Statistiques élémentaires avec le logiciel R
|
-- Session de formation continue pour l'université d'Angers --
|
Séance 3 : Analyse élémentaire de données qualitatives
|
1. Calculs et représentations graphiques pour les QL en dimension 1 et 2
1.1 Comment décrire une seule QL ?
Pour décrire une seule variable QL (variable qualitative), il suffit de compter les occurrences de chaque modalité, d'en faire un tableau récapitulatif et de représenter graphiquement ce tableau. Le comptage des différentes modalités se nomme tri à plat et doit se doubler du calcul des pourcentages correspondants, qu'on affiche souvent par ordre décroissant. Il va de soi qu'on affiche les labels (ou "libellés") mais qu'en aucun cas les code ne doivent apparaître. La représentation graphique associée préférée est l'histogramme des fréquences, plus apte à montrer les différences qu'un diagramme circulaire en secteurs (camemberts ou parts de gâteaux). On peut y faire figurer les comptages, les fréquences, mais les barres doivent de toutes façons être séparées car il s'agit de valeurs distinctes et discontinues. L'échelle des hauteurs doit de préférence correspondre aux pourcentages et doit en principe couvrir toute la plage de 0 à 100 % afin d'éviter des effets de zoom.
Les principales fonctions de R associées à ces calculs et représentations se nomment table() et barplot().
Exemple de code-source R pour traiter la variable SEXE du dossier ELF, fichier elf.dar :
## TRAITEMENT D'UNE VARIABLE QUALITATIVE
# 1. chargement des fonctions de statgh.r
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1")
# 2. lecture de données numériques en 0/1 pour le code-sexe
elfdata <- read.table("elf.dar",head=TRUE,row.names=1)
# 2.1 à éviter : utiliser les codes
cats("Voici ce qu'il ne faut pas faire : utiliser les codes") ;
sx <- elfdata$SEXE # ou elfdata[,"SEXE"]
# liste des modalités rencontrées
cat("Modalités rencontrées pour la variable sexe :")
print( unique(sx) )
# comptage des modalités
cat("comptages\n")
print( table(sx) )
# en pourcentage (noter la différence avec le comptage)
cat("pourcentages (arrondis)\n")
print( round(table(sx)*100/length(sx)) )
# ce qu'on tape souvent en R mais qui ne convient pas ici
cat("résumé obtenu via la fonction summary() de R\n")
print( summary(sx) )
