![]()
![]()
Les dates de formation sont ici.
Solutions pour la séance numéro 2 (énoncés)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Solutions pour la séance numéro 2 (énoncés)
Pour définir un modèle linéaire avec R, il faut utiliser la fonction lm() et la droite correspondante se trace directement avec abline(). Pour afficher le modèle, on peut utiliser les fonctions génériques summary() et coef().
# chargement des fonctions (gH) source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") ## lecture des données (enregistrées en local) ## km <- lit.dar("km.dar") # lecture des données sur internet km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") idx <- order(km$distance) # tracé rapide # surtout pas # with( km, plot(essence~distance,type="b") ) with( km, plot(essence[idx]~distance[idx],type="p",pch=19,col="red" )) # ajout de la droite de régression et un titre ml <- lm(essence ~ distance,data=km) # pas besoin de idx ici abline(ml, col="blue",lwd=2) title("Consommation d'essence en fonction de la distance") # affichons le nom des points text(x=km$distance,y=km$essence+2,label=1:nrow(km)) # oups, le point 4 déborde, ajoutons-le text(x=400,y=33,label="4") # description du modèle cats("Modèle linéaire ESSENCE en fonction de DISTANCE") print( summary(ml) ) cats("ANOVA de ce modèle") print( anova(ml) ) # coefficients cats("coefficients seulement") print( coef(ml) ) # l'objet issu de lm est complexe cats("Objet modèle linéaire :") print( names(ml) ) print( str(ml) )Modèle linéaire ESSENCE en fonction de DISTANCE =============================================== Call: lm(formula = essence ~ distance, data = km) Residuals: Min 1Q Median 3Q Max -1.6824 -0.9326 -0.6783 0.0686 4.4836 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.350376 0.894150 3.747 0.00458 ** distance 0.083320 0.004985 16.714 4.39e-08 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.835 on 9 degrees of freedom Multiple R-squared: 0.9688, Adjusted R-squared: 0.9653 F-statistic: 279.4 on 1 and 9 DF, p-value: 4.393e-08 ANOVA de ce modèle ================== Analysis of Variance Table Response: essence Df Sum Sq Mean Sq F value Pr(>F) distance 1 940.61 940.61 279.36 4.393e-08 *** Residuals 9 30.30 3.37 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 coefficients seulement ====================== (Intercept) distance 3.35037574 0.08331991 Objet modèle linéaire : ======================= [1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign" "qr" "df.residual" "xlevels" "call" "terms" [12] "model" List of 12 $ coefficients : Named num [1:2] 3.3504 0.0833 ..- attr(*, "names")= chr [1:2] "(Intercept)" "distance" $ residuals : Named num [1:11] -0.6824 -0.0144 1.6537 -0.6783 0.1516 ... ..- attr(*, "names")= chr [1:11] "traj0001" "traj0002" "traj0003" "traj0004" ... $ effects : Named num [1:11] -50.051 -30.669 1.756 -0.609 0.304 ... ..- attr(*, "names")= chr [1:11] "(Intercept)" "distance" "" "" ... $ rank : int 2 $ fitted.values: Named num [1:11] 11.7 20 28.3 36.7 15.8 ... ..- attr(*, "names")= chr [1:11] "traj0001" "traj0002" "traj0003" "traj0004" ... $ assign : int [1:2] 0 1 $ qr :List of 5 ..$ qr : num [1:11, 1:2] -3.317 0.302 0.302 0.302 0.302 ... .. ..- attr(*, "dimnames")=List of 2 .. .. ..$ : chr [1:11] "traj0001" "traj0002" "traj0003" "traj0004" ... .. .. ..$ : chr [1:2] "(Intercept)" "distance" .. ..- attr(*, "assign")= int [1:2] 0 1 ..$ qraux: num [1:2] 1.3 1.19 ..$ pivot: int [1:2] 1 2 ..$ tol : num 1e-07 ..$ rank : int 2 ..- attr(*, "class")= chr "qr" $ df.residual : int 9 $ xlevels : Named list() $ call : language lm(formula = essence ~ distance, data = km) $ terms :Classes 'terms', 'formula' length 3 essence ~ distance .. ..- attr(*, "variables")= language list(essence, distance) .. ..- attr(*, "factors")= int [1:2, 1] 0 1 .. .. ..- attr(*, "dimnames")=List of 2 .. .. .. ..$ : chr [1:2] "essence" "distance" .. .. .. ..$ : chr "distance" .. ..