![]()
![]()
|
Solutions pour la séance numéro 1 (énoncés)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 1
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Solutions pour la séance numéro 1 (énoncés)
L'analyse d'une QT (variable quantitative) se fait à l'aide de résumés statistiques de tendance centrale (moyenne, médiane) et de dispersion (écart-type, coefficient de variation (cdv), quartiles, distance inter quartiles...) sans oublier la taille de l'échantillon (nombre de valeurs) ainsi que le minimum et le maximum pour vérification (sans interprétation statistique). La plupart des logiciels statistiques ne permettent pas d'indiquer les unités utilisées, ce qui est très dangereux : pour des valeurs en kg, la variance est en kg^2 et le cdv en %, d'où des risques de confusion possibles. Les graphiques associés sont la courbe des données (quand elles sont peu nombreuses), l'histogramme de fréquences par classe, le diagramme en tige et feuilles (stemleaf), la boite à moustache (boxplot), le diagramme en haricot (ou en violon) et la courbe de densité.
Les fonctions R associées sont :
Taille length() Moyenne mean() Médiane median() Variance var() Ecart type sd() Quantile quantile() Minimum min() Maximum max()
Courbe (lignes) plot() Points supplémentaires points() Ligne supplémentaire abline() Courbes multiples pairs() Histogramme de classes hist() Histogramme d'effectifs barplot() Boite à moustache boxplot() Diagramme tige et feuille stem() Pour réaliser l'analyse conjointe de deux QT, on étudie la normalité des distributions puis on calcule le coefficient de corrélation linéaire, les coefficients a et b du modèle linéaire. Au niveau des graphiques, on trace une QT en fonction de l'autre (diagramme de dispersion ou scatterplot) avec éventuellement la droite de régression linéaire. Les fonctions R associées pour le calcul sont nommées cor() et lm() et plot(), points(), lines(), text() et legend() pour le tracé.
Excel dispose d'un certain nombre de fonctions statistiques de base. En voici une grande partie :
AVERAGEA LOI.NORMALE BETA.INVERSE LOI.NORMALE.INVERSE CENTILE LOI.NORMALE.STANDARD CENTREE.REDUITE LOI.NORMALE.STANDARD INVERSE COEFFICIENT.ASYMETRIE LOI.POISSON COEFFICIENT.CORRELATION LOI.STUDENT COEFFICIENT.DETERMINATION LOI.STUDENT.INVERSE COVARIANCE LOI.WEIBULL CRITERE.LOI.BINOMIALE MAX CROISSANCE MEDIANE CROISSANCE MIN DROITEREG MODE ECART.MOYEN MOYENNE ECARTYPE MOYENNE.GEOMETRIQUE ECARTYPEP MOYENNE.HARMONIQUE ERREUR.TYPE.XY MOYENNE.REDUITE FISHER NB FISHER.INVERSE NBVAL FREQUENCE ORDONNEE.ORIGINE GRANDE.VALEUR PEARSON INTERVALLE.CONFIANCE PENTE INVERSE.LOI.F PERMUTATION KHIDEUX.INVERSE PETITE.VALEUR KURTOSIS PREVISION LNGAMMA PROBABILITE LOGREG QUARTILE LOI.BETA RANG LOI.BINOMIALE RANG.POURCENTAGE LOI.BINOMIALE.NEG SOMME.CARRES.ECARTS LOI.EXPONENTIELLE TENDANCE LOI.F TEST.F LOI.GAMMA TEST.KHIDEUX LOI.GAMMA.INVERSE TEST.STUDENT LOI.HYPERGEOMETRIQUE TEST.Z LOI.KHIDEUX VAR LOI.LOGNORMALE VAR.P LOI.LOGNORMALE.INVERSEPar contre, en statistiques descriptives, Excel ne dispose pas de fonctions pour découper une QT en classes, et les fonctions de tracé ne permettent pas de tracer des boites à moustaches, ni des tracés en tige et feuille ou des histogrammes. De plus la gestion des axes ne permet pas de produire facilement des graphiques comparables avec les mêmes plages de variation sur les axes, là ou R fournit cut(), hist(), axis() et des paramètres de tracé comme xlim et ylim.