# 2.2 construisons et analysons une vraie QL
cats("Voici ce qu'il faut faire : définir un \"facteur\" :") ;
nbind <- length(sx)
sxql <- factor(sx,levels=c(0,1), labels=c("Homme","Femme"))
print( summary(sxql) )
cat("\nTri à à plat du code-sexe dans ELF (en % pour ",nbind," personnes)\n\n")
print( round(table(sxql)*100/length(sxql)) )
# surtout pas
barplot(sx,main="Surtout pas")
# un peu mieux
barplot( table(sx) )
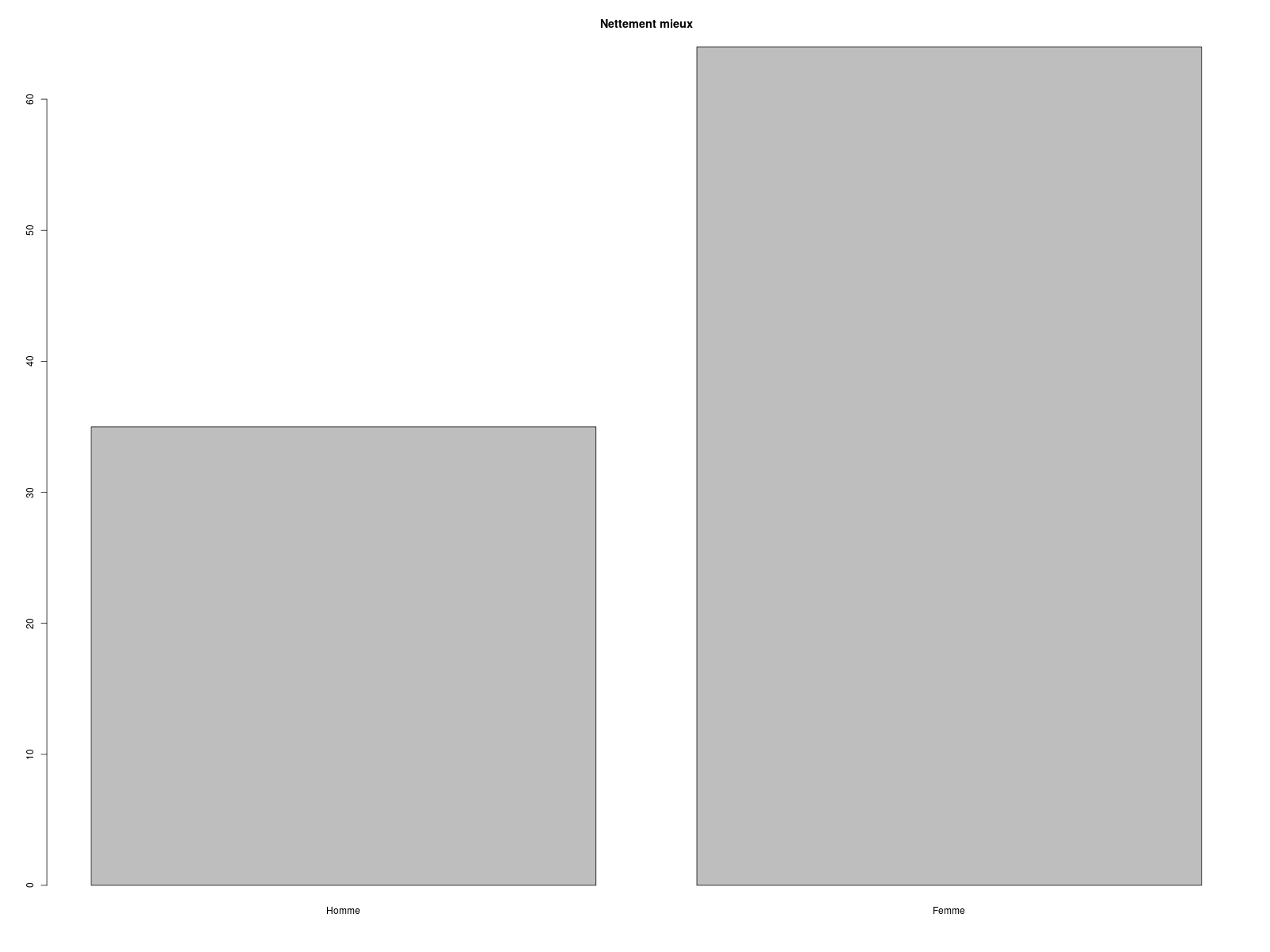
# nettement mieux
barplot( table(sxql),main="Nettement mieux" )
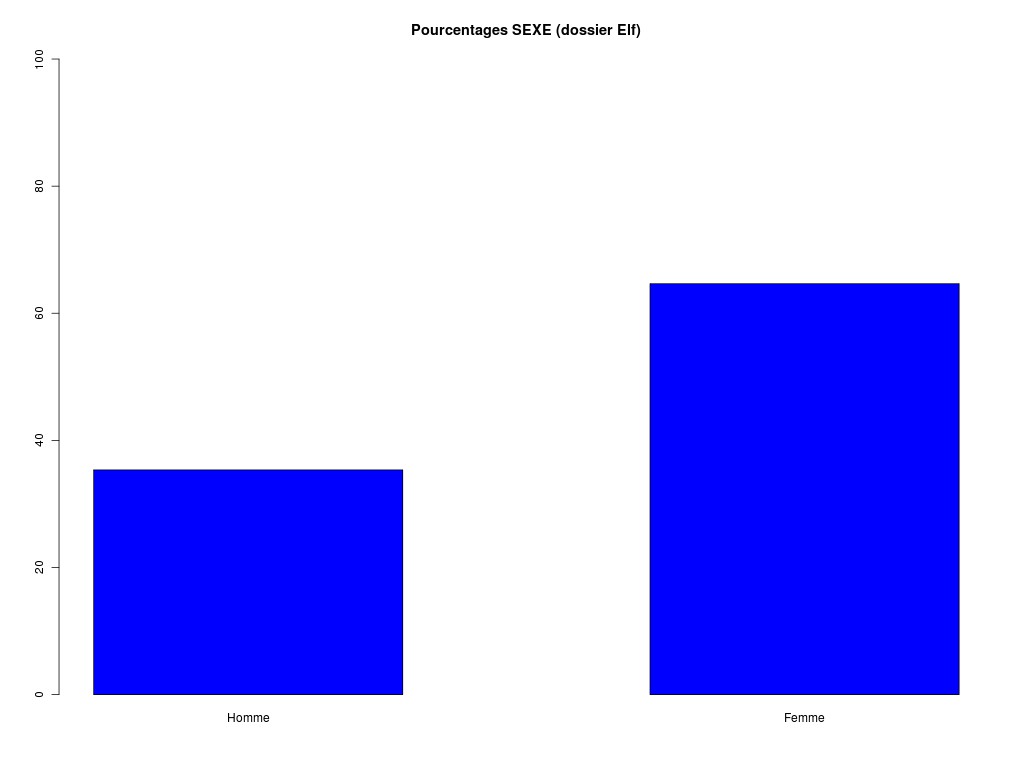
# un graphique nommé et normalisé
pcts <- table(sxql)*100/length(sxql)
barplot( pcts, ylim=c(0,100),main="Variable SEXE du dossier ELF" )
# 2.3 utilisons des fonctions "étudiées pour"
cats("Avec les focntions (gH) :") ;
decritQL(titreQL="Variable SEXE du dossier ELF",
nomVar=elfdata$SEXE,
labelMod="Homme Femme",
graphique=TRUE
) # fin de decritQL
Résultats :
Voici ce qu'il ne faut pas faire : utiliser les codes
=====================================================
Modalités rencontrées pour la variable sexe :[1] 1 0
comptages
sx
0 1
35 64
pourcentages (arrondis)
sx
0 1
35 65
résumé obtenu via la fonction summary() de R
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0000 0.0000 1.0000 0.6465 1.0000 1.0000
Voici ce qu'il faut faire : définir un "facteur" :
==================================================
Homme Femme
35 64
Tri à à plat du code-sexe dans ELF (en % pour 99 personnes)
sxql
Homme Femme
35 65
Avec les fonctions (gH)
=======================
TRI A PLAT DE : Variable SEXE du dossier ELF (ordre des modalités)
Homme Femme Total
Effectif 35 64 99
Cumul Effectif 35 99 99
Frequence (en %) 35 65 100
Cumul fréquences 35 100 100
VARIABLE : Variable SEXE du dossier ELF (par fréquence décroissante)
Femme Homme Total
Effectif 64 35 99
Cumul Effectif 64 99 99
Frequence (en %) 65 35 100
Cumul fréquences 65 100 100
Graphiques générés :
1.2 Comment décrire un couple de QL ?
Pour décrire conjointement des variables qualitatives, c'est-à-dire ensemble deux à deux, on calcule pour chaque couple de variables QL les comptages de couples de modalités, ce qui se nomme tri croisé et on affiche des histogrammes de comptages groupés, empilés ou superposés suivant ce qui est le plus « flagrant ».
