La difficulté vient ici du fait que les données sont dans l'onglet 2, et non pas dans l'onglet 1. Heureusement, la fonction read.xls() du package gdata a un paramètre sheet. Donc au lieu de
elf <- read.xls("elfOrthoQL3.xls")
il suffit d'écrire
elf <- read.xls("elfOrthoQL3.xls",sheet = 2)
et le tour est joué !
On aurait aussi pu s'en sortir en recopiant le fichier elfOrthoQL3.xls par exemple en elf3.xls et en venant sous Excel permuter les feuilles de calcul.
Avec Rcmdr, c'est un peu plus simple puisque le sous-menu Importer des données, sous-sous-menu depuis un fichier Excel détecte automatiquement les feuilles de données et demande de choisir celle qu'on veut importer.
1.
Dans le fichier repqual.csv, nous avions vu qu'il y avait des données manquantes pour l'AGE (repérées par NA dans les affichages de R). Comment savoir où sont ces données, sachant que le fichier fait 500 lignes et 120 colonnes, et qu'on n'a donc pas envie de chercher soigneusement à quelle ligne cela arrive. Au passage, comment trier les données sous R ? Et avec Rcmdr ?
Rcmdr ne sait pas répondre à la question de localisation des données manquantes de l'age car aucun menu n'est prévu pour cela. Avec R, détecter si une valeur est manquante se fait via la fonction is.na() et la fonction which() est adaptée à ce type de recherche :
## recherche des données manquantes pour l'AGE dans le fichier repqual.csv
repqual <- read.csv("repqual.csv")
print( which(is.na(repqual$AGE)) )
La réponse de R est 370 500 ce qui signifie que c'est à la ligne 370 et à la ligne 500 que ces données sont manquantes.
Trier les données pour trouver les données manquantes est une bonne idée puisqu'elles seront en début ou en fin d'affichage. Le tri d'un vecteur se fait avec la fonction sort() mais il faut penser à utiliser le paramètre na.last pour prendre en compte les valeurs manquantes en R :
## TRIS avec sort() POUR DES DONNEES MANQUANTES DANS UN VECTEUR
> sort(c(1,NA,2))
[1] 1 2
> sort(c(1,NA,2),na.last = TRUE)
[1] 1 2 NA
> sort(c(1,NA,2),na.last = FALSE)
[1] NA 1 2
> sort(c(1,NA,2),na.last = NA)
[1] 1 2
Trier tout un tableau est un peu plus compliqué par ce qu'il faut trier toute l'information des lignes à la fois. En général on se contente donc de trouver l'ordre des lignes correspondant au critère de tri via la fonction order() puis on affiche les données selon cet ordre. Voici ce que cela donne sur notre exemple, sachant que pour fonction order() le paramètre na.last vaut TRUE par défaut :
## TRIS avec order() POUR DES DONNEES MANQUANTES DANS UN TABLEAU
# lecture des données
repqual <- read.csv("repqual.csv")
# ordre de tri
tri <- order(repqual$AGE)
# affichage des dernières lignes
print( tail(repqual[tri,(1:5)]) )
# résultat :
X NUM CSP AGE SEX
170 3192 2 92 0
302 1741 4 92 1
336 1372 2 92 1
343 1302 4 92 0
370 1033 3 NA 1
500 NA NA NA 1
Rcmdr dispose, dans le menu Données, sous-menu Jeu de données actif d'un sous-sous-menu Trier le jeu de données actif mais le tri est assez primaire. Par exemple, le tri par ordre de courtoisie (les femmes d'abord, par age décroissant) se fait bien en R, difficilement en Rcmdr :
## TRI MULTI CRITERES, ORDRE DE COURTOISIE
## (les femmes d'abord, par age décroissant)
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL3.xls",sheet = 2)
# construction de l'index de tri
tri2 <- order(xtfrm(elf2$SEXE),xtfrm(elf2$AGE),decreasing=c(FALSE,TRUE))
# affiche partiel
extrait( elf2[tri2,] )
Extrait des données avec 5 lignes et 4 colonnes
IDEN SEXE AGE ETUD
79 M079 18 BEPC
73 M073 33 SUP
12 M012 F 11 BEPC
34 M034 F 12 BEPC
93 M093 F 13 BEPC
[...]
