Introduction
Après «ma thèse en 3 secondes», «toute l'Encyclopedia Universalis en 20 lignes» et «les fondements de la rationalité de l'être chez Schopenhauer et Nietzsche en moins de 120 signes», voici une présentation ultra-courte de 10 minutes plus 5 minutes de démonstration interactive sur R avec une forte orientation bioinformatique.
Ce n'est, bien sûr, ni pédagogique ni faussement inutile, même si cela ressemble un peu à de la mise en scène.

1. Mini-présentation de R
R est un logiciel scriptable et programmable gratuit, disponible pour Windows, MacOs et Linux. Il est exhaustivement complet pour tout ce qui touche aux statistiques, ce qui inclut les biostatistiques et la bioinformatique.
R comprend :
-
des centaines de commandes de base ;
-
la possibilité d'enchainer les commandes et d'automatiser les traitements dans des scripts ;
-
des milliers de données prêtes à l'emploi, y compris en génomique, métagénomique ;
-
des structures de données adaptées aux statistiques, aux biostatistiques et à la bioinformatique : vecteurs, matrices, listes, "data frames", séries chronologiques, modèles statistiques... ;
-
des environnements d'exécution avec ou sans menu, avec production automatisée ou non de documents HTML, Word, LaTeX ou PDF ;
-
des milliers de fonctions déjà disponibles et la possibilité d'en programmer de nouvelles ;
-
des graphiques de qualité prévus pour les articles et les posters ;
-
une organisation en packages et en tâches pour [essayer de] s'y retrouver ;
-
des manuels de références, des documentations PDF nommées vignettes et des "vrais" livres ;
-
des millions d'utilisateurs et de professionnels, des blogs, des sites de référence, des conférences...
2. R et la bioinformatique dont la métagénomique
Les analyses bioinformatiques couvrent un large spectre de calculs et de techniques, que ce soit les constructions d'alignements de séquences, la réalisation d'arbres phylogénétiques, la visualisation sous forme de heatmaps, l'expression différentielle de gènes, l'analyse de réseaux d'interactions ou de réseaux de gènes, la prédiction de structures, la génétique des populations, la représentation en bigraphes de gènes et d'articles PUBMED, le calcul de distances génomiques euclidiennes ou non euclidiennes.. .
R est particulièrement bien adapté à ce genre de calculs et d'analyses parce que R est un langage assez ouvert et qui s'interface bien avec des exécutables utilisables en ligne de commandes. De plus les possibilités graphiques de R et sa lecture de fichiers sur Internet lui permettent d'accéder dynamiquement aux grandes bases de données biologiques du NCBI, de l'EBI, d'UNIPROT, sans compter son site dédié nommé Bioconductor...
De plus R n'est pas en reste pour tout ce qui concerne les données massives, que ce soit le faux Big Data, nommé aussi Big Data Statistique (disons moins de 100 Go de données, mais des tableaux de dimension (n,p) avec p>>n) ou le vrai Big Data, pour lequel les données ne tiennent pas en mémoire centrale, et qui nécessite plusieurs ordinateurs, plusieurs serveurs via un cluster ou un grid.
Enfin, la centralisation et la mise à disposition des calculs, données, exemples et fichiers d'aides font de R un laboratoire interactif d'outils bioinformatiques inégalable, même si le langage Python, plus généraliste, se révèle un concurrent sérieux et efficace, notamment quand on sait déjà programmer...
3. Bibliographie R volontairement restreinte et orientée bioinformatique
Des recherches sur le web avec les expressions
bioinformatics, "with R", "using R" et books ou filetype:pdf aboutissent à de nombreux ouvrages, parfois publiés, parfois simplement distribués sur le Web,
comme on peut le vérifier ci-dessous.