Remarque sur le vocabulaire : réaliser la description d'une seule variable ou de plusieurs variables séparément, c'est effectuer une analyse univariée alors que les traiter deux à deux se nomme analyse bivariée. Enfin, une analyse multivariée prend en compte toutes les variables en même temps.
Les principales fonctions de R associées à ces calculs et représentations sont les mêmes que précédemment et se nomment donc table() et barplot().
Exemple de code-source R pour traiter les variable SEXE et ETUD du dossier ELF (fichier elf.dar) :
# lecture des données
elfdata <- lit.dar("elf.dar")
# tri croisé minimaliste
## -----------------------------------
cats("Ce qu'il ne faut pas afficher")
## -----------------------------------
print( table(elfdata$SEXE) )
print( table(elfdata$ETUD) )
print( table(elfdata$SEXE,elfdata$ETUD) )
# et ses graphiques possibles
cinqcouleurs <- c("red","green","blue","yellow","black")
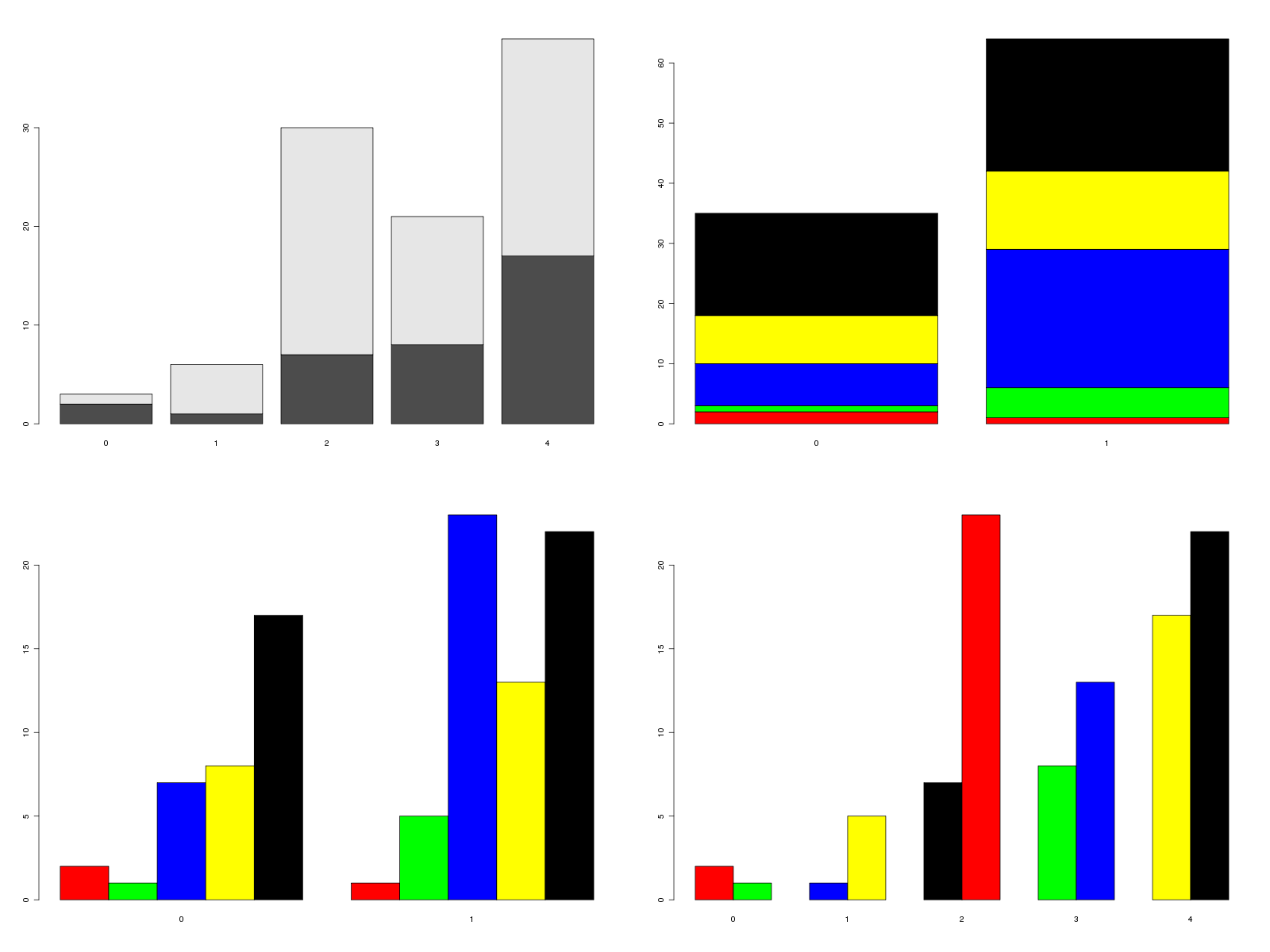
barplot(table(elfdata$SEXE,elfdata$ETUD))
barplot(table(elfdata$ETUD,elfdata$SEXE),col=cinqcouleurs)
barplot(table(elfdata$ETUD,elfdata$SEXE),col=cinqcouleurs,beside=TRUE)
barplot(table(elfdata$SEXE,elfdata$ETUD),col=cinqcouleurs,beside=TRUE)
## -----------------------------------
cats("Ce qu'il faut afficher")
## -----------------------------------
# mieux : avec des modalités
m_sexe <- c("Homme","Femme")
m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur")
sexe <- factor(elfdata$SEXE,levels=0:1,labels=m_sexe)
