![]()
![]()
Les dates de formation sont ici.
Solutions pour la séance numéro 5 (énoncés)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Solutions pour la séance numéro 5 (énoncés)
Comme indiqué à la séance 1, la notion de corrélation regroupe différents concepts. Si on s'intéresse à la liaison entre deux variables quantitatives différentes, la corrélation de Pearson, Kendall ou Spearman est adaptée. Si par contre on s'intéresse à la reproductibilité, il faut utiliser la corrélation de concordance au sens de Lin, qui modélise Y = X et non pas Y = aX+b. Enfin, si on veut analyser la concordance de plusieurs variables, la corrélation intra classes (dans le sens de "concordance") est sans doute ce qu'il faut utiliser. On consultera l'excellente page de J. Uebersax sur le sujet.
La fonction cor() du package stats permet de calculer des coefficiens de corrélation au sens de Pearson, Kendall ou Spearman. Pour calculer un coefficient de corrélation de Lin, il faut passer par la fonction epi.ccc() du package epiR (R package for EPIdemiological data). Enfin, les coefficients de corrélation intra classes peuvent être calculées au moyen de la fonction icc() du package psy (PSYchometry) ou de la fonction icc() du package MAc (Meta-Analysis with Correlations).
Corrélations pour les données sommeil animal :
Rappelons pourquoi la lecture des données en R via read.table() sur notre fichier sleep.txt ne pose pas de problème particulier : il faut sauter les premières lignes qui sont des commentaires, ne lire ensuite que 62 lignes, remplacer les -999.0 par des NA, convertir les trois dernières variables en "facteurs", soit le code :
# (gH) -_- sleep1.r ; TimeStamp (unix) : 10 Décembre 2013 vers 13:47 # lecture des données dans sleep.txt : # il y a 50 lignes de commentaires puis 62 lignes de données # de "African elephant" à "Yellow-bellied marmot" sleep <- read.table("http://forge.info.univ-angers.fr/~gh/wstat/Eda/sleep.txt", row.names=1,header=FALSE,skip=50,nrows=62,blank.lines.skip=FALSE) colnames(sleep) <- c( "poidsCorps", "poidsCerveau", "ondesLentes", "sommeilParadoxal", "sommeilTotal", "dureeVieMax", "dureeGestation", "predation", "exposition", "danger" ) # fin de c # il faut remplacer les -999.0 par des NA (non disponible) sleep[ sleep==-999.0 ] <- NA # il faut indiquer que predation, exposition et danger sont des # variables qualitatives ordinales sleep$predation <- factor(sleep$predation, levels=1:5, ordered=TRUE, labels=paste("IP",1:5,sep="") ) # fn de factor sleep$exposition <- factor(sleep$exposition, levels=1:5, ordered=TRUE, labels=paste("IE",1:5,sep="") ) # fn de factor sleep$danger <- factor(sleep$danger, levels=1:5, ordered=TRUE, labels=paste("ID",1:5,sep="") ) # fn de factor print(sleep)Si par contre on avait voulu lire le fichier original de statlib, il aurait fallu utiliser la fonction read.fwf() du package utils plutôt que la fonction read.table() et préciser les largeurs des colonnes, soit le code :
# (gH) -_- sleep1fwf.r ; TimeStamp (unix) : 10 Décembre 2013 vers 14:17 # lecture des données dans ib.stat.cmu.edu/datasets/sleep # il y a 50 lignes de commentaires puis 62 lignes de données # de "African elephant" à "Yellow-bellied marmot" # il y a des mots séparés donc il faut utiliser des formats de longueur fixe sleep <- read.fwf("http://lib.stat.cmu.edu/datasets/sleep", header=FALSE,skip=50,nrows=62,blank.lines.skip=FALSE, width=c(25,8,9,rep(8,8)) ) # fin de read colnames(sleep) <- c( "espece", "poidsCorps", "poidsCerveau", "ondesLentes", "sommeilParadoxal", "sommeilTotal", "dureeVieMax", "dureeGestation", "predation", "exposition", "danger" ) # fin de c # on met espéce comme identifiant de ligne row.names(sleep) <- sleep[,1] sleep <- sleep[,-1] # il faut remplacer les -999.0 par des NA (non disponible) sleep[ sleep==-999.0 ] <- NA # il faut indiquer que predation, exposition et danger sont des # variables qualitatives ordinales sleep$predation <- factor(sleep$predation, levels=1:5, ordered=TRUE, labels=paste("IP",1:5,sep="") ) # fn de factor sleep$exposition <- factor(sleep$exposition, levels=1:5, ordered=TRUE, labels=paste("IE",1:5,sep="") ) # fn de factor sleep$danger <- factor(sleep$danger, levels=1:5, ordered=TRUE, labels=paste("ID",1:5,sep="") ) # fn de factor print(sleep)Si vous n'avez pas réussi à lire les données, vous pouvez télécharger sleep.Rdata et exécuter load("sleep.Rdata") pour disposer du data.frame nommé sleep.
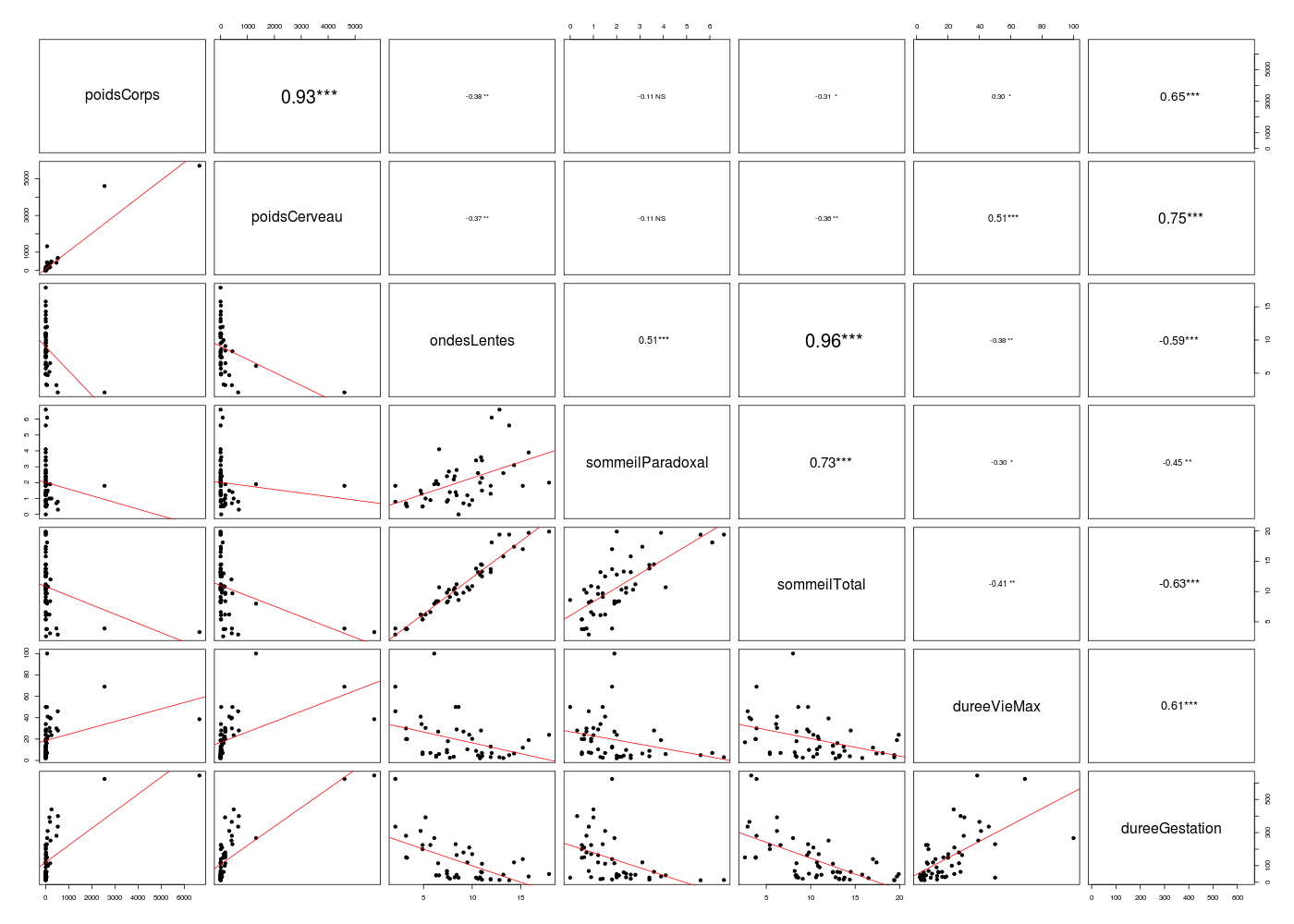
Une fois les données lues, on peut calculer des corrélations au sens de Pearson, Kendall et Spearman sur les variables quantitatives, seulement, avec la fonction cor() du package stats ou avec notre fonction mdc().
# on se restreint aux variables quantitatives sqt <- sleep[,(1:7)] # matrices de corrélation rectangulaires print( cor(sqt,method="pearson", use="pairwise.complete.obs") ) print( cor(sqt,method="kendall", use="pairwise.complete.obs") ) print( cor(sqt,method="spearman", use="pairwise.complete.obs") ) # matrices de corrélation triangulaires inférieures mdc(sqt,method="pearson") mdc(sqt,method="kendall") mdc(sqt,method="spearman")> # on se restreint aux variables quantitatives > > sqt <- sleep[,(1:7)] > # matrices de corrélation rectangulaires > > print( cor(sqt,method="pearson", use="pairwise.complete.obs") ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.0000000 0.9341638 -0.3759462 -0.1093833 -0.3071859 0.3024506 0.6511022 poidsCerveau 0.9341638 1.0000000 -0.3692177 -0.1051388 -0.3581020 0.5092527 0.7472425 ondesLentes -0.3759462 -0.3692177 1.0000000 0.5142539 0.9627147 -0.3844318 -0.5947028 sommeilParadoxal -0.1093833 -0.1051388 0.5142539 1.0000000 0.7270870 -0.2957453 -0.4508987 sommeilTotal -0.3071859 -0.3581020 0.9627147 0.7270870 1.0000000 -0.4102024 -0.6313262 dureeVieMax 0.3024506 0.5092527 -0.3844318 -0.2957453 -0.4102024 1.0000000 0.6148488 dureeGestation 0.6511022 0.7472425 -0.5947028 -0.4508987 -0.6313262 0.6148488 1.0000000 > print( cor(sqt,method="kendall", use="pairwise.complete.obs") ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.0000000 0.8334657 -0.3618561 -0.2533108 -0.3516921 0.5498203 0.5441867 poidsCerveau 0.8334657 1.0000000 -0.3860919 -0.3087198 -0.3864916 0.6636306 0.6073512 ondesLentes -0.3618561 -0.3860919 1.0000000 0.3832724 0.8503598 -0.2886283 -0.4416006 sommeilParadoxal -0.2533108 -0.3087198 0.3832724 1.0000000 0.5443938 -0.2716209 -0.4147186 sommeilTotal -0.3516921 -0.3864916 0.8503598 0.5443938 1.0000000 -0.3165320 -0.4779700 dureeVieMax 0.5498203 0.6636306 -0.2886283 -0.2716209 -0.3165320 1.0000000 0.4866147 dureeGestation 0.5441867 0.6073512 -0.4416006 -0.4147186 -0.4779700 0.4866147 1.0000000 > print( cor(sqt,method="spearman", use="pairwise.complete.obs") ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.0000000 0.9534986 -0.5051446 -0.4078569 -0.5058158 0.7240897 0.7282895 poidsCerveau 0.9534986 1.0000000 -0.5305696 -0.5057066 -0.5572121 0.8156980 0.8053013 ondesLentes -0.5051446 -0.5305696 1.0000000 0.5411845 0.9624671 -0.4141204 -0.5998025 sommeilParadoxal -0.4078569 -0.5057066 0.5411845 1.0000000 0.7240864 -0.4486152 -0.5822196 sommeilTotal -0.5058158 -0.5572121 0.9624671 0.7240864 1.0000000 -0.4574006 -0.6573483 dureeVieMax 0.7240897 0.8156980 -0.4141204 -0.4486152 -0.4574006 1.0000000 0.6728017 dureeGestation 0.7282895 0.8053013 -0.5998025 -0.5822196 -0.6573483 0.6728017 1.0000000 > # matrices de corrélation triangulaires inférieures > > mdc(sqt,method="pearson") Matrice des corrélations au sens de Pearson pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.934 1.000 ondesLentes -0.376 -0.369 1.000 sommeilParadoxal -0.109 -0.105 0.514 1.000 sommeilTotal -0.307 -0.358 0.963 0.727 1.000 dureeVieMax 0.302 0.509 -0.384 -0.296 -0.410 1.000 dureeGestation 0.651 0.747 -0.595 -0.451 -0.631 0.615 1.000 > mdc(sqt,method="kendall") Matrice des corrélations au sens de Kendall pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.833 1.000 ondesLentes -0.362 -0.386 1.000 sommeilParadoxal -0.253 -0.309 0.383 1.000 sommeilTotal -0.352 -0.386 0.850 0.544 1.000 dureeVieMax 0.550 0.664 -0.289 -0.272 -0.317 1.000 dureeGestation 0.544 0.607 -0.442 -0.415 -0.478 0.487 1.000 > mdc(sqt,method="spearman") Matrice des corrélations au sens de Spearman pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.953 1.000 ondesLentes -0.505 -0.531 1.000 sommeilParadoxal -0.408 -0.506 0.541 1.000 sommeilTotal -0.506 -0.557 0.962 0.724 1.000 dureeVieMax 0.724 0.816 -0.414 -0.449 -0.457 1.000 dureeGestation 0.728 0.805 -0.600 -0.582 -0.657 0.673 1.000Pour ne retenir que les «meilleures» corrélations, il faut se fixer un seuil (en valeur absolue), par exemple 0,7 ou 0,8. On peut alors utiliser notre fonction mdc() avec ses paramètres meilcor et stopcor.
# on se restreint aux variables quantitatives sqt <- sleep[,(1:7)] # meilleures corrélations mdc(sqt,method="pearson",meilcor=TRUE,stopcor=0.7)> # on se restreint aux variables quantitatives > > sqt <- sleep[,(1:7)] > # meilleures corrélations > > mdc(sqt,method="pearson",meilcor=TRUE,stopcor=0.7) Matrice des corrélations au sens de Pearson pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.934 1.000 ondesLentes -0.376 -0.369 1.000 sommeilParadoxal -0.109 -0.105 0.514 1.000 sommeilTotal -0.307 -0.358 0.963 0.727 1.000 dureeVieMax 0.302 0.509 -0.384 -0.296 -0.410 1.000 dureeGestation 0.651 0.747 -0.595 -0.451 -0.631 0.615 1.000 Meilleure corrélation 0.9627147 pour sommeilTotal et ondesLentes p-value 0 Formules ondesLentes = 0.771 * sommeilTotal + 0.427 et sommeilTotal = 1.203 * ondesLentes + 0.270 Coefficients de corrélation par ordre décroissant (on se restreint aux corrélations supérieures à 0.7 en valeur absolue) 0.963 p-value 0.0000 pour sommeilTotal et ondesLentes : sommeilTotal = 1.203 x ondesLentes + 0.270 0.934 p-value 0.0000 pour poidsCerveau et poidsCorps : poidsCerveau = 0.966 x poidsCorps + 91.004 0.747 p-value 0.0000 pour dureeGestation et poidsCerveau : dureeGestation = 0.114 x poidsCerveau + 107.960 0.727 p-value 0.0000 pour sommeilTotal et sommeilParadoxal : sommeilTotal = 2.305 x sommeilParadoxal + 6.027La corrélation de Spearman est liée à la monotonie des couples(x,y) alors que la corrélation de Pearson est liée à la linéarité. Si x et y croissent ensemble, leur corrélation de Spearman vaut forcément 1.