- attr(*, "term.labels")= chr "distance" .. ..- attr(*, "order")= int 1 .. ..- attr(*, "intercept")= int 1 .. ..- attr(*, "response")= int 1 .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv> .. ..- attr(*, "predvars")= language list(essence, distance) .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric" .. .. ..- attr(*, "names")= chr [1:2] "essence" "distance" $ model :'data.frame': 11 obs. of 2 variables: ..$ essence : int [1:11] 11 20 30 36 16 12 7 8 5 10 ... ..$ distance: int [1:11] 100 200 300 400 150 50 60 70 20 100 ... ..- attr(*, "terms")=Classes 'terms', 'formula' length 3 essence ~ distance .. .. ..- attr(*, "variables")= language list(essence, distance) .. .. ..- attr(*, "factors")= int [1:2, 1] 0 1 .. .. .. ..- attr(*, "dimnames")=List of 2 .. .. .. .. ..$ : chr [1:2] "essence" "distance" .. .. .. .. ..$ : chr "distance" .. .. ..- attr(*, "term.labels")= chr "distance" .. .. ..- attr(*, "order")= int 1 .. .. ..- attr(*, "intercept")= int 1 .. .. ..- attr(*, "response")= int 1 .. .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv> .. .. ..- attr(*, "predvars")= language list(essence, distance) .. .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric" .. .. .. ..- attr(*, "names")= chr [1:2] "essence" "distance" - attr(*, "class")= chr "lm" NULL
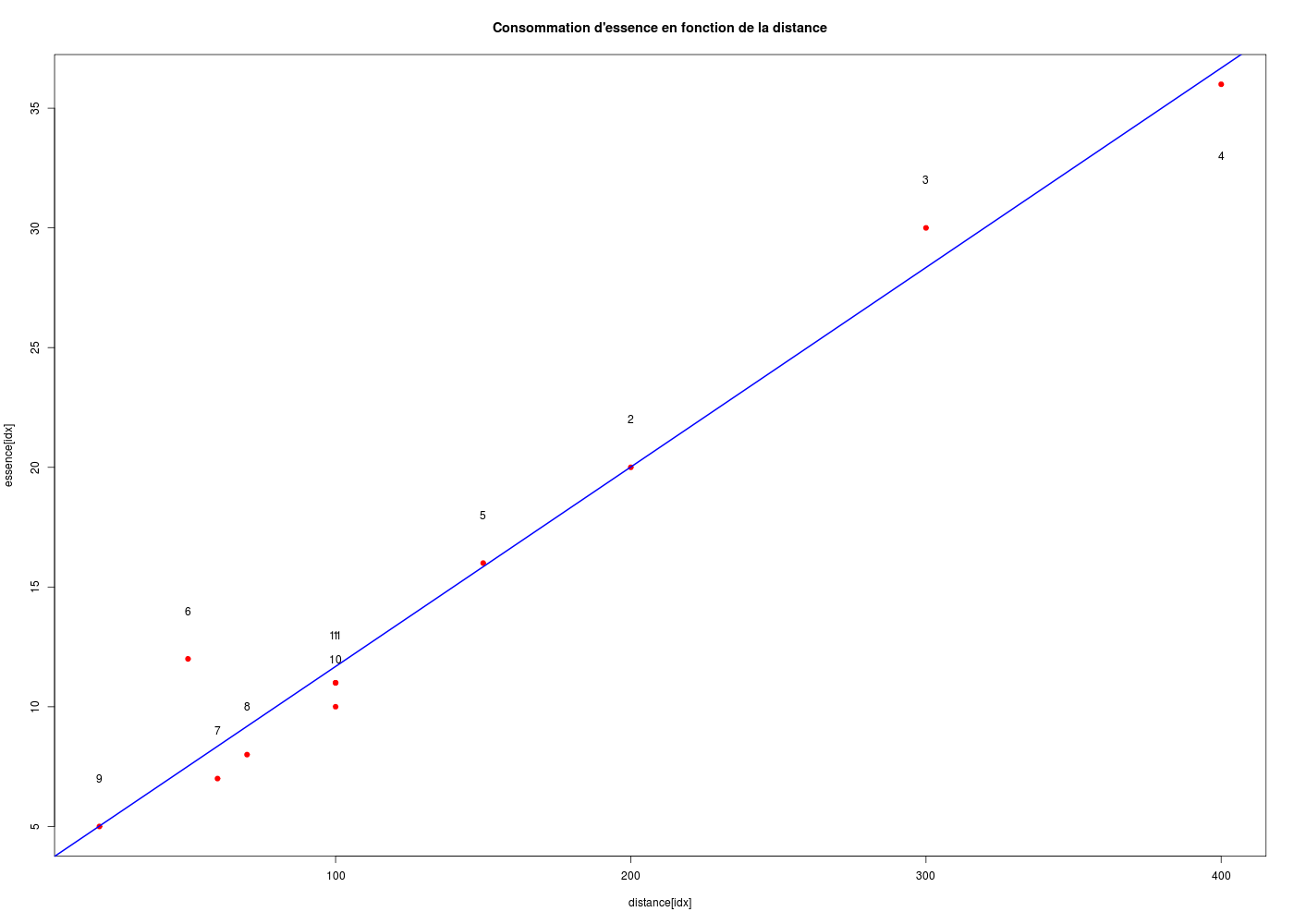
Il est d'usage de commencer par regarder si le modèle est significativement différent de zéro dans les sorties de summary() grâce à la p-value du test de Fisher. Si cette p-value est supérieure à 0,05 «le modèle ne vaut rien». Si le modèle est significativement différent de zéro, on peut s'intéresser directement au coefficient de détermination en régression linéaire simple. Par contre en régression linéaire multiple, il faut regarder les p-values des coefficients pour envisager une sélection de variables avant d'utiliser le coefficient de détermination ajusté.
Ici, le modèle est significativement différent de zéro (p=4.393e-08<<0,05) et on peut donc dire ici que la consommation est d'environ 0,08332 litre par km, ou, pour parler plus couramment, d'environ 8,332 litre "aux 100". Donc si la distance augmente d'un km, la consommation augmente de 0,008332 litre. Par contre il ne faut pas mésestimer le terme constant, soit ici 3,53 l qui doit correspondre au premier démarrage de la voiture (comme le montre l'image, il s'agit d'une XM et il ne faut pas rouler tant que le systéme hydraulique n'est pas opérationnel, donc tant que la voiture n'est pas en "position haute", ce qui dure au moins 30 secondes...) et à la consommation pendant l'arrêt. Cette constante sera d'autant plus importante que la distance est effectuée en ville, à cause des stops et des feux rouges, mais il est clair que ces interprétations ne sont pas statistiques et font appel à des connaissances contextuelles liées aux données. Le modèle est un "très bon modèle" puisque le coefficient de détermination vaut 0.97 (donc très proche de 1).
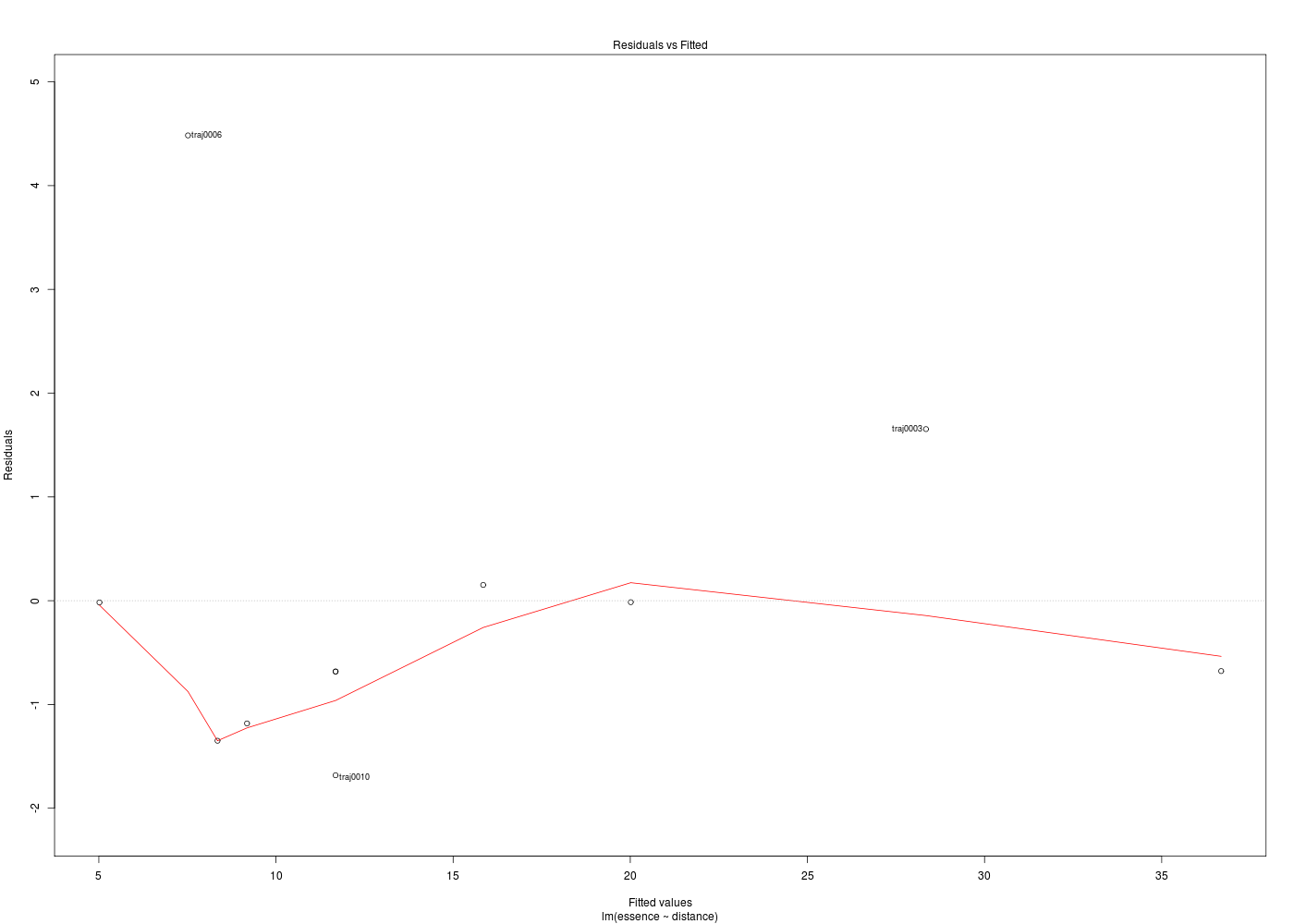
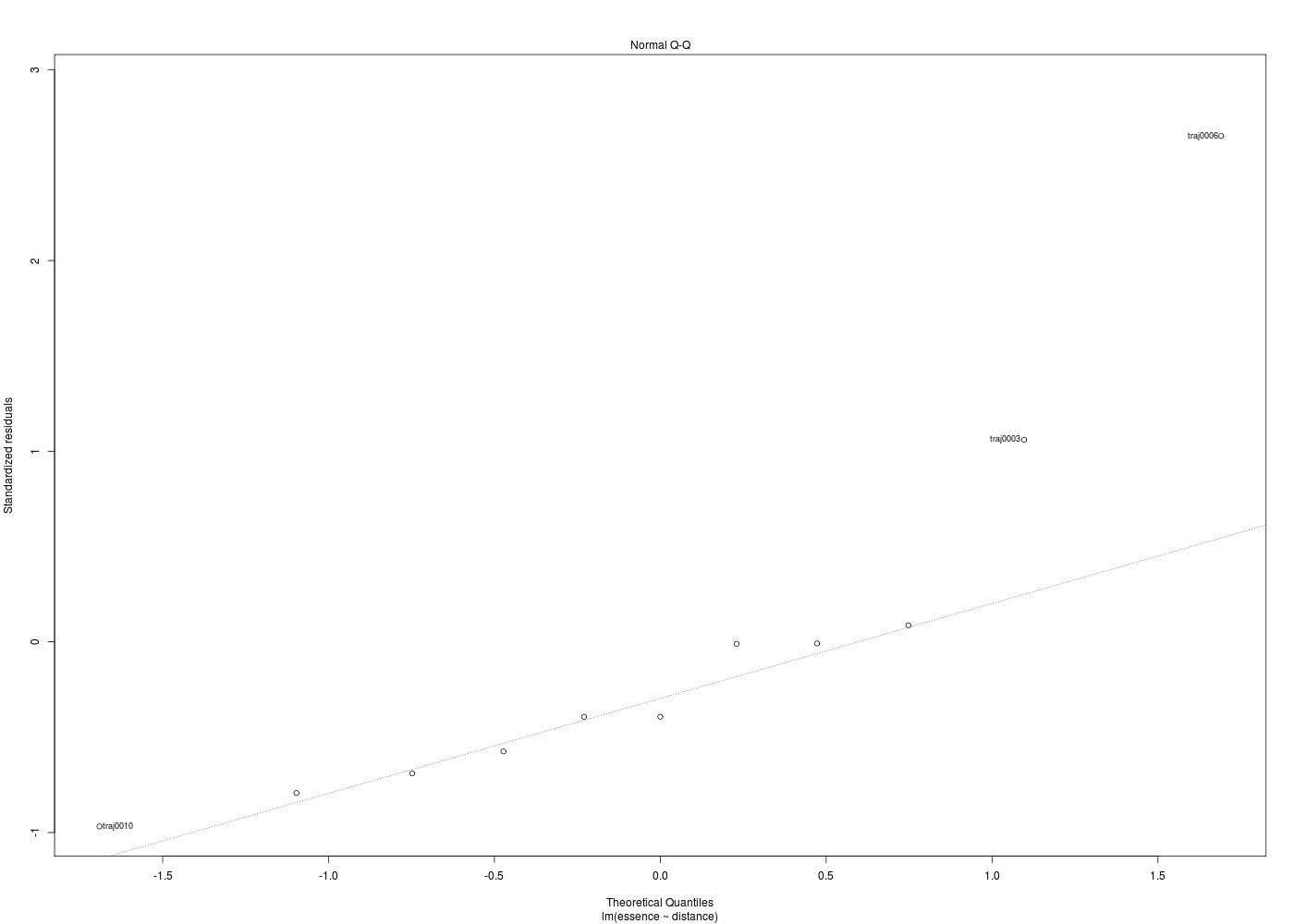
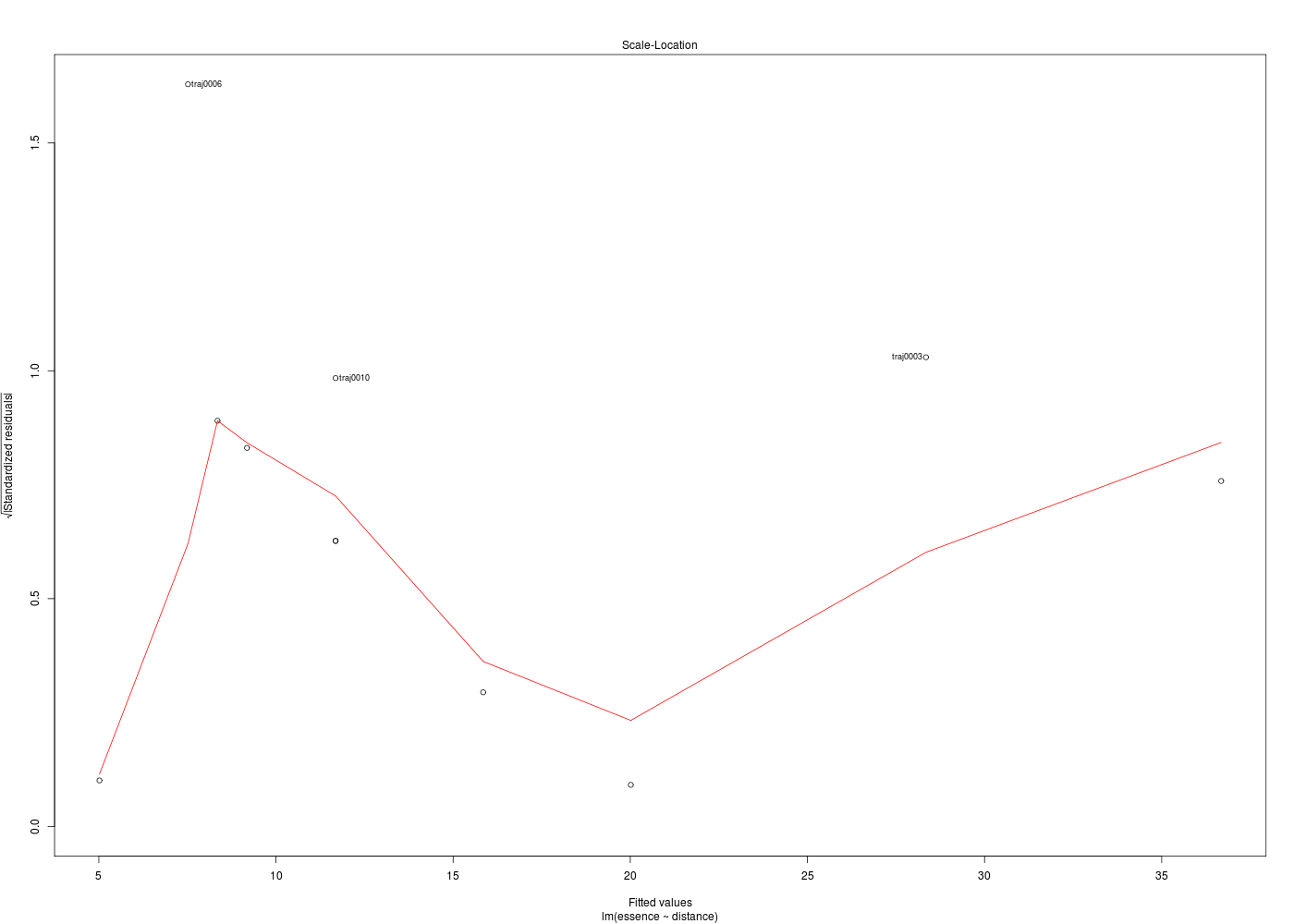
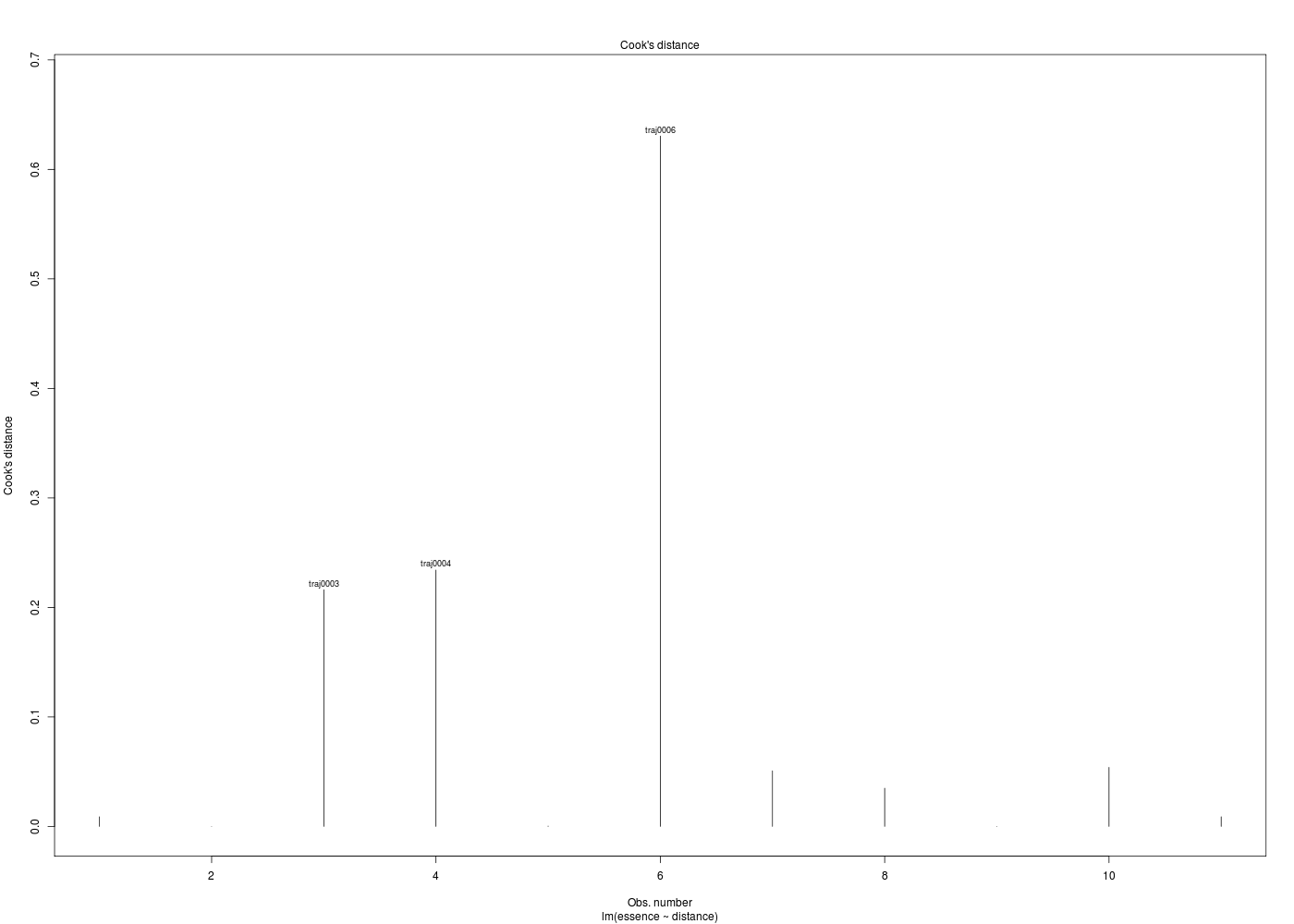
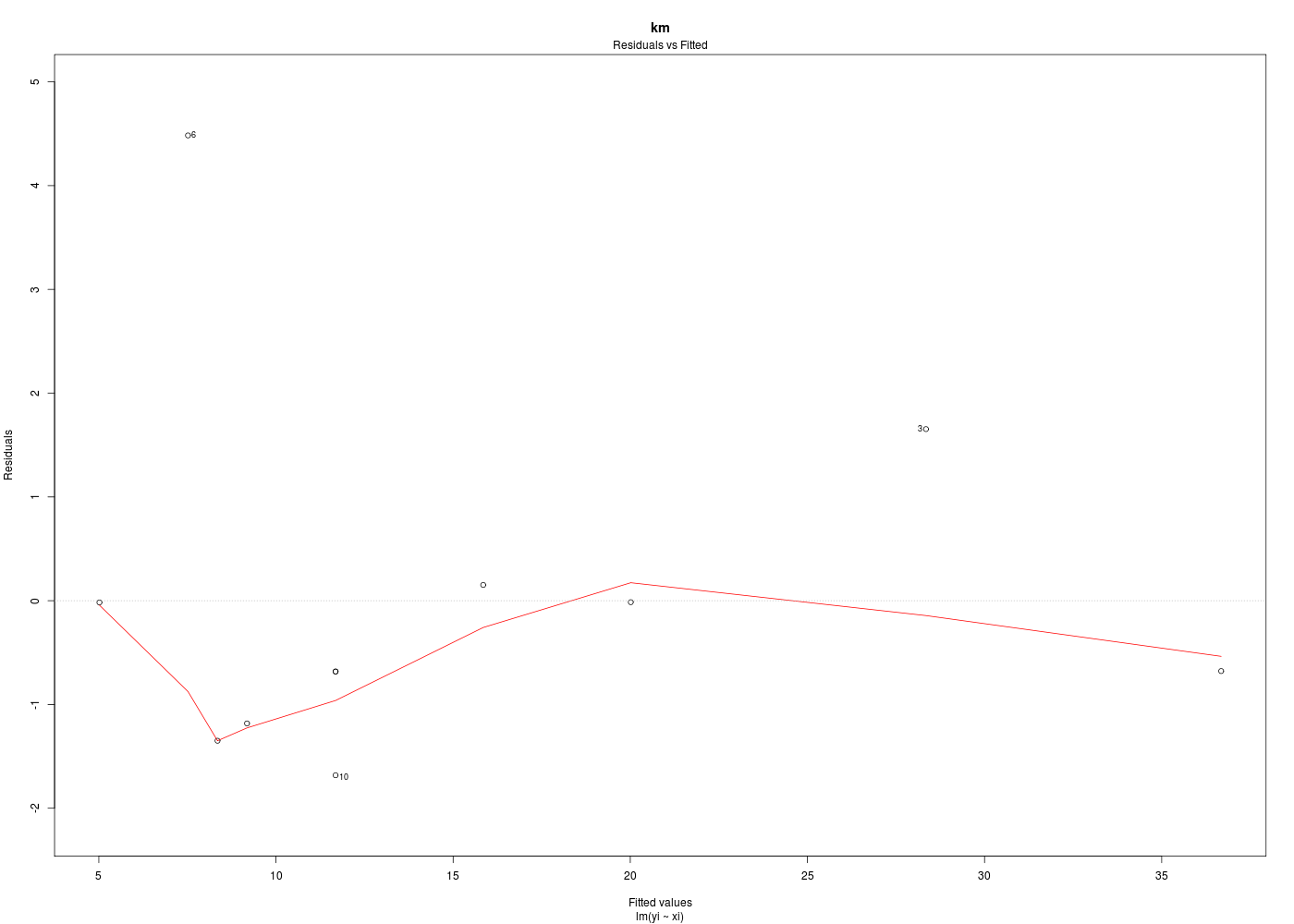
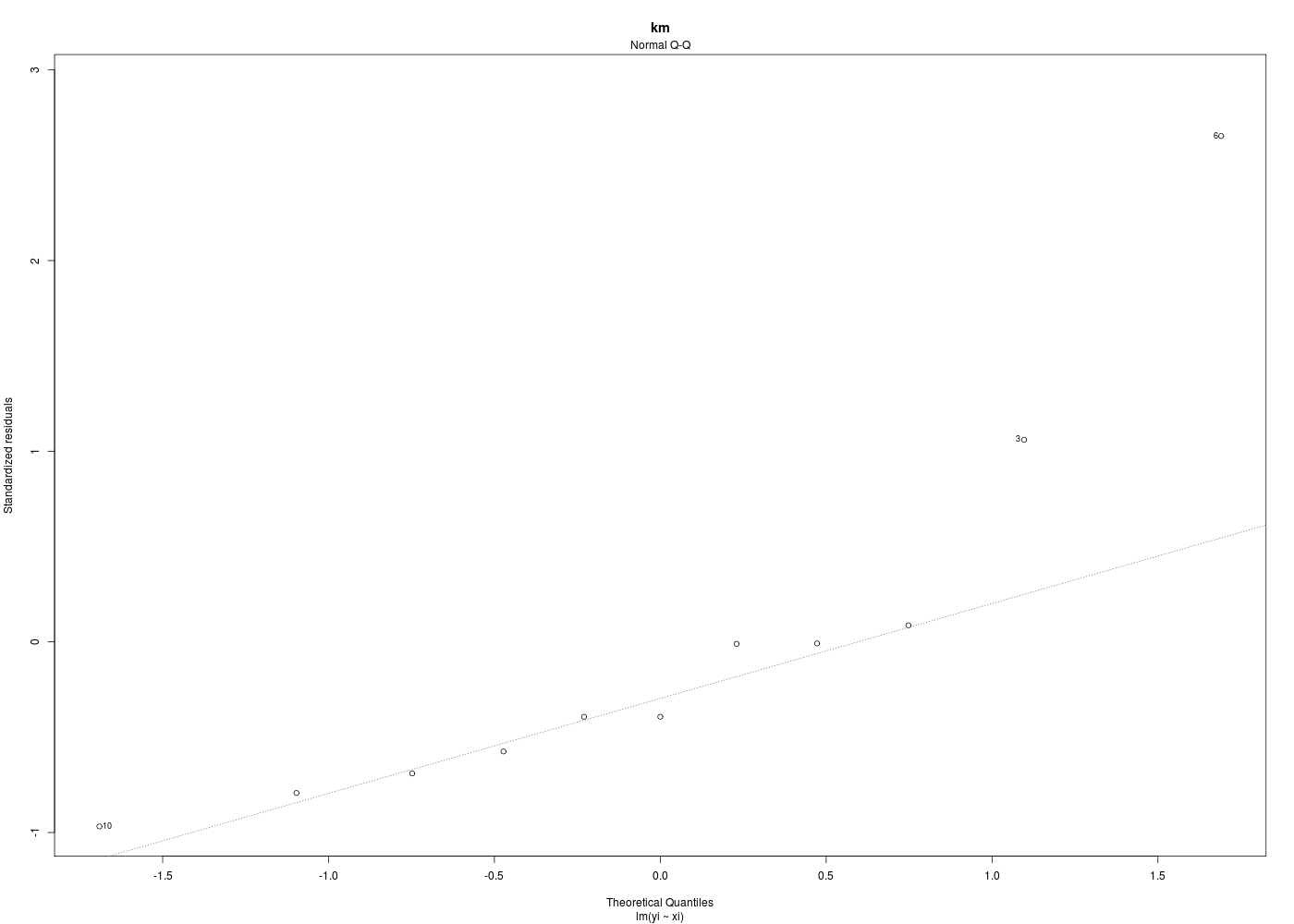
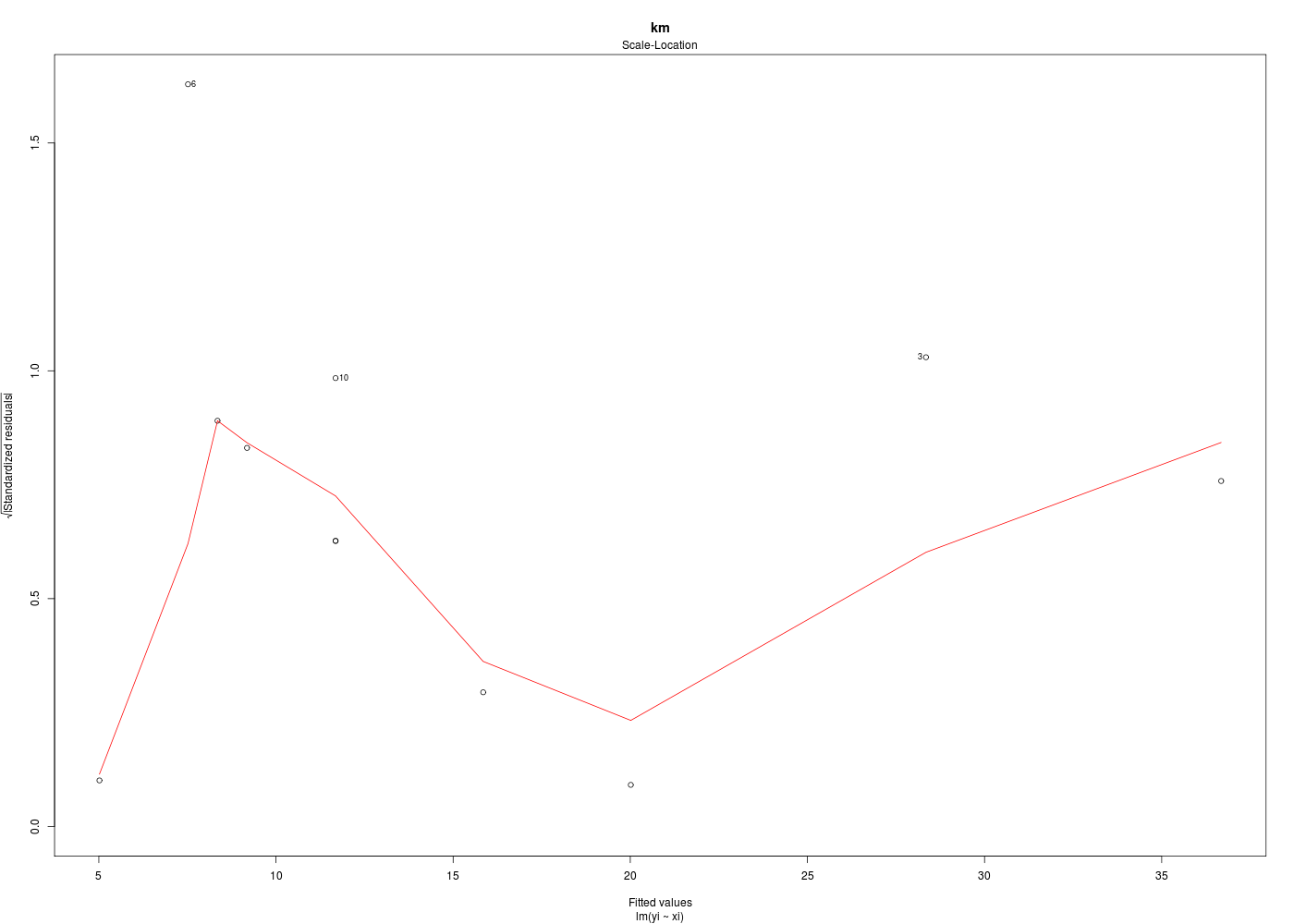
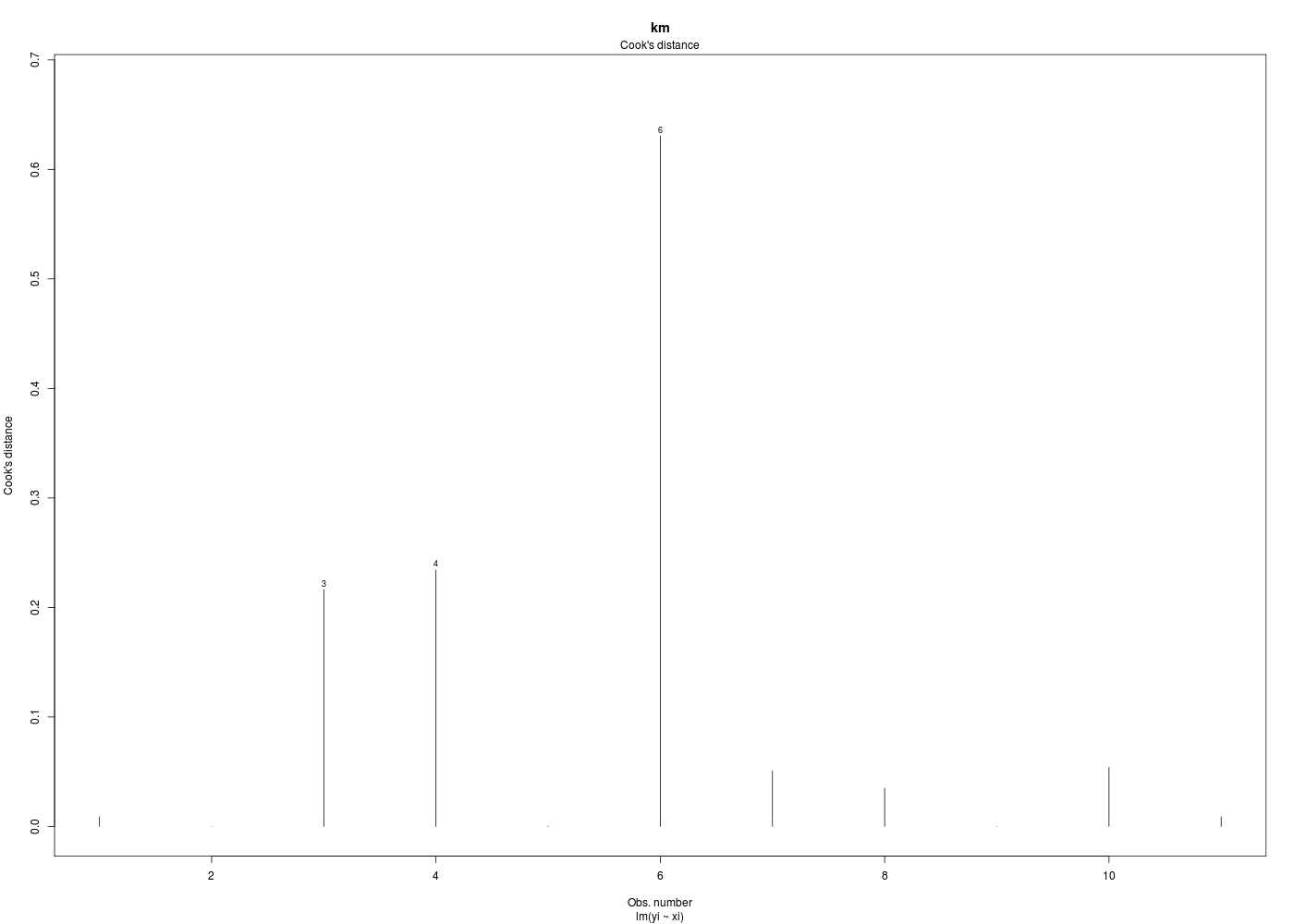
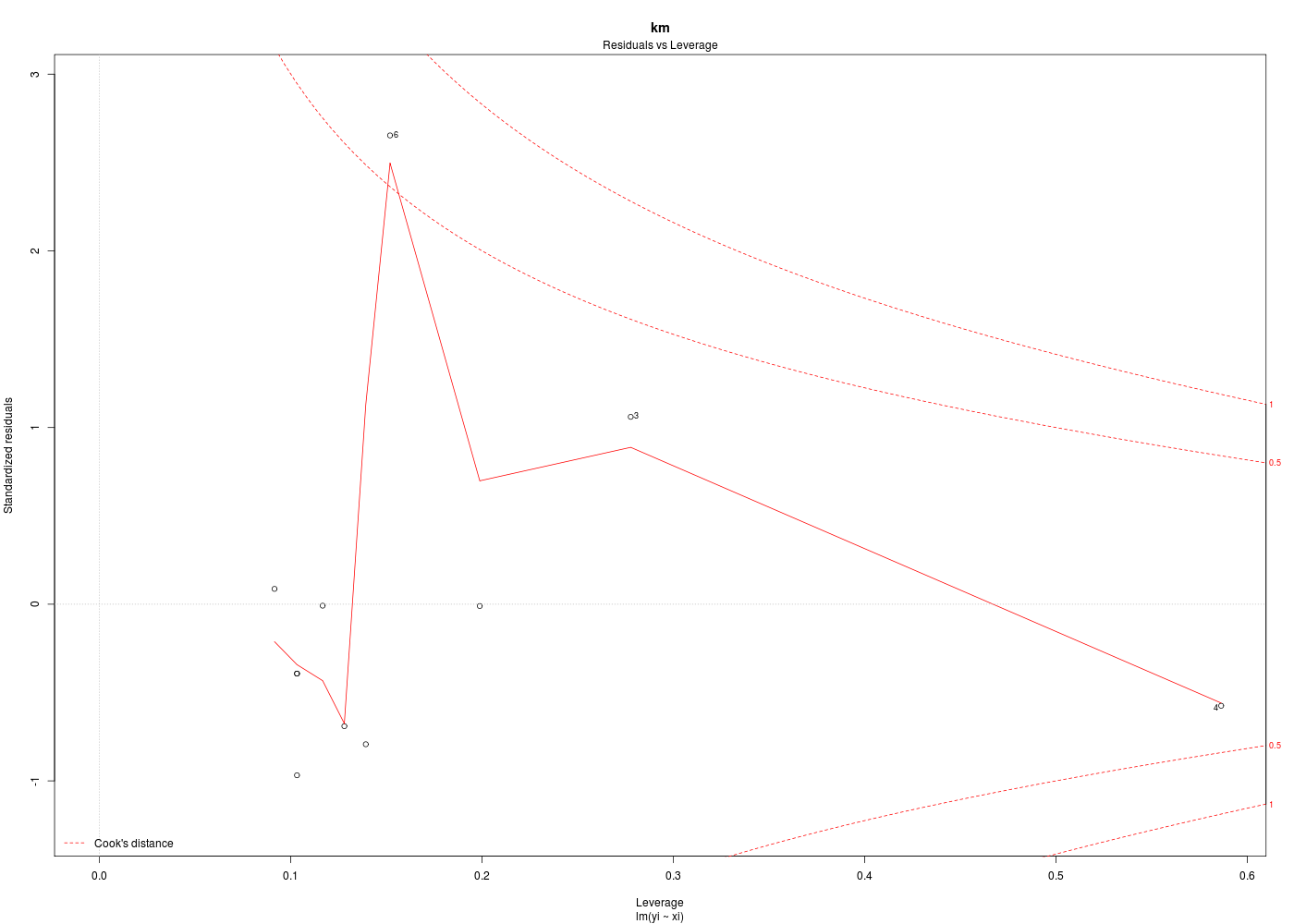
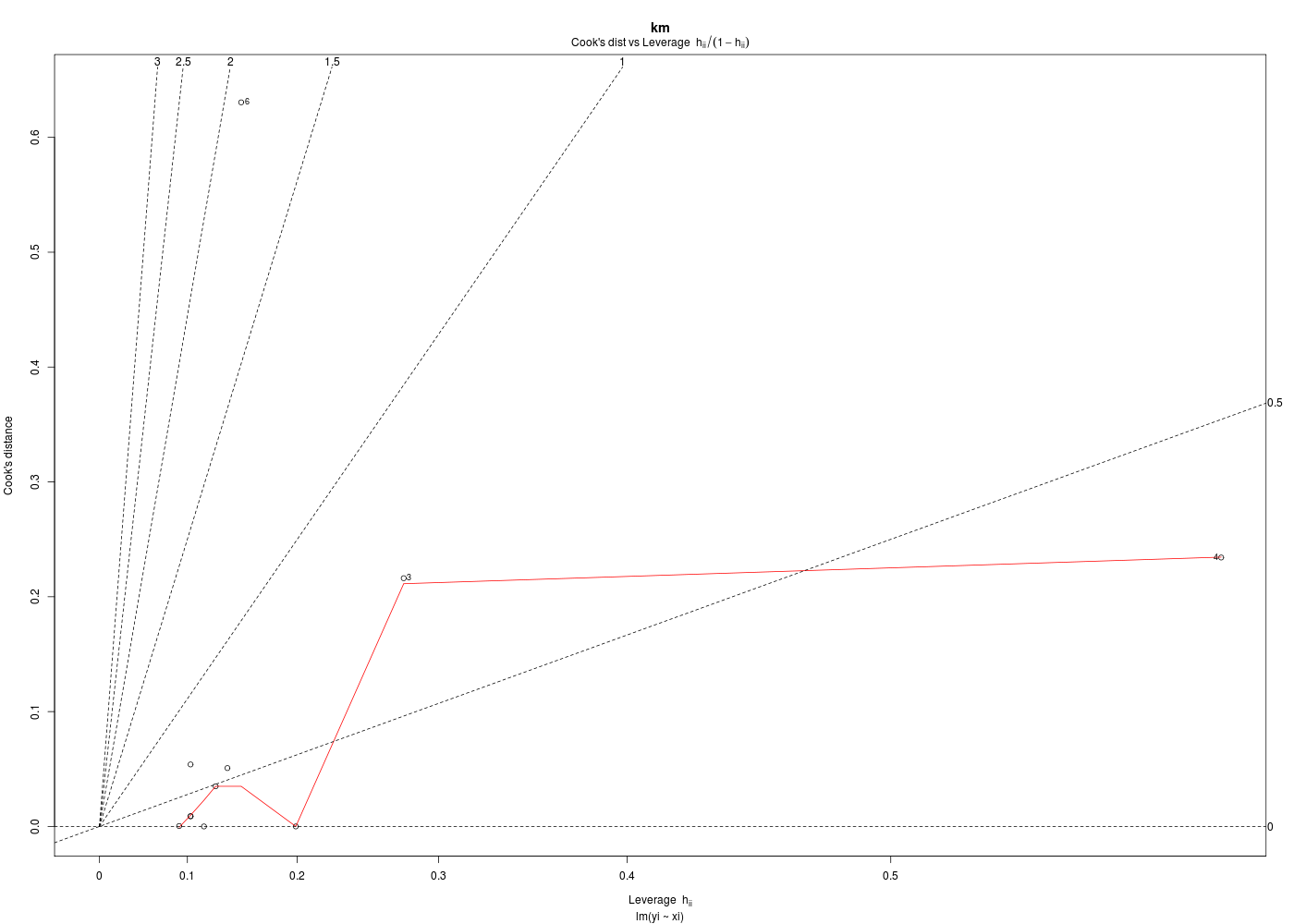
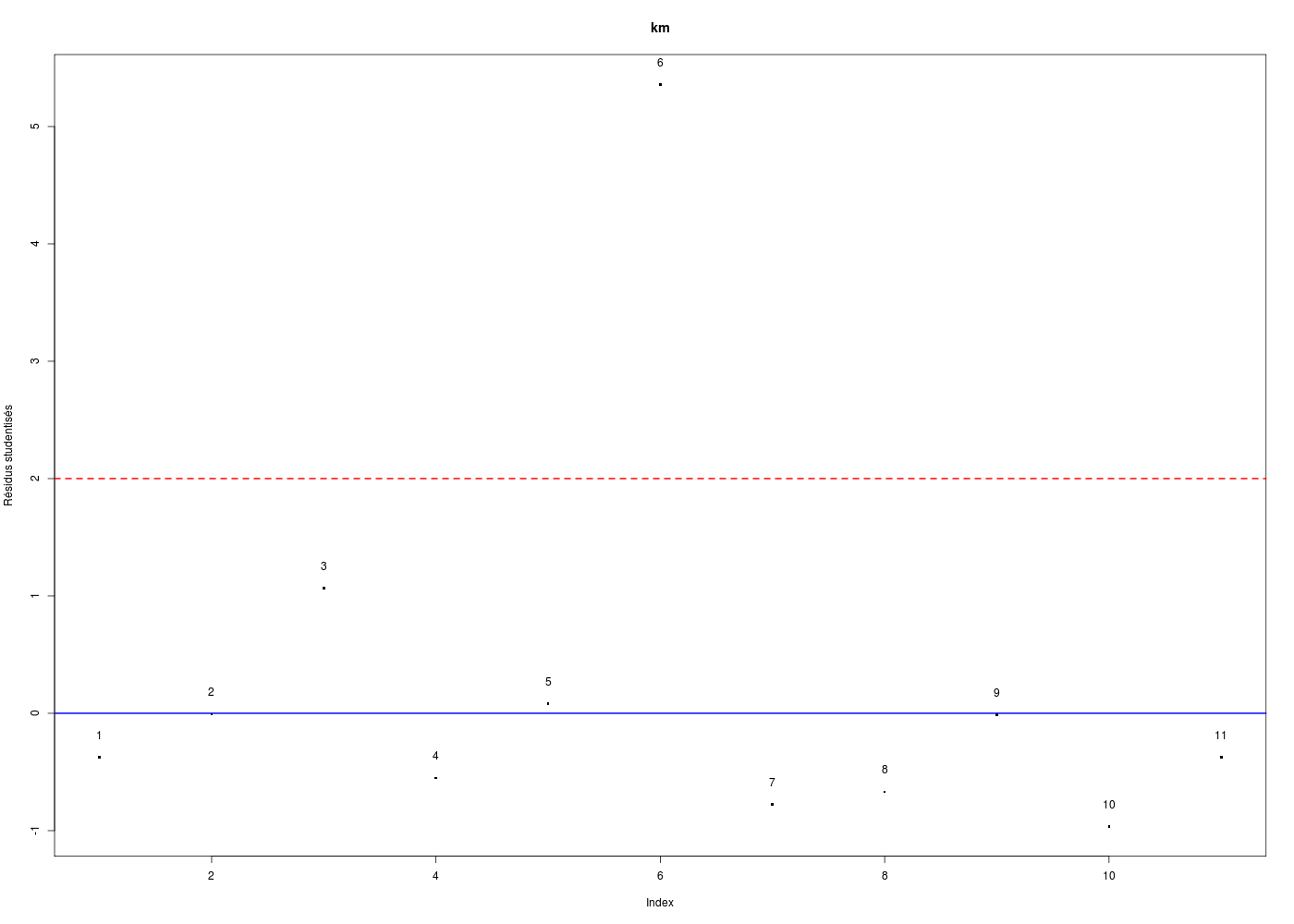
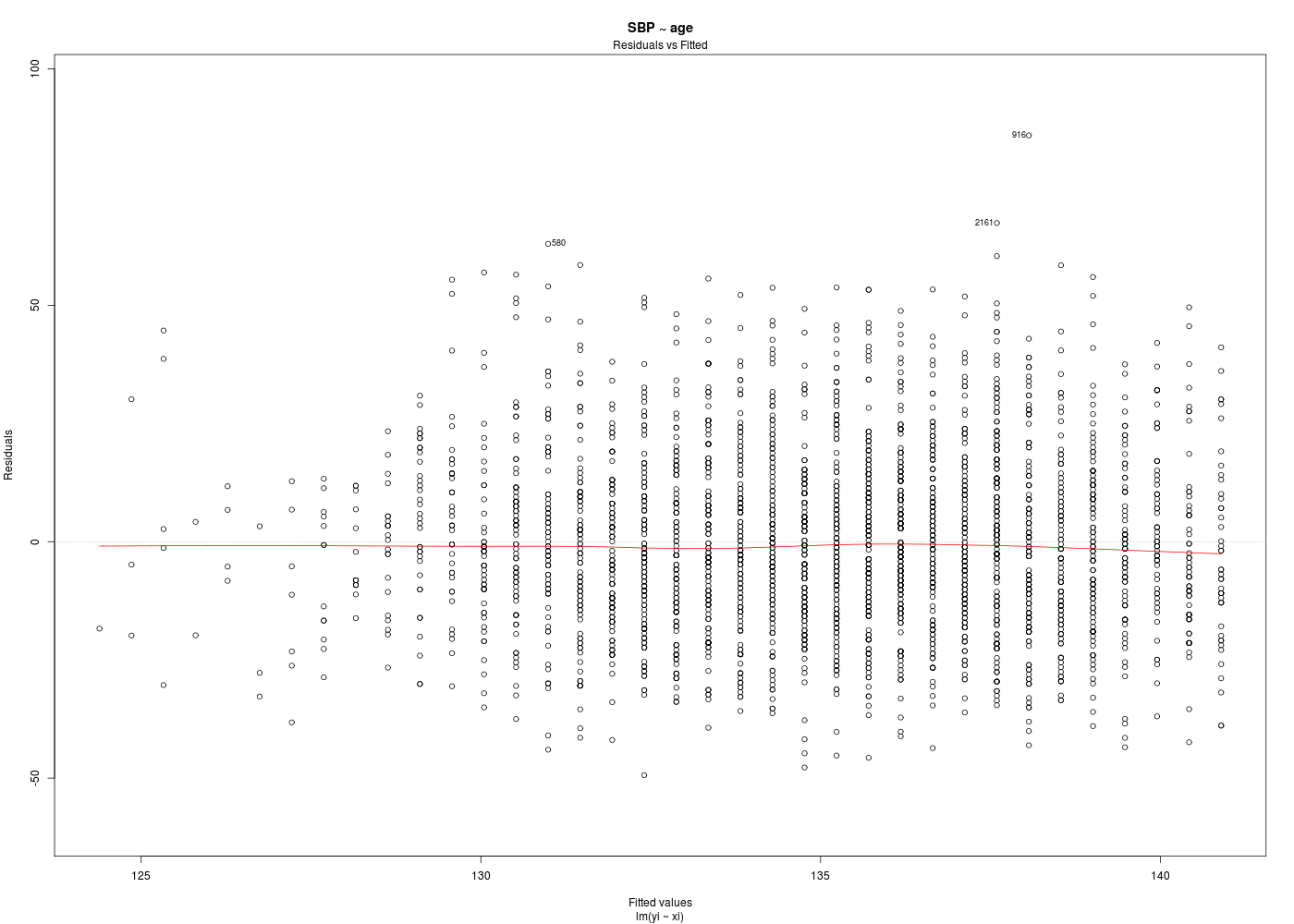
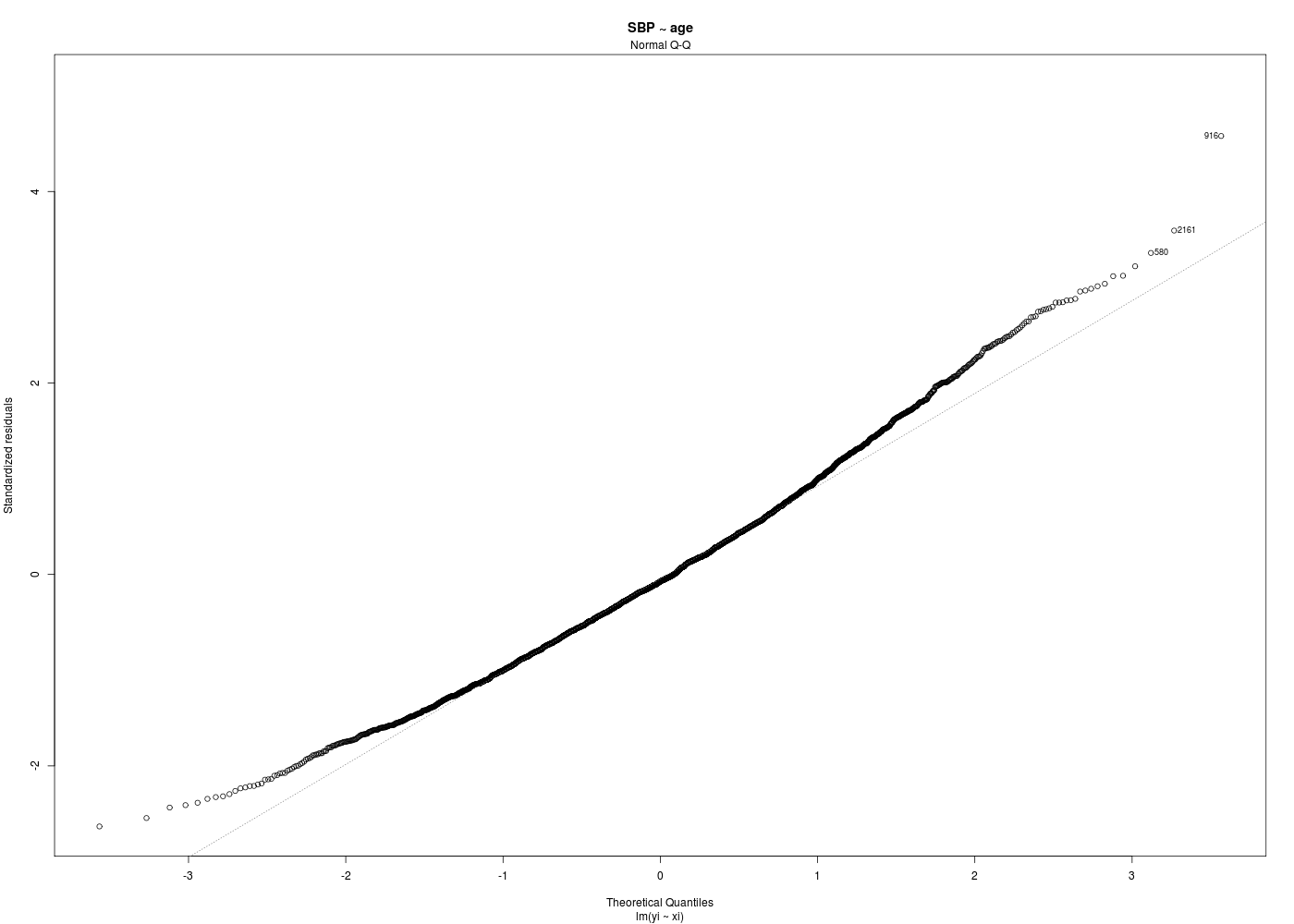
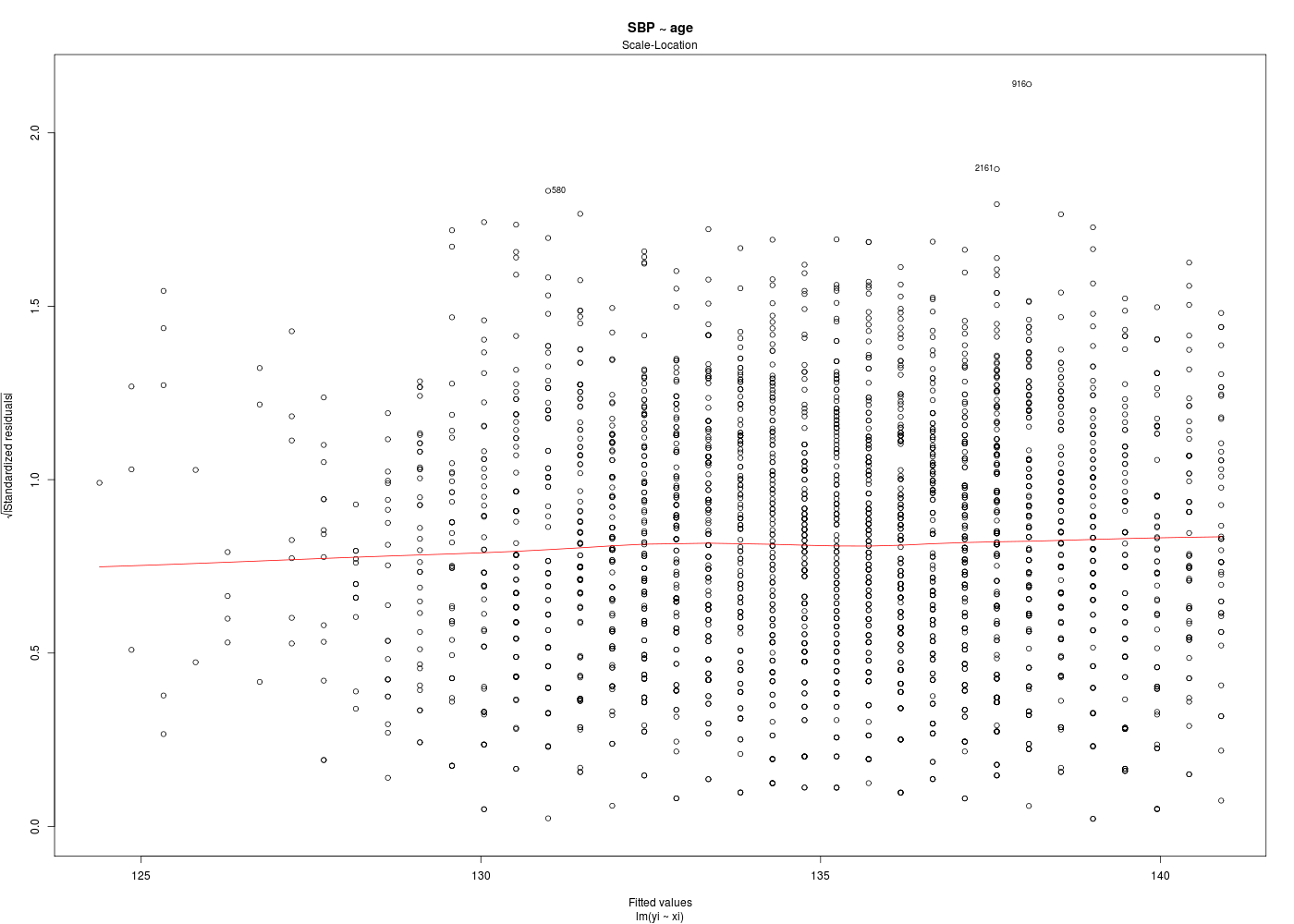
Dans la mesure où un modèle linéaire est [presque] toujours calculable, il est important de savoir si la modélisation est significativement non nulle, c'est-à-dire si on peut accepter le modèle. C'est pour cela qu'il faut utiliser le test de Fisher (de l'analyse de la variance) appliqué au modèle, et ensuite regarder le coefficient de corrélation linéaire. Il ne faut pas accorder une confiance aveugle à ces tests, qui peuvent être mis en défaut notamment pour de petits échantillons. On doit donc systématiquement réaliser une analyse des résidus, ce qui peut souvent se réduire à des tracés diagnostics que fournit la fonction plot.lm() du package stats. C'est ce qui explique que R fournit 6 tracés (dont 4 seulement par défaut, repérés ci-dessous par une étoile) pour plot.lm(modele) qui est équivalent à plot(lm(modele)).
