.
Pour analyser une QL, il est équivalent mathématiquement de fournir soit les comptages soit les pourcentages et l'effectif total. Concrètement, que doit-on afficher comme résultats ? Juste les comptages ? Juste les pourcentages ? Les deux ? Et faut-il tenir compte des valeurs manquantes quand on calcule les pourcentages ?
La réponse est plus compliquée qu'il n'y parait. Il est conseillé d'afficher les comptages et les pourcentages parce que les deux types d'informations sont utiles, mais pas dans le même contexte. Lorsqu'il s'agit de comparer des échantillons ou des séries, seuls les pourcentages sont utilisables. Par contre, connaitre le nombre exact d'individus correspondant à un comptage prend tout son sens et doit être apprécié à sa juste valeur, notamment pour les petites séries ou les petits-sous groupes. Ainsi, passer d'une personne sur 5 à deux personnes sur 5 augmente de 20 % les pourcentages. De même, 3 % ne représentent pas la même quantité suivant l'effectif total : avec 100 personnes, cela fait 3 individus ; avec 5 000 en tout, cela en fait 150.
Il faut toujours rapporter, au moins dans un premier temps, les valeurs manquantes. Là encore, pour les petites séries, les pourcentages sont fortement perturbés suivant qu'on prend en compte les valeurs manquantes ou non. Par exemple avec 10 valeurs, dont 5 'oui', 3 'non' et 2 'non réponses', le pourcentage de 'oui' est 63 % sans les valeurs manquantes, mais retombe à seulement 50 % avec les valeurs manquantes.
1.
Réaliser un tri croisé, c'est juste compter les croisements des modalités de deux variables. Il arrive qu'on ait besoin d'aller plus loin dans les calculs, comme par exemple calculer la moyenne d'une troisième variable pour chaque croisement. Comment réalise-t-on cela avec R et Rcmdr ?
Application : calculer la moyenne de l'âge pour les croisements SEXE/ETUD dans le dossier ELF.
R permet de découper les données avec la fonction split() et ensuite de traiter chaque sous-groupe avec la fonction lapply(). On utilise aussi souvent sapply() qui produit un affichage concis et simplifié pour des sous-groupes simples.
## MOYENNES D'AGE POUR DIVERS SOUS-GROUPES AVEC spli() et apply()
## DOSSIER ELF, VARIABLES SEXE, AGE, ETUD
# 1. lecture des données et gestion des modalités
elf <- read.table("elf.dar",header=TRUE,row.names=1)
m_sexe <- c("Homme","Femme")
m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur")
sexe <- factor(elf$SEXE,levels=0:1,labels=m_sexe)
etud <- factor(elf$ETUD,levels=0:4,labels=m_etud)
# 2. moyenne des ages par sexe
cats("Calculs avec lapply")
elf2 <- split(x=elf$AGE,f=sexe)
print( lapply(X=elf2,FUN=mean) )
cats("Affichage amélioré avec sapply")
print( sapply(X=elf2,FUN=mean) )
# 3. moyenne des ages par niveau d'études
cats("Moyennes d'ages (niveaux d'études)")
elf3 <- split(x=elf$AGE,f=etud)
print( sapply(X=elf3,FUN=mean) )
# 4. moyenne des ages par croisement sexe/niveau d'études
cats("Calculs sur croisement de modalités")
elf4 <- split(x=elf$AGE,f=list(sexe,etud))
print( lapply(X=elf4,FUN=mean) )
Calculs avec lapply
===================
$Homme
[1] 36.4
$Femme
[1] 35.51562
Affichage amélioré avec sapply
==============================
Homme Femme
36.40000 35.51562
Moyennes d'ages (niveaux d'études)
==================================
NR Primaire Secondaire Bac Supérieur
50.00000 56.83333 35.60000 35.23810 32.00000
Calculs sur croisement de modalités
===================================
$Homme.NR
[1] 43.5
$Femme.NR
[1] 63
$Homme.Primaire
[1] 43
$Femme.Primaire
[1] 59.6
$Homme.Secondaire
[1] 40
$Femme.Secondaire
[1] 34.26087
$Homme.Bac
[1] 41.625
$Femme.Bac
[1] 31.30769
$Homme.Supérieur
[1] 31.23529
$Femme.Supérieur
[1] 32.59091
Ce genre de manipulation est tellement usuel que R fournit une fonction tapply() qui effectue tout le travail aussi bien pour des modalités que pour des croisements de modalités, comme on peut le voir ci-dessous.