Au niveau conceptuel on retiendra que moyenne et médiane s'utilisent différemment. Par exemple : on utilise souvent la moyenne des tailles et la médiane des poids (voir aussi moyenne et médiane dans l'article Keegan 2007) et que les différents graphiques sont complémentaires (par exemple histogramme vs boxplot, beanplot vs boxplot).
L'étude d'une QL (variable qualitative) se fait à l'aide de calculs d'effectifs (ou fréquences) absolus ou relatifs, c'est-à-dire des comptages et des pourcentages. Les graphiques associés sont les histogrammes de fréquences, plus faciles à lire et à comparer que les diagrammes circulaires sectoriels (ou "camemberts"). Les fonctions R correspondantes sont nommées table() pour les tris à plat comme pour les tris croisés et barplot() pour le tracé.
Excel, via le menu Données / Rapport de tableau croisé dynamique sait effectuer des tris à plat et des tris croisés et permet de les tracer. Par contre, là encore, le choix des unités sur les axes laisse à désirer.
Oui pour les calculs, parfois dès l'abstract ; non pour les graphiques, malheureusement. Cela vient peut-être des limitations imposées à l'article (nombre de pages, de figures...).
Pour les articles des doctorants, consulter analyses2018.txt que l'on pourra comparer aux analyses des années précédentes dans le fichier analyses.txt.
R ne se trompe pas en général dans ses calculs, mais on peut avoir des erreurs d'arrondi. Par contre Excel est mal programmé et se trompe aussi par suite d'arrondi. Ainsi, la variance d'un échantillon peut se calculer comme la différence entre la moyenne des carrés et le carré de la moyenne ou comme la moyenne des carrés des écarts à la moyenne. Voici ce cela donne sous R :
# essais de calculs de la variance en R avec différentes formules formule1 <- function (v) { return( mean(v*v) - mean(v)^2 ) } formule2 <- function (v) { return( mean( (v - mean(v))^2 ) ) } x <- 1:5 y <- x + 10**9 cat(" Voici les valeurs de x : ",x,"\n") cat(" et celles de y : ",sprintf("%11d",y),"\n\n") cat(" Pour la variance de x, avec la formule 1, on trouve : ",formule1(x),"\n") cat(" et avec la formule 2 : ",formule2(y),"\n\n") cat(" Pour la variance de y, avec la formule 1, on trouve : ",formule1(y),"\n") cat(" et avec la formule 2 : ",formule2(y),"\n\n")On obtient donc des "erreurs" :
Voici les valeurs de x : 1 2 3 4 5 et celles de y : 1000000001 1000000002 1000000003 1000000004 1000000005 Pour la variance de x, avec la formule 1, on trouve : 2 et avec la formule 2 : 2 Pour la variance de y, avec la formule 1, on trouve : 0 et avec la formule 2 : 2La fonction var() de R est "bien sûr" programmée avec la formule 1 et la fonction variance.p() d'Excel avec la formule 2.