IDEN SEXE AGE ETUD
9 M009 H 62 SUP
23 M023 H 64 BEPC
11 M011 H 65 NR
13 M013 H 78 BAC
98 M098 M 62 BAC
2.
On décide de travailler avec une partie des données, par exemple avec juste les femmes de plus de 40 ans. Comment réaliser cette sélection de données ?
Plus généralement, on voudrait créer des sous-groupes, par exemple celui des appareillés de celui des non appareillés avant de leur appliquer un traitement. Comment procéder ?
R permet de créer des filtres vectoriels qu'on peut utiliser directement, mais fournit aussi la fonction subset() :
## CREATION DE SOUS-GROUPES AVEC R
# données ELF : lecture et dimensions
> library(gdata)
> elf <- read.xls("elfOrthoQL.xls")
> print(dim(elf))
99 4
# données ELF (extrait : fin des données)
> print(tail(elf))
IDEN SEXE AGE ETUD
94 M094 H 12 BEPC
95 M095 F 31 SUP
96 M096 F 17 BAC
97 M097 F 39 BEPC
98 M098 M 62 BAC
99 M100 F 48 SUP
## sous-ensemble des femmes de plus de 40 ans
# 1. par filtrage vectoriel direct
> flt <- (elf$SEXE=="F") & (elf$AGE>40)
> fs40 <- elf[ flt, ]
> print(tail(fs40))
IDEN SEXE AGE ETUD
55 M055 F 50 BEPC
85 M085 F 73 BAC
86 M086 F 60 BEPC
87 M087 F 49 SUP
91 M091 F 50 BEPC
99 M100 F 48 SUP
# 2. via la fonction subset
> fs40 <- subset(elf,SEXE=="F" & AGE>40)
> print(tail(fs40))
IDEN SEXE AGE ETUD
55 M055 F 50 BEPC
85 M085 F 73 BAC
86 M086 F 60 BEPC
87 M087 F 49 SUP
91 M091 F 50 BEPC
99 M100 F 48 SUP
R peut créer des sous-groupes avec la fonction split(). On peut alors appliquer des calculs à chacun des sous-groupes avec la fonction lapply() mais très souvent utiliser sapply() fournit des affichages "plus propres" parce que simplifiés :
## CALCULS SUR SOUS-GROUPES AVEC SPLIT, LAPPLY et SAPPLY
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL3.xls",sheet = 2)
# création des sous-groupes complets
elfGrps <- split(x=elf2,f=elf2$SEXE)
# affichage
print(elfGrps)
# création des sous-groupes d'ages
elfAges <- split(x=elf2$AGE,f=elf2$SEXE)
# affichage
print(elfAges)
# effectifs de chaque groupe avec lapply
eff1 <- lapply(X=elfAges,FUN=length)
print(eff1)
# effectifs de chaque groupe avec sapply
eff2 <- sapply(X=elfAges,FUN=length)
print(eff2)
# des calculs plus sophistiqués
sophi <- sapply(X=elfAges,FUN=function (x) c(length(x),mean(x),median(x)))
calcs <- data.frame(t(sophi))
names(calcs) <- c("Effectif","Moyenne","Médiane")
print(calcs)
[[1]]
IDEN SEXE AGE ETUD
73 M073 33 SUP
79 M079 18 BEPC
$F
IDEN SEXE AGE ETUD
1 M001 F 62 BEPC
3 M003 F 31 SUP
4 M004 F 27 SUP
[...]
$H
IDEN SEXE AGE ETUD
2 M002 H 60 BAC
5 M005 H 22 SUP
9 M009 H 62 SUP
[...]
$M
IDEN SEXE AGE ETUD
98 M098 M 62 BAC
[[1]]
[1] 33 18
$F
[1] 62 31 27 70 19 53 63 [...]
[61] 31 17 39 48
$H
[1] 60 22 62 65 78 20 49 [...]
