![]()
![]()
Les dates de formation sont ici.
Solutions pour la séance numéro 3 (énoncés)
|
{kind=link}
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Solutions pour la séance numéro 3 (énoncés)
Pour effectuer la régression, un seul appel à lm() suffit, une fois la variable NIDS enlevée. Voici le code R correspondant :
# fonctions gh source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar" chen <- lit.dar(url) # on retire NIDS (variable 11) chen <- chen[,-11] # régression de LN_NIDS en fonction des autres variables chenml <- lm(LN_NID~.,data=chen) print(summary(chenml)) # tracé des valeurs originales et des valeurs prédites gr("chenglob.png") with(chen,plot(LN_NID,LN_NID,pch=19,col="black")) abline(a=0,b=1) points(chen$LN_NID,chenml$fitted.values ,pch=19,col="red",cex=0.7) legend( x="topleft", legend=c("points originaux","modèle global"), col=c("black","red"), pch=19 ) # fin de legend dev.off()Call: lm(formula = LN_NID ~ ., data = chen) Residuals: Min 1Q Median 3Q Max -1.69899 -0.27317 -0.00036 0.32463 1.73050 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 10.998412 3.060273 3.594 0.00161 ** ALT -0.004431 0.001557 -2.846 0.00939 ** PENTE -0.053830 0.021900 -2.458 0.02232 * PINS 0.067939 0.099472 0.683 0.50174 HAUT -1.293637 0.563811 -2.294 0.03168 * DIAM 0.231637 0.104378 2.219 0.03709 * DENS -0.356788 1.566465 -0.228 0.82193 ORIEN -0.237473 1.006006 -0.236 0.81557 HAUTDOM 0.181061 0.236724 0.765 0.45248 STRAT -1.285322 0.864848 -1.486 0.15142 MELAN -0.433102 0.734870 -0.589 0.56162 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.8293 on 22 degrees of freedom Multiple R-squared: 0.6949, Adjusted R-squared: 0.5563 F-statistic: 5.012 on 10 and 22 DF, p-value: 0.0007878
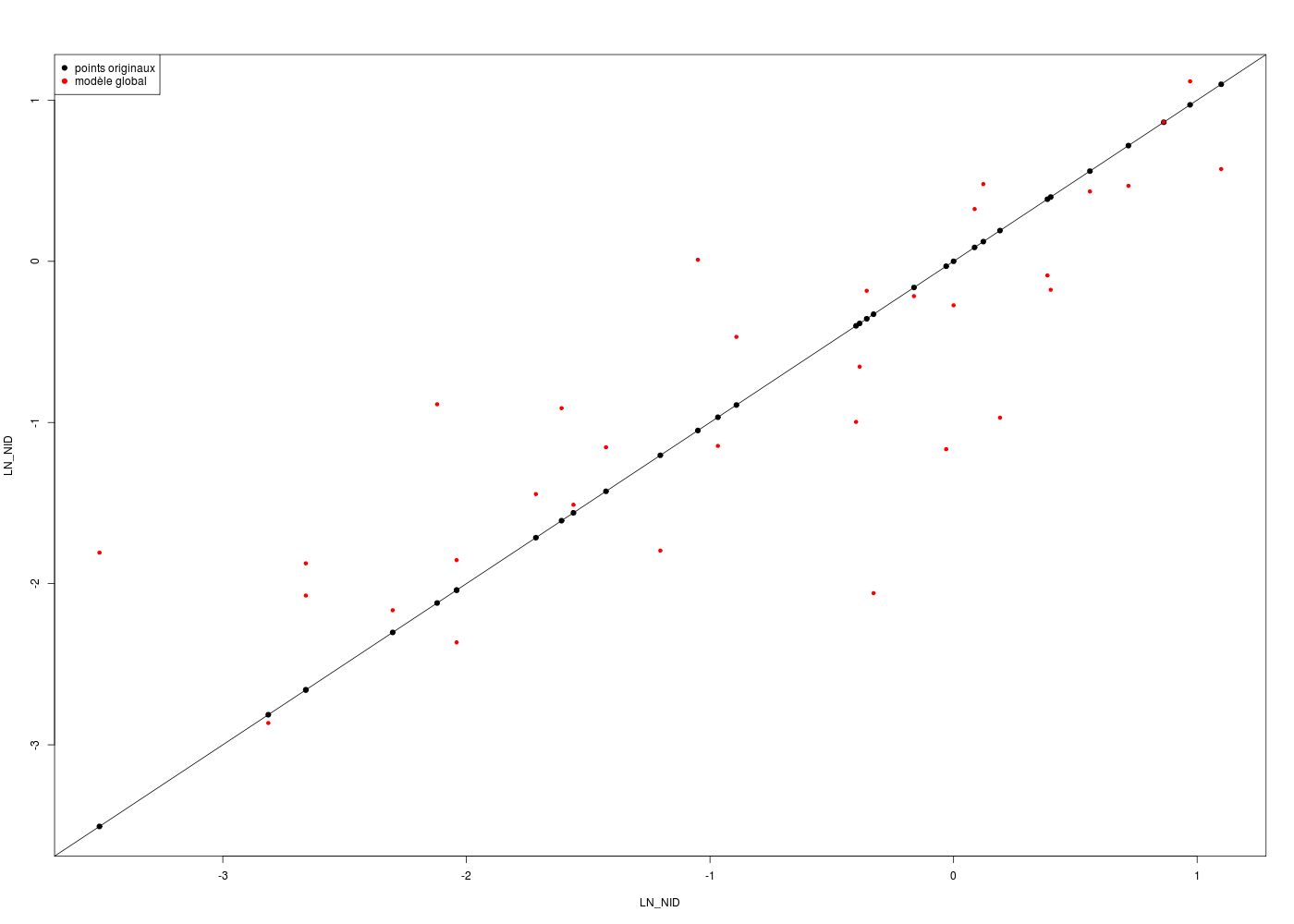
Il serait prudent de connaitre les unités des données, comme ici.
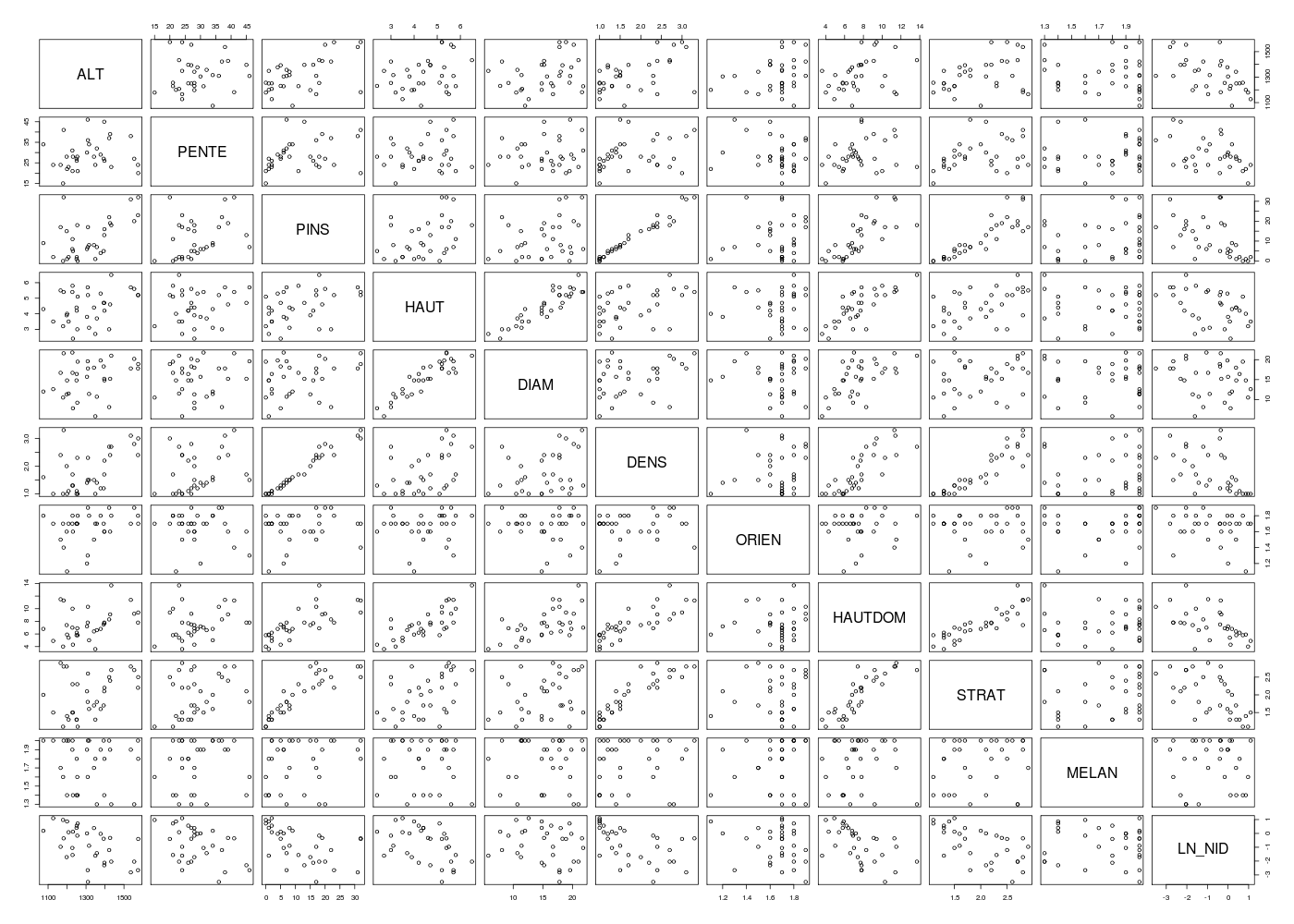
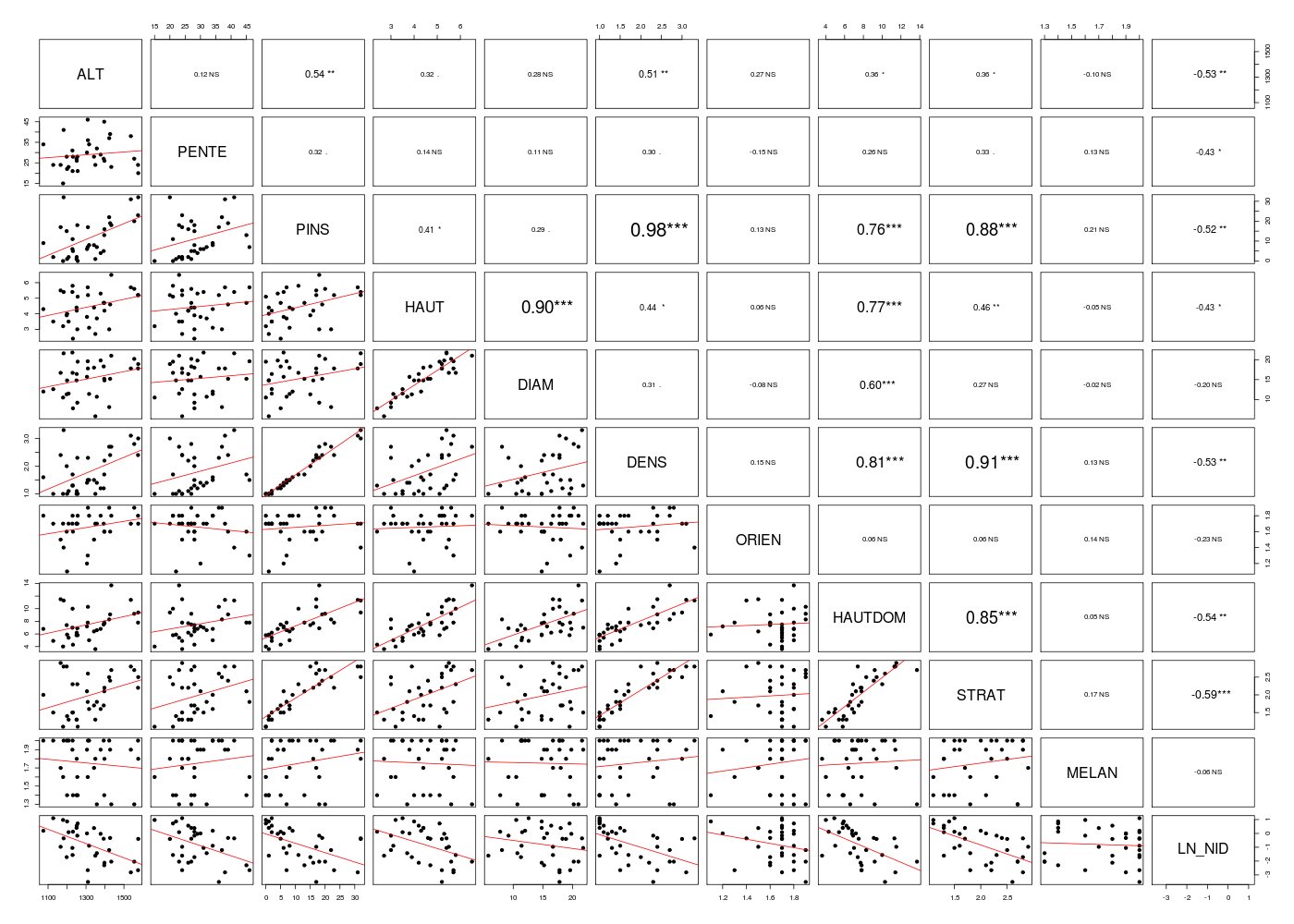
Pour connaitre le signe des coefficients, on peut effectuer une régression linéaire avec chaque variable séparément, consulter la matrice des corrélations, tracer la variable résultat LN_NID en fonction de chaque variable séparément, par exemple avec la fonction pairs()...
