Statistiques élémentaires avec le logiciel R
|
-- Session de formation continue pour l'université d'Angers --
|
Séance 2 : Préparation, vérification et restructuration de données
|
1. Lecture de fichiers textes et de fichiers Excel avec R
1.1 Gestion attentive des données
Dans la séance 1 nous avons insisté sur la notion de donnée, qualitative ou quantitative, et sur la notion de protocole. Pour bien traiter les données, il faut être capable de les visualiser, de les vérifier, de les transformer si nécessaire. Par exemple on peut imaginer avoir à recoder en homme/femme (à moins que ce ne soit en femme/homme) des données en 0/1, on peut avoir besoin de recoder en classes d'ages junior/senior des ages exprimés en années. Tout cela demande de maîtriser la lecture des données, leur vérification, leur gestion.
Il ne faut surtout pas sous-estimer cette phase de data management parce que c'est une phase essentielle, voire cruciale. Ainsi, se rendre a posteriori qu'il y a des erreurs de saisie et qu'on a une valeur de "37 ans" au lieu de "73 ans" fausse considérablement la moyenne, donc la plupart des calculs. Ne pas avoir indiqué à l'ordinateur qu'une variable est qualitative aboutit au fait que l'ordinateur se croira en droit de calculer des moyennes de codes, ce qui est tout simplement absurde.
1.2 Visualisation et lecture de données, données manquantes
Même si Excel (ou son équivalent libre) n'est pas un "bon" logiciel pour les analyses statistiques justement par ce qu'il ne permet pas de distinguer les variables qualitatives des variables quantitatives, Excel est un outil "correct" pour visualiser, voire éditer les données lorsque le volume de données n'est pas trop important. En effet, Excel charge les données en mémoire et les affiche. C'est donc très pratique si tout l'écran n'est pas pris par l'affichage des données. Essayez par exemple de consulter les fichiers simple.xls et repQual.xls avec Excel. Dans le premier cas, c'est assez facile. Dans le second, cela relève de l'impossible. Au passage, savez-vous comment on va rapidement en fin de fichier pour consulter les dernières valeurs ?
Même s'il y a beaucoup de données, nous vous conseillons de systématiquement regarder les données, ne serait-ce que pour vous faire une idée du contenu des colonnes. On découvre parfois qu'il y a des "trous" ou "cases vides", ce qui donne lieu à des données manquantes dont la gestion est toujours problématique. Il peut aussi arriver que les données soit fournies au format texte (extension .TXT) ou dans un format spécial, par exemple avec des virgules ou des points-virgules comme séparateur (extension .CSV ou .CSV2). Excel sait en principe les lire, les convertir, mais pas aussi bien que R avec toutes ses fonctions read.* et surtout toutes ses options de lecture. Voir par exemple l'aide de read.table().
2. Vérifications élémentaires de données QL et QT (plages de variation, comptage de modalités)
2.1 Unités et plages de variation
Après avoir repéré les variables quantitatives -- qui doivent être uniquement numériques ou vides, il convient de s'assurer l'on maîtrise les unités et les valeurs usuelles des variables, ainsi que les minima et maxima "légaux". Par exemple, la variable LAFON correspond au test phonétique de LAFON. Est-ce que la valeur 37 est acceptable ? Au niveau du questionnaire APHAB (Abreviated Profil of Hearing Aid Benefit), peut-on avoir les valeurs 0 % et 100 %? Afin de pouvoir vérifier les données, il est donc important de trouver rapidement les plus petites valeurs et les plus grandes valeurs, voire de trier afin de contrôler tout cela.
Attention : en cas de donnée(s) manquante(e)s les valeurs "vides" se retrouvent parfois considérées comme les plus petites valeurs ou les plus grandes valeurs.
Le logiciel R dispose d'une fonction nommée summary() qui est capable de renseigner rapidement sur une ou plusieurs variables numériques -- ce qui suppose qu'il s'agit bien de variables quantitatives. Voici un exemple d'utilisation :
# lecture des données au format CSV
> repq <- read.csv("repqual.csv")
# résumé de l'AGE
> summary(repq$AGE) # ou summary(repq[,"AGE"])
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.00 41.00 51.50 53.92 71.00 92.00 2
Au passage, voyez-vous les «incohérences dans ces données d'age» ? Les aviez-vous détectées lors de la visualisation sous Excel du fichier repqual.csv ?
