Recopiez l'archive lesbd.zip sur votre ordinateur puis insérez les tables dans la base de données scripts. Vérifiez que vous avez bien un utilisateur anonymous avec un mot de passe anonymous et qu'il peut lire les bases de données exemples en mode SELECT. On testera les commandes MySql suivantes :
use scripts
select * from scripts.elf order by iden limit 10 ;
select iden,age,sexe
from elf
where sexe=0 and age>30
order by sexe,age desc
limit 5 ;
SELECT etud, AVG(age) FROM elf GROUP BY etud ;
SELECT ROUND(100*COUNT(sexe)/ (SELECT count(iden) FROM elf) ) AS frq ,
"%", IF(sexe=0,"hommes","femmes") AS sexe
FROM elf GROUP BY sexe ORDER BY frq DESC ;
Afin de recréer les tables avec leur contenu, il suffit, sous Mysql, de sélectionner la base et d'exécuter la commande source avec comme paramètre le nom du fichier qui contient les les instructions MySql. On peut aussi appeler MySql en ligne de commande en passant le nom de la base en paramètre et utiliser la redirection d'entrée...
Pour avoir un utilisateur anonymous avec les droits de sélection, il faut écrire
linux> mysql -h localhost -u root -p
sql: CREATE USER 'anonymous'@'localhost' ;
sql: SET PASSWORD FOR 'anonymous'@'localhost' = PASSWORD('anonymous') ;
sql: # CREATE DATABASE scripts ; # éventuellement
sql: GRANT SELECT ON scripts.* TO 'anonymous'@'localhost' ;
sql: USE scripts ;
sql: SOURCE elf_mysql_cr.txt ;
sql: exit
linux> # autre solution :
linux> mysql -h localhost -u root -p scripts < elf_mysql_cr.txt
Pour la base de données ELF, on voudrait obtenir un affichage numéroté des personnes, des hommes ou des femmes, avec un filtre explicite sur l'age. Tester les différentes solutions en RPPR. On essaiera de programmer dans tous ces langages un sous-programme affNumFlt(sexe,age) qui fournit les personnes avec le "bon" code-sexe et avec un age supérieur à celui indiqué. On pourra dans un premier temps se limiter à une solution en Ruby.
Fournir ensuite une interface graphique pour résoudre le même problème en Python avec easygui. On pourra s'inspirer de la solution Web de la page affnumflt.php. On utilisera d'abord MySql puis sqlite3 via elf_sqlite3.bin.
Pour Ruby, une première difficulté est que sa classe ActiveRecord utilise un nommage particulier des bases et tables. Il faut nommer la table au pluriel et définir une classe avec initiale majuscules. Donc ici pour Elf, la table doit se nommer elves. Le reste peut se faire classiquement en ORM avec find ou all, de façon plus ou moins paramétrée :
Voici ce qu'on obtient avec elf_rb.txt :
Solution 1
M009 62
M011 65
M013 78
M023 64
M098 62
Solution 2
M009 62
M011 65
M013 78
M023 64
M098 62
Solution 3
M009 62
M011 65
M013 78
M023 64
M098 62
Solution 4
M009 62
M011 65
M013 78
M023 64
M098 62
Définir en PPPR une classe d'objets personne avec les données nom, pren (prénom) et naiss (année de naissance). On définira «le plus naturellement possible» les getters et setters et on ajoutera une méthode age (calcul à la volée, basé sur l'année courante et l'année de naissance).
Ecrire en PPPR la création des personnes Jean Moulin, né en 1899, Pierre et Marie Curie, nés respectivement en 1859 et 1867. Afficher ces personnes puis sauvegardez-les au format JSON, YAML et XML (on ne créera que des éléments XML et aucun attribut). Ecrire ensuite en PPPR des fonctions ou des méthodes toDB() et fromDB() qui permettent de d'importer ou d'exporter dans une base de données des objets-personnes. On pourra s'inspirer de oo_pers.php. dont le code source est ici qui utilise oo_inc.php.
A l'exercice 8 de la série 1 on avait utilisé sqlite3 comme moteur de base de données pour le tutoriel Django. Comment fait-on pour consulter la base et les tables créées ? Quelle différence avec MySql ? Quel intérêt pour du prototypage en développement Web ? Quelles sont les tables créées dans le tuteur Django ?