# fonctions gh source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar" chen <- lit.dar(url) # on retire NIDS (variable 11) chen <- chen[,-11] # régression de LN_NIDS en fonction chaque variable séparément nbvar <- 1:(ncol(chen) - 1) for (idv in nbvar) { lavar <- names(chen)[idv] cats(paste("Régression en fonction de",lavar,"seulement")) fo <- paste("LN_NID ~",lavar) ml <- lm( as.formula(fo),data=chen) print(summary(ml)) } # fin pour idv # matrice des corrélations via une fonction gh mdc(chen) ## tracés de LN_NIDS en fonction chaque variable séparément # avec la variable pairs() originale gr("chenpairs1.png") pairs(chen) dev.off() # avec notre fonction pairsi() gr("chenpairs2.png") pairsi(chen,opt=2) dev.off() # coefficients de corrélation linéaire et de régression linéaire univariés et multivariés nomscols <- c("Variable","coeffCorLin","coeffRegLinUnivar","coeffRegLinMultivar") mcoef <- data.frame(matrix(NA,nrow=length(nbvar),ncol=length(nomscols))) names(mcoef) <- nomscols mcoef[,1] <- names(chen)[nbvar] for (idv in nbvar) { lavar <- names(chen)[idv] mcoef[idv,2] <- cor(chen$LN_NID,chen[,lavar]) fo <- paste("LN_NID ~",lavar) ml <- lm( as.formula(fo),data=chen) mcoef[idv,3] <- coefficients(ml)[2] } # fin pour idv mcoef[,4] <- coefficients(lm(LN_NID~.,data=chen))[-1] # sans arrondi print(mcoef) # avec arrondi mcoef2 <- mcoef mcoef2[,2:4] <- lapply(FUN=function(x) round(x,3),X=mcoef2[,2:4]) print(mcoef2)Régression en fonction de ALT seulement ======================================= Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.72074 -0.68616 0.00178 0.94230 1.74964 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 5.958414 1.936589 3.077 0.00435 ** ALT -0.005148 0.001465 -3.513 0.00138 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.07 on 31 degrees of freedom Multiple R-squared: 0.2847, Adjusted R-squared: 0.2617 F-statistic: 12.34 on 1 and 31 DF, p-value: 0.001384 Régression en fonction de PENTE seulement ========================================= Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.2142 -0.9769 0.2790 0.9433 1.5437 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.31175 0.82689 1.586 0.1228 PENTE -0.07320 0.02765 -2.648 0.0126 * --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.142 on 31 degrees of freedom Multiple R-squared: 0.1844, Adjusted R-squared: 0.1581 F-statistic: 7.01 on 1 and 31 DF, p-value: 0.01263 Régression en fonction de PINS seulement ======================================== Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.3184 -0.7781 0.2604 0.8380 1.8454 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -0.03901 0.29711 -0.131 0.89639 PINS -0.06760 0.02006 -3.370 0.00203 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.082 on 31 degrees of freedom Multiple R-squared: 0.2681, Adjusted R-squared: 0.2445 F-statistic: 11.36 on 1 and 31 DF, p-value: 0.002027 Régression en fonction de HAUT seulement ======================================== Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.3125 -1.1291 0.2460 0.9391 1.8610 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.4513 0.8882 1.634 0.1124 HAUT -0.5087 0.1944 -2.616 0.0136 * --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.145 on 31 degrees of freedom Multiple R-squared: 0.1809, Adjusted R-squared: 0.1545 F-statistic: 6.845 on 1 and 31 DF, p-value: 0.01361 Régression en fonction de DIAM seulement ======================================== Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.5451 -0.9392 0.2989 0.8394 1.7781 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 0.07346 0.80584 0.091 0.928 DIAM -0.05814 0.05091 -1.142 0.262 Residual standard error: 1.239 on 31 degrees of freedom Multiple R-squared: 0.04038, Adjusted R-squared: 0.00942 F-statistic: 1.304 on 1 and 31 DF, p-value: 0.2622 Régression en fonction de DENS seulement ======================================== Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.2265 -0.8000 0.2660 0.8289 1.8401 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 0.8286 0.5095 1.626 0.11400 DENS -0.9168 0.2647 -3.464 0.00158 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.074 on 31 degrees of freedom Multiple R-squared: 0.2791, Adjusted R-squared: 0.2558 F-statistic: 12 on 1 and 31 DF, p-value: 0.001577 Régression en fonction de ORIEN seulement ========================================= Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.3924 -0.8565 0.1141 0.9578 1.9767 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.719 1.939 0.887 0.382 ORIEN -1.528 1.163 -1.314 0.199 Residual standard error: 1.231 on 31 degrees of freedom Multiple R-squared: 0.05275, Adjusted R-squared: 0.0222 F-statistic: 1.726 on 1 and 31 DF, p-value: 0.1985 Régression en fonction de HAUTDOM seulement =========================================== Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -1.9251 -0.8830 0.4163 0.8720 1.5343 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.34730 0.63046 2.137 0.04060 * HAUTDOM -0.28657 0.07994 -3.585 0.00114 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.063 on 31 degrees of freedom Multiple R-squared: 0.2931, Adjusted R-squared: 0.2703 F-statistic: 12.85 on 1 and 31 DF, p-value: 0.00114 Régression en fonction de STRAT seulement ========================================= Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.0833 -0.8512 0.2844 0.9167 1.5247 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.7737 0.6537 2.713 0.010780 * STRAT -1.3054 0.3175 -4.111 0.000268 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.018 on 31 degrees of freedom Multiple R-squared: 0.3528, Adjusted R-squared: 0.3319 F-statistic: 16.9 on 1 and 31 DF, p-value: 0.0002681 Régression en fonction de MELAN seulement ========================================= Call: lm(formula = as.formula(fo), data = chen) Residuals: Min 1Q Median 3Q Max -2.6174 -0.8257 0.4276 0.9753 1.9877 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -0.2787 1.5406 -0.181 0.858 MELAN -0.3052 0.8706 -0.351 0.728 Residual standard error: 1.262 on 31 degrees of freedom Multiple R-squared: 0.003949, Adjusted R-squared: -0.02818 F-statistic: 0.1229 on 1 and 31 DF, p-value: 0.7283 Matrice des corrélations au sens de Pearson pour 33 lignes et 11 colonnes ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN LN_NID ALT 1.000 PENTE 0.121 1.000 PINS 0.538 0.322 1.000 HAUT 0.321 0.137 0.414 1.000 DIAM 0.284 0.113 0.295 0.905 1.000 DENS 0.515 0.301 0.980 0.439 0.306 1.000 ORIEN 0.268 -0.152 0.128 0.058 -0.079 0.151 1.000 HAUTDOM 0.360 0.262 0.759 0.772 0.596 0.810 0.060 1.000 STRAT 0.364 0.326 0.877 0.460 0.267 0.909 0.063 0.854 1.000 MELAN -0.100 0.129 0.206 -0.045 -0.025 0.130 0.138 0.054 0.175 1.000 LN_NID -0.534 -0.429 -0.518 -0.425 -0.201 -0.528 -0.230 -0.541 -0.594 -0.063 1.000 Variable coeffCorLin coeffRegLinUnivar coeffRegLinMultivar 1 ALT -0.53361382 -0.005148273 -0.004430808 2 PENTE -0.42943963 -0.073200298 -0.053830065 3 PINS -0.51778795 -0.067595146 0.067938732 4 HAUT -0.42529455 -0.508726059 -1.293637117 5 DIAM -0.20093786 -0.058141245 0.231636849 6 DENS -0.52827817 -0.916801789 -0.356787698 7 ORIEN -0.22968178 -1.528001217 -0.237472561 8 HAUTDOM -0.54137095 -0.286571785 0.181060697 9 STRAT -0.59398965 -1.305378665 -1.285321962 10 MELAN -0.06283817 -0.305201715 -0.433102101 Variable coeffCorLin coeffRegLinUnivar coeffRegLinMultivar 1 ALT -0.534 -0.005 -0.004 2 PENTE -0.429 -0.073 -0.054 3 PINS -0.518 -0.068 0.068 4 HAUT -0.425 -0.509 -1.294 5 DIAM -0.201 -0.058 0.232 6 DENS -0.528 -0.917 -0.357 7 ORIEN -0.230 -1.528 -0.237 8 HAUTDOM -0.541 -0.287 0.181 9 STRAT -0.594 -1.305 -1.285 10 MELAN -0.063 -0.305 -0.433
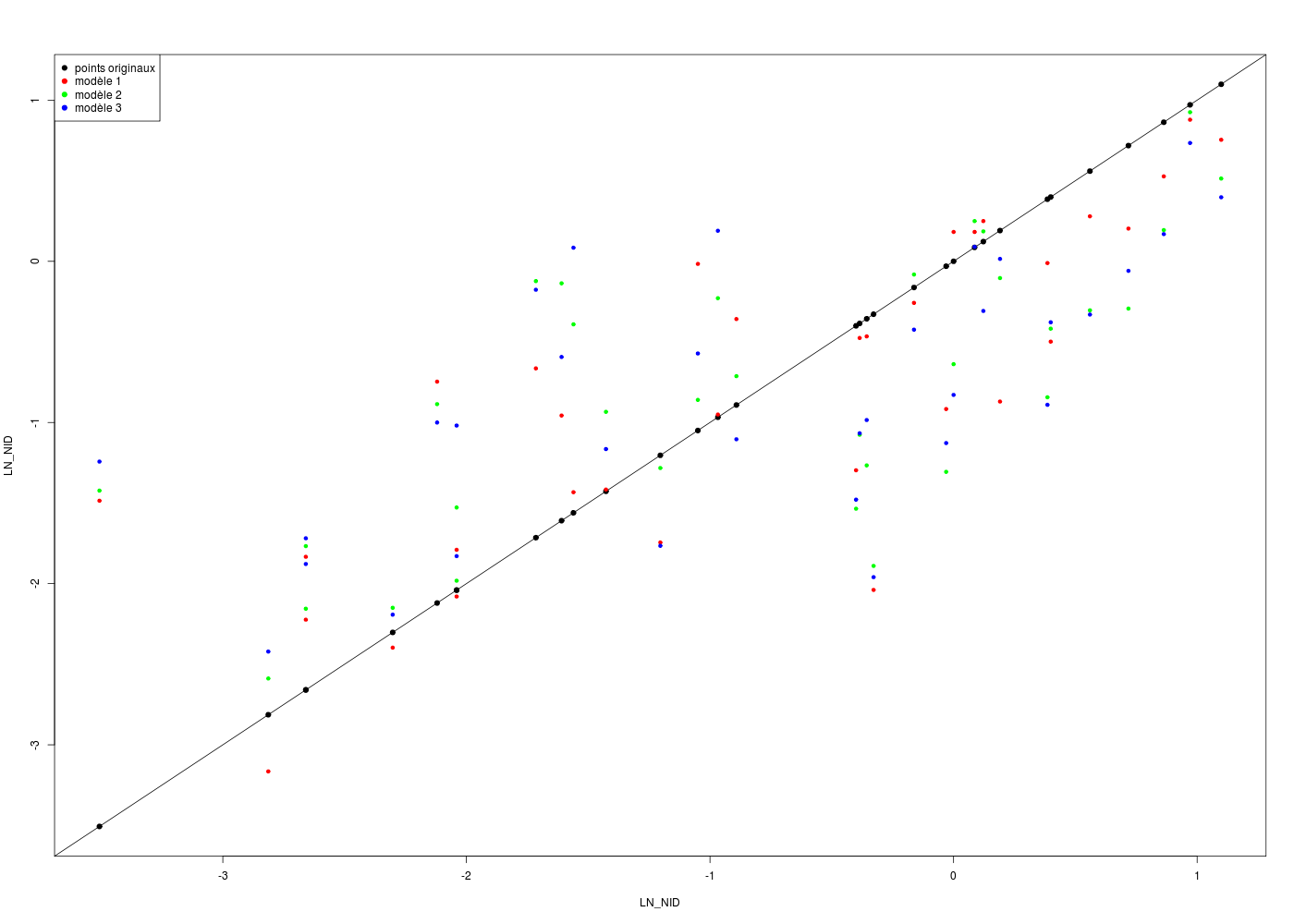