$M
[1] 62
[[1]]
[1] 2
$F
[1] 64
$H
[1] 32
$M
[1] 1
F H M
2 64 32 1
Effectif Moyenne Médiane
2 25.50000 25.5
F 64 35.51562 29.5
H 32 36.28125 29.0
M 1 62.00000 62.0
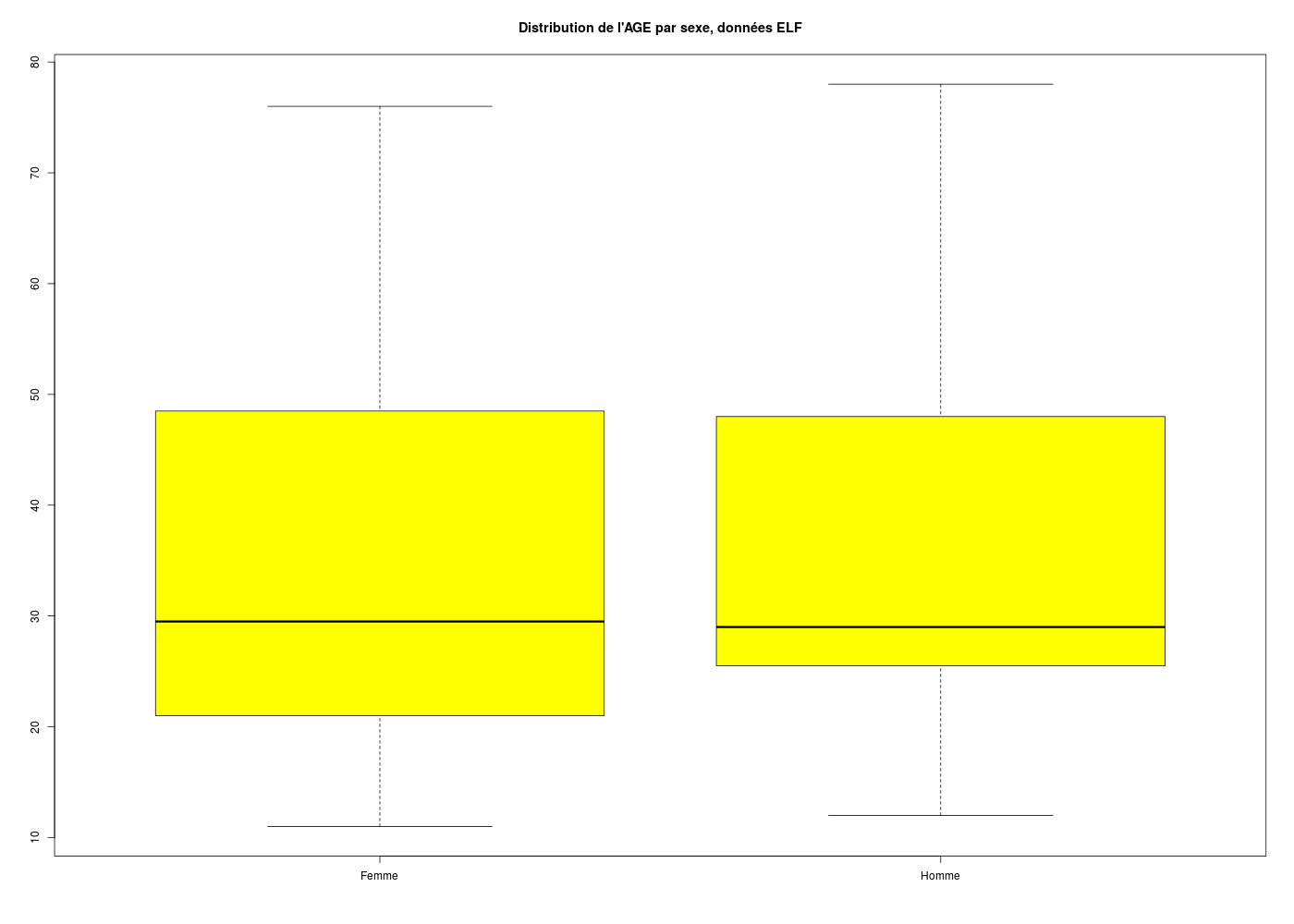
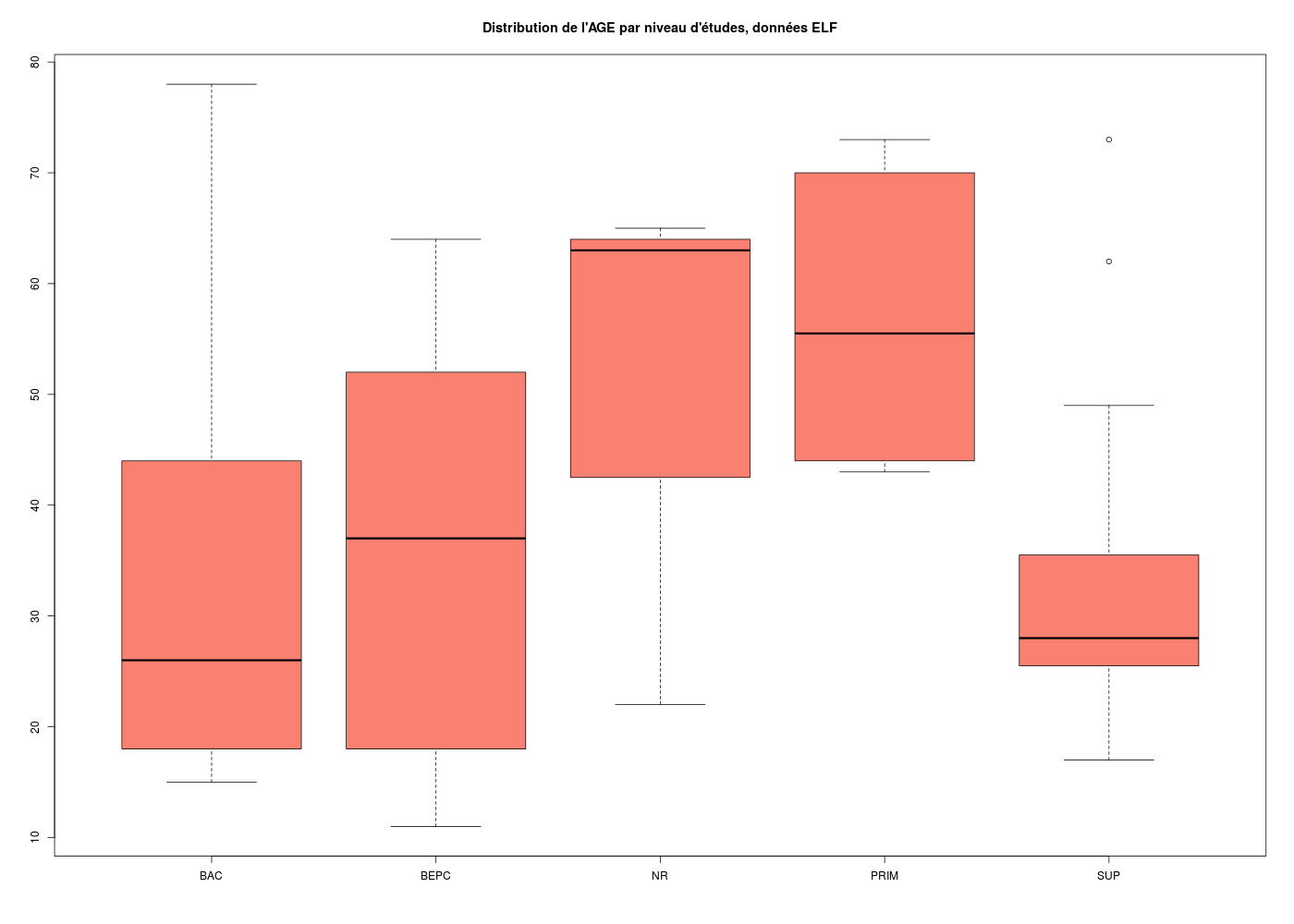
En fait, avec R, on n'a pas vraiment besoin de créer explicitement de sous-groupes, parce que R sait séparer en sous-groupes juste au moment de calculer, via la notation tilde, comme par exemple pour la création de boites à moustaches :
## GRAPHIQUES PAR SOUS-GROUPES AVEC LA NOTATION TILDE
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL.xls")
# tracé en boxplot de l'age par SEXE
levels(elf$SEXE) <- c("Femme","Homme")
boxplot(elf$AGE ~ elf$SEXE,col="yellow",main="Distribution de l'AGE par sexe, données ELF")
# tracé en boxplot de l'age par niveau d'ETUDes
boxplot(elf$AGE ~ elf$ETUD,col="salmon",main="Distribution de l'AGE par niveau d'études, données ELF")
On peut réaliser le même type de graphiques avec Rcmdr, à condition d'utiliser le menu Graphes, sous-menu Boite de dispersion à condition de cliquer sur le bouton Graphe par : afin d'indiquer SEXE ou ETUD comme critère de sous-groupe, mais sans la couleur ni le titre.
