractères. De plus elles peuvent être internes ou externes ; enfin, les entités générales externes peuvent être "parsées" (parsed en anglais) ou "non parsées" (unparsed en anglais) et dans ce dernier cas, le processeur XML ne regarde pas le code, ne s'inquiète pas des symboles <, > etc. On utilise les entités à l'aide de & au début et ; en fin. Par exemple
<!ENTITY auteur "Gilles HUNAULT"> <!ENTITY % ccm #REQUIRED type(K7|MiniDisc|Vinyl) "CD"> <!ENTITY ccedille "ç" > <!ENTITY nbsp "Š" >
permet d'écrire
Dans cet ouvrage, <titre>Candide<version>françle;aise</version></titre> utilisé par &auteur; ; comme exemple de document...
On trouvera dans la section Exemples détaillés des DTD complètes et expliquées. Un exemple réel de DTD est erele-090.dtd dont une copie au format texte est erele.txt. Il s'agit de la définition-type de documents pour les "études et rapports électroniques" du ministère de l'équipement qui s'inscrit dans le cadre de la gamme d'outils proposés pour mettre en oeuvre le plan de diffusion des données numériques du ministère.
Des exemples simples et progressifs de DTD sont proposés sur l'excellent site selfhtml à la rubrique XML/DTD comme la DTD personnes.dtd qui est une grammaire de description de personnes mélant éléments et attributs et collab.xml qui est un document XML avec une DTD interne visible dans la "source" du document ou dans cette copie au format-texte. On notera au passage l'utilisation d'un espace de nommage col:.
Voici d'autres exemples de DTD :
cv.dtd pour des CV en français resume.dtd pour des CV en anglais voltige.dtd une DTD pour décrire les figures de voltiges aériennes SVG DTD la spécification (longue) de la grammaire DTD pour les graphiques SVG SMIL 3 DTD la spécification (longue) de la grammaire DTD pour les fichiers de présentation multimedia SMIL Pour savoir comment on teste si un document XML est conforme à sa DTD, voir la section validation de DTD dans notre page sur les outils logiciels et les langages pour XML.
Dans la mesure où les DTD peuvent être internes à un document XML, les spécifications de DTD sont intégrées aux spécifications de XML 1.0. Nous les avons extraites dans le document dtd_specs.txt.
4. Les grammaires XSD ou schémas de balises
Les principaux reproches qu'on peut faire à une DTD sont les suivants
- il n'y a pas de typage fort : tout est chaine de caractères seulement. Ainsi #PCDATA peut correspondre à n'importe quelle chaine de caractères ; on ne peut donc pas définir qu'une date est au format XX et non pas au format MMXX avec une DTD, ni qu'elle est valide après 1975 par exemple ;
- il n'y pas de gestion de la cardinalité : par exemple on ne peut pas dire que tel élément doit contenir de 3 à 5 éléments d'un type donné ;
- la syntaxe des DTD n'est pas standard : un fichier .DTD n'est pas un fichier .XML et il est donc difficile de vérifier si une DTD est correctement écrite ;
- on ne peut pas faire hériter un élément d'un autre élément avec des spécifications raffinées comme en programmation objet.
Pour pallier à ces inconvénients, les schémas ont été créés. Ce sont de vrais fichiers XML dont le but est de valider les documents. Un schéma est un fichier de type .XSD ; il y a de fortes chances que les schémas supplantent les DTD dans les années futures. Toutefois, les DTD sont plus simples et plus faciles à écrire que les schémas.
Un schéma commence par une ligne <?xml version=" puisque c'est un document XML. La première balise est obligatoirement <xsd:schema, la plupart du temps associée à l'espace de noms XMLSchema du W3C soit le début de fichier
<?xml version="1.0"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
On notera au passage que la référence URI n'est pas une vraie URL : en particulier, il est tout à fait possible qu'il n'y ait aucun fichier nommé http://www.w3.org/2001/XMLSchema.
En principe, les balises d'un schéma commencent toutes soit par xsd ou par xs. En particulier, les éléments du schéma sont définis par <xsd:element et les attributs des éléments y sont définis par <xsd:attribute.
