![]()
![]()
Les dates de formation sont ici.
Solutions pour la séance numéro 4 (énoncés)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Solutions pour la séance numéro 4 (énoncés)
La cote est liée à la probabilité par la la relation cote = proba / (1-proba) soit encore proba = cote / (1+cote). Ainsi une cote de 3 pour 1 correspond à une probabilité de 0,75 et une proba de 0,5 à une cote de 1 pour 1. Voici les fonctions associées :
proba2cote <- function(proba) { return( proba/(1-proba) ) } # fin de fonction proba2cote #################################### cote2proba <- function(cote) { return( cote/(1+cote) ) } # fin de fonction cote2proba #################################### #################################### cat(" à une cote de de 3/1 correspond une proba de ",cote2proba(3/1),"\n") cat(" à une probabilité de 0,5 correspond une cote de ",proba2cote(0.5),"\n")à une cote de de 3/1 correspond une proba de 0.75 à une probabilité de 0,5 correspond une cote de 1Le rapport de chances ou rapport de cotes ou OR (odds ratio) est une valeur numérique qui quantifie la dépendance et l'importance d'évènements binaires.
Voir à ce sujet et dans cet ordre le wiki français (court) puis le wiki anglais (long).
Il ne faut pas confondre le rapport de cotes et le risque relatif RR, en anglais : relative risk. Pour faire court : RR est le rapport des risques et OR est le rapport des cotes.
Si dans la régression linéaire classique on modélise la variable continue quantitative Y par une combinaison linéaire de variables xi (notée βX), en régression logistique, on modélise une variable Y qualitative ce qui inclut le cas d'une variable Y binaire ou («logique»). Le modèle linéaire de base s'écrit Y = βX alors que le modèle linéaire généralisé s'écrit g(Y) = βX où g est nommée fonction de lien. Pour la régression logistique, la fonction de lien est la fonction logit définie par logit(p)=log(p/(1-p)) dont l'inverse est la fonction logistique qui est donc définie par logis(x)=exp(x)/(1+exp(x)).
On lira avec profit le document MODGEN du CNAM pour comprendre ce que sont les modèles linéaires généralisés, puis le document semin-R pour voir un exemple d'application.
Un long document en français (270 pages) sur le sujet la régression logistique est celui de R. Rakotomalala disponible à l'adresse
http://eric.univ-lyon2.fr/~ricco/cours/cours/pratique_regression_logistique.pdf
dont une copie locale est ici.
Pour réaliser une régression logistique en R, on utilise la fonction glm() du package stats au lieu de la fonction lm() du package stats pour la régression linéaire et on précise que la famille de fonctions à utiliser est binomial.
L'affichage du modèle via la fonction générique print() du package base n'est en général pas suffisant et on lui préfère la fonction summary.glm() du package stats mais comme pour la fonction summary.lm() de ce même package stats on peut se contenter d'utiliser la fonction générique summary() du package base. En d'autres termes, si rlb est un modèle issu d'une régression logistique, on peut utiliser summary(rlb) mais si on veut de l'aide sur la "vraie" fonction summary() utilisée pour ce modèle, il faut écrire help(summary.glm). Il est en général conseillé d'appliquer aussi la fonction générique anova() sur un modèle issu d'une régression logistique, ce qui a pour but d'exécuter la fonction anova.glm().
Comme pour la fonction lm() et sa fonction predict.lm(), la fonction glm() dispose d'une fonction predict.glm() disponible via la fonction générique predict().
De la même façon, comme pour la fonction lm() et sa fonction plot.lm(), la fonction glm() dispose d'une fonction plot.glm() disponible via la fonction générique plot() qui permet de réaliser une analyse graphique des résidus.
Il est bien sûr très fortement conseillé d'étudier les deux variables TAILLE et GROUPE séparément puis conjointement avant d'effectuer la régression logistique binaire de GROUPE en fonction de TAILLE, soit le code R :
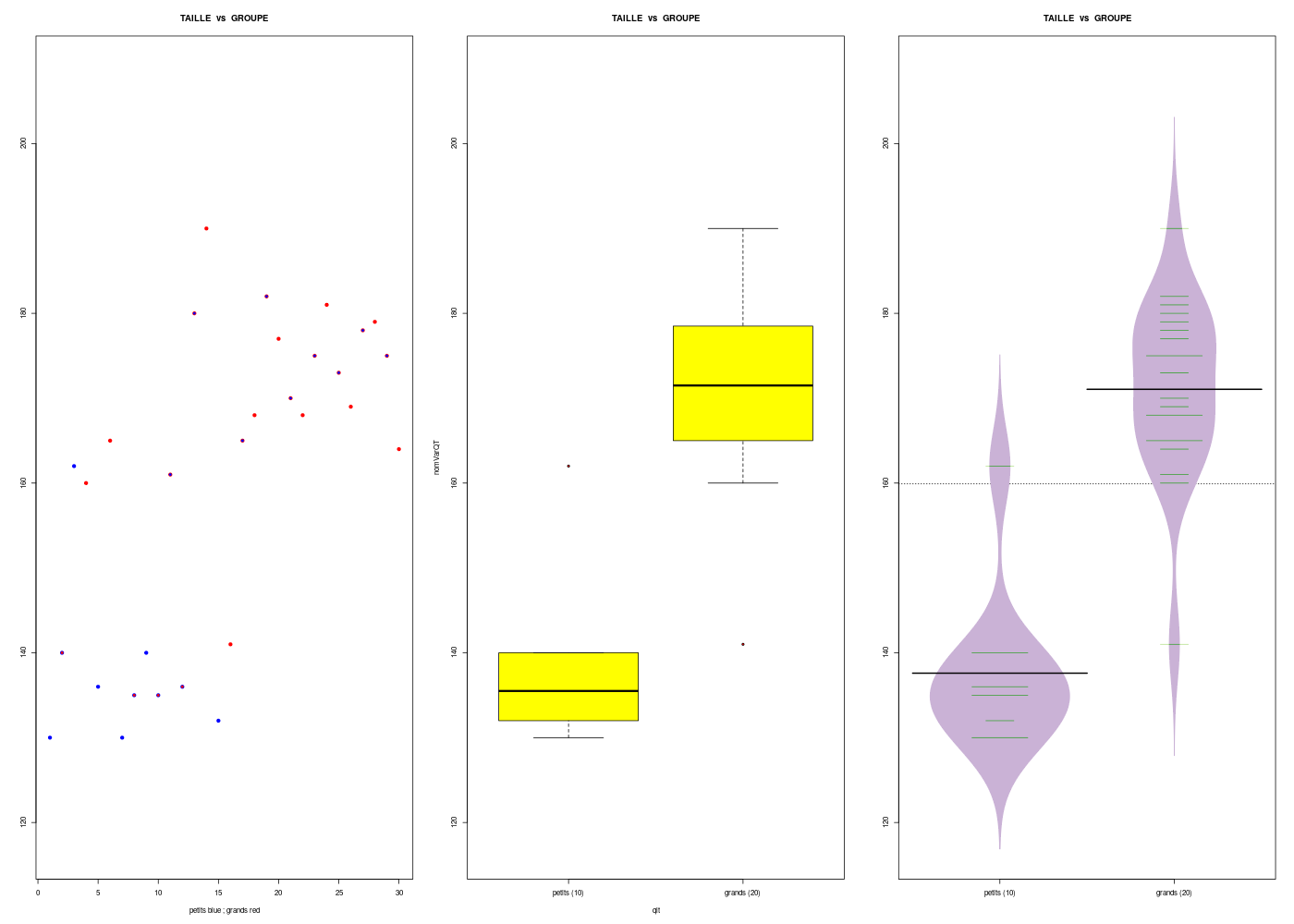
## avant la régression logistique binaire simple de GROUPE en fonction de TAILLE ## dans les données du fichier pg.dar, on analyse les variables # chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données du fichier-texte pg <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/pg.dar") # description de TAILLE gr("pgTAILLE.png") decritQT("TAILLE",pg$TAILLE,"cm",TRUE) dev.off() # description de GROUPE gr("pgGROUPE.png") decritQL("GROUPE",pg$GROUPE,"petits grands",TRUE) dev.off() # description de TAILLE par GROUPE gr("pgTAILLEparGROUPE.png") decritQTparFacteur("TAILLE",pg$TAILLE,"cm","GROUPE",pg$GROUPE,"petits grands",TRUE) dev.off()DESCRIPTION STATISTIQUE DE LA VARIABLE TAILLE Taille 30 individus Moyenne 159.9000 cm Ecart-type 18.8869 cm Coef. de variation 12 % 1er Quartile 140.0000 cm Mediane 165.0000 cm 3eme Quartile 175.0000 cm iqr absolu 35.0000 cm iqr relatif 21.0000 % Minimum 130.000 cm Maximum 190.000 cm Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 13 | 0025566 14 | 001 15 | 16 | 012455889 17 | 0355789 18 | 012 19 | 0 TRI A PLAT DE : GROUPE (ordre des modalités) petits grands Total Effectif 10 20 30 Cumul Effectif 10 30 30 Frequence (en %) 33 67 100 Cumul fréquences 33 100 100 VARIABLE : GROUPE (par fréquence décroissante) grands petits Total Effectif 20 10 30 Cumul Effectif 20 30 30 Frequence (en %) 67 33 100 Cumul fréquences 67 100 100 [1] "petits" "grands" VARIABLE QT TAILLE ,unit=cm VARIABLE QL GROUPE labels : petits grands N Moy Unite Ect Cdv Q1 Med Q3 EIQ Min Max Global 30 159.900 cm 18.569 12 140.000 165.000 175.000 35.000 130.000 190.000 petits 10 137.600 cm 8.789 6 132.750 135.500 139.000 6.250 130.000 162.000 grands 20 171.050 cm 10.278 6 165.000 171.500 178.250 13.250 141.000 190.000 Analysis of Variance Table Response: nomVarQT Df Sum Sq Mean Sq F value Pr(>F) ql 1 7459.4 7459.4 72.387 2.998e-09 *** Residuals 28 2885.4 103.0 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ANOVA : there is a significant diffence at the level 0.05 for TAILLE GROUPE Kruskal-Wallis rank sum test data: nomVarQT by ql Kruskal-Wallis chi-squared = 18.239, df = 1, p-value = 1.948e-05 KRUSKAL-WALLIS : there is a significant diffence at the level 0.05 for TAILLE GROUPEUne lecture détaillée de ces résultats et des graphiques montre qu'il y a bien sans doute deux groupes de taille.