# chargement éventuel des fonctions gH : if (!exists("cats")) { source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") } # x et exp(x*x) sont liés mais pas linéairement x <- 1:10 y <- exp(x*x) # donc la corrélation au sens de Pearson est faible cat(" pearson : ",cor(x,y,method="pearson"),"\n") # alors que celle de Spearman est au maximum cat(" spearman : ",cor(x,y,method="spearman"),"\n") # tracé gr("corrun.png") plot(y~x,main="corrélation non linéaire",col="red",pch=19,type="b") dev.off()pearson : 0.522233 spearman : 1
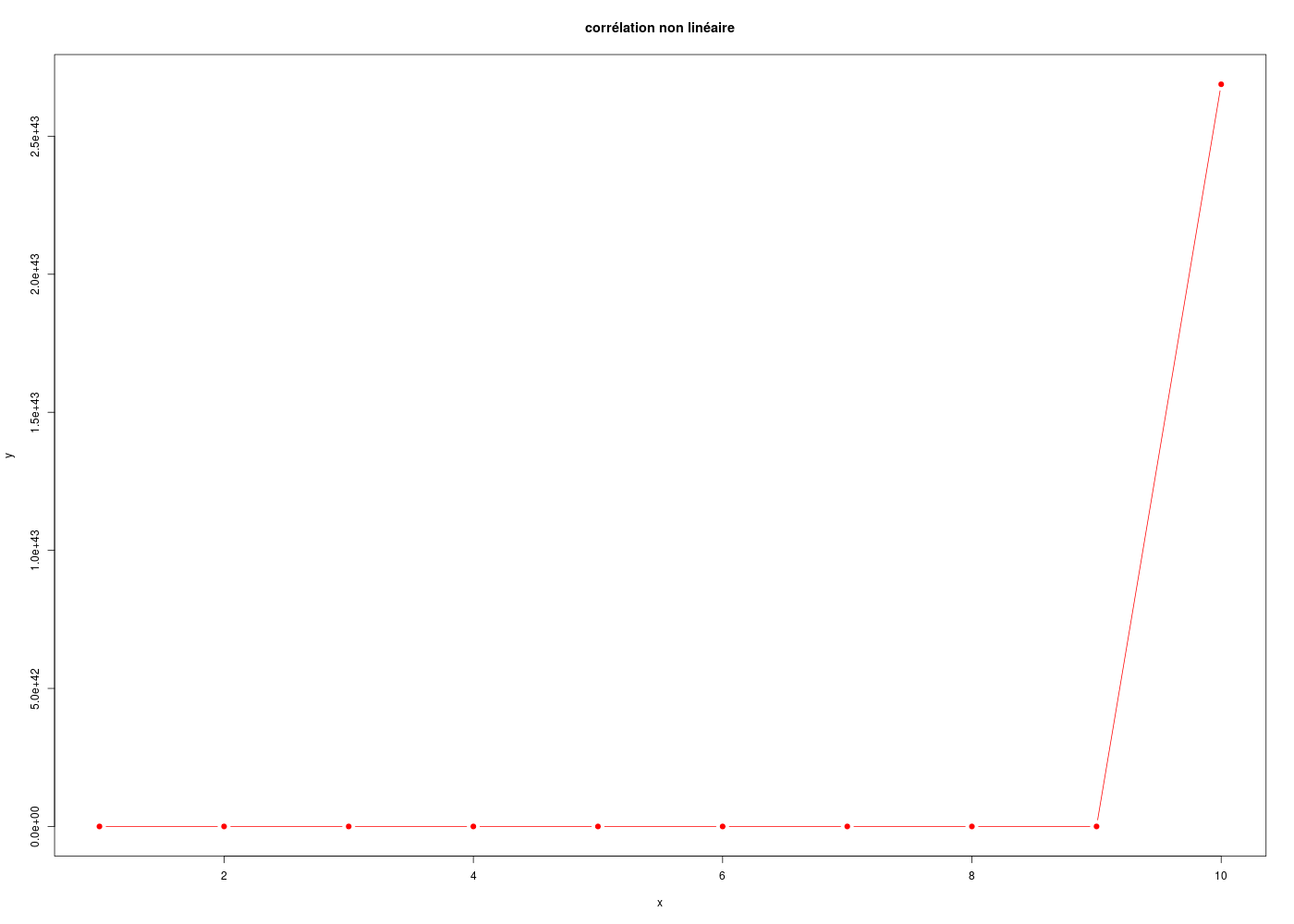
Il est facile de vérifier (et pas très difficile de démontrer) que la corrélation de Spearman entre X et Y quantitatives correspond exactement à la corrélation de Pearson des rangs de X et de Y :
## la corrélation de Spearman pour X et Y ## correspond à la corrélation de Pearson pour les rangs de X et de Y with(sleep, cor(poidsCorps,poidsCerveau,method="spearman")) # on trouve 0.9534986 with(sleep, cor(rank(poidsCorps),rank(poidsCerveau),method="pearson")) # on trouve aussi 0.9534986Si X et Y sont en corrélation linéaire parfaite, on parle de colinéarité et on peut alors écrire Y = aX+b. Si par contre on a une liaison linéaire entre plus de deux variables comme par exemple Z = cX+dY, on emploie le terme de multicolinéarité.
Le coefficient VIF permet de quantifier la multicolinéarité. La fonction vif() du package car implémente ce calcul.
Nous avons vu à la séance 3, exercice 2 que la mutlicolinéarité pouvait entrainer des inversions de signe dans les coefficients, ce qui rend donc l'interprétation des coefficients pour le moins périlleuse.
# chargement de la librairie car pour (la fonction vif) library(car) # lecture des données chenil <- lit.dar("chenilles.txt") # matrice de corrélation mdc(chenil) # coefficients vif si on régresse NIDS chenil1 <- chenil[, -ncol(chenil) ] ml1 <- lm(NIDS ~ ., data=chenil1) vi1 <- vif(ml1) print(summary(ml1)) print(vi1) # coefficients vif si on régresse LN_NID chenil2 <- chenil[, -11 ] ml2 <- lm(LN_NID ~ ., data=chenil2) vi2 <- vif(ml2) print(summary(ml2)) print(vi2) # coefficients vif si on régresse LN_NID # en fonction des variables 1 2 4 et 5 seulement ml3 <- lm(LN_NID ~ ALT + PENTE + HAUT + DIAM , data=chenil) vi3 <- vif(ml3) print(summary(ml3)) print(vi3)> # chargement de la librairie car pour (la fonction vif) > > library(car) > # lecture des données > > chenil <- lit.dar("chenilles.txt") > # matrice de corrélation > > mdc(chenil) Matrice des corrélations au sens de Pearson pour 33 lignes et 12 colonnes ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN NIDS LN_NID ALT 1.000 PENTE 0.121 1.000 PINS 0.538 0.322 1.000 HAUT 0.321 0.137 0.414 1.000 DIAM 0.284 0.113 0.295 0.905 1.000 DENS 0.515 0.301 0.980 0.439 0.306 1.000 ORIEN 0.268 -0.152 0.128 0.058 -0.079 0.151 1.000 HAUTDOM 0.360 0.262 0.759 0.772 0.596 0.810 0.060 1.000 STRAT 0.364 0.326 0.877 0.460 0.267 0.909 0.063 0.854 1.000 MELAN -0.100 0.129 0.206 -0.045 -0.025 0.130 0.138 0.054 0.175 1.000 NIDS -0.530 -0.455 -0.564 -0.358 -0.158 -0.570 -0.212 -0.551 -0.636 -0.124 1.000 LN_NID -0.534 -0.429 -0.518 -0.425 -0.201 -0.528 -0.230 -0.541 -0.594 -0.063 0.876 1.000 > # coefficients vif si on régresse NIDS > > chenil1 <- chenil[, -ncol(chenil) ] > ml1 <- lm(NIDS ~ ., data=chenil1) > vi1 <- vif(ml1) > print(summary(ml1)) Call: lm(formula = NIDS ~ ., data = chenil1) Residuals: Min 1Q Median 3Q Max -1.04564 -0.28874 -0.03165 0.22697 1.35444 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 8.243695 2.040342 4.040 0.000547 *** ALT -0.002875 0.001038 -2.770 0.011166 * PENTE -0.035048 0.014601 -2.400 0.025275 * PINS 0.027882 0.066320 0.420 0.678260 HAUT -0.466332 0.375903 -1.241 0.227835 DIAM 0.103799 0.069591 1.492 0.150015 DENS 0.075530 1.044392 0.072 0.943001 ORIEN -0.260833 0.670724 -0.389 0.701101 HAUTDOM 0.023532 0.157828 0.149 0.882832 STRAT -0.886833 0.576610 -1.538 0.138306 MELAN -0.332745 0.489952 -0.679 0.504132 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.5529 on 22 degrees of freedom Multiple R-squared: 0.6767, Adjusted R-squared: 0.5297 F-statistic: 4.604 on 10 and 22 DF, p-value: 0.001361 > print(vi1) ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN 1.877395 1.190410 41.870812 16.021876 9.384459 58.755770 1.649080 14.422552 11.168597 1.650929 > # coefficients vif si on régresse LN_NID > > chenil2 <- chenil[, -11 ] > ml2 <- lm(LN_NID ~ ., data=chenil2) > vi2 <- vif(ml2) > print(summary(ml2)) Call: lm(formula = LN_NID ~ ., data = chenil2) Residuals: Min 1Q Median 3Q Max -1.69899 -0.27317 -0.00036 0.32463 1.73050 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 10.998412 3.060273 3.594 0.00161 ** ALT -0.004431 0.001557 -2.846 0.00939 ** PENTE -0.053830 0.021900 -2.458 0.02232 * PINS 0.067939 0.099472 0.683 0.50174 HAUT -1.293637 0.563811 -2.294 0.03168 * DIAM 0.231637 0.104378 2.219 0.03709 * DENS -0.356788 1.566465 -0.228 0.82193 ORIEN -0.237473 1.006006 -0.236 0.81557 HAUTDOM 0.181061 0.236724 0.765 0.45248 STRAT -1.285322 0.864848 -1.486 0.15142 MELAN -0.433102 0.734870 -0.589 0.56162 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.8293 on 22 degrees of freedom Multiple R-squared: 0.6949, Adjusted R-squared: 0.5563 F-statistic: 5.012 on 10 and 22 DF, p-value: 0.0007878 > print(vi2) ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN 1.877395 1.190410 41.870812 16.021876 9.384459 58.755770 1.649080 14.422552 11.168597 1.650929 > # coefficients vif si on régresse LN_NID > # en fonction des variables 1 2 4 et 5 seulement > > ml3 <- lm(LN_NID ~ ALT + PENTE + HAUT + DIAM , .... [TRUNCATED] > vi3 <- vif(ml3) > print(summary(ml3)) Call: lm(formula = LN_NID ~ ALT + PENTE + HAUT + DIAM, data = chenil) Residuals: Min 1Q Median 3Q Max -2.02087 -0.25012 0.09002 0.35179 1.71056 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.732147 1.488585 5.194 1.63e-05 *** ALT -0.003924 0.001148 -3.419 0.001946 ** PENTE -0.057343 0.019388 -2.958 0.006236 ** HAUT -1.356138 0.319834 -4.240 0.000220 *** DIAM 0.283059 0.076260 3.712 0.000905 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.7906 on 28 degrees of freedom Multiple R-squared: 0.6471, Adjusted R-squared: 0.5967 F-statistic: 12.83 on 4 and 28 DF, p-value: 4.677e-06 > print(vi3) ALT PENTE HAUT DIAM 1.122649 1.026427 5.672093 5.511056Il est d'usage de «soupçonner» la mutlicolinéarité lorsqu'un coefficient VIF est supérieur à 10, voire juste supérieur à 5 (mais cela ne donne pas la relation de mutlicolinéarité). Donc ici avec toutes les variables, les coefficients VIF pour PINS (41.870812) et DENS (58.755770) montrent qu'il y a mutlicolinéarité. Comment résoudre le problème est une autre histoire.
En mathématiques, on parle aussi bien de colinéarité que de dépendance linéaire ou de relation linéaire (entre deux vecteurs, en algèbre linéaire). Le terme de corrélation linéaire est plus un terme statistique que mathématique.
On pourrait penser qu'il est possible d'utiliser les outils mathématiques que sont les déterminants pour détecter la multi-colinéarité. En pratique, ce n'est pas possible car on ne pourrait garantir que Δ=0 et encore que si le calcul et exact !
Si on réfléchit bien, il n'y a pas que la valeur du coefficient de corrélation à afficher. Il peut être intéressant d'afficher aussi la p-value du test qui indique si le coefficient est significativement différent de zéro, et éventuellement le nombre de couples sur lequel le coefficient est calculé, comme le fait SAS, car il peut y avoir des données manquantes à certains endroits :
body_weight brain_weight slow_sleep para_sleep total_sleep span body_weight 1.00000 0.93416 -0.37595 -0.10938 -0.30719 0.30245 <.0001 0.0085 0.4495 0.0190 0.0210 62 62 48 50 58 58 brain_weight 0.93416 1.00000 -0.36922 -0.10514 -0.35810 0.50925 <.0001 0.0098 0.4674 0.0058 <.0001 62 62 48 50 58 58 slow_sleep -0.37595 -0.36922 1.00000 0.51425 0.96271 -0.38443 0.0085 0.0098 0.0002 <.0001 0.0091 48 48 48 48 48 45 para_sleep -0.10938 -0.10514 0.51425 1.00000 0.72709 -0.29575 0.4495 0.4674 0.0002 <.0001 0.0436 50 50 48 50 48 47 total_sleep -0.30719 -0.35810 0.96271 0.72709 1.00000 -0.41020 0.0190 0.0058 <.0001 <.0001 0.0021 58 58 48 48 58 54 span 0.30245 0.50925 -0.38443 -0.29575 -0.41020 1.00000 0.0210 <.0001 0.0091 0.0436 0.0021 58 58 45 47 54 58Dès qu'on a plus de quelques variables, afficher la matrice sous sa forme triangulaire inférieure (puisqu'elle est symétrique) peut faciliter sa lecture, comme réduire le nombre de décimales :
# analyse des correlations dans le df sleep # (on a exécuté sleep.r pour lire les données) sqt <- sleep[,(1:7)] # que les quantitatives # matrice des corrélations classiques (rectangulaire) print( cor(sqt) ) # à cause des NA, il faut préciser le paramètre use mcor <- cor(sqt,use="pairwise.complete.obs") print( mcor ) # c'est plus facile à lire avec moins de décimales : print( round(mcor,3) ) # notre fonction mdc renvoie une matrice triangulaire inférieure mdc(sqt)> # analyse des correlations dans le df sleep > # (on a exécuté sleep.r pour lire les données) > > sqt <- sleep[,(1:7)] # que les quantitatives > # matrice des corrélations classiques (rectangulaire) > > print( cor(sqt) ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.0000000 0.9341638 NA NA NA NA NA poidsCerveau 0.9341638 1.0000000 NA NA NA NA NA ondesLentes NA NA 1 NA NA NA NA sommeilParadoxal NA NA NA 1 NA NA NA sommeilTotal NA NA NA NA 1 NA NA dureeVieMax NA NA NA NA NA 1 NA dureeGestation NA NA NA NA NA NA 1 > # à cause des NA, il faut préciser le paramètre use > > mcor <- cor(sqt,use="pairwise.complete.obs") > print( mcor ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.0000000 0.9341638 -0.3759462 -0.1093833 -0.3071859 0.3024506 0.6511022 poidsCerveau 0.9341638 1.0000000 -0.3692177 -0.1051388 -0.3581020 0.5092527 0.7472425 ondesLentes -0.3759462 -0.3692177 1.0000000 0.5142539 0.9627147 -0.3844318 -0.5947028 sommeilParadoxal -0.1093833 -0.1051388 0.5142539 1.0000000 0.7270870 -0.2957453 -0.4508987 sommeilTotal -0.3071859 -0.3581020 0.9627147 0.7270870 1.0000000 -0.4102024 -0.6313262 dureeVieMax 0.3024506 0.5092527 -0.3844318 -0.2957453 -0.4102024 1.0000000 0.6148488 dureeGestation 0.6511022 0.7472425 -0.5947028 -0.4508987 -0.6313262 0.6148488 1.0000000 > # c'est plus facile à lire avec moins de décimales : > > print( round(mcor,3) ) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 0.934 -0.376 -0.109 -0.307 0.302 0.651 poidsCerveau 0.934 1.000 -0.369 -0.105 -0.358 0.509 0.747 ondesLentes -0.376 -0.369 1.000 0.514 0.963 -0.384 -0.595 sommeilParadoxal -0.109 -0.105 0.514 1.000 0.727 -0.296 -0.451 sommeilTotal -0.307 -0.358 0.963 0.727 1.000 -0.410 -0.631 dureeVieMax 0.302 0.509 -0.384 -0.296 -0.410 1.000 0.615 dureeGestation 0.651 0.747 -0.595 -0.451 -0.631 0.615 1.000 > # notre fonction mdc renvoie une matrice triangulaire inférieure > > mdc(sqt) Matrice des corrélations au sens de Pearson pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.934 1.000 ondesLentes -0.376 -0.369 1.000 sommeilParadoxal -0.109 -0.105 0.514 1.000 sommeilTotal -0.307 -0.358 0.963 0.727 1.000 dureeVieMax 0.302 0.509 -0.384 -0.296 -0.410 1.000 dureeGestation 0.651 0.747 -0.595 -0.451 -0.631 0.615 1.000Lorsqu'on a peu de variables, la fonction pairs() du package graphics fournit de bonnes représentations, que l'on peut personnaliser, par exemple à l'aide de notre fonction pairsi() :
# affichage par paires gr("sleep_pairs1.png") pairs(sqt) dev.off() gr("sleep_pairs2.png") pairsi(sqt,opt=1) # fonction gH dev.off() gr("sleep_pairs3.png") pairsi(sqt,opt=2) # fonction gH dev.off()
De nombreuses représentations existent pour essayer d'aider à visualiser l'ensemble de la matrice des coefficients de corrélation, de façon à bien faire ressortir les corrélations fortes, à différencier les corrélations positives des négatives, à montrer comment regrouper les variables. On peut ainsi citer :
- la fonction corrplot() du package corrplot,
- la fonction corclust() du package klaR,
- la fonction hclustvar() du package ClustOfVar,
- la fonction plot.corGraph() du package pcalg,
- notre fonction corCircle(),
- la fonction correlogram() du package Correlplot,
- la fonction corrgram() du package corrgram.