etud <- factor(elfdata$ETUD,levels=0:4,labels=m_etud)
titre1 <- "Tri à plat de SEXE dans le dossier ELF"
cat(titre1,"\n")
print( table(sexe) )
titre2 <- "Tri à plat de ETUD dans le dossier ELF"
cat(titre2,"\n")
print( table(etud) )
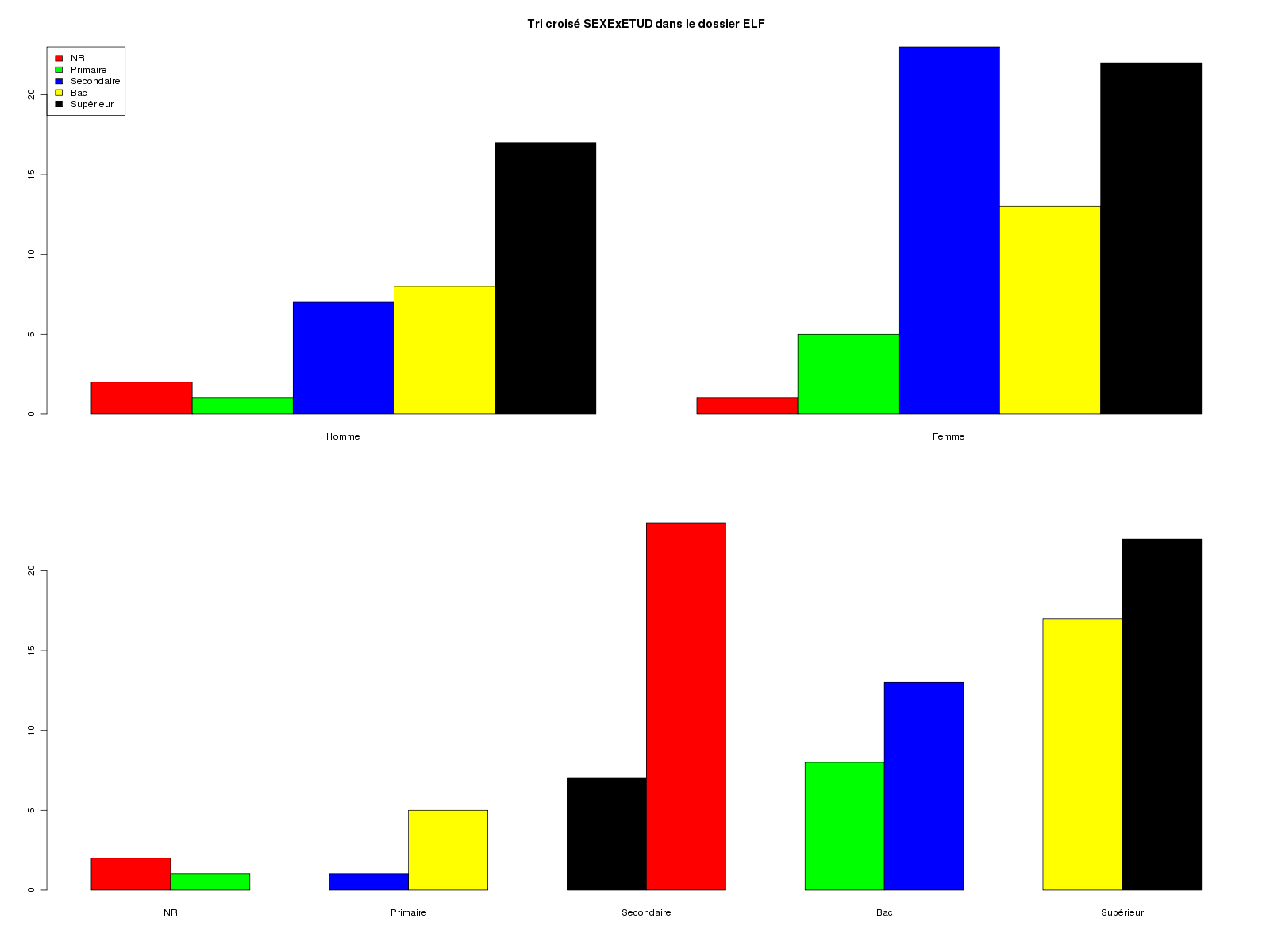
titre3 <- "Tri croisé SEXExETUD dans le dossier ELF"
cat("\n",titre3,"\n")
print( table(sexe,etud) )
barplot(table(etud,sexe),col=cinqcouleurs,beside=TRUE,
legend.text=m_etud,args.legend=list(x="topleft"),main=titre3 )
barplot(table(sexe,etud),col=cinqcouleurs,beside=TRUE)
Résultats :
Ce qu'il ne faut pas afficher
=============================
0 1
35 64
0 1 2 3 4
3 6 30 21 39
0 1 2 3 4
0 2 1 7 8 17
1 1 5 23 13 22
Ce qu'il faut afficher
======================
Tri à plat de SEXE dans le dossier ELF
sexe
Homme Femme
35 64
Tri à plat de ETUD dans le dossier ELF
etud
NR Primaire Secondaire Bac Supérieur
3 6 30 21 39
Tri croisé SEXExETUD dans le dossier ELF
etud
sexe NR Primaire Secondaire Bac Supérieur
Homme 2 1 7 8 17
Femme 1 5 23 13 22
Graphiques générés (ratés):
Graphiques générés (corrects):
Une question importante à se poser est celle des graphiques à afficher et de leur pertinence à représenter les effectifs. Ainsi le dernier graphique précédent est moins intéressant que l'avant-dernier graphique : il ne fait que [re]montrer la disproportion homme/femme (en gros 1 homme pour 3 femmes) dans chaque modalité d'étude alors que l'avant-dernier montre une différence de profil des niveaux d'études suivant le sexe.
