Pour ce qui suit, nous allons réduire l'action à exécuter sur le fichier au simple affichage de son nom. On admettra donc que le traitement d'un fichier est réalisé par la fonction suivante :
# fonction-test pour traiter un fichier
# (dummy function to process a file)
traiteFic <- function(nomFichier) {
cat("traitement du fichier",nomFichier,"\n")
} # fin de fonction traiteFic
Pour traiter une liste de fichiers comme celle indiquée, il pourrait être tentant d'écrire une boucle POUR à partir de la liste des fichiers, soit le code :
# traitement de tous les fichiers d'une "liste de fichiers"
# à l'aide la fonction traiteFic
traiteFic <- function(nomFichier) { cat("traitement du fichier",nomFichier,"\n") }
listeFic <- paste("serie",sprintf("%02d",1:10),".txt",sep="")
nbFic <- length( listeFic )
for (indFic in (1:nbFic)) {
cat(sprintf("%02d",indFic),"/",nbFic," : ")
traiteFic( listeFic[ indFic ])
} # fin de pour
D'où l'affichage :
01 / 10 : traitement du fichier serie01.txt
02 / 10 : traitement du fichier serie02.txt
03 / 10 : traitement du fichier serie03.txt
04 / 10 : traitement du fichier serie04.txt
05 / 10 : traitement du fichier serie05.txt
06 / 10 : traitement du fichier serie06.txt
07 / 10 : traitement du fichier serie07.txt
08 / 10 : traitement du fichier serie08.txt
09 / 10 : traitement du fichier serie09.txt
10 / 10 : traitement du fichier serie10.txt
Ce n'est certainement pas la seule solution. Elle oblige à programmer une boucle, alors qu'on peut se contenter d'écrire le code :
# traitement de tous les fichiers d'une "liste de fichiers"
# à l'aide la fonction traiteFic SANS BOUCLE
traiteFic <- function(nomFichier) { cat("traitement du fichier",nomFichier,"\n") }
listeFic <- paste("serie",sprintf("%02d",1:10),".txt",sep="")
res <- sapply(FUN = traiteFic,X=listeFic)
dont l'affichage est :
traitement du fichier serie01.txt
traitement du fichier serie02.txt
traitement du fichier serie03.txt
traitement du fichier serie04.txt
traitement du fichier serie05.txt
traitement du fichier serie06.txt
traitement du fichier serie07.txt
traitement du fichier serie08.txt
traitement du fichier serie09.txt
traitement du fichier serie10.txt
Si maintenant on veut absolument un affichage comme fichier xx/yy il est possible d'écrire, toujours sans boucle :
# traitement de tous les fichiers d'une "liste de fichiers"
# à l'aide la fonction traiteFic SANS BOUCLE
traiteFic <- function(nomFichier) { cat("traitement du fichier",nomFichier,"\n") }
traiteFicNum <- function(indice,liste) {
nombre <- length( liste )
cat(sprintf("%02d",indice),"/",nombre," : ")
traiteFic( liste[ indice ])
} # fin de function traiteFicNum
listeFic <- paste("serie",sprintf("%02d",1:10),".txt",sep="")
res <- lapply(X = 1:10,FUN=traiteFicNum,listeFic)
2. Transformations dans un data frame
Comment fait-on en R pour convertir des données dans un data frame ? Par exemple, comment convertir les unités américaines dans le système métrique pour les données height, weight et waist des données DIABETES ?
La réponse tient en un seul mot : il s'agit de la fonction transform(). Voici ce qu'on pourrait naivement écrire, si on ne connaissait pas cette fonction :
## 1. Lecture des données diabetes avec nos fonctions
# 1.1 chargement de nos fonctions
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r", encoding="latin1" )
# 1.2 lecture des données diabetes sur internet
urldiab <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/diabetes.dar"
diaborg <- lit.dar(urldiab)
print( lesColonnes(diaborg) )
# 1.3 on ne garde que les variables à convertir et l'identifiant patient
garde <- c("id","height","weight","waist")
diab <- diaborg[, garde ]
# 2. Transformation des variables
# 2.1 on rajoute directement dans le dataframe avec la notation dollar
diab$taille <- diab$height * 2.54
diab$ceinture <- diab$waist * 2.54
diab$poids <- diab$weight * 0.45359237
# 2.2 autre solution : on crée des fonctions de conversion et on les applique
poucesEnCm <- function(x) { return (x*2.54) }
livresEnKg <- function(x) { return (x*0.45359237) }
diab$taille <- poucesEnCm( diab$height )
diab$ceinture <- poucesEnCm( diab$waist )
diab$poids <- livresEnKg( diab$weight )
Et bien sûr la "bonne" solution, plus concise avec la fonction transform() :
# conversion de valeurs américaines au système métrique
poucesEnCm <- function(x) { return (x*2.54) }
livresEnKg <- function(x) { return (x*0.45359237) }
diab <- transform(diab,
taille=poucesEnCm(height),
poids=livresEnKg(weight),
ceinture=poucesEnCm(waist)
) # fin de transform
Pour des transformations plus sophistiquées, par exemple si on veut utiliser dans la foulée des colonnes tout juste créees, on peut passer par la fonction mutate() du package plyr.