# visualisation des correlations dans le df sleep # (on a exécuté sleep.r pour lire les données) sqt <- sleep[,(1:7)] # que les quantitatives # matrice des corrélations mcor <- cor(sqt,use="pairwise.complete.obs") # "heatmap" des corrélation library(corrplot) gr("sleepcor1.png") corrplot(mcor) dev.off() # classification hiérarchique library(ClustOfVar) plot(hclustvar(sqt)) library(klaR) gr("sleepcor2.png") corclust(sqt) dev.off() # graphe des corrélations library(pcalg) print( cg <- corGraph(sqt)) gr("sleepcor3.png") plot( cg) dev.off() # notre corCircle issu de l'ACP gr("sleepcor4.png") corCircle(titre="sleep",data=sqt) dev.off() # un corrélogramme du package Correlplot library(Correlplot) gr("sleepcor5.png") correlogram(mcor) dev.off() # corrgram du package corrgram library(corrgram) gr("sleepcor6.png") corrgram(mcor) dev.off()> # visualisation des correlations dans le df sleep > # (on a exécuté sleep.r pour lire les données) > > sqt <- sleep[,(1:7)] # que les quantitatives > # matrice des corrélations > > mcor <- cor(sqt,use="pairwise.complete.obs") > # "heatmap" des corrélation > > library(corrplot) > gr("sleepcor1.png") > corrplot(mcor) > dev.off() > # classification hiérarchique > > # library(hclustvar) ??? dommage > > library(klaR) > gr("sleepcor2.png") > corclust(sqt) $min.abs.cor poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 0.00000000 0.06583616 0.62405375 0.8906167 0.69281409 0.6975494 0.3488978 poidsCerveau 0.06583616 0.00000000 0.63078234 0.8948612 0.64189797 0.4907473 0.2527575 ondesLentes 0.62405375 0.63078234 0.00000000 0.4857461 0.03728529 0.6155682 0.4052972 sommeilParadoxal 0.89061669 0.89486121 0.48574607 0.0000000 0.27291304 0.7042547 0.5491013 sommeilTotal 0.69281409 0.64189797 0.03728529 0.2729130 0.00000000 0.5897976 0.3686738 dureeVieMax 0.69754944 0.49074732 0.61556821 0.7042547 0.58979761 0.0000000 0.3851512 dureeGestation 0.34889782 0.25275752 0.40529723 0.5491013 0.36867380 0.3851512 0.0000000 $clustering Call: hclust(d = variables, method = method) Cluster method : complete Number of objects: 7 > dev.off() > # graphe des corrélations > > library(pcalg) > print( cg <- corGraph(sqt)) A graphNEL graph with undirected edges Number of Nodes = 7 Number of Edges = 19 > gr("sleepcor3.png") > plot( cg) > dev.off() > # notre corCircle issu de l'ACP > > gr("sleepcor4.png") > corCircle(titre="sleep",data=sqt) > dev.off()
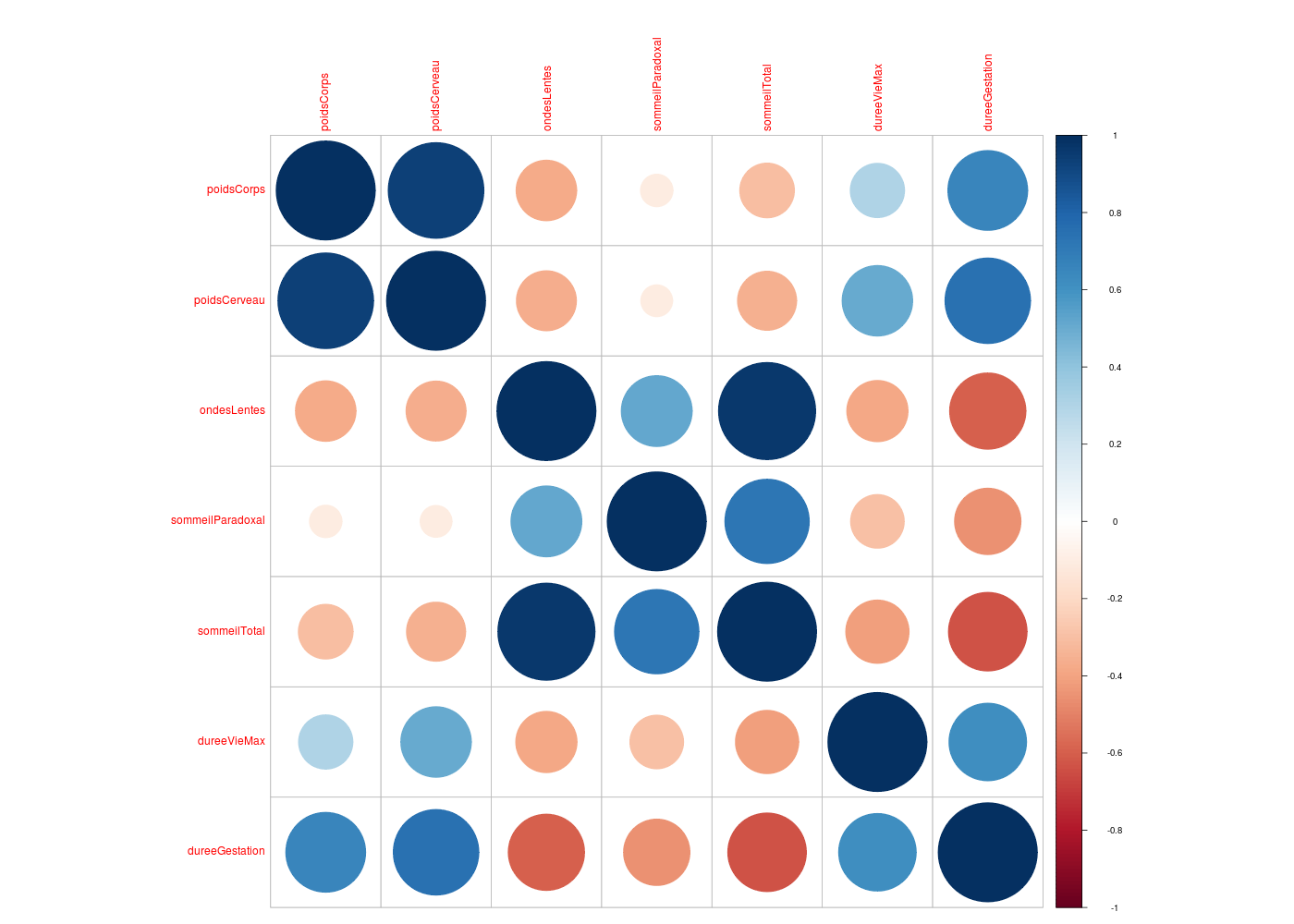

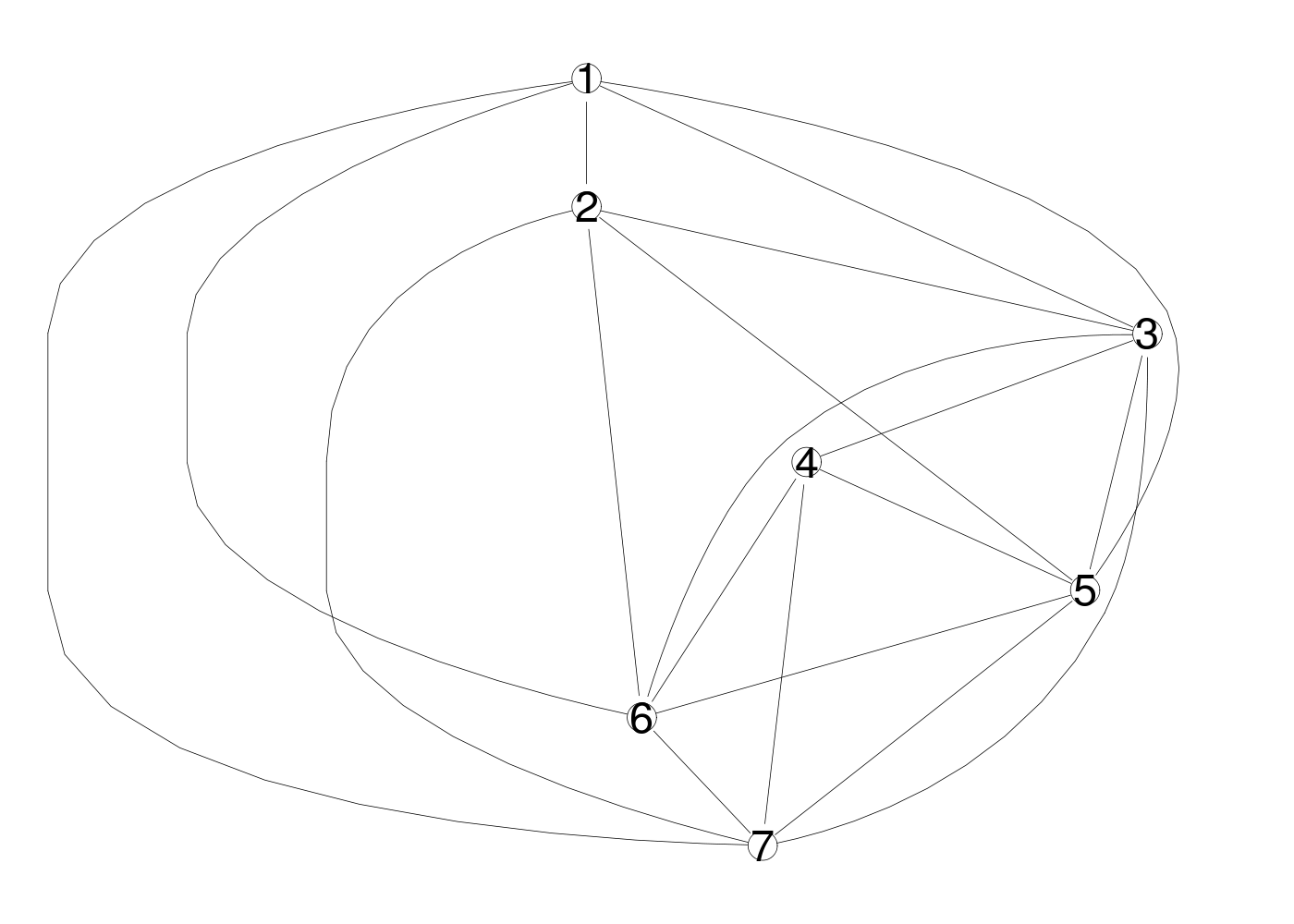
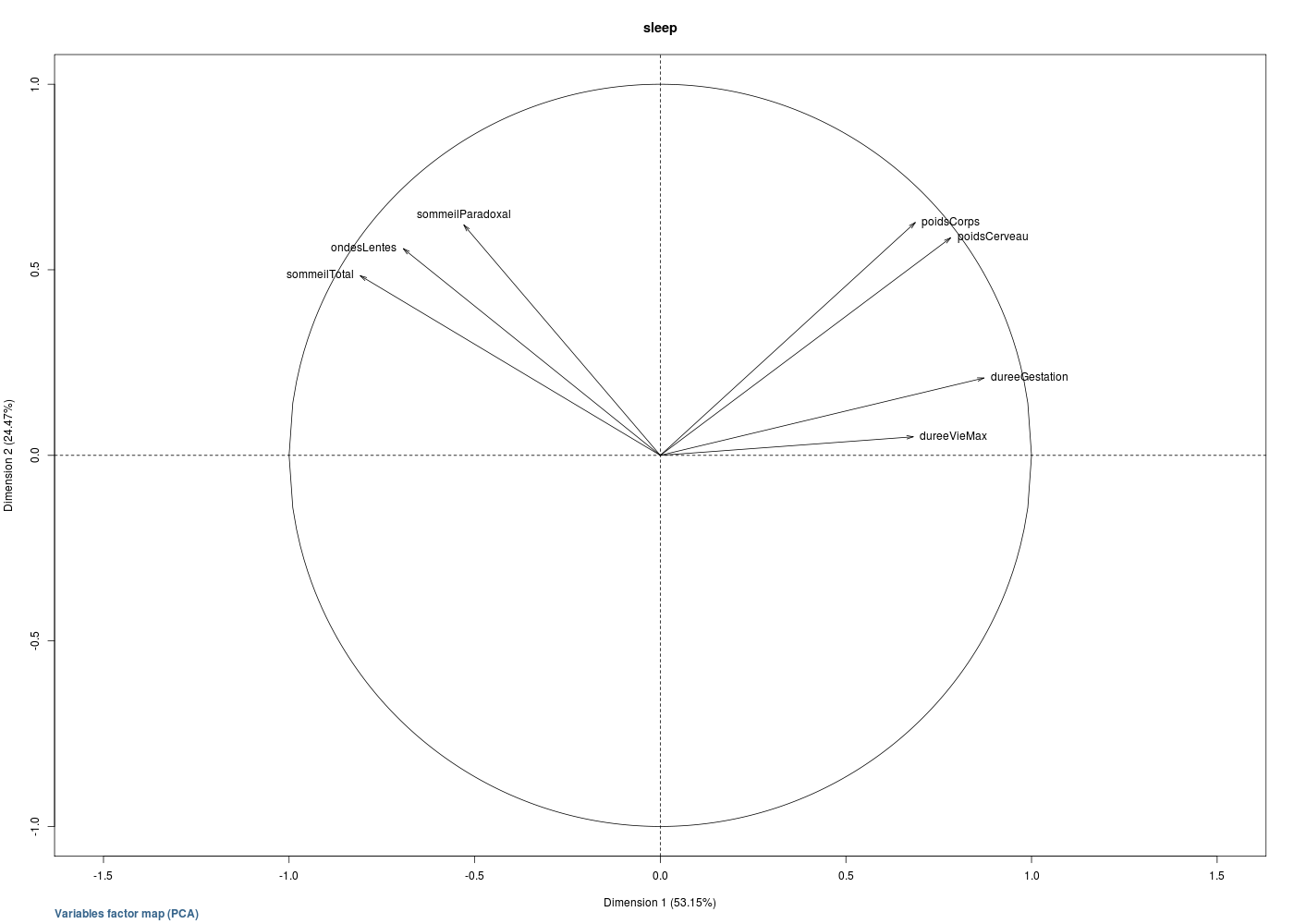
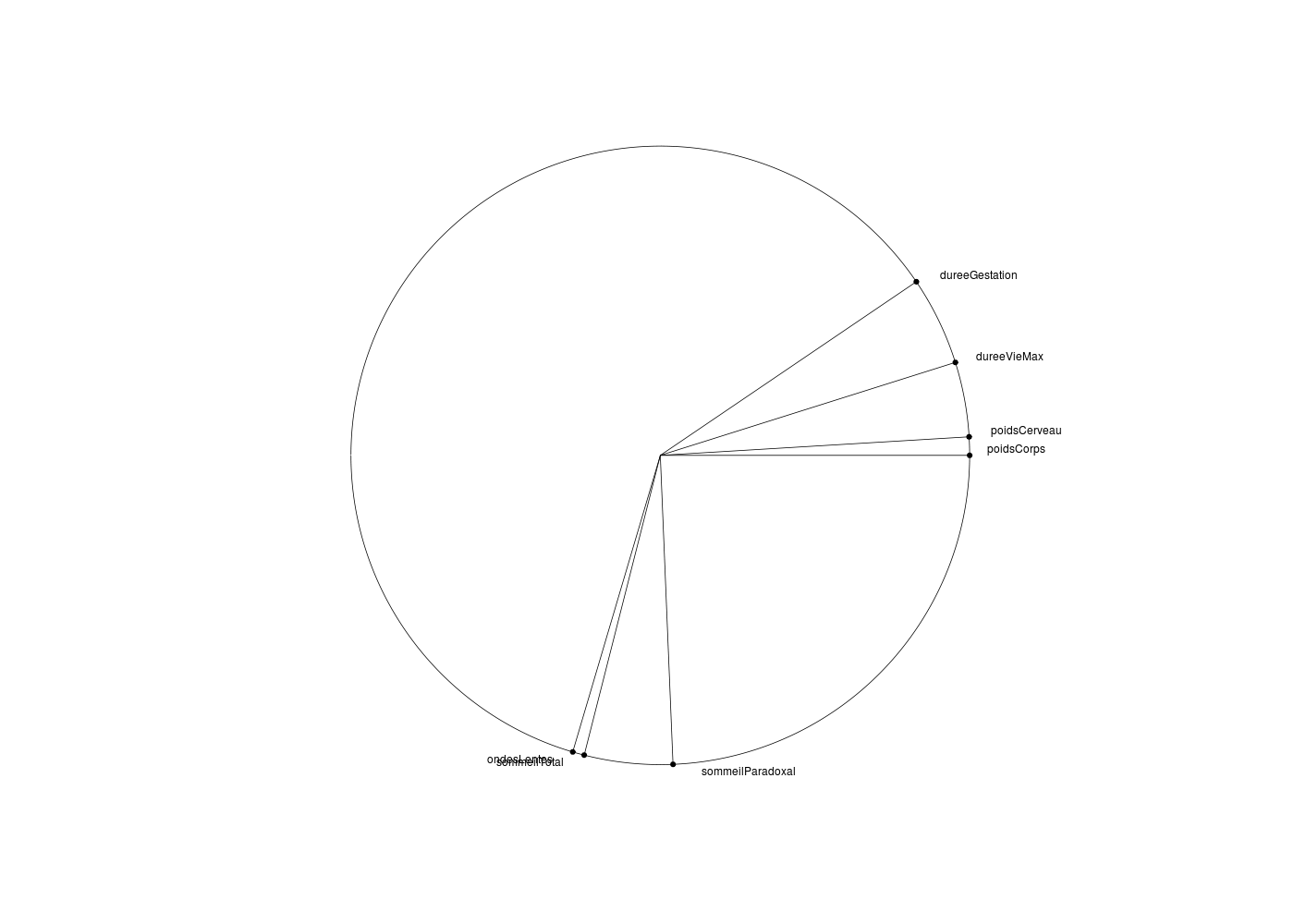

On peut aussi, et c'est ce que font certains logiciels du commerce comme Sas, Statistica, afficher en couleur les coefficients significativement non nuls, en rouge les significativement positifs, en vert les significativement négatifs...