Application : que contient le fichier binaire elf_sqlite3.bin ?
Attention : ce n'est pas parce que Django (Python) utilise sqlite3 que la commande sqlite3 est forcément installée. On viendra donc l'installer via sudo apt-get install sqlite3 sqlite3-doc. L'intérêt est que la table tient tout entière dans un seul fichier, facilement copiable et transportable, sans administrateur. Le défaut, c'est qu'à part la commande SELECT les autres instruction en REPL sont différentes. Par exemple il faut taper .quit au lieu de quit ; pour sortir de l'interpréteur sql. Voici un exemple de session bash puis sql3 qui montre ce que contient la table du tutoriel, ici nommée matable.
$gh> sqlite3 -help
Usage: sqlite3 [OPTIONS] FILENAME [SQL]
FILENAME is the name of an SQLite database. A new database is created
if the file does not previously exist.
OPTIONS include:
-help show this message
-init filename read/process named file
-echo print commands before execution
-[no]header turn headers on or off
-bail stop after hitting an error
-interactive force interactive I/O
-batch force batch I/O
-column set output mode to 'column'
-csv set output mode to 'csv'
-html set output mode to HTML
-line set output mode to 'line'
-list set output mode to 'list'
-separator 'x' set output field separator (|)
-nullvalue 'text' set text string for NULL values
-version show SQLite version
$gh> sqlite3 matable
SQLite version 3.6.22
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite> .help
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail ON|OFF Stop after hitting an error. Default OFF
.databases List names and files of attached databases
.dump ?TABLE? ... Dump the database in an SQL text format
If TABLE specified, only dump tables matching
LIKE pattern TABLE.
.echo ON|OFF Turn command echo on or off
.exit Exit this program
.explain ?ON|OFF? Turn output mode suitable for EXPLAIN on or off.
With no args, it turns EXPLAIN on.
.genfkey ?OPTIONS? Options are:
--no-drop: Do not drop old fkey triggers.
--ignore-errors: Ignore tables with fkey errors
--exec: Execute generated SQL immediately
See file tool/genfkey.README in the source
distribution for further information.
.header(s) ON|OFF Turn display of headers on or off
.help Show this message
.import FILE TABLE Import data from FILE into TABLE
.indices ?TABLE? Show names of all indices
If TABLE specified, only show indices for tables
matching LIKE pattern TABLE.
.load FILE ?ENTRY? Load an extension library
.mode MODE ?TABLE? Set output mode where MODE is one of:
csv Comma-separated values
column Left-aligned columns. (See .width)
html HTML <table> code
insert SQL insert statements for TABLE
line One value per line
list Values delimited by .separator string
tabs Tab-separated values
tcl TCL list elements
.nullvalue STRING Print STRING in place of NULL values
.output FILENAME Send output to FILENAME
.output stdout Send output to the screen
.prompt MAIN CONTINUE Replace the standard prompts
.quit Exit this program
.read FILENAME Execute SQL in FILENAME
.restore ?DB? FILE Restore content of DB (default "main") from FILE
.schema ?TABLE? Show the CREATE statements
If TABLE specified, only show tables matching
LIKE pattern TABLE.
.separator STRING Change separator used by output mode and .import
.show Show the current values for various settings
.tables ?TABLE? List names of tables
If TABLE specified, only list tables matching
LIKE pattern TABLE.