Voici le code R pour réaliser les trois régressions demandées et leur comparaison :
# fonctions gh source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar" chen <- lit.dar(url) # pour simplifier l'écriture attach(chen) # régression 1 cats("Régression numéro 1") m1 <- lm( LN_NID ~ ALT + PENTE + HAUT + DIAM ) print(summary(m1)) fit1 <- m1$fitted.values # régression 2 cats("Régression numéro 2") m2 <- lm( LN_NID ~ ALT + PENTE + HAUT ) print(summary(m2)) fit2 <- m2$fitted.values # régression 3 cats("Régression numéro 3") m3 <- lm( LN_NID ~ ALT + PENTE + DIAM ) print(summary(m3)) fit3 <- m3$fitted.values # tracés gr("chen3modeles.png") plot(LN_NID,LN_NID,pch=19,col="black") abline(a=0,b=1) points(LN_NID,fit1,pch=19,col="red",cex=0.7) points(LN_NID,fit2,pch=19,col="green",cex=0.7) points(LN_NID,fit3,pch=19,col="blue",cex=0.7) legend( x="topleft", legend=c("points originaux","modèle 1","modèle 2","modèle 3"), col=c("black","red","green","blue"), pch=19 ) # fin de legend dev.off() # comparaison des régressions cats("Résumé des modèles") modeles <- list(m1,m2,m3) nbmodeles <- length(modeles) nomscols <- c("Régression","Formule","nbVar","R2a") mcomp <- data.frame(matrix(NA,nrow=nbmodeles,ncol=length(nomscols))) names(mcomp) <- nomscols mcomp[,1] <- paste("m",1:nbmodeles,sep="") mcomp[,2] <- sapply(X=modeles,FUN=function(x) as.character(summary(x)$call)[2]) mcomp[,3] <- sapply(X=modeles,FUN=function(x) length(coefficients(x))) - 1 mcomp[,4] <- sapply(X=modeles,FUN=function(x) summary(x)$adj.r.squared) print(mcomp) # à ne pas oublier detach(chen)Régression numéro 1 ===================== Call: lm(formula = LN_NID ~ ALT + PENTE + HAUT + DIAM) Residuals: Min 1Q Median 3Q Max -2.02087 -0.25012 0.09002 0.35179 1.71056 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.732147 1.488585 5.194 1.63e-05 *** ALT -0.003924 0.001148 -3.419 0.001946 ** PENTE -0.057343 0.019388 -2.958 0.006236 ** HAUT -1.356138 0.319834 -4.240 0.000220 *** DIAM 0.283059 0.076260 3.712 0.000905 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.7906 on 28 degrees of freedom Multiple R-squared: 0.6471, Adjusted R-squared: 0.5967 F-statistic: 12.83 on 4 and 28 DF, p-value: 4.677e-06 Régression numéro 2 ===================== Call: lm(formula = LN_NID ~ ALT + PENTE + HAUT) Residuals: Min 1Q Median 3Q Max -2.0837 -0.5037 -0.0635 0.6903 1.5616 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.448568 1.784311 4.174 0.000249 *** ALT -0.003986 0.001377 -2.894 0.007153 ** PENTE -0.058997 0.023264 -2.536 0.016860 * HAUT -0.293479 0.171126 -1.715 0.097016 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.949 on 29 degrees of freedom Multiple R-squared: 0.4734, Adjusted R-squared: 0.419 F-statistic: 8.691 on 3 and 29 DF, p-value: 0.0002869 Régression numéro 3 ===================== Call: lm(formula = LN_NID ~ ALT + PENTE + DIAM) Residuals: Min 1Q Median 3Q Max -2.2638 -0.7811 0.2125 0.7013 1.6313 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.237019 1.868584 3.873 0.000564 *** ALT -0.004659 0.001428 -3.262 0.002834 ** PENTE -0.062853 0.024358 -2.580 0.015197 * DIAM -0.006389 0.042806 -0.149 0.882384 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.9955 on 29 degrees of freedom Multiple R-squared: 0.4205, Adjusted R-squared: 0.3605 F-statistic: 7.014 on 3 and 29 DF, p-value: 0.001093 Résumé des modèles ================== Régression Formule nbVar R2a 1 m1 LN_NID ~ ALT + PENTE + HAUT + DIAM 4 0.5966640 2 m2 LN_NID ~ ALT + PENTE + HAUT 3 0.4189593 3 m3 LN_NID ~ ALT + PENTE + DIAM 3 0.3605213Si on compare les modèles 1 et 3, on remarque le coefficient de DIAM est positif avec le modèle 1 (valeur 0.283) mais négatif avec le modèle 3 (valeur -0.006). Compte-tenu de la question 1, le coefficient devrait être négatif. C'est sans doute la colinéarité entre HAUT et DIAM (r=0.905) qui cause cette "instabilité" de coefficient.
Le meilleur modèle prédictif de ces trois modèles est le premier, parce que son R2 ajusté est le plus élevé (0.5967 vs 0.4190 et 0.3605).
Malheureusement, ce modèle 1 est sans doute incorrect, à cause du signe de DIAM.
Le meilleur modèle explicatif est certainement le modèle 2.
Dans Z = 3*X + 2*Y + 5, on remplace 2*Y par Y + Y et on utilise Y = X + 1 à la place du premier de ces deux Y. On obtient alors Z = 4*X + Y + 6, ce qui montre qu'il n'y a pas unicité des coefficients en cas de colinéarité des variables en RLM.
Que fait R dans ce cas-là ? Voici la réponse en session :
> chen <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar.txt") > chenX <- chen$LN_NID > chenY <- chenX + 1 > chenZ <- 3*chenX + 2*chenY + 5 > XYZ <- data.frame( cbind(chenX,chenY,chenZ)) > ml <- lm(chenZ ~ chenX + chenY, data=XYZ ) +--------------------------------------------------------------------------+ | Warning message: | | In summary.lm(ml) : essentially perfect fit: summary may be unreliable | +--------------------------------------------------------------------------+ > print(summary(ml)) Call: lm(formula = chenZ ~ chenX + chenY, data = XYZ) Residuals: Min 1Q Median 3Q Max -2.232e-15 -6.393e-16 -7.790e-17 1.986e-16 4.089e-15 Coefficients: (1 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 7.000e+00 2.533e-16 2.764e+16 <2e-16 *** chenX 5.000e+00 1.722e-16 2.904e+16 <2e-16 *** chenY NA NA NA NA --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.212e-15 on 31 degrees of freedom Multiple R-squared: 1, Adjusted R-squared: 1 F-statistic: 8.435e+32 on 1 and 31 DF, p-value: < 2.2e-16C'est encore pire avec le deuxième exemple : on obtient Z = -4*X - (5 - 7*X) - Y + 3 soit Z = 3*X - Y -2. Donc le coefficient de X a changé de signe.
Dans Z = 3*U +4*V + 2*W + 5, on remplace 2*W par 3*W-W et on utilise W = 2*U + 3*V à la place du dernier W. On obtient alors Z = U + V + 3*W + 5 ce qui montre qu'il n'y a pas unicité des coefficients en cas de multicolinéarité des variables en RLM.
Pour gérer la multicolinéarité, soit on est capable d'éliminer les variables trop corrélées (voir la séance 5), soit on utilise des méthodes de régression avec pénalité, comme les méthodes de régression ridge, lasso ou, elastic net.
Le nombre de sous-ensembles à k éléments pris parmi n est donné par un coeficient nommé coefficient du binome. Leur nombre total est 2 puissance n.
Pour le dossier chenilles avec 10 variables prédicteurs, cela fait 2**10 soit 1024 sous-ensembles à envisager.
Description des variables :