Le code R suivant réalise la régression logistique de GROUPE en fonction de TAILLE
## exemple de régression logistique binaire simple : ## on modélise GROUPE en fonction de TAILLE dans les données ## du fichier pg.dar # chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données du fichier-texte pg <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/pg.dar") # calcul de la régression logistique rlb <- glm(GROUPE ~ TAILLE,data=pg,family="binomial") # affichage simplifié (coefficients) cats("Régression logistique de GROUPE en fonction de TAILLE") print(rlb) # affichage détaillé cats("Détails de la régression logistique") print(summary(rlb))Régression logistique de GROUPE en fonction de TAILLE ===================================================== Call: glm(formula = GROUPE ~ TAILLE, family = "binomial", data = pg) Coefficients: (Intercept) TAILLE -27.2103 0.1812 Degrees of Freedom: 29 Total (i.e. Null); 28 Residual Null Deviance: 38.19 Residual Deviance: 10.89 AIC: 14.89 Détails de la régression logistique =================================== Call: glm(formula = GROUPE ~ TAILLE, family = "binomial", data = pg) Deviance Residuals: Min 1Q Median 3Q Max -2.1225 -0.2589 0.1087 0.2728 1.9168 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -27.21029 8.95762 -3.038 0.00238 ** TAILLE 0.18118 0.05893 3.074 0.00211 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 38.191 on 29 degrees of freedom Residual deviance: 10.895 on 28 degrees of freedom AIC: 14.895 Number of Fisher Scoring iterations: 6Comme pour une régression linéaire, il est possible de connaitre les valeurs calculées par le modèle et d'en prédire de nouvelles :
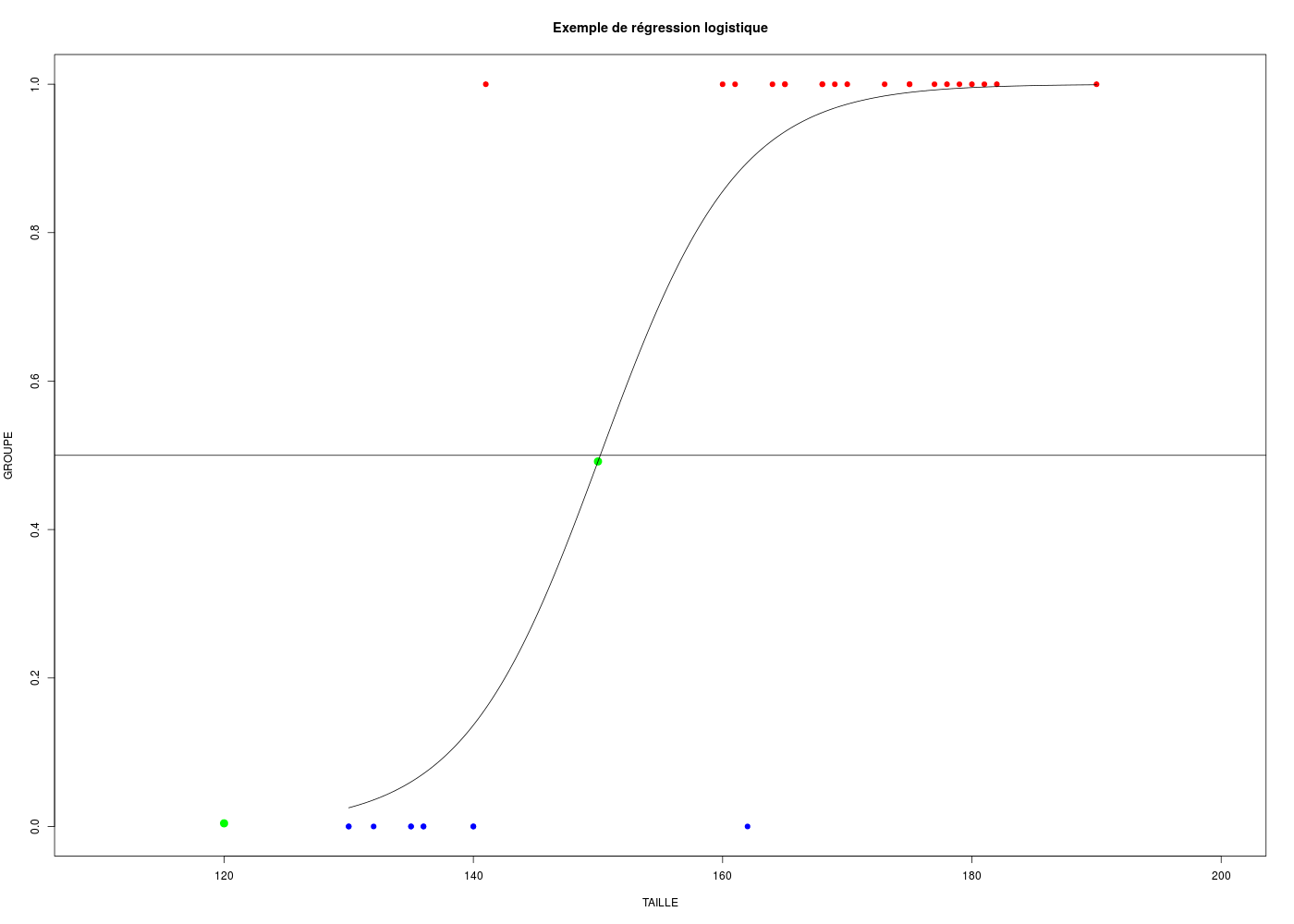
## régression logistique binaire simple et prédictions ## on prédit des données pour les tailles 120 et 150 cm # chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données du fichier-texte pg <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/pg.dar") # calcul de la régression logistique rlb <- glm(GROUPE ~ TAILLE,data=pg,family="binomial") # affichage des valeurs calculées par le modèle # (données triées par groupe puis taille croissante) npg <- cbind(pg,rlb$fitted.values) ord <- order(pg$GROUPE,pg$TAILLE) print(npg[ord,]) # prédictions cats("Valeurs prédites") nTailles <- data.frame( TAILLE=c(120,150) ) nGroupes <- predict(rlb,nTailles,"response") print( cbind(nTailles,nGroupes) ) # tracé des valeurs initiales et prédites coulGrp <- ifelse(pg$GROUPE==0,"blue","red") plot(GROUPE ~ TAILLE,data=pg,xlim=c(110,200),col=coulGrp,type="p",pch=19) title(main="Exemple de régression logistique") points( as.numeric(nGroupes) ~ unlist(nTailles), col="green", cex=1.5,pch=19 ) # tracé de la fonction logistique du modèle x <- data.frame( TAILLE=seq(from=min(pg$TAILLE),to=max(pg$TAILLE),length.out=1000) ) y <- predict(rlb,x,"response") points( as.numeric(y) ~ unlist(x), col="black", type="l") # valeur-seuil par défaut : 0.5 abline(h=0.5)TAILLE GROUPE rlb$fitted.values A01 130 0 0.02517286 A04 130 0 0.02517286 A09 132 0 0.03577320 A05 135 0 0.06005399 A07 135 0 0.06005399 A03 136 0 0.07113425 A08 136 0 0.07113425 A02 140 0 0.13650072 A06 140 0 0.13650072 C01 162 0 0.89485898 A10 141 1 0.15929538 C02 160 1 0.85557305 C04 161 1 0.87655250 C20 164 1 0.92440288 C03 165 1 0.93613049 C07 165 1 0.93613049 C08 168 1 0.96189141 C12 168 1 0.96189141 C16 169 1 0.96800461 C11 170 1 0.97316451 C15 173 1 0.98423973 C13 175 1 0.98897761 C19 175 1 0.98897761 C10 177 1 0.99230232 C17 178 1 0.99356976 C18 179 1 0.99462964 C05 180 1 0.99551561 C14 181 1 0.99625597 C09 182 1 0.99687448 C06 190 1 0.99926469 Valeurs prédites ================ TAILLE nGroupes 1 120 0.004200577 2 150 0.491792541
Un simple appel de la fonction ifelse() du package base permet de déterminer les groupes prédits une fois le seuil de séparation choisi. La matrice de confusion est alors simplement le tri croisé des variables groupesOriginaux et groupesPredits. Le taux de bien classés s'obtient comme le pourcentage associé aux valeurs de la diagonale :
## qualité de la régression sur les données pg.dar avec un seuil de séparation à 0,5 # calcul de la régression rlb <- glm(GROUPE ~ TAILLE,data=pg,family="binomial") # valeurs prédites ypred <- predict(rlb,newdata=data.frame(TAILLE=pg$TAILLE),type="response") # groupes prédits tdr <- data.frame( taille=pg$TAILLE, groupeOriginal=pg$GROUPE, groupePredit= ifelse( ypred<0.5,0,1) ) # fin de data.frame print(tdr) cats("Matrice de confusion") with(tdr,print(table( groupeOriginal, groupePredit ))) cats("Nombre et taux de bien classés") nbTot <- nrow(tdr) nbBc <- sum(tdr$groupeOriginal==tdr$groupePredit) pctBc <- 100*nbBc/nbTot cat(nbBc,"bien classés sur",nbTot,"individus en tout, soit",pctBc,"%\n")taille groupeOriginal groupePredit 1 130 0 0 2 140 0 0 3 162 0 1 4 160 1 1 5 136 0 0 6 165 1 1 7 130 0 0 8 135 0 0 9 140 0 0 10 135 0 0 11 161 1 1 12 136 0 0 13 180 1 1 14 190 1 1 15 132 0 0 16 141 1 0 17 165 1 1 18 168 1 1 19 182 1 1 20 177 1 1 21 170 1 1 22 168 1 1 23 175 1 1 24 181 1 1 25 173 1 1 26 169 1 1 27 178 1 1 28 179 1 1 29 175 1 1 30 164 1 1 Matrice de confusion ==================== groupePredit groupeOriginal 0 1 0 9 1 1 1 19 Nombre et taux de bien classés ============================== 28 bien classés sur 30 individus en tout, soit 93.33333 %Avec un seuil de séparation à 0,15, tous les individus du groupe 1 sont bien prédits et le taux de bien classés est alors meilleur, mais bien sûr ce seuil est arbitraire et lié aux données...
## qualité de la régression sur les données pg.dar avec un seuil de séparation à 0,15 # calcul de la régression rlb2 <- glm(GROUPE ~ TAILLE,data=pg,family="binomial") # valeurs prédites ypred <- predict(rlb2,newdata=data.frame(TAILLE=pg$TAILLE),type="response") # groupes prédits tdr2 <- data.frame( taille=pg$TAILLE, groupeOriginal=pg$GROUPE, groupePredit= ifelse( ypred<0.15,0,1) ) # fin de data.frame cats("Matrice de confusion") with(tdr2,print(table( groupeOriginal, groupePredit ))) cats("Nombre et taux de bien classés") nbTot <- nrow(tdr2) nbBc <- sum(tdr2$groupeOriginal==tdr2$groupePredit) pctBc <- 100*nbBc/nbTot cat(nbBc,"bien classés sur",nbTot,"individus en tout, soit",pctBc,"%\n")Matrice de confusion ==================== groupePredit groupeOriginal 0 1 0 9 1 1 0 20 Nombre et taux de bien classés ============================== 29 bien classés sur 30 individus en tout, soit 96.66667 %Commençons par regarder les variables CHD69 et AGE séparément puis conjointement.
