![]()
![]()
Tuteur AJAX / AJAX Tutorialgilles.hunault@univ-angers.fr Table des matières1. Qu'est-ce qu'AJAX ?AJAX est un ensemble de technologies dont le but est de fournir une plus grande réactivité au niveau des pages Web. Consultez par exemple les deux formulaires démo 1 et démo 2. Le formulaire 1 utilise deux pages distinctes : une pour la question et une pour la réponse. Le formulaire 2 utilise une seule page, la même qui sert à la fois pour la question et pour la réponse. Ce deuxième formulaire passe par Javascript et CSS pour afficher la réponse. N'hésitez pas à consulter le
Le mot AJAX correspond à la technique utilisée pour le formulaire 2 : pas de rechargement de la page et un traitement des éléments de la page en Javascript, d'où les deux lettres JA. Le A en début signifie Asynchrone (ce qui sera expliqué dans la section 5) et le X en fin est mis soit pour XML car au niveau le plus technique, les éléments traités viennent soit d'un document XML général soit d'un document HTML suffisamment bien formé, c'est-à-dire d'un document XHTML qui est un document XML particulier, soit pour XMLHttpRequest car c'est l'objet Javascript utilisé. Voici deux autres démonstrations d'AJAX (n'hésitez pas à consulter le code-source des pages) :
Le site (en français et qu'on peut télécharger officiellement et gratuitement) SELFHTML nous semble être une bonne référence pour réviser tous les domaines traités dans cette page (XHTML, DOM, Javascript, Xml...) avant d'aborder AJAX. 2. Visions et Révisions : XMLXML n'est pas strictement obligatoire mais lorsqu'on doit gérer un volume important d'informations structurées, ce format s'impose : d'une part la structure en arbre permet d'accéder rapidement et facilement aux informations ; d'autre part, XML est un méta-langage en format texte, ce qui se prête bien à une transmission sur le Web. A défaut de lire notre tuteur XML nous fournissons ici un bref rappel des propriétés de XML. XML n'est pas un langage mais un méta-langage, qui permet de codifier toute information structurée en un fichier texte facilement lisible sans support extérieur, contrairement aux formats propriétaires. Sa structuration hiérarchique en arbre lui permet d'inclure des contenus homogènes et hétérogènes, d'intégrer les bases de données aussi bien relationnelles que hiérarchiques... Par exemple :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<base_de_données>
<table_de_données nom="clients">
<ligne num="1">
<colonne num="1">
<id>0217</id>
<nom>DURAND</nom>
...
</colonne>
<colonne num="2">
<id>0589</id>
<nom>ZANOU</nom>
...
</colonne>
</ligne>
</table_de_données>
<table_de_données nom="fournisseurs">
...
</table_de_données>
</base_de_données>
