![]()
![]()
|
Enoncés pour la séance numéro 3 (solutions)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 1
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Enoncés pour la séance numéro 3 (solutions)
La séance précédente a montré comment calculer un intervalle de confiance pour une proportion et pour une moyenne. Existe-t-il d'autres intervalles de confiance ?
Qu'est-ce qu'un « petit échantillon » ? Pourquoi faut-il le distinguer d'un « grand échantillon » ? Qu'est-ce qu'un « échantillon normal » ? Pourquoi faut-il le distinguer d'un « échantillon non normal » ?
Comment tester en R qu'un échantillon est « normal » ?
On dispose d'un échantillon de 150 patients pour lesquels on a mesuré le taux de cholestérol en g/l. La somme des valeurs est 273 et la somme de leurs carrés dépasse un peu 512. On trouvera ces données dans le fichier choldata.dar. Décrire ces données puis décider s'il y a une différence significative avec le taux théorique de cholestérol qui est de 2 g/l (exercice de J.-B. Hardouin).
On pourra lire les données via les instructions (au format large) :
# lecture des données sur internet url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/choldata.dar" chol <- read.table(url,head=TRUE,row.names=1) ## lecture des données en local sur le disque D: ## chol <- read.table("D:/choldata.dar",head=TRUE,row.names=1)La solution statistique (sans utiliser R) est ici : il s'agit de l'exercice III.
On dispose de deux colonnes QT, par exemple AGEH et AGEF (format large). Comment en faire des données en format long c'est-à-dire avec une colonne AGE et une colonne GROUPE (1 pour H et 2 pour F) ?
Comment effectuer la transformation inverse ?
On pourra utiliser les instructions suivantes pour définir AGEH, AGEF, AGE et GROUPE :
# colonnes QT (format large) AGEH <- c(27,29,61,18,42) AGEF <- c(10,18,35,40,50,18,50) # colonne QT et colonne QL (format long) AGE <- c(27,29,61,18,42,10,18,35,40,50,18,50) GROUPE <- c( 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2)Ce qui correspond aux données suivantes :
AGEH AGEF | AGE GROUPE 27 10 | 27 1 29 18 | 29 1 61 35 | 61 1 18 40 | 18 1 42 50 | 42 1 18 | 10 2 50 | 18 2 | 35 2 | 40 2 | 50 2 | 18 2 | 50 2Remarque : il est conseillé de lire l'aide sur les fonctions c, length et rep ainsi que cbind, rbind, as.factor, as.data.frame avant de résoudre l'exercice.
Un biologiste veut comparer les résultats fournis (en g/l) pour deux souches différentes de souris. Il dispose de deux échantillons de 50 souris dont les données sont dans le fichier souris.dar. Décrire ces données puis décider s'il y a une différence significative entre les moyennes de ces deux souches (exercice de J.-B. Hardouin).
On pourra lire les données via les instructions :
# lecture des données sur internet url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/souris.dar" souris <- read.table(url,head=TRUE,row.names=1) ## lecture des données en local sur le disque D: ## souris <- read.table("D:/souris.dar",head=TRUE,row.names=1)La solution statistique (sans utiliser R) est ici : il s'agit de l'exercice IV.
Si les données sont appariées, est-ce que le test de comparaison de moyennes reste valable ?
Où trouver une documentation sur le test t de Welch ? Pourquoi R change-t-il le nom du test t suivant les options ?
Comparer les temps suivants (en secondes) de parcours d'un labyrinthe pour les mêmes souris, avant et après l'injection d'une substance "dopante" :
Souris S01 S02 S03 S04 S05 S06 S07 S08 Avant 125 130 132 135 136 138 140 145 Après 127 132 133 136 139 141 145 148 On pourra utiliser les instructions R suivantes pour les données :
avant <- c(125, 130, 132, 135, 136, 138, 140, 145) apres <- c(127, 132, 133, 136, 139, 141, 145, 148)Pourquoi y a-t-il un risque de biais de confusion ici ?
Doit-on effectuer un test unilatéral ou bilatéral ? A quoi sert l'adjectif «dopante» ?
Qu'est-ce qu'une ANOVA ? Une ANCOVA ? Une MANOVA ? Une MANCOVA ?