# fonctions gh source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar" chenilles <- lit.dar(url) # on retire LN_NIDS (variable 12) chenilles <- chenilles[,-12] # défintion des unités unites <- c("m","°","pins","m","cm","ppp","N1S2","m","strates","de1a2","nids") names(unites) <- names(chenilles) # description des variables et tests de normalité for (idv in names(chenilles)) { decritQT(idv,chenilles[,idv],unites[idv],TRUE) tdn(idv,chenilles[,idv],"?",TRUE) } # fin pour idv # matrice des corrélations (fonction GH) mdc(chenilles)DESCRIPTION STATISTIQUE DE LA VARIABLE ALT Taille 33 individus Moyenne 1315.3333 m Ecart-type 129.0370 m Coef. de variation 10 % 1er Quartile 1228.0000 m Mediane 1309.0000 m 3eme Quartile 1396.0000 m iqr absolu 168.0000 m iqr relatif 13.0000 % Minimum 1075.000 m Maximum 1575.000 m Tracé tige et feuilles The decimal point is 2 digit(s) to the right of the | 10 | 8 11 | 3788 12 | 0013335556 13 | 111245689 14 | 00233 15 | 4578 TESTS DE NORMALITE POUR LA VARIABLE y = ALT pour 33 valeurs (0 valeurs NA) Variable Test p-value 1/y Kolmogorov-Smirnov 0.8011774511 1/y Shapiro 0.6989553323 ln(ln(y+1)) Kolmogorov-Smirnov 0.6960403827 ln(y+1) Kolmogorov-Smirnov 0.6794529107 sqrt(y) Kolmogorov-Smirnov 0.6227517081 y Kolmogorov-Smirnov 0.5708345248 ln(ln(y+1)) Shapiro 0.5504703000 ln(y+1) Shapiro 0.5158355592 y^2 Kolmogorov-Smirnov 0.4837555813 sqrt(y) Shapiro 0.3816855581 y Shapiro 0.2529654489 y^2 Shapiro 0.0828985232 DESCRIPTION STATISTIQUE DE LA VARIABLE PENTE Taille 33 individus Moyenne 29.0303 ° Ecart-type 7.3036 ° Coef. de variation 25 % 1er Quartile 24.0000 ° Mediane 28.0000 ° 3eme Quartile 34.0000 ° iqr absolu 10.0000 ° iqr relatif 36.0000 % Minimum 15.000 ° Maximum 46.000 ° Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 1 | 5 2 | 0112334444 2 | 6677788889 3 | 01244 3 | 6789 4 | 1 4 | 56 TESTS DE NORMALITE POUR LA VARIABLE y = PENTE pour 33 valeurs (0 valeurs NA) Variable Test p-value 1/y Kolmogorov-Smirnov 0.9662589402 ln(ln(y+1)) Kolmogorov-Smirnov 0.8696884572 ln(y+1) Kolmogorov-Smirnov 0.7517855152 ln(y+1) Shapiro 0.7450904158 ln(ln(y+1)) Shapiro 0.6734217091 sqrt(y) Kolmogorov-Smirnov 0.5406332529 sqrt(y) Shapiro 0.5353096346 y Kolmogorov-Smirnov 0.3507465853 y Shapiro 0.1659908441 y^2 Kolmogorov-Smirnov 0.1398586569 1/y Shapiro 0.0954149830 y^2 Shapiro 0.0035012231 DESCRIPTION STATISTIQUE DE LA VARIABLE PINS Taille 33 individus Moyenne 11.4545 pins Ecart-type 9.5364 pins Coef. de variation 82 % 1er Quartile 4.0000 pins Mediane 8.0000 pins 3eme Quartile 18.0000 pins iqr absolu 14.0000 pins iqr relatif 175.0000 % Minimum 0.000 pins Maximum 32.000 pins Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 0 | 001112224 0 | 556677889 1 | 13 1 | 5677889 2 | 023 2 | 3 | 122 TESTS DE NORMALITE POUR LA VARIABLE y = PINS pour 33 valeurs (0 valeurs NA) Variable Test p-value sqrt(y) Kolmogorov-Smirnov 0.8789050467 ln(y+1) Kolmogorov-Smirnov 0.6213425135 y Kolmogorov-Smirnov 0.3935415541 sqrt(y) Shapiro 0.3906972408 y^2 Kolmogorov-Smirnov 0.0627736648 ln(y+1) Shapiro 0.0386626832 y Shapiro 0.0085973606 y^2 Shapiro 0.0000023339 ln(ln(y+1)) Shapiro NaN 1/y Shapiro NaN ln(ln(y+1)) Kolmogorov-Smirnov NA 1/y Kolmogorov-Smirnov NA DESCRIPTION STATISTIQUE DE LA VARIABLE HAUT Taille 33 individus Moyenne 4.4515 m Ecart-type 1.0408 m Coef. de variation 23 % 1er Quartile 3.7000 m Mediane 4.4000 m 3eme Quartile 5.3000 m iqr absolu 1.6000 m iqr relatif 36.0000 % Minimum 2.400 m Maximum 6.500 m Tracé tige et feuilles The decimal point is at the | 2 | 4 2 | 7 3 | 0012 3 | 55789 4 | 022344 4 | 677 5 | 1222344 5 | 56778 6 | 6 | 5 TESTS DE NORMALITE POUR LA VARIABLE y = HAUT pour 33 valeurs (0 valeurs NA) Variable Test p-value y^2 Kolmogorov-Smirnov 0.7888435742 y Kolmogorov-Smirnov 0.6556542010 sqrt(y) Kolmogorov-Smirnov 0.5908516961 ln(y+1) Kolmogorov-Smirnov 0.5571140131 ln(ln(y+1)) Kolmogorov-Smirnov 0.5312780227 1/y Kolmogorov-Smirnov 0.5264803372 y Shapiro 0.4742085234 y^2 Shapiro 0.3701001428 sqrt(y) Shapiro 0.3155720908 ln(y+1) Shapiro 0.1929170376 ln(ln(y+1)) Shapiro 0.0647421671 1/y Shapiro 0.0071295518 DESCRIPTION STATISTIQUE DE LA VARIABLE DIAM Taille 33 individus Moyenne 15.2515 cm Ecart-type 4.3026 cm Coef. de variation 28 % 1er Quartile 11.5000 cm Mediane 15.7000 cm 3eme Quartile 18.3000 cm iqr absolu 6.8000 cm iqr relatif 43.0000 % Minimum 5.800 cm Maximum 21.800 cm Tracé tige et feuilles The decimal point is at the | 4 | 8 6 | 8 8 | 12 10 | 57345 12 | 06 14 | 888227 16 | 477888 18 | 039568 20 | 2068 TESTS DE NORMALITE POUR LA VARIABLE y = DIAM pour 33 valeurs (0 valeurs NA) Variable Test p-value y^2 Kolmogorov-Smirnov 0.8556211754 y Kolmogorov-Smirnov 0.6821607452 sqrt(y) Kolmogorov-Smirnov 0.3982037290 y^2 Shapiro 0.3503466038 y Shapiro 0.2315635758 ln(y+1) Kolmogorov-Smirnov 0.2223072795 ln(ln(y+1)) Kolmogorov-Smirnov 0.1319463967 sqrt(y) Shapiro 0.0693343720 1/y Kolmogorov-Smirnov 0.0454076588 ln(y+1) Shapiro 0.0132551936 ln(ln(y+1)) Shapiro 0.0023680656 1/y Shapiro 0.0000430273 DESCRIPTION STATISTIQUE DE LA VARIABLE DENS Taille 33 individus Moyenne 1.7909 ppp Ecart-type 0.7174 ppp Coef. de variation 39 % 1er Quartile 1.2000 ppp Mediane 1.5000 ppp 3eme Quartile 2.4000 ppp iqr absolu 1.2000 ppp iqr relatif 80.0000 % Minimum 1.000 ppp Maximum 3.300 ppp Tracé tige et feuilles The decimal point is 1 digit(s) to the left of the | 10 | 00000000 12 | 0000 14 | 00000 16 | 000 18 | 20 | 0 22 | 000 24 | 000 26 | 00 28 | 0 30 | 00 32 | 0 TESTS DE NORMALITE POUR LA VARIABLE y = DENS pour 33 valeurs (0 valeurs NA) Variable Test p-value ln(ln(y+1)) Kolmogorov-Smirnov 0.5827859504 ln(y+1) Kolmogorov-Smirnov 0.5374347576 sqrt(y) Kolmogorov-Smirnov 0.4763202747 1/y Kolmogorov-Smirnov 0.4313133859 y Kolmogorov-Smirnov 0.2791976463 y^2 Kolmogorov-Smirnov 0.0881468133 ln(ln(y+1)) Shapiro 0.0135296348 ln(y+1) Shapiro 0.0095044549 sqrt(y) Shapiro 0.0089265243 1/y Shapiro 0.0077252053 y Shapiro 0.0039250522 y^2 Shapiro 0.0003492964 DESCRIPTION STATISTIQUE DE LA VARIABLE ORIEN Taille 33 individus Moyenne 1.6576 N1S2 Ecart-type 0.1871 N1S2 Coef. de variation 11 % 1er Quartile 1.6000 N1S2 Mediane 1.7000 N1S2 3eme Quartile 1.8000 N1S2 iqr absolu 0.2000 N1S2 iqr relatif 12.0000 % Minimum 1.100 N1S2 Maximum 1.900 N1S2 Tracé tige et feuilles The decimal point is 1 digit(s) to the left of the | 11 | 0 12 | 0 13 | 0 14 | 0 15 | 00 16 | 00000 17 | 000000000000 18 | 0000000 19 | 000 TESTS DE NORMALITE POUR LA VARIABLE y = ORIEN pour 33 valeurs (0 valeurs NA) Variable Test p-value y^2 Kolmogorov-Smirnov 0.0427822292 y Kolmogorov-Smirnov 0.0261543024 sqrt(y) Kolmogorov-Smirnov 0.0208164232 ln(y+1) Kolmogorov-Smirnov 0.0197762834 ln(ln(y+1)) Kolmogorov-Smirnov 0.0152072676 1/y Kolmogorov-Smirnov 0.0117404424 y^2 Shapiro 0.0029625178 y Shapiro 0.0003919643 sqrt(y) Shapiro 0.0001301344 ln(y+1) Shapiro 0.0001031360 ln(ln(y+1)) Shapiro 0.0000235599 1/y Shapiro 0.0000044128 DESCRIPTION STATISTIQUE DE LA VARIABLE HAUTDOM Taille 33 individus Moyenne 7.5394 m Ecart-type 2.3519 m Coef. de variation 31 % 1er Quartile 5.9000 m Mediane 7.2000 m 3eme Quartile 9.1000 m iqr absolu 3.2000 m iqr relatif 44.0000 % Minimum 