3.
Reprendre le fichier des données RONFLE et remplacer sous R les 0/1 par des modalités en lettres. On utilisera le fichier ronfle01.xls. Ajouter ensuite une variable QIMC définie selon la page du wiki à savoir :
IMC
Qualificatif
moins de 18,5
maigre
entre 18,5 et 25
normal
de 25 à 30
surpoids
plus de 30
obèse
Est-ce plus simple de réaliser ces manipulations avec Rcmdr ?
Tout ce que nous avons vu auparavant permet de répondre à l'exercice. Toutefois, la fonction transform() et sa grande soeur mutate() (du package plyr) permettent une écriture plus compacte des transformations :
## CODAGE ET RECODAGE DE DONNEES AVEC R
# lecture des données sur internet
library("gdata")
url <- "http://forge.info.univ-angers.fr/~gh/wstat/Ortho/ronfle01.xls"
ronfle <- read.xls(url)
# affichage des données avant
cat("DATA en 0/1\n")
cat("===========\n\n")
print(head(ronfle))
# recodage des variables qualitatives
ronfle$SEXE <- ifelse(ronfle$SEXE==0,"Homme","Femme")
# transform() est plus agréable à utiliser pour ce
# type de recodage :
ronfle <- transform(ronfle,
RONFLE=ifelse(RONFLE==0,"non-ronfleur","ronfleur"),
TABA=ifelse(TABA==0,"non-fumeur","fumeur")
) # fin de transform
cat("DATA en lettres (QL)\n")
cat("====================\n\n")
print(head(ronfle))
# ajout de la variable IMC et de la variabe QIMC
library(plyr)
ronfle <- mutate(ronfle,
IMC=POIDS/((TAILLE/100)^2),
QIMC=cut(IMC,breaks=c(0,18.5,25,30,100),labels=c("maigre","normal","surpoids","obèse"))
) # fin de mutate
cat("DATA avec IMC et QIMC\n")
cat("======================\n\n")
print(head(ronfle))
Voici les résultats de l'exécution de ces instructions :
DATA en 0/1
===========
IDEN AGE POIDS TAILLE ALCOOL SEXE RONFLE TABA
1 P0001 47 71 158 0 0 0 1
2 P0002 56 58 164 7 0 1 0
3 P0003 46 116 208 3 0 0 1
4 P0005 70 96 186 3 0 0 1
5 P0006 51 91 195 2 0 1 1
6 P0007 46 98 188 0 1 0 0
DATA en lettres (QL)
====================
IDEN AGE POIDS TAILLE ALCOOL SEXE RONFLE TABA
1 P0001 47 71 158 0 Homme non-ronfleur fumeur
2 P0002 56 58 164 7 Homme ronfleur non-fumeur
3 P0003 46 116 208 3 Homme non-ronfleur fumeur
4 P0005 70 96 186 3 Homme non-ronfleur fumeur
5 P0006 51 91 195 2 Homme ronfleur fumeur
6 P0007 46 98 188 0 Femme non-ronfleur non-fumeur
DATA avec IMC et QIMC
======================
IDEN AGE POIDS TAILLE ALCOOL SEXE RONFLE TABA IMC QIMC
1 P0001 47 71 158 0 Homme non-ronfleur fumeur 28.44095 surpoids
2 P0002 56 58 164 7 Homme ronfleur non-fumeur 21.56454 normal
3 P0003 46 116 208 3 Homme non-ronfleur fumeur 26.81213 surpoids
4 P0005 70 96 186 3 Homme non-ronfleur fumeur 27.74887 surpoids
5 P0006 51 91 195 2 Homme ronfleur fumeur 23.93162 normal
6 P0007 46 98 188 0 Femme non-ronfleur non-fumeur 27.72748 surpoids
Avec Rcmdr, tout se passe par des clics-souris dans les menus. Ainsi, pour passer des 0/1 aux libellés, une fois les données chargéees dans Rcmdr, il faut utiliser le menu Données, sous-menu Gérer les variables du jeu de données actif puis le sous-sous-menu Recoder des variables. Dans le panneau qui apparait, on sélectionne une variable, par exemple SEXE, puis on écrit SEXE dans la zone Nouveau nom de variable et enfin, dans les directives de recodage, on ecrit 0="Homme" et 1="Femme". Rcmdr demande ensuite de confirmer qu'on réécrit dans la variable d'origine. On fait de même pour les variables RONFLE et TABA.