La lecture des données et le calcul avec les fonctions usuelles de R peut se faire par :
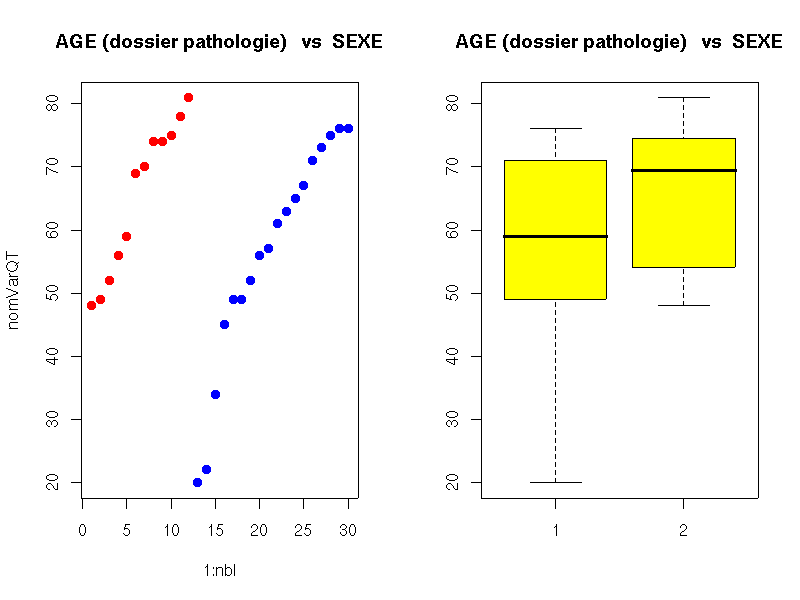
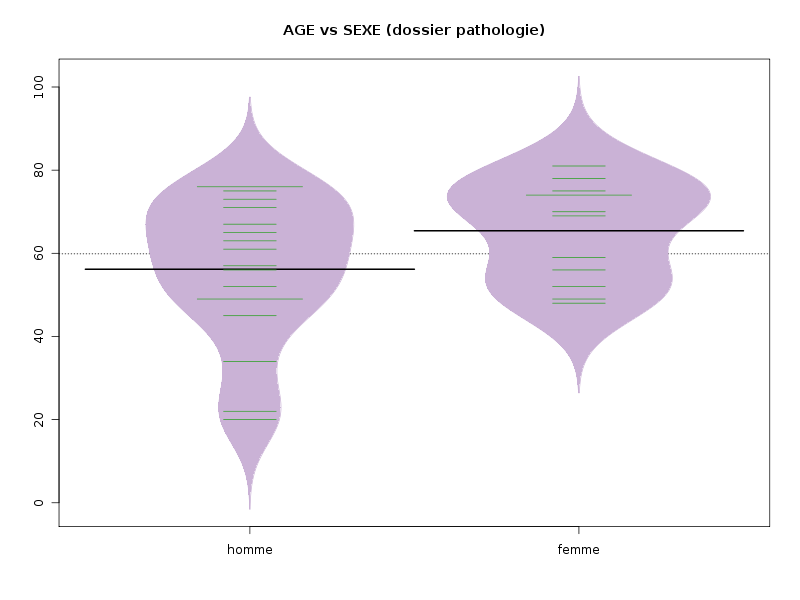
# utilisation des fonctions usuelles de R urldata <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/pathologie.dar" patho <- read.table(urldata,head=TRUE,row.names=1) attach(patho) # ce n'est peut-être pas le plus conseillé (en 2018) age <- AGE sexe <- SEXE detach(patho) cat("Nombre de valeurs ",length(age)," patients\n") cat("Moyenne ",mean(age)," ans\n") cat("Médiane ",median(age)," ans\n") cat("Etendue ",max(age)-min(age)," ans\n") cat("Variance ",var(age)," ans\n") cat("Ecart-type ",sd(age)," ans\n") mo <- rev(sort(table(age)))[1] cat(" Mode : ",names(mo)," ans, vu ",mo," fois\n") ; # utilisation des fonctions de statgh.r source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") decritQT("AGE (dossier pathologie)",age,"ans",TRUE) decritQTparFacteur("AGE (dossier pathologie) ", age,"ans","SEXE",sexe,"homme femme",TRUE)Les résultats et graphiques sont :
# utilisation des fonctions usuelles de R Nombre de valeurs 30 patients Moyenne 59.86667 ans Médiane 62 ans Etendue 61 ans Variance 251.5678 ans Ecart-type 15.86089 ans Mode : 49 ans, vu 3 fois # utilisation des fonctions de statgh.r VARIABLE AGE (dossier pathologie) Taille 30 individus Moyenne 59.8667 ans Ecart-type 15.5943 ans Coef. de variation 26 % 1er Quartile 49.75 ans Médiane 62 ans 3eme Quartile 73.75 ans iqr 24 ans Minimum 20 ans Maximum 81 ans DIAGRAMME TIGE ET FEUILLES 2 | 02 3 | 4 4 | 58999 