.timeout MS Try opening locked tables for MS milliseconds
.width NUM1 NUM2 ... Set column widths for "column" mode
.timer ON|OFF Turn the CPU timer measurement on or off
sqlite> .tables
auth_group django_admin_log
auth_group_permissions django_content_type
auth_message django_session
auth_permission django_site
auth_user polls_choice
auth_user_groups polls_poll
auth_user_user_permissions
sqlite> .schema
CREATE TABLE "auth_group" (
"id" integer NOT NULL PRIMARY KEY,
"name" varchar(80) NOT NULL UNIQUE
);
CREATE TABLE "auth_group_permissions" (
"id" integer NOT NULL PRIMARY KEY,
"group_id" integer NOT NULL REFERENCES "auth_group" ("id"),
"permission_id" integer NOT NULL REFERENCES "auth_permission" ("id"),
UNIQUE ("group_id", "permission_id")
);
CREATE TABLE "auth_message" (
"id" integer NOT NULL PRIMARY KEY,
"user_id" integer NOT NULL REFERENCES "auth_user" ("id"),
"message" text NOT NULL
);
CREATE TABLE "auth_permission" (
"id" integer NOT NULL PRIMARY KEY,
"name" varchar(50) NOT NULL,
"content_type_id" integer NOT NULL,
"codename" varchar(100) NOT NULL,
UNIQUE ("content_type_id", "codename")
);
CREATE TABLE "auth_user" (
"id" integer NOT NULL PRIMARY KEY,
"username" varchar(30) NOT NULL UNIQUE,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL,
"email" varchar(75) NOT NULL,
"password" varchar(128) NOT NULL,
"is_staff" bool NOT NULL,
"is_active" bool NOT NULL,
"is_superuser" bool NOT NULL,
"last_login" datetime NOT NULL,
"date_joined" datetime NOT NULL
);
CREATE TABLE "auth_user_groups" (
"id" integer NOT NULL PRIMARY KEY,
"user_id" integer NOT NULL REFERENCES "auth_user" ("id"),
"group_id" integer NOT NULL REFERENCES "auth_group" ("id"),
UNIQUE ("user_id", "group_id")
);
CREATE TABLE "auth_user_user_permissions" (
"id" integer NOT NULL PRIMARY KEY,
"user_id" integer NOT NULL REFERENCES "auth_user" ("id"),
"permission_id" integer NOT NULL REFERENCES "auth_permission" ("id"),
UNIQUE ("user_id", "permission_id")
);
CREATE TABLE "django_admin_log" (
"id" integer NOT NULL PRIMARY KEY,
"action_time" datetime NOT NULL,
"user_id" integer NOT NULL REFERENCES "auth_user" ("id"),
"content_type_id" integer REFERENCES "django_content_type" ("id"),
"object_id" text,
"object_repr" varchar(200) NOT NULL,
"action_flag" smallint unsigned NOT NULL,
"change_message" text NOT NULL
);
CREATE TABLE "django_content_type" (
"id" integer NOT NULL PRIMARY KEY,
"name" varchar(100) NOT NULL,
"app_label" varchar(100) NOT NULL,
"model" varchar(100) NOT NULL,
UNIQUE ("app_label", "model")
);
CREATE TABLE "django_session" (
"session_key" varchar(40) NOT NULL PRIMARY KEY,
"session_data" text NOT NULL,
"expire_date" datetime NOT NULL
);
CREATE TABLE "django_site" (
"id" integer NOT NULL PRIMARY KEY,
"domain" varchar(100) NOT NULL,
"name" varchar(50) NOT NULL
);
CREATE TABLE "polls_choice" (
"id" integer NOT NULL PRIMARY KEY,
"poll_id" integer NOT NULL REFERENCES "polls_poll" ("id"),
"choice" varchar(200) NOT NULL,
"votes" integer NOT NULL
);
CREATE TABLE "polls_poll" (
"id" integer NOT NULL PRIMARY KEY,
"question" varchar(200) NOT NULL,
"pub_date" datetime NOT NULL
);
CREATE INDEX "auth_message_user_id" ON "auth_message" ("user_id");
CREATE INDEX "auth_permission_content_type_id" ON "auth_permission" ("content_type_id");
CREATE INDEX "django_admin_log_content_type_id" ON "django_admin_log" ("content_type_id");
CREATE INDEX "django_admin_log_user_id" ON "django_admin_log" ("user_id");
CREATE INDEX "polls_choice_poll_id" ON "polls_choice" ("poll_id");
sqlite> select * from auth_user ;
1|chf|||chf@gmail.com|sha1$8e395$810830d4165b30b5b178d81d3292f1293955e086|1|1|1|2013-01-23 10:15:15.071657|2013-01-23 10:01:49.950561
sqlite> select * from django_site ;
1|example.com|example.com
sqlite>.quit
Le fichier binaire elf_sqlite3.bin contient juste la table de données elves pour que ruby puisse faire de l'ORM avec un objet Elf comme vu dans ce cours. Il s'agit bien sûr d'une copie de la table elf de la base statdata.
Y a-t-il d'autres formats de sérialisation que JSON et YAML ? Pourquoi ?