3.600 m Maximum 13.700 m Tracé tige et feuilles The decimal point is at the | 2 | 6 4 | 03904889 6 | 24688902457888 8 | 3124 10 | 03345 12 | 7 TESTS DE NORMALITE POUR LA VARIABLE y = HAUTDOM pour 33 valeurs (0 valeurs NA) Variable Test p-value ln(ln(y+1)) Kolmogorov-Smirnov 0.9760721339 ln(y+1) Shapiro 0.9684095663 sqrt(y) Shapiro 0.8988879874 ln(y+1) Kolmogorov-Smirnov 0.8863240944 ln(ln(y+1)) Shapiro 0.7765631463 sqrt(y) Kolmogorov-Smirnov 0.6996897862 1/y Kolmogorov-Smirnov 0.6633375379 y Kolmogorov-Smirnov 0.4237016578 y Shapiro 0.3198704310 y^2 Kolmogorov-Smirnov 0.1065338293 1/y Shapiro 0.0530601099 y^2 Shapiro 0.0019458956 DESCRIPTION STATISTIQUE DE LA VARIABLE STRAT Taille 33 individus Moyenne 1.9818 strates Ecart-type 0.5665 strates Coef. de variation 28 % 1er Quartile 1.5000 strates Mediane 2.0000 strates 3eme Quartile 2.5000 strates iqr absolu 1.0000 strates iqr relatif 50.0000 % Minimum 1.100 strates Maximum 2.900 strates Tracé tige et feuilles The decimal point is 1 digit(s) to the left of the | 10 | 00 12 | 0000 14 | 0000 16 | 0000 18 | 00 20 | 000 22 | 0000 24 | 000 26 | 000 28 | 0000 TESTS DE NORMALITE POUR LA VARIABLE y = STRAT pour 33 valeurs (0 valeurs NA) Variable Test p-value sqrt(y) Kolmogorov-Smirnov 0.9002033485 ln(y+1) Kolmogorov-Smirnov 0.8891340855 y Kolmogorov-Smirnov 0.7770274649 ln(ln(y+1)) Kolmogorov-Smirnov 0.6569742858 y^2 Kolmogorov-Smirnov 0.4168664821 1/y Kolmogorov-Smirnov 0.4131227800 sqrt(y) Shapiro 0.0553628090 ln(y+1) Shapiro 0.0520034347 y Shapiro 0.0450443535 ln(ln(y+1)) Shapiro 0.0388969213 y^2 Shapiro 0.0140074476 1/y Shapiro 0.0128910983 DESCRIPTION STATISTIQUE DE LA VARIABLE MELAN Taille 33 individus Moyenne 1.7515 de1a2 Ecart-type 0.2563 de1a2 Coef. de variation 14 % 1er Quartile 1.6000 de1a2 Mediane 1.8000 de1a2 3eme Quartile 2.0000 de1a2 iqr absolu 0.4000 de1a2 iqr relatif 22.0000 % Minimum 1.300 de1a2 Maximum 2.000 de1a2 Tracé tige et feuilles The decimal point is 1 digit(s) to the left of the | 13 | 000 14 | 00000 15 | 16 | 000 17 | 00 18 | 0000 19 | 00000 20 | 00000000000 TESTS DE NORMALITE POUR LA VARIABLE y = MELAN pour 33 valeurs (0 valeurs NA) Variable Test p-value y^2 Kolmogorov-Smirnov 0.1591305364 y Kolmogorov-Smirnov 0.1294551032 sqrt(y) Kolmogorov-Smirnov 0.1186340618 ln(y+1) Kolmogorov-Smirnov 0.1158637196 ln(ln(y+1)) Kolmogorov-Smirnov 0.1061088716 1/y Kolmogorov-Smirnov 0.0709008433 y^2 Shapiro 0.0002155297 y Shapiro 0.0001429407 sqrt(y) Shapiro 0.0001101803 ln(y+1) Shapiro 0.0001020325 ln(ln(y+1)) Shapiro 0.0000695004 1/y Shapiro 0.0000419928 DESCRIPTION STATISTIQUE DE LA VARIABLE NIDS Taille 33 individus Moyenne 0.8112 nids Ecart-type 0.8062 nids Coef. de variation 98 % 1er Quartile 0.1800 nids Mediane 0.6700 nids 3eme Quartile 1.1300 nids iqr absolu 0.9500 nids iqr relatif 142.0000 % Minimum 0.030 nids Maximum 3.000 nids Tracé tige et feuilles The decimal point is at the | 0 | 0111111122223444 0 | 77779 1 | 00112 1 | 558 2 | 14 2 | 6 3 | 0 TESTS DE NORMALITE POUR LA VARIABLE y = NIDS pour 33 valeurs (0 valeurs NA) Variable Test p-value sqrt(y) Kolmogorov-Smirnov 0.7445409555 ln(y+1) Kolmogorov-Smirnov 0.4707968678 ln(ln(y+1)) Kolmogorov-Smirnov 0.2883073940 y Kolmogorov-Smirnov 0.2614654789 sqrt(y) Shapiro 0.0802992428 ln(ln(y+1)) Shapiro 0.0599220649 1/y Kolmogorov-Smirnov 0.0271139743 ln(y+1) Shapiro 0.0127728964 y^2 Kolmogorov-Smirnov 0.0126027258 y Shapiro 0.0003362189 1/y Shapiro 0.0000001855 y^2 Shapiro 0.0000001076 Matrice des corrélations au sens de Pearson pour 33 lignes et 11 colonnes ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN NIDS ALT 1.000 PENTE 0.121 1.000 PINS 0.538 0.322 1.000 HAUT 0.321 0.137 0.414 1.000 DIAM 0.284 0.113 0.295 0.905 1.000 DENS 0.515 0.301 0.980 0.439 0.306 1.000 ORIEN 0.268 -0.152 0.128 0.058 -0.079 0.151 1.000 HAUTDOM 0.360 0.262 0.759 0.772 0.596 0.810 0.060 1.000 STRAT 0.364 0.326 0.877 0.460 0.267 0.909 0.063 0.854 1.000 MELAN -0.100 0.129 0.206 -0.045 -0.025 0.130 0.138 0.054 0.175 1.000 NIDS -0.530 -0.455 -0.564 -0.358 -0.158 -0.570 -0.212 -0.551 -0.636 -0.124 1.000Pour trouver le meilleur modèle selon le critère du R2 ajusté (rappel sur le R2a), il faut passer en revue tous les modèles à une, deux, trois... variables jusqu'au modèle saturé (toutes les variables). C'est ce que fait en automatique la fonction step() du package stats avec une option de "direction" pour savoir si on ajoute ou si on supprime des variables. Voici le code R correspondant :
# fonctions gh source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") # lecture des données url <- "http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar" chen <- lit.dar(url) # on retire LN_NID (variable 12) chen <- chen[,-12] # régression de NIDS en fonction des autres variables chenml <- lm( NIDS ~ .,data=chen) # on utilise la fonction step du package stats best1_fo <- step(object=chenml,direction="forward") best2_ba <- step(object=chenml,direction="backward") best3_bo <- step(object=chenml,direction="both") cats("comparaison des modèles au final pour NIDS") print(summary(best1_fo)) print(summary(best2_ba)) print(summary(best3_bo))(gH) version 6.33 fonctions d'aides : lit() fqt() fql() ic() fapprox() chi2() fcomp() datagh() taper aide() pour revoir cette liste Start: AIC=-30.49 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN Start: AIC=-30.49 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - DENS 1 0.00160 6.7270 -32.482 - HAUTDOM 1 0.00680 6.7322 -32.457 - ORIEN 1 0.04623 6.7717 -32.264 - PINS 1 0.05403 6.7795 -32.226 - MELAN 1 0.14100 6.8664 -31.805 <none> 6.7254 -30.490 - HAUT 1 0.47047 7.1959 -30.259 - DIAM 1 0.68011 7.4056 -29.311 - STRAT 1 0.72313 7.4486 -29.120 - PENTE 1 1.76141 8.4869 -24.814 - ALT 1 2.34586 9.0713 -22.616 Step: AIC=-32.48 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - HAUTDOM 1 0.01200 6.7390 -34.423 - ORIEN 1 0.04709 6.7741 -34.252 - MELAN 1 0.20419 6.9312 -33.496 <none> 6.7270 -32.482 - PINS 1 0.46525 7.1923 -32.275 - HAUT 1 0.59890 7.3259 -31.668 - DIAM 1 0.77434 7.5014 -30.887 - STRAT 1 0.77873 7.5058 -30.868 - PENTE 1 1.77704 8.5041 -26.747 - ALT 1 2.37895 9.1060 -24.490 Step: AIC=-34.42 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + STRAT + MELAN Df Sum of Sq RSS AIC - ORIEN 1 0.04761 6.7867 -36.191 - MELAN 1 0.22347 6.9625 -35.347 <none> 6.7390 -34.423 - PINS 1 0.49639 7.2354 -34.078 - HAUT 1 0.69932 7.4384 -33.165 - DIAM 1 0.76474 7.5038 -32.876 - STRAT 1 1.05953 7.7986 -31.605 - PENTE 1 1.78734 8.5264 -28.660 - ALT 1 2.48880 9.2278 -26.051 Step: AIC=-36.19 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT + MELAN Df Sum of Sq RSS AIC - MELAN 1 0.29920 7.0859 -36.767 <none> 6.7867 -36.191 - PINS 1 0.47258 7.2592 -35.970 - HAUT 1 0.97417 7.7608 -33.765 - STRAT 1 1.01268 7.7993 -33.602 - DIAM 1 1.09705 7.8837 -33.246 - PENTE 1 1.74142 8.5281 -30.654 - ALT 1 2.90494 9.6916 -26.433 Step: AIC=-36.77 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - PINS 1 0.35221 7.4381 -37.167 <none> 7.0859 -36.767 - HAUT 1 0.85056 7.9364 -35.027 - DIAM 1 0.99324 8.0791 -34.439 - STRAT 1 0.99727 