## MOYENNES D'AGE POUR DIVERS SOUS-GROUPES AVEC tapply()
## DOSSIER ELF, VARIABLES SEXE, AGE, ETUD
# 1. lecture des données et gestion des modalités
elf <- read.table("elf.dar",header=TRUE,row.names=1)
m_sexe <- c("Homme","Femme")
m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur")
sexe <- factor(elf$SEXE,levels=0:1,labels=m_sexe)
etud <- factor(elf$ETUD,levels=0:4,labels=m_etud)
# 2. moyenne (arrondie) des ages par sexe
cats("Calculs avec tapply")
elfAges2 <- tapply(X=elf$AGE,INDEX=sexe,FUN=mean)
print( round(elfAges2,2) )
# 3. moyenne des ages par niveau d'études
cats("Moyennes d'ages (niveaux d'études)")
elfAges3 <- tapply(X=elf$AGE,INDEX=etud,FUN=mean)
print( round(elfAges3, 1) )
# 4. moyenne des ages par croisement sexe/niveau d'études
cats("Calculs sur croisement de modalités")
elfAges4 <- tapply(X=elf$AGE,INDEX=list(sexe,etud),FUN=mean)
print( round(elfAges4, 1) )
Calculs avec tapply
===================
Homme Femme
36.40 35.52
Moyennes d'ages (niveaux d'études)
==================================
NR Primaire Secondaire Bac Supérieur
50.0 56.8 35.6 35.2 32.0
Calculs sur croisement de modalités
===================================
NR Primaire Secondaire Bac Supérieur
Homme 43.5 43.0 40.0 41.6 31.2
Femme 63.0 59.6 34.3 31.3 32.6
2.
On dispose des résultats suivants de tris à plat obtenus via l'ordre historique des variables et des modalités.
| NOM |
Mode |
Effectif |
Modalité |
Effectif |
Modalité |
Effectif |
| SEXE |
Femme |
45.88888 % |
Homme |
54.11111 % |
| SUD |
Oui |
29.212121 % |
Non |
71.787878 % |
| RACE |
Hispanique |
5.27532 % |
Blanche |
82.17123 % |
Autre |
12.55345 % |
| SNDIAT |
Non membre |
82.01876 % |
Membre |
17.98123 % |
| SECTE |
Autre |
77 % |
Manufact. |
18.54 % |
| ST.MARITAL |
Oui |
66 % |
Non |
34.46 % |
| OCCPN |
Profess. |
20.1234 % |
Religieux |
18.2368 % |
Autre |
29.6741 % |
Réordonner les lignes et les colonnes afin de faciliter l'interprétation de ces comptages et pourcentages.
Pour produire un "beau tableau intelligent", il faut :
-
renommer les variables selon le sens et non selon le codade informatique ;
-
arrondir chaque pourcentage afin de faciliter sa lecture ;
-
trier chaque ligne par pourcentage décroissant ;
-
trier ensuite le tableau par ordre décroissant sur le premier pourcentage, c'est-à-dire sur le plus fort pourcentage de la variable.