5 | 226679 6 | 13579 7 | 0134455668 8 | 1 VARIABLE QT AGE (dossier pathologie) unité : ans VARIABLE QL SEXE labels : homme femme N Moy Unite Ect Cdv Q1 Med Q3 EIQ Min Max Global 30 59.8667 ans 15.5943 26 49.75 62 73.75 24 20 81 homme 18 56.1667 ans 16.8696 30 49 59 70 21 20 76 femme 12 65.4167 ans 11.3905 17 55 69.5 74.25 19.25 48 81
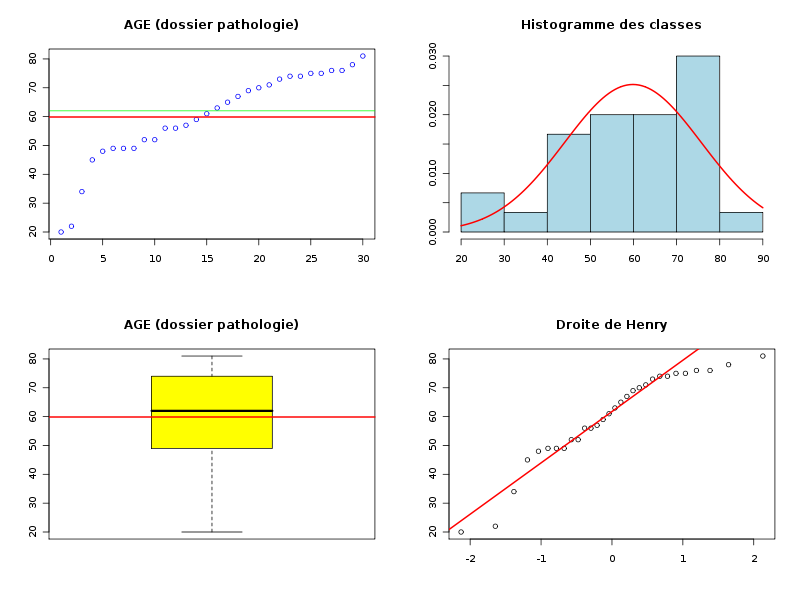
Les commentaires sur la variable AGE doivent indiquer que l'échantillon est petit (30 personnes), que l'age varie peu (cdv 26 %) et est en moyenne celui de seniors (moyenne 60 ans, premier quartile à 50 ans). Les hommes semblent en général plus jeunes que les femmes et l'age des femmes est plus homogène.
Le format utilisé est un format dit long car il utilise une colonne AGE et une colonne SEXE. Un format large utiliserait une colonne AGEHOMME et une colonne AGEFEMME. Il est en général préférable d'avoir un format long (donc avec des colonnes de même longueur).
# format large AGEHOMME AGEFEMME 20 48 22 49 34 52 45 56 49 59 49 69 52 70 56 74 57 74 61 75 63 78 65 81 67 71 73 75 76 76 # format long (SEXE 1 = HOMME, SEXE 2 = FEMME) SEXE AGE 2 48 2 49 2 52 2 56 2 59 2 69 2 70 2 74 2 74 2 75 2 78 2 81 1 20 1 22 1 34 1 45 1 49 1 49 1 52 1 56 1 57 1 61 1 63 1 65 1 67 1 71 1 73 1 75 1 76 1 76Chacune des 5 pièces suit une loi de Bernoulli b(p=0,5) où 0 signifie '0 fois PILE' et 1 '1 fois PILE'. Sous l'hypothèse d'indépendance des 5 pièces, leur somme suit une loi binomiale B(n=5,p=0,5).
La probabilité d'avoir k fois PILE est alors Cnk pk (1-p)n-k pour k de 0 à n=5.