8.0831 -34.422 - PENTE 1 1.82065 8.9065 -31.221 - ALT 1 2.62466 9.7105 -28.369 Step: AIC=-37.17 NIDS ~ ALT + PENTE + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC <none> 7.4381 -37.167 - STRAT 1 0.85317 8.2912 -35.583 - HAUT 1 1.21834 8.6564 -34.161 - DIAM 1 1.37527 8.8133 -33.568 - PENTE 1 1.72426 9.1623 -32.286 - ALT 1 2.32266 9.7607 -30.199 Start: AIC=-30.49 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - DENS 1 0.00160 6.7270 -32.482 - HAUTDOM 1 0.00680 6.7322 -32.457 - ORIEN 1 0.04623 6.7717 -32.264 - PINS 1 0.05403 6.7795 -32.226 - MELAN 1 0.14100 6.8664 -31.805 <none> 6.7254 -30.490 - HAUT 1 0.47047 7.1959 -30.259 - DIAM 1 0.68011 7.4056 -29.311 - STRAT 1 0.72313 7.4486 -29.120 - PENTE 1 1.76141 8.4869 -24.814 - ALT 1 2.34586 9.0713 -22.616 Step: AIC=-32.48 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - HAUTDOM 1 0.01200 6.7390 -34.423 - ORIEN 1 0.04709 6.7741 -34.252 - MELAN 1 0.20419 6.9312 -33.496 <none> 6.7270 -32.482 - PINS 1 0.46525 7.1923 -32.275 - HAUT 1 0.59890 7.3259 -31.668 - DIAM 1 0.77434 7.5014 -30.887 - STRAT 1 0.77873 7.5058 -30.868 + DENS 1 0.00160 6.7254 -30.490 - PENTE 1 1.77704 8.5041 -26.747 - ALT 1 2.37895 9.1060 -24.490 Step: AIC=-34.42 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + STRAT + MELAN Df Sum of Sq RSS AIC - ORIEN 1 0.04761 6.7867 -36.191 - MELAN 1 0.22347 6.9625 -35.347 <none> 6.7390 -34.423 - PINS 1 0.49639 7.2354 -34.078 - HAUT 1 0.69932 7.4384 -33.165 - DIAM 1 0.76474 7.5038 -32.876 + HAUTDOM 1 0.01200 6.7270 -32.482 + DENS 1 0.00680 6.7322 -32.457 - STRAT 1 1.05953 7.7986 -31.605 - PENTE 1 1.78734 8.5264 -28.660 - ALT 1 2.48880 9.2278 -26.051 Step: AIC=-36.19 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT + MELAN Df Sum of Sq RSS AIC - MELAN 1 0.29920 7.0859 -36.767 <none> 6.7867 -36.191 - PINS 1 0.47258 7.2592 -35.970 + ORIEN 1 0.04761 6.7390 -34.423 + HAUTDOM 1 0.01252 6.7741 -34.252 + DENS 1 0.00000 6.7866 -34.191 - HAUT 1 0.97417 7.7608 -33.765 - STRAT 1 1.01268 7.7993 -33.602 - DIAM 1 1.09705 7.8837 -33.246 - PENTE 1 1.74142 8.5281 -30.654 - ALT 1 2.90494 9.6916 -26.433 Step: AIC=-36.77 NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - PINS 1 0.35221 7.4381 -37.167 <none> 7.0859 -36.767 + MELAN 1 0.29920 6.7867 -36.191 + ORIEN 1 0.12334 6.9625 -35.347 - HAUT 1 0.85056 7.9364 -35.027 + DENS 1 0.05047 7.0354 -35.003 + HAUTDOM 1 0.03765 7.0482 -34.943 - DIAM 1 0.99324 8.0791 -34.439 - STRAT 1 0.99727 8.0831 -34.422 - PENTE 1 1.82065 8.9065 -31.221 - ALT 1 2.62466 9.7105 -28.369 Step: AIC=-37.17 NIDS ~ ALT + PENTE + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC <none> 7.4381 -37.167 + DENS 1 0.39561 7.0425 -36.970 + PINS 1 0.35221 7.0859 -36.767 + MELAN 1 0.17883 7.2592 -35.970 - STRAT 1 0.85317 8.2912 -35.583 + ORIEN 1 0.07023 7.3678 -35.480 + HAUTDOM 1 0.06732 7.3707 -35.467 - HAUT 1 1.21834 8.6564 -34.161 - DIAM 1 1.37527 8.8133 -33.568 - PENTE 1 1.72426 9.1623 -32.286 - ALT 1 2.32266 9.7607 -30.199 comparaison des modèles au final pour NIDS ========================================== Call: lm(formula = NIDS ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN, data = chen) Residuals: Min 1Q Median 3Q Max -1.04564 -0.28874 -0.03165 0.22697 1.35444 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 8.243695 2.040342 4.040 0.000547 *** ALT -0.002875 0.001038 -2.770 0.011166 * PENTE -0.035048 0.014601 -2.400 0.025275 * PINS 0.027882 0.066320 0.420 0.678260 HAUT -0.466332 0.375903 -1.241 0.227835 DIAM 0.103799 0.069591 1.492 0.150015 DENS 0.075530 1.044392 0.072 0.943001 ORIEN -0.260833 0.670724 -0.389 0.701101 HAUTDOM 0.023532 0.157828 0.149 0.882832 STRAT -0.886833 0.576610 -1.538 0.138306 MELAN -0.332745 0.489952 -0.679 0.504132 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.5529 on 22 degrees of freedom Multiple R-squared: 0.6767, Adjusted R-squared: 0.5297 F-statistic: 4.604 on 10 and 22 DF, p-value: 0.001361 Call: lm(formula = NIDS ~ ALT + PENTE + HAUT + DIAM + STRAT, data = chen) Residuals: Min 1Q Median 3Q Max -1.09845 -0.27226 0.00947 0.28545 1.23455 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 5.9981789 1.0041510 5.973 2.27e-06 *** ALT -0.0022915 0.0007892 -2.904 0.00727 ** PENTE -0.0338090 0.0135138 -2.502 0.01872 * HAUT -0.5215956 0.2480264 -2.103 0.04493 * DIAM 0.1241452 0.0555627 2.234 0.03394 * STRAT -0.3849351 0.2187347 -1.760 0.08976 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.5249 on 27 degrees of freedom Multiple R-squared: 0.6424, Adjusted R-squared: 0.5762 F-statistic: 9.701 on 5 and 27 DF, p-value: 2.171e-05 Call: lm(formula = NIDS ~ ALT + PENTE + HAUT + DIAM + STRAT, data = chen) Residuals: Min 1Q Median 3Q Max -1.09845 -0.27226 0.00947 0.28545 1.23455 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 5.9981789 1.0041510 5.973 2.27e-06 *** ALT -0.0022915 0.0007892 -2.904 0.00727 ** PENTE -0.0338090 0.0135138 -2.502 0.01872 * HAUT -0.5215956 0.2480264 -2.103 0.04493 * DIAM 0.1241452 0.0555627 2.234 0.03394 * STRAT -0.3849351 0.2187347 -1.760 0.08976 . --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.5249 on 27 degrees of freedom Multiple R-squared: 0.6424, Adjusted R-squared: 0.5762 F-statistic: 9.701 on 5 and 27 DF, p-value: 2.171e-05A titre de comparaison, voici ce qu'on obtient si on essaie de modéliser LN_NID au lieu de NIDS :
# lecture des données chen <- lit.dar("chenilles.dar") # on retire NIDS (variable 11) chen <- chen[,-11] # régression de LN_NIDS en fonction des autres variables chenml <- lm(LN_NID~.,data=chen) # on utilise la fonction step du package stats best1_fo <- step(object=chenml,direction="forward") best2_ba <- step(object=chenml,direction="backward") best3_bo <- step(object=chenml,direction="both") cats("comparaison des modèles au final pour LN_NID") print(summary(best1_fo)) print(summary(best2_ba)) print(summary(best3_bo))> # lecture des données > > chen <- lit.dar("chenilles.dar") > # on retire NIDS (variable 11) > > chen <- chen[,-11] > # régression de LN_NIDS en fonction des autres variables > > chenml <- lm(LN_NID~.,data=chen) > # on utilise la fonction step du package stats > > best1_fo <- step(object=chenml,direction="forward") Start: AIC=-3.73 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN > best2_ba <- step(object=chenml,direction="backward") Start: AIC=-3.73 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - DENS 1 0.0357 15.166 -5.6569 - ORIEN 1 0.0383 15.168 -5.6511 - MELAN 1 0.2389 15.369 -5.2177 - PINS 1 0.3208 15.451 -5.0422 - HAUTDOM 1 0.4023 15.532 -4.8685 <none> 15.130 -3.7346 - STRAT 1 1.5190 16.649 -2.5774 - DIAM 1 3.3869 18.517 0.9317 - HAUT 1 3.6205 18.750 1.3453 - PENTE 1 4.1551 19.285 2.2730 - ALT 1 5.5717 20.702 4.6122 Step: AIC=-5.66 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - ORIEN 1 0.0871 15.253 -7.4679 - MELAN 1 0.2063 15.372 -7.2110 - HAUTDOM 1 0.3742 15.540 -6.8525 <none> 15.166 -5.6569 - PINS 1 0.9909 16.156 -5.5683 - STRAT 1 1.8513 17.017 -3.8560 - DIAM 1 3.5100 18.676 -0.7866 - HAUT 1 4.0339 19.199 0.1263 - PENTE 1 4.1218 19.287 0.2771 - ALT 1 5.5373 20.703 2.6142 Step: AIC=-7.47 