Un fichier XML est un arbre enraciné au sens informatique du terme : il contient un élément racine qui contient d'autres éléments pouvant à leur tour contenir d'autres éléments qui eux-mêmes.... Ces éléments sont repérés par des balises ouvrantes et fermantes (mais on peut aussi utiliser des éléments auto-fermants). A chaque élément on peut, si besoin est, associer un ou plusieurs attributs selon le modèle variable=valeur. Le nom des éléments et le choix de leurs attributs est libre et chacun peut inventer sa propre grammaire pour en définir :
Les règles de construction d'un fichier XML "bien formé" sont simples et peu nombreuses car il n'y a que des éléments et des attributs :
A cette simplicité d'écriture, il faut ajouter la possibilité de vérifier la structure (on dit que le fichier est valide s'il est conforme à sa grammaire), de l'analyser, le parcourir et de transformer tout élément, tout attribut, tout sous-arbre via des actions écrites en XSL. De plus, ces actions XSL (qui s'écrivent d'ailleurs en XML), disposent de toute la richesse des "fonctions informatiques modernes" : itérateurs de structure, expressions régulières, parcours d'arbres paramétrés... qui s'appliquent sur des axes et des ensembles de noeuds de l'arbre. Enfin, pour terminer, il faut signaler que tout navigateur sait ouvrir un fichier XML comme bd.xml et que chaque langage de programmation dispose de fonctions, bibliothèques et sous-programmes pour gérer toutes ces fonctionnnalités de XML. 3. Visions et Révisions côté client : JavascriptPour utiliser AJAX, il faut bien connaitre Javascript car c'est via ce langage qu'on gère les informations et les éléments de la page, ce qui nécessite de savoir manipuler DOM et de bien connaitre CSS. On pourra relire au passage la section 6 de notre tuteur Javascript pour réviser l'accès aux noeuds et à la gestion dynamique d'un document. Pour profiter pleinement d'AJAX, il faut donc savoir récupèrer l'information à distance sur les serveurs, la parcourir, l'analyser, la restructurer et l'insérer dynamiquement. Il convient donc de maitriser les chaines de caractères et les fonctions associées ainsi que les tableaux et les expressions régulières. En particulier, il est bon se savoir appeler correctement les fonctions suivantes et de connaitre les propriétés listées :
string.charAt(nb)
string.charCodeAt(nb) document.getElementById(id)
string.concat(str1,str2) document.getElementsByTagName(eltname)
string.fromCharCode(ustr1,ustr2...) node.getAttribute(attr)
string.indexOf(str,nb) node.setAttribute(attr,attrval)
string.lastIndexOf(str,nb) node.appendChild(node)
string.length node.insertBefore(node,node)
string.match(regexp) node.removeChild(node)
string.replace(regexp,text) node.replaceChild(node,node)
string.search(regexp)
string.slice(nb1,nb2) node.childNodes
string.split(regexp) node.attributes
string.substr(nb1,nb2) node.data