Si on utilise les fonctions de statgh.r on dispose de plus de détails dans les calculs et de couleurs "automatiques" dans les graphiques :
# lecture de statgh.r
source("statgh.r")
# lecture des données
elfdata <- lit.dar("elf.dar")
# conversion en variables qualitatives
m_sexe <- c("Homme","Femme")
m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur")
sexe <- factor(elfdata$SEXE,levels=0:1,labels=m_sexe)
etud <- factor(elfdata$ETUD,levels=0:4,labels=m_etud)
# tri croisé
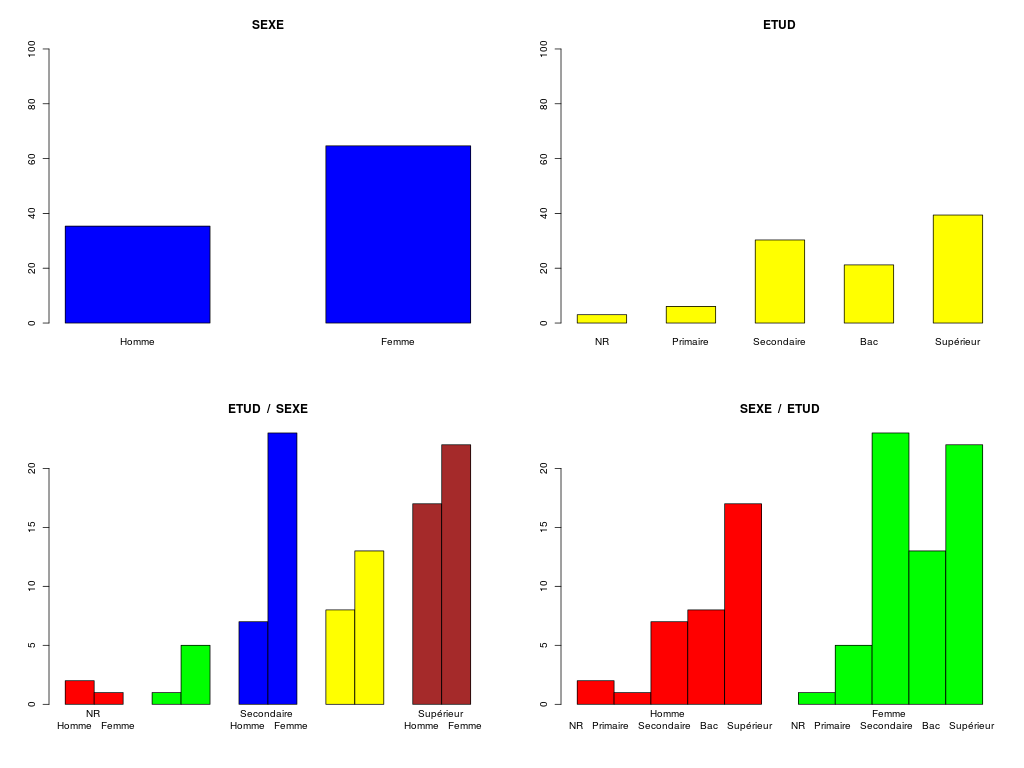
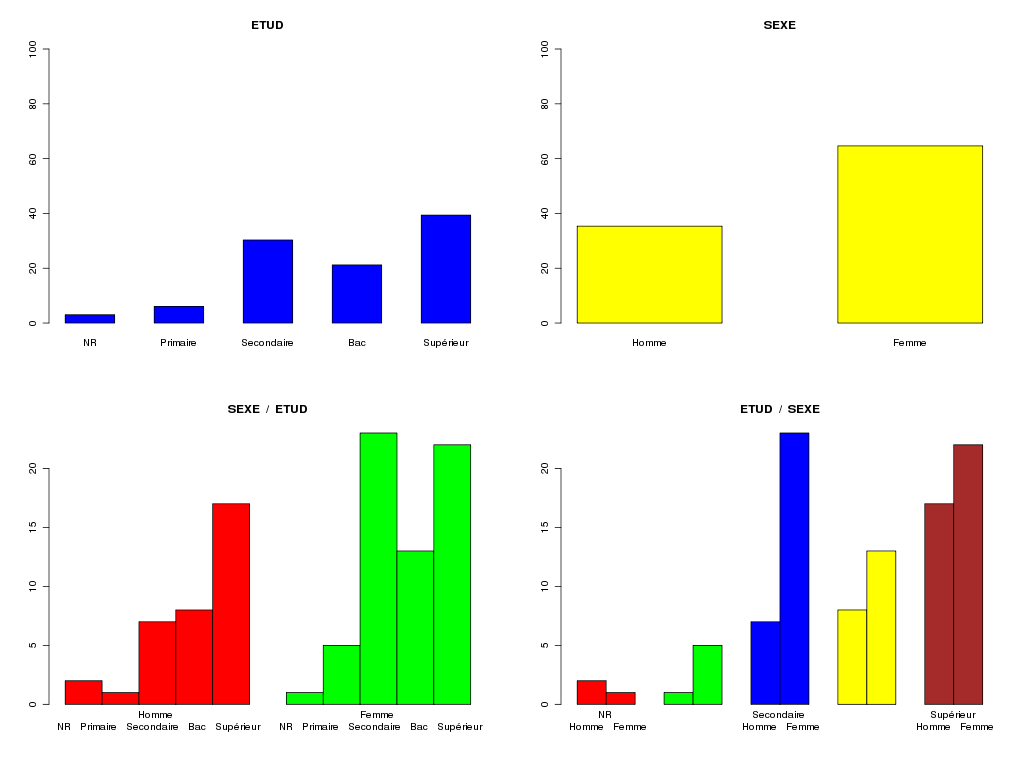
triCroise("SEXE",sexe,m_sexe,"ETUD",etud,m_etud,TRUE,"rcalcql5_1.png")
Résultats :
TRI CROISE DES QUESTIONS :
SEXE (en ligne)
ETUD (en colonne)
Effectifs
NR Primaire Secondaire Bac Supérieur
Homme 2 1 7 8 17
Femme 1 5 23 13 22
Valeurs en % du total
NR Primaire Secondaire Bac Supérieur TOTAL
Homme 2 1 7 8 17 35
Femme 1 5 23 13 22 65
TOTAL 3 6 30 21 39 100
CALCUL DU CHI-DEUX D'INDEPENDANCE
=================================
TABLEAU DES DONNEES
Homme Femme Total
NR 2 1 3
Primaire 1 5 6
Secondaire 7 23 30
Bac 8 13 21
Supérieur 17 22 39
Total 35 64 99
VALEURS ATTENDUES et MARGES
Homme Femme Total
NR 1.1 1.9 3
Primaire 2.1 3.9 6
Secondaire 10.6 19.4 30
Bac 7.4 13.6 21
Supérieur 13.8 25.2 39
Total 35.0 64.0 99
CONTRIBUTIONS SIGNEES
Homme Femme
NR + 0.832 - 0.455
Primaire - 0.593 + 0.324
Secondaire - 1.226 + 0.671
Bac + 0.045 - 0.024
Supérieur + 0.748 - 0.409
Valeur du chi-deux 5.326981
Le chi-deux max (table) à 5 % est 9.487729 ; p-value 0.2553618 pour 4 degrés de liberte
décision : au seuil de 5 % on ne peut pas rejeter l'hypothèse
qu'il y a indépendance entre ces deux variables qualitatives.