2.2 Comptages et libellés des modalités
La fonction summary() présentée dans la section précédente s'applique aussi aux données qualitatives :
# chargement du package gdata (pour la fonction read.xls)
> library("gdata")
# lecture des données
> elf <- read.xls("elfOrthoQL2.xls",na.strings = "")
# résumé de la variable SEXE
> summary(elf$SEXE)
F H M NA's
64 32 1 2
Cette fonction summary() est préférable à la fonction table() qui n'affiche pas par défaut le décompte des valeurs manquantes :
# comptages des modalités de la variable SEXE, données ELF
> table(elf$SEXE)
F H M
64 32 1
> table(elf$SEXE,useNA="always")
F H M <NA>
64 32 1 2
Si une variable qualitative est codée numériquement, il ne faut jamais faire référence explicitement à ces codes. Lorsque les libellés sont longs (voir ci-dessous), il faut trouver une «façon propre» de nommer les modalités, avec un sigle, une abbréviation et ne pas oublier de fournir la table de correspondance :
Codage et modalités de la variable ETUD du dossier ELF
======================================================
Code Libellé Modalité
0 Sans Sans diplome déclaré
1 Prim Niveau primaire
2 Bepc Niveau secondaire avant la seconde
3 Bac Niveau secondaire après la seconde
4 Sup Niveau d'études supérieures
Au passage, voyez-vous là encore les «incohérences des données» dans ce fichier elfOrthoQL2.xls ?
2.3 Que faire des données manquantes ?