Pourquoi parler d'analyse de variance pour comparer des moyennes ?
Qu'est-ce qu'un test post hoc ?
Vérifier que l'ANOVA est équivalente à une comparaison de moyennes pour les données de l'exercice 4 (test sanguin en g/l pour les souris).
Réaliser une ANOVA des données IRIS, variable petal.length en fonction de l'espèce.
«Monsieur, je n'arrive jamais à me rappeler dans quel sens on interprète une p-value». Comment faire pour retrouver le bon sens ?
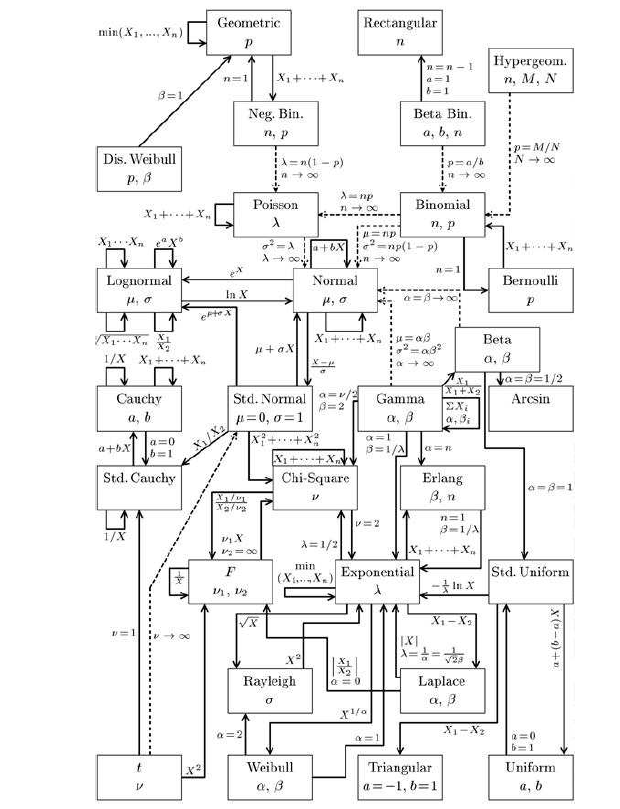
Qu'est-ce qu'un modèle probabiliste ? Quels sont les « grands » modèles probabilistes ?
Comprenez-vous le schéma ci-dessous ?
Donner la valeur exacte de la probabilité p(3≤X≤6) si X suit une loi binomiale de paramètres n=15 et p=0,3. Donner la valeur approchée si on approxime la loi binomiale par la loi normale, avec et sans correction de continuité (continuity correction en anglais).
On rappelle que B(n,p) tend vers N(m=np,v=npq) pour n>30, np>5, nq>5 alors que B(n,p) tend vers P(m=np) pour n>30, np<5 ou pour n>50, p < 0,1 même si certains spécialistes utilisent d'autres bornes (comme n>35 ou n>40...).
Pour certains cancers, dont le cancer colo-rectal, il est admis qu'on comptabilise en général 1500 toxicités majeures ou mineures (neutropénie, syndrome mains-pieds, diarrhées... en cas d'utilisation du 5FU, par exemple) pour 1000 personnes au cours des 5 premiers cycles de traitement (soit environ 2 mois et demi). Si on accepte ces valeurs, quelle est la probabilité qu'une personne ait subi moins de deux toxicités pour ces 5 cycles ? On donnera une approximation par la loi normale puis par la loi de Poisson.
Quel livre sur R spécialisé sur les tests peut-on lire ?
Comment effectuer une régression linéaire en R ? Quelle est la différence avec une régression logistique ? Pourquoi distinguer causalité et corrélation ? Application : utiliser les variables height et weight du jeu de données diabetes de la page datasets du professeur F. Harrell, le célèbre auteur de Regression Modeling Strategies, puis les variables waist et weight. Une copie des données au format .dar est diabetes.dar mais attention, il y a des données manquantes, repérées par NA.
Réaliser une régression linéaire des données IRIS pour les variables petal.length et petal.width. Quelle causalité est mise en jeu ?