Application aux données chenilles
Si on veut voir les valeurs de corrélation, notre fonction mdc() est sans doute adaptée. Mais un hclust ou une heatmap ou un corrélogramme est sans doute plus visuel :
# lecture des données chen <- lit.dar("chenilles.dar") # valeurs de la matrice de corrélation mdc(chen,meilcor=TRUE,stopcor=0.7) # 0.7 choisi "après coup" mcor <- cor(chen) # représentation hiérarchique gr("chen_cor1.png") library(klaR) corclust(chen) dev.off() # heatmap gr("chen_cor2.png") library(corrplot) corrplot(mcor) dev.off() # corrélogramme gr("chen_cor3.png") library(corrgram) corrgram(mcor) dev.off()Matrice des corrélations au sens de Pearson pour 33 lignes et 12 colonnes ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN NIDS LN_NID ALT 1.000 PENTE 0.121 1.000 PINS 0.538 0.322 1.000 HAUT 0.321 0.137 0.414 1.000 DIAM 0.284 0.113 0.295 0.905 1.000 DENS 0.515 0.301 0.980 0.439 0.306 1.000 ORIEN 0.268 -0.152 0.128 0.058 -0.079 0.151 1.000 HAUTDOM 0.360 0.262 0.759 0.772 0.596 0.810 0.060 1.000 STRAT 0.364 0.326 0.877 0.460 0.267 0.909 0.063 0.854 1.000 MELAN -0.100 0.129 0.206 -0.045 -0.025 0.130 0.138 0.054 0.175 1.000 NIDS -0.530 -0.455 -0.564 -0.358 -0.158 -0.570 -0.212 -0.551 -0.636 -0.124 1.000 LN_NID -0.534 -0.429 -0.518 -0.425 -0.201 -0.528 -0.230 -0.541 -0.594 -0.063 0.876 1.000 Meilleure corrélation 0.9795521 pour DENS et PINS p-value 0 Formules PINS = 13.022 * DENS -11.867 et DENS = 0.074 * PINS + 0.947 Coefficients de corrélation par ordre décroissant (on se restreint aux corrélations supérieures à 0.7 en valeur absolue) 0.980 p-value 0.0000 pour DENS et PINS : DENS = 0.074 x PINS + 0.947 0.909 p-value 0.0000 pour STRAT et DENS : STRAT = 0.717 x DENS + 0.697 0.905 p-value 0.0000 pour DIAM et HAUT : DIAM = 3.740 x HAUT - 1.397 0.877 p-value 0.0000 pour STRAT et PINS : STRAT = 0.052 x PINS + 1.385 0.876 p-value 0.0000 pour LN_NID et NIDS : LN_NID = 1.353 x NIDS - 1.911 0.854 p-value 0.0000 pour STRAT et HAUTDOM : STRAT = 0.206 x HAUTDOM + 0.432 0.810 p-value 0.0000 pour HAUTDOM et DENS : HAUTDOM = 2.656 x DENS + 2.782 0.772 p-value 0.0000 pour HAUTDOM et HAUT : HAUTDOM = 1.744 x HAUT - 0.226 0.759 p-value 0.0000 pour HAUTDOM et PINS : HAUTDOM = 0.187 x PINS + 5.395

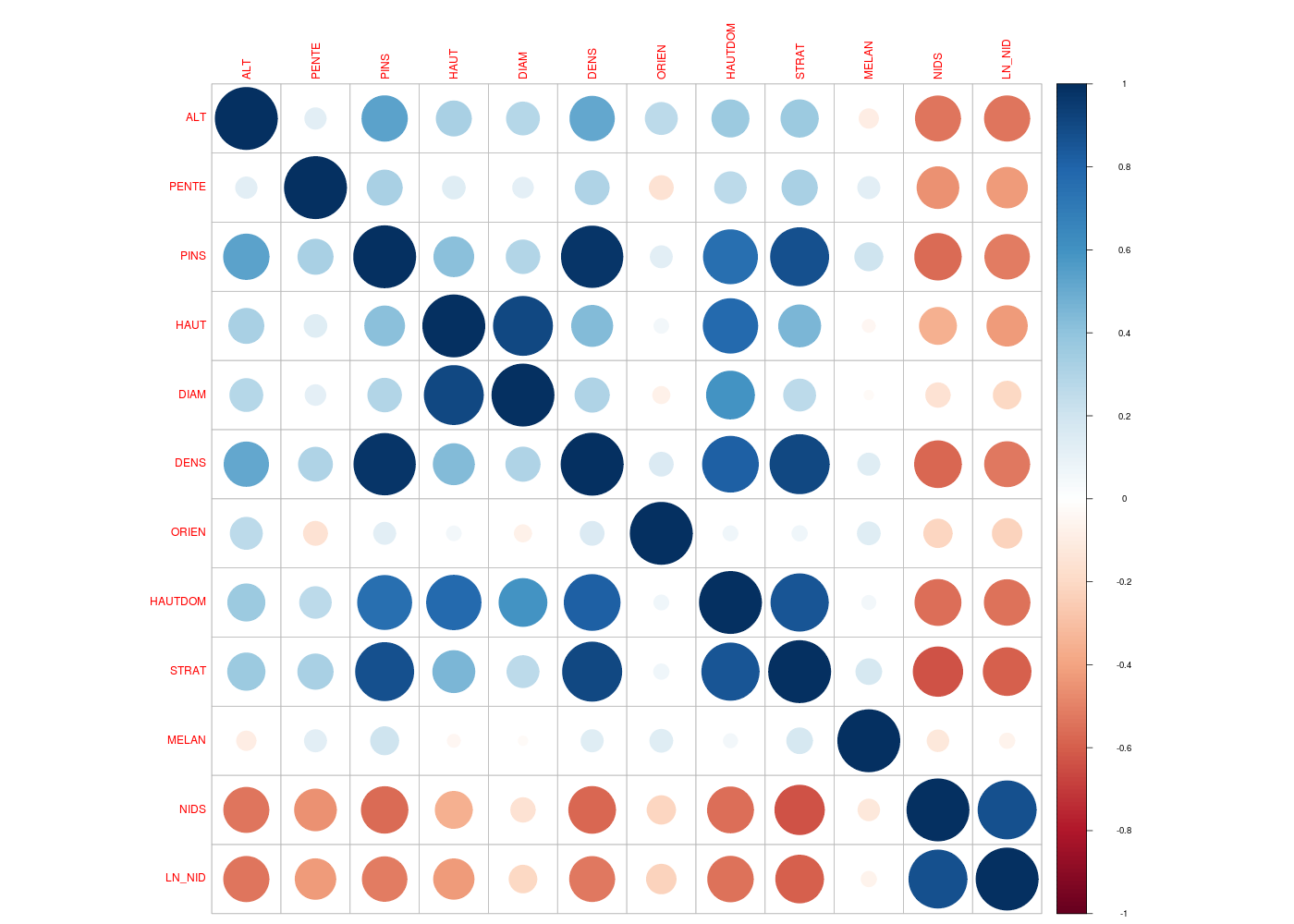
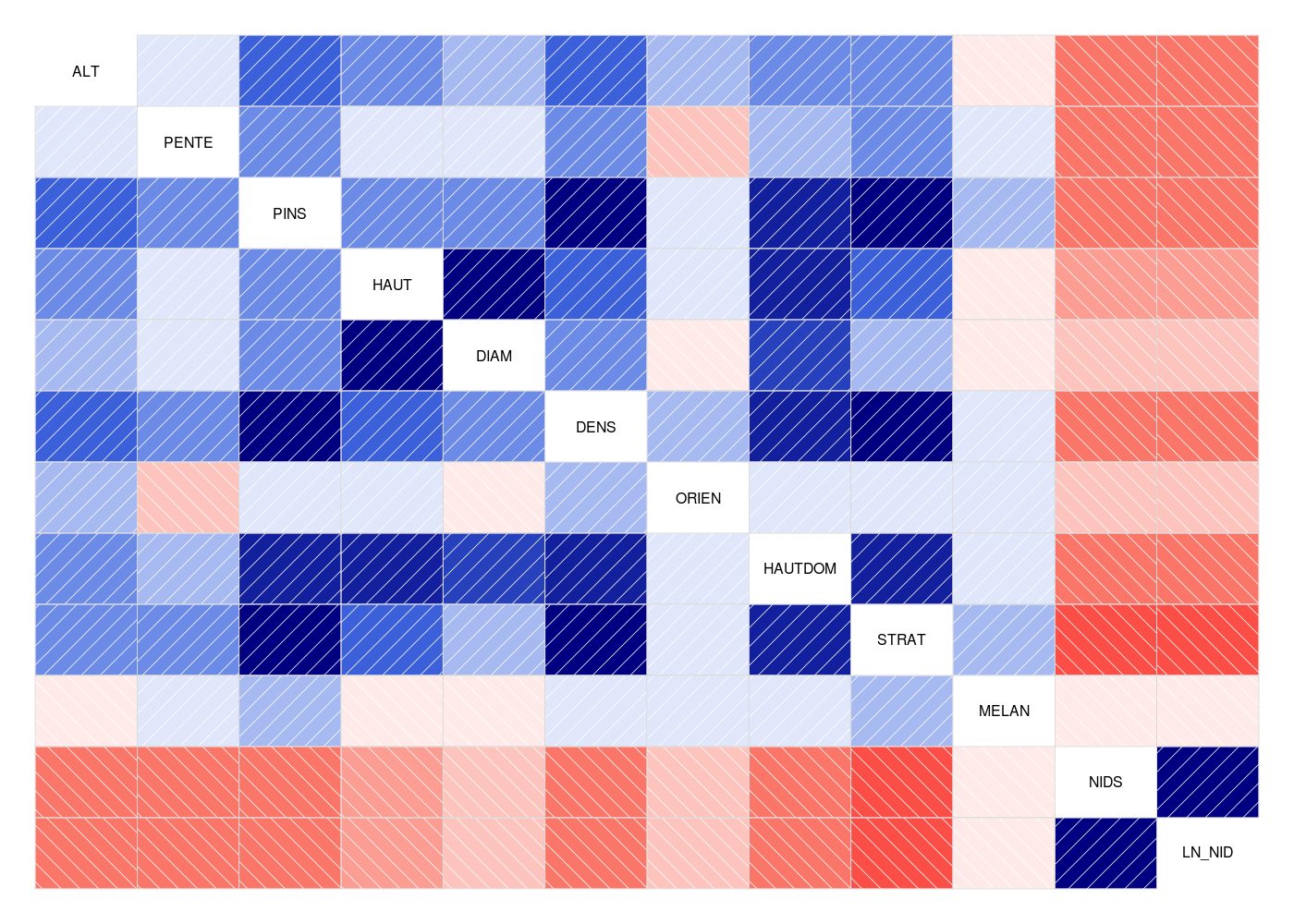
Application aux données hers
Hélas, le fichier de données contient de nombreuses variables qualitatives. Pour traiter de corrélation, il faut commencer par faire le ménage pour ne garder que les quantitatives...