A part XML et le format de sérialisation propre à PHP, on serait tenté de dire non parce que JSON est minimal, YAML en est une extension qui reste toutefois un peu incomplète et XML maximal. Dans la mesure où XML couvre tous les besoins, XML s'est imposé pour la sérialisation «de haut niveau».
Ruby peut utiliser une sérialisation binaire avec marshall et Python utilise pickle.
Comment fait-on pour utiliser l'ORM pour la table ELF en PPPR ?
Solution détaillée volontairement non communiquée.
On fournit seulement elf.rb et elf.py.
On voudrait stocker un graphe simple non orienté, non pondéré dont les sommets sont nommés. Quel format de stockage proposez-vous ? Reprendre avec les graphes orientés, pondérés, valués, les multigraphes... Et si on veut les afficher graphiquement, avec des ronds, des flèches, comme ci-dessous à gauche ? Essayer ensuite de reproduire rapidement le graphe de droite. Est-ce adapté aux diagrammes UML, schémas MCD, MCT et autres descriptions de base de données ?
 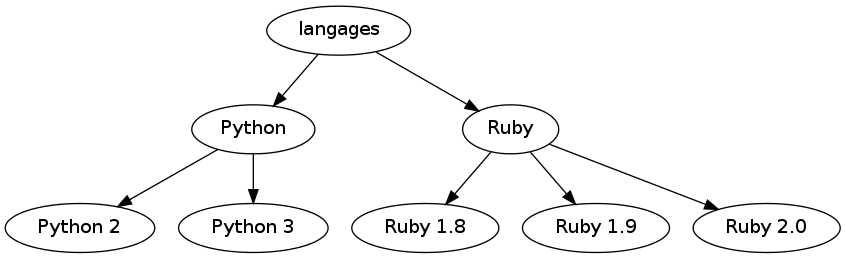
Le plus simple est sans doute d'utiliser le langage dot qui fait partie de Graphviz. Voici donc la solution dans le fichier graphrp.dot. On produit le fichier png via la commande dot -T png graphrp.dot -o graphrp.png. Une copie du manuel de dot est dotguide.pdf. La grammaire du langage dot est ici.
digraph graphname {
langages -> Python ;
langages -> Ruby ;
Python -> "Python 2" ;
Python -> "Python 3" ;
Ruby -> "Ruby 1.8" ;
Ruby -> "Ruby 1.9" ;
Ruby -> "Ruby 2.0" ;
} # fin de digraph
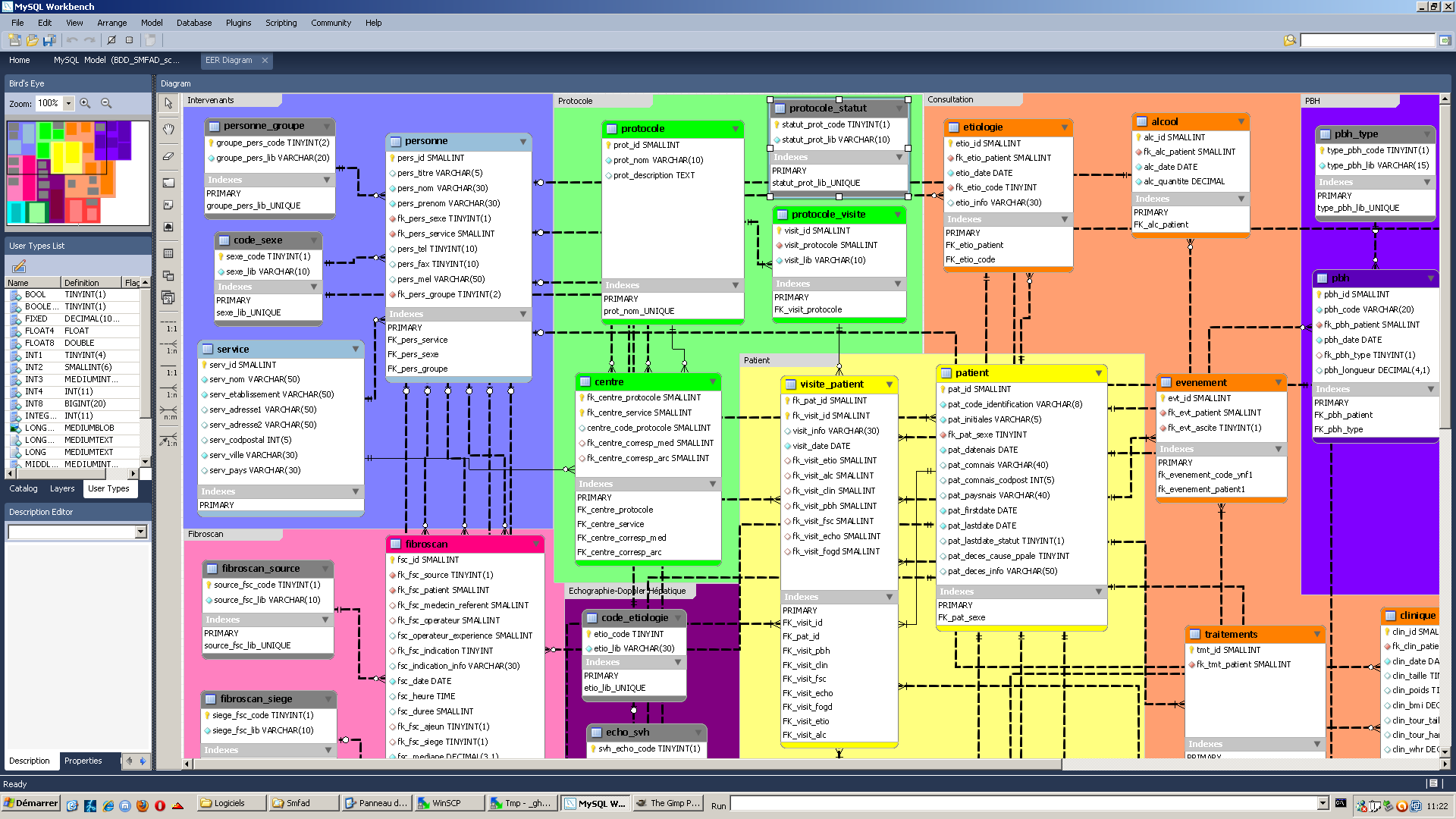
Pour tout ce qui concerne UML, MCD, MCT et la description de bases de données, il existe des logiciels spécialisés, comme par exemple MySQL Workbench dont voici une capture écran sur une de nos bases :
On notera qu'il existe un langage spécifique nommé ogdl qui utilise des fichiers-textes et l'indentation pour définir les graphes. L'URL du site officiel est http://ogdl.sourceforge.net/.