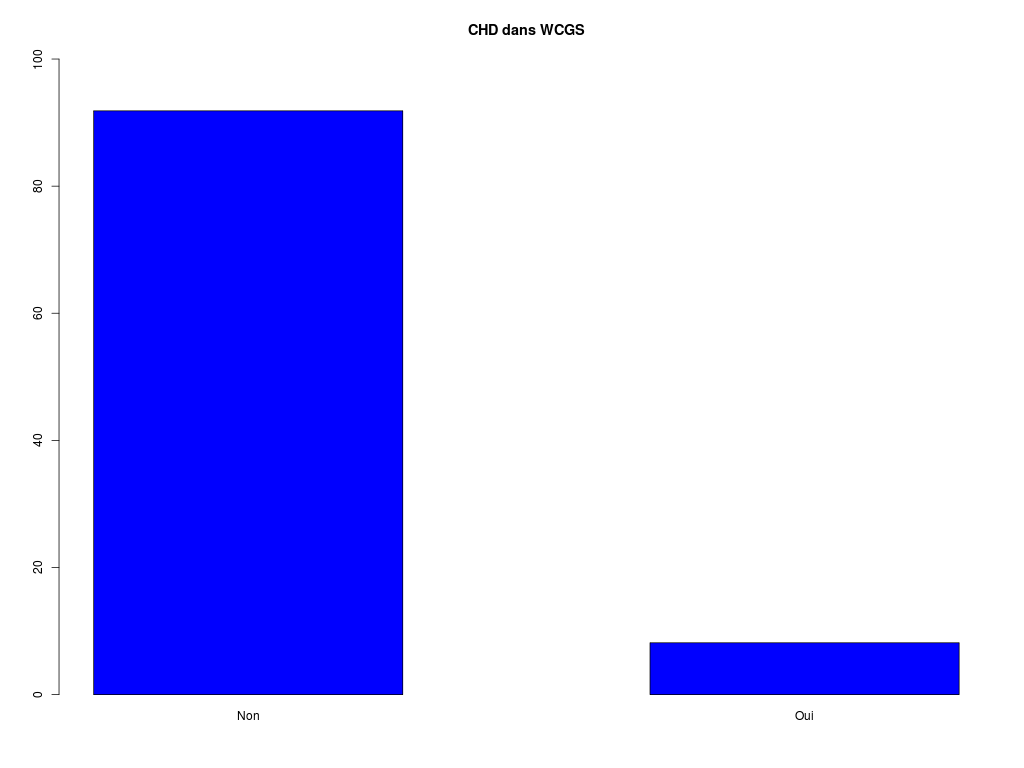
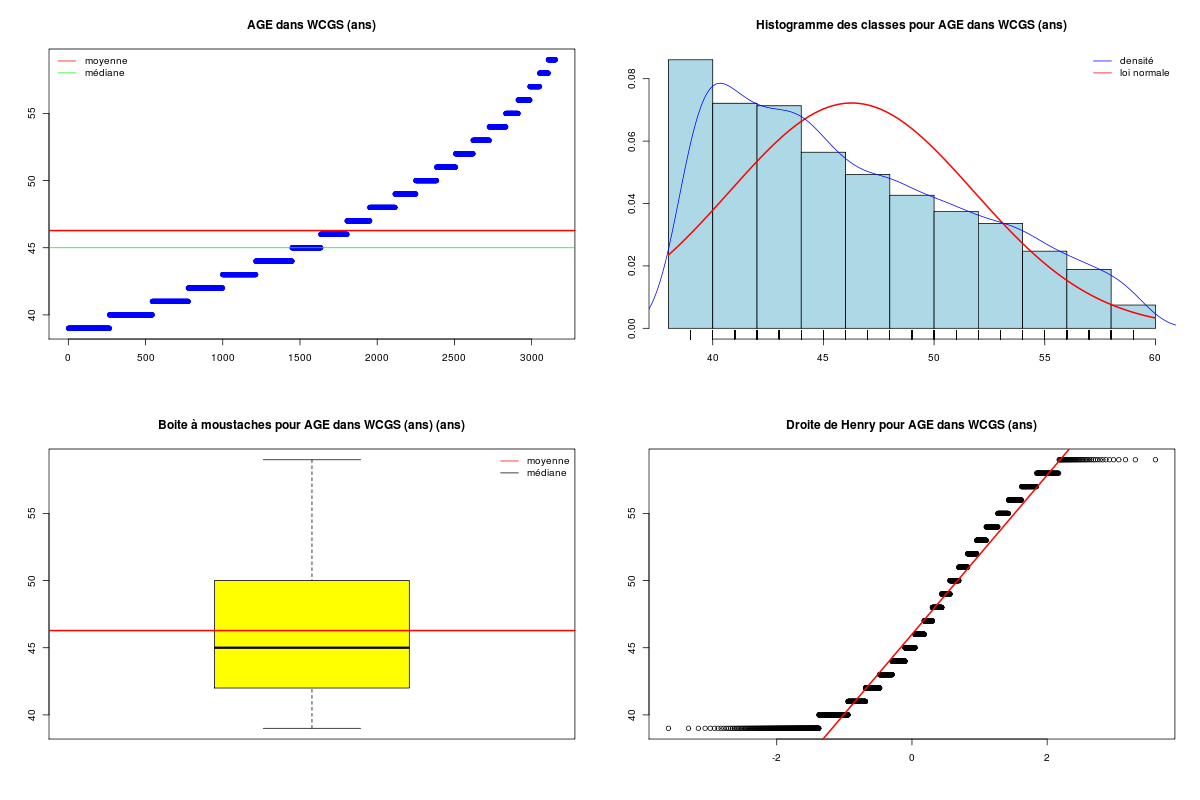
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE # recodage de chd chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) chd69 <- ifelse(chd=="Non",0,1) # statistiques élémentaires decritQT("AGE dans WCGS",age,"ans",TRUE,"wcgs_age.png") decritQL("CHD dans WCGS",chd69,c("Non","Oui"),TRUE,"wcgs_chd.png") decritQTparFacteur( titreQT="AGE dans WCGS", nomVarQT=age, unite="ans", titreQL="CHD", nomVarQL=chd69, labels=c("Non","Oui"), graphique=TRUE, fichier_image="wcgs1.png" ) # fin de decritQTparFacteurDESCRIPTION STATISTIQUE DE LA VARIABLE AGE dans WCGS Taille 3154 individus Moyenne 46.2787 ans Ecart-type 5.5240 ans Coef. de variation 12 % 1er Quartile 42.0000 ans Mediane 45.0000 ans 3eme Quartile 50.0000 ans iqr absolu 8.0000 ans iqr relatif 18.0000 % Minimum 39 ans Maximum 59 ans Tracé tige et feuilles The decimal point is at the | 39 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+136 40 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+147 41 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+103 42 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+92 43 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+85 44 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+105 45 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+56 46 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+40 47 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+17 48 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+34 49 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+4 50 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+5 51 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 52 | 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 53 | 000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 54 | 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 55 | 00000000000000000000000000000000000000000000000000000000000000000000000000000000 56 | 0000000000000000000000000000000000000000000000000000000000000000000000000000 57 | 000000000000000000000000000000000000000000000000000000000000000 58 | 00000000000000000000000000000000000000000000000000000000 59 | 00000000000000000000000000000000000000000000000 vous pouvez utiliser wcgs_age.png TRI A PLAT DE : CHD dans WCGS (ordre des modalités) Non Oui Total Effectif 2897 257 3154 Cumul Effectif 2897 3154 3154 Frequence (en %) 92 8 100 Cumul fréquences 92 100 100 VARIABLE : CHD dans WCGS (par fréquence décroissante) Non Oui Total Effectif 2897 257 3154 Cumul Effectif 2897 3154 3154 Frequence (en %) 92 8 100 Cumul fréquences 92 100 100 [1] "Non" "Oui" vous pouvez utiliser wcgs_chd.png VARIABLE QT AGE dans WCGS ,unit=ans VARIABLE QL CHD labels : Non Oui N Moy Unite Ect Cdv Q1 Med Q3 EIQ Min Max Global 3154 46.279 ans 5.523 12 42.000 45.000 50.000 8.000 39.000 59.000 Non 2897 46.082 ans 5.456 12 41.000 45.000 50.000 9.000 39.000 59.000 Oui 257 48.490 ans 5.790 12 44.000 49.000 53.000 9.000 39.000 59.000 Analysis of Variance Table Response: nomVarQT Df Sum Sq Mean Sq F value Pr(>F) ql 1 1369 1368.52 45.48 1.827e-11 *** Residuals 3152 94846 30.09 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Kruskal-Wallis rank sum test data: nomVarQT by ql Kruskal-Wallis chi-squared = 40.8787, df = 1, p-value = 1.62e-10
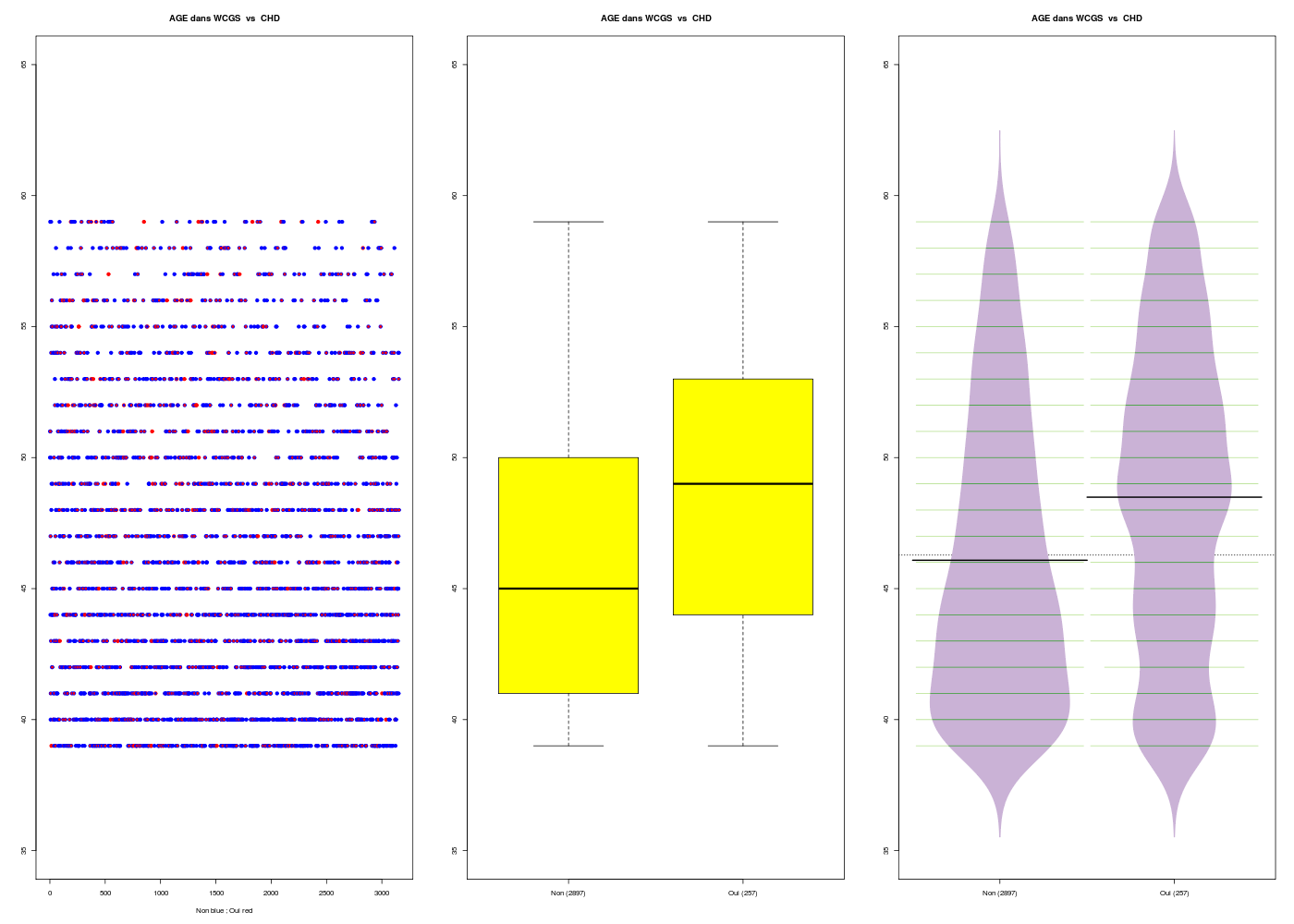
On peut en concure que pour les données présentées, l'AGE est assez homogène (cdv=12 %), peu étendu et non normal, et que la CHD est assez peu présente (8 %), avec une différence significative de CHD selon l'age (p<<0,0001).
Réalisons maintenant la régression logistique de la variable CHD69 (binaire) à l'aide de la seule variable AGE (continue) à l'aide de la fonction glm et dont les résultats peuvent être consultés via la fonction summary.glm. Comme il est d'usage de rapporter la log-vraisemblance du modèle, les intervalles de confiance des coefficients, le rapport de vraisemblance (LR) et le [pseudo]R2, nous utilisons, en plus des fonctions confint et logLik du package élémentaire stats les fonctions confint.glm() et lrm() des packages MASS et Design qui fournissent directement ces valeurs. Remarque : la fonction classique anova fournit aussi le LR (qu'elle nomme Deviance).