PLUS FORTES CONTRIBUTIONS AVEC SIGNE DE DIFFERENCE
Signe Valeur Pct Mligne Mcolonne Ligne Colonne Obs Th
- 1.226 23.02 % Secondaire Homme 3 1 7 10.6
+ 0.832 15.62 % NR Homme 1 1 2 1.1
+ 0.748 14.05 % Supérieur Homme 5 1 17 13.8
+ 0.671 12.59 % Secondaire Femme 3 2 23 19.4
- 0.593 11.13 % Primaire Homme 2 1 1 2.1
- 0.455 8.54 % NR Femme 1 2 1 1.9
- 0.409 7.68 % Supérieur Femme 5 2 22 25.2
+ 0.324 6.08 % Primaire Femme 2 2 5 3.9
+ 0.045 0.84 % Bac Homme 4 1 8 7.4
- 0.024 0.46 % Bac Femme 4 2 13 13.6
Graphiques générés :
2. Etude de cas : manipulations avec R sous Rstudio
2.1 Comptages, pourcentages et arrondis
R calcule en automatique les effectifs absolus (comptages) avec la fonction table() et les fréquences avec la fonction prop.table(). Pour calculer les effectifs relatifs (pourcentages), il faut multiplier par 100 et sans doute ensuite arrondir. Pour cela, on peut utiliser la fonction round() même si la fonction sprintf() est parfois plus adaptée pour formater les résultats :
## lecture des données ROSSO
# fonctions auditives centrales
# patients presbyacousiques appareillés
rosso3 <- read.table(file="rosso_mini3.dar",header=TRUE,row.names=1)
cats("Voici les données")
print( rosso3 )
cat("\n Analyse grossière de la variable A71 (age avant 71 ans)\n")
tap <- table(rosso3$A71)
tapp <- rbind(tap,100*prop.table(tap))
print(tapp)
cat("\n Présentation plus soignée\n")
tapp[2,] <- round(tapp[2,])
tapp[1,] <- sprintf("%4d",tapp[,1])
tapp[2,] <- paste(" ",tapp[2,],"%")
row.names(tapp) <- c("Comptages","Pourcentages")
print(tapp,quote=FALSE)
Voici les données
=================
AGE A71 TED L30 Htrr MLD Baddeley PASAT
P01 63 oui 10% 15 4 2 89,66 36
P02 66 oui 18% 20 20 5,5 97,06 50
P03 69 oui 2% 18 0 1,5 95,78 57
P04 69 oui 4% 22 7 4 97,19 21
P05 70 oui 22% 14 13 1 88,91 35
P06 70 oui 6% 19 16 5 94,99 56
P07 72 non 32% 24 20 1,5 102,24 57
P08 72 non 28% 26 7 2 107,5 46
P09 72 non 26% 28 0 3,5 101,43 33
P10 73 non 4% 18 20 3,5 79,42 41
P11 74 non 10% 21 18 4 100,21 40
P12 75 non 24% 22 20 5 92,14 59
P13 75 non 14% 18 10 3,5 69,47 52
P14 81 non 22% 24 14 2 84,3 54
P15 81 non 26% 27 20 3 101,97 46
P16 53 non 26% 21 20 -2 112,47 57
P17 57 non 42% 17 20 6 103,13 60
Analyse grossière de la variable A71 (age avant 71 ans)
non oui
tap 11.00000 6.00000
64.70588 35.29412
Présentation plus soignée
non oui
Comptages 11 65
Pourcentages 65 % 35 %
2.2 Tris des valeurs et des modalités
On peut avoir besoin de trier les résultats, par modalité, par pourcentage. Il vaut mieux alors utiliser la fonction order() que la fonction sort() car elle permet de trier simultanément plusieurs blocs de lignes ou de colonnes ensemble.