Les données qu'on utilise dans des analyses statistiques sont en général rectangulaires : toutes les lignes ont le même nombre de mots et les données associées à une colonne sont homogènes. Quel format de stockage proposez-vous ?
Les langages Perl, PHP, Ruby, Python sont-ils adaptés pour réaliser des analyses statistiques, par exemple pour réaliser un test de Student ? Quel langage de scripts est un «bon» langage pour réaliser des analyses statistiques ? Et pour tracer des beanplots ou des boxplots ?
Hélas, les statistiques sont un monde à part. Le logiciel R et son langage est l'un des rares langages gratuits qui permet de réaliser toutes les analyses statistiques, même les plus sophistiquées. Pour plus d'informations voir mon introduction non élémentaire à R et mon cours de programmation R avancée en plus de mes cours de statistique avec R pour l'école doctorale Biologie Santé. De plus R s'interface bien avec le Web. Voir par exemple la page statistical analysis et cliquer sur le bouton Length pour voir des beanplots ou des boxplots générés à la volée.
Toutefois, Python avec NumPy et ScyPy semble aujourd'hui (2014) un bon langage pour la programmation scientifique, dont les analyses statistiques "classiques".
En ce qui concerne le format de stockage, ce n'est souvent pas un problème. La plupart des langages ont des fonctions pour lire des données Excel, des données SQL etc. et pour convertir ensuite en une structure de données adaptée au langage. Par contre, pour passer d'un format long à un format large, c'est plus difficile. Voir par exemple le manuel du package reshape2.
En ce qui concerne la représentation de données, la librairie protovis qui est devenue D3.js a son gemme nommé rubyvis et le package correspondant pour Python se nomme tw2.protovis.core.
Code-source php de cette page ; code javascript utilisé. Retour à la page principale du cours.
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)