Avec le logiciel R, on peut utiliser la fonction choose pour les coefficients du binome. On peut alors écrire le calcul de chacune des probabilités et leur somme (pour obtenir la fonction de répartition) à l'aide des instructions suivantes :
# calcul "à la main" des probabilités de la loi binomiale # et de sa fonction de répartition pour 5 pièces de monnaie # non truquées n <- 5 p <- 0.5 valeurs <- 0:n cat("Etude de la loi binomiale B(n=",n,",p=",p,") \n\n") mdr <- matrix(nrow=2,ncol=1+n) row.names(mdr) <- c("probabilité","cumul") colnames(mdr) <- as.character(valeurs) # probabilités for (k in valeurs) { mdr[1,1+k] <- choose(n,k)*(p**k)*(1-p)**(n-k) if (k==0) { mdr[2,1+k] <- mdr[1,1+k] } else { mdr[2,1+k] <- mdr[2,k] + mdr[1,1+k] } # fin si } # fin pour k print(mdr) # fréquences cat("Pourcentages\n") mdr <- round(100*mdr) row.names(mdr) <- c("fréquence (%)","répartition (%)" ) print(mdr)Voici l'affichage correspondant :
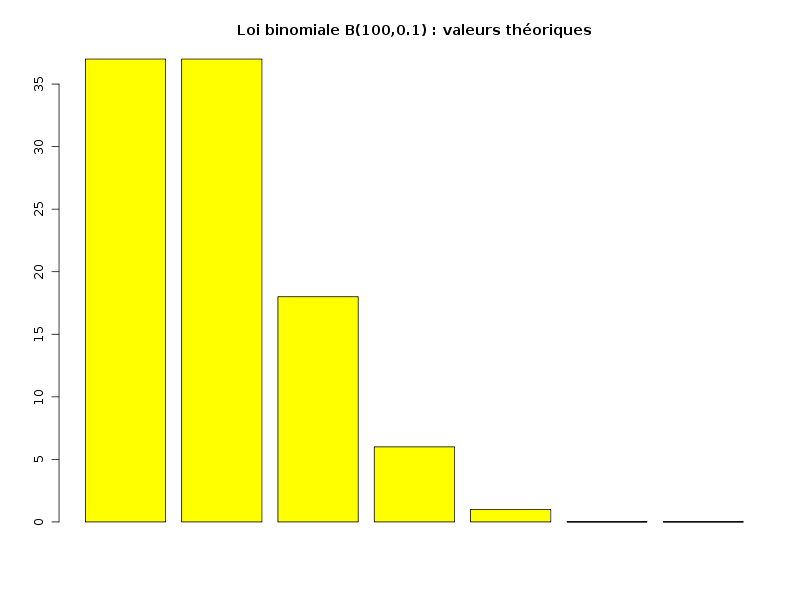
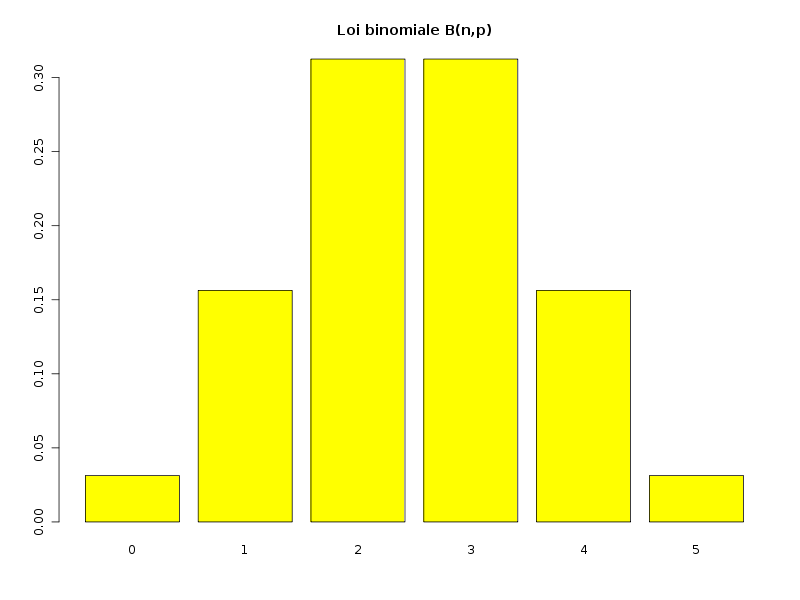