Voici mes favoris :
4. Démonstrations par l'exemple via R dans RStudio
Voici un texte R simple à lire pour compter puis analyser le nombre de nucléotides du gène X94991. C'est bien sûr R qui fait la lecture au NCBI de la séquence du gène via Internet (tout ce qui commence par # est un commentaire, ignoré par R) :
#############################################
# #
# comptage des nucléotides du gène X94991 #
# #
#############################################
#
# pour le GBSA (gH). novembre 2015 #
library(ape) # chargement de la librairie
geneX <- read.GenBank("X94991.1",as.character=TRUE) # lecture du gène demandé
cnt <- table(geneX) # comptages par type de nucléotide
print( cnt ) # affichage
print(chisq.test(cnt)) # calcul du chi-deux d'adéquation
Voici le résultat de l'exécution
geneX
a c g t
410 789 573 394
Chi-squared test for given probabilities
data: cnt X-squared = 187.07, df = 3, p-value < 2.2e-16
Moyennant quelques autres commandes on peut obtenir un affichage plus propre et graphique des comptages
#############################################
# #
# comptage des nucléotides du gène X94991 #
# puis pourcentages et graphiques #
# #
#############################################
#
# pour le GBSA (gH). novembre 2015 #
# tri à plat des nucléotides du gène
tap <- table(geneX)
# répartition détaillée des nucléotides
props <- as.numeric(prop.table(tap))
pcts <- paste(round(100*props,1),"%")
dfRes <- data.frame(tap,props,pcts)
names(dfRes) <- c("Nucléotides","Comptages","Proportions","Pourcentages")
print(dfRes)
# visualisation graphique
lng <- sum(tap)
coul <- rainbow(dim(tap)) # mieux que c("red","green","blue","yellow")
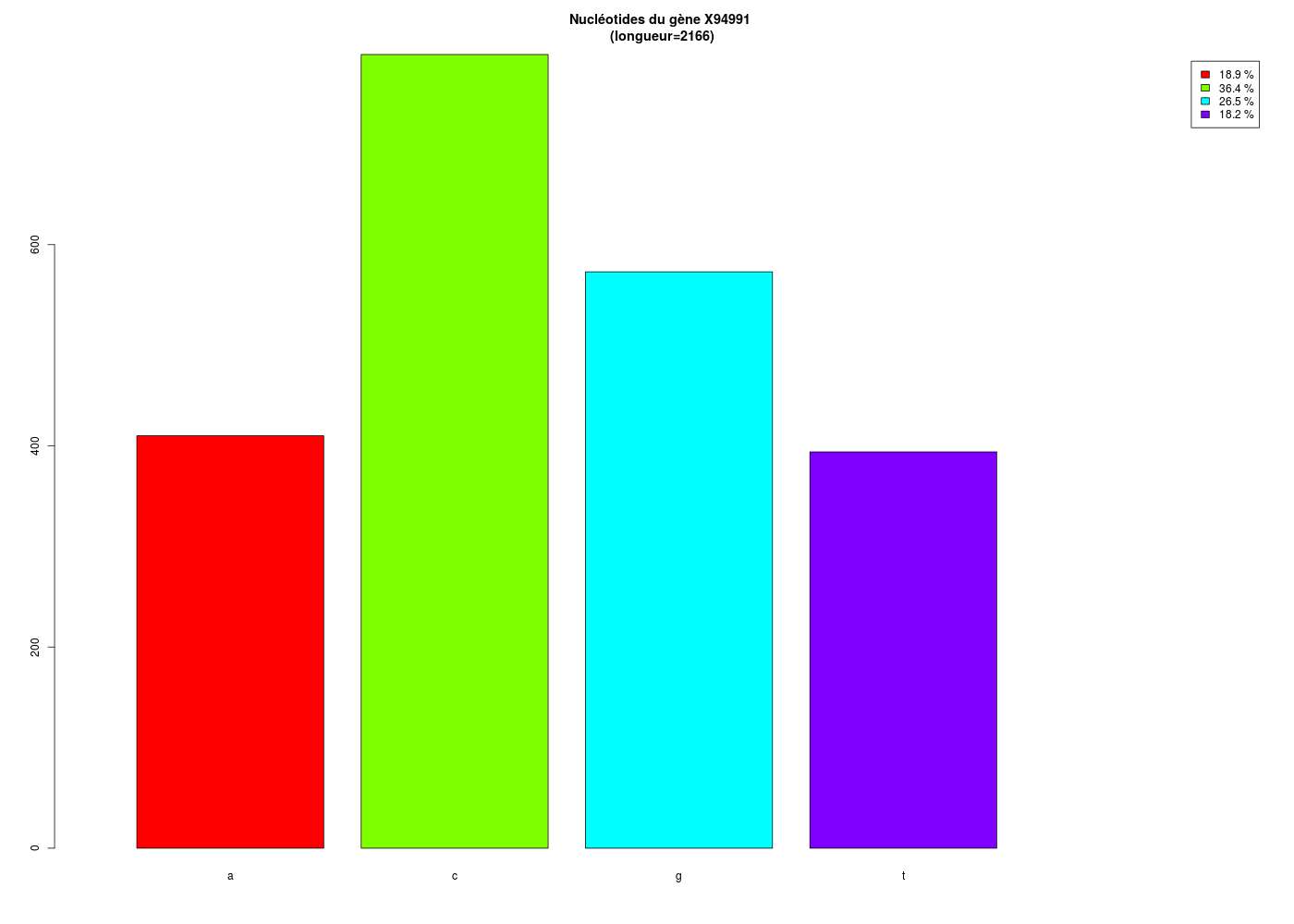
titre <- paste("Nucléotides du gène X94991\n (longueur=",lng,")",sep="")
barplot(tap,main=titre,col=coul,legend.text=pcts,xlim=c(0,6))
On obtient alors
Nucléotides Comptages Proportions Pourcentages
1 a 410 0.1892890 18.9 %
2 c 789 0.3642659 36.4 %
3 g 573 0.2645429 26.5 %
4 t 394 0.1819021 18.2 %
Ensuite, si on programme «un peu», on peut fournir des sorties en français et automatiser des traitements pour les utilisateurs de base :
#############################################
# #
# comptage des nucléotides du gène X94991 #
# calcu du chi2 d'équirépartition #
# #
#############################################
#
# pour le GBSA (gH). novembre 2015 #
# un chi-deux détaillé en français avec conclusion automatique
# issu des fonctions du "p'titgros"
# disponibles à l'adresse
# http://www.info.univ-angers.fr/~gh/wstat/statghfns.php
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1")
# réalisation du chi-deux et explications en français
# il s'agit ici du chi-deux d'adéquation à une distribution théorique
# (de même effectif global) soit ici la loi uniforme discrète,
# autrement dit, la loi sous hypothèse d'équirépartition
chi2Adeq(vth=rep(length(geneX[[1]])/4,4),vobs=tap,graph=TRUE)
CALCUL DU CHI-DEUX D'ADEQUATION
Valeurs théoriques 541.5 541.5 541.5 541.5
Valeurs observées 410 789 573 394
Valeur du chi-deux 187.0674