# données utilisées
cat("\nDonnées originales\n")
print(rosso3)
# tri des données par AGE
cat("\nDonnées par AGE croissant\n")
ord <- order(rosso3$AGE)
print( rosso3[ ord, ] )
# tri par test LAFON 30
cat("\nDonnées par LAFON30 décroissant\n")
ord <- order(rosso3$L30,decreasing=TRUE)
print( rosso3[ ord, ] )
Données originales
AGE A71 TED L30 Htrr MLD Baddeley PASAT
P01 63 oui 10% 15 4 2 89,66 36
P02 66 oui 18% 20 20 5,5 97,06 50
P03 69 oui 2% 18 0 1,5 95,78 57
P04 69 oui 4% 22 7 4 97,19 21
P05 70 oui 22% 14 13 1 88,91 35
P06 70 oui 6% 19 16 5 94,99 56
P07 72 non 32% 24 20 1,5 102,24 57
P08 72 non 28% 26 7 2 107,5 46
P09 72 non 26% 28 0 3,5 101,43 33
P10 73 non 4% 18 20 3,5 79,42 41
P11 74 non 10% 21 18 4 100,21 40
P12 75 non 24% 22 20 5 92,14 59
P13 75 non 14% 18 10 3,5 69,47 52
P14 81 non 22% 24 14 2 84,3 54
P15 81 non 26% 27 20 3 101,97 46
P16 53 non 26% 21 20 -2 112,47 57
P17 57 non 42% 17 20 6 103,13 60
Données par AGE croissant
AGE A71 TED L30 Htrr MLD Baddeley PASAT
P16 53 non 26% 21 20 -2 112,47 57
P17 57 non 42% 17 20 6 103,13 60
P01 63 oui 10% 15 4 2 89,66 36
P02 66 oui 18% 20 20 5,5 97,06 50
P03 69 oui 2% 18 0 1,5 95,78 57
P04 69 oui 4% 22 7 4 97,19 21
P05 70 oui 22% 14 13 1 88,91 35
P06 70 oui 6% 19 16 5 94,99 56
P07 72 non 32% 24 20 1,5 102,24 57
P08 72 non 28% 26 7 2 107,5 46
P09 72 non 26% 28 0 3,5 101,43 33
P10 73 non 4% 18 20 3,5 79,42 41
P11 74 non 10% 21 18 4 100,21 40
P12 75 non 24% 22 20 5 92,14 59
P13 75 non 14% 18 10 3,5 69,47 52
P14 81 non 22% 24 14 2 84,3 54
P15 81 non 26% 27 20 3 101,97 46
Données par LAFON30 décroissant
AGE A71 TED L30 Htrr MLD Baddeley PASAT
P09 72 non 26% 28 0 3,5 101,43 33
P15 81 non 26% 27 20 3 101,97 46
P08 72 non 28% 26 7 2 107,5 46
P07 72 non 32% 24 20 1,5 102,24 57
P14 81 non 22% 24 14 2 84,3 54
P04 69 oui 4% 22 7 4 97,19 21
P12 75 non 24% 22 20 5 92,14 59
P11 74 non 10% 21 18 4 100,21 40
P16 53 non 26% 21 20 -2 112,47 57
P02 66 oui 18% 20 20 5,5 97,06 50
P06 70 oui 6% 19 16 5 94,99 56
P03 69 oui 2% 18 0 1,5 95,78 57
P10 73 non 4% 18 20 3,5 79,42 41
P13 75 non 14% 18 10 3,5 69,47 52
P17 57 non 42% 17 20 6 103,13 60
P01 63 oui 10% 15 4 2 89,66 36
P05 70 oui 22% 14 13 1 88,91 35
3. Etude de cas : manipulations avec Rcmdr
3.1 Comptages, pourcentages et arrondis
Si Rcmdr connait les variables qualitatives et sait les analyser, via le menu Statistiques, sous-menu Résumés, sous-sous-menu Distributions de fréquences, les sorties fournies sont rudimentaires. Pour mémoire, on obtient directement mais sans un "bel affichage" les comptages (counts en anglais) et les pourcentages (percentages en anglais).
RcmdrMsg: [1] NOTE: R Commander Version 2.3-0: Sat Oct 1 19:49:52 2016
Version de Rcmdr 2.3-0
RcmdrMsg: [2] NOTE: Le jeu de données rosso3 a 17 lignes et 8 colonnes.
Rcmdr> local({
Rcmdr+ .Table <- with(rosso3, table(A71))
Rcmdr+ cat("\ncounts:\n")
Rcmdr+ print(.Table)
Rcmdr+ cat("\npercentages:\n")
Rcmdr+ print(round(100*.Table/sum(.Table), 2))
Rcmdr+ })
counts:
A71
non oui
11 6
percentages:
A71
non oui
64.71 35.29
3.2 Tris des valeurs et des modalités
Comme indiqué juste au-dessus, les sorties de Rcmdr sont rudimentaires. Donc difficile de gérer quoi que ce soit. Il y a bien un menu Trier mais il ne s'applique qu'au tri des données actives...
4. Mise en forme des résultats et interprétation
4.1 Analyse de toutes les variables QL et mise en forme des résultats
S'il est assez simple de décrire une variable QL, passer en revue toutes les variables QL d'un dossier peut se révéler fastidieux. Il est pourtant obligatoire de toutes les analyser. Analyser une QL produit tout un [petit] tableau de comptages et pourcentages, donc passer en revue tous les tableaux de tris à plat oblige à consulter plein de petits tableaux. Il est préférable, même si cela prend du temps, de construire un grand tableau récapitulatif qui fournira une vision d'ensemble.
Pour décrire plusieurs variables QL séparément, il faut recourir à un tableau résumé des fréquences et pourcentages, que nous conseillons de construire comme suit : ce tableau contient sur chaque ligne les plus forts pourcentages des modalités d'une même variable ; les lignes du tableau sont triées par ordre décroissant suivant le mode c'est-à-dire suivant la valeur du plus fort pourcentage (voir l'exemple ci-dessous pour mieux comprendre comment est constitué le tableau). S'il est licite et conseillé de tracer tous les histogrammes de fréquence, on prendra soin à utiliser les mêmes échelles afin de permettre une comparaison visuelle des comptages.