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - MELAN 1 0.2984 15.551 -8.8285 - HAUTDOM 1 0.3782 15.631 -8.6597 - PINS 1 0.9455 16.198 -7.4832 <none> 15.253 -7.4679 - STRAT 1 1.7752 17.028 -5.8346 - PENTE 1 4.0447 19.297 -1.7058 - DIAM 1 4.7047 19.957 -0.5960 - HAUT 1 4.9416 20.194 -0.2066 - ALT 1 6.3926 21.645 2.0831 Step: AIC=-8.83 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + HAUTDOM + STRAT Df Sum of Sq RSS AIC - HAUTDOM 1 0.4992 16.050 -9.7858 - PINS 1 0.7699 16.321 -9.2338 <none> 15.551 -8.8285 - STRAT 1 1.9116 17.463 -7.0027 - PENTE 1 4.1556 19.707 -3.0132 - DIAM 1 4.5302 20.081 -2.3918 - HAUT 1 4.8757 20.427 -1.8288 - ALT 1 6.1082 21.659 0.1045 Step: AIC=-9.79 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - PINS 1 0.9272 16.977 -9.9325 <none> 16.050 -9.7858 - STRAT 1 1.4451 17.495 -8.9408 - PENTE 1 4.2645 20.315 -4.0102 - DIAM 1 4.3079 20.358 -3.9398 - HAUT 1 4.7457 20.796 -3.2377 - ALT 1 6.6711 22.721 -0.3156 Step: AIC=-9.93 LN_NID ~ ALT + PENTE + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - STRAT 1 0.5259 17.503 -10.9257 <none> 16.977 -9.9325 - PENTE 1 4.0243 21.002 -4.9127 - DIAM 1 5.6406 22.618 -2.4660 - ALT 1 5.8582 22.836 -2.1500 - HAUT 1 6.2248 23.202 -1.6246 Step: AIC=-10.93 LN_NID ~ ALT + PENTE + HAUT + DIAM Df Sum of Sq RSS AIC <none> 17.503 -10.9257 - PENTE 1 5.4683 22.972 -3.9540 - ALT 1 7.3067 24.810 -1.4135 - DIAM 1 8.6123 26.116 0.2790 - HAUT 1 11.2389 28.742 3.4414 > best3_bo <- step(object=chenml,direction="both") Start: AIC=-3.73 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - DENS 1 0.0357 15.166 -5.6569 - ORIEN 1 0.0383 15.168 -5.6511 - MELAN 1 0.2389 15.369 -5.2177 - PINS 1 0.3208 15.451 -5.0422 - HAUTDOM 1 0.4023 15.532 -4.8685 <none> 15.130 -3.7346 - STRAT 1 1.5190 16.649 -2.5774 - DIAM 1 3.3869 18.517 0.9317 - HAUT 1 3.6205 18.750 1.3453 - PENTE 1 4.1551 19.285 2.2730 - ALT 1 5.5717 20.702 4.6122 Step: AIC=-5.66 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + ORIEN + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - ORIEN 1 0.0871 15.253 -7.4679 - MELAN 1 0.2063 15.372 -7.2110 - HAUTDOM 1 0.3742 15.540 -6.8525 <none> 15.166 -5.6569 - PINS 1 0.9909 16.156 -5.5683 - STRAT 1 1.8513 17.017 -3.8560 + DENS 1 0.0357 15.130 -3.7346 - DIAM 1 3.5100 18.676 -0.7866 - HAUT 1 4.0339 19.199 0.1263 - PENTE 1 4.1218 19.287 0.2771 - ALT 1 5.5373 20.703 2.6142 Step: AIC=-7.47 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + HAUTDOM + STRAT + MELAN Df Sum of Sq RSS AIC - MELAN 1 0.2984 15.551 -8.8285 - HAUTDOM 1 0.3782 15.631 -8.6597 - PINS 1 0.9455 16.198 -7.4832 <none> 15.253 -7.4679 - STRAT 1 1.7752 17.028 -5.8346 + ORIEN 1 0.0871 15.166 -5.6569 + DENS 1 0.0845 15.168 -5.6511 - PENTE 1 4.0447 19.297 -1.7058 - DIAM 1 4.7047 19.957 -0.5960 - HAUT 1 4.9416 20.194 -0.2066 - ALT 1 6.3926 21.645 2.0831 Step: AIC=-8.83 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + HAUTDOM + STRAT Df Sum of Sq RSS AIC - HAUTDOM 1 0.4992 16.050 -9.7858 - PINS 1 0.7699 16.321 -9.2338 <none> 15.551 -8.8285 + MELAN 1 0.2984 15.253 -7.4679 + ORIEN 1 0.1792 15.372 -7.2110 - STRAT 1 1.9116 17.463 -7.0027 + DENS 1 0.0030 15.548 -6.8348 - PENTE 1 4.1556 19.707 -3.0132 - DIAM 1 4.5302 20.081 -2.3918 - HAUT 1 4.8757 20.427 -1.8288 - ALT 1 6.1082 21.659 0.1045 Step: AIC=-9.79 LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - PINS 1 0.9272 16.977 -9.9325 <none> 16.050 -9.7858 - STRAT 1 1.4451 17.495 -8.9408 + HAUTDOM 1 0.4992 15.551 -8.8285 + MELAN 1 0.4195 15.631 -8.6597 + ORIEN 1 0.2096 15.841 -8.2195 + DENS 1 0.0588 15.991 -7.9070 - PENTE 1 4.2645 20.315 -4.0102 - DIAM 1 4.3079 20.358 -3.9398 - HAUT 1 4.7457 20.796 -3.2377 - ALT 1 6.6711 22.721 -0.3156 Step: AIC=-9.93 LN_NID ~ ALT + PENTE + HAUT + DIAM + STRAT Df Sum of Sq RSS AIC - STRAT 1 0.5259 17.503 -10.9257 <none> 16.977 -9.9325 + PINS 1 0.9272 16.050 -9.7858 + DENS 1 0.9266 16.051 -9.7846 + HAUTDOM 1 0.6565 16.321 -9.2338 + MELAN 1 0.2032 16.774 -8.3298 + ORIEN 1 0.1018 16.876 -8.1310 - PENTE 1 4.0243 21.002 -4.9127 - DIAM 1 5.6406 22.618 -2.4660 - ALT 1 5.8582 22.836 -2.1500 - HAUT 1 6.2248 23.202 -1.6246 Step: AIC=-10.93 LN_NID ~ ALT + PENTE + HAUT + DIAM Df Sum of Sq RSS AIC <none> 17.503 -10.9257 + STRAT 1 0.5259 16.977 -9.9325 + MELAN 1 0.3916 17.112 -9.6724 + ORIEN 1 0.0516 17.452 -9.0232 + HAUTDOM 1 0.0351 17.468 -8.9919 + DENS 1 0.0328 17.471 -8.9877 + PINS 1 0.0080 17.495 -8.9408 - PENTE 1 5.4683 22.972 -3.9540 - ALT 1 7.3067 24.810 -1.4135 - DIAM 1 8.6123 26.116 0.2790 - HAUT 1 11.2389 28.742 3.4414 > cats("comparaison des modèles au final") comparaison des modèles au final ================================ > print(summary(best1_fo)) Call: lm(formula = LN_NID ~ ALT + PENTE + PINS + HAUT + DIAM + DENS + ORIEN + HAUTDOM + STRAT + MELAN, data = chen) Residuals: Min 1Q Median 3Q Max -1.69899 -0.27317 -0.00036 0.32463 1.73050 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 10.998412 3.060273 3.594 0.00161 ** ALT -0.004431 0.001557 -2.846 0.00939 ** PENTE -0.053830 0.021900 -2.458 0.02232 * PINS 0.067939 0.099472 0.683 0.50174 HAUT -1.293637 0.563811 -2.294 0.03168 * DIAM 0.231637 0.104378 2.219 0.03709 * DENS -0.356788 1.566465 -0.228 0.82193 ORIEN -0.237473 1.006006 -0.236 0.81557 HAUTDOM 0.181061 0.236724 0.765 0.45248 STRAT -1.285322 0.864848 -1.486 0.15142 MELAN -0.433102 0.734870 -0.589 0.56162 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.8293 on 22 degrees of freedom Multiple R-squared: 0.6949, Adjusted R-squared: 0.5563 F-statistic: 5.012 on 10 and 22 DF, p-value: 0.0007878 > print(summary(best2_ba)) Call: lm(formula = LN_NID ~ ALT + PENTE + HAUT + DIAM, data = chen) Residuals: Min 1Q Median 3Q Max -2.02087 -0.25012 0.09002 0.35179 1.71056 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.732147 1.488585 5.194 1.63e-05 *** ALT -0.003924 0.001148 -3.419 0.001946 ** PENTE -0.057343 0.019388 -2.958 0.006236 ** HAUT -1.356138 0.319834 -4.240 0.000220 *** DIAM 0.283059 0.076260 3.712 0.000905 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.7906 on 28 degrees of freedom Multiple R-squared: 0.6471, Adjusted R-squared: 0.5967 F-statistic: 12.83 on 4 and 28 DF, p-value: 4.677e-06 > print(summary(best3_bo)) Call: lm(formula = LN_NID ~ ALT + PENTE + HAUT + DIAM, data = chen) Residuals: Min 1Q Median 3Q Max -2.02087 -0.25012 0.09002 0.35179 1.71056 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 7.732147 1.488585 5.194 1.63e-05 *** ALT -0.003924 0.001148 -3.419 0.001946 ** PENTE -0.057343 0.019388 -2.958 0.006236 ** HAUT -1.356138 0.319834 -4.240 0.000220 *** DIAM 0.283059 0.076260 3.712 0.000905 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.7906 on 28 degrees of freedom Multiple R-squared: 0.6471, Adjusted R-squared: 0.5967 F-statistic: 12.83 on 4 and 28 DF, p-value: 4.677e-06Le meilleur de tous les modèles (visiblement au sens du critère AIC) semble donc être celui qui utilise les variables ALT, PENTE, HAUT et DIAM avec un R2 ajusté de 0,5967. Voici les graphiques des résidus pour ce modèle :
# meilleur modèle de régression cats("Régression chenilles (meilleur modèle) ") mm <- lm( LN_NID ~ ALT + PENTE + HAUT + DIAM ,data=chen) print(summary(m1)) for (idg in (1:6)) { nomg <- paste("bestchen_res",idg,".png",sep="") gr(nomg) plot(mm,which=idg) dev.off() } # fin pour idg # analyse des points influents ???
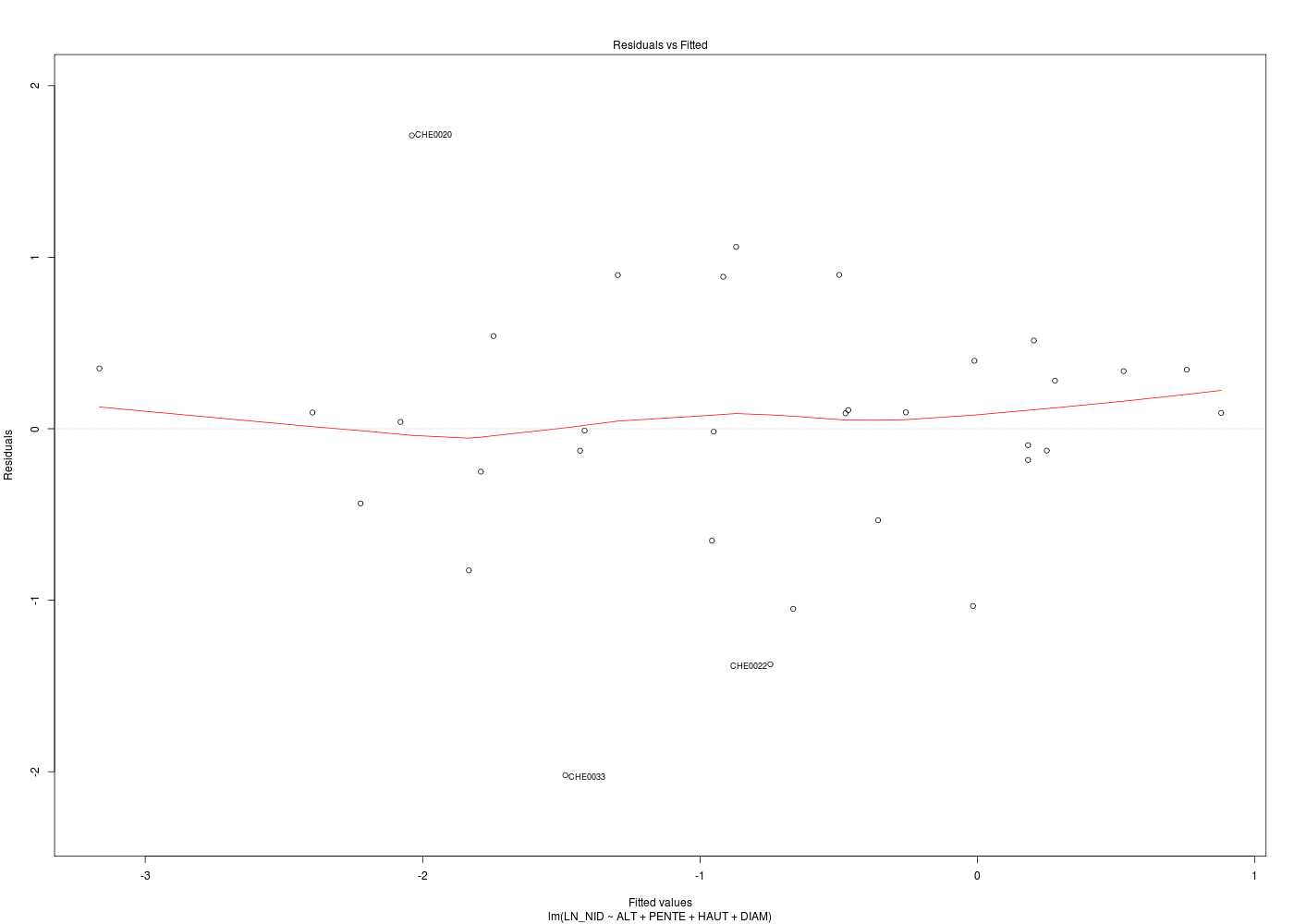