Etude de la loi binomiale B(n=5,p=0.5) Distribution 0 1 2 3 4 5 probabilité 0.03125 0.15625 0.3125 0.3125 0.15625 0.03125 cumul 0.03125 0.18750 0.5000 0.8125 0.96875 1.00000 Pourcentages 0 1 2 3 4 5 fréquence (%) 3 16 31 31 16 3 répartition (%) 3 19 50 81 97 100Mais le logiciel R connait déjà la distribution binomiale via la fonction dbinom et le cumul de valeurs peut se faire via la fonction cumsum. On peut donc écrire de façon plus concise :
# calcul des probabilités de la loi binomiale # et de sa fonction de répartition pour 5 pièces de monnaie # non truquées via dbinom et cumsum n <- 5 p <- 0.5 valeurs <- 0:n cat("Etude de la loi binomiale B(n=",n,",p=",p,") \n\n") mdr <- matrix(nrow=2,ncol=1+n) row.names(mdr) <- c("probabilité","cumul") colnames(mdr) <- as.character(valeurs) mdr[1,] <- unlist(lapply(valeurs,function(x) { return(dbinom(x,n,p)) })) cumul <- cumsum(mdr[1,]) mdr[2,] <- cumul print(mdr)Le tracé des probabilités peut alors se faire avec l'instruction
barplot(cumul,col="yellow",main="Loi binomiale B(n,p)") :
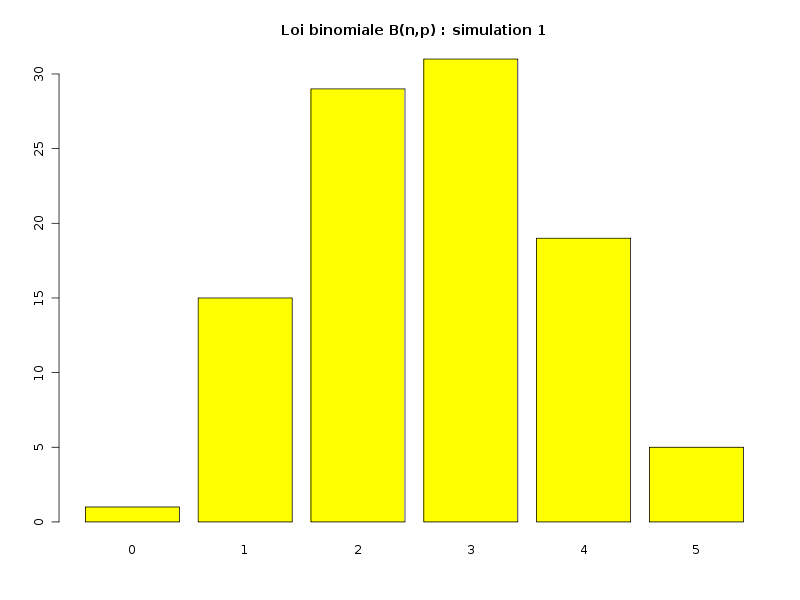
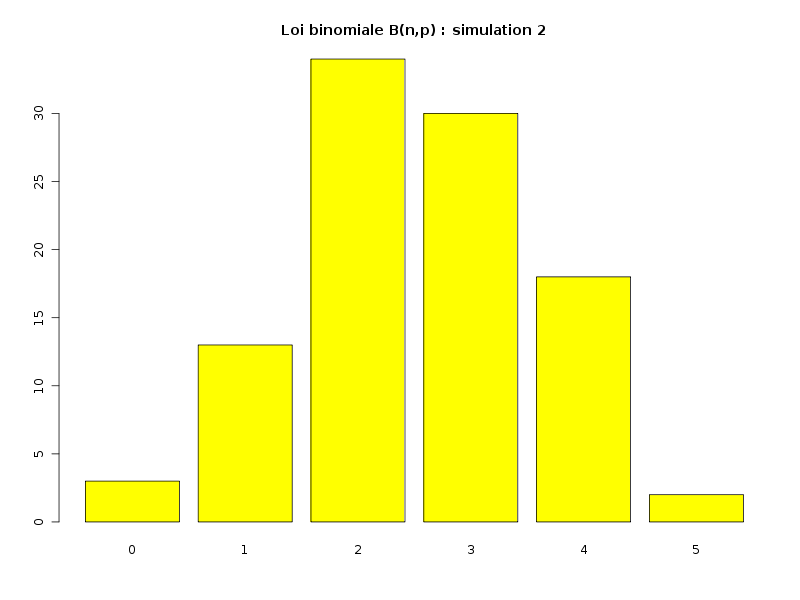