# lecture des données WCGS <- lit.dar("wcgs.dar") age <- WCGS$AGE chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) summary.glm( rlb ) anova( rlb ) # il manque la log-vraisemblance et les intervalles de confiance logLik( rlb ) library(MASS) confint( rlb ) # l'intervalle calculé par Stata dans le livre de Vittinghoff correspond # à l'intervalle sous hypothèse de normalité asymptotique confint.default( rlb ) library(Design) lrm( rlb )> rlb <- glm( formula = chd ~ age, family = binomial() ) > summary.glm( rlb ) Call: glm(formula = chd ~ age, family = binomial()) Deviance Residuals: Min 1Q Median 3Q Max -0.6208 -0.4545 -0.3668 -0.3292 2.4835 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -5.93952 0.54932 -10.813 < 2e-16 *** age 0.07442 0.01130 6.585 4.56e-11 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1781.2 on 3153 degrees of freedom Residual deviance: 1738.4 on 3152 degrees of freedom AIC: 1742.4 Number of Fisher Scoring iterations: 5 > anova( rlb ) Analysis of Deviance Table Model: binomial, link: logit Response: chd Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 3153 1781.2 age 1 42.888 3152 1738.4 > logLik( rlb ) 'log Lik.' -869.178 (df=2) > library(MASS) > confint( rlb ) 2.5 % 97.5 % (Intercept) -7.02449218 -4.86960992 age 0.05227351 0.09661197 > confint.default( rlb ) 2.5 % 97.5 % (Intercept) -7.01616019 -4.86287169 age 0.05227038 0.09657473 > library(Design) > lrm( rlb ) Logistic Regression Model lrm(formula = rlb) Frequencies of Responses Non Oui 2897 257 Obs Max Deriv Model L.R. d.f. P C Dxy Gamma Tau-a R2 Brier 3154 9e-08 42.89 1 0 0.62 0.24 0.252 0.036 0.031 0.074 Coef S.E. Wald Z P Intercept -5.93952 0.54932 -10.81 0 age 0.07442 0.01130 6.58 0Le rapport de côte p/(1-p) pour une augmentation de l'age d'un an s'obtient en prenant l'exponentielle du coefficient β1fois 1, soit ici exp(0.074*1) qui vaut à peu près 1,077 ; pour 10 ans, c'est exp(0.074*10) soit 2,105.
La probabilité d'avoir un trouble coronarien pour une personne de 55 ans se calcule avec la fonction logistique :
p(55) = exp(-5.940+0.074*55)/(1 + exp(-5.940+0.074*55)) = 0.1335417On pourra comparer ces résultats à ceux fournis par Sas :
OPTIONS nodate LINESIZE=256 PAGESIZE=50 NOCENTER FORMDLIM=' ' FORMCHAR='-----------' nonumber ; PROC IMPORT datafile="wcgs.xls" dbms=excel out=wcgs replace ; * Etude de l'age ; PROC MEANS data=wcgs N MEAN STD CV MIN MAX MAXDEC=2 ; var age ; * Etude de la cardiopathie coronarienne ; PROC FREQ data=wcgs ; table chd69 ; * Régression logistique de la cardiopathie coronarienne; * en fonction de l'age ; PROC LOGISTIC data=wcgs simple descending ; model chd69 = age / expb rsquare clparm=both ; units age = 1 5 10 20 ; RUN ;NOTE: SAS (r) Proprietary Software 9.2 (TS2M3) NOTE: Copyright (c) 2002-2008 by SAS Institute Inc., Cary, NC, USA. Licensed to LICENCE GRATUITE ETUDIANTS PROFS MENR, Site 50101271. NOTE: La session est exécutée sur la plate-forme XP_PRO . NOTE: L'initialisation de SAS a utilisé : temps réel 0.65 secondes temps UC 0.60 secondes 1 /* TimeStamp (dos) : 30 Octobre 10 17:33 ; z:\wcgs.sas */ 2 3 OPTIONS nodate LINESIZE=256 PAGESIZE=50 NOCENTER FORMDLIM=' ' FORMCHAR='-----------' nonumber ; 4 5 PROC IMPORT datafile="wcgs.xls" dbms=excel out=wcgs replace ; 6 7 * Etude de l'age ; 8 NOTE: WORK.WCGS data set was successfully created. NOTE: Procédure IMPORT a utilisé (Durée totale du traitement) : temps réel 0.95 secondes temps UC 0.67 secondes 9 PROC MEANS data=wcgs N MEAN STD CV MIN MAX MAXDEC=2 ; 10 var age ; 11 12 * Etude de la cardiopathie coronarienne ; 13 NOTE: 3154 observation(s) lue(s) dans la table WORK.WCGS. NOTE: La procédure MEANS a été imprimée en page 1. NOTE: Procédure MEANS a utilisé (Durée totale du traitement) : temps réel 0.25 secondes temps UC 0.13 secondes 14 PROC FREQ data=wcgs ; 15 table chd69 ; 16 17 * Régression logistique de la cardiopathie coronarienne; 18 * en fonction de l'age ; 19 NOTE: 3154 observation(s) lue(s) dans la table WORK.WCGS. NOTE: La procédure FREQ a été imprimée en page 2. Le Système SAS NOTE: Procédure FREQ a utilisé (Durée totale du traitement) : temps réel 0.03 secondes temps UC 0.03 secondes 20 PROC LOGISTIC data=wcgs simple descending ; 21 model chd69 = age / expb rsquare clparm=both ; 22 NOTE: PROC LOGISTIC is modeling the probability that chd69=1. NOTE: Critère de convergence (GCONV=1E-8) respecté. NOTE: 3154 observation(s) lue(s) dans la table WORK.WCGS. NOTE: La procédure LOGISTIC a été imprimée en pages 3-5. NOTE: Procédure LOGISTIC a utilisé (Durée totale du traitement) : temps réel 0.59 secondes temps UC 0.57 secondes 23 PROC LOGISTIC data=wcgs descending ; 24 model chd69 = age ; 25 units age = 1 5 10 20 ; 26 27 RUN ; NOTE: PROC LOGISTIC is modeling the probability that chd69=1. NOTE: Critère de convergence (GCONV=1E-8) respecté. NOTE: 3154 observation(s) lue(s) dans la table WORK.WCGS. NOTE: La procédure LOGISTIC a été imprimée en pages 6-7. NOTE: Procédure LOGISTIC a utilisé (Durée totale du traitement) : temps réel 0.51 secondes temps UC 0.50 secondes NOTE: SAS Institute Inc., SAS Campus Drive, Cary, NC USA 27513-2414 NOTE: Le Système SAS a utilisé : temps réel 3.12 secondes temps UC 2.56 secondesLe Système SAS Procédure MEANS Variable d'analyse : age Coef de N Moyenne Ecart-type variation Minimum Maximum ------------------------------------------------------------------------------------ 3154 46.28 5.52 11.94 39.00 59.00 ------------------------------------------------------------------------------------ Procédure FREQ Fréquence Pctage. chd69 Fréquence Pourcentage cumulée cumulé ----------------------------------------------------------------- 0 2897 91.85 2897 91.85 1 257 8.15 3154 100.00 Procédure LOGISTIC Informations sur le modèle Table WORK.WCGS Variable de réponse chd69 Nombre de niveaux de réponse 2 Modèle logit binaire Technique d'optimisation Score de Fisher Nombre d'observations lues 3154 Nombre d'observations utili 3154 Profil de réponse Valeur Fréquence ordonnée chd69 totale 1 1 257 2 0 2897 La probabilité modélisée est chd69=1. Statistiques descriptives pour variables continues Ecart- Variable chd69 Moyenne type Minimum Maximum age 1 48.490272 5.801477 39.000000 59.000000 0 46.082499 5.456675 39.000000 59.000000 ------------------------------------------------------------------------------------------ Total 46.278694 5.524045 39.000000 59.000000 Etat de convergence du modèle Critère de convergence (GCONV=1E-8) respecté. Statistiques d'ajustement du modèle Constante Constante et Critère uniquement covariables AIC 1783.244 1742.356 SC 1789.300 1754.469 -2 Log L 1781.244 1738.356 R carré 0.0135 R carré remis à l'échelle max. 0.0313 Test de l'hypothèse nulle globale : BETA=0 Test Khi-2 DDL Pr > Khi-2 Rapp. de vrais. 