Voici ce qu'on obtient alors :
| NOM DE LA VARIABLE |
Mode |
Effectif |
Modalité |
Effectif |
| ETHNIE |
Blanche |
82 % |
Autre |
13 % |
| SYNDICAT |
Non membre |
82 % |
Membre |
18 % |
| SECTEUR ACTIVITE |
Autre |
77 % |
Manufact. |
19 % |
| RESIDE AU SUD |
Non |
71 % |
Oui |
29 % |
| EN COUPLE |
Oui |
66 % |
Non |
34 % |
| SEXE |
Homme |
54 % |
Femme |
46 % |
| ACTIVITE PRINCIPALE |
Autre |
29 % |
Profess. |
20 % |
| OCCUPATION |
Autre |
30 % |
Profess. |
20 % |
Il sera alors sans doute possible de rédiger un commentaire comme
La race blanche est manifestement très prépondérante et la plus importante en effectif (440 individus sur 534 soit 82 %) dans cette analyse, de même que les personnes non membres d'un syndicat (438 individus soit aussi 82 %). La modalité qui est ensuite la plus présente est celle du secteur d'activité 'autre', encore prépondérante puisque son effectif relatif est de 77 %... Très faiblement majoritaire, la variable SEXE répartit presque équitablement les hommes et les femmes avec toutefois un léger sureffectif pour les hommes (289 hommes soit 54 % contre 245 femmes soit 46 %).
Malheureusement la variable OCCUP, dont toutes les modalités sont minoritaires...
3.
Qu'est-ce qu'une variable qualitative ordonnée ? La traite-on différement d'une variable qualitative «classique» ? Comment prévenir R qu'une variable qualitative est ordonnée ?
Application : traiter la variable ETUD du dossier ELF.
Une variable qualitative ordonnée est une variable qualitative pour laquelle les modalités ont un ordre établi. La modalité 1 est donc inférieure à la modalité 2, elle-même inférieure à la modalité 3 etc. La description de la presbyacousie sur le wiki français (https://fr.wikipedia.org/wiki/Presbyacousie) par exemple pourrait faire penser à une variable qualitative ordonnée car les modalités sont [incorrectement] numérotées, ce que ne font pas le wiki anglais et le wiki italien, par exemple.
Si une variable qualitative est ordonnée, il faut présenter les modalités par ordre [croissant ou décroissant] et fournir les cumuls d'effectifs et de pourcentages lors des tris à plat, par exemple à l'aide de la fonction cumsum().
On prévient R qu'une variable qualitative est ordonnée à l'ide du paramètre ordered mis à vrai. Il est alors important d'indiquer l'ordre des niveaux.
Voici la lecture et le traitement R de la variable ETUD du dossier ELF sans prendre en compte la nature ordinale de cette variable :
## LECTURE ET TRAITEMENT DE LA VARIABLE ETUD (DONNEES ELF)
## SANS PRISE EN COMPTE DE LA NATURE ORDINALE DE LA VARIABLE
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL.xls")
# tri à plat et cumul ratés
tap <- table(elf2$ETUD)
cum <- cumsum(tap)
mdr <- rbind(tap,cum) # Matrice Des Résultats
row.names(mdr) <- c("Effectifs","Cumul")
print(mdr)
BAC BEPC NR PRIM SUP
Effectifs 21 30 3 6 39
Cumul 21 51 54 60 99
Et voici la "bonne" lecture et le "bon" traitement R de la variable ETUD du dossier ELF avec prise en compte de la nature ordinale de cette variable :
## LECTURE ET TRAITEMENT DE LA VARIABLE ETUD (DONNEES ELF)
## AVEC PRISE EN COMPTE DE LA NATURE ORDINALE DE LA VARIABLE
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL.xls")
elf2$ETUD <-factor(elf2$ETUD,ordered=TRUE,levels=c("NR", "PRIM", "BEPC","BAC","SUP"))
# tri à plat et cumul réussis
tap <- table(elf2$ETUD)
cum <- cumsum(tap)
mdr <- rbind(tap,cum) # Matrice Des Résultats
row.names(mdr) <- c("Effectifs","Cumul")
print(mdr)
NR PRIM BEPC BAC SUP
Effectifs 3 6 30 21 39
Cumul 3 9 39 60 99
4.