Pour associer un schéma à un fichier XML on peut utiliser l'attribut noNamespaceSchemaLocation d'une balise xsi qui fait référence aux schémas du W3C. Il est conseillé d'attacher cette balise xsi à la balise racine du document. Par exemple, si on veut associer le schéma meslivres.xsd au document livres.xml dont la balise racine est lesLivres on écrira comme début de fichier livres.xml
<?xml version="1.0"?> <lesLivres xsi:noNamespaceSchemaLocation="meslivres.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Les élements d'un schéma sont soit des éléments simples soit des éléments complexes. A chaque élément est associé un type, qu'il soit prédéfini par le W3C (comme par exemple xsd:string pour chaine de caractères) ou que ce soit un type inventé. Les attributs minOccurs et maxOccurs permettent de dire combien de fois chaque élément a le droit d'apparaitre (pour maxOccurs la valeur "unbounded" indique qu'aucune valeur maximale n'est précisée). La valeur par défaut pour minOccurs et maxOccurs est bien sur 1, ce qui permet de ne pas écrire ces attributs s'ils utilisent la valeur par défaut. L'ordre des éléments dans le schéma fixe l'ordre des éléments dans le document XML. Si un élément contient d'autres éléments ou des attributs, il doit être déclaré comme <xsd:complexType et ses éléments doivent être définis par la balise <xsd:sequence.
Prenons un exemple : disons qu'un film de cinéma a exactement un titre et un acteur ou plus (ce qui est faux en toute rigueur car les dessins animés n'ont pas d'acteur). Pour mettre dans le document cinema.xml deux films validés par le schéma films.xsd on écrit dans le document cinema.xml
<?xml version="1.0" ?> <films xsi:noNamespaceSchemaLocation="films.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" > <film> <titre>le silence des agneaux</titre> <acteur>jodie foster</acteur> <acteur>anthony hopkins</acteur> </film> <film> <titre>conan le barbare</titre> <acteur>arnold schwarzenegger</acteur> </film> </films>
et le schéma (fichier films.xsd) contiendra
<?xml version="1.0" ?> <xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="acteur" type="xsd:string"/> <xsd:element name="titre" type="xsd:string"/> <xsd:element name="film"> <xsd:complexType> <xsd:sequence> <xsd:element ref="titre"/> <xsd:element ref="acteur" maxOccurs="unbounded"/> </xsd:sequence> </xsd:complexType> </xsd:element> <xsd:element name="films"> <xsd:complexType> <xsd:sequence> <xsd:element ref="film" maxOccurs="unbounded"/> </xsd:sequence> </xsd:complexType> </xsd:element> </xsd:schema>
Il est possible de spécifier l'ordre ou de laisser un ordre quelconque avec les trois constructions de groupes suivantes :Les types prédéfinis, avec leurs plages de variations strictement définies, sont nombreux, comme par exemple
- xsd:all pour que chaque élément du groupe apparaisse au plus une fois, l'ordre n'étant pas important,
- xsd:choice pour qu'un seul élement n'apparaisse ou pour que de N à M éléments du groupe apparaisse dans un ordre quelconque,
- xsd:sequence pour chaque élément du groupe apparaisse exactement une fois dans l'ordre indiqué.
Pour controler les valeurs possibles on dispose d'attributs comme
- xsd:float, xsd:double, xsd:decimal, xsd:integer, xsd:nonPositiveInteger etc.