42.8876 1 <.0001 Score 44.8616 1 <.0001 Wald 43.3584 1 <.0001 Estimations par l'analyse du maximum de vraisemblance Valeur Erreur Khi-2 Paramètre DDL estimée type de Wald Pr > Khi-2 Exp(Est) Intercept 1 -5.9395 0.5493 116.9098 <.0001 0.003 age 1 0.0744 0.0113 43.3584 <.0001 1.077 Estimations des rapports de cotes Valeur estimée Intervalle de confiance Effet du point de Wald à 95 % age 1.077 1.054 1.101 Association des probabilités prédites et des réponses observées Pourcentage concordant 59.5 D de Somers 0.240 Pourcentage discordant 35.6 Gamma 0.252 Pourcentage lié 4.9 Tau-a 0.036 Paires 744529 c 0.620 Intervalle de confiance de vraisemblance du profil pour les paramètres Valeur Paramètre estimée Intervalle de confiance à 95 % Intercept -5.9395 -7.0245 -4.8696 age 0.0744 0.0523 0.0966 Intervalle de confiance de Wald pour les paramètres Valeur Paramètre estimée Intervalle de confiance à 95 % Intercept -5.9395 -7.0162 -4.8629 age 0.0744 0.0523 0.0966 Rapports de cotes Valeur Effet Unité estimée age 1.0000 1.077 age 5.0000 1.451 age 10.0000 2.105 age 20.0000 4.430Pour savoir si c'est un bon modèle, on peut essayer un seuil de séparation à 0,5 et calculer le taux de bien-classés, comme précédemment :
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) summary.glm( rlb ) anova( rlb ) # prédictions et taux total de bien classés ypred <- predict(rlb,newdata=data.frame(CHD69=WCGS$CHD69),type="response") tdr <- data.frame(chdOrg=WCGS$CHD69,chdPred=ifelse(ypred<0.5,0,1)) cats("Matrice de confusion") with(tdr,print(table( chdOrg, chdPred ))) cats("Nombre et taux de bien classés") nbTot <- nrow(tdr) nbBc <- sum(tdr$chdOrg==tdr$chdPred) pctBc <- 100*nbBc/nbTot cat(nbBc,"bien classés sur",nbTot,"individus en tout, soit",pctBc,"%\n")Call: glm(formula = chd ~ age, family = binomial()) Deviance Residuals: Min 1Q Median 3Q Max -0.6209 -0.4545 -0.3669 -0.3292 2.4835 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -5.93952 0.54932 -10.813 < 2e-16 *** age 0.07442 0.01130 6.585 4.56e-11 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1781.2 on 3153 degrees of freedom Residual deviance: 1738.4 on 3152 degrees of freedom AIC: 1742.4 Number of Fisher Scoring iterations: 5 Analysis of Deviance Table Model: binomial, link: logit Response: chd Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 3153 1781.2 age 1 42.888 3152 1738.4 Matrice de confusion ==================== chdPred chdOrg 0 0 2897 1 257 Nombre et taux de bien classés ============================== 2897 bien classés sur 3154 individus en tout, soit 91.85162 %Comme pour une régression linéaire, il n'est pas possible d'utiliser la fonction plot() pour afficher le modèle parce que cette fonction plot() affiche l'analyse graphique des résidus. Il faut donc construire des points où x (l'age) couvre une grande plage de variation et où y est la valeur prédite par ce modèle, soit le code R suivant :
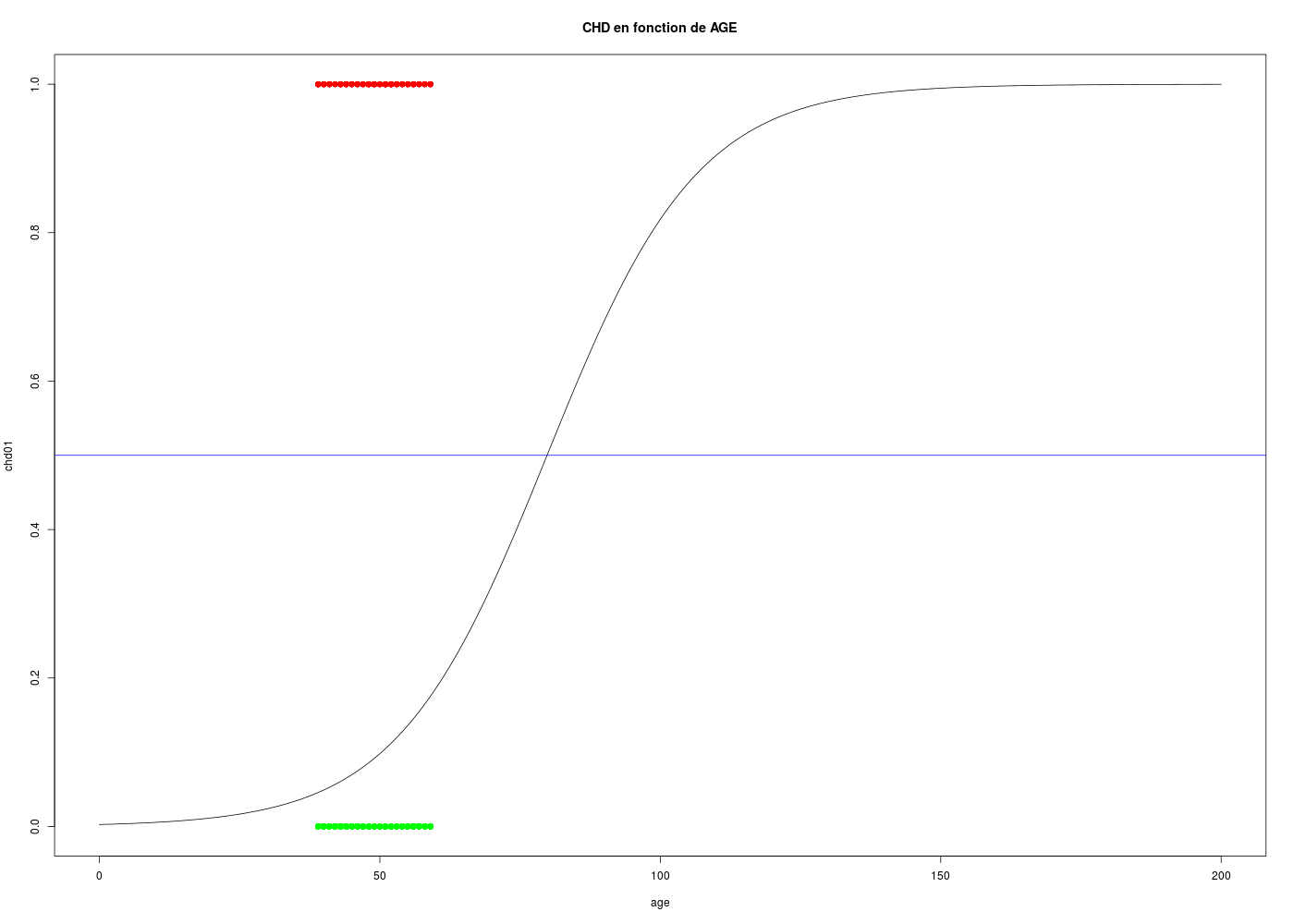
## tracé d'une régression logistique binaire # chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # calcul du modèle régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) # tracé de la variable binaire en fonction de la variable explicative chd01 <- WCGS$CHD69 couleurCHD <- ifelse(chd01==0,"green","red") plot( chd01 ~ age,type="p",main="CHD en fonction de AGE",pch=19,col=couleurCHD,xlim=c(0,200)) # tracé de la fonction logistique du modèle x <- data.frame( age=seq(from=0,to=200,length.out=1000)) y <- predict(rlb,x,"response") points( as.numeric(y) ~ unlist(x), col="black", type="l") # valeur-seuil par défaut : 0.5 abline(h=0.5,col="blue")On se rend sans doute compte ici que la régression logistique n'est pas "bonne".
La sensibilité et la spécificité sont des indicateurs diagnostiques qui permettent de décrire la performance d'une prédiction. Ce sont deux indicateurs parmi de nombreux autres, obtenus à partir des 4 valeurs entières VP, FP, FN et VP. Voir notre page étude de valeurs diagnostiques pour plus d'explications avec des exemples numériques.
ROC signifie Receiver Operating Characteristic (mais la page wiki en est plus complète, comme souvent) alors que AUROC signifie Area Under the ROC Curve. Une courbe ROC modélise les performances de la prédiction en fonction des différents seuils possibles et l'AUROC est l'aire sous la courbe. Cette aire est utilisée comme indicateur global de la performance, moins sensible à la prévalence que la sensibilité et la spécificité.
On lira avec intérêt les transparents de E. Rakotomalala et, pour une approche plus bioinformatique : évaluation proteome avant de regarder notre page de calcul d'AUROC en direct pour se familiariser avec ces notions.
Pour calculer une AUROC avec R, de nombreux packages existent, par exemple le package limma avec sa fonction auROC() et le package AUC et sa fonction auc() :
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE chdbin <- WCGS$CHD69 # en 0/1 # recodage de chd chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) # prédiction ypred <- predict(rlb,newdata=data.frame(age),type="response") # auroc via le package limma library(limma) cat(" AUROC (pkg limma) = ", auROC(WCGS$CHD69,ypred),"\n") detach("package:limma") ; # auroc via le package AUC library(AUC) cat(" AUROC (pkg AUC) = ", auc(roc(ypred,chd)),"\n") detach("package:AUC") ;AUROC (pkg limma) = 0.6238682 AUROC (pkg AUC) = 0.6199228Il est donc relativement clair que cette modélisation n'est pas très bonne, puisque l'AUROC ne vaut "que" environ 0,6. A titre de comparaison, l'AUROC de la modélisation précédente, pour les données pg.dar était de 0,985..
Si on veut disposer de l'intervalle de confiance de l'AUROC, il faut se tourner vers le package pROC avec sa fonction ci.auc() ; ce package fournit également le tracé de la courbe ROC via la fonction plot.roc(). Pour calculer l'odds ratio, le package questionp fournit la fonction odds.ratio(). A l'aide de notre fonction sensSpec() il est possible de connaitre les différents seuils intéressants :