Dans le cadre d'un mémoire sur la pré-validation du test ODETAB (Outil de DEpistage d'un Trouble Auditif dans le Bruit), les sujets étudiés sont répartis en sourds et non-sourds. Comment s'est effectuée cette séparation ? Le terme est-il bien choisi ? Voici un extrait des données (fichier odetabExtrait1.xls) :
Individu Sourd Age PlainteOui PlainteNon
P001 non 22 0 5
P002 non 21 0 5
P003 non 21 0 5
P004 non 32 0 5
P005 non 37 0 5
P006 non 26 1 4
P007 non 21 1 4
P008 non 20 0 5
P009 non 19 1 4
P010 non 19 0 5
P011 non 19 0 5
P012 non 21 2 3
P013 non 20 0 5
P014 non 21 0 5
P015 non 19 0 5
P016 oui 65 3 2
P017 oui 54 1 4
P018 oui 74 2 3
P019 oui 68 4 1
P020 oui 78 4 1
P021 oui 78 0 5
P022 oui 58 3 2
P023 oui 65 3 2
P024 oui 71 1 4
P025 oui 59 1 4
P026 oui 53 3 2
P027 oui 57 3 2
Construire une variable qualitative ordonnée nommée CLAG (CLasse d'AGe) pour ces données puis analyser les deux variables Sourd et CLAG. Que peut-on en conclure ?
Indication : pour choisir le nombre de classes et les bornes de classes d'age, on pourra utiliser les fonctions de R nommées stem() et dotchart() du package graphics qui permet de réaliser un diagramme en tiges et feuilles.