- xsd:gYear, xsd:gMonth, xsd:gDay, xsd:time, xsd:date
- xsd:string, xsd:normalizedString, xsd:token
- xsd:ENTITY, xsd:NOTATION, xsd:IDREF
Il est possible de définir un type dérivé qui utilise un type de base avec des restrictions. Par exemple pour définir l'année de naissance et imposer qu'elle n'est valide que pour 1950 et au-dela, on écrira
- xsd:minExclusive pour indiquer la valeur minimale (non comprise)
- xsd:maxInclusive pour indiquer la valeur maximale (comprise)
- xsd:maxExclusive pour indiquer la valeur maximale (non comprise)
- xsd:enumeration pour donner une liste de valeurs valides
- xsd:whiteSpace pour indiquer comment gérer les espaces et les caractères associés dans l'élément
- xsd:pattern pour utiliser une expression régulière de comparaison
<xsd:simpleType name="anNaissance"> <xsd:restriction base="xsd:gYear"> <xsd:minInclusive value="1950" /> </xsd:restriction> </xsd:simpleType>
De plus pour les chaines de caractères, on peut préciser des contraintes de longueur avec length, minLength, et maxLength. Pour les nombres, totalDigits et fractionDigits jouent un role similaire. Avec xsd:pattern on peut préciser des expressions régulières étendues (comprenant des spécifications pour l'unicode) qui permettent de restreindre principalement le type xsd:string.Pour être complet sur les schémas, signalons aussi qu'il est possible de gérer les espaces de noms dans les schémas. Par exemple on peut écrire
<xsd:schema xmlns:xsd="http://UN" xmlns="http://DEUX" targetNamespace="http://TROIS" elementFormDefault="qualified" attributeFormDefault="unqualified" >
ce qui permet ensuite de valider avec plusieurs espaces de noms un document xml qui commence par
<song:SONG xmlns:song="http://TROIS" xmlns:xsi="http://UN" xsi:schemaLocation ="UN namespace_song.xsd" >
On trouvera dans la section Exemples détaillés des schémas complets et expliqués. Un premier exemple réel est la grammaire siret.xsd pour les codes SIRET des entreprises (une copie au format xml est siret.xml) et un second est la grammaire actesv1_1.xsd pour la transmission des actes officiels entre organismes et [sous-]préfecture dont une copie en actesv1_1.xml est lisible comme un "vrai" document XML.
Voici d'autres exemples de Schémas XSD :
040917 (xmlfr) comment définir des formats décimaux français (ou bilingues) ? onix.xsd norme ONIX de la BTLF (schéma en extension xml ici) SMIL 2 XSD la spécification (longue) de la grammaire XSD pour les fichiers de présentation multimedia SMIL Pour savoir comment on teste si un document XML est conforme à son schéma, voir la section validation de schéma dans notre page sur les outils logiciels et les langages pour XML. Enfin, pour avoir une idée des types définis en XSD par le W3C, on lira la page built-in-datatypes.
On trouvera sur le site du W3C, rubrique XML Technology, sous-rubrique Schema les spécifications de XSD 1.1 ; la documentation en trois parties, dont un primer, une partie structure, structure et une partie type de données, montre bien la complexité de XSD.
Il est fortement conseillé de lire le «schéma du schéma» à l'adresse XMLSchema.xsd en copie locale ici.
5. Les XSL ou feuilles de styles généralisées et transformations
La transformation d'un document XML en un autre document, par exemple HTML, XHTML, PDF ou PS se fait à l'aide du langage XSL (soit eXtensible Stylesheet Language) qui utilise XSLT (soit eXtensible Stylesheet Language Transformation) et XSLFO (soit XSL Formatting Objects ). Il s'agit d'un véritable langage de programmation basé sur la technique de déclenchement d'actions vis à vis de règles de gabarits ou modèles ("templates rules"), un peu comme Awk mais en beaucoup plus complet et plus sophistiqué puisque les données sont structurées dans un arbre... Schématiquement, les opérations de sélection via XPATH utilisent des filtres sur les axes, éléments et attributs et autres contenus textuels à l'aides de fonctions sophistiquées où les expressions régulières sont omniprésentes qui renvoient des listes de noeuds, des sous-arbres alors que les actions associées profitent de la récursivité, des parcours d'arbres, de la modularité et de souplesse d'XML.
On peut donc à juste titre considérer un fichier XSL comme l'équivalent d'un programme procédural de traitement ou de mise en forme des données sans avoir à se préoccuper du langage de programmation.
XSLT peut produire à partir d'un fichier XML et d'un fichier XSL un document XML intermédiaire (arbre) que l'on convertira avec XSLFO en un "vrai" document XML, HTML, PS, PDF etc.
Un fichier XSL commence par une ligne <?xml version=" puisque c'est un document XML. Il peut servir directement de feuille de style pour un document XML si on le met en référence dans celui-ci. Par exemple pour que le document fac.xml utilise fac.xsl comme feuille de style, on écrira
<?xml-stylesheet type="text/xsl" href="fac.xsl" ?>Les navigateurs évolués (depuis Internet Explorer 5) interprétent alors directement le code XSL et produisent automatiquement la page Web. C'est donc en local sur votre PC que la transformation a lieu. Mais il est possible de faire effectuer la transformation par le serveur et de lui faire renvoyer le résultat de la transformation...