x y 1 * Fitted values Residuals 2 * Theoretical quantiles Standardized residuals 3 * Fitted values Root of standardized residuals 4 Observation number Cook's distance 5 * Leverage Standardized residuals 6 Leverage hn Cook's distance Pour obtenir les 6 tracés, il faut utiliser le paramètre which :
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # tracé des 6 graphiques de diagnostics pour le modèle ml <- lm(essence ~ distance,data=km) for (idg in (1:6)) { plot(ml,which=idg) } # fin pour idg # tracés et stockage des tracés dans des fichiers PNG par(ask=FALSE) for (idg in (1:6)) { fgr <- paste("kmdiagno_",idg,".png",sep="") gr(fgr) plot(ml,which=idg) dev.off() cat("fichier ",fgr," généré.\n") } # fin pour idg
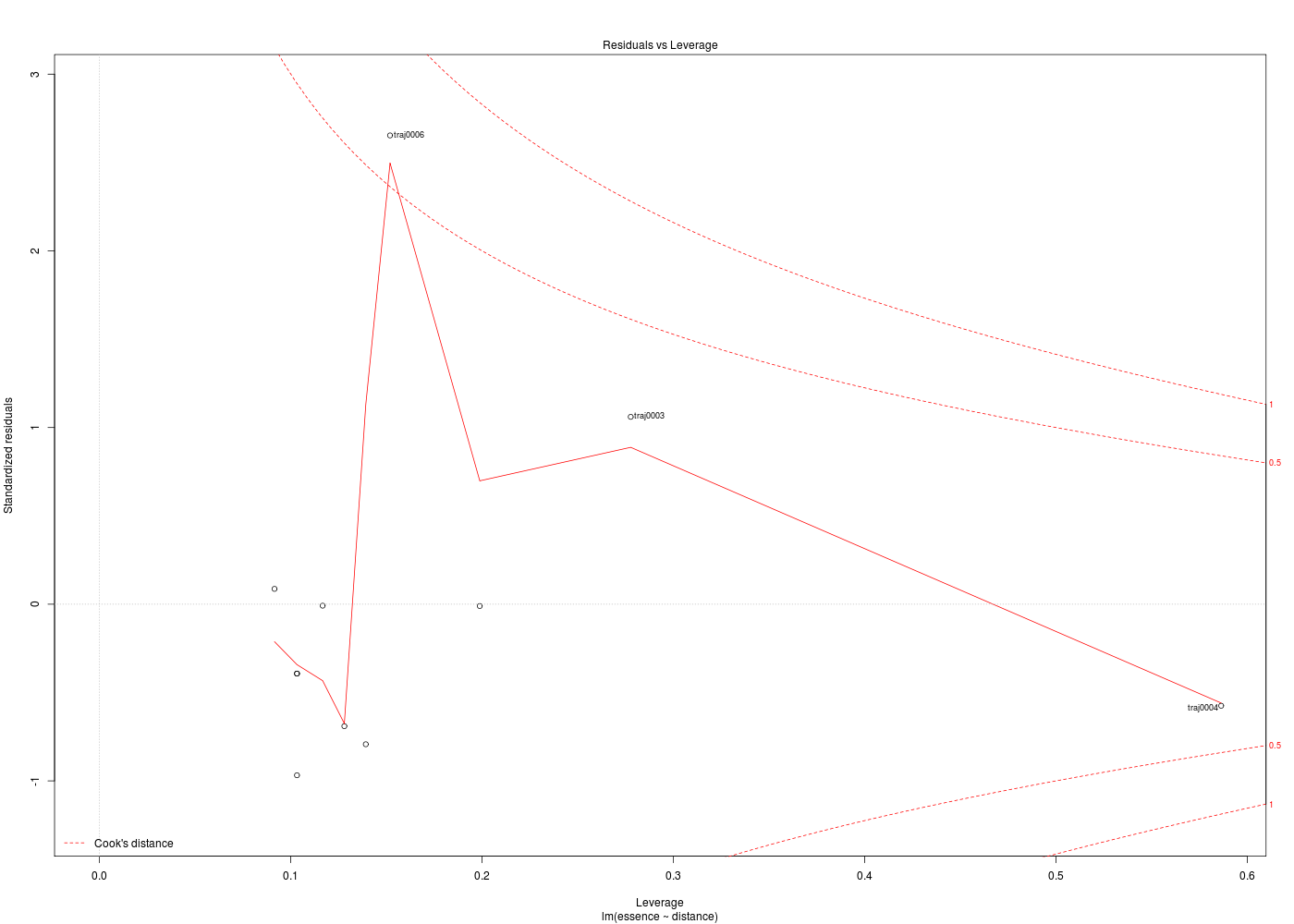
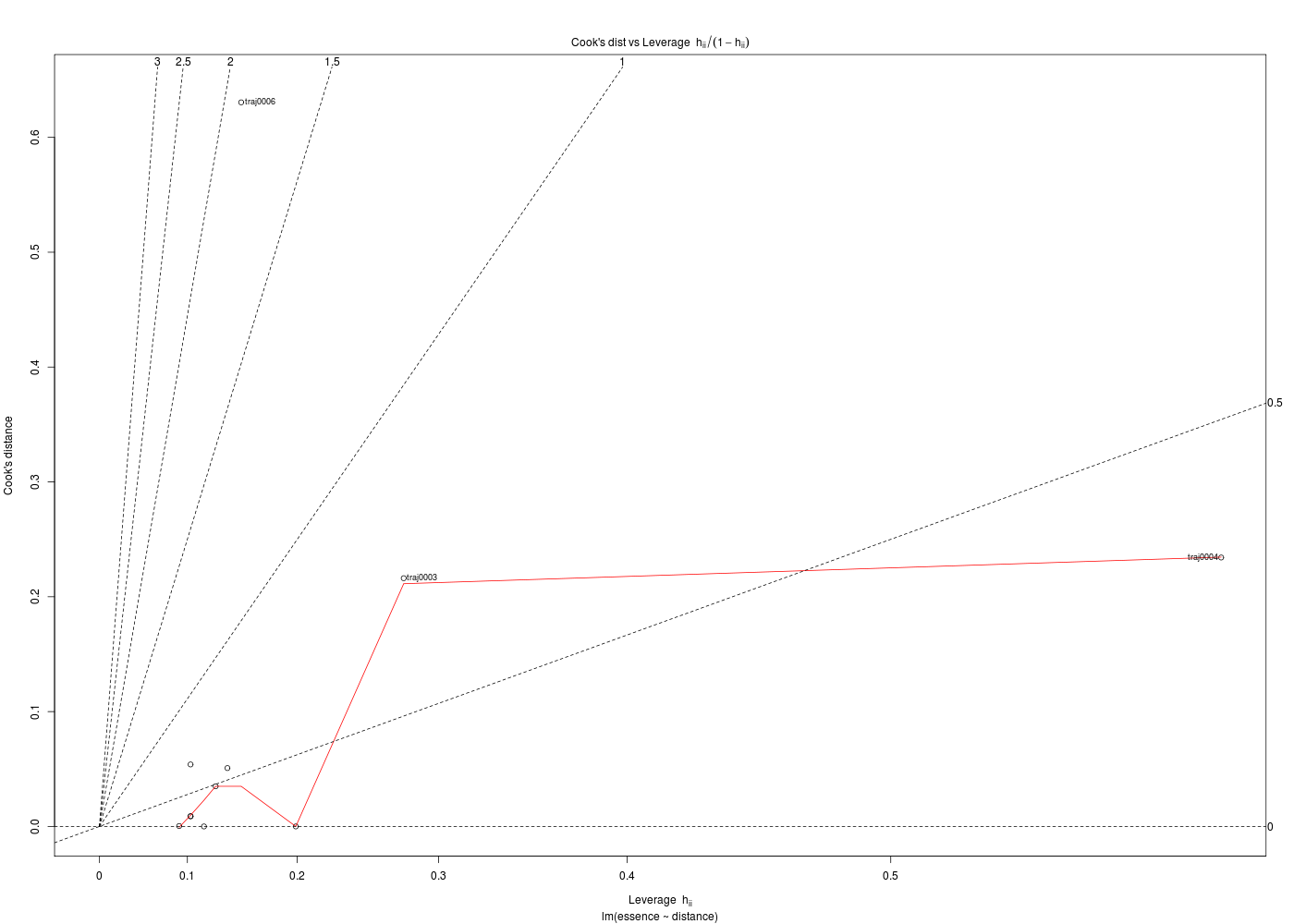
Les graphiques obtenus se nomment tracés de diagnostic du modèle et viennent analyser les résidus, les points-leviers, les outliers... Ici par exemple, les trois premiers graphiques montrent que les trajets 3, 6 et 10 semblent ne pas bien être en accord avec le modèle.
Avec la fonction predict() appliquée à un data frame avec les mêmes noms de variables, on peut utiliser le modèle linéaire pour prédire de nouvelles valeurs :
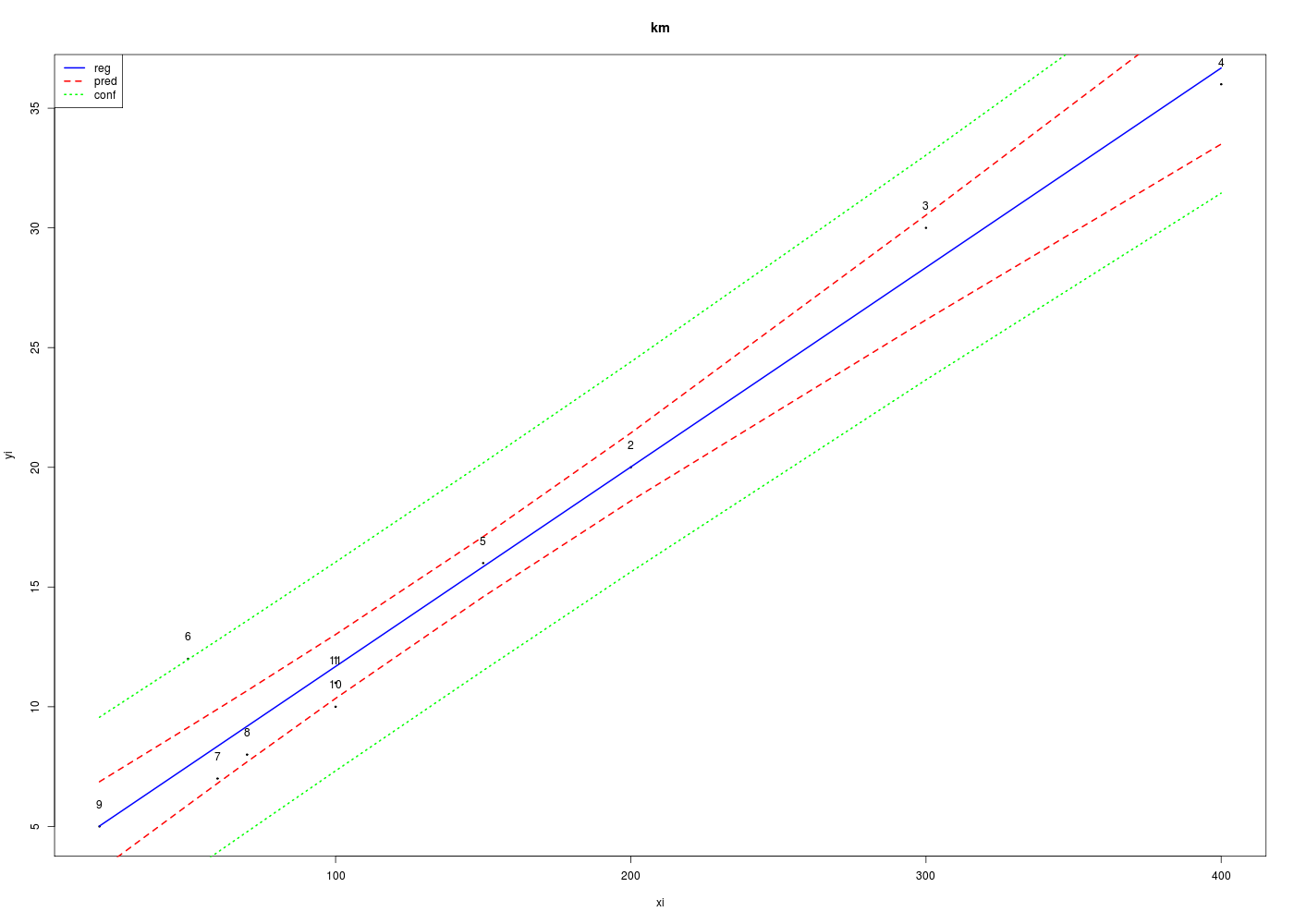
# lecture des données km <- lit.dar("km.dar") # régression linéaire ml <- lm(essence ~ distance,data=km) # prédictions cats("valeurs prédites") newx <- c(100,250) # surtout pas # newy <- predict(ml,newx) # car cela produit l'erreur # Erreur dans eval(predvars, data, env) : # argument numérique 'envir' n'ayant une longueur unitaire # on construit un nouveau data frame avec le même nom pour x newxdf <- data.frame(distance=newx) newy <- predict(ml,newxdf) print(rbind(newx,newy)) # tracé avec ajout des points prédits et des intervalles de confiance co <- round(coef(ml),3) idx <- order(km$distance) formule <- paste("Consommation = ", 100*co[2]," x distance/100 + ",co[1],sep="") gr("kmpreds.png") par(omi=c(0,1,0,0)) # pour avoir plus place à gauche de l'axe with( km, plot(essence[idx]~distance[idx],type="p", pch=19,col="blue",xlim=c(0,800),ylim=c(0,60), xlab="distance (kilomètres)",ylab="essence (litres)",main=formule ) # fin de plot ) # fin de with abline(ml,lwd=2,col="black") # droite de régression (moindres carrés ordinaires) # points pour lesquels on veut une prédiction points(cbind(newx,newy),cex=1.5,col="red",pch=19) lines(rep(newx[1],2),c(-10,newy[1]),lty=3,col="blue",lwd=2) lines(rep(newx[2],2),c(-10,newy[2]),lty=3,col="blue",lwd=2) lines(c(-50,newx[1]),rep(newy[1],2),lty=3,col="blue",lwd=2) lines(c(-50,newx[2]),rep(newy[2],2),lty=3,col="blue",lwd=2) # tracé des intervalles de confiance grillex <- data.frame(distance=1:800) icConf <- predict(ml,new=grillex,interval="confidence",level=0.95) icPred <- predict(ml,new=grillex,interval="prediction",level=0.95) matlines(grillex,cbind(icConf,icPred[,-1]),lty=c(1,2,2,3,3),col=c("black","red","red","green","green"),lwd=2) # un légende, c'est utile legend( x="topleft", legend=c("valeurs originales","valeurs prédites","droite MCO","IC conf","IC pred"), col=c("blue","red","black","red","green"), pch=c(19,19,NA,NA,NA), lty=c(0,0,1,3,3), lwd=c(0,0,2,2,2) ) # fin de legend dev.off()valeurs prédites ================ 1 2 newx 100.00000 250.00000 newy 11.68237 24.18035
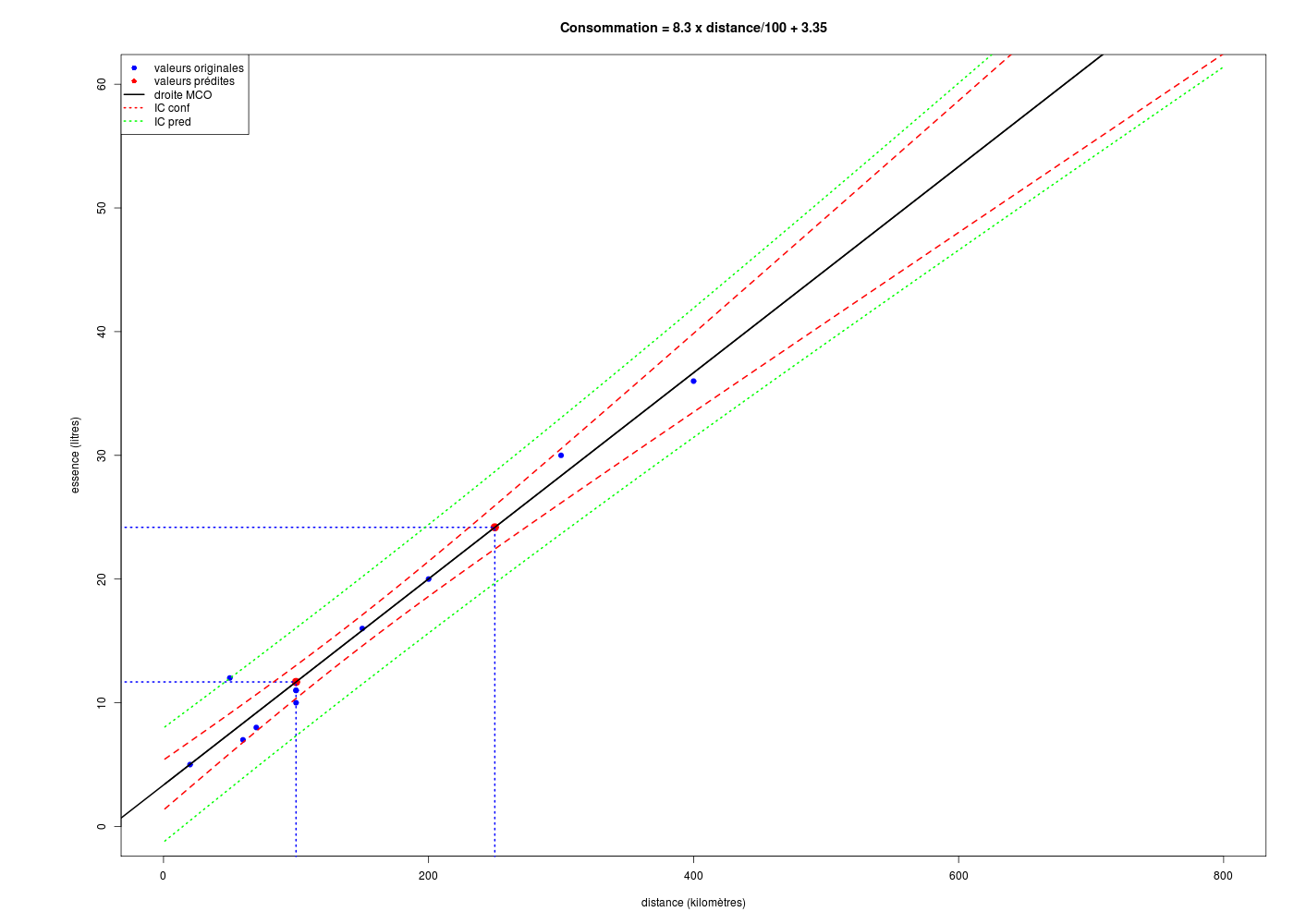
Il y a bien sûr ici une relation de causalité, la cause étant la distance et l'effet étant la consommation, ce que l'on peut résumer par plus on roule, plus on consomme.