Ce n'est visiblement pas une question de statistiques, cette répartition ! Sans aucune information complémentaire sur les critères utilisés pour dire si on est sourd ou pas, il est impossible de savoir comment cela a été fait. On peut sans doute supposer que cette distinction repose sur la normalité d'un bilan d'audiogramme tonal et vocal, mais cela demande a être confirmé. Le terme «sourd» plutôt que «mal entendant» est mal choisi parce que ce n'est pas l'usage d'utiliser un tel qualificatif, pas plus que orthophoniquement défaillant .
Après la lecture des données sous R, le diagramme en tiges et feuilles de l'age montre visiblement deux classes d'age, l'une avant 40 ans et l'autre après 40 ans. Nous qualifierons arbitrairement de jeune (ou junior ?) les personnes avant cette borne et de vieux (ou senior ?) les personnes après cette borne. On trouvera ci-dessous les instructions R associées :
## ANALYSE DES DONNEES ODETAB
# lecture du fichier Excel
library("gdata")
odetab <- read.xls("odetabExtrait1.xls")
# tri à plat de la variable Sourd
cat("QL \"sourd\"\n")
print( table(odetab$Sourd) )
# affichage de l'age (trié)
cat("\nQT age (valeurs croissantes)\n")
print(sort(odetab$Age) )
# diagramme en tiges et feuilles de l'age
print( stem(odetab$Age) )
# graphiques en dotchart
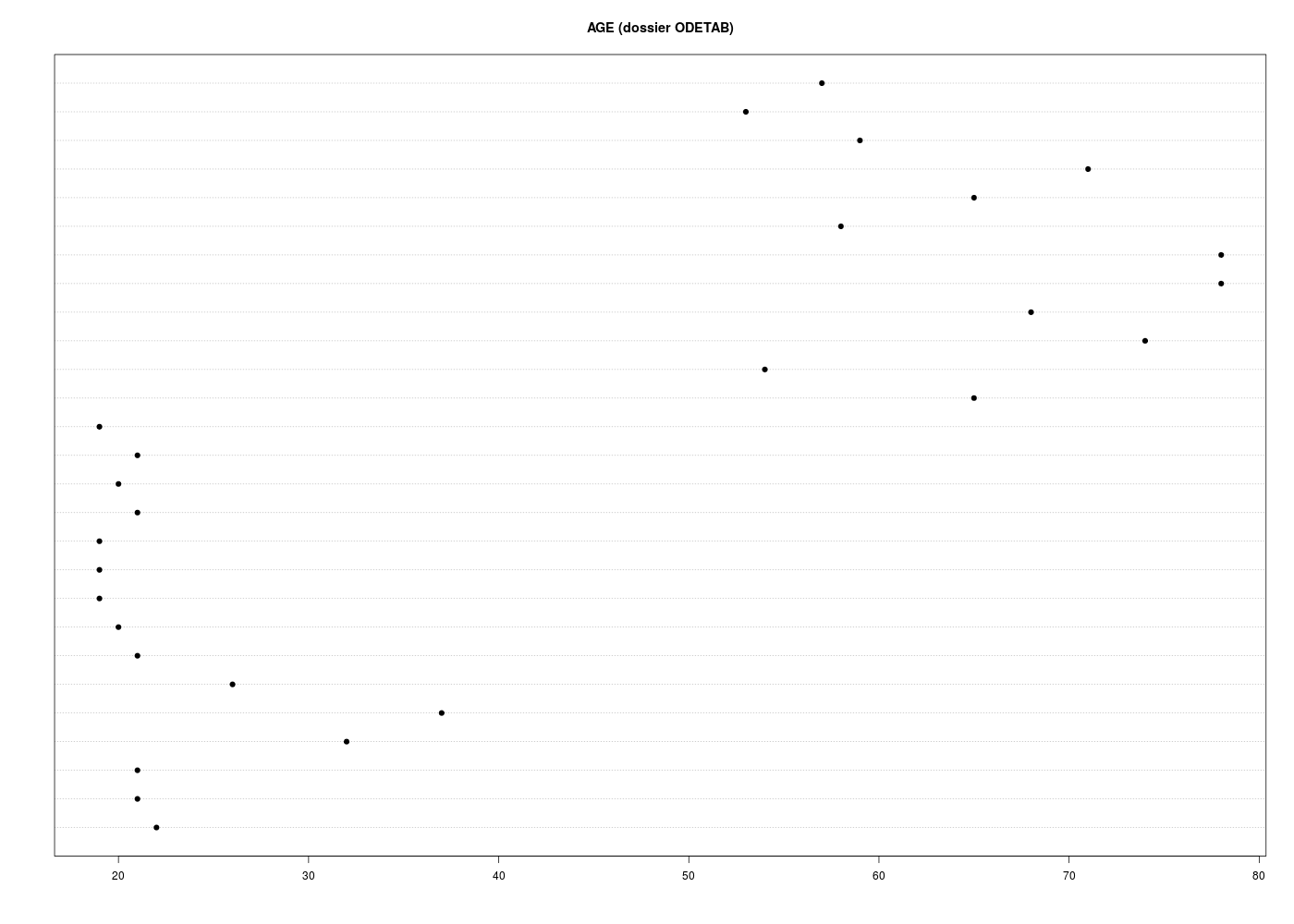
dotchart(odetab$Age,pch=19,main="AGE (dossier ODETAB)")
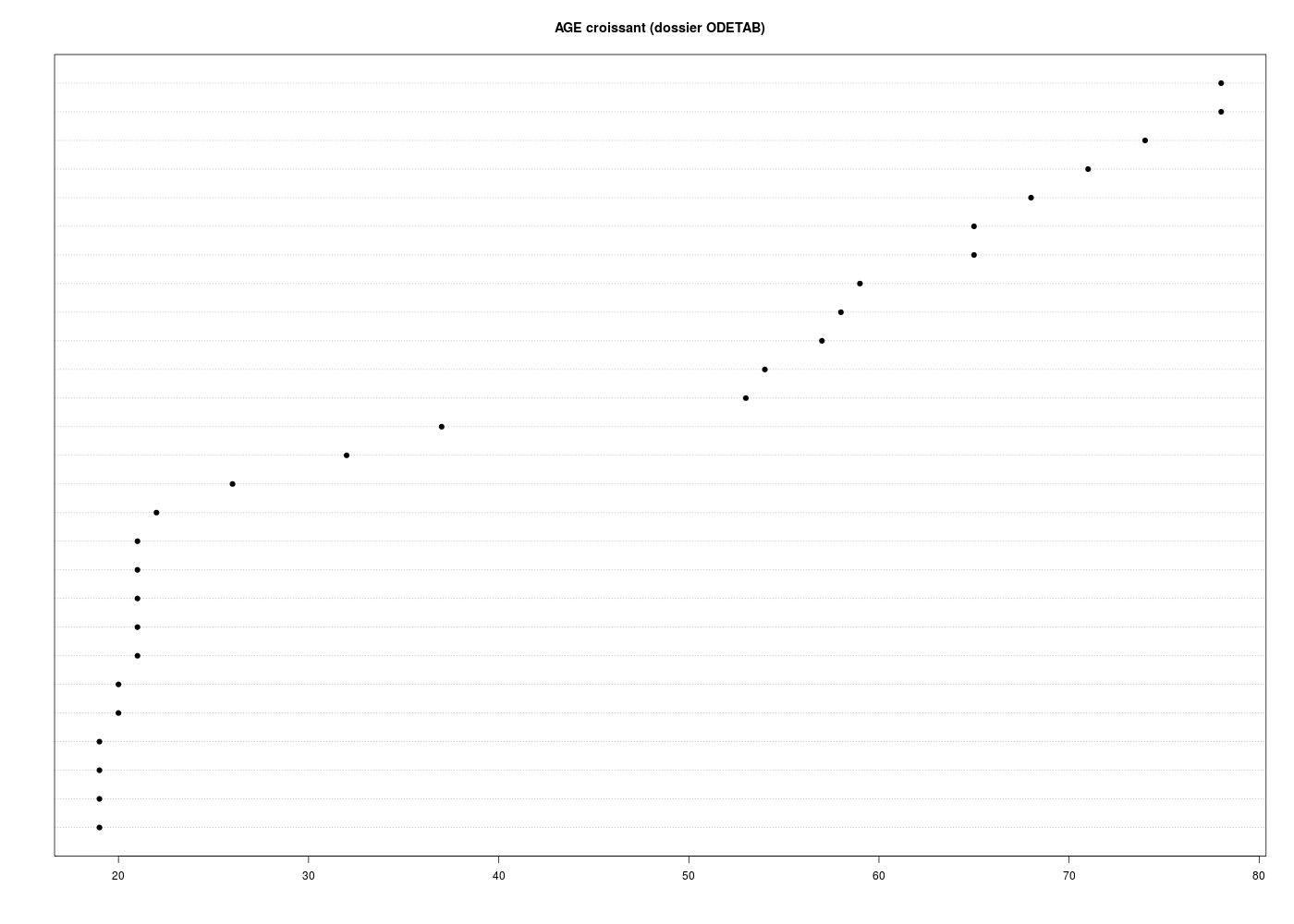
dotchart( sort(odetab$Age),pch=19,main="AGE croissant (dossier ODETAB)")