string.substring(nb1,nb2) node.firstChild
string.toLowerCase() node.lastChild
string.toString() node.nextSibling
string.toUpperCase() node.nodeName
string.valeOf() node.nodeType
RegExp node.nodeValue
node.parentNode
escape(str) node.previousSibling
unescape(str)
array.concat(arr) document.createElement(eltname)
array.length() document.createAttribute(attr)
array.reverse() document.createTextNode(txt)
array.slice(nb1,nb2)
array.sort()
array.join()
array.pop()
array.push(item)
array.splice(nb1,nb2) try
array.shift() catch
array.unshift(item) eval
On pourra également profiter de la page réintroduction pour découvrir des aspects cachés de Javascript. 4. Visions et Révisions côté serveur : fichiers et PhpAvec AJAX, on traite tout ce qu'un serveur peut envoyer, soit directement, comme du texte "brut", un fichier HTML ou un fichier XML, un fichier contenant du code JSON, soit transmis par PHP, Ruby ou tout autre script CGI ou application serveur. Voici quelques exemples de liens pouvant être appelés en AJAX :
La section suivante montre comment traiter tous ces exemples. 5. Mise en oeuvre et exemples "à la main"Le principe d'AJAX est simple : on vient charger les contenus externes dont on a besoin au fur et à mesure. Contrairement à un chargement synchrone de la page où toute la page est chargée dès le départ, on charge à la demande (en mode asynchrone d'où le premier A de AJAX) le contenu. Le terme asynchrone est sans doute mal choisi car le chargement est en fait à la fois asynchrone avec le chargement de la page et synchrone avec les évènements-utilisateurs. Dire "à la volée" ou "à la demande" serait donc sans doute plus exact. Comme les différentes versions de Javascript des divers navigateurs (IE, FF...) n'implèmentent les mêmes fonctions associées, il faut recourir à une technique d'interception des "exceptions" avec try/catch avant d'accèder aux informations que l'on récupère via des propriétés responseText, responseXML d'un flux correctement attendu, ouvert et envoyé (fonctions open, send, onreadystatechange... propriétés readyState, status...). Une fois l'information récupérée, il faut l'insérer, la substituer, l'afficher... à l'aide des fonctions DOM qui permettent de manipuler le document. On se méfiera du traitement des noeuds (éléments) d'un document XML qui est différent d'un navigateur à l'autre. La démonstration est ici. On lira avec attention le fichier tutajax.js qui contient l'ensemble des fonctions utilisées pour les exemples qui suivent et qui détaillent cette technique. Pour ceux et celles qui préfèrent un exposé plus "linéaire", on pourra consulter les liens suivants :
Commençons par insérer du texte brut. Choisissez le personnage dans la liste suivante et regardez le texte qui apparait dans le cadre grisé :