3. Positions dans une structure
Quelle est la façon la plus efficace en R pour trouver les positions d'éléments remarquables ? Par exemple pour trouver les positions du minimum, ou les valeurs plus grandes que la moyenne plus deux écart-types ?
Nous avons déjà vu et expliqué ce genre de problème et la réponse est le filtrage vectoriel. Voici par exemple comment compter combien de valeurs sont supérieures à la moyenne :
> print( v <- round(runif(20,min=0,max=50)) )
25 9 32 33 33 43 12 24 14 2 26 1 21 33 21 21 42 27 1 27
> cat(" il y a",sum(v>mean(v)),"valeurs supérieures à la moyenne qui est",sprintf("%0.1f",mean(v)),"\n")
il y a 11 valeurs supérieures à la moyenne qui est 22.4
4. Barre de progression
Comment implémenter une barre de progression en R ?
Ceci est un problème simple et classique. Il est donc normal qu'il y ait plusieurs solutions en R et il ne faut pas passer de temps à essayer de programmer cela. On pourra s'en convaincre à l'aide de la commande RSiteSearch("progress bar"). La page Web associée est ici.
Prenons tout d'abord quelque chose d'un peu long à calculer :
# une fonction qui peut durer longtemps
# pour n=300, il faut à peu près 20 secondes
unPeuLong <- function(n) {
nb <- 10*n
x <- c()
for (i in (1:nb)) {
x <- c(x,rnorm(i))
} # fin pour
} # fin de fonction unPeuLong
Et voyons comment afficher une barre de progression
sur 50 caractères "égal". Nous commençons par afficher une ligne d'étoiles de la
même longueur que la barre de progression :
unPeuLongBarre <- function(n) {
nb <- 10*n
lng <- 50 # longueur de la barre
barre <- txtProgressBar(min=0,max=nb,width=lng)
cat(paste(rep("*",lng),collapse=""),"\n")
x <- c()
for (i in (1:nb)) {
x <- c(x,rnorm(i))
setTxtProgressBar(barre,i)
} # fin pour
close(barre)
} # fin de fonction unPeuLongBarre
Voici ce qui est affiché au bout de 10 secondes si on exécute
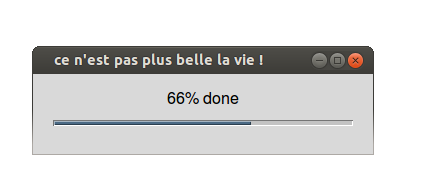
Les barres de progression affichées par tkProgressBar() sont des fenêtres à part et qui n'apparaissent pas
dans la sortie console. En voici un exemple, inspiré, bien sûr de example(tkProgressBar)
sachant que la syntaxe de la fonction tkProgressBar()
est très similaire à celle de la fonction txtProgressBar() :
non <- "ce n'est pas plus belle la vie !"
pb <- tkProgressBar("test progress bar", non, 0, 100, 50)
u <- c(0, sort(runif(20, 0, 100)), 100)
for(i in u) {
Sys.sleep(1.0)
info <- sprintf("%d%% done", round(i))
setTkProgressBar(pb, i, non, info)
}
close(pb)
Voici ce qui est affiché au bout de 10 secondes :
Conclusion : il y a très souvent dans les packages R tout ce qu'on veut comme solution technique
à un problème classique ou fréquent.
5. Documenter la fin de fonction
Vous avez déjà vu dans nos codes-source les fins de fonctions
documentées comme ceci :
} # fin de fonction convPouceCm
} # fin de fonction carre
} # fin de fonction TA
A quoi cela peut-il servir ?