Cette question est délicate. Dans l'absolu, il vaudrait mieux éviter d'avoir des données manquantes. Lorsqu'on utilise un questionnaire rempli en présentiel, disons pour un mémoire de stage, on doit être capable de ne pas en avoir. Si par contre les données sont obtenues de façon externe (sondage sur le Web, par exemple), on peut envisager trois stratégies. La première consiste à supprimer toutes les lignes avec des données manquantes, à condition d'avoir suffisamment de données, bien sûr. La deuxième vient remplacer les valeurs manquantes par une valeur "cohérente" avec les autres données de la variable (moyenne ou médiane pour une variable quantitative, mode pour une variable qualitative). La troisième stratégie consiste à ne rien faire a priori mais à gérer dans chaque calcul les valeurs manquantes (par exemple : omettre temporairement ces valeurs pour le calcul de la moyenne).
3. Filtrage vectoriel, création de sous-groupes et recodages
3.1 Filtrage et sous-groupes
On a parfois besoin de travailler sur un sous-groupe, comme celui des hommes de plus de 60 ans. R permet d'extraire des données avec la fonction subset(). Voici un exemple :
# données ELF : dimensions
> print(dim(elf))
99 4
# données ELF (extrait : fin des données)
> print(tail(elf))
IDEN SEXE AGE ETUD
94 M094 H 12 BEPC
95 M095 F 31 SUP
96 M096 F 17 BAC
97 M097 F 39 BEPC
98 M098 M 62 BAC
99 M100 F 48 SUP
# sous-ensemble des hommes de plus de 60 ans
> print( h60 <- subset(elf,SEXE=="H" & AGE>60) )
IDEN SEXE AGE ETUD
9 M009 H 62 SUP
11 M011 H 65 NR
13 M013 H 78 BAC
23 M023 H 64 BEPC
3.2 Recodage et discrétisation
Pour recoder une variable qualitative, il suffit de changer ce que R nomme les levels de la variable :
# lecture des données avec QL
> elfQL <- read.xls("elfOrthoQL.xls")