La simulation de la loi binomiale se fait via la fonction rbinom ; voici par exemple comment simuler 4 séries de valeurs avec stockage en PNG de l'histogramme correspondant :
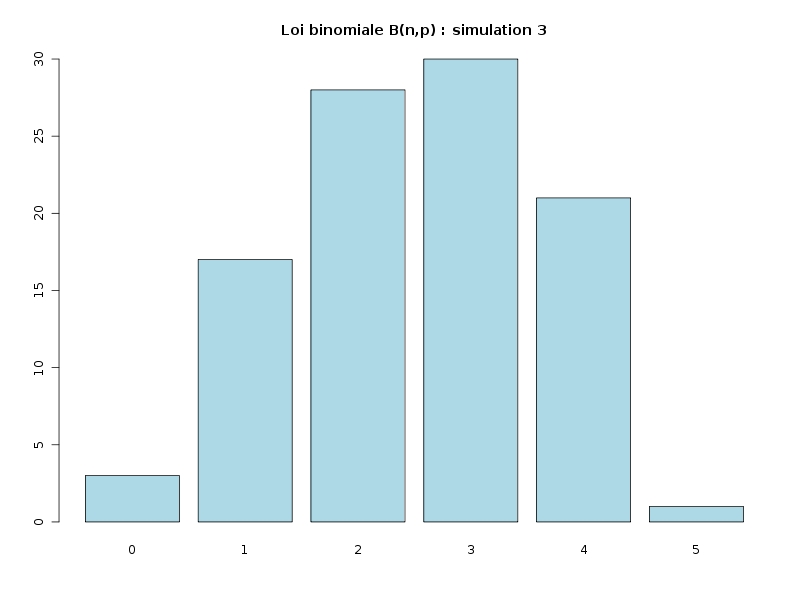
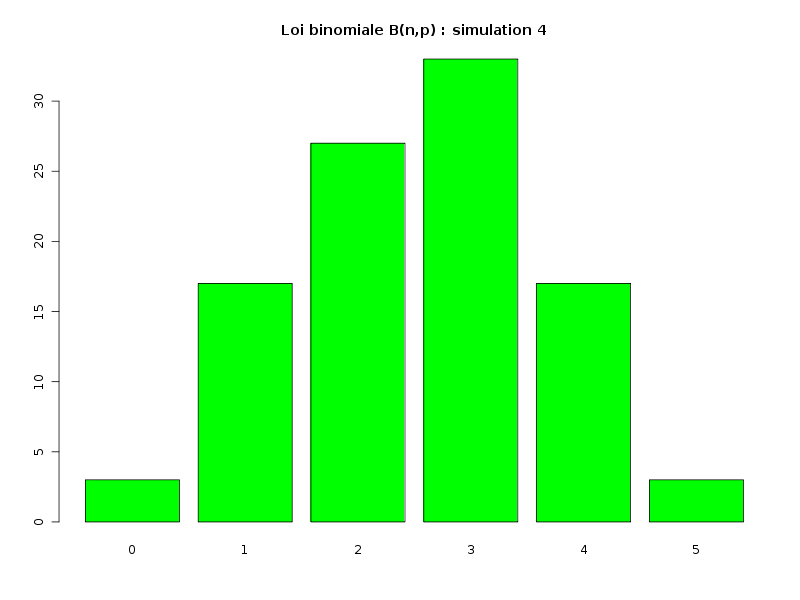
# simulation de la loi binomiale B(n=5,p=0.5) sur 100 valeurs # avec production d'images PNG simul1 <- rbinom(100,5,0.5) png("simulbinom1.png",width=800,height=600) barplot(table(simul1),col="yellow",main="Loi binomiale B(n,p) : simulation 1") dev.off() simul2 <- rbinom(100,5,0.5) png("simulbinom2.png",width=800,height=600) barplot(table(simul2),col="yellow",main="Loi binomiale B(n,p) : simulation 2") dev.off() simul3 <- rbinom(100,5,0.5) png("simulbinom3.png",width=800,height=600) barplot(table(simul3),col="light blue",main="Loi binomiale B(n,p) : simulation 3") dev.off() simul4 <- rbinom(100,5,0.5) png("simulbinom4.png",width=800,height=600) barplot(table(simul4),col="green",main="Loi binomiale B(n,p) : simulation 4") dev.off()
Pour le nombre de filles dans une famille de 5 enfants, en admettant l'équiprobabilité des sexes à la naissance, il s'agit de la même modélisation avec donc la même loi binomiale B(5,0.5).