# lecture des données library(gdata) #hers <- read.xls("hersdata.xls") # il y a beaucoup de variables cat(" il y a ",ncol(hers)," variables\n") lvnonql <- c() nbnonql <- 0 # dont de nombreuses sont qualitatives... for (idv in (1:ncol(hers))) { cat("variable numéro ",sprintf("%2d",idv)," soit ",sprintf("%-15s",colnames(hers)[idv])," : ") if (is.factor(hers[,idv])) { cat(" qualitative") } else { nbnonql <- nbnonql + 1 cat(" sans doute non qualitative numéro ",sprintf("%02d",nbnonql)) lvnonql <- c(lvnonql,idv) } # fin si cat("\n") } # fin pour idv # ici, on peut sans doute calculer des corrélations vqt <- hers[, lvnonql ] mdc(vqt,meilcor=TRUE,stopcor=0.8) # la valeur 0.8 a été choisie a posteriori mcor <- cor(vqt,use="pairwise.complete.obs") # représentation hiérarchique gr("hers_cor1.png") library(klaR) corclust(vqt) dev.off() # heatmap gr("hers_cor2.png") library(corrplot) corrplot(mcor) dev.off() # corrélogramme gr("hers_cor3.png") library(corrgram) corrgram(mcor) dev.off()il y a 37 variables variable numéro 1 soit HT : qualitative variable numéro 2 soit age : sans doute non qualitative numéro 01 variable numéro 3 soit raceth : qualitative variable numéro 4 soit nonwhite : qualitative variable numéro 5 soit smoking : qualitative variable numéro 6 soit drinkany : qualitative variable numéro 7 soit exercise : qualitative variable numéro 8 soit physact : qualitative variable numéro 9 soit globrat : qualitative variable numéro 10 soit poorfair : qualitative variable numéro 11 soit medcond : sans doute non qualitative numéro 02 variable numéro 12 soit htnmeds : qualitative variable numéro 13 soit statins : qualitative variable numéro 14 soit diabetes : qualitative variable numéro 15 soit dmpills : qualitative variable numéro 16 soit insulin : qualitative variable numéro 17 soit weight : sans doute non qualitative numéro 03 variable numéro 18 soit BMI : sans doute non qualitative numéro 04 variable numéro 19 soit waist : sans doute non qualitative numéro 05 variable numéro 20 soit WHR : sans doute non qualitative numéro 06 variable numéro 21 soit glucose : sans doute non qualitative numéro 07 variable numéro 22 soit weight1 : sans doute non qualitative numéro 08 variable numéro 23 soit BMI1 : sans doute non qualitative numéro 09 variable numéro 24 soit waist1 : sans doute non qualitative numéro 10 variable numéro 25 soit WHR1 : sans doute non qualitative numéro 11 variable numéro 26 soit glucose1 : sans doute non qualitative numéro 12 variable numéro 27 soit tchol : sans doute non qualitative numéro 13 variable numéro 28 soit LDL : sans doute non qualitative numéro 14 variable numéro 29 soit HDL : sans doute non qualitative numéro 15 variable numéro 30 soit TG : sans doute non qualitative numéro 16 variable numéro 31 soit tchol1 : sans doute non qualitative numéro 17 variable numéro 32 soit LDL1 : sans doute non qualitative numéro 18 variable numéro 33 soit HDL1 : sans doute non qualitative numéro 19 variable numéro 34 soit TG1 : sans doute non qualitative numéro 20 variable numéro 35 soit SBP : sans doute non qualitative numéro 21 variable numéro 36 soit DBP : sans doute non qualitative numéro 22 variable numéro 37 soit age10 : sans doute non qualitative numéro 23 Matrice des corrélations au sens de Pearson pour 2763 lignes et 23 colonnes age medcond weight BMI waist WHR glucose weight1 BMI1 waist1 WHR1 glucose1 tchol LDL HDL TG tchol1 LDL1 HDL1 TG1 SBP DBP age10 age 1.000 medcond 0.052 1.000 weight -0.219 0.024 1.000 BMI -0.159 0.045 0.921 1.000 waist -0.141 0.036 0.850 0.840 1.000 WHR -0.055 0.042 0.285 0.286 0.651 1.000 glucose -0.074 0.074 0.252 0.273 0.309 0.248 1.000 weight1 -0.231 0.013 0.968 0.886 0.820 0.261 0.238 1.000 BMI1 -0.170 0.032 0.892 0.962 0.813 0.264 0.257 0.924 1.000 waist1 -0.154 0.041 0.845 0.835 0.934 0.564 0.310 0.860 0.857 1.000 WHR1 -0.072 0.055 0.308 0.311 0.608 0.825 0.262 0.306 0.314 0.663 1.000 glucose1 -0.076 0.091 0.216 0.228 0.267 0.221 0.694 0.207 0.222 0.268 0.242 1.000 tchol -0.015 -0.032 0.039 0.048 0.031 0.005 0.014 0.021 0.035 0.028 0.011 -0.017 1.000 LDL -0.052 -0.051 0.057 0.061 0.038 0.006 0.006 0.041 0.050 0.038 0.009 -0.016 0.939 1.000 HDL 0.117 0.001 -0.197 -0.194 -0.240 -0.223 -0.123 -0.201 -0.198 -0.237 -0.219 -0.133 0.177 -0.022 1.000 TG -0.009 0.051 0.160 0.177 0.236 0.231 0.161 0.154 0.169 0.221 0.234 0.129 0.247 0.074 -0.409 1.000 tchol1 -0.016 -0.010 0.004 0.023 0.021 0.025 -0.021 0.016 0.038 0.036 0.039 0.029 0.611 0.572 0.133 0.125 1.000 LDL1 -0.048 -0.024 0.024 0.035 0.027 0.021 -0.025 0.035 0.049 0.042 0.033 0.013 0.553 0.592 0.007 0.009 0.910 1.000 HDL1 0.113 -0.008 -0.194 -0.193 -0.231 -0.200 -0.155 -0.208 -0.206 -0.236 -0.201 -0.173 0.112 -0.011 0.732 -0.364 0.118 -0.072 1.000 TG1 -0.026 0.044 0.111 0.130 0.180 0.182 0.142 0.126 0.148 0.189 0.190 0.188 0.110 0.025 -0.299 0.589 0.235 -0.036 -0.375 1.000 SBP 0.165 0.071 0.032 0.060 0.071 0.066 0.106 0.024 0.055 0.071 0.068 0.116 0.072 0.052 0.010 0.071 0.068 0.049 0.002 0.054 1.000 DBP -0.142 -0.028 0.122 0.111 0.110 0.035 -0.001 0.128 0.124 0.117 0.042 0.007 0.114 0.109 0.033 0.008 0.101 0.091 0.027 0.017 0.519 1.000 age10 1.000 0.052 -0.219 -0.159 -0.141 -0.055 -0.074 -0.231 -0.170 -0.154 -0.072 -0.076 -0.015 -0.052 0.117 -0.009 -0.016 -0.048 0.113 -0.026 0.165 -0.142 1.000 Meilleure corrélation 1 pour age10 et age p-value 0 Formules age = 10.000 * age10 + 0.000 et age10 = 0.100 * age -0.000 Coefficients de corrélation par ordre décroissant (on se restreint aux corrélations supérieures à 0.8 en valeur absolue) 1.000 p-value 0.0000 pour age10 et age : age10 = 0.100 x age - 0.000 0.968 p-value 0.0000 pour weight1 et weight : weight1 = 0.986 x weight + 0.306 0.962 p-value 0.0000 pour BMI1 et BMI : BMI1 = 0.979 x BMI + 0.393 0.939 p-value 0.0000 pour LDL et tchol : LDL = 0.867 x tchol - 53.086 0.934 p-value 0.0000 pour waist1 et waist : waist1 = 0.936 x waist + 5.300 0.924 p-value 0.0000 pour BMI1 et weight1 : BMI1 = 0.345 x weight1 + 3.528 0.921 p-value 0.0000 pour BMI et weight : BMI = 0.345 x weight + 3.458 0.910 p-value 0.0000 pour LDL1 et tchol1 : LDL1 = 0.864 x tchol1 - 56.994 0.892 p-value 0.0000 pour BMI1 et weight : BMI1 = 0.339 x weight + 3.701 0.886 p-value 0.0000 pour weight1 et BMI : weight1 = 2.419 x BMI + 2.911 0.860 p-value 0.0000 pour waist1 et weight1 : waist1 = 0.780 x weight1 + 34.989 0.857 p-value 0.0000 pour waist1 et BMI1 : waist1 = 2.084 x BMI1 + 32.035 0.850 p-value 0.0000 pour waist et weight : waist = 0.784 x weight + 34.742 0.845 p-value 0.0000 pour waist1 et weight : waist1 = 0.780 x weight + 34.366 0.840 p-value 0.0000 pour waist et BMI : waist = 2.065 x BMI + 32.729 0.835 p-value 0.0000 pour waist1 et BMI : waist1 = 2.065 x BMI + 32.109 0.825 p-value 0.0000 pour WHR1 et WHR : WHR1 = 0.807 x WHR + 0.165 0.820 p-value 0.0000 pour weight1 et waist : weight1 = 0.906 x waist - 11.024 0.813 p-value 0.0000 pour BMI1 et waist : BMI1 = 0.335 x waist - 2.339
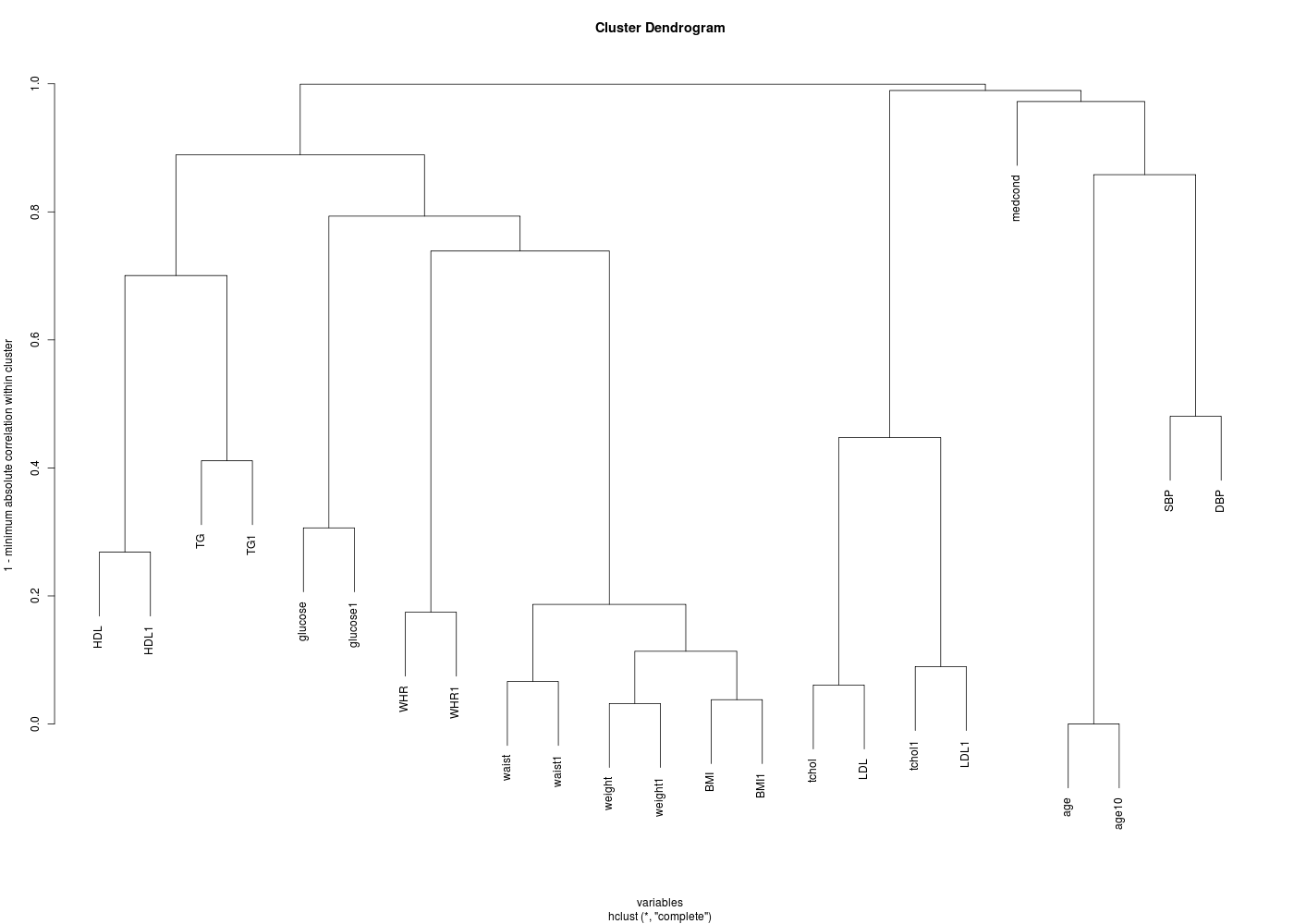
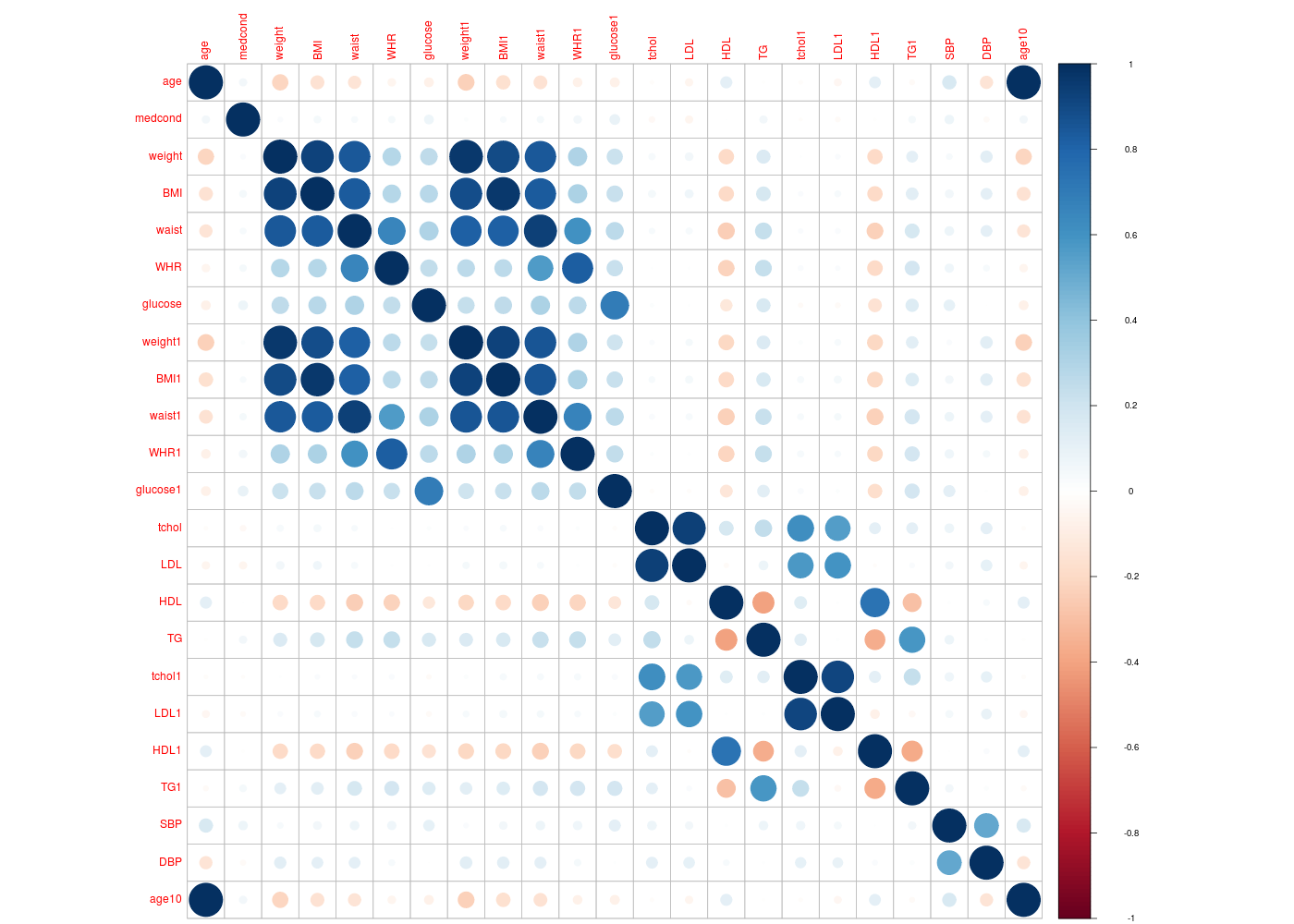
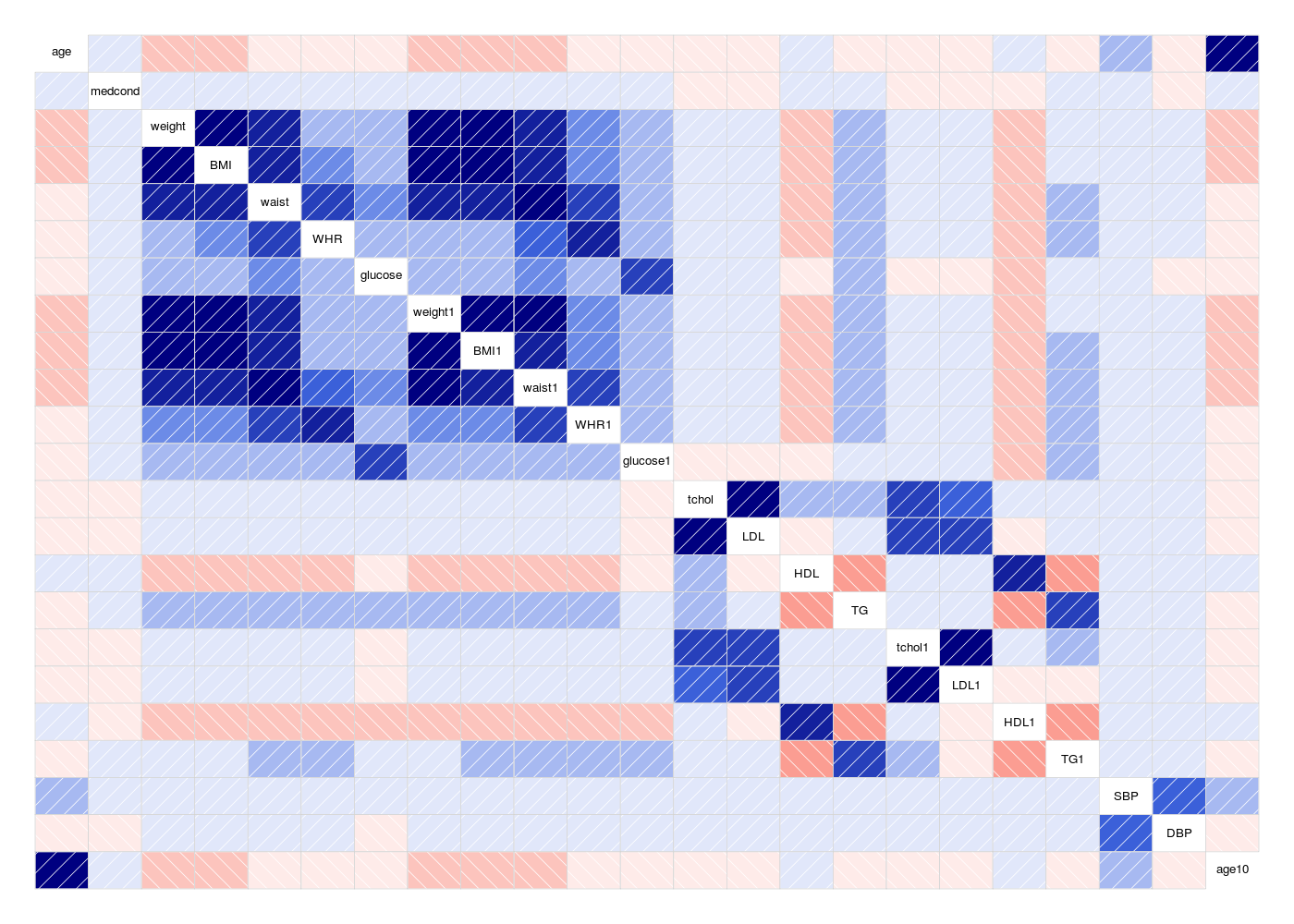
Application aux données segmentationOriginal du package AppliedPredictiveModeling
Hélas, là encore le fichier de données contient de nombreuses variables qualitatives. Pour traiter de corrélation, il faudrait commencer par faire le ménage pour ne garder que les quantitatives...