# affichage des données (extrait)
> print(head(elf))
IDEN SEXE AGE ETUD
1 M001 F 62 BEPC
2 M002 H 60 BAC
3 M003 F 31 SUP
4 M004 F 27 SUP
5 M005 H 22 SUP
6 M006 F 70 PRIM
# recodage en homme/femme
> levels(elfQL$SEXE) <- c("Femme","Homme")
# nouvel affichage des données (extrait)
> print(head(elf))
IDEN SEXE AGE ETUD
1 M001 Femme 62 BEPC
2 M002 Homme 60 BAC
3 M003 Femme 31 SUP
4 M004 Femme 27 SUP
5 M005 Homme 22 SUP
6 M006 Femme 70 PRIM
Par contre, pour coder une variable quantitative, ce qu'on nomme discrétisation, on peut passer par les fonctions ifelse() et cut() :
# lecture des données avec QT
> elf <- read.xls("elfOrtho.xls")
# discrétisation avec la fonction ifelse()
> elf$ageQL <- ifelse(elf$AGE<20,"jeune","vieux")
> print(tail(elf[,c("AGE","ageQL")]))
AGE ageQL
94 12 jeune
95 31 vieux
96 17 jeune
97 39 vieux
98 62 vieux
99 48 vieux
# discrétisation avec la fonction cut()
> elf$clAGE <- cut(elf$AGE,breaks =c(0,20,100) )
> tail(elf[,c("AGE","clAGE")])
AGE clAGE
94 12 (0,20]
95 31 (20,100]
96 17 (0,20]
97 39 (20,100]
98 62 (20,100]
99 48 (20,100]
4. Applications concrètes à des données réelles, tracés élémentaires (axes et couleurs)
4.1 Tracés élémentaires
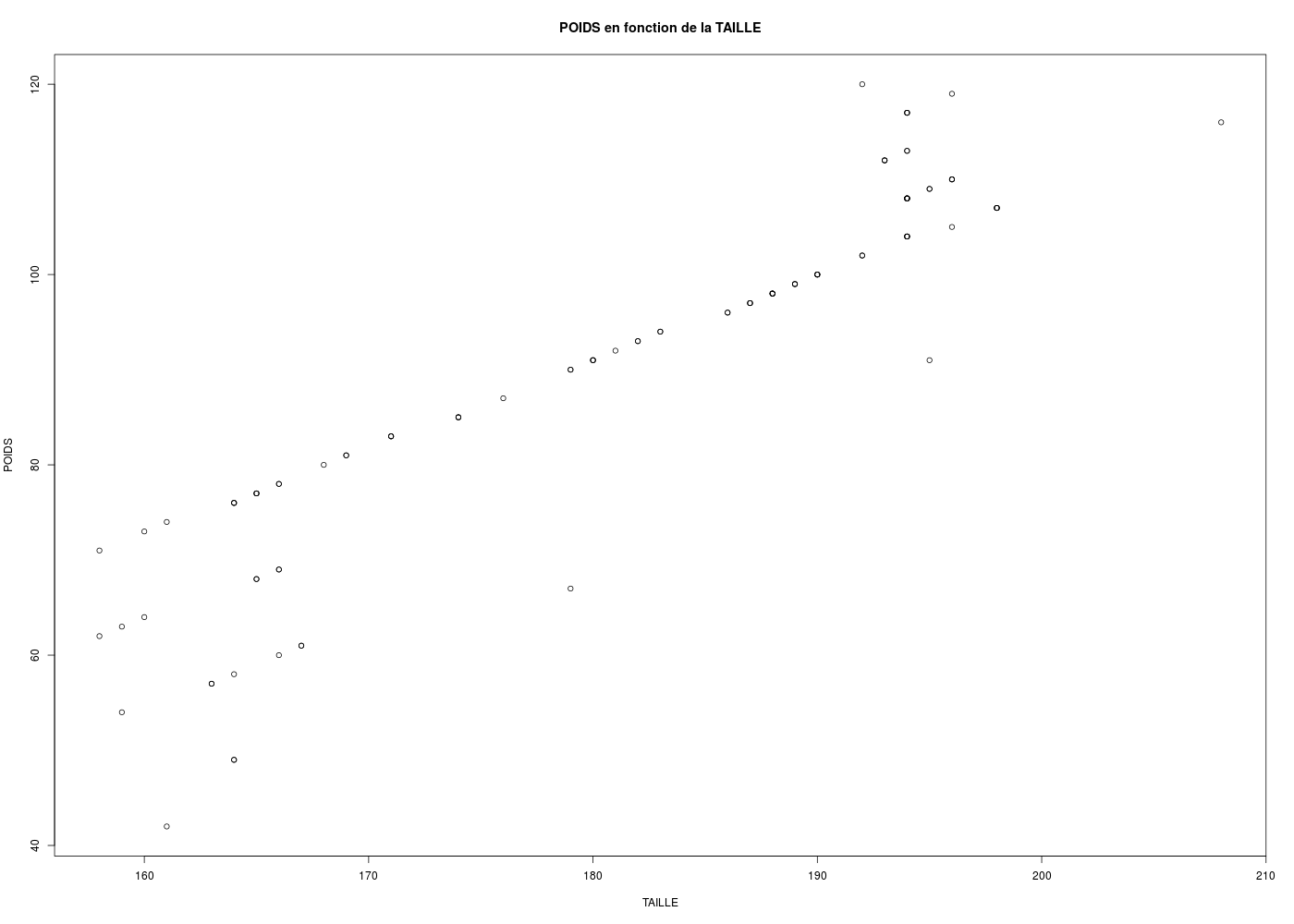
Une façon simple de vérifier les données, lorsqu'elles sont un peu nombreuses, consiste à les représenter graphiquement. Par exemple, pour nos données RONFLE, tracer le poids en fonction de la taille se résume à l'appel de la fonction plot() :
# lecture des données sur Internet
url <- "http://www.info.univ-angers.fr/pub/gh/Datasets/ronfle.dar"