Un outlier est situé "loin de la moyenne". Sous hypothèse de normalité, un outlier est à plus de deux (trois ?) écarts-type de la moyenne, ce qui est simple à tester :
# lecture des données km <- lit.dar("km.dar") # points à plus de 2 écarts-type de la moyenne # sous réserve que la normalité soit avérée cats("points \"outlier\" pour essence :") # solution 1 moy <- mean(km$essence) ect <- sd(km$essence) out <- which(abs(km$essence-moy)>2*ect) cat(" indice(s) outlier : ") print(out) cat(" soit les valeurs ") ; print(km$essence[out]) # solution 2 (unité=écart-type) ess_cr <- scale(km$essence) outbis <- which(abs(ess_cr)>=2) # identical(out,outbis) renvoie TRUE cats("points \"outlier\" pour distance :") dist_cr <- scale(km$distance) out <- which(abs(dist_cr)>=2) cat(" indice(s) outlier : ") print(out) cat(" soit les valeurs ") ; print(km$distance[out])points "outlier" pour essence : =============================== indice(s) outlier : [1] 4 soit les valeurs [1] 36 points "outlier" pour distance : ================================ indice(s) outlier : [1] 4 soit les valeurs [1] 400Il est plus sage de commencer par analyser d'abord les variables et de tester cette hypothèse de normalité :
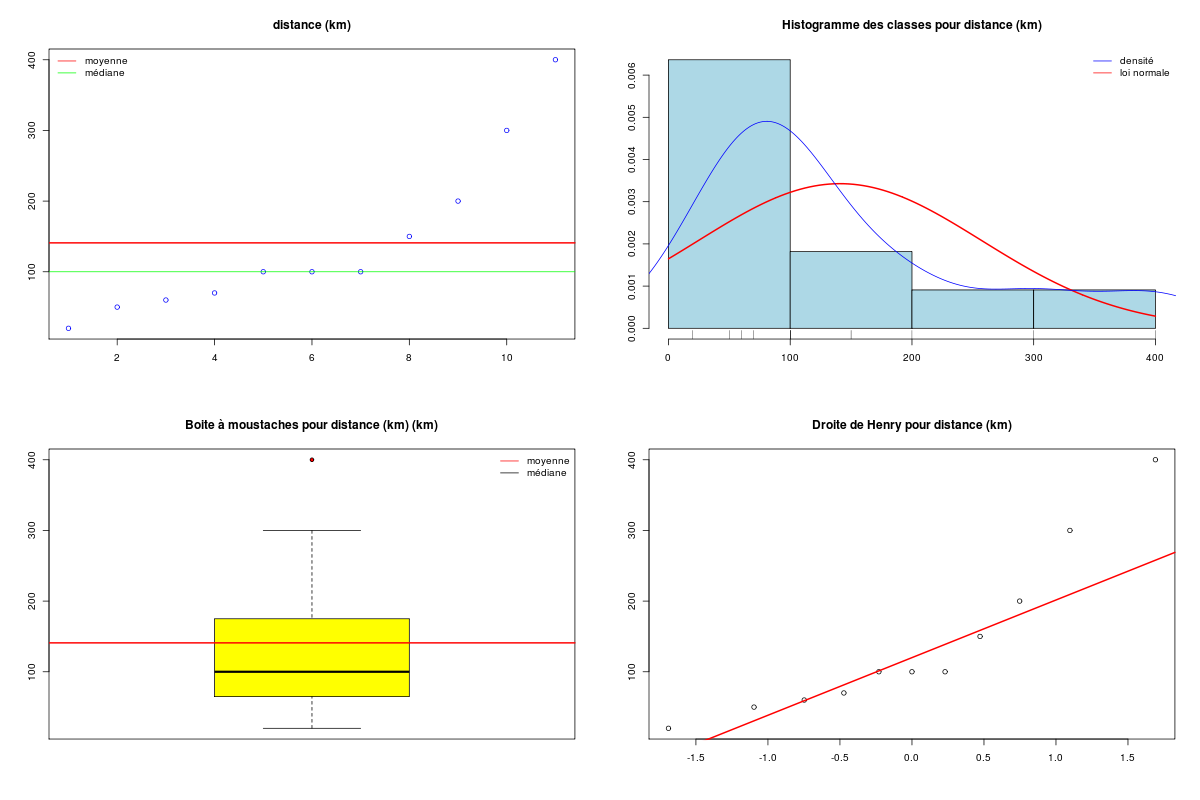
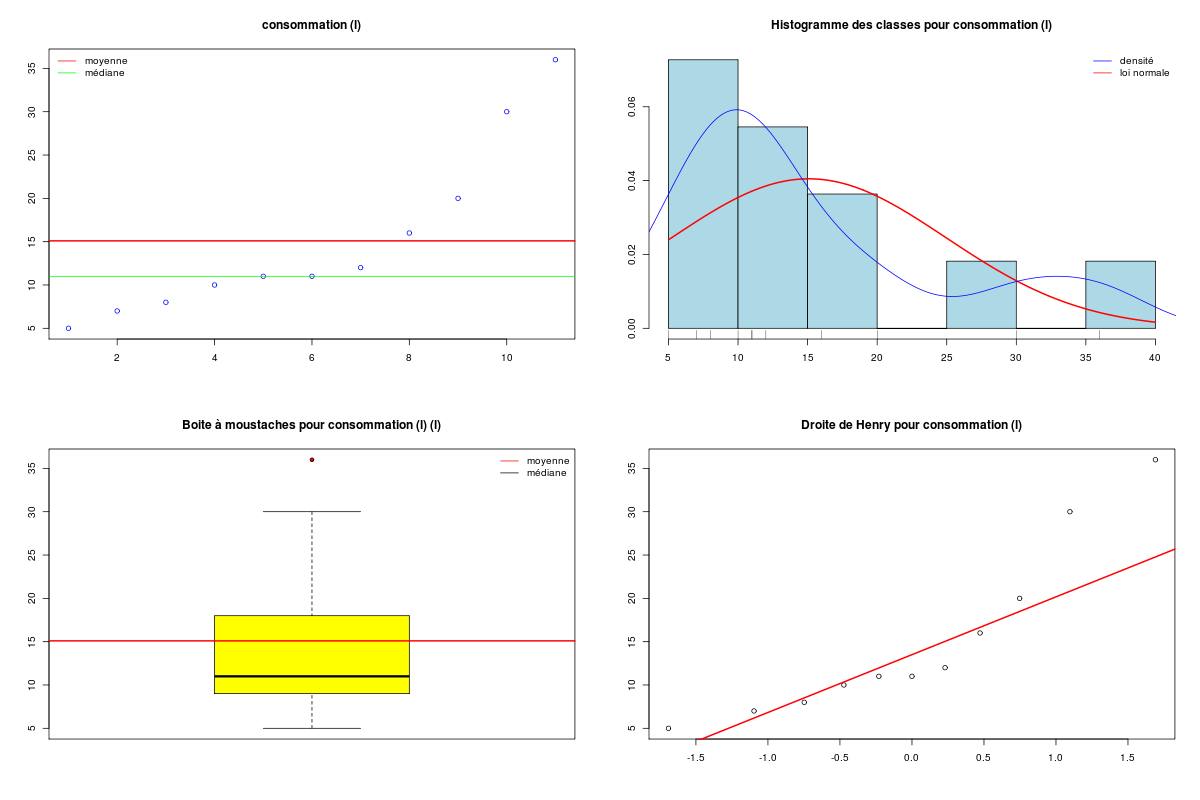
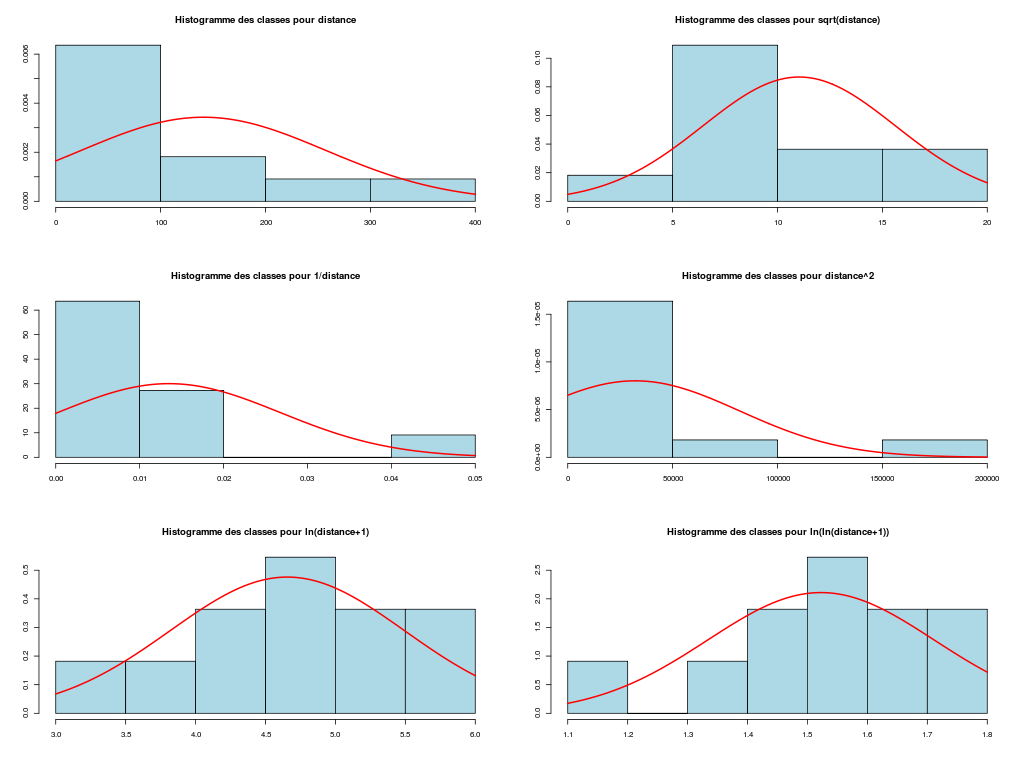
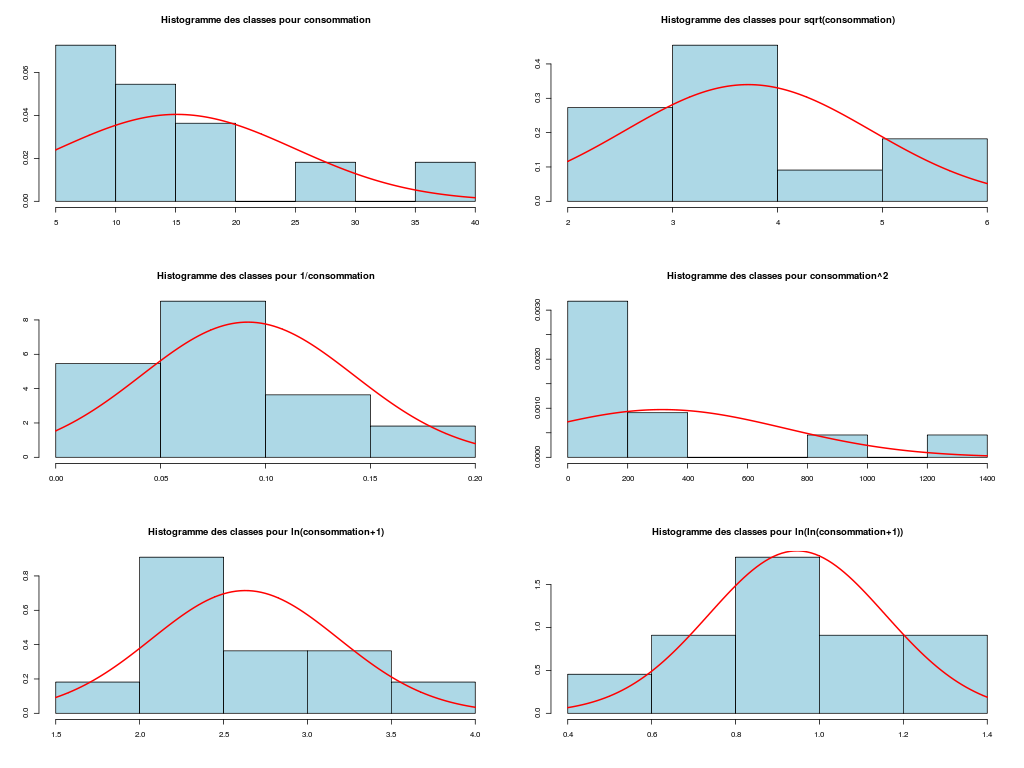
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # description des variables decritQT(titreQT="distance", nomVar=km$distance, unite="km", graphique=TRUE, fichier_image="km_dist.png" ) # fin de decritQT decritQT(titreQT="consommation", nomVar=km$essence, unite="l", graphique=TRUE, fichier_image="km_consom.png" ) # fin de decritQT # test de normalité tdn(titreQT="distance", nomVar=km$distance, unite="km", graphique=TRUE, fichier_image="km_dist_N.png" ) # fin de decritQT tdn(titreQT="consommation", nomVar=km$essence, unite="l", graphique=TRUE, fichier_image="km_consom_N.png" ) # fin de decritQTDESCRIPTION STATISTIQUE DE LA VARIABLE distance Taille 11 individus Moyenne 140.9091 km Ecart-type 110.9836 km Coef. de variation 79 % 1er Quartile 65.0000 km Mediane 100.0000 km 3eme Quartile 175.0000 km iqr absolu 110.0000 km iqr relatif 110.0000 % Minimum 20 km Maximum 400 km Tracé tige et feuilles The decimal point is 2 digit(s) to the right of the | 0 | 2567 1 | 0005 2 | 0 3 | 0 4 | 0 vous pouvez utiliser km_dist.png DESCRIPTION STATISTIQUE DE LA VARIABLE consommation Taille 11 individus Moyenne 15.0909 l Ecart-type 9.3949 l Coef. de variation 62 % 1er Quartile 9.0000 l Mediane 11.0000 l 3eme Quartile 18.0000 l iqr absolu 9.0000 l iqr relatif 82.0000 % Minimum 5 l Maximum 36 l Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 0 | 578 1 | 01126 2 | 0 3 | 06 vous pouvez utiliser km_consom.png TESTS DE NORMALITE POUR LA VARIABLE y = distance pour 11 valeurs (0 valeurs NA) Variable Test p-value ln(ln(y+1)) Kolmogorov-Smirnov 0.9639553129 ln(y+1) Kolmogorov-Smirnov 0.9520817984 ln(y+1) Shapiro 0.9390586420 ln(ln(y+1)) Shapiro 0.6819119784 sqrt(y) Kolmogorov-Smirnov 0.6314665564 1/y Kolmogorov-Smirnov 0.5499771135 sqrt(y) Shapiro 0.5428647932 y Kolmogorov-Smirnov 0.3819356043 y^2 Kolmogorov-Smirnov 0.2462832286 y Shapiro 0.0391463323 1/y Shapiro 0.0010844889 y^2 Shapiro 0.0002135310 RStudioGD 2 TESTS DE NORMALITE POUR LA VARIABLE y = consommation pour 11 valeurs (0 valeurs NA) Variable Test p-value ln(ln(y+1)) Kolmogorov-Smirnov 0.9747442735 ln(ln(y+1)) Shapiro 0.9397029971 1/y Kolmogorov-Smirnov 0.9387176589 ln(y+1) Kolmogorov-Smirnov 0.8578754101 ln(y+1) Shapiro 0.7436280317 sqrt(y) Kolmogorov-Smirnov 0.6468448563 1/y Shapiro 0.5558556921 y Kolmogorov-Smirnov 0.4493424682 y^2 Kolmogorov-Smirnov 0.2797524762 sqrt(y) Shapiro 0.2680327032 y Shapiro 0.0356862694 y^2 Shapiro 0.0006385556 RStudioGD 2
Ensuite, il ne faut pas confondre outlier et point-influent, point-levier car un point extrême en X n'est pas un problème s'il est sur la droite de régression linéaire (en d'autres termes, il ne faut pas confondre outlier pour les données et outliers pour le modèle). Il y a des indicateurs statistiques éprouvés pour détecter les "vrais" outliers :
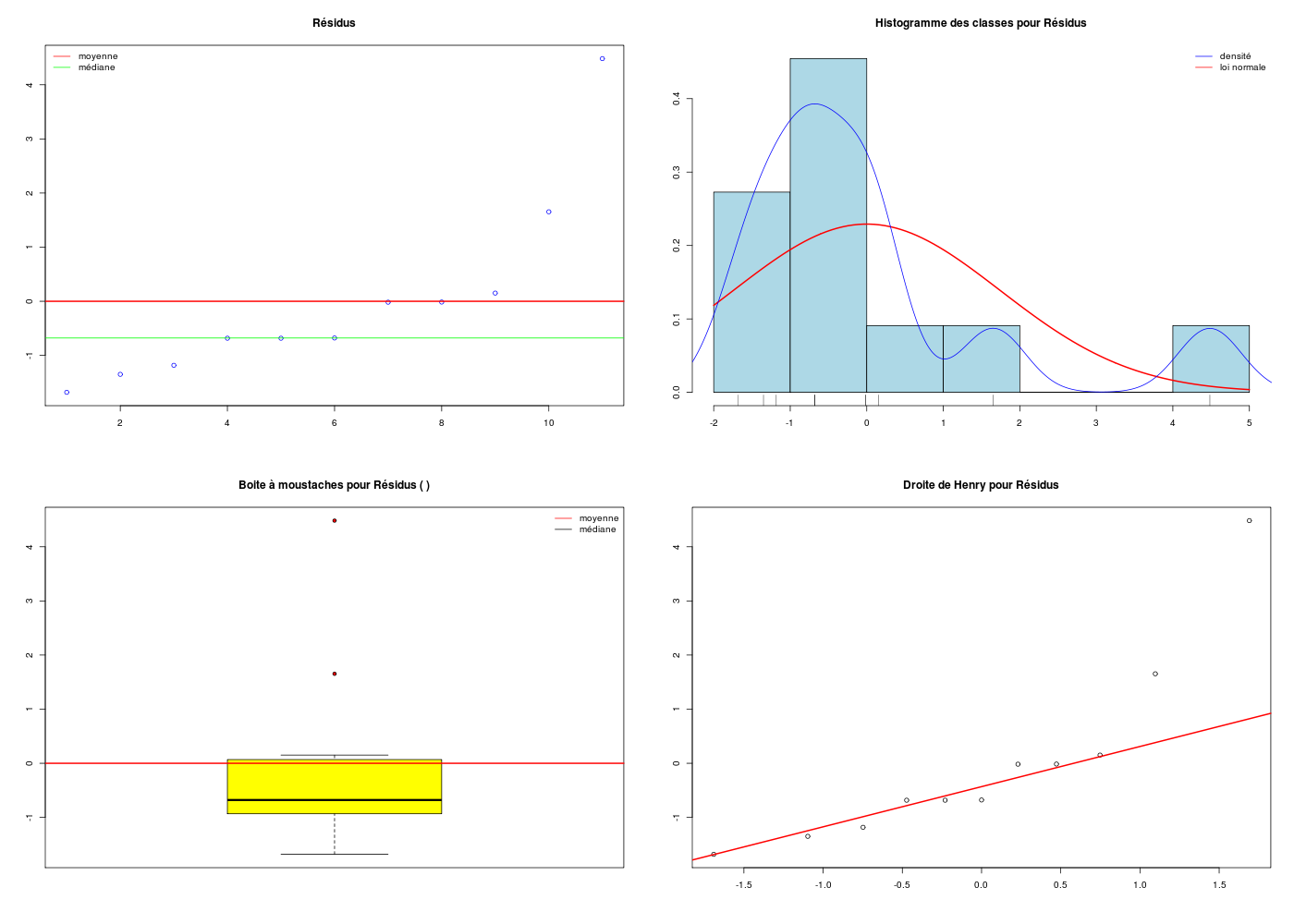
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # utilisation de notre fonction analyseRegression( titre="km", xi=km$distance, yi=km$essence, graphiques=TRUE, basegr="kmdetail_", interactif=FALSE ) # fin de analyseRegressionAnalyse de la régression "km" sur 11 valeurs ============================================ Affichage de summary(lm(yi~xi) : -------------------------------- Call: lm(formula = yi ~ xi) Residuals: Min 1Q Median 3Q Max -1.6824 -0.9326 -0.6783 0.0686 4.4836 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.350376 0.894150 3.747 0.00458 ** xi 0.083320 0.004985 16.714 4.39e-08 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.835 on 9 degrees of freedom Multiple R-squared: 0.9688, Adjusted R-squared: 0.9653 F-statistic: 279.4 on 1 and 9 DF, p-value: 4.393e-08 Résultats de la régression : ---------------------------- valeur de R : rho = 0.984 donc R2= 0.969 ; p-value : 0.000 *** coefficients de la régression et intervalles de confiance à 95 % Estimate Std. Error t value Pr(>|t|) 2.5 % 97.5 % (Intercept) 3.350 0.894 3.747 0.005 1.328 5.373 xi 0.083 0.005 16.714 0.000 0.072 0.095 Résidus et points remarquables ------------------------------ Début de ces résultats obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 1 100 11 11.682367 -0.68236715 -0.392702305 0.10326087 -0.373456701 -0.126728731 8.879051e-03 2 200 20 20.014359 -0.01435856 -0.008325883 0.11668009 -0.007849748 -0.002852956 4.578354e-06 3 300 30 28.346350 1.65365003 1.060391910 0.27771068 1.068735976 0.662691080 2.161644e-01 4 400 36 36.678341 -0.67834138 -0.574793163 0.58635266 -0.552149567 -0.657386930 2.341649e-01 5 150 16 15.848363 0.15163714 0.086701395 0.09151906 0.081777018 0.025955483 3.786325e-04 6 50 12 7.516371 4.48362856 2.653297269 0.15190553 5.360451373 2.268642350 6.304798e-01 2 levier(s) important(s) >= seuil 3/n = 0.2727273 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 3 300 30 28.346 1.654 1.060 0.278 1.069 0.663 0.216 4 400 36 36.678 -0.678 -0.575 0.586 -0.552 -0.657 0.234 autres seuils possibles : 2/n = 0.182 Hoaglin et Welsch (1978 ) ; 0.5 Huber (1987) 1 résidu(s) studentisé(s) fort(s) >= seuil = 2 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 6.000 50.000 12.000 7.516 4.484 2.653 0.152 5.360 2.269 0.630 1 observation(s) mal reconstituée(s), rstudent >= seuil = 2.306004 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 6.000 50.000 12.000 7.516 4.484 2.653 0.152 5.360 2.269 0.630 1 dfits significatif(s) >= seuil 2*racine(2/n) = 0.8528029 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 6.000 50.000 12.000 7.516 4.484 2.653 0.152 5.360 2.269 0.630 1 distance(s) de cook >= seuil = 0.3636364 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 6.000 50.000 12.000 7.516 4.484 2.653 0.152 5.360 2.269 0.630 autres seuils possibles : souhaitable f(1,n-1,0.1) = 0.017 ; précoccupant f(1,n-1,0.5) = 0.49 Cook (1977) 2 point(s) remarquable(s) vus par influence.measures obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 4 400 36 36.678 -0.678 -0.575 0.586 -0.552 -0.657 0.234 6 50 12 7.516 4.484 2.653 0.152 5.360 2.269 0.630 vous pouvez utiliser kmdetail_1.png vous pouvez utiliser kmdetail_2.png DESCRIPTION STATISTIQUE DE LA VARIABLE Résidus Taille 11 individus Moyenne -0.0000 Ecart-type 1.6598 Coef. de variation -1 % 1er Quartile -0.9326 Mediane -0.6783 3eme Quartile 0.0686 iqr absolu 1.0012 iqr relatif -148.0000 % Minimum -2 Maximum 4 Tracé tige et feuilles The decimal point is at the | -0 | 73277700 0 | 27 2 | 4 | 5 Test de normalité de Shapiro-Wilk Shapiro-Wilk normality test data: ei W = 0.7899, p-value = 0.006924 vous pouvez utiliser kmdetail_3.png vous pouvez utiliser kmdetail_4.png vous pouvez utiliser kmdetail_5.png vous pouvez utiliser kmdetail_6.png vous pouvez utiliser kmdetail_7.png vous pouvez utiliser kmdetail_8.png vous pouvez utiliser kmdetail_9.png vous pouvez utiliser kmdetail_10.png Test de l'homoscédasticité des résidus ====================================== studentized Breusch-Pagan test data: lm(yi ~ xi) BP = 0.6647, df = 1, p-value = 0.4149 $modele Call: lm(formula = yi ~ xi) Coefficients: (Intercept) xi 3.35038 0.08332 $coefs Estimate Std. Error t value Pr(>|t|) 2.5 % 97.5 % (Intercept) 3.35037574 0.894150165 3.746994 4.575841e-03 1.32766754 5.3730839 xi 0.08331991 0.004985016 16.714073 4.393217e-08 0.07204303 0.0945968 $indicateurs obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 1 100 11 11.682367 -0.68236715 -0.392702305 0.10326087 -0.373456701 -0.126728731 8.879051e-03 2 200 20 20.014359 -0.01435856 -0.008325883 0.11668009 -0.007849748 -0.002852956 4.578354e-06 3 300 30 28.346350 1.65365003 1.060391910 0.27771068 1.068735976 0.662691080 2.161644e-01 4 400 36 36.678341 -0.67834138 -0.574793163 0.58635266 -0.552149567 -0.657386930 2.341649e-01 5 150 16 15.848363 0.15163714 0.086701395 0.09151906 0.081777018 0.025955483 3.786325e-04 6 50 12 7.516371 4.48362856 2.653297269 0.15190553 5.360451373 2.268642350 6.304798e-01 7 60 7 8.349571 -1.34957059 -0.792736805 0.13922437 -0.774944502 -0.311661567 5.082219e-02 8 70 8 9.182770 -1.18276973 -0.690279807 0.12801932 -0.668745432 -0.256238960 3.497752e-02 9 20 5 5.016774 -0.01677402 -0.010212843 0.19880569 -0.009628816 -0.004796433 1.294059e-05 10 100 10 11.682367 -1.68236715 -0.968202319 0.10326087 -0.964437256 -0.327271967 5.397242e-02 11 100 11 11.682367 -0.68236715 -0.392702305 0.10326087 -0.373456701 -0.126728731 8.879051e-03
Ici, il semblerait que les trajets 3 et 4 soient des leviers car ils ont des valeurs très élevées en X, et que le trajet 6 soit un point influent, mal reconstitué. On remarquera que seul le trajet 6 semble sortir des intervalles de confiance.