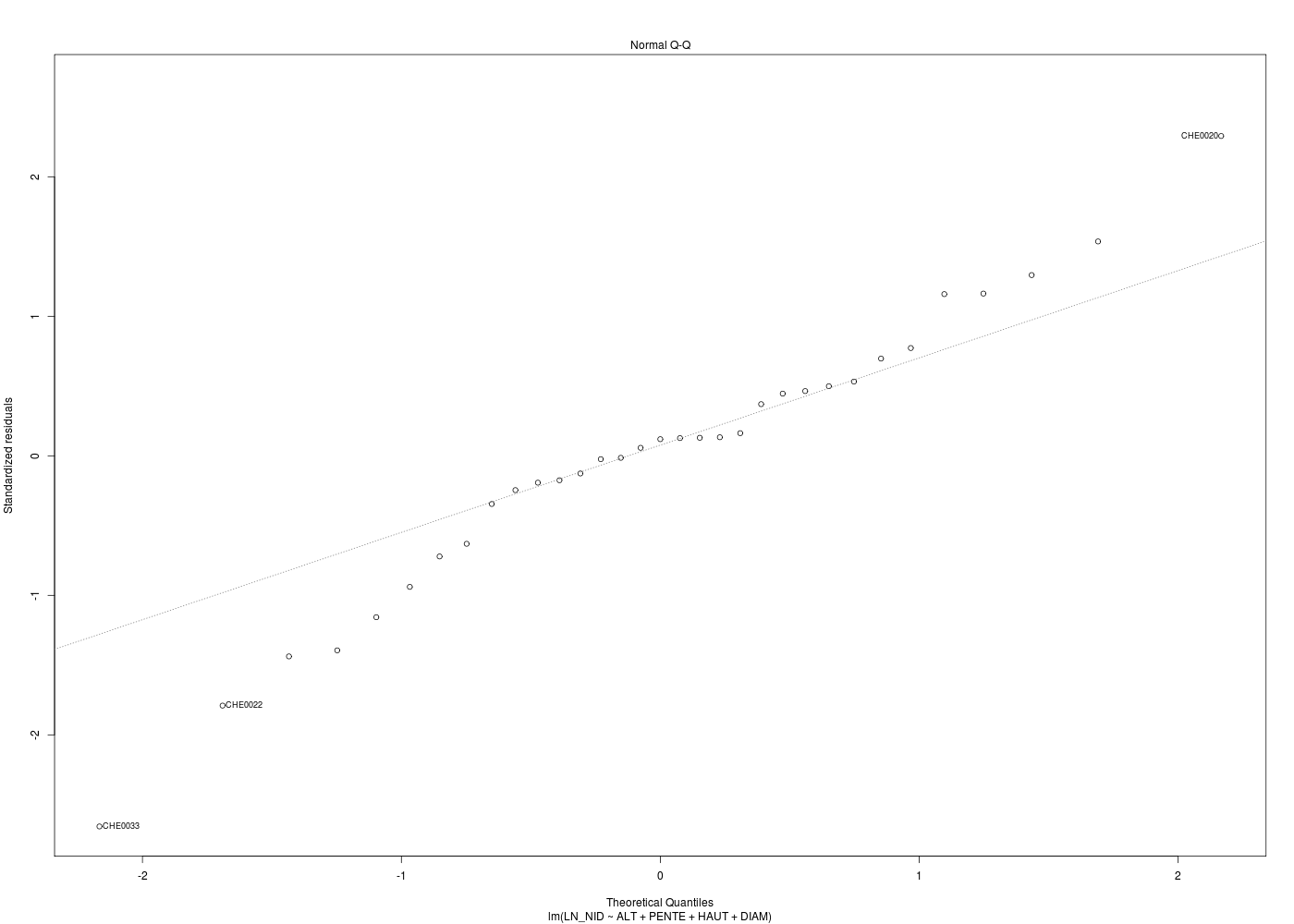
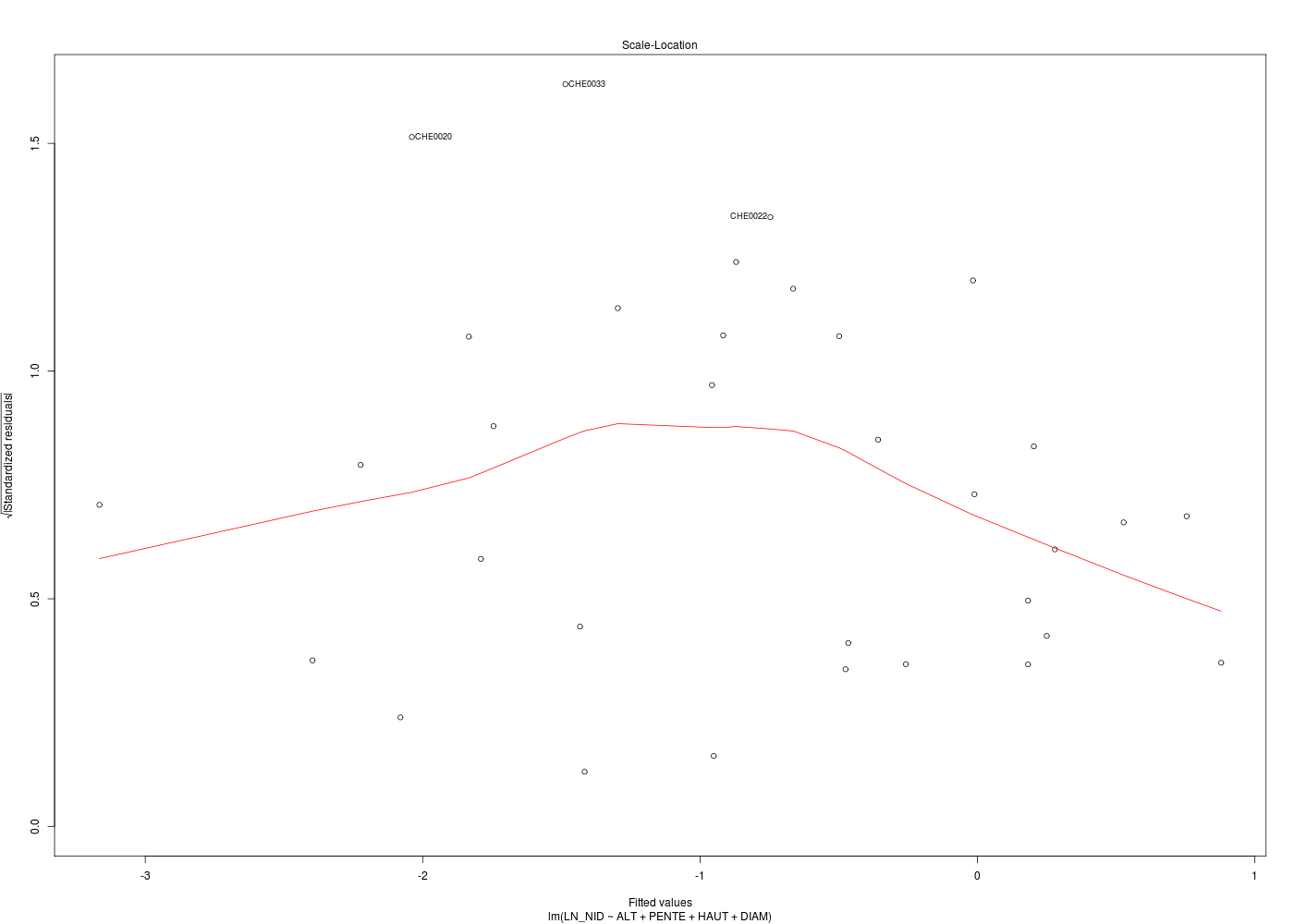
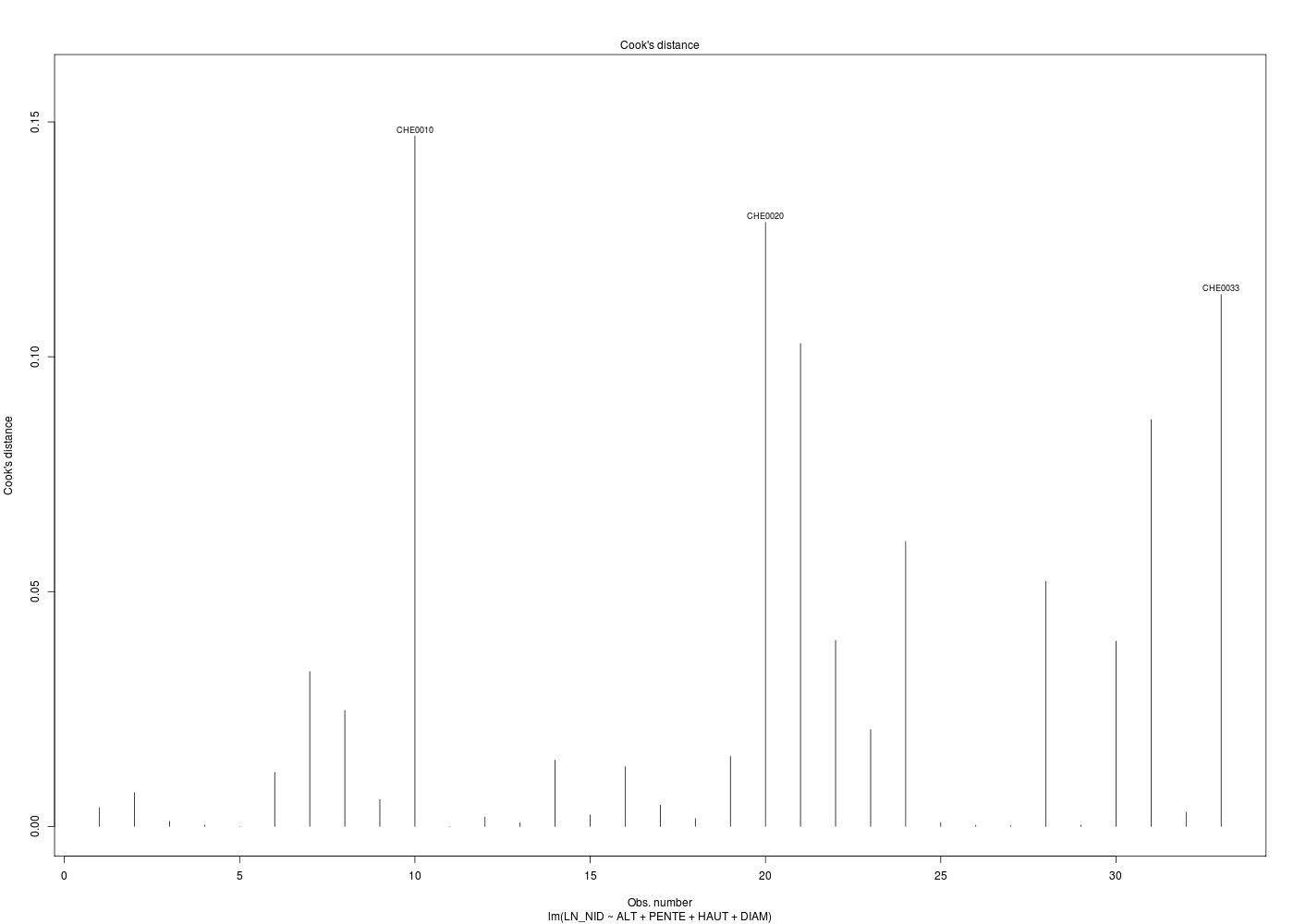
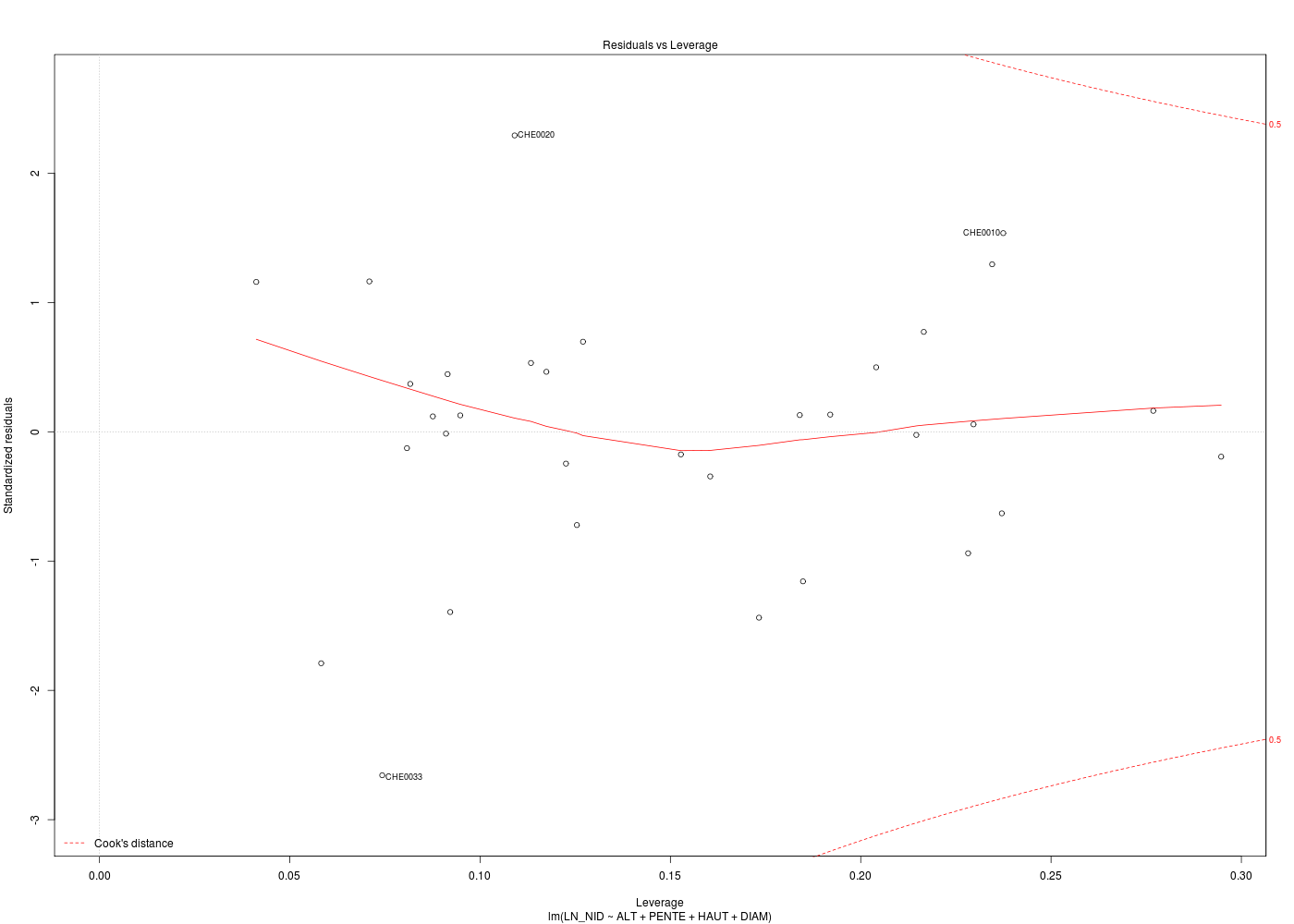
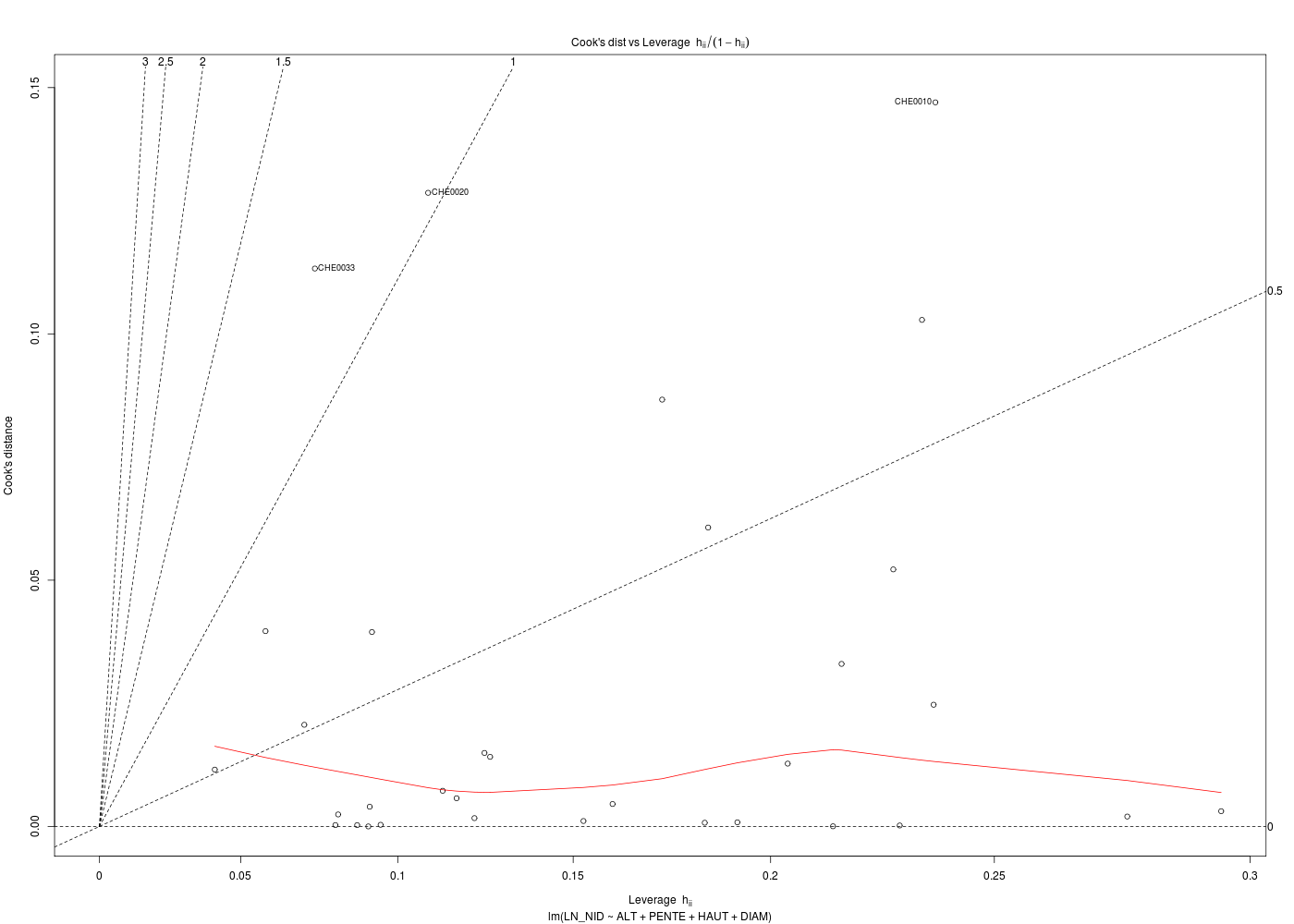
On ne fournit volontairement que le code R et les résultats d'exécution :
# chargement du package gdata library(gdata) # lecture des données hers <- read.xls("http://forge.info.univ-angers.fr/~gh/wstat/Eda/hersdata.xls") # filtrage des données en diabétiques/non diabétiques flt <- hers$diabetes=="yes" avecdiab <- hers[flt ,] sansdiab <- hers[(!flt) ,] # RLM de glucose en fonction de exercice, age, drinkany et BMI pour les personnes sans diabète ml1 <- lm(glucose ~ exercise + age + drinkany + BMI , data = sansdiab) print(summary(ml1)) # RLM de glucose en fonction de exercice, age, drinkany et BMI pour les personnes avec diabète ml2 <- lm(glucose ~ exercise + age + drinkany + BMI , data = avecdiab) print(summary(ml2)) # RLM de glucose en fonction de exercice, age, drinkany et BMI pour toutes les personnes ml3 <- lm(glucose ~ exercise + age + drinkany + BMI , data = hers) print(summary(ml3))> # filtrage des données > > flt <- hers$diabetes=="yes" > avecdiab <- hers[flt ,] > sansdiab <- hers[(!flt) ,] > # RLM de glucose en fonction de exercice, age, drinkany et BMI pour les personnes sans diabète > > ml1 <- lm(glucose ~ exercise + age + drinkany + .... [TRUNCATED] > print(summary(ml1)) Call: lm(formula = glucose ~ exercise + age + drinkany + BMI, data = sansdiab) Residuals: Min 1Q Median 3Q Max -47.582 -6.381 -0.901 5.508 32.015 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 89.47279 7.11416 12.577 <2e-16 *** exerciseyes -0.91077 0.42933 -2.121 0.0340 * age 0.06093 0.03144 1.938 0.0528 . drinkanyno -10.34285 6.66006 -1.553 0.1206 drinkanyyes -9.66632 6.66150 -1.451 0.1469 BMI 0.48899 0.04163 11.746 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 9.406 on 2024 degrees of freedom (2 observations deleted due to missingness) Multiple R-squared: 0.07188, Adjusted R-squared: 0.06959 F-statistic: 31.35 on 5 and 2024 DF, p-value: < 2.2e-16 > # RLM de glucose en fonction de exercice, age, drinkany et BMI pour les personnes avec diabète > > ml2 <- lm(glucose ~ exercise + age + drinkany + .... [TRUNCATED] > print(summary(ml2)) Call: lm(formula = glucose ~ exercise + age + drinkany + BMI, data = avecdiab) Residuals: Min 1Q Median 3Q Max -123.51 -32.88 -11.29 27.84 150.20 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 176.72625 22.89270 7.720 3.88e-14 *** exerciseyes 1.44587 3.90530 0.370 0.7113 age -0.64006 0.28642 -2.235 0.0257 * drinkanyyes 0.03523 4.11297 0.009 0.9932 BMI 0.65439 0.31903 2.051 0.0406 * --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 48.29 on 723 degrees of freedom (3 observations deleted due to missingness) Multiple R-squared: 0.01491, Adjusted R-squared: 0.009457 F-statistic: 2.735 on 4 and 723 DF, p-value: 0.02802 > # RLM de glucose en fonction de exercice, age, drinkany et BMI pour toutes les personnes > > ml3 <- lm(glucose ~ exercise + age + drinkany + BMI , .... [TRUNCATED] > print(summary(ml3)) Call: lm(formula = glucose ~ exercise + age + drinkany + BMI, data = hers) Residuals: Min 1Q Median 3Q Max -75.545 -18.767 -9.897 4.514 189.023 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 81.8232 26.2536 3.117 0.00185 ** exerciseyes -2.7443 1.4003 -1.960 0.05012 . age -0.2164 0.1026 -2.108 0.03508 * drinkanyno 0.3146 24.9805 0.013 0.98995 drinkanyyes -6.8424 24.9862 -0.274 0.78422 BMI 1.6900 0.1256 13.452 < 2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 35.29 on 2752 degrees of freedom (5 observations deleted due to missingness) Multiple R-squared: 0.08567, Adjusted R-squared: 0.08401 F-statistic: 51.57 on 5 and 2752 DF, p-value: < 2.2e-16Il y a beaucoup trop de variables pour effectuer directement une régression. De plus certaines variables ont des valeurs NA :
# régression de glucose en fonction de toutes les autres variables mlglucose <- lm(glucose~.,data=hers) print(summary(mlglucose))Call: lm(formula = glucose ~ ., data = hers) Residuals: Min 1Q Median 3Q Max -142.403 -7.193 -0.507 6.279 154.497 Coefficients: (5 not defined because of singularities) Estimate Std. Error t value Pr(>|t|) (Intercept) 5.270e+01 2.498e+01 2.109 0.03500 * HTplacebo 1.153e-02 9.692e-01 0.012 0.99051 age -4.511e-02 7.705e-02 -0.585 0.55832 racethOther -3.653e+00 3.035e+00 -1.204 0.22887 racethWhite -1.222e+00 1.829e+00 -0.668 0.50403 nonwhiteyes NA NA NA NA smokingyes -1.170e+00 1.424e+00 -0.822 0.41136 drinkanyno -4.666e+00 1.604e+01 -0.291 0.77118 drinkanyyes -3.285e+00 1.605e+01 -0.205 0.83780 exerciseyes 4.321e-01 9.761e-01 0.443 0.65808 physactmuch less active -1.649e+00 2.023e+00 -0.815 0.41513 physactmuch more active -2.940e+00 1.591e+00 -1.849 0.06463 . physactsomewhat less active -2.309e+00 1.349e+00 -1.712 0.08708 . physactsomewhat more active -1.294e+00 1.147e+00 -1.128 0.25961 globratexcellent 2.458e+00 1.618e+01 0.152 0.87928 globratfair 4.318e+00 1.606e+01 0.269 0.78802 globratgood 1.986e+00 1.604e+01 0.124 0.90147 globratpoor -1.270e+00 1.639e+01 -0.078 0.93823 globratvery good 3.524e+00 1.606e+01 0.219 0.82631 poorfairno NA NA NA NA poorfairyes NA NA NA NA medcond -1.232e-01 9.673e-01 -0.127 0.89868 htnmedsyes 8.263e-02 1.203e+00 0.069 0.94523 statinsyes 1.129e-01 9.588e-01 0.118 0.90631 diabetesyes 2.830e+01 1.736e+00 16.299 < 2e-16 *** dmpillsyes 5.854e+00 2.020e+00 2.898 0.00378 ** insulinyes 1.554e+01 2.061e+00 7.540 6.51e-14 *** weight -4.787e-01 3.793e-01 -1.262 0.20703 BMI 1.878e+00 9.125e-01 2.058 0.03965 * waist -2.359e-02 1.527e-01 -0.154 0.87727 WHR 1.072e+01 1.448e+01 0.740 0.45916 weight1 3.193e-01 3.790e-01 0.843 0.39958 BMI1 -1.513e+00 9.285e-01 -1.630 0.10325 waist1 1.909e-01 1.687e-01 1.131 0.25797 WHR1 -9.201e+00 1.551e+01 -0.593 0.55311 glucose1 3.199e-01 1.401e-02 22.830 < 2e-16 *** tchol -1.216e+05 1.162e+05 -1.046 0.29545 LDL 1.216e+05 1.162e+05 1.046 0.29545 HDL 1.216e+05 1.162e+05 1.046 0.29545 TG 2.433e+04 2.325e+04 1.046 0.29545 tchol1 -1.493e-01 3.611e-02 -4.134 3.69e-05 *** LDL1 1.147e-01 3.793e-02 3.023 0.00252 ** HDL1 7.626e-02 5.504e-02 1.386 0.16601 TG1 NA NA NA NA SBP -1.080e-02 2.967e-02 -0.364 0.71582 DBP 1.957e-02 5.809e-02 0.337 0.73621 age10 NA NA NA NA --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 22.5 on 2533 degrees of freedom (188 observations deleted due to missingness) Multiple R-squared: 0.6196, Adjusted R-squared: 0.6135 F-statistic: 100.6 on 41 and 2533 DF, p-value: < 2.2e-16Pour réaliser la régression demandée, il faudrait donc passer en revue toutes les variables, décider, en fonction du nombre de NA de celles que l'on garde et de celles que l'on écarte. Tout ce travail demande beaucoup trop de temps pour pouvoir être réalisé ici dans le cadre de cette séance de trois heures en tout.