# création de la variable CLAG (CLasse d'AGe)
odetab$CLAG <- ifelse(odetab$Age<40,"jeune","vieux")
# tri à plat de la variable CLAG
print( table(odetab$CLAG) )
QL "sourd"
non oui
15 12
QT age (valeurs croissantes)
19 19 19 19 20 20 21 21 21 21 21 22 26 32 37 53 54 57 58 59 65 65 68 71 74 78 78
The decimal point is 1 digit(s) to the right of the |
1 | 9999
2 | 001111126
3 | 27
4 |
5 | 34789
6 | 558
7 | 1488
jeune vieux
15 12
Une analyse soignée des deux variables qualitatives devrait réaliser les deux tris à plat et un tri croisé, soit les résultats et graphiques ci-dessous (code R volontairement non fourni) :
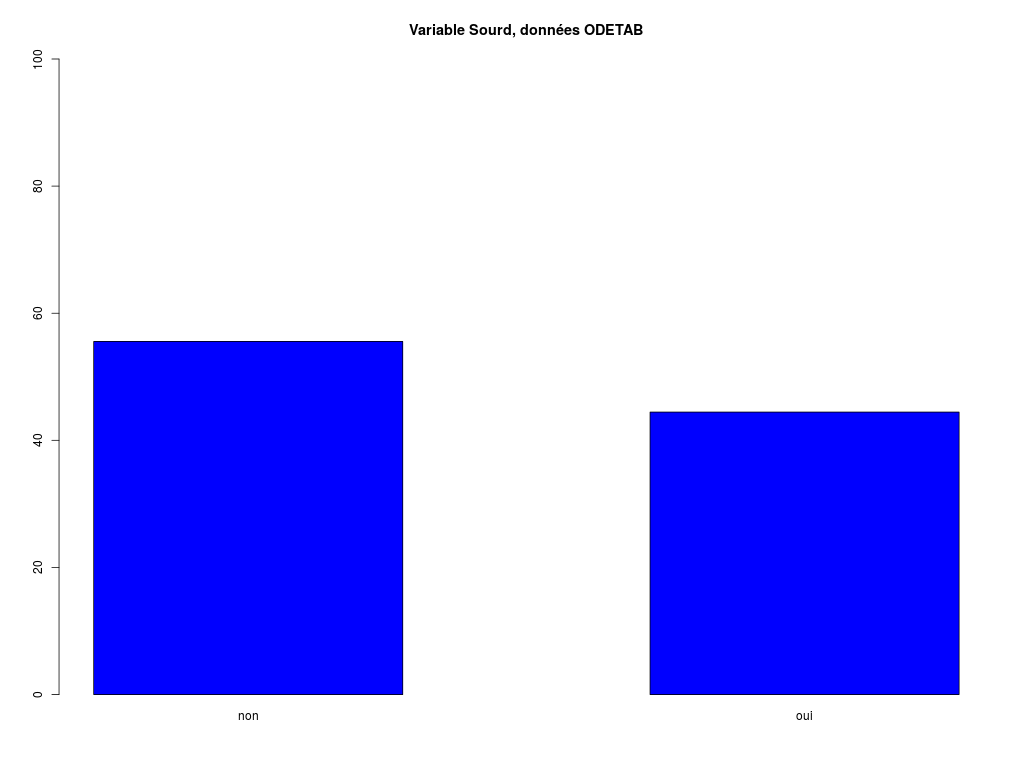
VARIABLE : Variable Sourd, données ODETAB (par fréquence décroissante)
non oui Total
Effectif 15 12 27
Cumul Effectif 15 27 27
Frequence (en %) 56 44 100
Cumul fréquences 56 100 100
Distribution de l'AGE
=====================
The decimal point is 1 digit(s) to the right of the |
1 | 9999
2 | 001111126
3 | 27
4 |
5 | 34789
6 | 558
7 | 1488
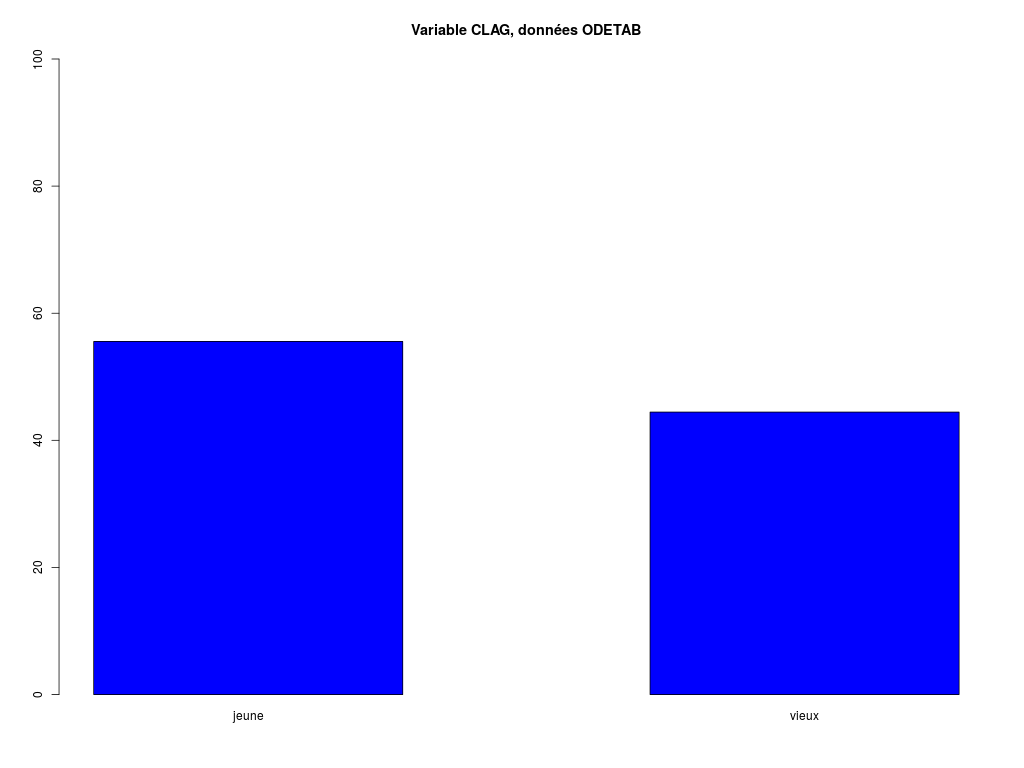
TRI A PLAT DE : Variable CLAG, données ODETAB (ordre des modalités)
jeune vieux Total
Effectif 15 12 27
Cumul Effectif 15 27 27
Frequence (en %) 56 44 100
Cumul fréquences 56 100 100
VARIABLE : Variable CLAG, données ODETAB (par fréquence décroissante)
jeune vieux Total
Effectif 15 12 27
Cumul Effectif 15 27 27