Si on enlève le point trajet6 (50,12), on obtient un meilleur modèle (R2 ajusté de 0.9923 vs 0.9653) et des prédictions légèrement différentes :
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") cats(" ancien modèle linéaire ") print( summary(lm(essence ~ distance,data=km)) ) cats(" anciennes prédictions ") newx <- c(100,250) newxdf <- data.frame(distance=newx) newy <- predict(ml,newxdf) print(rbind(newx,newy)) # on supprime le trajet 6 km <- km[ -6,] # nouveau modèle linéaire : cats(" nouveau modèle") ml2 <- lm(essence ~ distance,data=km) print(summary(ml2)) cats(" nouvelles prédictions ") newx <- c(100,250) newxdf <- data.frame(distance=newx) newy <- predict(ml2,newxdf) print(rbind(newx,newy))ancien modèle linéaire ======================== Call: lm(formula = essence ~ distance, data = km) Residuals: Min 1Q Median 3Q Max -1.6824 -0.9326 -0.6783 0.0686 4.4836 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.350376 0.894150 3.747 0.00458 ** distance 0.083320 0.004985 16.714 4.39e-08 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.835 on 9 degrees of freedom Multiple R-squared: 0.9688, Adjusted R-squared: 0.9653 F-statistic: 279.4 on 1 and 9 DF, p-value: 4.393e-08 anciennes prédictions ======================= 1 2 newx 100.00000 250.00000 newy 11.68237 24.18035 nouveau modèle =============== Call: lm(formula = essence ~ distance, data = km) Residuals: Min 1Q Median 3Q Max -1.11677 -0.54913 -0.05665 0.51416 1.56994 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 2.369937 0.478887 4.949 0.00112 ** distance 0.086867 0.002555 34.003 6.11e-10 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.9083 on 8 degrees of freedom Multiple R-squared: 0.9931, Adjusted R-squared: 0.9923 F-statistic: 1156 on 1 and 8 DF, p-value: 6.113e-10 nouvelles prédictions ======================= 1 2 newx 100.00000 250.00000 newy 11.05665 24.08671On notera que parmi les graphiques de diagnostic, ne figure pas le tracé des valeurs prédites en fonction des valeurs originales, qui devraient se situer sur la première diagonale. Ce graphique, qui peut aider à repérer les forts résidus, n'est utilisable que quand il y a peu de points :
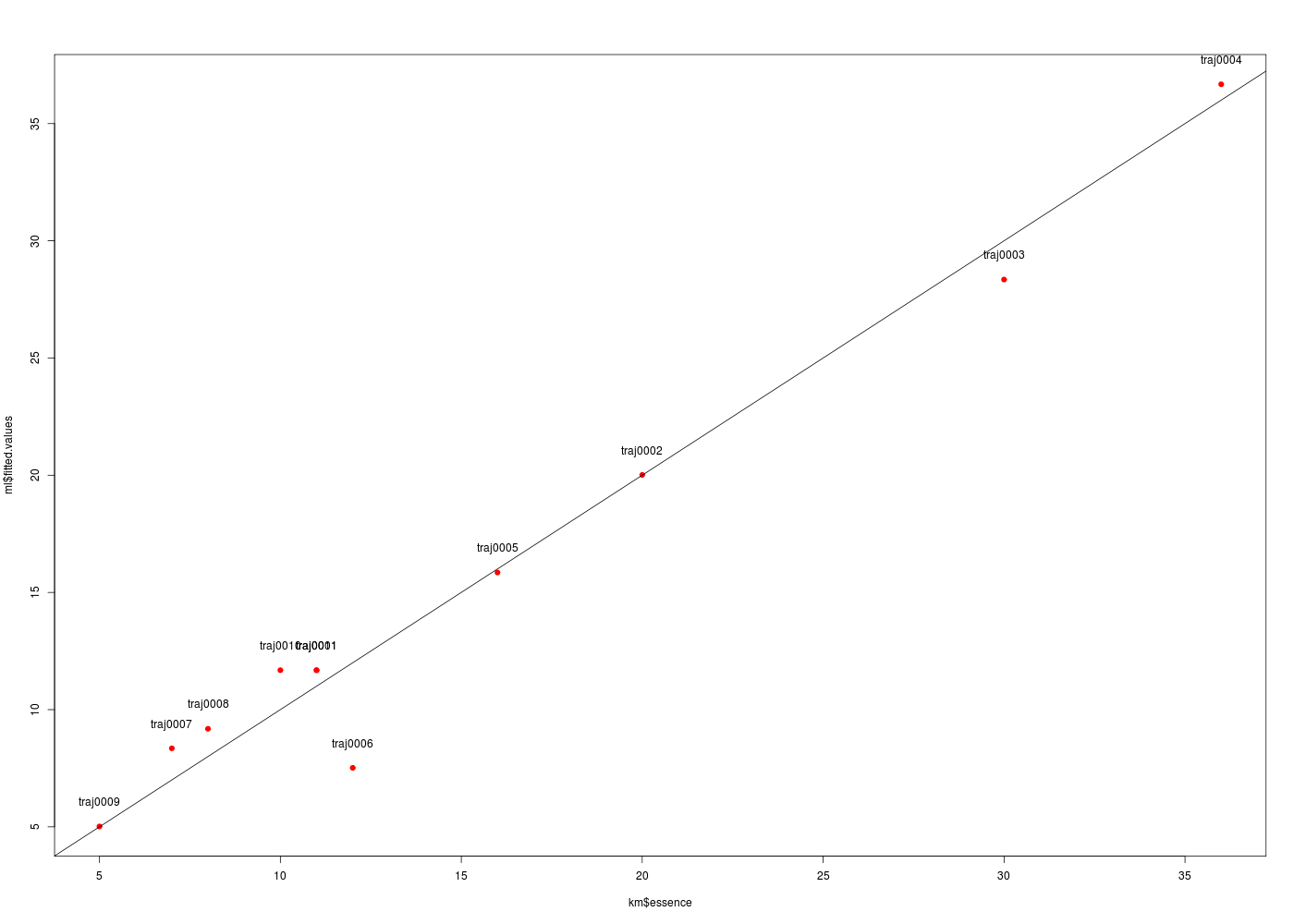
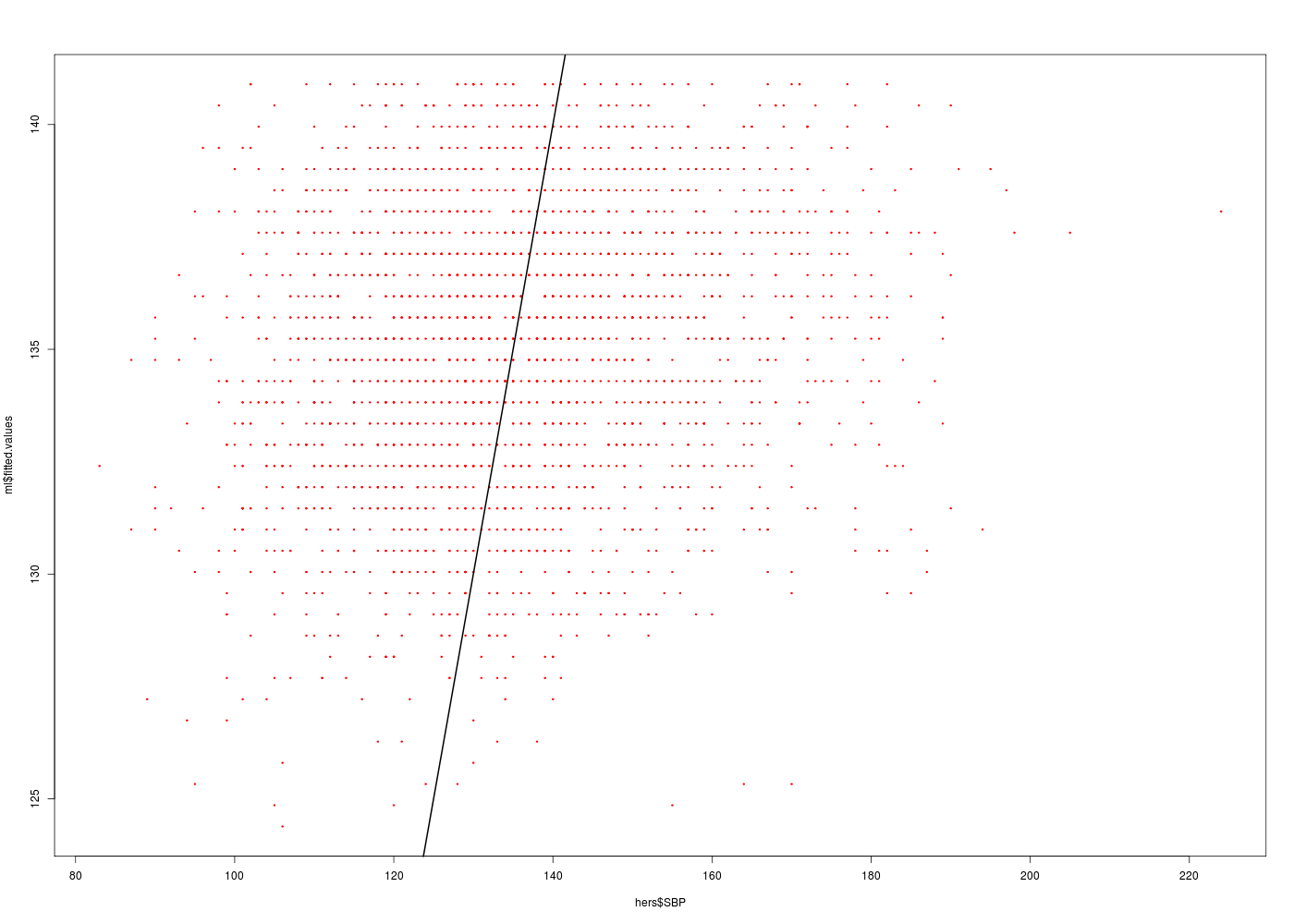
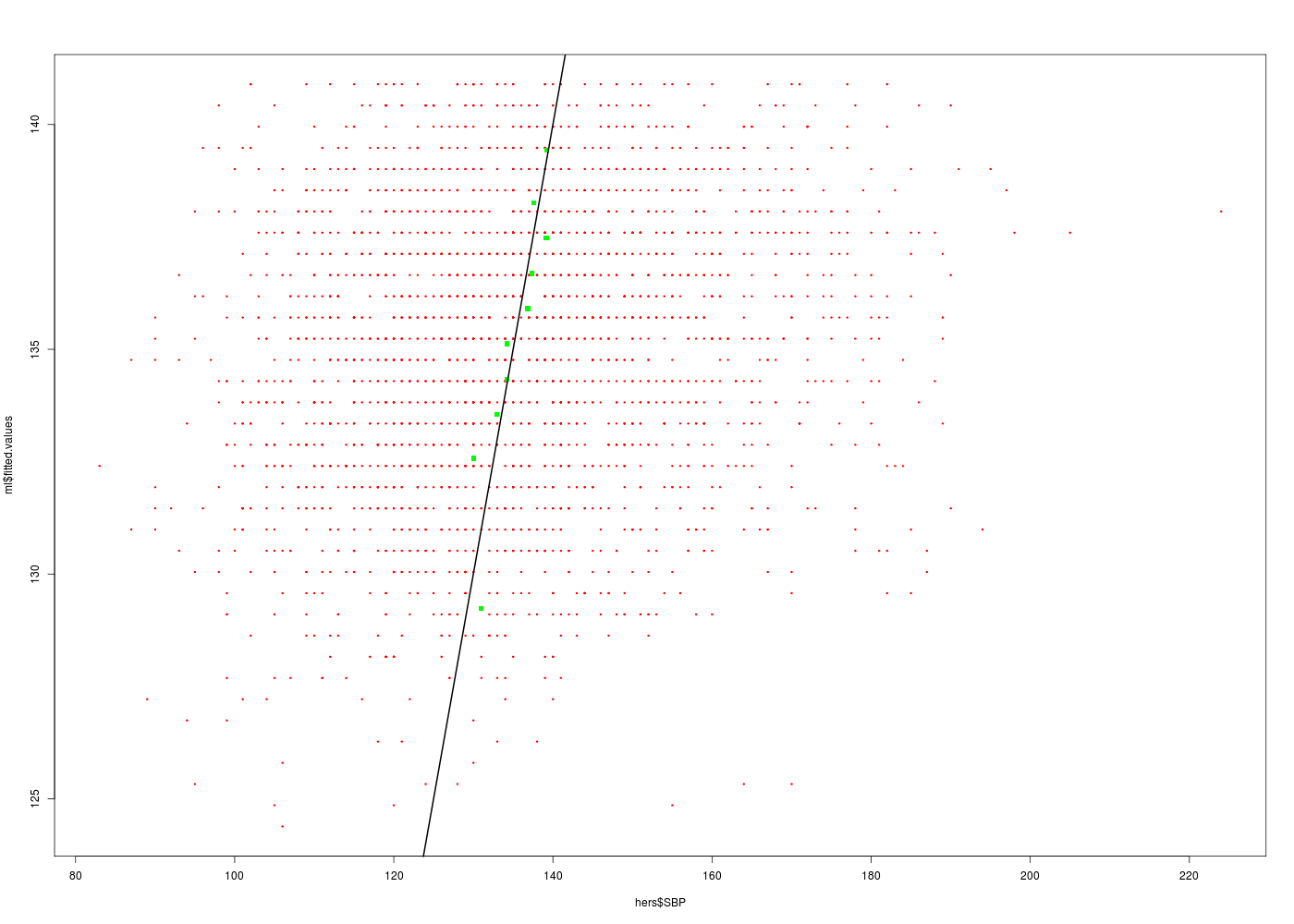
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # régression linéaire ml <- lm(essence ~ distance,data=km) # tracé des valeurs prédites en fonction des valeurs originales gr("kmpred2.png") plot(ml$fitted.values~km$essence,col="red",pch=19) text(x=km$essence,y=ml$fitted.values+1,labels=row.names(km)) abline(a=0,b=1,col="black") # attention : a + b * x dev.off()
Pour lire le fichier Excel indiqué, on peut par exemple utiliser la fonction read.xls(). Sauf que cette fonction n'est pas une fonction élémentaire de R. Elle se trouve dans le package gdata. Il faut donc commencer par charger ce package. On devrait donc se contenter du code :
# chargement de packages library(gdata) # pour la fonction read.xls # lecture des données hers <- read.xls("http://forge.info.univ-angers.fr/~gh/wstat/Eda/hersdata.xls")Malheureusement, dans les salles de l'université d'Angers à la faculté des sciences, ce package n'est pas installé. Il faut donc l'installer par la commande
install.packages("gdata") # la commande suivante doit alors fonctionner library("gdata")Comme le disque C: est protégé en écriture, il faut créer un répertoire sur le disque D:, par exemple D:/eda avant de pouvoir l'installer :
install.packages("gdata",lib="d:/eda") library("gdata",lib="d:/eda")Voici finalement le code source correspondant pour la lecture des données, la description des variables et la régression linéaire :
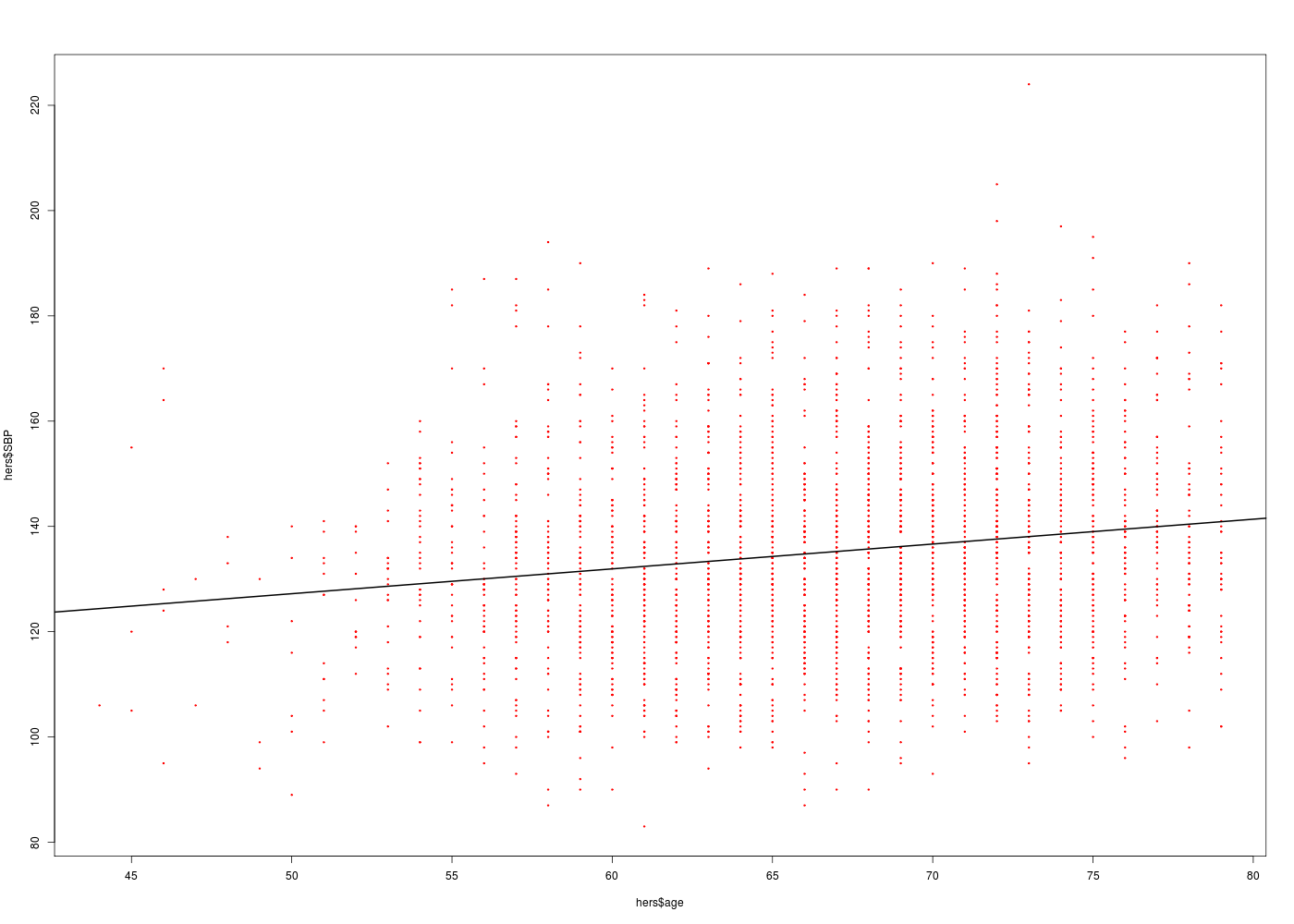
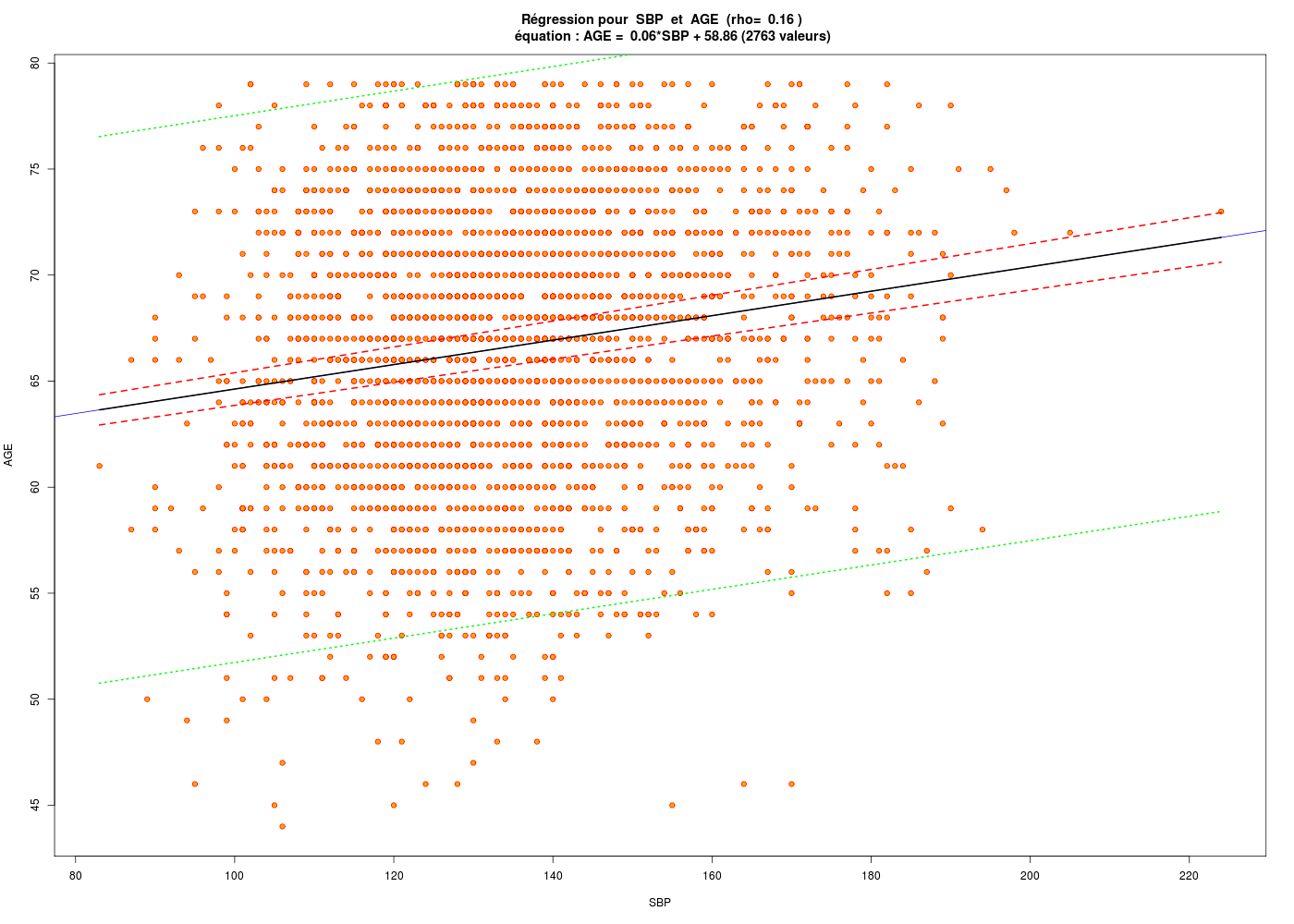
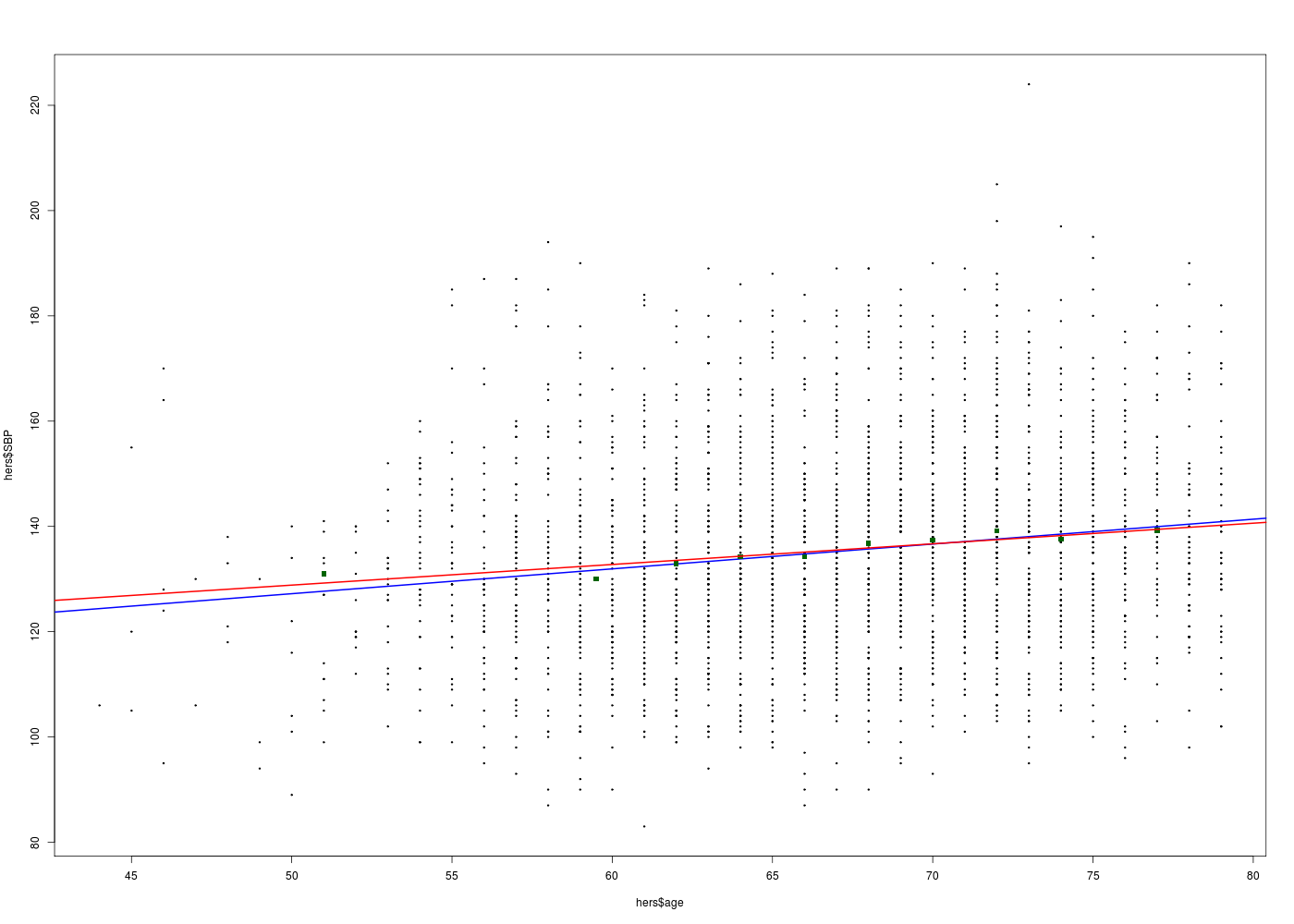
# chargement de packages library(gdata) # pour la fonction read.xls library(Hmisc) # pour la fonction describe # lecture des données hers <- read.xls("http://forge.info.univ-angers.fr/~gh/wstat/Eda/hersdata.xls") print(lesColonnes(hers)) # on sauvegarde au format R (lecture plus rapide) save(hers,file="hers.Rdata") # on se restreint à nos variables sbpAge <- hers[,c("SBP","age")] print(lesColonnes(sbpAge)) # description de age et SBP describe(hers$age) decritQT("AGE",hers$age,"ans",TRUE,"hers_AGE.png") tdn("AGE",hers$age,"ans",TRUE,"hers_AGE_N.png") describe(hers$SBP) decritQT("SBP",hers$SBP,"mmHg",TRUE,"hers_SBP.png") tdn("SBP",hers$SBP,"mmHg",TRUE,"hers_SBP_N.png") # régression linéaire cats("Modèle linéaire SBP en fonction de l'AGE") ml <- lm(SBP ~ age,data=sbpAge) print( summary(ml) ) # tracé de SBP en fonction de age gr("SBPagepred1.png") plot(hers$SBP~hers$age,col="red",pch=19,cex=0.3) abline(ml,col="black",lwd=2) dev.off() # tracé des valeurs prédites en fonction des valeurs originales gr("SBPagepred2.png") plot(ml$fitted.values~hers$SBP,col="red",pch=19,cex=0.3) abline(a=0,b=1,col="black",lwd=2) # attention : a + b * x dev.off()Voici l'analyse des 37 colonnes (stat. sur 2763 lignes en tout) Num NbVal Min Max Distinct Manquantes age 2 2763 44.000 79.000 36 0 age10 37 2763 4.400 7.900 36 0 BMI 18 2758 15.210 54.130 1465 5 BMI1 23 2610 14.730 54.040 1448 153 DBP 36 2762 45.000 102.000 58 1 diabetes 14 2763 1.000 2.000 2 0 dmpills 15 2763 1.000 2.000 2 0 drinkany 6 2763 1.000 3.000 3 0 exercise 7 2763 1.000 2.000 2 0 globrat 9 2763 1.000 6.000 6 0 glucose 21 2763 29.000 298.000 202 0 glucose1 26 2613 42.000 440.000 230 150 HDL 29 2752 14.000 130.000 85 11 HDL1 33 2608 14.000 124.000 89 155 HT 1 2763 1.000 2.000 2 0 htnmeds 12 2763 1.000 2.000 2 0 insulin 16 2763 1.000 2.000 2 0 LDL 28 2752 36.800 393.400 758 11 LDL1 32 2608 -20.000 450.200 752 155 medcond 11 2763 0.000 1.000 2 0 nonwhite 4 2763 1.000 2.000 2 0 physact 8 2763 1.000 5.000 5 0 poorfair 10 2763 1.000 3.000 3 0 raceth 3 2763 1.000 3.000 3 0 SBP 35 2763 83.000 224.000 110 0 smoking 5 2763 1.000 2.000 2 0 statins 13 2763 1.000 2.000 2 0 tchol 27 2759 110.000 465.000 225 4 tchol1 31 2613 92.000 535.000 229 150 TG 30 2759 31.000 476.000 287 4 TG1 34 2613 31.000 1016.000 367 150 waist 19 2761 56.900 170.000 496 2 waist1 24 2612 59.000 142.000 490 151 weight 17 2761 37.500 132.000 549 2 weight1 22 2613 37.700 142.000 540 150 WHR 20 2760 0.624 1.218 385 3 WHR1 25 2612 0.606 1.150 366 151 NULL Voici l'analyse des 2 colonnes (stat. sur 2763 lignes en tout) Num NbVal Min Max Distinct Manquantes age 2 2763 44 79 36 0 SBP 1 2763 83 224 110 0 NULL hers$age n missing unique Mean .05 .10 .25 .50 .75 .90 .95 2763 0 36 66.65 55 58 62 67 72 75 77 lowest : 44 45 46 47 48, highest: 75 76 77 78 79 DESCRIPTION STATISTIQUE DE LA VARIABLE AGE Taille 2763 individus Moyenne 66.6486 ans Ecart-type 6.6531 ans Coef. de variation 10 % 1er Quartile 62.0000 ans Mediane 67.0000 ans 3eme Quartile 72.0000 ans iqr absolu 10.0000 ans iqr relatif 15.0000 % Minimum 44 ans Maximum 79 ans Tracé tige et feuilles The decimal point is at the | 44 | 0000 46 | 0000000 48 | 0000000 50 | 00000000000000000000 52 | 000000000000000000000000000000000000 54 | 00000000000000000000000000000000000000000000000000000000000000000000000000000 56 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 58 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+38 60 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+81 62 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+101 64 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+134 66 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+146 68 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+193 70 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+160 72 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+159 74 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+72 76 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000+5 78 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 vous pouvez utiliser hers_AGE.png TESTS DE NORMALITE POUR LA VARIABLE y = AGE pour 2763 valeurs (0 valeurs NA) Variable Test p-value y^2 Kolmogorov-Smirnov 0.0000002117 y Kolmogorov-Smirnov 0.0000000001 ln(ln(y+1)) Shapiro 0.0000000000 ln(ln(y+1)) Kolmogorov-Smirnov 0.0000000000 ln(y+1) Shapiro 0.0000000000 ln(y+1) Kolmogorov-Smirnov 0.0000000000 y^2 Shapiro 0.0000000000 1/y Shapiro 0.0000000000 1/y Kolmogorov-Smirnov 0.0000000000 sqrt(y) Shapiro 0.0000000000 sqrt(y) Kolmogorov-Smirnov 0.0000000000 y Shapiro 0.0000000000 RStudioGD 2 hers$SBP n missing unique Mean .05 .10 .25 .50 .75 .90 .95 2763 0 110 135.1 106 111 122 134 147 160 170 lowest : 83 87 89 90 92, highest: 195 197 198 205 224 DESCRIPTION STATISTIQUE DE LA VARIABLE SBP Taille 2763 individus Moyenne 135.0695 ? Ecart-type 19.0278 ? Coef. de variation 14 % 1er Quartile 122.0000 ? Mediane 134.0000 ? 3eme Quartile 147.0000 ? iqr absolu 25.0000 ? iqr relatif 19.0000 % Minimum 83 ? Maximum 224 ? Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 8 | 3779 9 | 0000002333445555566678888888899999999999 10 | 0000000111111111111111111122222222222233333333333334444444444444444444455555555555555555555666666666666666666677777777+44 11 | 0000000000000000000000000000000000000111111111111111111111111111112222222222222222222222222222222222223333333333333333+220 12 | 0000000000000000000000000000000000000000000000000000000000000000000001111111111111111111111111111111111111111111111111+423 13 | 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000011111111111111111111111111+461 14 | 0000000000000000000000000000000000000000000000000000000000000000000000000001111111111111111111111111111111111111111111+325 15 | 0000000000000000000000000000000000000000000000000001111111111111111111111111111111111111122222222222222222222222222222+172 16 | 0000000000000000000000000001111111111111111111222222222223333334444444444444444555555555555555555555566666666666666777+21 17 | 0000000000000000001111111111222222222222222233334444455555555555666677777777788888888999 18 | 000000001111112222222223344555555666778899999 19 | 00014578 20 | 5 21 | 22 | 4 vous pouvez utiliser hers_SBP.png TESTS DE NORMALITE POUR LA VARIABLE y = SBP pour 2763 valeurs (0 valeurs NA) Variable Test p-value ln(y+1) Kolmogorov-Smirnov 0.1288886586 ln(y+1) Shapiro 0.0801980376 ln(ln(y+1)) Kolmogorov-Smirnov 0.0701632315 ln(ln(y+1)) Shapiro 0.0195306059 sqrt(y) Kolmogorov-Smirnov 0.0035898522 1/y Kolmogorov-Smirnov 0.0000213847 y Kolmogorov-Smirnov 0.0000130594 sqrt(y) Shapiro 0.0000058832 y^2 Shapiro 0.0000000000 y^2 Kolmogorov-Smirnov 0.0000000000 1/y Shapiro 0.0000000000 y Shapiro 0.0000000000 RStudioGD 2 Modèle linéaire SBP en fonction de l'AGE ======================================== Call: lm(formula = SBP ~ age, data = sbpAge) Residuals: Min 1Q Median 3Q Max -49.405 -13.150 -1.405 11.378 85.934 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 103.62949 3.59573 28.820 <2e-16 *** age 0.47173 0.05368 8.787 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 18.77 on 2761 degrees of freedom Multiple R-squared: 0.02721, Adjusted R-squared: 0.02685 F-statistic: 77.21 on 1 and 2761 DF, p-value: < 2.2e-16
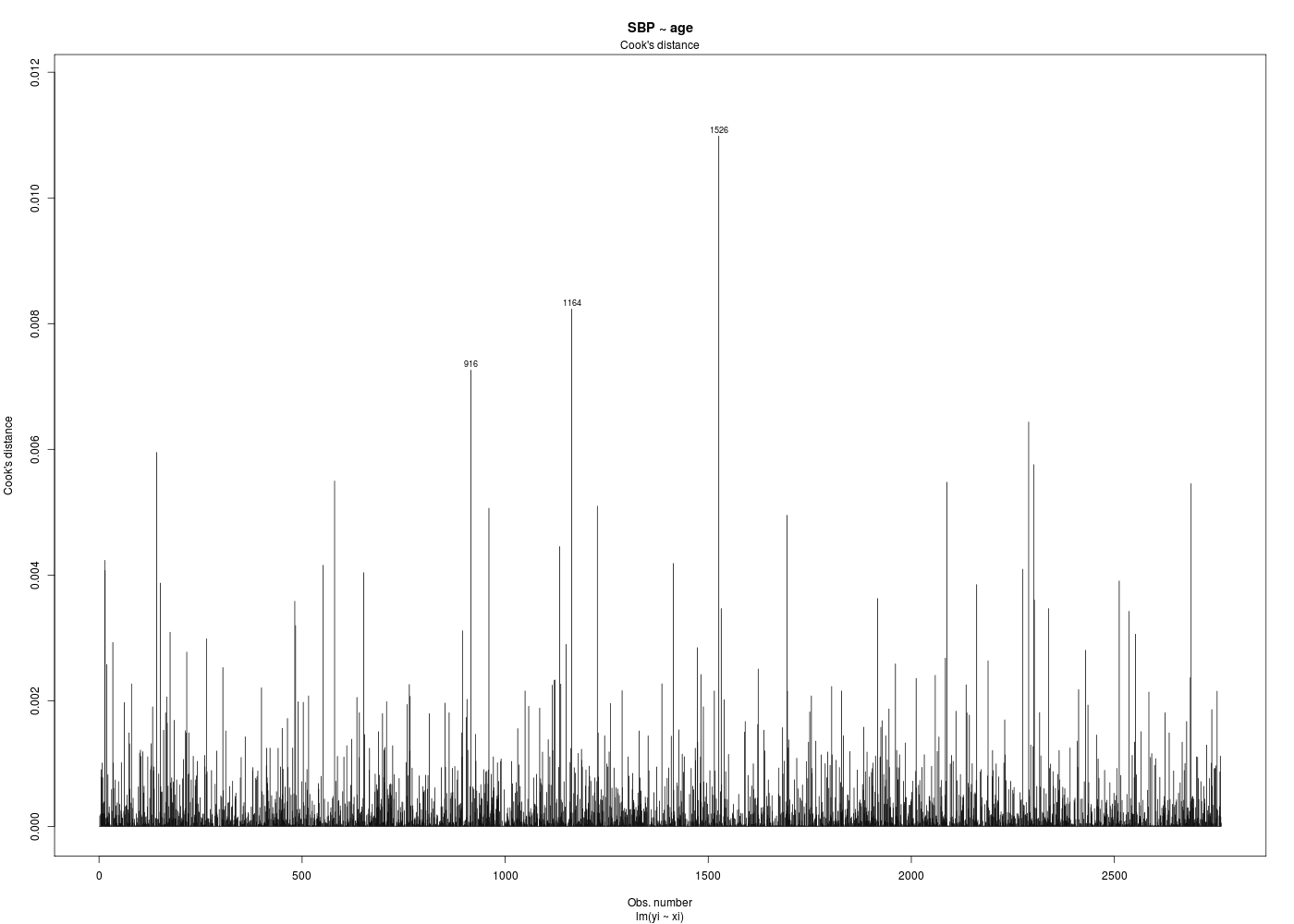
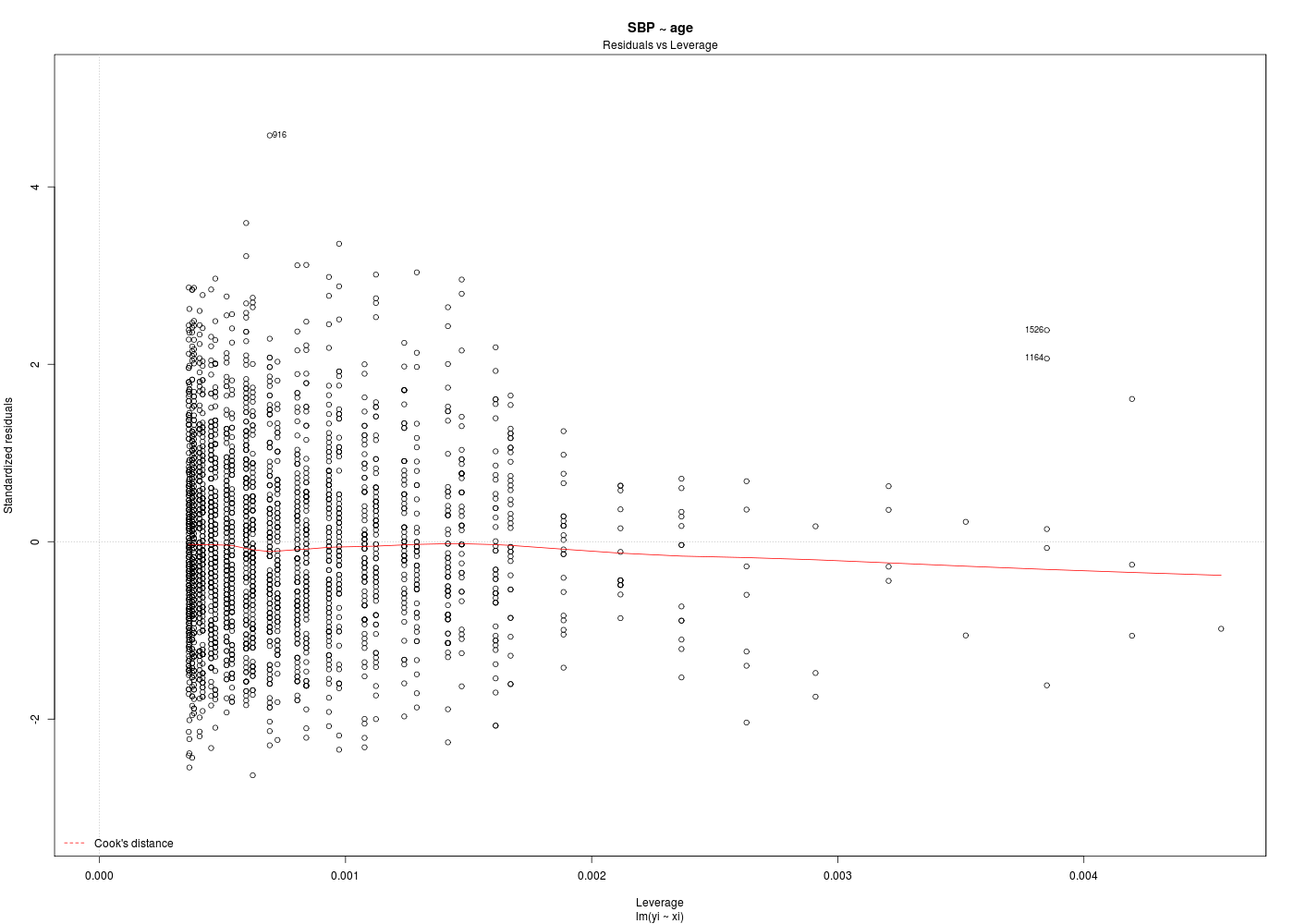
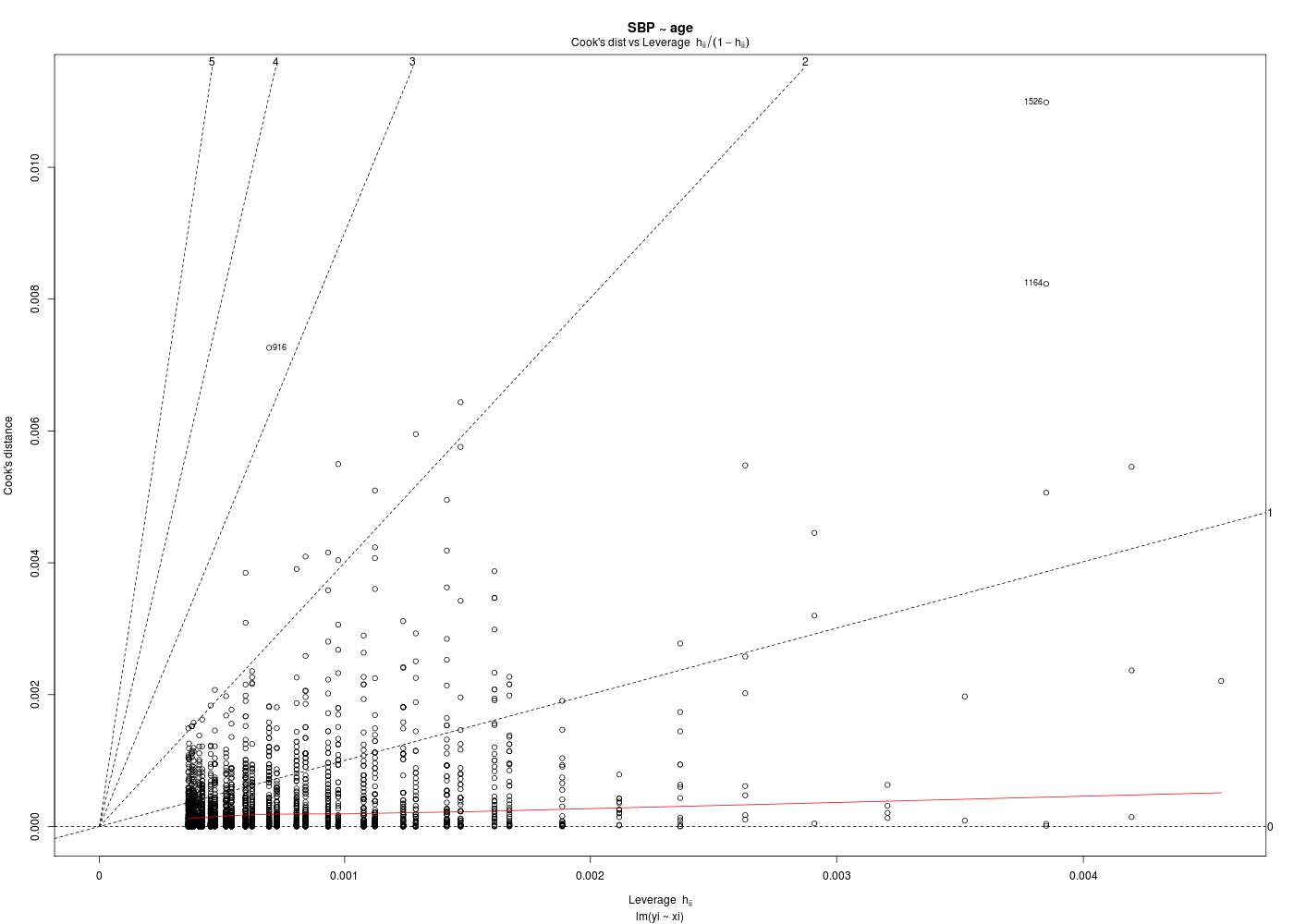
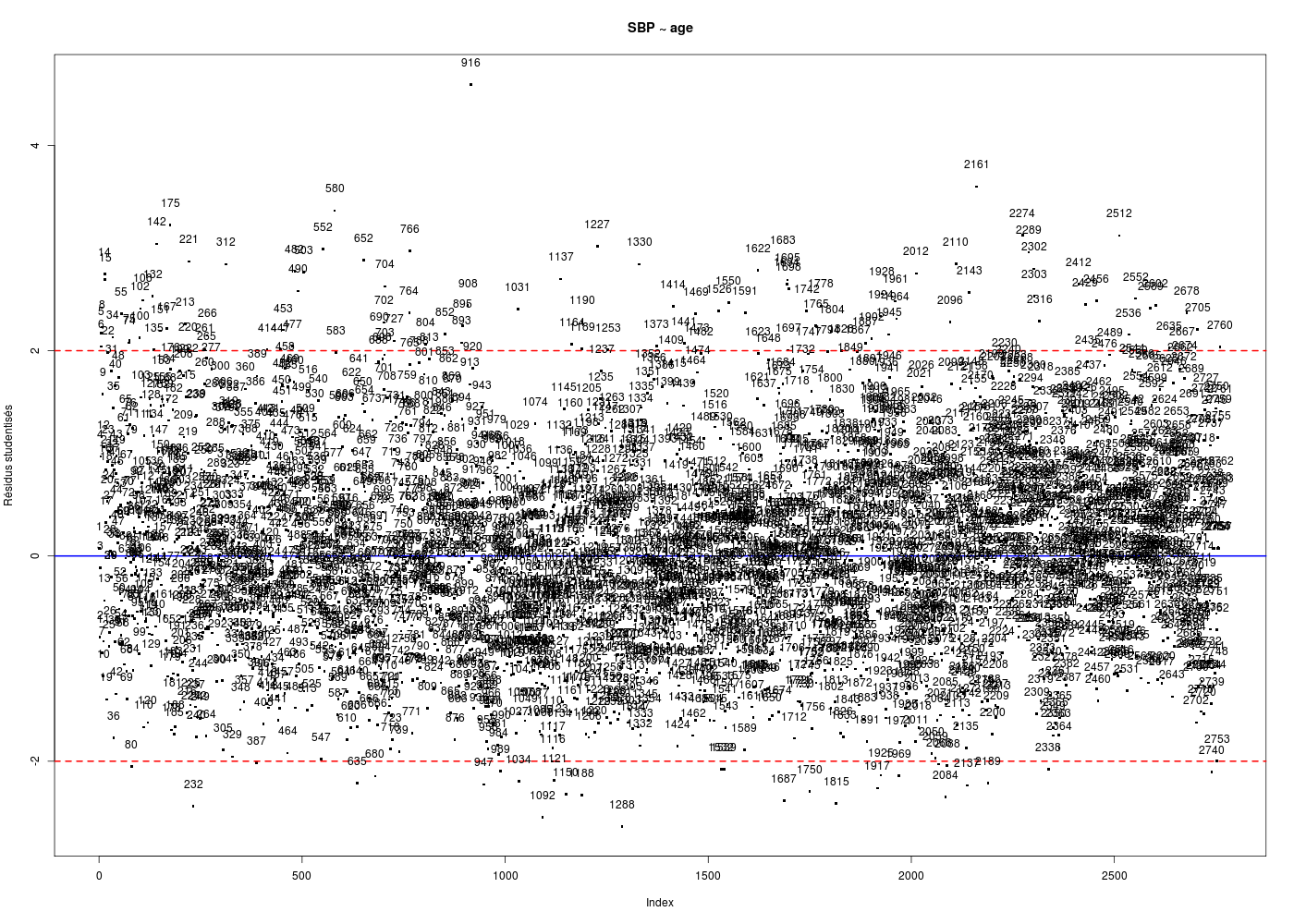
# tracés diagnostics par(ask=FALSE) for (idg in (1:6)) { fgr <- paste("SBP_AGE_",idg,".png",sep="") gr(fgr) plot(ml,which=idg) dev.off() cat("fichier ",fgr," généré.\n") } # fin pour idg mlsbpage <- lm(SBP ~ age,data=hers) print(summary(mlsbpage)) print(anova(mlsbpage)) analyseRegression( titre="SBP ~ age", xi=hers$age, yi=hers$SBP, graphiques=TRUE, basegr="SBP_AGE_detail_", interactif=FALSE ) # fin de analyseRegressionAnalyse de la régression "SBP ~ age" sur 2763 valeurs ===================================================== Affichage de summary(lm(SBP~age) : -------------------------------- Call: lm(formula = yi ~ xi) Residuals: Min 1Q Median 3Q Max -49.405 -13.150 -1.405 11.378 85.934 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 103.62949 3.59573 28.820 <2e-16 *** xi 0.47173 0.05368 8.787 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 18.77 on 2761 degrees of freedom Multiple R-squared: 0.02721, Adjusted R-squared: 0.02685 F-statistic: 77.21 on 1 and 2761 DF, p-value: < 2.2e-16 Affichage de anova(lm(SBP~age) : -------------------------------- Analysis of Variance Table Response: SBP Df Sum Sq Mean Sq F value Pr(>F) age 1 27205 27205.3 77.214 < 2.2e-16 *** Residuals 2761 972797 352.3 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Résultats de la régression : ---------------------------- valeur de R : rho = 0.165 donc R2= 0.027 ; p-value : 0.000 *** coefficients de la régression et intervalles de confiance à 95 % Estimate Std. Error t value Pr(>|t|) 2.5 % 97.5 % (Intercept) 103.629 3.596 28.820 0 96.579 110.680 xi 0.472 0.054 8.787 0 0.366 0.577 Résidus et points remarquables ------------------------------ Début de ces résultats obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 1 70 138 136.6505 1.349547 0.07191319 0.0004537991 0.07190023 0.001532007 1.173945e-06 2 62 118 132.8766 -14.876629 -0.79276328 0.0005386795 -0.79270993 -0.018403335 1.693642e-04 3 69 134 136.1787 -2.178725 -0.11609482 0.0004071521 -0.11607408 -0.002342621 2.744917e-06 4 64 152 133.8201 18.179915 0.96873486 0.0004193045 0.96872406 0.019840652 1.968301e-04 5 65 175 134.2918 40.708187 2.16913808 0.0003841558 2.17059553 0.042551612 9.041045e-04 6 68 174 135.7070 38.293003 2.04043741 0.0003768643 2.04160775 0.039641188 7.848113e-04 436 levier(s) important(s) >= seuil 3/n = 0.001085776 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 13 52 120 128.159 -8.159 -0.435 0.002 -0.435 -0.020 0.000 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 15 57 181 130.518 50.482 2.691 0.001 2.694 0.090 0.004 ... autres seuils possibles : 2/n = 0.001 Hoaglin et Welsch (1978 ) ; 0.5 Huber (1987) 129 résidu(s) studentisé(s) fort(s) >= seuil = 2 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 5 65 175 134.292 40.708 2.169 0.000 2.171 0.043 0.001 6 68 174 135.707 38.293 2.040 0.000 2.042 0.040 0.001 8 69 178 136.179 41.821 2.228 0.000 2.230 0.045 0.001 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 ... 142 observation(s) mal reconstituée(s), rstudent >= seuil = 1.960824 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 5 65 175 134.292 40.708 2.169 0.000 2.171 0.043 0.001 6 68 174 135.707 38.293 2.040 0.000 2.042 0.040 0.001 8 69 178 136.179 41.821 2.228 0.000 2.230 0.045 0.001 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 15 57 181 130.518 50.482 2.691 0.001 2.694 0.090 0.004 22 64 171 133.820 37.180 1.981 0.000 1.982 0.041 0.001 ... 130 dfits significatif(s) >= seuil 2*racine(2/n) = 0.05380895 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 15 57 181 130.518 50.482 2.691 0.001 2.694 0.090 0.004 19 50 101 127.216 -26.216 -1.398 0.003 -1.399 -0.072 0.003 34 56 170 130.046 39.954 2.130 0.001 2.131 0.077 0.003 62 47 106 125.801 -19.801 -1.057 0.004 -1.057 -0.063 0.002 ... 130 distance(s) de cook >= seuil = 0.001447702 obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 15 57 181 130.518 50.482 2.691 0.001 2.694 0.090 0.004 19 50 101 127.216 -26.216 -1.398 0.003 -1.399 -0.072 0.003 34 56 170 130.046 39.954 2.130 0.001 2.131 0.077 0.003 62 47 106 125.801 -19.801 -1.057 0.004 -1.057 -0.063 0.002 74 73 177 138.066 38.934 2.075 0.001 2.076 0.055 0.001 ... autres seuils possibles : souhaitable f(1,n-1,0.1) = 0.016 ; précoccupant f(1,n-1,0.5) = 0.455 Cook (1977) 188 point(s) remarquable(s) vus par influence.measures obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 5 65 175 134.292 40.708 2.169 0.000 2.171 0.043 0.001 8 69 178 136.179 41.821 2.228 0.000 2.230 0.045 0.001 13 52 120 128.159 -8.159 -0.435 0.002 -0.435 -0.020 0.000 14 57 182 130.518 51.482 2.744 0.001 2.747 0.092 0.004 15 57 181 130.518 50.482 2.691 0.001 2.694 0.090 0.004 ... vous pouvez utiliser SBP_AGE_detail_1.png vous pouvez utiliser SBP_AGE_detail_2.png DESCRIPTION STATISTIQUE DE LA VARIABLE Résidus Taille 2763 individus Moyenne -0.0000 Ecart-type 18.7672 Coef. de variation -1 % 1er Quartile -13.1505 Mediane -1.4049 3eme Quartile 11.3778 iqr absolu 24.5283 iqr relatif -1746.0000 % Minimum -49 Maximum 86 Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | -4 | 9865544332221111000 -3 | 999998888877776666555555555544444443333333333333333222222222111111111111111100000000000000000000000000000 -2 | 9999999999999999999988888888888888888888887777777777777777777777777666666666666666666666666555555555555555555555554444+156 -1 | 9999999999999999999999999999999999999999888888888888888888888888888888888888888888877777777777777777777777777777777766+344 -0 | 9999999999999999999999999999999999999999999999999999999999998888888888888888888888888888888888888888888888888888888888+462 0 | 0000000000000000000000001111111111111111111111111111111111111111112222222222222222222222222222222222222222222222223333+379 1 | 0000000000000000000000000000000000000000000000000000011111111111111111111111111111111111111112222222222222222222222222+238 2 | 0000000000000000000000001111111111111111111222222222222222222222223333333333333333333333333334444444444444444444444555+83 3 | 0000000000111111111111111111112222222222222222233333333333444444444444444455555666666777777777788888888888888899999999 4 | 000000011111122222333334444445555566666677777788899 5 | 000011222223334445666789 6 | 037 7 | 8 | 6 Test de normalité de Shapiro-Wilk Shapiro-Wilk normality test data: ei W = 0.9896, p-value = 2.667e-13 vous pouvez utiliser SBP_AGE_detail_3.png vous pouvez utiliser SBP_AGE_detail_4.png vous pouvez utiliser SBP_AGE_detail_5.png vous pouvez utiliser SBP_AGE_detail_6.png vous pouvez utiliser SBP_AGE_detail_7.png vous pouvez utiliser SBP_AGE_detail_8.png vous pouvez utiliser SBP_AGE_detail_9.png vous pouvez utiliser SBP_AGE_detail_10.png Test de l'homoscédasticité des résidus ====================================== studentized Breusch-Pagan test data: lm(yi ~ xi) BP = 0.4802, df = 1, p-value = 0.4883 $modele Call: lm(formula = yi ~ xi) Coefficients: (Intercept) xi 103.6295 0.4717 $coefs Estimate Std. Error t value Pr(>|t|) 2.5 % 97.5 % (Intercept) 103.6294883 3.59572516 28.820192 6.536725e-160 96.5789056 110.6800709 xi 0.4717281 0.05368381 8.787157 2.641961e-18 0.3664636 0.5769925 $indicateurs obs xi yi yi_chapeau résidu résidu_studentisé levier rstudent dfits cook_dist 1 70 138 136.6505 1.349546898 0.0719131888 0.0004537991 0.0719002319 1.532007e-03 1.173945e-06 2 62 118 132.8766 -14.876628549 -0.7927632790 0.0005386795 -0.7927099271 -1.840334e-02 1.693642e-04 3 69 134 136.1787 -2.178725033 -0.1160948233 0.0004071521 -0.1160740807 -2.342621e-03 2.744917e-06 4 64 152 133.8201 18.179915313 0.9687348584 0.0004193045 0.9687240564 1.984065e-02 1.968301e-04 ...