# chargement du package library(AppliedPredictiveModeling) ddata("AppliedPredictiveModeling") apm <- segmentationOriginal # beaucoup de variables au départ # dont de nombreuses sont qualitatives... cat(" il y a ",ncol(apm)," variables\n") lvnonql <- c() nbnonql <- 0 for (idv in (1:ncol(apm))) { cat("variable numéro ",sprintf("%3d",idv)," soit ",sprintf("%-35s",colnames(apm)[idv])," : ") if (is.factor(apm[,idv])) { cat(" qualitative") } else { nbnonql <- nbnonql + 1 cat(" sans doute non qualitative numéro ",sprintf("%3d",nbnonql)) lvnonql <- c(lvnonql,idv) } # fin si cat("\n") } # fin pour idv # ici, on peut sans doute calculer des corrélations... # vu qu'on dispose des données quantitatives seulement vqt <- apm[, lvnonql ]Jeux de données du package AppliedPredictiveModeling ==================================================== name class length nrow ncol name2 data_001 ChemicalManufacturingProcess data.frame 176 58 _______________ data_002 abalone ____________________ data.frame 4177 9 _______________ data_003 bio ________________________ data.frame 281 184 hepatic ________ data_004 cars2010 ___________________ data.frame 1107 14 FuelEconomy ____ data_005 cars2011 ___________________ data.frame 245 14 FuelEconomy ____ data_006 cars2012 ___________________ data.frame 95 14 FuelEconomy ____ data_007 chem _______________________ data.frame 281 192 hepatic ________ data_008 classes ____________________ factor ___ 208 twoClassData ___ data_009 concrete ___________________ data.frame 1030 9 _______________ data_010 diagnosis __________________ factor ___ 333 AlzheimerDisease data_011 fingerprints _______________ matrix ___ 165 1107 permeability ___ data_012 injury _____________________ factor ___ 281 hepatic ________ data_013 logisticCreditPredictions __ data.frame 200 4 _______________ data_014 mixtures ___________________ data.frame 1030 9 concrete _______ data_015 permeability _______________ matrix ___ 165 1 _______________ data_016 predictors _________________ data.frame 333 130 AlzheimerDisease data_017 predictors _________________ data.frame 208 2 twoClassData ___ data_018 schedulingData _____________ data.frame 4331 8 _______________ data_019 segmentationOriginal _______ data.frame 2019 119 _______________ data_020 solTestX ___________________ data.frame 316 228 solubility _____ data_021 solTestXtrans ______________ data.frame 316 228 solubility _____ data_022 solTestY ___________________ numeric __ 316 solubility _____ data_023 solTrainX __________________ data.frame 951 228 solubility _____ data_024 solTrainXtrans _____________ data.frame 951 228 solubility _____ data_025 solTrainY __________________ numeric __ 951 solubility _____ il y a 119 variables variable numéro 1 soit Cell : sans doute non qualitative numéro 1 variable numéro 2 soit Case : qualitative variable numéro 3 soit Class : qualitative variable numéro 4 soit AngleCh1 : sans doute non qualitative numéro 2 variable numéro 5 soit AngleStatusCh1 : sans doute non qualitative numéro 3 variable numéro 6 soit AreaCh1 : sans doute non qualitative numéro 4 variable numéro 7 soit AreaStatusCh1 : sans doute non qualitative numéro 5 variable numéro 8 soit AvgIntenCh1 : sans doute non qualitative numéro 6 variable numéro 9 soit AvgIntenCh2 : sans doute non qualitative numéro 7 variable numéro 10 soit AvgIntenCh3 : sans doute non qualitative numéro 8 variable numéro 11 soit AvgIntenCh4 : sans doute non qualitative numéro 9 variable numéro 12 soit AvgIntenStatusCh1 : sans doute non qualitative numéro 10 variable numéro 13 soit AvgIntenStatusCh2 : sans doute non qualitative numéro 11 variable numéro 14 soit AvgIntenStatusCh3 : sans doute non qualitative numéro 12 variable numéro 15 soit AvgIntenStatusCh4 : sans doute non qualitative numéro 13 variable numéro 16 soit ConvexHullAreaRatioCh1 : sans doute non qualitative numéro 14 variable numéro 17 soit ConvexHullAreaRatioStatusCh1 : sans doute non qualitative numéro 15 variable numéro 18 soit ConvexHullPerimRatioCh1 : sans doute non qualitative numéro 16 variable numéro 19 soit ConvexHullPerimRatioStatusCh1 : sans doute non qualitative numéro 17 variable numéro 20 soit DiffIntenDensityCh1 : sans doute non qualitative numéro 18 variable numéro 21 soit DiffIntenDensityCh3 : sans doute non qualitative numéro 19 variable numéro 22 soit DiffIntenDensityCh4 : sans doute non qualitative numéro 20 variable numéro 23 soit DiffIntenDensityStatusCh1 : sans doute non qualitative numéro 21 variable numéro 24 soit DiffIntenDensityStatusCh3 : sans doute non qualitative numéro 22 variable numéro 25 soit DiffIntenDensityStatusCh4 : sans doute non qualitative numéro 23 variable numéro 26 soit EntropyIntenCh1 : sans doute non qualitative numéro 24 variable numéro 27 soit EntropyIntenCh3 : sans doute non qualitative numéro 25 variable numéro 28 soit EntropyIntenCh4 : sans doute non qualitative numéro 26 variable numéro 29 soit EntropyIntenStatusCh1 : sans doute non qualitative numéro 27 variable numéro 30 soit EntropyIntenStatusCh3 : sans doute non qualitative numéro 28 variable numéro 31 soit EntropyIntenStatusCh4 : sans doute non qualitative numéro 29 variable numéro 32 soit EqCircDiamCh1 : sans doute non qualitative numéro 30 variable numéro 33 soit EqCircDiamStatusCh1 : sans doute non qualitative numéro 31 variable numéro 34 soit EqEllipseLWRCh1 : sans doute non qualitative numéro 32 variable numéro 35 soit EqEllipseLWRStatusCh1 : sans doute non qualitative numéro 33 variable numéro 36 soit EqEllipseOblateVolCh1 : sans doute non qualitative numéro 34 variable numéro 37 soit EqEllipseOblateVolStatusCh1 : sans doute non qualitative numéro 35 variable numéro 38 soit EqEllipseProlateVolCh1 : sans doute non qualitative numéro 36 variable numéro 39 soit EqEllipseProlateVolStatusCh1 : sans doute non qualitative numéro 37 variable numéro 40 soit EqSphereAreaCh1 : sans doute non qualitative numéro 38 variable numéro 41 soit EqSphereAreaStatusCh1 : sans doute non qualitative numéro 39 variable numéro 42 soit EqSphereVolCh1 : sans doute non qualitative numéro 40 variable numéro 43 soit EqSphereVolStatusCh1 : sans doute non qualitative numéro 41 variable numéro 44 soit FiberAlign2Ch3 : sans doute non qualitative numéro 42 variable numéro 45 soit FiberAlign2Ch4 : sans doute non qualitative numéro 43 variable numéro 46 soit FiberAlign2StatusCh3 : sans doute non qualitative numéro 44 variable numéro 47 soit FiberAlign2StatusCh4 : sans doute non qualitative numéro 45 variable numéro 48 soit FiberLengthCh1 : sans doute non qualitative numéro 46 variable numéro 49 soit FiberLengthStatusCh1 : sans doute non qualitative numéro 47 variable numéro 50 soit FiberWidthCh1 : sans doute non qualitative numéro 48 variable numéro 51 soit FiberWidthStatusCh1 : sans doute non qualitative numéro 49 variable numéro 52 soit IntenCoocASMCh3 : sans doute non qualitative numéro 50 variable numéro 53 soit IntenCoocASMCh4 : sans doute non qualitative numéro 51 variable numéro 54 soit IntenCoocASMStatusCh3 : sans doute non qualitative numéro 52 variable numéro 55 soit IntenCoocASMStatusCh4 : sans doute non qualitative numéro 53 variable numéro 56 soit IntenCoocContrastCh3 : sans doute non qualitative numéro 54 variable numéro 57 soit IntenCoocContrastCh4 : sans doute non qualitative numéro 55 variable numéro 58 soit IntenCoocContrastStatusCh3 : sans doute non qualitative numéro 56 variable numéro 59 soit IntenCoocContrastStatusCh4 : sans doute non qualitative numéro 57 variable numéro 60 soit IntenCoocEntropyCh3 : sans doute non qualitative numéro 58 variable numéro 61 soit IntenCoocEntropyCh4 : sans doute non qualitative numéro 59 variable numéro 62 soit IntenCoocEntropyStatusCh3 : sans doute non qualitative numéro 60 variable numéro 63 soit IntenCoocEntropyStatusCh4 : sans doute non qualitative numéro 61 variable numéro 64 soit IntenCoocMaxCh3 : sans doute non qualitative numéro 62 variable numéro 65 soit IntenCoocMaxCh4 : sans doute non qualitative numéro 63 variable numéro 66 soit IntenCoocMaxStatusCh3 : sans doute non qualitative numéro 64 variable numéro 67 soit IntenCoocMaxStatusCh4 : sans doute non qualitative numéro 65 variable numéro 68 soit KurtIntenCh1 : sans doute non qualitative numéro 66 variable numéro 69 soit KurtIntenCh3 : sans doute non qualitative numéro 67 variable numéro 70 soit KurtIntenCh4 : sans doute non qualitative numéro 68 variable numéro 71 soit KurtIntenStatusCh1 : sans doute non qualitative numéro 69 variable numéro 72 soit KurtIntenStatusCh3 : sans doute non qualitative numéro 70 variable numéro 73 soit KurtIntenStatusCh4 : sans doute non qualitative numéro 71 variable numéro 74 soit LengthCh1 : sans doute non qualitative numéro 72 variable numéro 75 soit LengthStatusCh1 : sans doute non qualitative numéro 73 variable numéro 76 soit MemberAvgAvgIntenStatusCh2 : sans doute non qualitative numéro 74 variable numéro 77 soit MemberAvgTotalIntenStatusCh2 : sans doute non qualitative numéro 75 variable numéro 78 soit NeighborAvgDistCh1 : sans doute non qualitative numéro 76 variable numéro 79 soit NeighborAvgDistStatusCh1 : sans doute non qualitative numéro 77 variable numéro 80 soit NeighborMinDistCh1 : sans doute non qualitative numéro 78 variable numéro 81 soit NeighborMinDistStatusCh1 : sans doute non qualitative numéro 79 variable numéro 82 soit NeighborVarDistCh1 : sans doute non qualitative numéro 80 variable numéro 83 soit NeighborVarDistStatusCh1 : sans doute non qualitative numéro 81 variable numéro 84 soit PerimCh1 : sans doute non qualitative numéro 82 variable numéro 85 soit PerimStatusCh1 : sans doute non qualitative numéro 83 variable numéro 86 soit ShapeBFRCh1 : sans doute non qualitative numéro 84 variable numéro 87 soit ShapeBFRStatusCh1 : sans doute non qualitative numéro 85 variable numéro 88 soit ShapeLWRCh1 : sans doute non qualitative numéro 86 variable numéro 89 soit ShapeLWRStatusCh1 : sans doute non qualitative numéro 87 variable numéro 90 soit ShapeP2ACh1 : sans doute non qualitative numéro 88 variable numéro 91 soit ShapeP2AStatusCh1 : sans doute non qualitative numéro 89 variable numéro 92 soit SkewIntenCh1 : sans doute non qualitative numéro 90 variable numéro 93 soit SkewIntenCh3 : sans doute non qualitative numéro 91 variable numéro 94 soit SkewIntenCh4 : sans doute non qualitative numéro 92 variable numéro 95 soit SkewIntenStatusCh1 : sans doute non qualitative numéro 93 variable numéro 96 soit SkewIntenStatusCh3 : sans doute non qualitative numéro 94 variable numéro 97 soit SkewIntenStatusCh4 : sans doute non qualitative numéro 95 variable numéro 98 soit SpotFiberCountCh3 : sans doute non qualitative numéro 96 variable numéro 99 soit SpotFiberCountCh4 : sans doute non qualitative numéro 97 variable numéro 100 soit SpotFiberCountStatusCh3 : sans doute non qualitative numéro 98 variable numéro 101 soit SpotFiberCountStatusCh4 : sans doute non qualitative numéro 99 variable numéro 102 soit TotalIntenCh1 : sans doute non qualitative numéro 100 variable numéro 103 soit TotalIntenCh2 : sans doute non qualitative numéro 101 variable numéro 104 soit TotalIntenCh3 : sans doute non qualitative numéro 102 variable numéro 105 soit TotalIntenCh4 : sans doute non qualitative numéro 103 variable numéro 106 soit TotalIntenStatusCh1 : sans doute non qualitative numéro 104 variable numéro 107 soit TotalIntenStatusCh2 : sans doute non qualitative numéro 105 variable numéro 108 soit TotalIntenStatusCh3 : sans doute non qualitative numéro 106 variable numéro 109 soit TotalIntenStatusCh4 : sans doute non qualitative numéro 107 variable numéro 110 soit VarIntenCh1 : sans doute non qualitative numéro 108 variable numéro 111 soit VarIntenCh3 : sans doute non qualitative numéro 109 variable numéro 112 soit VarIntenCh4 : sans doute non qualitative numéro 110 variable numéro 113 soit VarIntenStatusCh1 : sans doute non qualitative numéro 111 variable numéro 114 soit VarIntenStatusCh3 : sans doute non qualitative numéro 112 variable numéro 115 soit VarIntenStatusCh4 : sans doute non qualitative numéro 113 variable numéro 116 soit WidthCh1 : sans doute non qualitative numéro 114 variable numéro 117 soit WidthStatusCh1 : sans doute non qualitative numéro 115 variable numéro 118 soit XCentroid : sans doute non qualitative numéro 116 variable numéro 119 soit YCentroid : sans doute non qualitative numéro 117Ce n'est ni une question simple ni une question facile à résoudre.