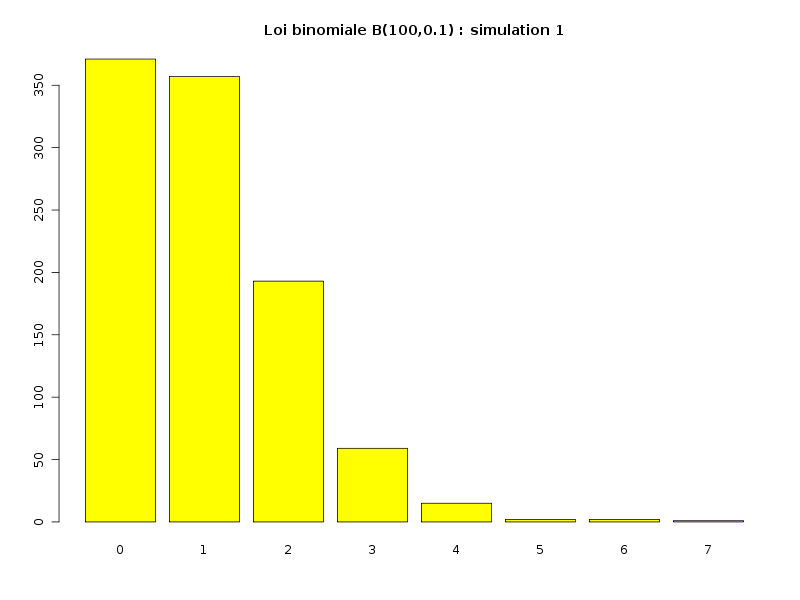
Pour le nombre de malades dans une échantillon de 100 personnes pour une maladie de prévalence 5/100, la modélisation se fait avec la loi binomiale B(100,0.05). La probabilité d'avoir plus de 5 malades est assez rapidement très faible :
n <- 100 p <- 0.01 valeurs <- 0:n probas <- unlist( lapply(valeurs, function(x) { return(dbinom(x,n,p)) }) ) debut <- 1:10 mdr <- rbind( valeurs[debut], round(100*probas[debut]) ) row.names(mdr) <- c("valeur","probabilité") colnames(mdr) <- rep("",10) print(mdr) cat("Remarque : la probabilité pour k=10 est ",probas[11],"\n")valeur 0 1 2 3 4 5 6 7 8 9 probabilité 37 37 18 6 1 0 0 0 0 0 Remarque : la probabilité pour k=10 est 7.006036e-08
Pour les autres lois usuelles de probabilités discrètes, on pourra utiliser notre page nommée loisStatp.
Le Falissard, bien sûr, car il est en français, court (384 pages -- hum --) et agréable à lire. De plus il contient des exemples de sorties de logiciels... Les deux autres ouvrages doivent plutôt être considérés comme des ouvrages de référence, ou des cours détaillés (respectivement 880 et 920 pages !).