Il y a en général deux parties distinctes dans un XSL : une partie sélection par règles de noeuds, éléments, attributs... et une partie application de règle[s] sur les noeuds, éléments, attributs... sélectionnés. On dispose de plus de fonctions en XSL pour désigner des noeuds et des familles de noeuds, de fonctions pour extraire des informations au niveau des noeuds (texte, contenu, attributs, sous-arbre..), d'instructions pour effectuer des tests et des boucles. Comme ces fonctions XSL sont écrites en XML ce sont aussi des "éléments", n'est-ce pas ? En voici la liste.
Pour définir une règle, on utilise <xsl:template et pour apppliquer une règle on utilise <xsl:apply-templates et <xsl:call-template
Les actions associées aux règles peuvent être de simples affichages avec l'attribut select de la balise <xsl:value-of soit des opérations plus compliquées comme des tests, des boucles, des appels d'autres règles...
On peut passer en revue des listes de noeuds avec <xsl:for-each. Un test classique se fait avec la balise <xsl:if, une variable se gère avec <xsl:variable, un paramètre est géré par la balise <xsl:param, pour utiliser un attribut on met $ devant le nom de l'attribut. etc.
Voici un exemple de transformation XSLT qui passe en revue toutes les balises SALLES d'un cinéma et met en évidence les films qui passent cette semaine :
<xsl:template match="SALLES"> <xsl:for-each select="FILM"> <xsl:if test="($sem='cette semaine')"> <blink>en ce moment : </blink> <font color="RED"> <xsl:apply-template select="." /> </font> </xsl:if> </xsl:for-each> </xsl:template>
Comme autre exemple de transformation, vous pouvez lire notre conversion en anglais de balises :
<?xml version="1.0" encoding="ISO-8859-1" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="xml" /> <xsl:template match="/"> <PERSONS> <xsl:apply-templates /> </PERSONS> </xsl:template> <xsl:template match="personne"> <PERSON> <xsl:apply-templates select="nom" /> <xsl:apply-templates select="service" /> </PERSON> </xsl:template> <xsl:template match="nom"> <NAME> <xsl:value-of select="." /> </NAME> </xsl:template> <xsl:template match="service"> <SERV> <xsl:value-of select="." /> </SERV> </xsl:template> </xsl:stylesheet>
qui permet de passer du fichier XML français
<?xml version="1.0" encoding="ISO-8859-1" ?> <personnes> <personne> <nom>Dupond</nom> <service>Achats</service> </personne> <personne> <nom>Durand</nom> <service>Achats</service> </personne> <personne> <nom>Dupuis</nom> <service>Courrier</service> </personne> </personnes>
au fichier XML anglais
<?xml version="1.0" ?> <PERSONS> <PERSON> <NAME>Dupond</NAME> <SERV>Achats</SERV> </PERSON> <PERSON> <NAME>Durand</NAME> <SERV>Achats</SERV> </PERSON> <PERSON> <NAME>Dupuis</NAME> <SERV>Courrier</SERV> </PERSON> </PERSONS>
La difficulté pour programmer en XSL, c'est qu'il n'y a pas de "vraies" variables mais plutôt des éléments, des séquences de noeuds, d'arbres à traiter. Il faut les sélectionner avec des match et des select appliqués à des expressions AFP (Axe, Filtre, Prédicat) qui utilisent le langage XPATH. Il faut un certain temps pour maitriser les étapes de localisation et autres subtilités de filtrage (copie locale). Heureusement, les documents de Philippe RIGAUX comme xpath-trouver-son-chemin-xml sont là pour nous aider à comprendre XPath et un exemple de localisation comme celui de F. Sajous explicitent [un peu] ces notions a priori abstraites.
On trouvera dans la section Exemples détaillés des transformations plus sophistiquées et dans la sous-section 4.3 on pourra voir les notations classiques de désignation des axes. Des exercices progressifs (gH) sont disponibles avec corrigés à l'adresse webrd03. On pourra avec profit utiliser le logiciel xmlstarlet, options el -u, -a et -v pour voir comment chaque élément, chaque attribut d'un document XML est référencé en absolu à partir de la racine.