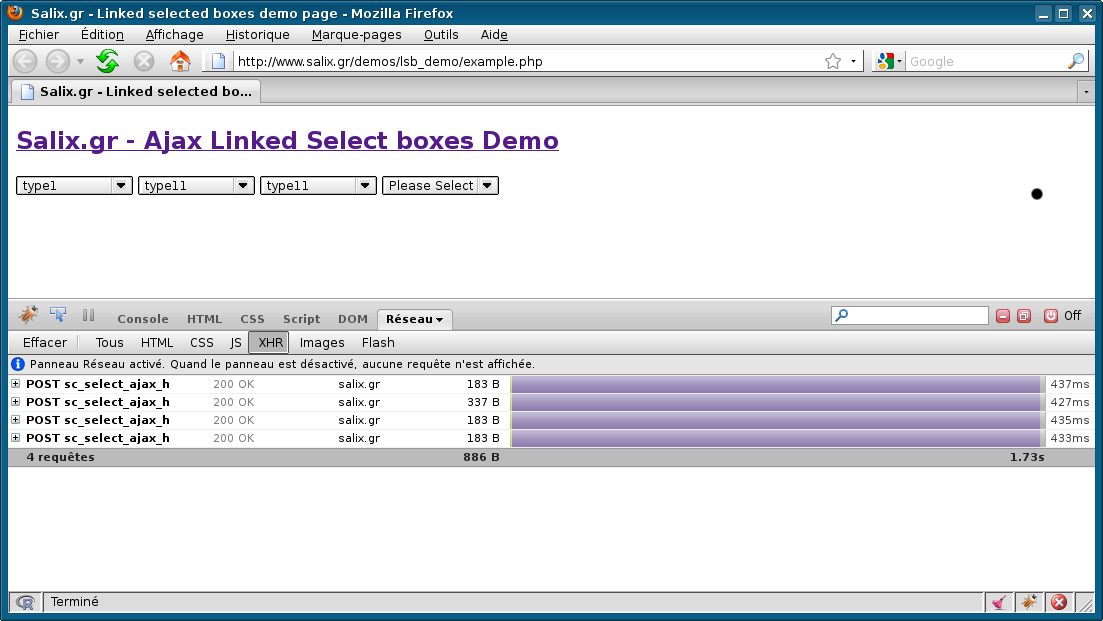
(au départ, ce cadre ne contient rien...) Passons maintenant à la gestion d'une liste de sélection. Choisissez la date dans la liste suivante et regardez le texte associé : L'exemple suivant vient remplir le paragraphe suivant dans le document : Ceci est le paragraphe original. Nous allons maintenant lire le fichier XML "tout élément " nommé tutajax_send4a.xml pour trouver le prix de l'article choisi : La version éléments/attributs de la lecture du fichier XML tutajax_send4b.xml n'est pas plus difficile : Le texte JSON s'exécute directement (ou plutôt il est facilement évalué) : (date non choisie) Lorsqu'on essaie de débugger du javascript et de l'AJAX, à part la technique d'une zone d'informations via un élément <pre> (comme dans la page tutajaxml.php dont le code-source php est ici avec son code javascript et dont le code xhtml généré est là) on peut se servir, sous Firefox, de la "Console d'erreurs" via le menu "Outils", ou utiliser Firebug. Signalons au passage qu'une fois activé, Firebug, dans son panneau "Réseau", montre les appels comme on peut le voir sur l'image ci-dessous :
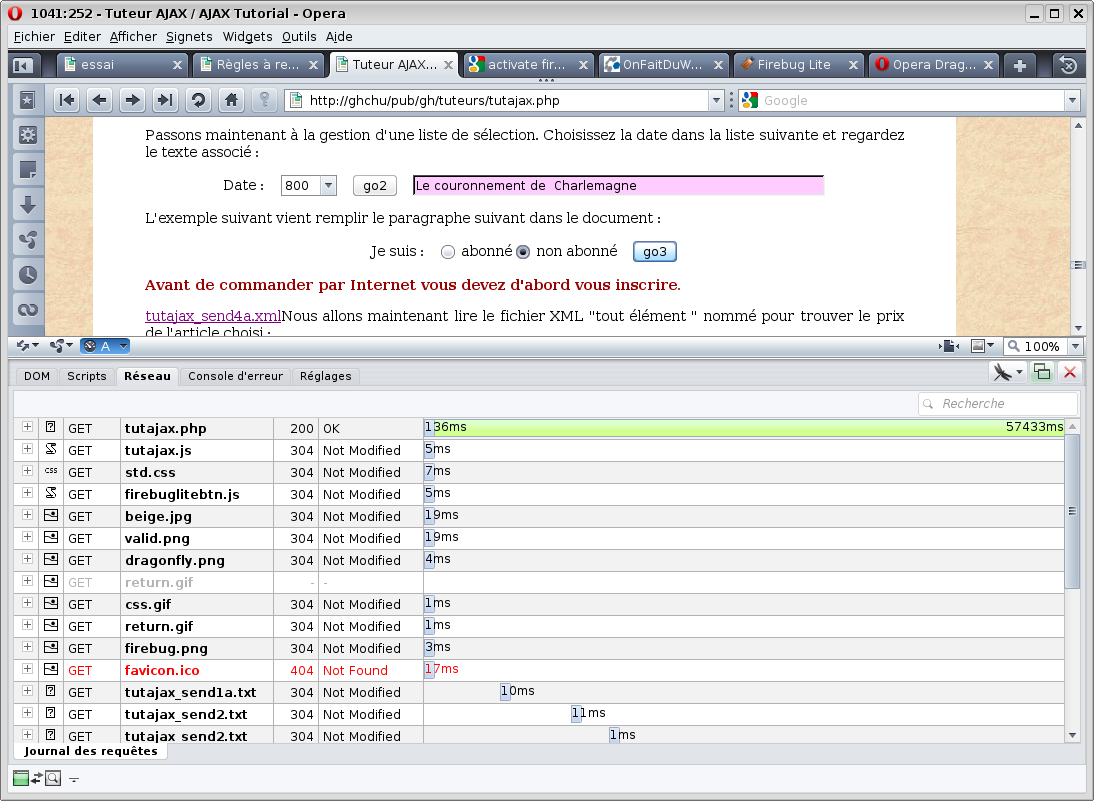
Depuis la version 9.5, Opera fournit un outil similaire, nommé Dragonfly qui s'active via Outils / Avancé / Outils de développeur :
Pour les autres navigateurs, on pourra utiliser Firebug Lite que vous pouvez activer sur cette page en cliquant sur le bouton suivant (il faut compter quelques secondes pour le chargement et le lancement) :
6. Exemples avec des bibliothèques standardIl existe différentes bibliothèques pour faire de l'AJAX (et plus généralement pour développer en Javascript), dont : Dojo, JQuery, Prototype et Mochikit. Ces bibliothèques ou "frameworks" fournissent du code Javascript prêt à l'emploi qui sait gérer les divers navigateurs et fournit des fonctions de "haut niveau" (comme la fonction $ de Prototype ou celle de jQuery) pour simplifier les requêtes, mises en forme, actions... de façon à offir, via un navigateur, de vraies applications. En plus des pages AJAX de notre collègue J. M. RICHER (dont le fameux exemple des CD), on pourra consulter, pour avoir une idée des possibilités offertes, les liens qui suivent :
Pour conclure, on remarquera que malheureusement tous ces ensembles de fonctions ne produisent pas systématiquement du code XHTML valide, que ce soit pour la grammaire transitionnelle ou stricte, ce qui peut être dommageable à un site qui se veut exemplaire en termes d'accessibilité, de respect des standards W3C... De même, la notion de contenu dynamique fourni à la demande est antinomique avec le référencement de contenu. Là encore, on voit bien que le développement Web va encore changer dans les prochaines années...
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)