Pour ajouter la variable IMC et QIMC avec Rcmdr, on utilise le sous-sous-menu Calculer une nouvelle variable. du menu Données, sous-menu Gérer les variables du jeu de données actif. Dans le panneau qui apparait, on écrit IMC dans la zone Nom de la nouvelle variable et on fournit dans la case suivante la formule de calcul, soit ici POIDS/((TAILLE/100)^2). Il ne reste plus qu'à cliquer sur OK pour réaliser le calcul.
A notre connaissance, Rcmdr ne dispose d'aucun moyen de définir la variable QIMC telle que demandée. En effet, il y a bien un sous-sous-menu Découper une variable numérique en classes mais aucune des trois méthodes de classes proposées (tailles égales, mêmes effectifs, classes naturelles) ne correspond à ce que l'on souhaite et il faut donc se rabattre sur l'écriture de l'expression R précédente avec cut().
La vidéo recode in R et la page recodage vous fourniront des compléments utiles sur le recodage de variables en R.
4.
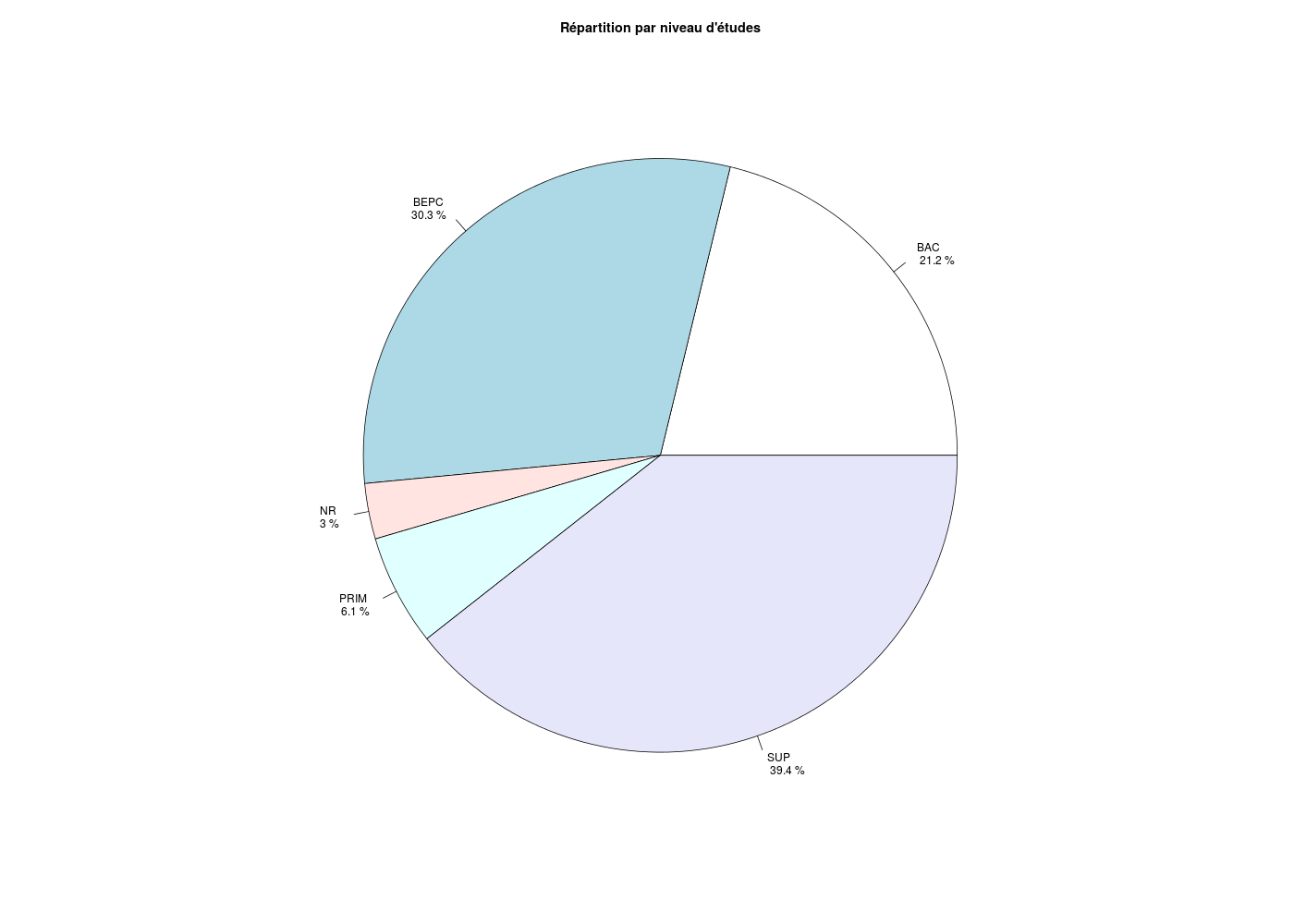