Est-ce simple d'écrire une fonction qui utilise un paramètre qui correspond
à un nom de fichier script au sens de R et en affiche la liste des fonctions
avec le numéro de ligne du début de fonction
comme dans
> listeFonctions("conversion.r")
Liste des fonctions du fichier conversion.r
===========================================
1. saisieConversion() 8
2. convPouceCm() 15
Comment utiliser cette fonction dans le terminal sans passer par Rstudio ?
Ecrire explicitement # fin de fonction, comme écrire
# fin si ou
# fin pour
rend le code-source beaucoup plus lisible pour un être humain (l'interpréteur
R, lui, utilise d'autres règles pour "lire" et "comprendre" le code).
Il est sûr que quand on lit un code comme
}}}
ou
}
}
}
on ne sait pas explicitement quelle structure se termine. C'est pourquoi nous vous conseillons
d'écrire
} # fin si égalité
} # fin pour i de 1 à 10
} # fin tant que sur repUsr
même si certains éditeurs de textes sont capables d'auto-indenter le code-source.
Documenter la fin de fonction rend aussi plus facile la recherche des fonctions dans un
texte par programme. C'est pourquoi nous écrivons # fin fonction xxx et non pas
# end function. Cela permet de pouvoir fournir facilement dans une page Web juste le code de la
fonction, comme par exemple pour l'interface de statghfns :
Si on respecte un minimum de convention d'écriture comme par exemple
mettre le début et la fin de fonction sur une seule ligne, produire une liste des fonctions
comme celle demandée consiste juste à savoir détecter les expressions <- function
et # fin fonction.
Heureusement, R dispose de fonctions pour cela.
Ainsi, avec la fonction grep() du package base, on peut facilement trouver les numéros de lignes.
Il suffit d'écrire, après la lecture du fichier par lignes <- readLines(fichier)
L'expression régulière utilisée ici "<-\\s+function\\(" est un tout petit peu plus compliquée
que la simple chaine "<- function"
car
il peut y avoir plusieurs espaces entre <- et function
d'où la partie \s+ ;
pour saisir un "slash" dans une expression régulière, il faut doubler ce symbole, d'où \\s+ ;
pour saisir une parenthèse dans une expression régulière, il faut la faire précéder d'un "slash" qui doit lui-même
être doublé d'où \\(.
Si de plus on utilise le paramètre value avec la valeur TRUE dans l'appel de la fonction grep(), R renvoie la chaine détectée. Voici ce qu'on
peut donc facilement obtenir avec R juste avec grep()et l'expression régulière :
Au niveau de la deuxième expression régulière, nous avons ajouté .* devant <- afin de récupérer le nom de la fonction.
Pour terminer l'exercice, il suffit de ne garder que le premier mot de chaque ligne trouvée, ce qu'on peut faire avec une fonction
anonyme. Voici donc le texte complet de la fonction qui construit la liste des fonctions d'un fichier-script :
listeFonctions <- function(fichier="") {
# test du paramètre et aide éventuelle
if (missing(fichier) | fichier=="") {
cat("\nsyntaxe : listeFonctions(fichier)\n")
return(invisible(""))
} # fin de si
stopifnot(file.exists(fichier)) # arrêt si le fichier n'est pas présent
lignes <- enc2utf8( readLines(fichier) ) # lecture du fichier + conversion en utf8
# détection des entêtes de fonction
expReg <- ".*<-\\s+function\\("
numLignes <- grep(pattern=expReg,x=lignes)
foncLignes <- grep(pattern=expReg,x=lignes,value=TRUE)
fonctions <- sapply(FUN=function(x) { x[[1]][1]} ,X=strsplit(foncLignes,split=" "))
# affichage
phrase <- paste("Liste des fonctions du fichier",fichier,collapse=" ")
soulign <- paste(rep("=",nchar(phrase)),collapse="")
cat("\n",phrase ,"\n",soulign,"\n\n")
print(cbind(numLignes,fonctions),quote=FALSE)
} # fin de fonction listeFonctions
Le rendu est presque conforme à ce qu'on voulait
> listeFonctions("conversion.r")
Liste des fonctions du fichier conversion.r
===========================================
numLignes fonctions
[1,] 8 saisieConversion
[2,] 32 convPouceCm
au cadrage près des numéros de ligne à droite, ce qu'on peut obtenir
facilement avec la fonction sprintf(). Il manque aussi les parenthèses après le nom des fonctions, ce qu'on réalise très
simplement la fonction paste(). Donc au lieu du print() en fin de fonction, si on écrit
matFonc <- cbind(sprintf("%6s",numLignes),paste(fonctions,"()",sep=""))
colnames(matFonc) <- c("numéros de ligne","fonctions")
print(matFonc,quote=FALSE)
alors le résultat est exactement ce qu'on voulait :
numéros de ligne fonctions
[1,] 8 saisieConversion()
[2,] 32 convPouceCm()
Vous aurez remarqué, bien sûr, qu'il n'y a pas de boucle, car nous n'avons utilisé que des fonctions vectorielles.