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE chdbin <- WCGS$CHD69 # en 0/1 # recodage de chd chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) # prédiction ypred <- predict(rlb,newdata=data.frame(age),type="response") #################################################### # odds ratio library(questionr) odds.ratio(rlb) detach("package:questionr") ; # intervalle de confiance de l'AUROC (package pROC) library(pROC) print(ci.auc(chdbin,age)) # tracé de la courbe ROC (package pROC) gr("auroc1.png") ; plot.roc(x=chdbin,predictor=age,print.thres="best",print.auc=TRUE) dev.off() detach("package:pROC") ; # seuils remarquables avec notre fonction sensSpec sensSpec(chdbin,age,FALSE) # tracés avec seuils (package PresenceAbsence) library(PresenceAbsence) dfauc <- data.frame(cbind(1:length(age),chdbin,ypred)) gr("auroc2.png") ; auc.roc.plot(dfauc,opt.methods=1:11) dev.off() detach("package:PresenceAbsence") ;OR 2.5 % 97.5 % p (Intercept) 0.003 0.001 0.008 < 2.2e-16 *** age 1.077 1.054 1.101 4.558e-11 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 95% CI: 0.5832-0.6566 (DeLong) Call: plot.roc.default(x = chdbin, predictor = age, print.thres = "best", print.auc = TRUE) Data: age in 2897 controls (chdbin 0) < 257 cases (chdbin 1). Area under the curve: 0.6199 Seuils remarquables parmi les 24 seuils vus CUTOFF CRIT VP FP FN VN TOTAL SPEC 1-SPEC SENS VPP VPN YOUDEN OA 0.5000 IO 257 2897 0 0 3154 0.000000 1.000000 1.000000 0.081484 1.000000 0.000000 0.081484 42.0000 IN 209 1947 48 950 3154 0.327925 0.672075 0.813230 0.096939 0.951904 0.141155 0.367470 47.0000 IY 152 1051 105 1846 3154 0.637211 0.362789 0.591440 0.126351 0.946181 0.228651 0.633481 58.0000 IP 11 36 246 2861 3154 0.987573 0.012427 0.042802 0.234043 0.920824 0.030375 0.910590 59.0000 OA 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516
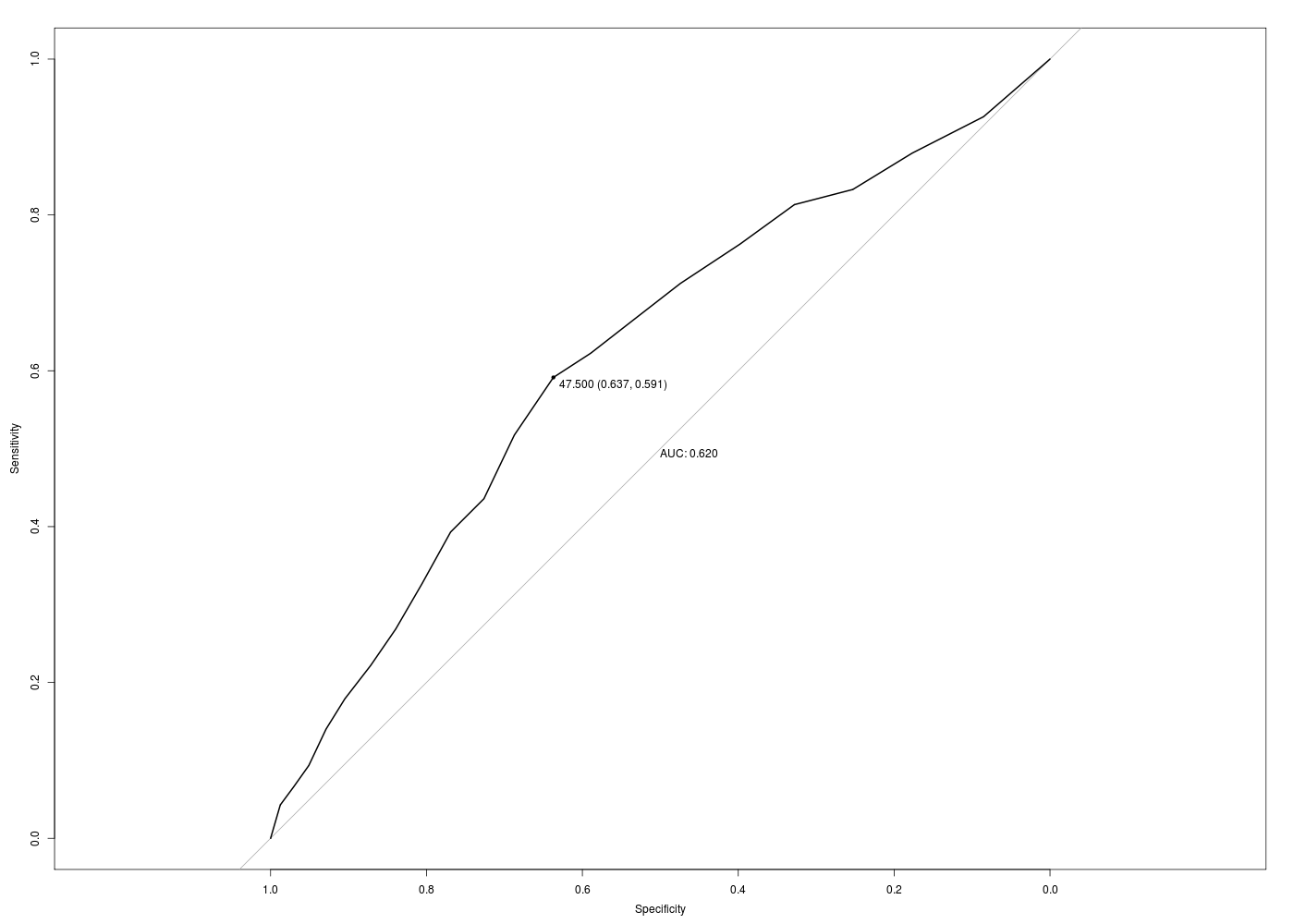
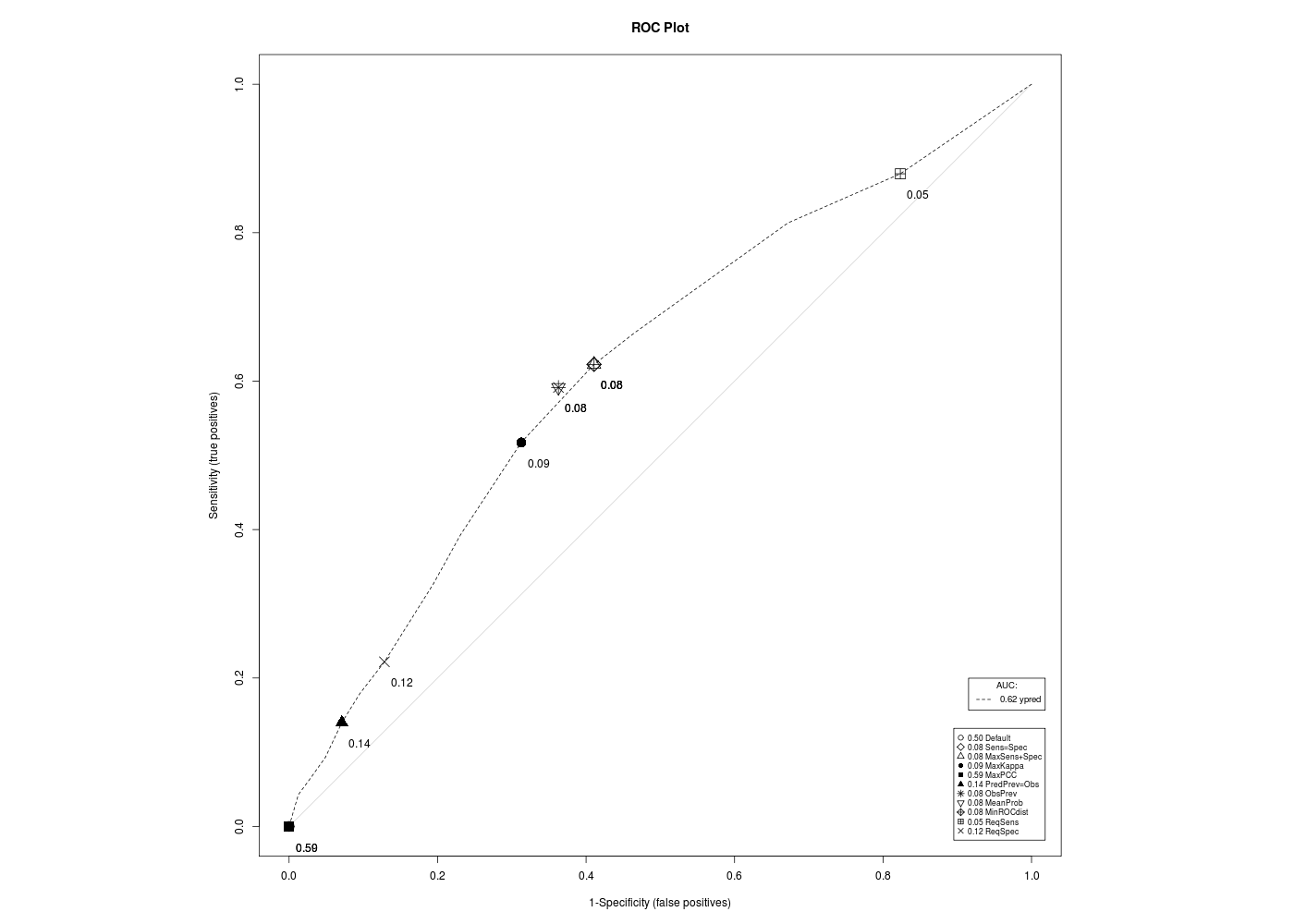
Une fois le seuil choisi, on peut produire à partir de la RLB une nouvelle classification et la comparer à la classification originale. Notre fonction decritModeleLogistiqueBinaire() se charge d'automatiser tous les calculs. Elle utilise le package ROCR :
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") age <- WCGS$AGE chdbin <- WCGS$CHD69 # en 0/1 # recodage de chd chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # régression logistique rlb <- glm( formula = chd ~ age, family = binomial() ) # prédiction ypred <- predict(rlb,newdata=data.frame(age),type="response") #################################################### # détails sur la RLB avec la fonction (gH) # qui utilise le package ROCR decritModeleLogistiqueBinaire( dfRLB=data.frame(chdbin,age), details=TRUE, sigvar=TRUE, seuil=0.0801 ) # fin de decritModeleLogistiqueBinaire detach("package:ROCR") ;TRI A PLAT DE : Cible 0/1 (ordre des modalités) 0 1 Total Effectif 2897 257 3154 Cumul Effectif 2897 3154 3154 Frequence (en %) 92 8 100 Cumul fréquences 92 100 100 VARIABLE : Cible 0/1 (par fréquence décroissante) 0 1 Total Effectif 2897 257 3154 Cumul Effectif 2897 3154 3154 Frequence (en %) 92 8 100 Cumul fréquences 92 100 100 [1] "0" "1" Call: glm(formula = qlbin ~ ., family = "binomial", data = dfRLB[, -1, drop = FALSE]) Deviance Residuals: Min 1Q Median 3Q Max -0.6209 -0.4545 -0.3669 -0.3292 2.4835 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -5.93952 0.54932 -10.813 < 2e-16 *** age 0.07442 0.01130 6.585 4.56e-11 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1781.2 on 3153 degrees of freedom Residual deviance: 1738.4 on 3152 degrees of freedom AIC: 1742.4 Number of Fisher Scoring iterations: 5 Auroc (ROCR) = 0.6199228 Estimate Std. Error z value Pr(>|z|) 2.5 % 97.5 % etendue (Intercept) -5.93951594 0.54931839 -10.812520 3.003058e-27 -7.02449218 -4.86960992 2.15488226 age 0.07442256 0.01130234 6.584705 4.557900e-11 0.05227351 0.09661197 0.04433846 Détails par seuil (gH) Liste des seuils et de leurs caractéristiques CUTOFF CRIT VP FP FN VN TOTAL SPEC 1-SPEC SENS VPP VPN YOUDEN OA 0.0000 257 2897 0 0 3154 0.000000 1.000000 1.000000 0.081484 1.000000 0.000000 0.081484 0.0458 238 2650 19 247 3154 0.085261 0.914739 0.926070 0.082410 0.928571 0.011331 0.153773 0.0491 238 2650 19 247 3154 0.085261 0.914739 0.926070 0.082410 0.928571 0.011331 0.153773 0.0527 226 2385 31 512 3154 0.176735 0.823265 0.879377 0.086557 0.942910 0.056112 0.233989 0.0566 IN 209 1947 48 950 3154 0.327925 0.672075 0.813230 0.096939 0.951904 0.141155 0.367470 0.0607 196 1745 61 1152 3154 0.397653 0.602347 0.762646 0.100979 0.949711 0.160299 0.427394 0.0651 183 1523 74 1374 3154 0.474284 0.525716 0.712062 0.107268 0.948895 0.186346 0.493659 0.0698 171 1349 86 1548 3154 0.534346 0.465654 0.665370 0.112500 0.947368 0.199716 0.545022 0.0747 171 1349 86 1548 3154 0.534346 0.465654 0.665370 0.112500 0.947368 0.199716 0.545022 0.0801 IY 152 1051 105 1846 3154 0.637211 0.362789 0.591440 0.126351 0.946181 0.228651 0.633481 0.0857 152 1051 105 1846 3154 0.637211 0.362789 0.591440 0.126351 0.946181 0.228651 0.633481 0.0917 133 906 124 1991 3154 0.687263 0.312737 0.517510 0.128008 0.941371 0.204772 0.673431 0.0981 112 793 145 2104 3154 0.726269 0.273731 0.435798 0.123757 0.935527 0.162066 0.702600 0.1049 84 563 173 2334 3154 0.805661 0.194339 0.326848 0.129830 0.930993 0.132509 0.766646 0.1121 69 465 188 2432 3154 0.839489 0.160511 0.268482 0.129213 0.928244 0.107972 0.792961 0.1197 69 465 188 2432 3154 0.839489 0.160511 0.268482 0.129213 0.928244 0.107972 0.792961 0.1278 46 276 211 2621 3154 0.904729 0.095271 0.178988 0.142857 0.925494 0.083717 0.845593 0.1363 46 276 211 2621 3154 0.904729 0.095271 0.178988 0.142857 0.925494 0.083717 0.845593 0.1453 36 206 221 2691 3154 0.928892 0.071108 0.140078 0.148760 0.924107 0.068970 0.864616 0.1548 24 142 233 2755 3154 0.950984 0.049016 0.093385 0.144578 0.922021 0.044369 0.881103 0.1648 IP 11 36 246 2861 3154 0.987573 0.012427 0.042802 0.234043 0.920824 0.030375 0.910590 0.1753 OA 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516 0.5000 IO 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516 1.0000 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516 Seuils remarquables parmi les 24 seuils vus CUTOFF CRIT VP FP FN VN TOTAL SPEC 1-SPEC SENS VPP VPN YOUDEN OA 0.0566 IN 209 1947 48 950 3154 0.327925 0.672075 0.813230 0.096939 0.951904 0.141155 0.367470 0.0801 IY 152 1051 105 1846 3154 0.637211 0.362789 0.591440 0.126351 0.946181 0.228651 0.633481 0.1648 IP 11 36 246 2861 3154 0.987573 0.012427 0.042802 0.234043 0.920824 0.030375 0.910590 0.1753 OA 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516 0.5000 IO 0 0 257 2897 3154 1.000000 0.000000 0.000000 1.000000 0.918516 0.000000 0.918516 voici les 2 variables significatives : ","(Intercept)","age Analyse des valeurs binaires prédites pour le seuil 0.0801 ============================================================ pct bien classés = 63.34813 Comparaison binaire org/prédite Matrice de pondération C01 C02 L01 0 1 L02 1 0 Fréquences initiales de référence = score1 freqref 0 1 2897 257 Fréquences correspondantes calculées = score2 0 1 1846 152 Matrice de discordance 0 1 Sum 0 1846 1051 2897 1 105 152 257 Sum 1951 1203 3154 score1 vs score2 score moyen de discordance 0.367 (0.3665187) ; 1998 bien classés sur 3154 soit % BC = 63.3 taux des 1998 bien classés sur 3154 : 63.34813 taux des 1846 bien classés sur 2897 pour la modalité 0 : 63.72109 taux des 152 bien classés sur 257 pour la modalité 1 : 59.14397 [1] 0.6199228Il n'y a a priori aucun problème pour modéliser la dépendance de la variable binaire CHD à partir de la variable ARCUS par une régression logistique, mais il est bon de commencer par réaliser le tri croisé de ces variables.