Pour tracer les intervalles de confiance, le plus simple est de passer par notre fonction traceLin.
# lecture des données library(gdata) hers <- read.xls("http://forge.info.univ-angers.fr/~gh/wstat/Eda/hersdata.xls") gr("SBPageCI.png") traceLin("SBP",hers$SBP,"AGE",hers$age,TRUE) dev.off()
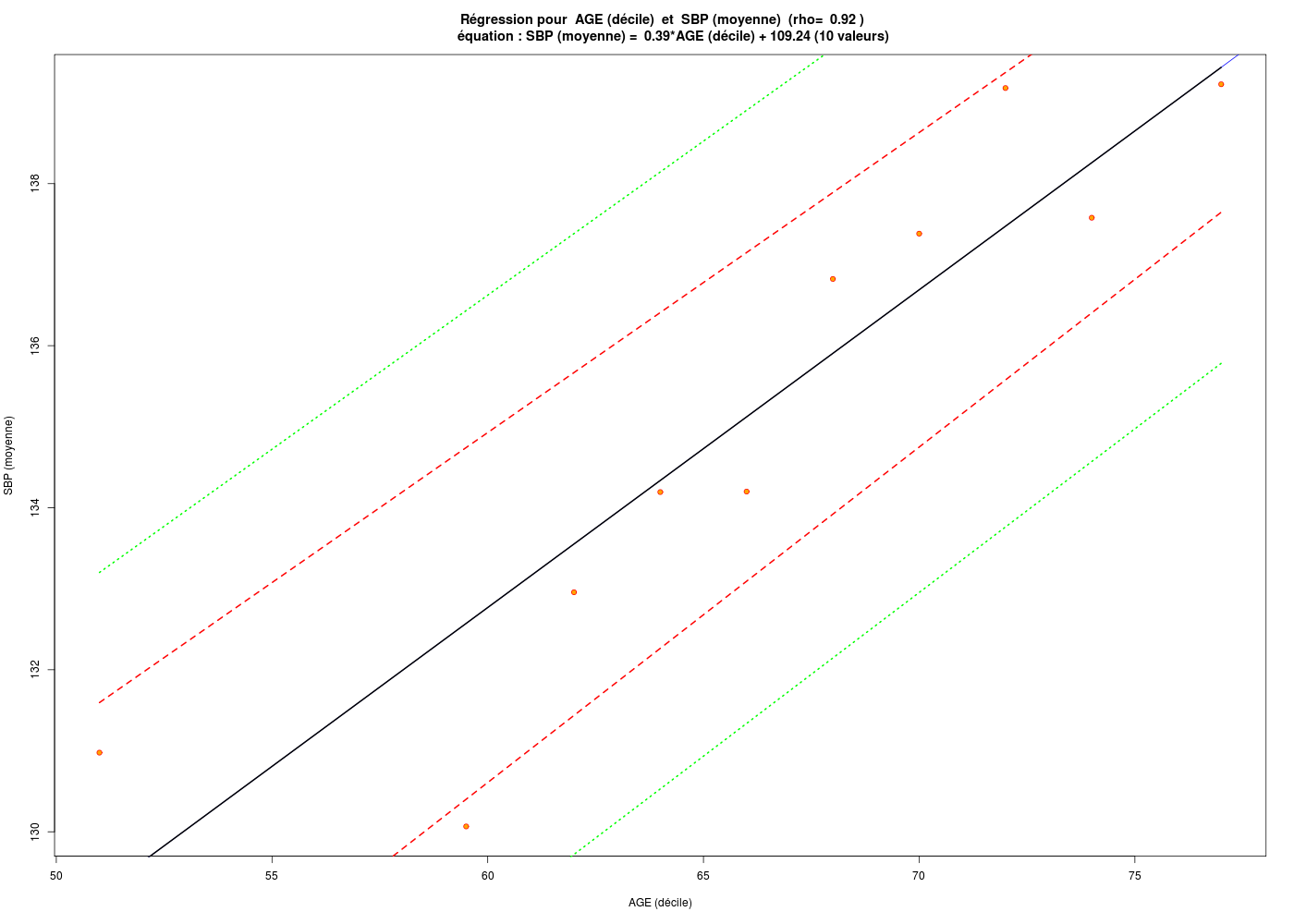
# déciles de l'age tab.deciles <- quantile(HERS$age,probs=seq(0,1,0.1)) deciles <- as.numeric(tab.deciles) # affichage des déciles print(cbind(deciles)) # points-milieu des déciles nbp <- length(deciles) agemilieu <- (deciles[1:(nbp-1)]+deciles[2:nbp])/2 # découpage de SBP en fonction des déciles HERS$ageq <- cut(HERS$age,breaks=tab.deciles,labels=FALSE) # calcul de la moyenne de SBP pour chaque intervalle moySBP <- as.numeric(tapply(HERS$SBP,HERS$ageq,mean)) # affichage des valeurs print(cbind(agemilieu,moySBP)) # régression sur l'age ml <- lm(SBP ~ age,data=hers) print( summary(ml) ) # régression sur les déciles ml2 <- lm(moySBP ~ agemilieu) print( summary(ml2) ) # tracé de SBP moyenn en fonction des déciles de AGE gr("SBP_moy_agepred1.png") plot(moySBP~agemilieu,col="green",pch=15) abline(ml2,col="black",lwd=2) dev.off() # tracé des valeurs prédites en fonction des valeurs originales gr("SBP_moy_agepred2.png") plot(ml2$fitted.values~moySBP,col="red",pch=19) abline(a=0,b=1,col="black",lwd=2) # attention : a + b * x dev.off() # superposition avec le modèle linéaire sur toutes les valeurs gr("SBPMagepred3.png") plot(hers$SBP~hers$age,col="black",pch=19,cex=0.3) abline(ml,col="blue",lwd=2) par(new=TRUE) points(agemilieu,moySBP,col="darkgreen",pch=15) abline(ml2,col="red",lwd=2) dev.off() # tracé des valeurs prédites en fonction des valeurs originales gr("SBPMagepred4.png") plot(ml$fitted.values~hers$SBP,col="red",pch=19,cex=0.3) par(new=TRUE) points(moySBP,ml2$fitted.values,col="green",pch=15) abline(a=0,b=1,col="black",lwd=2) # attention : a + b * x dev.off()deciles [1,] 44 [2,] 58 [3,] 61 [4,] 63 [5,] 65 [6,] 67 [7,] 69 [8,] 71 [9,] 73 [10,] 75 [11,] 79 agemilieu moySBP [1,] 51.0 130.9768 [2,] 59.5 130.0658 [3,] 62.0 132.9567 [4,] 64.0 134.1932 [5,] 66.0 134.1993 [6,] 68.0 136.8235 [7,] 70.0 137.3828 [8,] 72.0 139.1799 [9,] 74.0 137.5792 [10,] 77.0 139.2269 Call: lm(formula = SBP ~ age, data = hers) Residuals: Min 1Q Median 3Q Max -49.405 -13.150 -1.405 11.378 85.934 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 103.62949 3.59573 28.820 <2e-16 *** age 0.47173 0.05368 8.787 <2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 18.77 on 2761 degrees of freedom Multiple R-squared: 0.02721, Adjusted R-squared: 0.02685 F-statistic: 77.21 on 1 and 2761 DF, p-value: < 2.2e-16 Call: lm(formula = moySBP ~ agemilieu) Residuals: Min 1Q Median 3Q Max -2.5062 -0.6585 -0.1759 0.8617 1.7384 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 109.23714 4.01624 27.199 3.6e-09 *** agemilieu 0.39218 0.06017 6.518 0.000185 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.381 on 8 degrees of freedom Multiple R-squared: 0.8415, Adjusted R-squared: 0.8217 F-statistic: 42.48 on 1 and 8 DF, p-value: 0.0001846 RStudioGD 2 RStudioGD 2 RStudioGD 2 RStudioGD 2
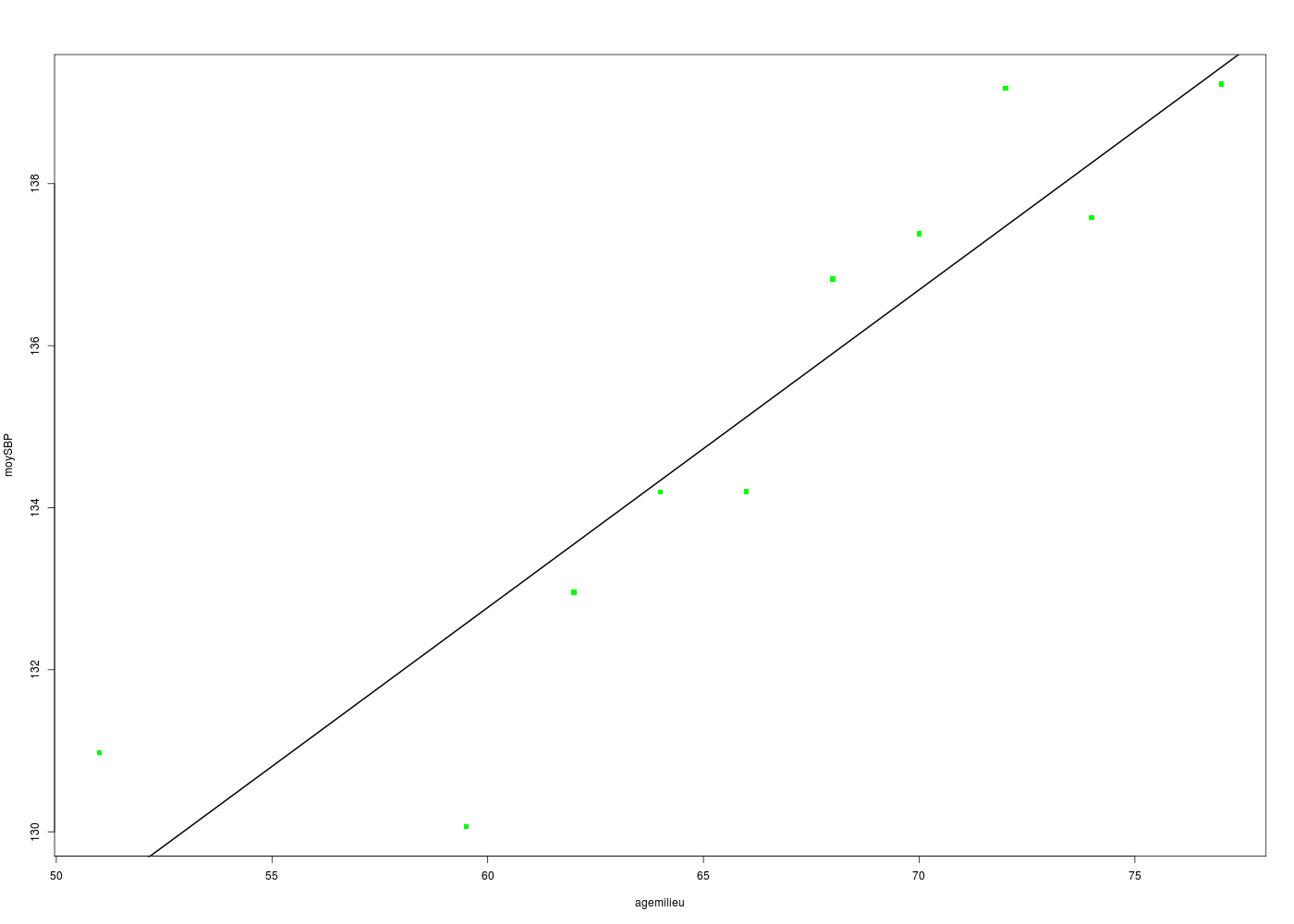
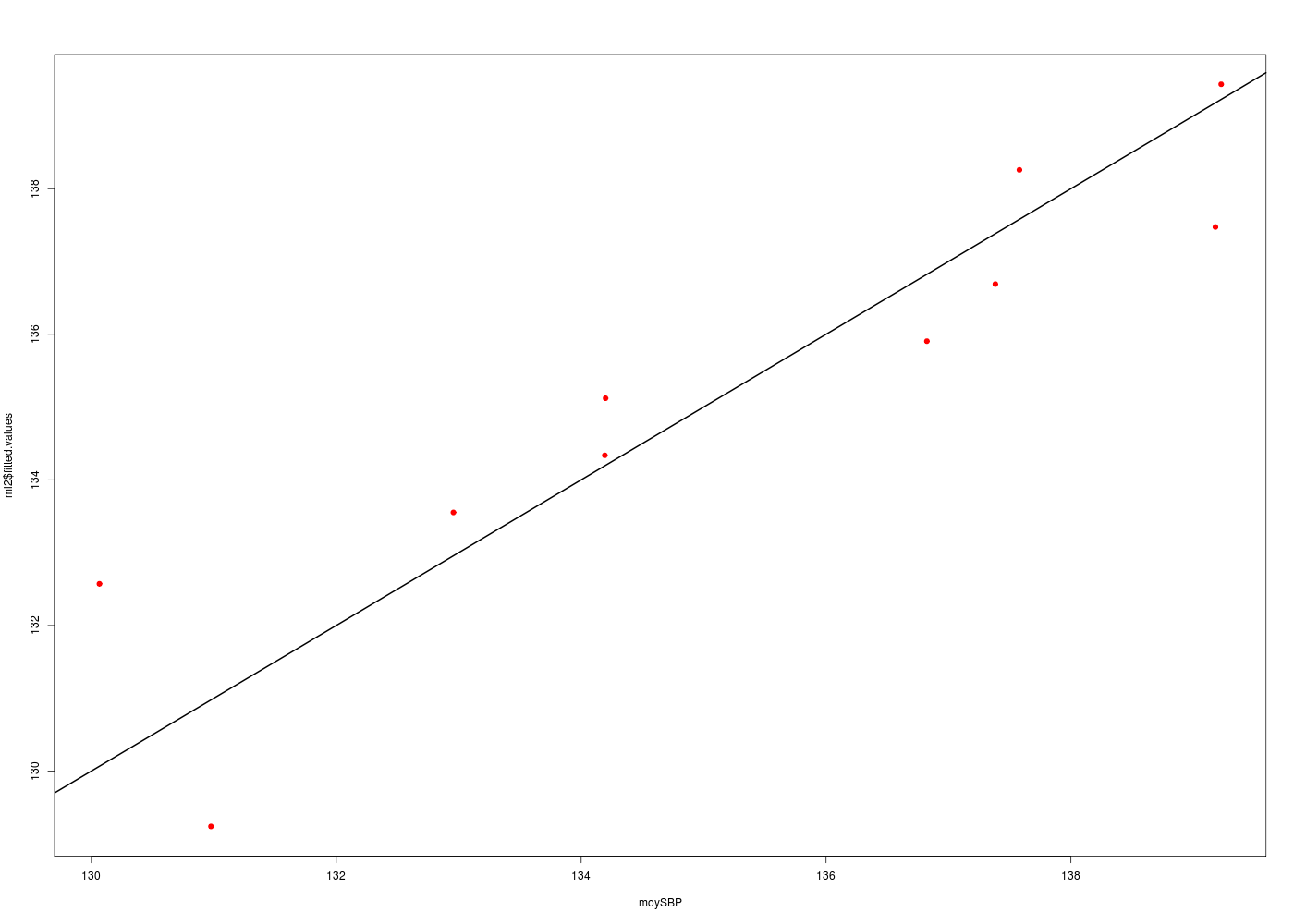
gr("SBPMageCI.png") traceLin("AGE (décile)",agemilieu,"SBP (moyenne)",moySBP,TRUE) dev.off()
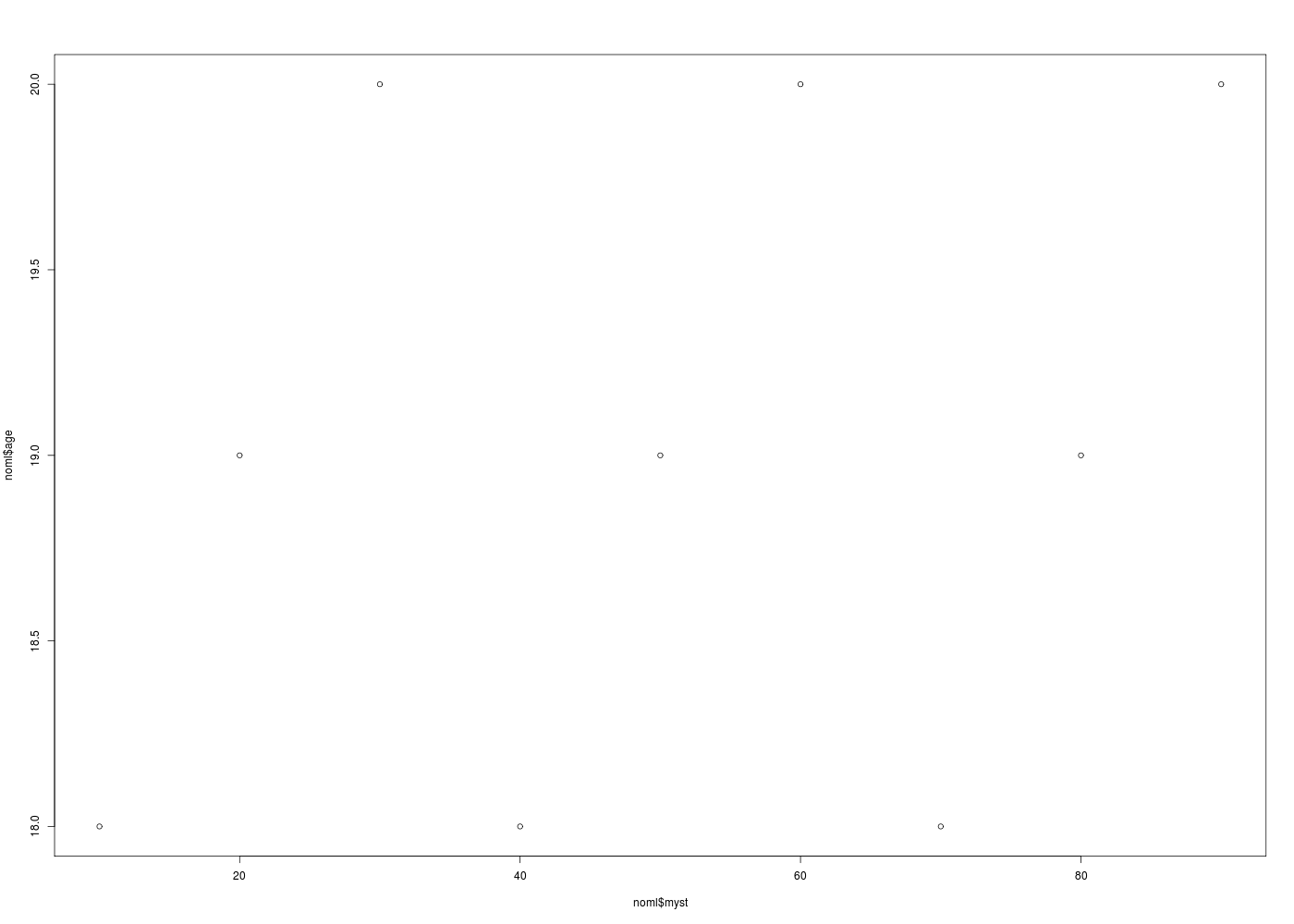
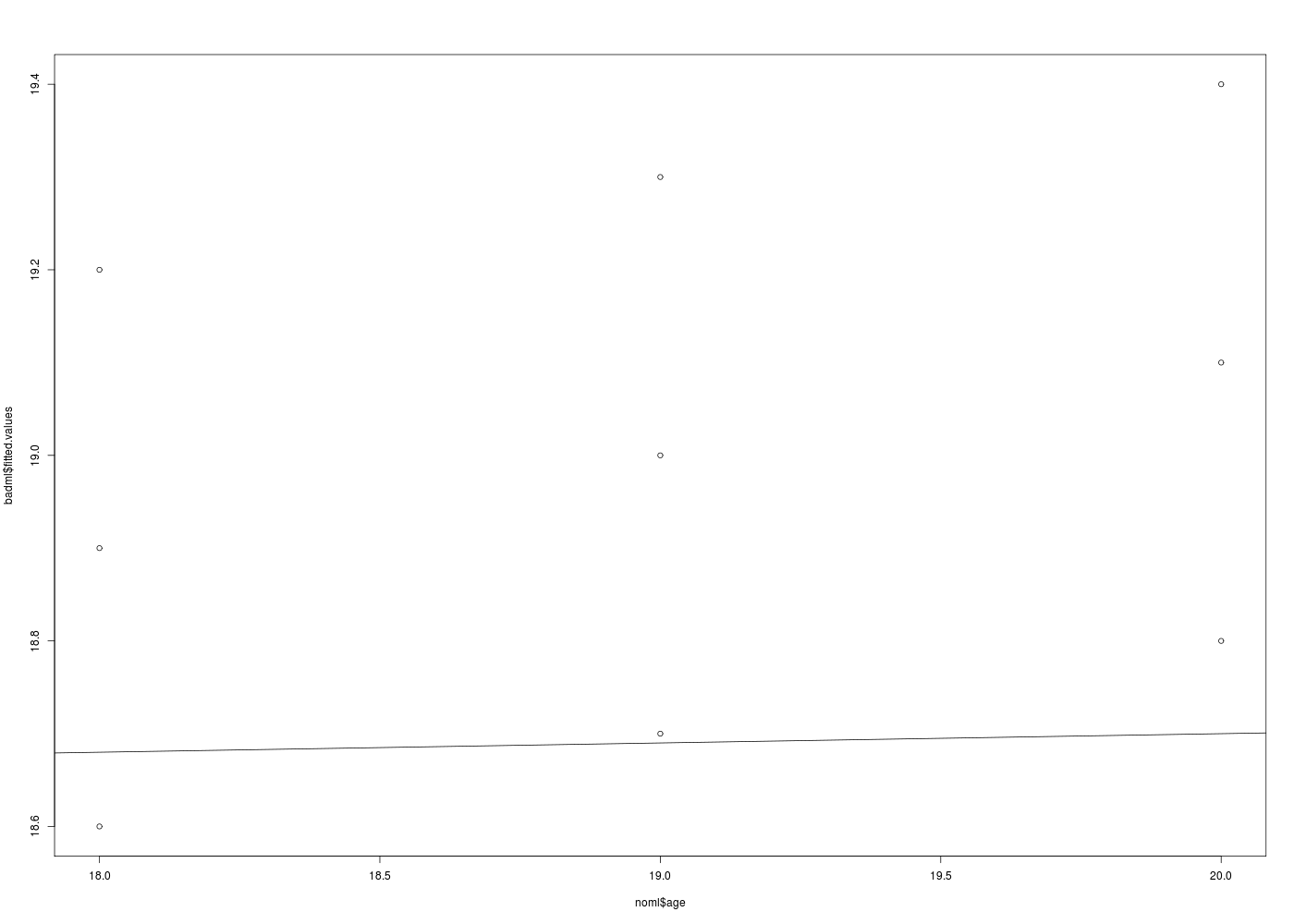
La relation n'est absolument pas linéaire entre les deux variables. Un graphique de age en fonction de myst le montre. Si on ne regarde que les chiffres, on constate que le test F dit que la régression n'est pas significative. Ce n'est donc pas la peine d'aller plus loin...
# lecture des données noml <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/noml.dar") # modèle linéaire badml <- lm(age~myst,data=noml) # statistiques print(summary(badml)) # tracés gr("noml1.png") ; plot(noml$myst,noml$age) dev.off() gr("noml2.png") ; plot(noml$age,badml$fitted.values) abline(badml) dev.off()Call: lm(formula = age ~ myst, data = noml) Residuals: Min 1Q Median 3Q Max -1.2 -0.6 0.0 0.6 1.2 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 18.50000 0.63808 28.993 1.49e-08 *** myst 0.01000 0.01134 0.882 0.407 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.8783 on 7 degrees of freedom Multiple R-squared: 0.1, Adjusted R-squared: -0.02857 F-statistic: 0.7778 on 1 and 7 DF, p-value: 0.4071
a vaut r*ect(Y)/ect(X) et b vaut moy(Y)-a*moy(X) où r est le coefficient de corrélation linéaire de Pearson entre X et Y. Le point des moyennes est donc toujours sur la droit de régression. Tous les coefficients du modèle linéaire reposent donc uniquement sur les moyennes et les écart-types, ce qui signifie que des données très différentes mais avec la même moyenne et le même écart-type définissent (sont modélisés par) le même modèle linéaire.
Les données d'Anscombe correspondent à 4 jeux de données qui donnent les mêmes résultats numériques de régression linéaire simple alors que les données sont très différentes. Il faut donc toujours utiliser des représentations graphiques au lieu de se baser uniquement sur les résultats chiffrés.