Pour utiliser cette fonction dans un terminal, il suffit de passer par la commande R ou la commande Rscript. Il faut bien sur récupérer le paramètre qui correspond au nom du fichier :
$gh> Rscript --slave listeDesFonctions.r
Lle nom du fichier est manquant.
Erreur : syntaxe : Rscript --slave listeDesFonctions.r FICHIER
Exécution arrêtée
$gh> Rscript --slave listeDesFonctions.r pomme.txt
Erreur : file.exists(nomFic) n'est pas TRUE
Exécution arrêtée
$gh> Rscript --slave listeDesFonctions.r conversions.r
Liste des fonctions du fichier conversions.r
============================================
numLignes fonctions
[1,] 7 saisieConversion
[2,] 26 convPouceCm
#############################################################################
$gh> cat listeDesFonctions.r
#############################################################################
# lecture de la fonction dans le fichier listefonc.r
source(file="listefonc.r",encoding="latin1")
# test de la présence du paramétre
argv <- commandArgs(TRUE)
if (length(argv)==0) {
cat("\n le nom du fichier est manquant.\n")
stop(" syntaxe : Rscript --slave listeDesFonctions.r FICHIER\n")
} # finf si
# vérification de l'existence du fichier
nomFic <- argv[1]
stopifnot( file.exists(nomFic) )
# si on arrive ici, c'est qu'il y a un paramétre
# et que le fichier correspondant existe
listeFonctions( nomFic )
6. Export de résultats pour publication ou démonstration
On voudrait produire des calculs en R et disposer rapidement et de façon reproductible des résultats numériques et graphiques sans avoir à passer par du copier/coller pour produire les documents associés. Comment faut-il s'y prendre ? Et si on a besoin de tirages aléatoires dans les calculs ?
Pour produire des résultats reproductibles, il vaut mieux éviter d'utiliser R via Rstudio à cause des variables qui pourraient être dans l'environnement. Il est donc conseillé d'exécuter R directement. Si on utilise des valeurs aléatoires, il faut utiliser toujours la même graine. Voici un exemple d'utilisation :
> # sans set.seed() impossible de reproduire les mêmes résultats aléatoires
> print( round(runif(5,1,100)))
71 75 85 81 5
> print( round(runif(5,1,100)))
73 17 73 13 50
> # avec set.seed() on démarre toujours avec les mêmes valeurs
> set.seed(100)
> print( round(runif(5,1,100)))
31 27 56 7 47
> set.seed(100)
> print( round(runif(5,1,100)))
31 27 56 7 47
En ce qui concerne la production de documents avec les résultats, il est clair que la technique du copier/coller n'est pas envisageable, de par le nombre et la répétition des manipulations, sans compter les risques d'erreur. R fournit de nombreuses solutions pour produire des documents. knitr est sans doute la plus pratique (plutôt que Sweave). Elle s'intègre à du code LaTeX, HTML ou Markdown.
Imaginons par exemple qu'on veuille rédiger un document qui montre comment tracer la densité d'un mélange de deux lois normales. Voici la fonction traceNorms() du fichier alea2.r qui réalise ce tracé :
set.seed(100)
traceNorms <- function(a,b,c,d,n) {
# simule deux lois normales
# rnorm(n,mean=a,sd=b) et rnorm(n,mean=c,sd=d)
# puis trace leur densité dans le plan fixe de R²
# définir par [-10,20]x[0,0.5]
norm1 <- rnorm(n=n, mean=a, sd=b)
norm2 <- rnorm(n=n, mean=c, sd=d)
plot(
density(c(norm1,norm2)),
xlim=c(-10,20),
ylim=c(0,0.5),
main="un exemple pour knitr",
xlab="",
ylab=""
) # fin de title
} # fin de fonction
Voici maintenant le document nommé alea.rnw au format knitr qui utilise cette fonction :
% # (gH) -_- alea.rnw ; TimeStamp (unix) : 14 Mars 2015 vers 23:05
%
\documentclass[12pt,a4paper]{article}
%
%\usepackage[T1]{fontenc}
\usepackage[latin1]{inputenc}
\usepackage[a4paper,nohead,margin=2.0cm]{geometry}
\usepackage{etex}
\usepackage{verbatim}
\usepackage{alltt}
\usepackage{color}
\usepackage[french]{babel}
\renewcommand{\thesection}{\arabic{section}. }
\renewcommand{\thesubsection}{\arabic{section}.\arabic{subsection}}
\parindent 0.0cm
\parskip 0.25cm
\def\ghversion{1.03}
%\input{preambKnitr.tex}
\newcommand{\cmt}[1]{}
\begin{document}
\thispagestyle{empty}
%
\begin{center}
{\LARGE KNITR par l'exemple}\\
Gilles HUNAULT Mars 2015
\end{center}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\section*{Un document automatis\'{e}}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Pour tracer la densit\'{e} du m\'{e}lange de deux lois normales, il est possible d'utiliser notre
fonction \textsf{traceNorms()} d\'{e}finie dans le fichier \textsf{alea2.r}.