Il est bien sûr possible passer en revue tous les couples de variables, et de supprimer X ou Y lorsque leur coefficient de corrélation est trop fort, mais d'une part cela ne résoud pas tous les problèmes, d'autre part le choix de X ou de Y à supprimer reste non résolu car ce n'est pas une question statistique.
Le packge caret fournit, avec la fonction findCorrelation() un moyen de choisir : on retire la variable la plus corrélée en moyenne aux autres variables. Nous avons, quant à nous, écrit deux fonctions, clusterCor() et clusterCorTrans() qui montrent comment créer des paquets de variables, soit toutes corrélées entre elles, soit corrélées transitivement, c'est-à-dire corrélées à au moins une des autres variables du paquet :
# recherche des variables à supprimer car trop corrélées # (on a exécuté sleep.r pour lire les données) # rappel de la matrice des corrélations mdc(sqt) # findCorrelation du package caret library(caret) findCorrelation(mcor,cutoff=0.8,verbose=TRUE) # nos algorithmes clusterCor et clusterCorTrans clusterCor(data=sqt,use="pairwise.complete.obs") clusterCorTrans(data=sqt,use="pairwise.complete.obs",detail=TRUE)Matrice des corrélations au sens de Pearson pour 62 lignes et 7 colonnes poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation poidsCorps 1.000 poidsCerveau 0.934 1.000 ondesLentes -0.376 -0.369 1.000 sommeilParadoxal -0.109 -0.105 0.514 1.000 sommeilTotal -0.307 -0.358 0.963 0.727 1.000 dureeVieMax 0.302 0.509 -0.384 -0.296 -0.410 1.000 dureeGestation 0.651 0.747 -0.595 -0.451 -0.631 0.615 1.000 Considering row 10 column 5 value 0.934 Flagging column 10 Considering row 5 column 9 value 0.813 Flagging column 5 Considering row 9 column 3 value 0.892 Flagging column 9 Considering row 3 column 4 value 0.921 Flagging column 3 Considering row 4 column 8 value 0.886 Flagging column 4 Considering row 8 column 11 value 0.306 Considering row 8 column 6 value 0.261 Considering row 8 column 19 value 0.208 Considering row 8 column 15 value 0.201 Considering row 8 column 16 value 0.154 Considering row 8 column 7 value 0.238 Considering row 8 column 12 value 0.207 Considering row 8 column 20 value 0.126 Considering row 8 column 13 value 0.021 Considering row 8 column 17 value 0.016 Considering row 8 column 1 value 0.231 Considering row 8 column 23 value 0.231 Considering row 8 column 14 value 0.041 Considering row 8 column 18 value 0.035 Considering row 8 column 22 value 0.128 Considering row 8 column 21 value 0.024 Considering row 8 column 2 value 0.013 Considering row 11 column 6 value 0.825 Flagging column 11 Considering row 6 column 19 value 0.2 Considering row 6 column 15 value 0.223 Considering row 6 column 16 value 0.231 Considering row 6 column 7 value 0.248 Considering row 6 column 12 value 0.221 Considering row 6 column 20 value 0.182 Considering row 6 column 13 value 0.005 Considering row 6 column 17 value 0.025 Considering row 6 column 1 value 0.055 Considering row 6 column 23 value 0.055 Considering row 6 column 14 value 0.006 Considering row 6 column 18 value 0.021 Considering row 6 column 22 value 0.035 Considering row 6 column 21 value 0.066 Considering row 6 column 2 value 0.042 Considering row 19 column 15 value 0.732 Considering row 19 column 16 value 0.364 Considering row 19 column 7 value 0.155 Considering row 19 column 12 value 0.173 Considering row 19 column 20 value 0.375 Considering row 19 column 13 value 0.112 Considering row 19 column 17 value 0.118 Considering row 19 column 1 value 0.113 Considering row 19 column 23 value 0.113 Considering row 19 column 14 value 0.011 Considering row 19 column 18 value 0.072 Considering row 19 column 22 value 0.027 Considering row 19 column 21 value 0.002 Considering row 19 column 2 value 0.008 Considering row 15 column 16 value 0.409 Considering row 15 column 7 value 0.123 Considering row 15 column 12 value 0.133 Considering row 15 column 20 value 0.299 Considering row 15 column 13 value 0.177 Considering row 15 column 17 value 0.133 Considering row 15 column 1 value 0.117 Considering row 15 column 23 value 0.117 Considering row 15 column 14 value 0.022 Considering row 15 column 18 value 0.007 Considering row 15 column 22 value 0.033 Considering row 15 column 21 value 0.01 Considering row 15 column 2 value 0.001 Considering row 16 column 7 value 0.161 Considering row 16 column 12 value 0.129 Considering row 16 column 20 value 0.589 Considering row 16 column 13 value 0.247 Considering row 16 column 17 value 0.125 Considering row 16 column 1 value 0.009 Considering row 16 column 23 value 0.009 Considering row 16 column 14 value 0.074 Considering row 16 column 18 value 0.009 Considering row 16 column 22 value 0.008 Considering row 16 column 21 value 0.071 Considering row 16 column 2 value 0.051 Considering row 7 column 12 value 0.694 Considering row 7 column 20 value 0.142 Considering row 7 column 13 value 0.014 Considering row 7 column 17 value 0.021 Considering row 7 column 1 value 0.074 Considering row 7 column 23 value 0.074 Considering row 7 column 14 value 0.006 Considering row 7 column 18 value 0.025 Considering row 7 column 22 value 0.001 Considering row 7 column 21 value 0.106 Considering row 7 column 2 value 0.074 Considering row 12 column 20 value 0.188 Considering row 12 column 13 value 0.017 Considering row 12 column 17 value 0.029 Considering row 12 column 1 value 0.076 Considering row 12 column 23 value 0.076 Considering row 12 column 14 value 0.016 Considering row 12 column 18 value 0.013 Considering row 12 column 22 value 0.007 Considering row 12 column 21 value 0.116 Considering row 12 column 2 value 0.091 Considering row 20 column 13 value 0.11 Considering row 20 column 17 value 0.235 Considering row 20 column 1 value 0.026 Considering row 20 column 23 value 0.026 Considering row 20 column 14 value 0.025 Considering row 20 column 18 value 0.036 Considering row 20 column 22 value 0.017 Considering row 20 column 21 value 0.054 Considering row 20 column 2 value 0.044 Considering row 13 column 17 value 0.611 Considering row 13 column 1 value 0.015 Considering row 13 column 23 value 0.015 Considering row 13 column 14 value 0.939 Flagging column 13 Considering row 17 column 1 value 0.016 Considering row 17 column 23 value 0.016 Considering row 17 column 14 value 0.572 Considering row 17 column 18 value 0.91 Flagging column 17 Considering row 1 column 23 value 1 Flagging column 1 Considering row 23 column 14 value 0.052 Considering row 23 column 18 value 0.048 Considering row 23 column 22 value 0.142 Considering row 23 column 21 value 0.165 Considering row 23 column 2 value 0.052 Considering row 14 column 18 value 0.592 Considering row 14 column 22 value 0.109 Considering row 14 column 21 value 0.052 Considering row 14 column 2 value 0.051 Considering row 18 column 22 value 0.091 Considering row 18 column 21 value 0.049 Considering row 18 column 2 value 0.024 Considering row 22 column 21 value 0.519 Considering row 22 column 2 value 0.028 Considering row 21 column 2 value 0.071 [1] 10 5 9 3 4 11 13 17 1 Groupes de variables fortement corrélées, seuil 0.8 pour la corrélation de pearson Group | Count | Highest r | Lowest r | Variables 1 | 2 | 0.963 | | sommeilTotal ondesLentes 2 | 2 | 0.934 | | poidsCerveau poidsCorps 3 | 2 | 0.615 | | dureeGestation dureeVieMax 4 | 1 | 0.000 | | sommeilParadoxal Regroupement transitif de variables fortement corrélées au seuil rho= 0.8 pour la corrélation de pearson Groupe 1 : poidsCorps * poidsCerveau Groupe 2 : ondesLentes * sommeilTotal Groupe 3 : sommeilParadoxal Groupe 4 : dureeVieMax Groupe 5 : dureeGestation Numéros de groupe de corrélation et variable retenue : Groupe Variable retenue poidsCorps 1 1 poidsCerveau 1 0 ondesLentes 2 2 sommeilParadoxal 3 3 sommeilTotal 2 0 dureeVieMax 4 4 dureeGestation 5 5 On retient 5 variables : Résumé des dimensions données initiales : 62 7 données finales : 62 5Le risque, avec une procédure automatique, est de supprimer une variable "intéressante". Dans le cas d'une modélisation linéaire ou logistique, le critère de choix pour conserver une variable ou une autre peut être sa qualité de prédicteur, détectée par exemple en univarié par un critère d'inertie (AIC, BIC...) ou de performance (AUROC, R²...).
Ainsi la procédure findCorrelation() a indiqué qu'il fallait retirer les variables 5 et 2, soit respectivement sommeilTotal et poidsCerveau.
Application 1, données LEA
# lecture des données lea <- lit.dar("http://www.info.univ-angers.fr/~gh/Datasets/lea.dar") # on supprime les qualitatives lea <- lea[, c(1,5:8)] mcor <- cor(lea) # réduction automatique des données cats("élimination des données trop corrélées, données LEA, seuil 0.8") cat("taille avant : ",sprintf("%2d",ncol(lea))," colonnes\n") print(cbind(names(lea))) cat("\n") library(caret) caot <- findCorrelation(mcor,cutoff=0.8,verbose=FALSE) lea2 <- lea[, -caot ] cat("taille après : ",sprintf("%2d",ncol(lea2))," colonnes\n") print(cbind(names(lea2)))élimination des données trop corrélées, données LEA, seuil 0.8 ============================================================== taille avant : 5 colonnes [,1] [1,] "length" [2,] "foldindex" [3,] "pi" [4,] "mw" [5,] "gravy" taille après : 4 colonnes [,1] [1,] "length" [2,] "foldindex" [3,] "pi" [4,] "gravy"Application 2, données HERS
# lecture des données library(gdata) hers <- read.xls("hersdata.xls") # il y a beaucoup de variables # dont de nombreuses sont qualitatives... cats("élimination des données trop corrélées, données HERS, seuil 0.8") cat("taille initiale : ",sprintf("%2d",ncol(hers))," colonnes\n") lvnonql <- c() nbnonql <- 0 for (idv in (1:ncol(hers))) { if (is.factor(hers[,idv])) { # cat(" qualitative") } else { nbnonql <- nbnonql + 1 # cat(" sans doute non qualitative numéro ",sprintf("%02d",nbnonql)) lvnonql <- c(lvnonql,idv) } # fin si } # fin pour idv # ici, on peut sans doute calculer des corrélations vqt <- hers[, lvnonql ] mcor <- cor(vqt,use="pairwise.complete.obs") cat("taille QT avant : ",sprintf("%2d",ncol(vqt))," colonnes\n") print(cbind(names(vqt))) cat("\n") library(caret) caot <- findCorrelation(mcor,cutoff=0.8,verbose=FALSE) vqt2 <- vqt[, -caot ] cat("taille après : ",sprintf("%2d",ncol(vqt2))," colonnes\n") print(cbind(names(vqt2)))élimination des données trop corrélées, données HERS, seuil 0.8 =============================================================== taille initiale : 37 colonnes taille QT avant : 23 colonnes [,1] [1,] "age" [2,] "medcond" [3,] "weight" [4,] "BMI" [5,] "waist" [6,] "WHR" [7,] "glucose" [8,] "weight1" [9,] "BMI1" [10,] "waist1" [11,] "WHR1" [12,] "glucose1" [13,] "tchol" [14,] "LDL" [15,] "HDL" [16,] "TG" [17,] "tchol1" [18,] "LDL1" [19,] "HDL1" [20,] "TG1" [21,] "SBP" [22,] "DBP" [23,] "age10" taille après : 14 colonnes [,1] [1,] "medcond" [2,] "WHR" [3,] "glucose" [4,] "weight1" [5,] "glucose1" [6,] "LDL" [7,] "HDL" [8,] "TG" [9,] "LDL1" [10,] "HDL1" [11,] "TG1" [12,] "SBP" [13,] "DBP" [14,] "age10"Application 3, données segmentationOriginal du package AppliedPredictiveModeling
# chargement du package library(AppliedPredictiveModeling) apm <- segmentationOriginal # beaucoup de variables au départ # dont de nombreuses sont qualitatives... cats("élimination des données trop corrélées, données segmentationOriginal, seuil 0.8") cat("taille initiale : ",sprintf("%2d",ncol(apm))," colonnes\n") lvnonql <- c() nbnonql <- 0 for (idv in (1:ncol(apm))) { if (is.factor(apm[,idv])) { #cat(" qualitative") } else { nbnonql <- nbnonql + 1 # cat(" sans doute non qualitative numéro ",sprintf("%3d",nbnonql)) lvnonql <- c(lvnonql,idv) } # fin si } # fin pour idv # ici, on peut sans doute calculer des corrélations... # vu qu'on dispose des données quantitatives seulement apm2 <- apm[, lvnonql ] # malheureusement, certaines variables sont "presque constantes", # ce qui empeche le calcul des corrélations caot <- nearZeroVar(apm2) cat(" on retire ",length(caot)," variables de variance presque nulle\n") apm3 <- apm2[, -caot ] mcor <- cor(apm3,use="pairwise.complete.obs") cat("taille QT avant : ",sprintf("%2d",ncol(apm3))," colonnes\n") print(cbind(names(apm3))) cat("\n") library(caret) caot <- findCorrelation(mcor,cutoff=0.8,verbose=FALSE) apm4 <- apm3[, -caot ] cat("taille après : ",sprintf("%2d",ncol(apm4))," colonnes\n") print(cbind(names(apm4)))élimination des données trop corrélées, données segmentationOriginal, seuil 0.8 =============================================================================== taille initiale : 119 colonnes on retire 3 variables de variance presque nulle taille QT avant : 114 colonnes [,1] [1,] "Cell" [2,] "AngleCh1" [3,] "AngleStatusCh1" [4,] "AreaCh1" [5,] "AreaStatusCh1" [6,] "AvgIntenCh1" [7,] "AvgIntenCh2" [8,] "AvgIntenCh3" [9,] "AvgIntenCh4" [10,] "AvgIntenStatusCh1" [11,] "AvgIntenStatusCh2" [12,] "AvgIntenStatusCh3" [13,] "AvgIntenStatusCh4" [14,] "ConvexHullAreaRatioCh1" [15,] "ConvexHullAreaRatioStatusCh1" [16,] "ConvexHullPerimRatioCh1" [17,] "ConvexHullPerimRatioStatusCh1" [18,] "DiffIntenDensityCh1" [19,] "DiffIntenDensityCh3" [20,] "DiffIntenDensityCh4" [21,] "DiffIntenDensityStatusCh1" [22,] "DiffIntenDensityStatusCh3" [23,] "DiffIntenDensityStatusCh4" [24,] "EntropyIntenCh1" [25,] "EntropyIntenCh3" [26,] "EntropyIntenCh4" [27,] "EntropyIntenStatusCh1" [28,] "EntropyIntenStatusCh3" [29,] "EntropyIntenStatusCh4" [30,] "EqCircDiamCh1" [31,] "EqCircDiamStatusCh1" [32,] "EqEllipseLWRCh1" [33,] "EqEllipseLWRStatusCh1" [34,] "EqEllipseOblateVolCh1" [35,] "EqEllipseOblateVolStatusCh1" [36,] "EqEllipseProlateVolCh1" [37,] "EqEllipseProlateVolStatusCh1" [38,] "EqSphereAreaCh1" [39,] "EqSphereAreaStatusCh1" [40,] "EqSphereVolCh1" [41,] "EqSphereVolStatusCh1" [42,] "FiberAlign2Ch3" [43,] "FiberAlign2Ch4" [44,] "FiberAlign2StatusCh3" [45,] "FiberAlign2StatusCh4" [46,] "FiberLengthCh1" [47,] "FiberLengthStatusCh1" [48,] "FiberWidthCh1" [49,] "FiberWidthStatusCh1" [50,] "IntenCoocASMCh3" [51,] "IntenCoocASMCh4" [52,] "IntenCoocASMStatusCh3" [53,] "IntenCoocASMStatusCh4" [54,] "IntenCoocContrastCh3" [55,] "IntenCoocContrastCh4" [56,] "IntenCoocContrastStatusCh3" [57,] "IntenCoocContrastStatusCh4" [58,] "IntenCoocEntropyCh3" [59,] "IntenCoocEntropyCh4" [60,] "IntenCoocEntropyStatusCh3" [61,] "IntenCoocEntropyStatusCh4" [62,] "IntenCoocMaxCh3" [63,] "IntenCoocMaxCh4" [64,] "IntenCoocMaxStatusCh3" [65,] "IntenCoocMaxStatusCh4" [66,] "KurtIntenCh1" [67,] "KurtIntenCh3" [68,] "KurtIntenCh4" [69,] "KurtIntenStatusCh3" [70,] "KurtIntenStatusCh4" [71,] "LengthCh1" [72,] "LengthStatusCh1" [73,] "NeighborAvgDistCh1" [74,] "NeighborAvgDistStatusCh1" [75,] "NeighborMinDistCh1" [76,] "NeighborMinDistStatusCh1" [77,] "NeighborVarDistCh1" [78,] "NeighborVarDistStatusCh1" [79,] "PerimCh1" [80,] "PerimStatusCh1" [81,] "ShapeBFRCh1" [82,] "ShapeBFRStatusCh1" [83,] "ShapeLWRCh1" [84,] "ShapeLWRStatusCh1" [85,] "ShapeP2ACh1" [86,] "ShapeP2AStatusCh1" [87,] "SkewIntenCh1" [88,] "SkewIntenCh3" [89,] "SkewIntenCh4" [90,] "SkewIntenStatusCh1" [91,] "SkewIntenStatusCh3" [92,] "SkewIntenStatusCh4" [93,] "SpotFiberCountCh3" [94,] "SpotFiberCountCh4" [95,] "SpotFiberCountStatusCh3" [96,] "SpotFiberCountStatusCh4" [97,] "TotalIntenCh1" [98,] "TotalIntenCh2" [99,] "TotalIntenCh3" [100,] "TotalIntenCh4" [101,] "TotalIntenStatusCh1" [102,] "TotalIntenStatusCh2" [103,] "TotalIntenStatusCh3" [104,] "TotalIntenStatusCh4" [105,] "VarIntenCh1" [106,] "VarIntenCh3" [107,] "VarIntenCh4" [108,] "VarIntenStatusCh1" [109,] "VarIntenStatusCh3" [110,] "VarIntenStatusCh4" [111,] "WidthCh1" [112,] "WidthStatusCh1" [113,] "XCentroid" [114,] "YCentroid" taille après : 77 colonnes [,1] [1,] "Cell" [2,] "AngleCh1" [3,] "AngleStatusCh1" [4,] "AvgIntenCh2" [5,] "AvgIntenStatusCh2" [6,] "AvgIntenStatusCh3" [7,] "AvgIntenStatusCh4" [8,] "ConvexHullAreaRatioStatusCh1" [9,] "ConvexHullPerimRatioCh1" [10,] "ConvexHullPerimRatioStatusCh1" [11,] "DiffIntenDensityStatusCh1" [12,] "DiffIntenDensityStatusCh3" [13,] "DiffIntenDensityStatusCh4" [14,] "EntropyIntenCh1" [15,] "EntropyIntenStatusCh1" [16,] "EntropyIntenStatusCh3" [17,] "EntropyIntenStatusCh4" [18,] "EqCircDiamStatusCh1" [19,] "EqEllipseLWRStatusCh1" [20,] "EqEllipseProlateVolCh1" [21,] "EqEllipseProlateVolStatusCh1" [22,] "FiberAlign2Ch3" [23,] "FiberAlign2Ch4" [24,] "FiberAlign2StatusCh3" [25,] "FiberAlign2StatusCh4" [26,] "FiberLengthStatusCh1" [27,] "FiberWidthCh1" [28,] "FiberWidthStatusCh1" [29,] "IntenCoocASMStatusCh3" [30,] "IntenCoocASMStatusCh4" [31,] "IntenCoocContrastCh3" [32,] "IntenCoocContrastCh4" [33,] "IntenCoocContrastStatusCh3" [34,] "IntenCoocContrastStatusCh4" [35,] "IntenCoocEntropyStatusCh3" [36,] "IntenCoocEntropyStatusCh4" [37,] "IntenCoocMaxStatusCh3" [38,] "IntenCoocMaxStatusCh4" [39,] "KurtIntenCh1" [40,] "KurtIntenCh3" [41,] "KurtIntenCh4" [42,] "KurtIntenStatusCh3" [43,] "KurtIntenStatusCh4" [44,] "LengthStatusCh1" [45,] "NeighborAvgDistCh1" [46,] "NeighborAvgDistStatusCh1" [47,] "NeighborMinDistCh1" [48,] "NeighborMinDistStatusCh1" [49,] "NeighborVarDistStatusCh1" [50,] "PerimStatusCh1" [51,] "ShapeBFRCh1" [52,] "ShapeBFRStatusCh1" [53,] "ShapeLWRCh1" [54,] "ShapeLWRStatusCh1" [55,] "ShapeP2AStatusCh1" [56,] "SkewIntenCh1" [57,] "SkewIntenStatusCh1" [58,] "SkewIntenStatusCh3" [59,] "SkewIntenStatusCh4" [60,] "SpotFiberCountCh3" [61,] "SpotFiberCountCh4" [62,] "SpotFiberCountStatusCh3" [63,] "SpotFiberCountStatusCh4" [64,] "TotalIntenCh2" [65,] "TotalIntenCh3" [66,] "TotalIntenStatusCh1" [67,] "TotalIntenStatusCh2" [68,] "TotalIntenStatusCh3" [69,] "TotalIntenStatusCh4" [70,] "VarIntenCh3" [71,] "VarIntenCh4" [72,] "VarIntenStatusCh1" [73,] "VarIntenStatusCh3" [74,] "VarIntenStatusCh4" [75,] "WidthStatusCh1" [76,] "XCentroid" [77,] "YCentroid"La corrélation linéaire peut sembler un bon choix, car le modèle est Y=1.0*X+0. Toutefois, la corrélation de concordance de Lin est prévue pour cela.
Vu qu'il y a environ 3000 lignes de données, il faut être très prudent. Par exemple la matrice de corrélation et le diagramme en paires donne l'illusion d'une bonne reproductibilité :
# lecture des données asats <- lit.dar("reproduct.data") print(head(asats)) # matrice de corrélations mdc(asats) # diagramme par paires gr("asats.png") pairsi(asats) dev.off()X Y1 Y2 Y3 640001 19 19.4801 20.80668 20.80668 640002 44 45.1776 47.93486 47.93486 640003 37 37.9823 43.70627 43.70627 640005 36 36.9544 40.16611 40.16611 640006 99 101.7121 102.05512 102.05512 640007 20 20.5080 22.67599 22.67599 Matrice des corrélations au sens de Pearson pour 3077 lignes et 4 colonnes X Y1 Y2 Y3 X 1.000 Y1 1.000 1.000 Y2 0.999 0.999 1.000 Y3 0.993 0.993 0.994 1.000
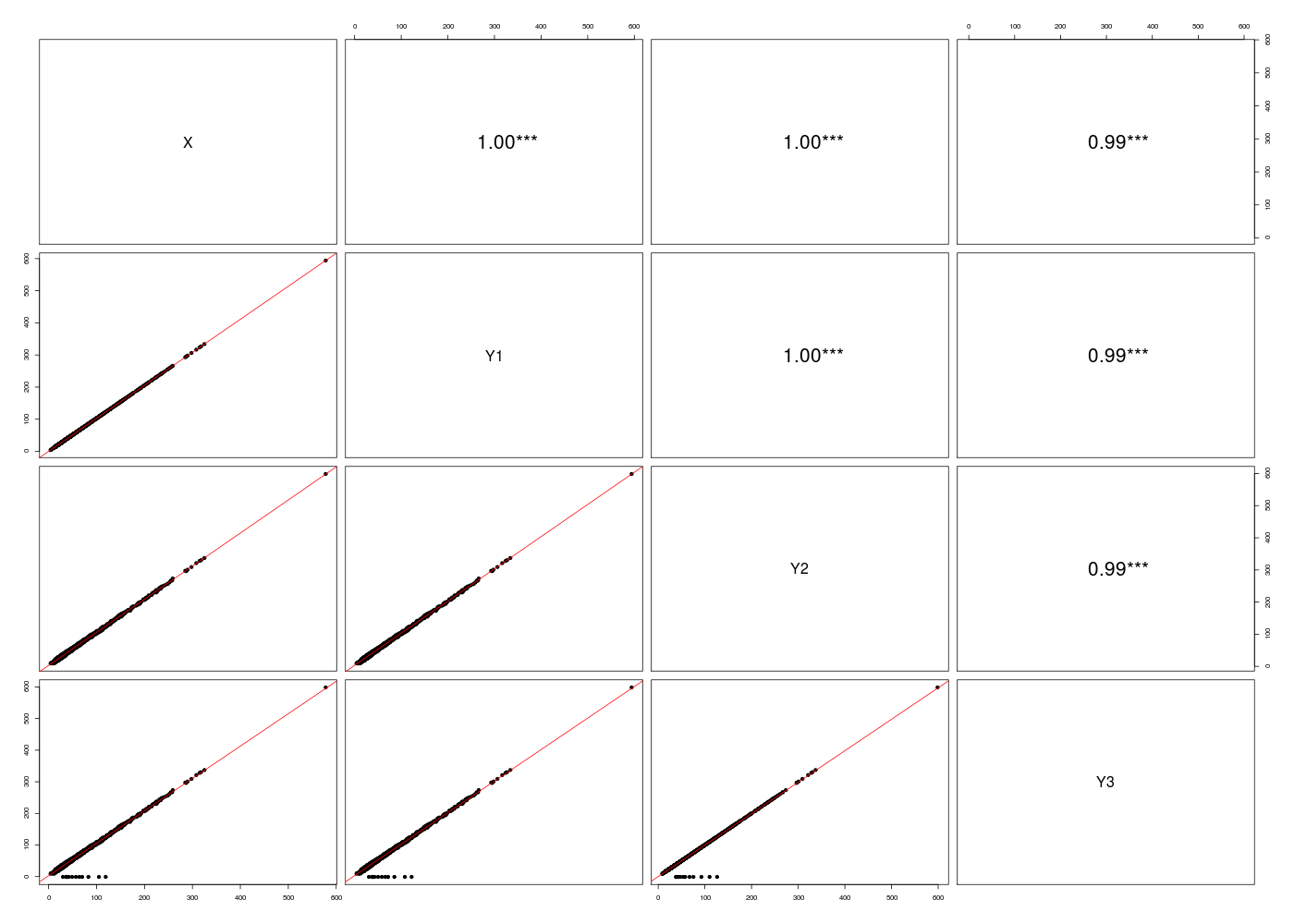
La lecture des coefficients de corrélations, le calcul de la corrélation de Lin et la description des variables montrent des différences entre les séries, non visibles à la seule lecture des coefficients de corrélation linéaire :
# chargement de la librairie epiR (pour la fonction epi.ccc) library(epiR) # lecture des données asats <- lit.dar("reproduct.data") print(head(asats)) # régression linéaire : r, a et b mdr <- matrix(nrow=3,ncol=4) colnames(mdr) <- c("lin","r","a","b") row.names(mdr) <- paste(" X vs Y",1:3,sep="") x <- asats[,"X"] for (idv in (1:3)) { jdv <- idv + 1 y <- asats[,jdv] mdr[idv,1] <- epi.ccc(x,y)$rho.c$est mdr[idv,2] <- cor(x,y) co <- coef(lm(y~x)) mdr[idv,3] <- co[2] mdr[idv,4] <- co[1] } # fin pour idv print(round(mdr,4)) for (idv in (1:4)) { decritQT( colnames(asats)[idv], asats[,idv],"UI/l") } # fin pour idvX Y1 Y2 Y3 640001 19 19.4801 20.80668 20.80668 640002 44 45.1776 47.93486 47.93486 640003 37 37.9823 43.70627 43.70627 640005 36 36.9544 40.16611 40.16611 640006 99 101.7121 102.05512 102.05512 640007 20 20.5080 22.67599 22.67599 lin r a b X vs Y1 0.9992 1.0000 1.0279 -0.0500 X vs Y2 0.9928 0.9988 1.0296 2.9026 X vs Y3 0.9873 0.9927 1.0251 2.8476 DESCRIPTION STATISTIQUE DE LA VARIABLE X Taille 3077 individus Moyenne 45.4351 UI/l Ecart-type 39.5323 UI/l Coef. de variation 87 % 1er Quartile 23.0000 UI/l Mediane 33.0000 UI/l 3eme Quartile 51.0000 UI/l iqr absolu 28.0000 UI/l iqr relatif 85.0000 % Minimum 4 UI/l Maximum 578 UI/l DESCRIPTION STATISTIQUE DE LA VARIABLE Y1 Taille 3077 individus Moyenne 46.6528 UI/l Ecart-type 40.6352 UI/l Coef. de variation 87 % 1er Quartile 23.5917 UI/l Mediane 33.8707 UI/l 3eme Quartile 52.3729 UI/l iqr absolu 28.7812 UI/l iqr relatif 85.0000 % Minimum 4 UI/l Maximum 594 UI/l DESCRIPTION STATISTIQUE DE LA VARIABLE Y2 Taille 3077 individus Moyenne 49.6823 UI/l Ecart-type 40.7495 UI/l Coef. de variation 82 % 1er Quartile 27.0430 UI/l Mediane 36.8636 UI/l 3eme Quartile 54.9723 UI/l iqr absolu 27.9293 UI/l iqr relatif 76.0000 % Minimum 9 UI/l Maximum 599 UI/l DESCRIPTION STATISTIQUE DE LA VARIABLE Y3 Taille 3077 individus Moyenne 49.4217 UI/l Ecart-type 40.8206 UI/l Coef. de variation 83 % 1er Quartile 26.9304 UI/l Mediane 36.6339 UI/l 3eme Quartile 54.6666 UI/l iqr absolu 27.7362 UI/l iqr relatif 76.0000 % Minimum -1 UI/l Maximum 599 UI/lMême si Y1 est en corrélation parfaite avec X, elle a un biais systématique. La série Y2 a une valeur de b très importante, comme Y3. Enfin, la série Y3 a des valeurs -1, ce qui indique sans doute un problème de mesure (ou d'automate).
En conclusion, aucun laboratoire ne permet de reproduire la mesure d'ASAT fournie en X de façon satisfaisante pour une routine médicale commercialisée.
Tout ce qu'il faut pour bien réviser ce module. Et en plus, il y a un site compagnon à l'ouvrage et les exemples numériques sont fournis avec le code R qui les a produits. Que demander de plus ?