# données arcus <- factor(WCGS$ARCUS,labels=c("Non","Oui")) chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # tri croisé tc <- table(chd,arcus) print(tc) print(chisq.test(tc)) triCroise("ARCUS",WCGS$ARCUS,"Non Oui","CHD",WCGS$CHD69,"Non oui") # régression logistique rlb <- glm( formula = chd ~ arcus, family = binomial() ) print( summary.glm( rlb ) ) print( anova( rlb ) ) #################################################### # auroc library(pROC) print(auc(chdbin,as.ordered(arcus))) print(ci.auc(chdbin,as.ordered(arcus))) detach("package:pROC") ; # odds ratio library(questionr) odds.ratio(rlb) detach("package:questionr") ; # risque relatif etc. library(epiR) epi.2by2(tc) detach("package:epiR") ;arcus chd Non Oui Non 2058 839 Oui 153 102 Pearson's Chi-squared test with Yates' continuity correction data: tc X-squared = 13.1161, df = 1, p-value = 0.0002928 TRI CROISE DES QUESTIONS : ARCUS (en ligne) CHD (en colonne) Effectifs Non oui Non 2058 153 Oui 839 102 Effectifs avec totaux Non oui Total Non 2058 153 2211 Oui 839 102 941 Total 2897 255 3152 Valeurs en % du total Non oui TOTAL Non 65 5 70 Oui 27 3 30 TOTAL 92 8 100 Call: glm(formula = chd ~ arcus, family = binomial()) Deviance Residuals: Min 1Q Median 3Q Max -0.4790 -0.4790 -0.3787 -0.3787 2.3112 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -2.5991 0.0838 -31.016 < 2e-16 *** arcusOui 0.4918 0.1342 3.664 0.000248 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1771.2 on 3151 degrees of freedom Residual deviance: 1758.2 on 3150 degrees of freedom (2 observations deleted due to missingness) AIC: 1762.2 Number of Fisher Scoring iterations: 5 Analysis of Deviance Table Model: binomial, link: logit Response: chd Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 3151 1771.2 arcus 1 12.984 3150 1758.2 Area under the curve: 0.5552 95% CI: 0.524-0.5864 (DeLong) OR 2.5 % 97.5 % p (Intercept) 0.074 0.063 0.087 < 2.2e-16 *** arcusOui 1.635 1.254 2.124 0.0002483 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Disease + Disease - Total Inc risk * Odds Exposed + 2058 839 2897 71.0 2.45 Exposed - 153 102 255 60.0 1.50 Total 2211 941 3152 70.1 2.35 Point estimates and 95 % CIs: --------------------------------------------------------- Inc risk ratio 1.18 (1.07, 1.31) Odds ratio 1.64 (1.24, 2.14) Attrib risk * 11.04 (4.8, 17.27) Attrib risk in population * 10.15 (3.92, 16.37) Attrib fraction in exposed (%) 15.54 (6.39, 23.8) Attrib fraction in population (%) 14.46 (5.87, 22.28) --------------------------------------------------------- * Cases per 100 population unitsPar contre, si on veut utiliser la variable AGEC, il faut commencer par la convertir en facteur afin de pouvoir réaliser la RLB sur chaque modalité.
# données age <- WCGS$AGE agec <- factor(WCGS$AGEC,labels=paste("Classe",0:4),ordered=TRUE) chd <- factor(WCGS$CHD69,labels=c("Non","Oui")) # tri croisé tc <- table(chd,agec) print(tc) print(chisq.test(tc)) triCroise("AGE (en 5 classes)",WCGS$AGEC,"Classe0 Classe1 Classe2 Classe3 Classe4","CHD",WCGS$CHD69,"Non oui") #################################################### # régression logistique FAUSSE (age est traitée en quantitative) rlb <- glm( formula = chd ~ age, family = binomial() ) print( summary.glm( rlb ) ) print( anova( rlb ) ) #################################################### # régression logistique CORRECTE (agec est traitée en qualitative) rlb <- glm( formula = chd ~ agec, family = binomial() ) print( summary.glm( rlb ) ) print( anova( rlb ) ) # auroc library(pROC) catn() print(auc(chdbin,agec)) print(ci.auc(chdbin,agec)) catn() # odds ratio library(questionr) odds.ratio(rlb) detach("package:questionr") ;agec chd Classe 0 Classe 1 Classe 2 Classe 3 Classe 4 Non 512 1036 680 463 206 Oui 31 55 70 65 36 Pearson's Chi-squared test data: tc X-squared = 46.6534, df = 4, p-value = 1.801e-09 TRI CROISE DES QUESTIONS : AGE (en 5 classes) (en ligne) CHD (en colonne) Effectifs Non oui Classe0 512 31 Classe1 1036 55 Classe2 680 70 Classe3 463 65 Classe4 206 36 Effectifs avec totaux Non oui Total Classe0 512 31 543 Classe1 1036 55 1091 Classe2 680 70 750 Classe3 463 65 528 Classe4 206 36 242 Total 2897 257 3154 Valeurs en % du total Non oui TOTAL Classe0 16 1 17 Classe1 33 2 35 Classe2 22 2 24 Classe3 15 2 17 Classe4 7 1 8 TOTAL 92 8 100 Call: glm(formula = chd ~ age, family = binomial()) Deviance Residuals: Min 1Q Median 3Q Max -0.6209 -0.4545 -0.3669 -0.3292 2.4835 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -5.93952 0.54932 -10.813 < 2e-16 *** age 0.07442 0.01130 6.585 4.56e-11 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1781.2 on 3153 degrees of freedom Residual deviance: 1738.4 on 3152 degrees of freedom AIC: 1742.4 Number of Fisher Scoring iterations: 5 Analysis of Deviance Table Model: binomial, link: logit Response: chd Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 3153 1781.2 age 1 42.888 3152 1738.4 Call: glm(formula = chd ~ agec, family = binomial()) Deviance Residuals: Min 1Q Median 3Q Max -0.5676 -0.4427 -0.3429 -0.3216 2.4444 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -2.34428 0.06908 -33.938 < 2e-16 *** agec.L 0.97791 0.17437 5.608 2.05e-08 *** agec.Q 0.09326 0.16193 0.576 0.5647 agec.C -0.27984 0.14615 -1.915 0.0555 . agec^4 0.16808 0.13208 1.273 0.2032 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1781.2 on 3153 degrees of freedom Residual deviance: 1736.3 on 3149 degrees of freedom AIC: 1746.3 Number of Fisher Scoring iterations: 5 Analysis of Deviance Table Model: binomial, link: logit Response: chd Terms added sequentially (first to last) Df Deviance Resid. Df Resid. Dev NULL 3153 1781.2 agec 4 44.946 3149 1736.3 Area under the curve: 0.6141 95% CI: 0.5783-0.6499 (DeLong) OR 2.5 % 97.5 % p (Intercept) 0.096 0.084 0.110 < 2.2e-16 *** agec.L 2.659 1.890 3.752 2.045e-08 *** agec.Q 1.098 0.794 1.500 0.56467 agec.C 0.756 0.567 1.007 0.05553 . agec^4 1.183 0.912 1.532 0.20317 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Exercice volontairement non détaillé sur le site. On fournit juste le code R solution.