Un fichier XSL-FO commence par une ligne <?xml version=" puisque c'est un document XML. Il commence par la balise <fo:root et définit toutes les parties du document à produire comme les marges, chapitres, sections, paragraphes, listes, notes... Par exemple
<fo:layout-master-set> <fo:simple-page-master ...page-width="21cm">
permet de travailler en largeur française.
Nous ne détaillerons pas ici XSL-FO car nous lui consacrons la page spéciale tutxmlfo.htm. Signalons seulement qu'il existe des logiciels XSL-FO prêts à l'emploi avec leur processeur, comme FOP qui produit des documents PDF. Ces processeurs s'utilisent aussi bien dans des pages Web qu'en ligne de commande.
A ce propos, rappelons où et comment peuvent s'effectuer les transformations XSL. Tout d'abord elles peuvent s'effectuer sur le serveur en ligne de commande ou en "batch" ou à l'aide d'un script CGI ou d'un service Web lors d'une requête HTTP. Ensuite elles peuvent avoir lieu chez le client, en local, après chargement de la page et de sa feuille de style.
Ainsi le document titres1.xml dont une copie au format texte est titres1.txt s'affiche "relativement bien" tout seul avec un navigateur récent (vous pouvez même cliquer sur les signes - et + pour montrer ou masquer des parties de l'arbre). Si on lui adjoint la transformation contenue dans titres.xsl dont une copie au format texte est titres2.txt alors on obtient le document filtré et formaté titres.xml équivalent à la page web/html "normale" titres3.htm dont une copie au format texte est titres3.txt. Par contre regardez la source du document, vous aurez une surprise...
Comme le montre l'affichage du document titres.xml c'est votre navigateur (client) qui effectue la transformation après reçu toutes les données. Il est possible d'effectuer la transformation sur le serveur et d'envoyer le résultat de la transformation à votre navigateur. Vous pouvez le vérifier ici lorsque le serveur local est actif (en attendant une installation officielle). Si vous regardez la "source" du document vous n'aurez plus que le code HTML résultant de la transformation. Sur le serveur, le code PHP qui a effectué la transformation est le suivant :
<?php $nomXml = "titres.xml"; $nomXsl = "titres.xsl"; $xsl = new XSLTProcessor(); $xsl->importStyleSheet(DOMDocument::load($nomXsl)); echo $xsl->transformToXML(DOMDocument::load($nomXml)); ?>
Comme XSL a besoin de sélectionner, filtrer des noeuds de l'arbre, il utilise le langage XPATH qui s'écrit, devinez-quoi, en... XML. Une gentille introduction soutenue à XPATH est disponible sur selhtml. XPATH est un langage complet avec de nombreuses fonctions et opérateurs de sélection, de filtrage qui s'appliquent à des "nodeset" ou ensembles de noeuds...
Pour savoir comment on effectue une transformation XSL sur un document XML, voir la section transformations XSL dans notre page sur les outils logiciels et les langages pour XML.
En conclusion, XML permet de faire des documents "propres" via des règles strictes d'écriture contenant une information structurée, dont les balises et la structure (souple) peuvent être vérifiées grâce aux grammaires (DTD, XSD) tout en restant facilement accessibles (via XPATH) et transformables (via XSL).
On trouvera sur le site du W3C, rubrique XML Technology, sous-rubrique Transformation tout ce qui touche à XSL, et en particulier XSLT dont XSLT 1.1 et XSLT 2.0, XPATH et XQUERY, dont XPATH 1.0 et XPATH 2.0 ainsi que XSL-FO, même s'il serait plus logique de regrouper d'un coté XPATH 1.0 avec XSLT 1.1 et XPATH 2.0 avec XSLT 2.0. La DTD (non normative) proposée par le W3C pour XSL peut se résumer à xslt1.dtd. La présentation de la syntaxe XPATH sur le site selfhtml est sans doute l'introduction la plus lisible et la plus complète à XPATH. Un schéma pour XSL est sans doute xslt.xsd vu sur docflex, cité par w3pdf.