Voici un premier exemple :
<<un>>=
date()
source("alea2.r",encoding="latin1")
traceNorms(-3,2,15,5,5000)
@
\newpage
Et un second :
<<deux>>=
traceNorms(-4,1,15,3,5000)
@
\end{document}
Dans une session R, il suffit de charger le package knitr puis d'exécuter la seule commande knit("alea.rnw",encoding="UTF-8") pour produire le fichier alea.tex. Via la commande pdflatex alea.tex on obtient alors le fichier alea.pdf. Facile, non ? Oui, si on connait déjà LaTeX.
Il serait même possible de créer une page Web pour faire saisir à l'utilisateur les 5 paramètres de la fonction traceNorms() et produire le PDF à la volée, mais c'est une autre histoire, qui met en jeu trois autres langages, à savoir PHP, HTML et CSS...
Pour avoir rapidement une idée des possibilités de Markdown dans R, le plus simple est d'utiliser Rstudio. Si on passe par le menu File/New File/R Markdown et si on sauvegarde les informations fournies, disons dans demo.Rmd, alors l'utilisation de l'icone Knit et de ses options HTML/PDF/Word produit les fichiers demandés...
7. Passer des boucles POUR aux fonctions *APPLY (ou autres)
Le passage en revue des colonnes d'un dataframe se fait facilement avec une boucle POUR, comme ci-dessous.
# min, max et nombre de valeurs différentes pour les colonnes numériques
# des données iris
data(iris)
for (idCol in (1:4)) {
dataCol <- iris[,idCol]
minCol <- min(dataCol)
maxCol <- max(dataCol)
nvdCol <- length(unique(dataCol))
cat(" colonne",idCol,"soit",names(iris)[idCol],"\n")
cat(" min=",minCol)
cat(" max=",maxCol)
cat(" ndv=",nvdCol)
cat("\n")
} # fin pour idv
colonne 1 soit Sepal.Length
min= 4.3 max= 7.9 ndv= 35
colonne 2 soit Sepal.Width
min= 2 max= 4.4 ndv= 23
colonne 3 soit Petal.Length
min= 1 max= 6.9 ndv= 43
colonne 4 soit Petal.Width
min= 0.1 max= 2.5 ndv= 22
Remplacer cette boucle POUR par un appel de la fonction SAPPLY via les indices de colonnes. Trouver ensuite comment utiliser SAPPLY avec les noms de colonnes. Quel est, hormis la concision, l'intérêt de passer par des fonctions *APPLY ?
Comment produire la matrice triangulaire inférieure d'une matrice symétrique ? On pourra utiliser la fonction cor() ou la fonction dist() pour générer une telle matrice, comme par exemple :
## exemples de matrices symétriques en R
data(iris)
iris4 <- iris[,-5] # on on utilise deux fois ce data.frame
cat("\n")
cat("Matrice des coefficients de corrélation linéaire (Pearson)\n")
print(cor(iris4)) # mieux sans doute : cor(iris4,method="pearson")
cat("\n")
cat("Matrice des distances euclidiennes entre colonnes\n")
print(dist(t(iris4))) # mieux sans doute : dist(t(iris4,method"euclidean")
rm(iris4) # une bonne pratique
Cet exercice semble être volontairement non corrigé sur cette page. Quoique...
Actually, the solution is available if you click on one the word of the preceding paragraph. Can you guess which one it is?