ronfle <- read.table(url,header=TRUE,row.names=1)
# début des données (pour vérification)
print(head(ronfle))
# tracé du poids en fonction de la taille
plot(ronfle$POIDS~ronfle$TAILLE,main="POIDS en fonction de la TAILLE")
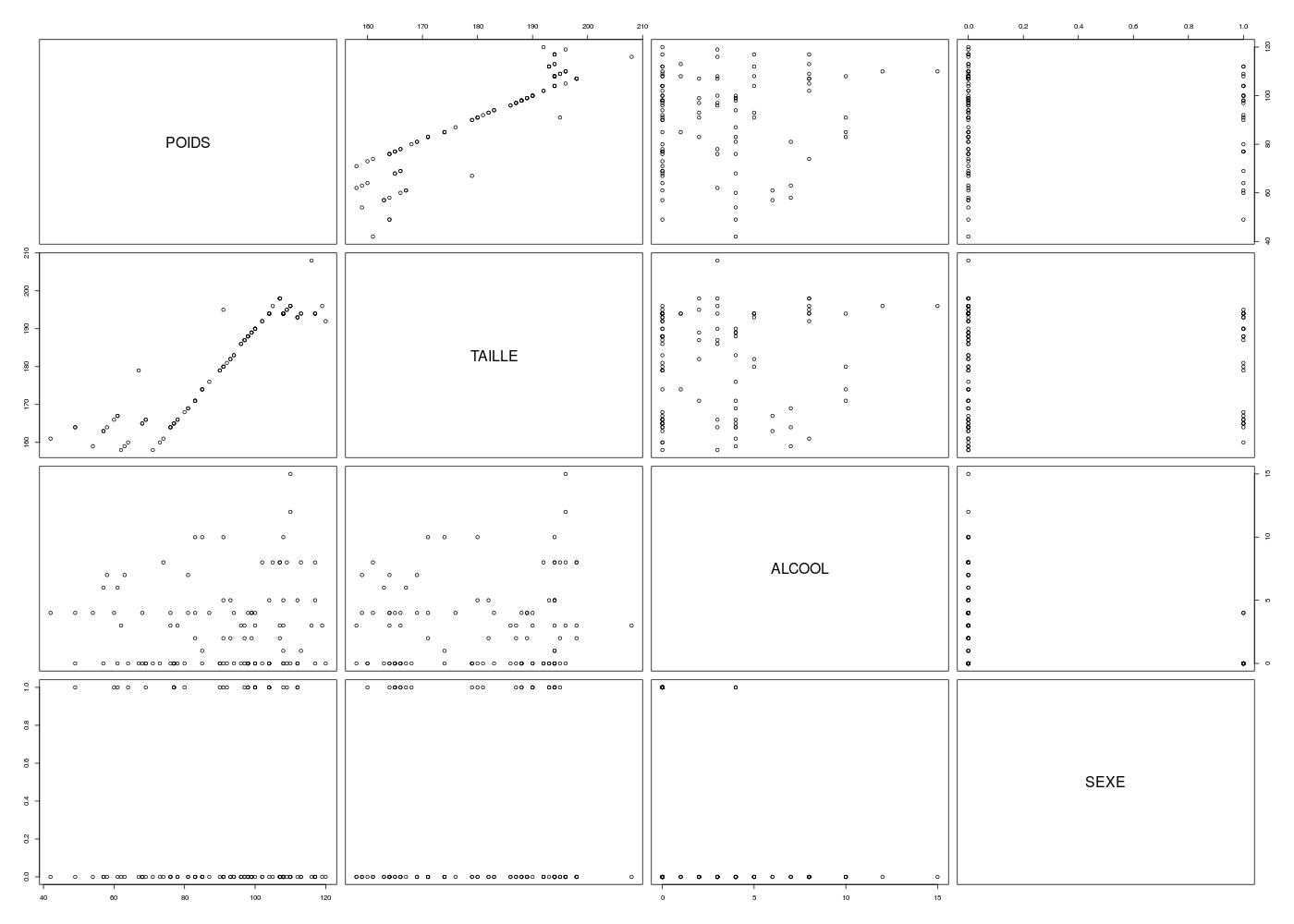
R sait également fournir un tracé par paires de plusieurs variables à la fois à l'aide de la fonction pairs() :
pairs( ronfle[,(2:5)] )
4.2 Choix des axes, des symboles et des couleurs
Contrairement à Rcmdr, R est très riche en graphiques et en option graphiques. On pourra consulter notre page introR3 et le site R graphical manual pour s'en rendre compte.
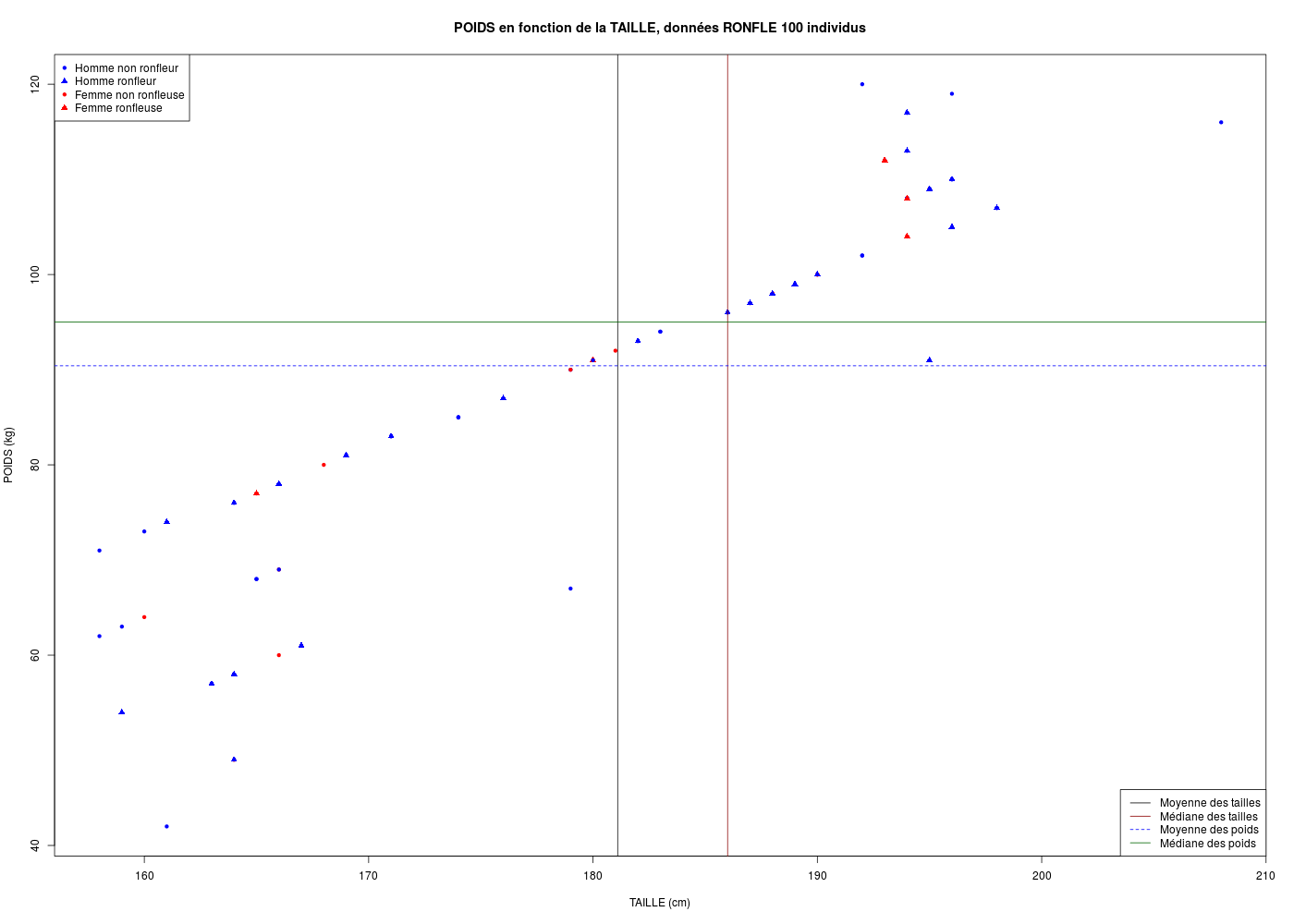
Par contre il faut y passer beaucoup de temps et bien lire les documentations pour s'en sortir. Ainsi, reprenons le tracé le poids en fonction de la taille, avec des ronds et des carrés pour les ronfleurs et les non-ronfleurs, en bleu pour les hommes et en rouge pour les femmes, soit le tracé suivant avec sa légende, où nous avons ajouté quelques droites intéressantes :
Le code R correspondant -- sans doute incompréhensible pour l'instant et c'est normal qu'il le soit pour vous -- est :
# tracé du poids en fonction de la taille
# avec indication homme/femme en bleu/rouge
# et ronfleur/non ronfleur en rond/carré
attach(ronfle)
titre <- paste("POIDS en fonction de la TAILLE, données RONFLE",nrow(ronfle),"individus")
plot(POIDS~TAILLE,
main=titre,
col=ifelse(SEXE==0,"blue","red"),
pch=ifelse(RONFLE==0,20,17),
xlab="TAILLE (cm)",
ylab="POIDS (kg)"
) # fin de plot
legend(
x="topleft",