Même si les statisticiennes et les statisticiens n'aiment pas (à juste titre) ce type de représentation, comment fait-on des graphiques circulaires en R, avec labels et pourcentages, comme ci-dessous :
Un graphique circulaire se réalise via la fonction pie() du package graphics. Voici la version minimale du tracé :
## DIAGRAMME CIRCULAIRE DES NIVEAUX D'ETUDE
pie( table(elf$ETUD) )
Mettre un titre est assez simple et immédiat, le paramètre main est prévu pour cela. Par contre pour un bel affichage des labels et des pourcentages, il faut un peu plus de temps. En effet, il faut récupérer les labels, convertir les pourcentages en texte et leur ajouter le symbole pour-cent puis ajouter le caractère \n qui signifie saut de ligne. Voici le code R qui a produit le graphique de l'énoncé :
## DIAGRAMME CIRCULAIRE DES NIVEAUX D'ETUDE
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL.xls")
# calcul des pourcentages
eff <- table(elf$ETUD)
pcts <- round(100*eff/sum(eff),1)
# ajout du symbole pour-cent
pctsTxt <- paste(pcts,"%")
# préparation des labels avec saut de ligne
labTxt <- paste( names(eff),"\n",pctsTxt)
# tracé
pie(eff,main="Répartition par niveau d'études",labels=labTxt)
Cela parait sans doute moins immédiat qu'avec Excel où il suffit de cliquer, mais cela prend tout son sens si on a plusieurs variables à traiter. Avec à peine plus d'efforts on peut produire le graphique pour le sexe juste en changeant la ligne de calcul de la variable eff :
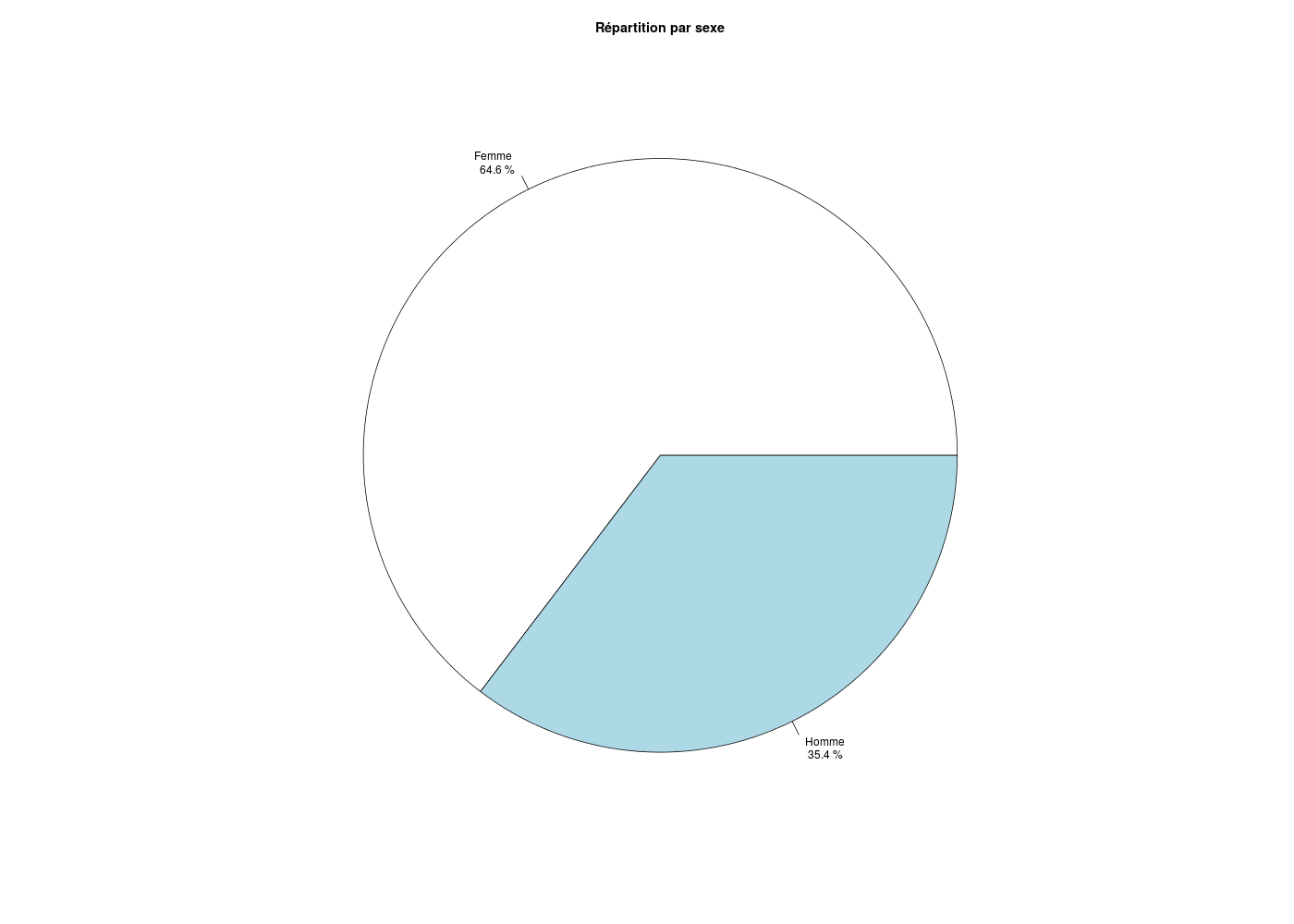
## DIAGRAMME CIRCULAIRE DE LA REPARTITION PAR SEXE
# lecture des données
library(gdata)
elf2 <- read.xls("elfOrthoQL.xls")
# calcul des pourcentages
eff <- table(elf$SEXE) ## <== seul "vrai" changement
pcts <- round(100*eff/sum(eff),1)
# ajout du symbole pour-cent
pctsTxt <- paste(pcts,"%")
# préparation des labels avec saut de ligne
labTxt <- paste( names(eff),"\n",pctsTxt)
# tracé
pie(eff,main="Répartition par sexe",labels=labTxt)
Avec encore un peu plus d'effort, on pourrait produire tous les graphiques d'un coup pour toutes les variables qualitatives avec une boucle sur leurs noms...
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)