Exemple de code-source R pour traiter les variable SEXE et ETUD du dossier ELF (fichier elf.dar) :
## analyse de plusieurs QL avec tableau récapitulatif bien structuré
# définition des matrices de modalités
elfCOLQL <- c(2,5)
elfQLm <- matrix(nrow=length(elfCOLQL),ncol=3)
# col 1 : intitulé court
# col 2 : texte de la question
# col 3 : modalités concaténées avec le symbole | via la fonction lstMod
# remplissage des matrices de modalités
elfQLm[1,1] <- c(" SEXE ")
elfQLm[1,2] <- c(" Sexe de la personne")
elfQLm[1,3] <- lstMod( m_sexe )
elfQLm[2,1] <- c(" ETUD ")
elfQLm[2,2] <- c(" Niveau d'études ")
elfQLm[2,3] <- lstMod( m_etud )
allQL(elfdata,elfQLm,elfCOLQL)
Résultats :
TABLEAU RECAPITULATIF DES VARIABLES QUALITATIVES
Intitulé Question
-------- --------
SEXE Sexe de la personne
ETUD Niveau d'études
Affichage par mode décroissant puis par effectifs décroissants
SEXE 65 % Femme 35 % Homme
ETUD 39 % Supérieur 30 % Secondaire 21 % Bac
La lecture d'un tel tableau de haut en bas puis de gauche à droite permet de découvrir rapidement quelles variables sont les plus "tranchées", voire majoritaires alors que les variables du bas du tableau correspondent aux variables les plus «neutres» parce que toutes les modalités ont soit toutes les mêmes valeurs soit par ce qu'elles n'ont toutes que des petits pourcentages.
4.2 Interprétation des comptages et des pourcentages
Comme d'habitude en statistiques, il faut commencer par paraphraser de façon «intelligente» les résultats les plus flagrants. Inutile donc de dire «la proportion de personnes appareillées est de 70 %» si le tableau des résultats contient la valeur 70 %. Il faut plutôt se renseigner et savoir si ont peut écrire que ce taux est assez faible, normal, fort, anormalement élevé...
Considérons par exemple le tableau suivant (déjà trié selon des "critères efficaces") :
| ETHNIE |
Blanche |
440 |
82 % |
|
Autre |
67 |
13 % |
|
Hispanique |
27 |
5 % |
| Effectif total |
534 |
100 % |
Avec un peu de réflexion, il doit sans doute être possible de le commenter ainsi :
Pour ce grand effectif de 534 personnes étudiées, une très grande majorité (82 %) de la population est blanche.
La population hispanique (5 %) est nettement moins présente que les autres races (13 %).
Un certain nombre d'habitudes rédactionnelles (de bon sens) sont faciles à acquérir avec un peu de réflexion.
Tout d'abord il faut s'abstraire du domaine technique pour viser une compréhension maximale. Cela signifie qu'il faut rédiger en termes simples, compréhensibles par tous. Le nombre total de personnes est sans doute une expression plus facile à comprendre que le terme effectif de l'échantillon, employer comptages et pourcentages est plus usuel que effectifs absolus et relatifs.
S'il n'est bien sûr pas possible de supprimer les termes techniques du domaine, il est souhaitable de les simplifier afin de raccourcir les phrases. Prenons l'exemple du poster de Balcon et al. (.copie locale) :

après avoir introduit l'acronyme TED, l'usage systématique de TED évite de répéter dans chaque phrase de résultat l'expression test d'écoute dichotique.
La rédaction est un art difficile. On peut évidemment utiliser des techniques rapides d'analyse, comme séparer les variables à modalités majoritaires de celles à modalités minoritaires, mais la qualification des variables et des modalités ne peut se faire qu'au prix d'une certaine réflexion. On peut parler de tendance consensuelle globale, mais cela n'a sans doute pas le même sens que celui d'une convergence fortement marquée. Il est possible que des communautés particulières, même dans le petit monde de l'orthophonie, certains usages lexicaux ou linguistiques aient cours, et l'on se doit de les connaître.
En particulier, on se méfiera des termes statistiques et communs généraux. Ainsi la majorité se définit légalement par «plus de 50 %». On peut donc parler de majorité pour 51 % comme pour 98 %, mais ces deux pourcentages n'expriment pas du tout la même réalité. C'est pourquoi, comme dans les rédactions précédentes, il est classique d'indiquer les pourcentages entre parenthèses après les qualificatifs employés.
Petits compléments : on peut générer des valeurs pseudo-aléatoires pour des QL avec les fonctions runif()
5. Les points essentiels à retenir
-
Avant de commencer l'analyse des QL, il faut s'assurer que l'on maîtrise le sens des modalités et qu'il ne reste plus aucun code numérique ou caractère.
-
Les analyses de QL se nomment tris à plat, tris croisés et correspondent aux comptages absolus et relatifs, soit encore, aux effectifs et aux pourcentages.
-
Il est d'usage d'ordonner les résultats par pourcentage décroissant et de distinguer les variables avec une modalité majoritaire.
-
On double les calculs par des représentations graphiques nommées histogrammes des fréquences, à tracer avec des axes allant de 0 à 100 %.
-
Pour traiter des QL avec R et Rcmdr, il faut que les colonnes de données soient définies comme des facteurs. Une façon simple d'y arriver est de fournir des données texte en entrée car R convertit en QL toutes les données texte.
exercices : énoncés solutions liens : lexique des fonctions vues retour au plan de cours
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)