7.1 Passage en revue des colonnes
Avant de passer de cette boucle POUR à un APPLY, essayons d'analyser ce qui pourrait déjà être amélioré dans le code afin qu'on puisse s'en resservir.
Pour gagner en généralité, le mieux est d'essayer de définir une fonction et de passer les données en paramètre. L'intérêt est qu'on pourra tester et réutiliser cette fonction en-dehors de la boucle. Voici donc une première tentative, toujours avec la boucle POUR.
# min, max et nombre de valeurs différentes pour les colonnes numériques
# des données iris
data(iris)
####################################################################
revueCol <- function(x) {
####################################################################
# on traite à part les facteurs
if (is.factor(x)) {
return( c(rep(NA,2),nlevels(x)) )
} # fin si
nvdCol <- length(unique(x))
vret <- c(range(x),nvdCol)
return( vret )
} # fin fonction revueCol
####################################################################
# programme principal
for (idCol in (1:4)) {
dataCol <- iris[,idCol]
cat(" colonne",idCol,"soit",names(iris)[idCol],"\n")
cat( revueCol(dataCol ) )
cat("\n")
} # fin pour idv
colonne 1 soit Sepal.Length
4.3 7.9 35
colonne 2 soit Sepal.Width
2 4.4 23
colonne 3 soit Petal.Length
1 6.9 43
colonne 4 soit Petal.Width
0.1 2.5 22
Enfin, une "vraie" solution R consiste à renvoyer un data.frame car cette structure de données est adaptée à l'utilisation de apply() et sapply comme on peut le voir ci-dessous
# min, max et nombre de valeurs différentes pour les colonnes numériques
# des données iris
data(iris)
####################################################################
revueCol <- function(x) {
####################################################################
# on traite à part les facteurs
if (is.factor(x)) {
vret <- data.frame(min=NA,max=NA,nbValDif=nlevels(x))
} else {
vret <- data.frame(min=min(x),max=max(x),nbValDif=length(unique(x)))
} # fin si
return( vret )
} # fin fonction revueCol
####################################################################
# programme principal
# cat("test :\n") : revueCol( iris[,1] )
print( sapply(F=revueCol,X=iris) )
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
min 4.3 2 1 0.1 NA
max 7.9 4.4 6.9 2.5 NA
nbValDif 35 23 43 22 3
7.2 Matrice triangulaire inférieure
Pour la matrice triangulaire inférieure, une(e) habitué(e) des matrices carrées de taille n viendra utiliser une boucle POUR de 1 à n avec un indice i sur les lignes et une boucle POUR de 1 à i sur les colonnes, soit le code :
## affichage de matrice triangulaire inférieure
data(iris)
md <- cor(iris[,-5])
cat("Matrice symétrique complète\n")
print(md)
cat("\n")
cat("Matrice triangulaire inférieure\n")
nbl <- nrow(md)
for (idl in (1:nbl)) {
for (jdc in (1:idl)) {
cat( sprintf("%7.3f ",md[idl,jdc] ))
} # fin pour j
cat("\n")
} # fin pour i
rm(md)
Il suffit maintenant d'utiliser la notation deux points de R pour éliminer la deuxième boucle POUR car la fonction printLig ne fait qu'appeler la fonction sprintf() qui est une fonction vectorielle donc éliminer cette boucle est facile. Du coup, la fonction printLig peut être remplacée par une fonction anonyme :
# affichage de matrice triangulaire inférieure
data(iris)
md <- cor(iris[,-5])
cat("Matrice symétrique complète\n")
print(md)
cat("\nMatrice triangulaire inférieure\n")
null <- lapply(
X=1:nrow(md),
FUN=function(x) {
cat( sprintf("%7.3f ",md[x,1:x]),"\n" )
} # fin de fonction
) # fin de lapply
Voici enfin la "vraie" solution R qui produit une matrice triangulaire inférieure, avec des noms de lignes et de colonnes, au lieu d'un simple affichage :
# affichage de matrice triangulaire inférieure
data(iris)
md <- cor(iris[,-5])
cat("Solution R native\n")
library(Matrix)
print(round(tril(md),3))
url <- "http://finzi.psych.upenn.edu/R/library/Matrix/html/00Index.html"
browseURL(url)
Solution R native
4 x 4 Matrix of class "dtrMatrix"
Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.000 . . .
Sepal.Width -0.118 1.000 . .
Petal.Length 0.872 -0.428 1.000 .
Petal.Width 0.818 -0.366 0.963 1.000
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)