Frequence (en %) 56 44 100
Cumul fréquences 56 100 100
TRI CROISE DES QUESTIONS :
Sourd (en ligne)
Classe d'age (en colonne)
Effectifs
jeune vieux
non 15 0
oui 0 12
Effectifs avec totaux
jeune vieux Total
non 15 0 15
oui 0 12 12
Total 15 12 27
Valeurs en % du total
jeune vieux TOTAL
non 56 0 56
oui 0 44 44
TOTAL 56 44 100
On en déduit certainement que l'échantillon utilisé se compose de deux sous-groupes bien distincts, les «jeunes non sourds» et les «vieux sourds», qu'on pourrait qualifier de sous-groupes respectivement «sain» et «pathologique».
5.
Visiblement, analyser une variable QL oblige à effectuer quelques calculs et affichages systématiques, comme celui des effectifs et pourcentages par effectif décroissant, le tracé de l'histogramme des pourcentages avec un axe vertical qui va de 0 % à 100 %. Il faut utiliser plusieurs fonctions de R pour cela, notamment table(), sum(), round(), barplot()... N'y aurait-il pas moyen d'automatiser tout cela afin d'aller rapidement à l'essentiel ?
Oui, bien sûr et c'est pourquoi nous avons fait le choix du logiciel R car il est programmable. Nous fournissons à l'adresse statgh.r un ensemble de fonctions prêtes à l'emploi pour des statistiques à la française. Par exemple les résultats de l'analyse QL de l'exercice précédent ont été réalisés avec seulement trois lignes de R :