legend=c("Homme non ronfleur","Homme ronfleur","Femme non ronfleuse","Femme ronfleuse"),
pch=c(20,17,20,17),
col=c("blue","blue","red","red")
) # fin de légende
abline(v=mean(TAILLE),col="black")
abline(v=median(TAILLE),col="darkred")
abline(h=mean(POIDS),col="blue",lty=2)
abline(h=median(POIDS),col="darkgreen")
legend(
x="bottomright",
legend=c("Moyenne des tailles","Médiane des tailles","Moyenne des poids","Médiane des poids"),
lty=c(1,1,2,1),
col=c("black","darkred","blue","darkgreen")
) # fin de légende
detach(ronfle)
Il ne faut pas s'inquiéter de la longueur du code ni des instructions utilisées, vous les apprendrez au fur et à mesure des séances.
5. Les points essentiels à retenir
-
Il faut toujours faire très attention aux données, car les fichiers parfaits n'existent pas.
-
Certaines données incorrectes peuvent remettre en cause tous les résultats.
-
Les données manquantes perturbent les calculs et la démarche statistique.
-
Connaître la plage de variation des données QT permet rapidement de s'assurer de la qualité des données QT.
-
Si les variables QL sont codées numériquement, il faut impérativement leur associer des libellés texte et les transformer en facteurs pour R.
-
Représenter graphiquement les données, même sommairement, permet souvent de voir des tendances.
-
R et Rcmdr ont toute une panoplie de fonctions pour lire des données, les résumer et les représenter graphiquement, que ce soit pour l'ensemble des données ou pour des sous-groupes.
exercices : énoncés solutions liens : lexique des fonctions vues retour au plan de cours
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)