# chargement des fonctions gH : source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données WCGS <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/wcgs.dar") # sélection des données (on en profite pour enlever les NA) lesv <- c("CHD69","AGE","CHOL","SBP","BMI","SMOKE") wcgs <- na.omit( WCGS[,lesv] ) # définition de la matrice des résultats nbv <- ncol(wcgs) -1 mdr <- data.frame(matrix(nrow=nbv,ncol=2)) names(mdr) <- c("AUROC","AIC") row.names(mdr) <- names(wcgs)[-1] # on utilise une boucle pour stocker les AUROC library(limma) # pour la fonction auROC for (idv in (1:nbv)) { rlb <- glm( wcgs$CHD69 ~ wcgs[,1+idv], family="binomial" ) # re <- summary(rlb) ypred <- predict(rlb,newdata=wcgs,type="response") mdr[idv , 1 ] <- auROC( wcgs$CHD69 ,ypred) mdr[idv , 2 ] <- rlb$aic } # fin pour idv # tri par AUROC décroissante idx <- order(mdr[,1],decreasing=TRUE) mdr <- mdr[idx,] cats("Meilleures régressions logistiques simples pour CHD69 :") print( round(mdr,2) ) # analyses complémentaires mdc(wcgs) # matrice des corrélations linéaires #gr("wcgs_pairs1.png") #pairsi(wcgs) #dev.off() # meilleur sous-ensemble de régression library(MASS) # pour la fonction stepAIC mrlb1 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="forward" , trace=5) mrlb2 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="backward", trace=5) mrlb3 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="both" , trace=5) ############################################################################################# # # on utilise maintenant 7 variables # ############################################################################################# catss("Analyse avec 7 variables") lesv2 <- c("CHD69","AGE","CHOL","SBP","BMI","SMOKE","ARCUS","DIBPAT") wcgs <- na.omit( WCGS[,lesv2] ) mdc(wcgs) # matrice des corrélations linéaires nbv <- ncol(wcgs) -1 mdr <- data.frame(matrix(nrow=nbv,ncol=2)) names(mdr) <- c("AUROC","AIC") row.names(mdr) <- names(wcgs)[-1] # on utilise une boucle pour stocker les AUROC library(limma) # pour la fonction auROC for (idv in (1:nbv)) { rlb <- glm( wcgs$CHD69 ~ wcgs[,1+idv], family="binomial" ) # re <- summary(rlb) ypred <- predict(rlb,newdata=wcgs,type="response") mdr[idv , 1 ] <- auROC( wcgs$CHD69 ,ypred) mdr[idv , 2 ] <- rlb$aic } # fin pour idv # tri par AUROC décroissante idx <- order(mdr[,1],decreasing=TRUE) mdr <- mdr[idx,] cats("Meilleures régressions logistiques simples pour CHD69 :") print( round(mdr,2) ) mrlb4 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="forward" , trace=5) mrlb5 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="backward", trace=5) mrlb6 <- stepAIC( glm( wcgs$CHD69 ~ . , data=wcgs[,-1], family="binomial" ) , direction="both" , trace=5) # auroc et AIC pour les 7 variables rlb <- glm( wcgs$CHD69 ~ .,data=wcgs[,-1], family="binomial" ) ypred <- predict(rlb,newdata=wcgs,type="response") cat("Auroc globale \n") print( c(auROC( wcgs$CHD69 ,ypred), rlb$aic ))Meilleures régressions logistiques simples pour CHD69 : ======================================================= AUROC AIC CHOL 0.66 703.84 SBP 0.64 724.07 AGE 0.62 735.22 SMOKE 0.62 757.56 BMI 0.57 768.15 Matrice des corrélations au sens de Pearson pour 3154 lignes et 6 colonnes CHD69 AGE CHOL SBP BMI SMOKE CHD69 1.000 AGE 0.119 1.000 CHOL 0.163 0.089 1.000 SBP 0.133 0.166 0.123 1.000 BMI 0.062 0.027 0.071 0.288 1.000 SMOKE 0.085 0.005 0.097 0.003 -0.142 1.000
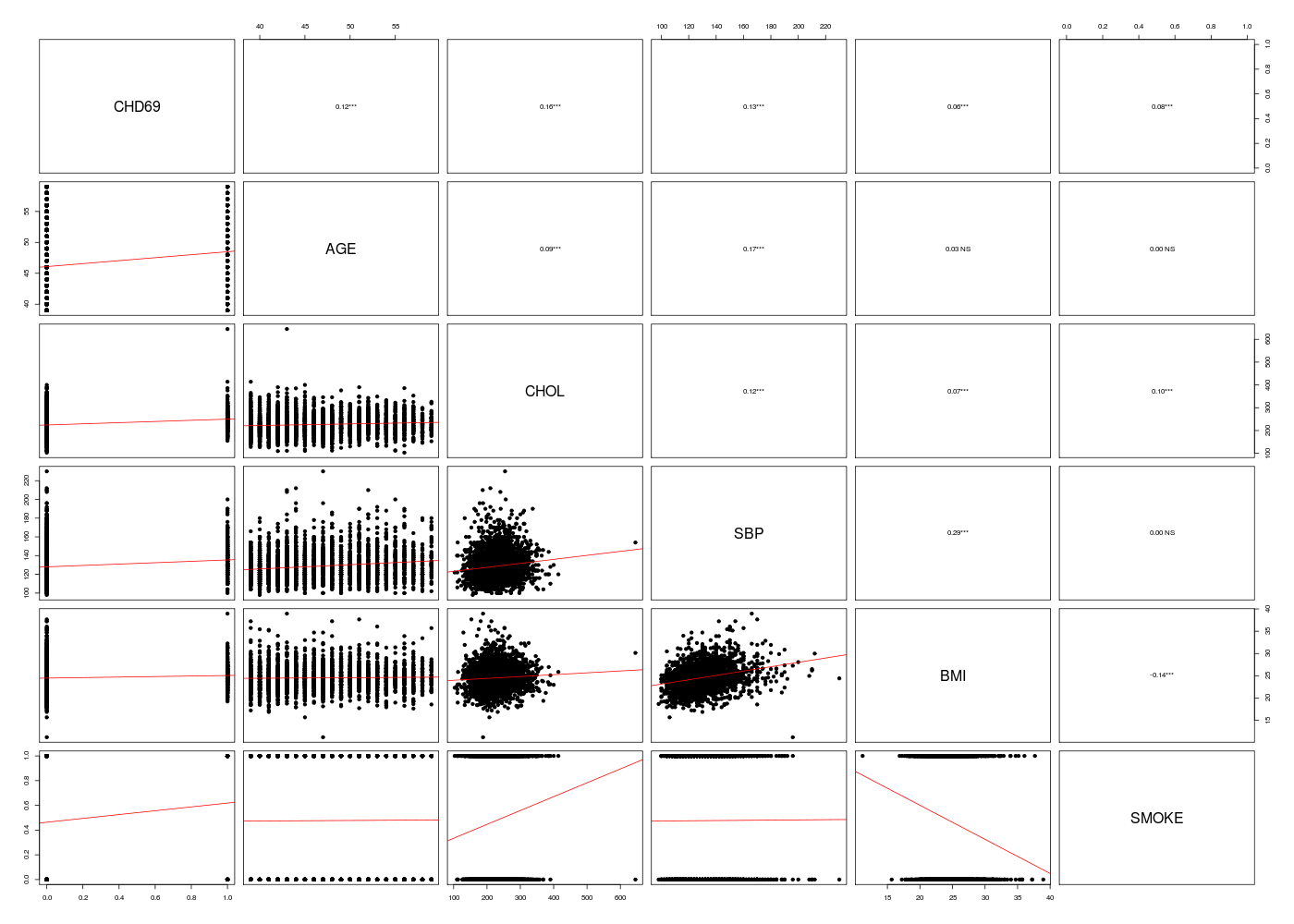
# lecture des données WCGS <- lit.dar("wcgs.dar") lesv1 <- c("AGE","CHOL","SBP","BMI","SMOKE") lesv2 <- c("ARCUS","DIBPAT") wcgs <- WCGS[,c(lesv1,lesv2)] # analyses préliminaires wcgs <- cbind(WCGS$CHD69,wcgs) names(wcgs)[1] <- "CHD69" mdc(wcgs) gr("wcgs_pairs2.png") pairsi(wcgs) dev.off() # meilleur modèle rchModeleLogistique(df=wcgs)Matrice des corrélations au sens de Pearson pour 3154 lignes et 8 colonnes CHD69 AGE CHOL SBP BMI SMOKE ARCUS DIBPAT CHD69 1.000 AGE 0.119 1.000 CHOL 0.163 0.089 1.000 SBP 0.133 0.166 0.123 1.000 BMI 0.062 0.027 0.071 0.288 1.000 SMOKE 0.085 0.005 0.097 0.003 -0.142 1.000 ARCUS 0.066 0.187 0.121 0.034 -0.035 0.073 1.000 DIBPAT 0.112 0.088 0.057 0.077 0.028 0.061 0.044 1.000 RStudioGD 2 AUROC (Intercept) AGE CHOL SBP BMI SMOKE ARCUS DIBPAT AIC M07V00 0.7503843 -12.274385 0.05718452 0.01038885 0.01821424 0.05948104 0.5986052 0.2190833 0.7021576 1594.445 M07V01 0.6199228 -5.939516 0.07442256 NA NA NA NA NA NA 1742.356 M07V02 0.6624719 -5.359022 NA 0.01244778 NA NA NA NA NA 1706.423 M07V03 0.6313891 -5.926461 NA NA 0.02667129 NA NA NA NA 1736.441 M07V04 0.5661082 -4.508689 NA NA NA 0.08427681 NA NA NA 1773.426 M07V05 0.5775470 -2.763620 NA NA NA NA 0.6298631 NA NA 1762.381 M07V06 0.5551950 -2.599052 NA NA NA NA NA 0.4918141 NA 1762.216 M07V07 0.6027757 -2.934395 NA NA NA NA NA NA 0.8641250 1744.344 M07V-01 0.7368158 -9.906505 NA 0.01033884 0.02161026 0.05373681 0.5563023 0.3531192 0.7427474 1614.084 M07V-02 0.7175185 -10.335688 0.05680841 NA 0.02009451 0.06780513 0.6615986 0.3156082 0.7252050 1643.590 M07V-03 0.7411357 -11.165558 0.06534138 0.01082220 NA 0.09108547 0.6135754 0.1868962 0.7335877 1610.684 M07V-04 0.7455221 -11.070892 0.05591968 0.01057667 0.02058945 NA 0.5478250 0.2089027 0.7086461 1597.388 M07V-05 0.7396840 -11.526847 0.05360428 0.01093851 0.01857986 0.04111321 NA 0.2521781 0.7282620 1610.730 M07V-06 0.7490711 -12.291680 0.06037041 0.01072095 0.01807657 0.05512504 0.6024262 NA 0.6971798 1604.035 M07V-07 0.7345037 -12.313392 0.06118345 0.01052450 0.01937777 0.06209862 0.6284042 0.2202162 NA 1617.149 M07VBS 0.7503843 -12.274385 0.05718452 0.01038885 0.01821424 0.05948104 0.5986052 0.2190833 0.7021576 1594.445 M07VFS 0.7503843 -12.274385 0.05718452 0.01038885 0.01821424 0.05948104 0.5986052 0.2190833 0.7021576 1594.445 M07VMS 0.7503843 -12.274385 0.05718452 0.01038885 0.01821424 0.05948104 0.5986052 0.2190833 0.7021576 1594.445
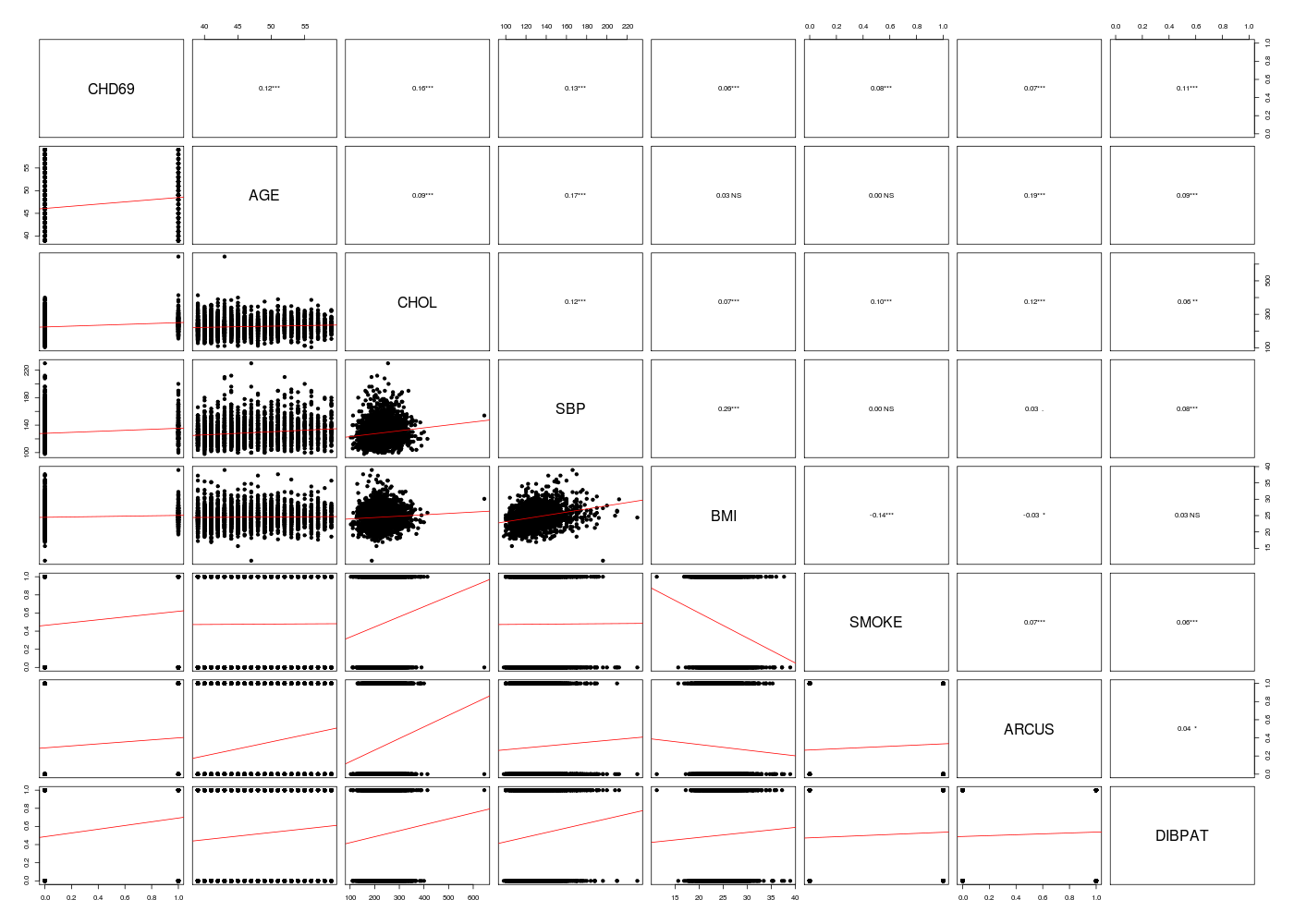
+ ======================== + + + + Analyse avec 7 variables + + + + ======================== + Matrice des corrélations au sens de Pearson pour 3140 lignes et 8 colonnes CHD69 AGE CHOL SBP BMI SMOKE ARCUS DIBPAT CHD69 1.000 AGE 0.120 1.000 CHOL 0.161 0.089 1.000 SBP 0.134 0.170 0.123 1.000 BMI 0.065 0.026 0.071 0.288 1.000 SMOKE 0.086 0.003 0.098 0.004 -0.143 1.000 ARCUS 0.066 0.188 0.121 0.032 -0.034 0.076 1.000 DIBPAT 0.113 0.090 0.057 0.078 0.027 0.061 0.046 1.000 Meilleures régressions logistiques simples pour CHD69 : ======================================================= AUROC AIC CHOL 0.66 1697.84 SBP 0.63 1724.10 AGE 0.62 1729.77 DIBPAT 0.60 1732.08 SMOKE 0.58 1750.06 BMI 0.57 1760.53 ARCUS 0.56 1760.23 Start: AIC=1594.44 wcgs$CHD69 ~ AGE + CHOL + SBP + BMI + SMOKE + ARCUS + DIBPAT Start: AIC=1594.44 wcgs$CHD69 ~ AGE + CHOL + SBP + BMI + SMOKE + ARCUS + DIBPAT Df Deviance AIC <none> 1578.4 1594.4 - ARCUS 1 1580.8 1594.8 - BMI 1 1583.4 1597.4 - SBP 1 1596.7 1610.7 - SMOKE 1 1596.7 1610.7 - AGE 1 1600.1 1614.1 - DIBPAT 1 1603.2 1617.2 - CHOL 1 1627.0 1641.0 Start: AIC=1594.44 wcgs$CHD69 ~ AGE + CHOL + SBP + BMI + SMOKE + ARCUS + DIBPAT Df Deviance AIC <none> 1578.4 1594.4 - ARCUS 1 1580.8 1594.8 - BMI 1 1583.4 1597.4 - SBP 1 1596.7 1610.7 - SMOKE 1 1596.7 1610.7 - AGE 1 1600.1 1614.1 - DIBPAT 1 1603.2 1617.2 - CHOL 1 1627.0 1641.0 Auroc globale 0.7503843 1594.4446497