decritQLf(titreQL="Variable Sourd, données ODETAB",nomFact=odetab$Sourd,graphique=TRUE)
decritQLf("Variable CLAG, données ODETAB",odetab$CLAG,TRUE)
triCroise("Sourd",odetab$Sourd,levels(odetab$Sourd),"Classe d'age",odetab$CLAG,levels(odetab$CLAG),graphique=TRUE)
En d'autres termes, l'ensemble du traitement effectué sur ces données est donc, au final, réalisé par le code R suivant :
## ANALYSE DES DONNEES ODETAB AVEC DES FONCTIONS "ETUDIEES POUR"
# chargement des fonctions (gH) dans le fichier statgh.r
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1")
# chargement de la librarie gdata (pour lire le fichier Excel)
library("gdata")
# lecture du fichier Excel
odetab <- read.xls("odetabExtrait1.xls")
# tri à plat de la variable Sourd
decritQLf("Variable Sourd, données ODETAB",odetab$Sourd,TRUE)
# diagramme en tiges et feuilles de l'age
cats("Distribution de l'AGE")
print( stem(odetab$Age) )
# création de la variable CLAG (CLasse d'AGe)
odetab$CLAG <- factor( ifelse(odetab$Age<40,"jeune","vieux") )
# tri à plat de la variable CLAG
decritQLf("Variable CLAG, données ODETAB",odetab$CLAG,TRUE)
# tri croisé
triCroise("Sourd",odetab$Sourd,levels(odetab$Sourd),
"Classe d'age",odetab$CLAG,levels(odetab$CLAG),
graphique=TRUE
) # fin de triCroise
retour au plan de cours
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)