Chi-deux max (table) à 5 % 7.814728 pour 3 degrés de liberté ; p-value 2.62465e-40
décision : au seuil de 5 % on peut rejeter l'hypothèse
que les données observées correspondent aux valeurs théoriques.
Enfin, avec quelques commandes Markdown bien choisies, par exemple si on ajoute en début de fichier
---
title: bRavo !
output: all
---
# un exemple vite fait
```{r}
[...] ici le code R précédent
alors on produit en un seul clic les fichiers suivants :
Vous pouvez vérifier tout ceci en exécutant le fichier genex04.rmd suivant
---
title: "demoR15"
output: all
---
# Gène X94991
```{r}
library(ape) # chargement de la librairie
geneX <- read.GenBank("X94991.1",as.character=TRUE) # lecture du gène demandé
cnt <- table(geneX) # comptages par type de nucléotide
print( cnt ) # affichage
print( cnt ) # affichage
```
# Histogramme des fréquences
```{r, echo=FALSE}
# répartition détaillée des nucléotides
tap <- table(geneX)
props <- as.numeric(prop.table(tap))
pcts <- paste(round(100*props,1),"%")
dfRes <- data.frame(tap,props,pcts)
names(dfRes) <- c("Nucléotides","Comptages","Proportions","Pourcentages")
print(dfRes)
# visualisation graphique
lng <- sum(tap)
coul <- rainbow(dim(tap)) # mieux que c("red","green","blue","yellow")
titre <- paste("Nucléotides du gène X94991\n (longueur=",lng,")",sep="")
barplot(tap,main=titre,col=coul,legend.text=pcts,xlim=c(0,6))
```
# Avec les fonctions (gH)
```{r,echo=FALSE,print=FALSE}
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1")
```
```{r}
# réalisation du chi-deux et explications en français
# il s'agit ici du chi-deux d'adéquation à une distribution théorique
# (de même effectif global) soit ici la loi uniforme discrète,
# autrement dit, la loi sous hypothèse d'équirépartition
chi2Adeq(vth=rep(length(geneX[[1]])/4,4),vobs=tap,graph=TRUE)
```
5. Bilan (rapide) : avantages et inconvénients de R
Avantages de R
Très bel outil statistique, gratuit, complet, bien documenté et bien adapté à la bioinformatique, aux publications de recherche et aux études reproductibles car il permet de s'affranchir des copier/coller pour produire les rapports et articles.
Inconvénients de R
Difficile à maitriser rapidement sans y passer du temps. Oblige (mais est-ce vraiment un défaut ?) à programmer pour être très efficace.
Pour finir cet exposé, quatre bonnes nouvelles pour éviter qu'utiliser R ne soit une galère :

-
Le site Datajoy permet d'utiliser R via une interface Web, donc sans aucune installation.
-
Les sites try.codeschool et datacamp fournissent des cours de R en auto-apprentissage, si les nombreuses vidéos et tutoriels pour R ne vous suffisent pas.
-
Depuis plusieurs années (en fait depuis 2011), Statistica et SPSS intégrent R dans leurs menus et SAS accède à R via SAS/IML :
-
Votre serviteur forme, au niveau ingénieur, doctoral ou post-doctoral plus de 50 personnes par an.
Voir par exemple les pages EDA biostats et progR.
N'hésitez pas non plus à consulter la page R pour les biostatistiques en 5 minutes top chrono (!) .
|










 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)