# lecture des données qansc <- lit.dar("http://www.info.univ-angers.fr/~gh/Datasets/anscombe.dar") # résumés "à l'aveugle" cats("les 4 colonnes semblent peu différentes, en résumé") cols <- paste("Y",1:4,sep="") mdr <- matrix(nrow=5,ncol=length(cols)) dy <- qansc[,cols] mdr[1,] <- colMeans( dy ) mdr[2,] <- apply(X=dy,FUN=sd,MARGIN=2) colnames(mdr) <- cols row.names(mdr) <- c("Moyennes","Ecarts-type","Statistique F","Rés. normaux","Signif. code") print(mdr[-3,]) # plus court à écrire que print(mdr[1:2,]) # les différents modèles linéaires cats("# modèle 1") print( summary(lm(Y1~X ,data=qansc)) ) cats("# modèle 2") print( summary(lm(Y2~X ,data=qansc)) ) cats("# modèle 3") print( summary(lm(Y3~X ,data=qansc)) ) cats("# modèle 4") print( summary(lm(Y4~X4,data=qansc)) ) ## ajoutons la valeur de la F-statistique au tableau des résumés # une liste de tous les modèles lstlm <- with(qansc,list( lm(Y1~X ), lm(Y2~X ), lm(Y3~X ), lm(Y4~X4) ) # fin de liste ) # fin de with # une fonction pour extraire la statistique F fstatistic <- function(modele) { return((anova(modele)$"Pr(>F)")[1]) } # ajout de la statistique F mdr[3,] <- sapply(X=lstlm,FUN=fstatistic) # on n'avait pas besoin d'inventer la fonction fstatistic : mdr2 <- mdr mdr2[3,] <- sapply(X=lstlm,FUN=function(modele) { return((anova(modele)$"Pr(>F)")[1])}) # print( identical(mdr,mdr2) ) renverrait TRUE # ajout de la p-value du test de normalité des résidus (shapiro.wilk) # et son interprétation mdr2[4,] <- sapply(X=lstlm,FUN=function(modele) { return(shapiro.test(residuals(modele))$p.value) }) mdr2[5,] <- sapply(X=mdr2[4,],FUN=as.sigcode) # affichage cats("Tableau résumé") print(mdr2,quote=FALSE) # visualisation des résidus gr("anscres.png") par(mfrow=c(2,2)) plot(lm(Y1~X,data=qansc),which=1) plot(lm(Y2~X,data=qansc),which=1) plot(lm(Y3~X,data=qansc),which=1) plot(lm(Y4~X4,data=qansc),which=1) par(mfrow=c(1,1)) dev.off()les 4 colonnes semblent peu différentes, en résumé ================================================== Y1 Y2 Y3 Y4 Moyennes 7.500909 7.500909 7.500000 7.500909 Ecarts-type 2.031568 2.031657 2.030424 2.030579 Rés. normaux NA NA NA NA Signif. code NA NA NA NA # modèle 1 ========== Call: lm(formula = Y1 ~ X, data = qansc) Residuals: Min 1Q Median 3Q Max -1.92127 -0.45577 -0.04136 0.70941 1.83882 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.0001 1.1247 2.667 0.02573 * X 0.5001 0.1179 4.241 0.00217 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.237 on 9 degrees of freedom Multiple R-squared: 0.6665, Adjusted R-squared: 0.6295 F-statistic: 17.99 on 1 and 9 DF, p-value: 0.00217 # modèle 2 ========== Call: lm(formula = Y2 ~ X, data = qansc) Residuals: Min 1Q Median 3Q Max -1.9009 -0.7609 0.1291 0.9491 1.2691 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.001 1.125 2.667 0.02576 * X 0.500 0.118 4.239 0.00218 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.237 on 9 degrees of freedom Multiple R-squared: 0.6662, Adjusted R-squared: 0.6292 F-statistic: 17.97 on 1 and 9 DF, p-value: 0.002179 # modèle 3 ========== Call: lm(formula = Y3 ~ X, data = qansc) Residuals: Min 1Q Median 3Q Max -1.1586 -0.6146 -0.2303 0.1540 3.2411 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.0025 1.1245 2.670 0.02562 * X 0.4997 0.1179 4.239 0.00218 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.236 on 9 degrees of freedom Multiple R-squared: 0.6663, Adjusted R-squared: 0.6292 F-statistic: 17.97 on 1 and 9 DF, p-value: 0.002176 # modèle 4 ========== Call: lm(formula = Y4 ~ X4, data = qansc) Residuals: Min 1Q Median 3Q Max -1.751 -0.831 0.000 0.809 1.839 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.0017 1.1239 2.671 0.02559 * X4 0.4999 0.1178 4.243 0.00216 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.236 on 9 degrees of freedom Multiple R-squared: 0.6667, Adjusted R-squared: 0.6297 F-statistic: 18 on 1 and 9 DF, p-value: 0.002165 Tableau résumé ============== Y1 Y2 Y3 Y4 Moyennes 7.50090909090909 7.50090909090909 7.5 7.50090909090909 Ecarts-type 2.03156813592582 2.03165673550162 2.03042360112367 2.0305785113876 Statistique F 0.0021696288730788 0.0021788162369108 0.00217630527922802 0.00216460234719722 Rés. normaux 0.545584685341384 0.0929488137110523 0.00157405546473418 0.780048487911356 Signif. code NS . ** NS
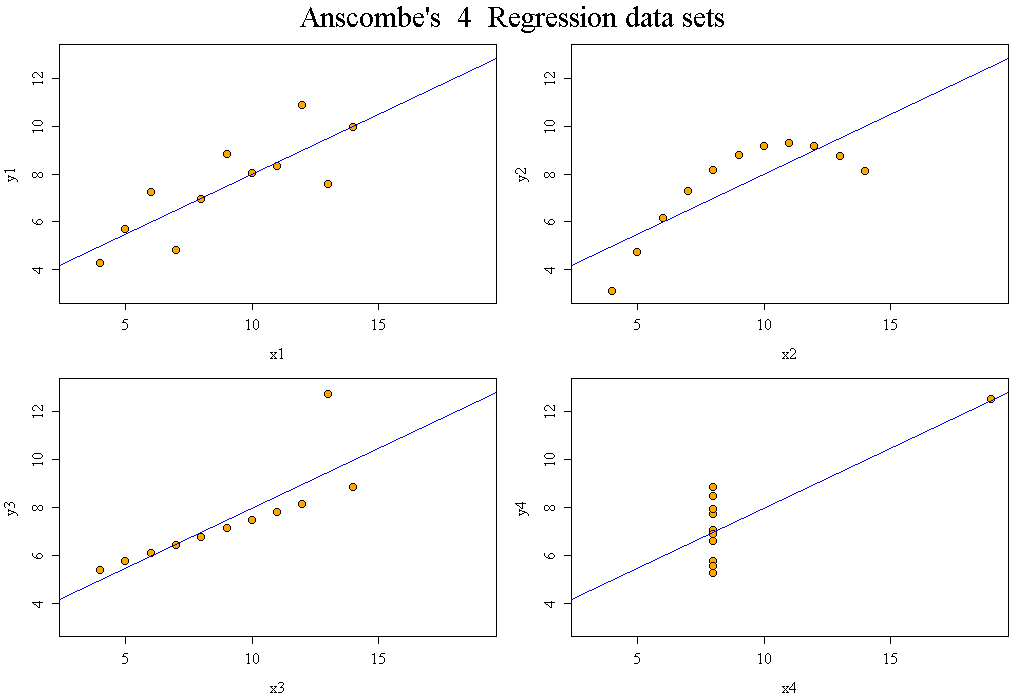
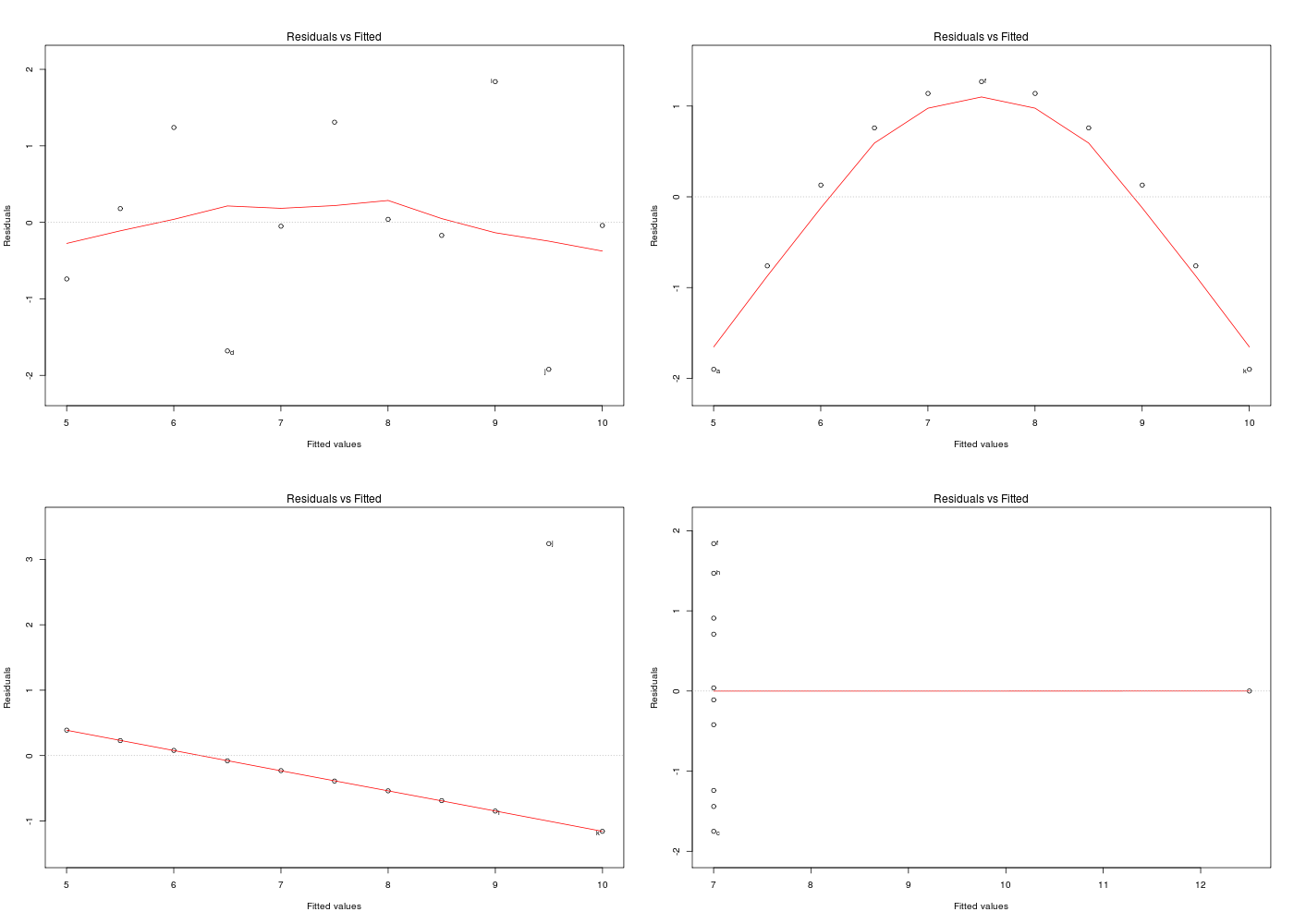
On consultera la page du wiki Anscombe pour plus d'information et on pourra lire la page d'aide associée au jeu de données anscombe du package datasets, aide disponible par help(anscombe) sous R, le tracé étant affiché par example(anscombe).
En principe, un modèle linéaire établi pour un intervalle I1 pour X et I2 pour Y ne peut être utilisé en prédiction que pour des valeurs x situées dans I1 et des valeurs y situées dans I2, et encore, en utilisant les intervalles de prédiction. Ainsi un modèle pour les années 1980 à 2000 ne doit pas être utilisé pour prédire des valeurs en 2050.
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # tracé sur de grands intervalles gr("kmpred_loin.png") traceLin( titreVar1="Distance", varQT1=km$distance, titreVar2="CONSOMMATION", varQT2=km$essence, graphique=TRUE, xmin=0, xmax=3000, ymin=0, ymax=400 ) # fin de traceLIn dev.off()
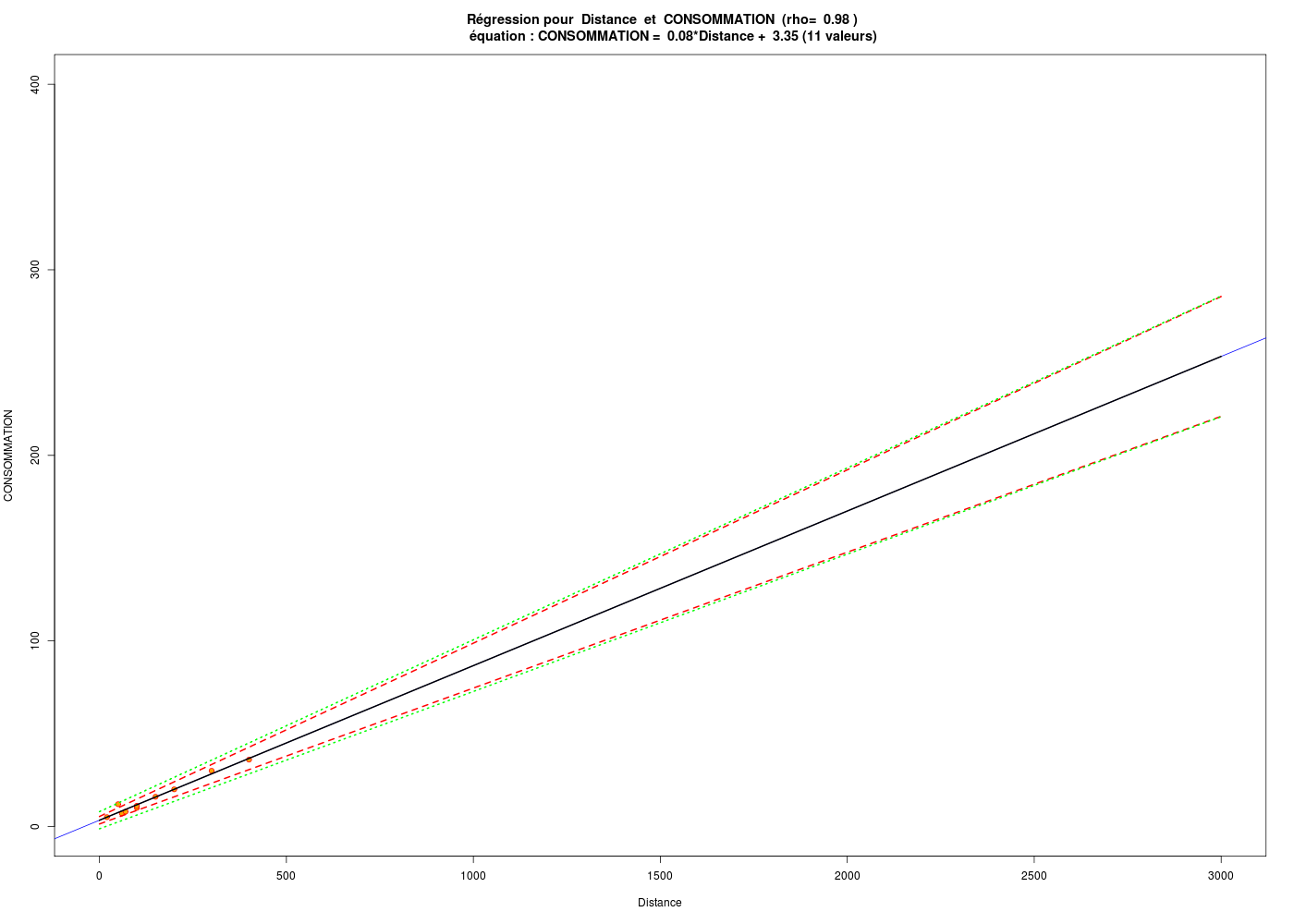
Les valeurs prédites par le modèle pour 1 000 km et 3 000 km sont donc certainement inexploitables (ce qui ne veut pas dire qu'elles sont fausses).
# lecture des données km <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/km.dar") # modèle linéaire ml <- lm(essence ~ distance,data=km) # prédictions cats("valeurs prédites") newx <- c(1000,3000) # on construit un nouveau data frame avec le même nom pour x newxdf <- data.frame(distance=newx) newy <- predict(ml,newxdf) print(rbind(newx,newy))valeurs prédites ================ 1 2 newx 1000.00000 3000.0000 newy 86.67029 253.3101Il est d'usage d'utiliser le coefficient de détermination R² comme critère de qualité d'une régression linéaire simple, équivalent au carré du coefficient de corrélation pour comparer divers modèles avec le même nombre de variables (en régression linéaire multiple, il faut utiliser un R2 ajusté). On peut utiliser une boucle pour calculer les coefficients de détermination ou passer par apply() du package base avec MARGIN=2 pour indiquer qu'on traite les colonnes de données.
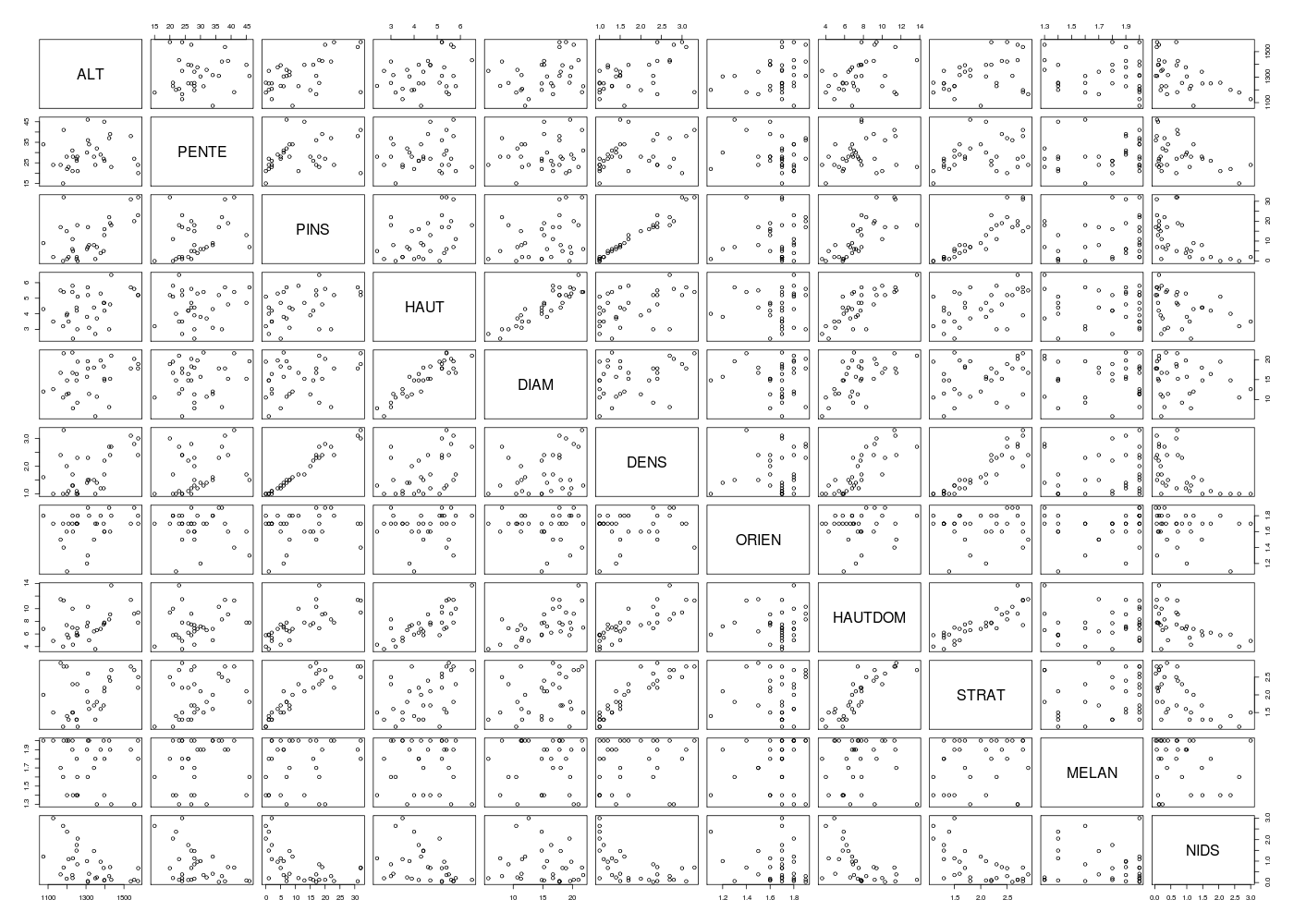
Le tracé par paires permet en général de se faire une idée de la "tendance linéaire" entre couples de variables. Pour cela, on peut utiliser la fonction pairs() de R ou notre version améliorée, nommée pairsi().
# lecture des données chenill <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.txt") # on ote la variable 12, LN_NID chenill <- chenill[,-12] # définition de la matrice des résultats nbv <- ncol(chenill) -1 mdr <- data.frame(matrix(nrow=nbv,ncol=5)) names(mdr) <- c("Variable","R²","R² ajusté","Corrélation","p-value") # on utilise une boucle pour stocker les R2 for (idv in (1:nbv)) { ml <- lm(chenill$NIDS ~ chenill[,idv]) re <- summary(ml) mdr[idv,1] <- names(chenill)[idv] mdr[idv,2] <- re$r.squared mdr[idv,3] <- re$adj.r.squared mdr[idv,4] <- cor(chenill$NIDS,chenill[,idv]) mdr[idv,5] <- cor.test(chenill$NIDS,chenill[,idv])$p.value } # fin pour idv # tri par R² décroissant idx <- order(mdr[,2],decreasing=TRUE) mdr <- mdr[idx,] cats("Meilleure régression simple pour NIDS:") print(mdr) # on écrit une fonction pour récupérer les R² r2 <- function(ml) { return(summary(ml)$r.squared) } r2a <- function(ml) { return(summary(ml)$adj.r.squared) } vr2 <- apply(X=chenill[,-11],M=2,F=function(x) { r2(lm(chenill$NIDS ~x)) }) vr2a <- apply(X=chenill[,-11],M=2,F=function(x) { r2a(lm(chenill$NIDS ~x)) }) mdr2 <- cbind(vr2,vr2a) names(mdr2) <- c("R²","R² ajusté") idx <- order(mdr2[,1],decreasing=TRUE) mdr2 <- mdr2[idx,] print(round(mdr2,3)) gr("chen_pairs1.png") pairs(chenill) dev.off() gr("chen_pairs2.png") pairsi(chenill) dev.off() mdc(chenill)Meilleure régression simple pour NIDS: ====================================== Variable R² R² ajusté Corrélation p-value 9 STRAT 0.40433270 0.385117628 -0.6358716 6.986539e-05 6 DENS 0.32517420 0.303405622 -0.5702405 5.309472e-04 3 PINS 0.31798408 0.295983565 -0.5639008 6.317299e-04 8 HAUTDOM 0.30374609 0.281286290 -0.5511316 8.872649e-04 1 ALT 0.28113194 0.257942648 -0.5302188 1.504379e-03 2 PENTE 0.20744214 0.181875755 -0.4554582 7.733643e-03 4 HAUT 0.12809342 0.099967401 -0.3579014 4.085378e-02 7 ORIEN 0.04483734 0.014025640 -0.2117483 2.368205e-01 5 DIAM 0.02489175 -0.006563354 -0.1577712 3.805462e-01 10 MELAN 0.01534070 -0.016422502 -0.1238576 4.922563e-01 R² R²a STRAT 0.404 0.385 DENS 0.325 0.303 PINS 0.318 0.296 HAUTDOM 0.304 0.281 ALT 0.281 0.258 PENTE 0.207 0.182 HAUT 0.128 0.100 ORIEN 0.045 0.014 DIAM 0.025 -0.007 MELAN 0.015 -0.016 Matrice des corrélations au sens de Pearson pour 33 lignes et 11 colonnes ALT PENTE PINS HAUT DIAM DENS ORIEN HAUTDOM STRAT MELAN NIDS ALT 1.000 PENTE 0.121 1.000 PINS 0.538 0.322 1.000 HAUT 0.321 0.137 0.414 1.000 DIAM 0.284 0.113 0.295 0.905 1.000 DENS 0.515 0.301 0.980 0.439 0.306 1.000 ORIEN 0.268 -0.152 0.128 0.058 -0.079 0.151 1.000 HAUTDOM 0.360 0.262 0.759 0.772 0.596 0.810 0.060 1.000 STRAT 0.364 0.326 0.877 0.460 0.267 0.909 0.063 0.854 1.000 MELAN -0.100 0.129 0.206 -0.045 -0.025 0.130 0.138 0.054 0.175 1.000 NIDS -0.530 -0.455 -0.564 -0.358 -0.158 -0.570 -0.212 -0.551 -0.636 -0.124 1.000
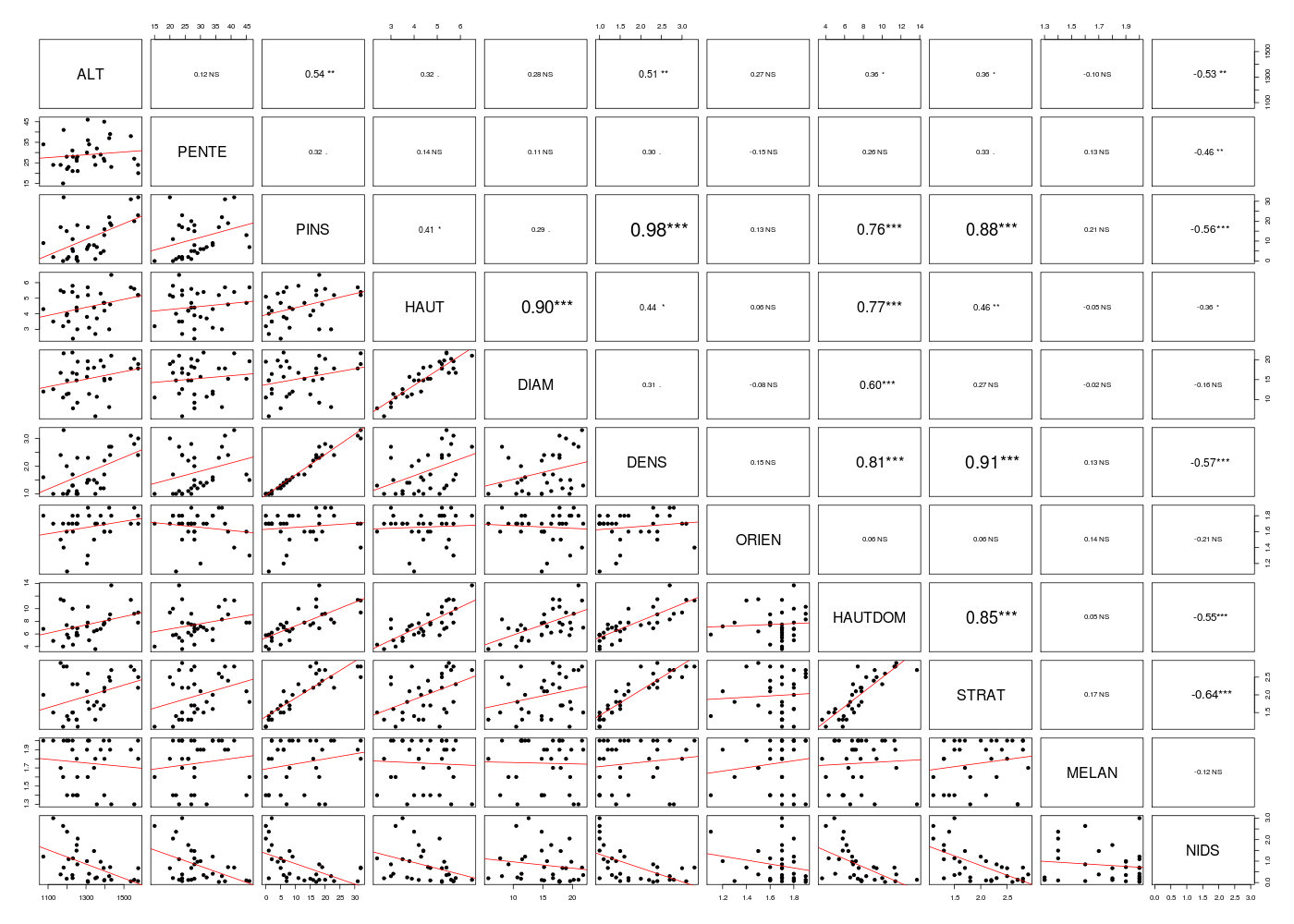
Il existe d'autres critères de qualité comme les critères AIC, BIC, la quantité RMSE...
library(rgp) # pour la fonction RMSE # lecture des données chenill <- lit.dar("chenilles.txt") # on ote la variable 12, LN_NID chenill <- chenill[,-12] # définition de la matrice des résultats nbv <- ncol(chenill) -1 mdr <- data.frame(matrix(nrow=nbv,ncol=7)) names(mdr) <- c("R2","R2 ajusté","Corrélation","p-value","AIC","BIC","RMSE") row.names(mdr) <- names(chenill)[1:nbv] # on utilise une boucle pour stocker les critères de qualité for (idv in (1:nbv)) { ml <- lm(chenill$NIDS ~ chenill[,idv]) re <- summary(ml) mdr[idv,1] <- re$r.squared mdr[idv,2] <- re$adj.r.squared mdr[idv,3] <- cor(chenill$NIDS,chenill[,idv]) mdr[idv,4] <- cor.test(chenill$NIDS,chenill[,idv])$p.value mdr[idv,5] <- AIC(ml) mdr[idv,6] <- BIC(ml) mdr[idv,7] <- rmse(chenill$NIDS,chenill[,idv]) } # fin pour idv # tri par R² décroissant idx <- order(mdr[,1],decreasing=TRUE) mdr <- mdr[idx,] cats("Meilleure régression simple pour NIDS:") print( round(mdr,3) )Meilleure régression simple pour NIDS: ====================================== R2 R2 ajusté Corrélation p-value AIC BIC RMSE STRAT 0.404 0.385 -0.636 0.000 67.322 71.812 1.696 DENS 0.325 0.303 -0.570 0.001 71.440 75.929 1.652 PINS 0.318 0.296 -0.564 0.001 71.790 76.279 14.509 HAUTDOM 0.304 0.281 -0.551 0.001 72.472 76.961 7.300 ALT 0.281 0.258 -0.530 0.002 73.526 78.016 1320.690 PENTE 0.207 0.182 -0.455 0.008 76.747 81.236 29.221 HAUT 0.128 0.100 -0.358 0.041 79.895 84.385 3.939 ORIEN 0.045 0.014 -0.212 0.237 82.905 87.395 1.201 DIAM 0.025 -0.007 -0.158 0.381 83.587 88.077 15.105 MELAN 0.015 -0.016 -0.124 0.492 83.909 88.398 1.276Au bout du compte, il semble bien que le meilleur modèle univarié soit celui qui utilise la variable STRAT, le second meilleur celui avec DENS... Cet ordre suit bien sûr l'orde des coefficients de corrélation linéaire des variables avec la variable NIDS...