![]()
![]()
Les dates de formation sont ici.
Solutions pour la séance numéro 1 (énoncés)
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Solutions pour la séance numéro 1 (énoncés)
Effectuer une régression de Y en fonction de X, c'est, en gros, modéliser Y par une fonction de X. Plus généralement, régresser Y sachant des variables Xj, c'est, étant donnée une classe C de fonctions et une fonction de coût L, trouver une fonction f de C qui minimise la somme des L( Yi - f( (Xj) )i ). Classiquement, f est une fonction linéaire et donc on modélise la dépendance de Y par rapport à X par Y = α*X + β quand il n'y a qu'une seule variable.
Si Y est quantitative, et si on n'a qu'une seule variable X quantitative, on parle de régression linéaire simple (RL ou RLINS). Si Y est quantitative, et si on a plusieurs variables X toutes quantitatives, on parle de régression linéaire multiple (RLM ou RLINM). Si Y est qualitative, on parle de régression logistique (RLO). Si Y est qualitative binaire, la régression est logistique binaire (RLOB) et on distingue, pour Y qualitative non binaire, le cas ordinal (régression logistique ordinale RLOO) du cas nominal (régression logistique polytomique ou RLOP). Sauf à définir le vocabulaire, en toute rigueur RL est ambigu et peut désigner aussi bien Régression Linéaire que Régression Logistique. En résumé :
Régression Y = f( X1, X2, ...) une seule variable X régression simple plusieurs variables Xi régression multiple
Régression Y = f( X1, X2, ...) Y quantitative régression linéaire Y qualitative régression logistique Réaliser une régression se fait en plusieurs étapes :
Définir le modèle a priori.
Décrire les variables et, éventuellement, pré-traiter les données et rédéfinir le modèle.
Sélectionner la ou les meilleures variables à utiliser en cas de régression multiple.
Estimer la qualité du modèle et, le cas échéant, les coefficients du modèle.
Analyser la validité du modèle retenu, les points influents, les points-leviers, les valeurs extrêmes, quitte à remettre en question le modèle ou les données.
Pour voir les formules mathématiques associées, on lira dans cet ordre le wiki anglais puis le wiki français sur la notion de régression linéaire puis, toujours dans cet ordre, le wiki anglais suivi du wiki français sur la notion de régression logistique.
Pour approfondir la notion de régression linéaire, on pourra lire le polycopié en français modulad35 (copie locale). En ce qui concerne la régression logistique, le texte de R. Rakotomalala, bien qu'un peu long, est certainement une bonne référence (copie locale).
On notera qu'ici Y et les Xj sont données. Ce pourrait être des variables issues de transformations. C'est aux experts des données fournies de savoir si on modèlise en fonction de Xj ou de 1/Xj ou de Xαj, si Y doit être utilisée telle quelle ou transformée...
La régression logistique peut être vue comme un modèle linéaire généralise (GLM). Consulter le wiki anglais à ce sujet et la page GLM avec R.
Très généralement, on parle de corrélation entre deux phénomènes lorsqu'ils sont reliés d'une façon ou d'une autre. En statistiques, on parle de corrélation entre deux variables X et Y lorsque X et Y «varient ensemble», dans le même sens ou en sens inverse. Il y donc une «forte intensité de la liaison» entre X et Y (voir wiki pour les formules). Si la liaison entre X et Y est linéaire, on parle de corrélation linéaire au sens de Pearson ou Bravais-Pearson. Si la liaison n'est pas linéaire, ou s'il y a peu de valeurs, il est conseillé d'utiliser la corrélation des rangs de Spearman (wiki FR et surtout wiki EN), qu'on qualifie également de corrélation non paramétrique. Il existe également une corrélation de Kendall, plus proche de la concordance que de la corrélation. Enfin, si on veut quantifier l'égalité Y=X, par exemple dans le cas d'une étude de reproductibilité, il y a la corrélation de Lin.
Pour plus de détails, on pourra consulter le document analyse de corrélation de R. Rakotomalala (copie locale).
Une relation de causalité est une relation orientée, non symétrique, qui relie un effet à une cause, avec un sens de relation entre les variables. La relation mathématique de corrélation est symétrique et ne suppose pas forcément de causalité. On pourra lire avec profit les liens suivant sur «corrélation n'est pas causalité» : cum hoc..., cafepedagogique, themadoc et sesame.
Il existe bien sûr des tests statistiques pour indiquer si une corrélation est significativement non nulle. Ces tests sont nommés tout simplement tests de corrélation. Il existe aussi des tests plus spécifiques pour comparer deux coefficients de corrélation.
Une corrélation linéaire parfaite entre X et Y se traduit par ρ(X,Y)=1 ou ρ(X,Y)=-1 où ρ désigne le coefficient de corrélation linéaire de Pearson. Il existe alors des constantes a, b, c telles que aX+bY+c=0. Il est assez facile de voir que l'équation X=1*X+0 implique que la relation binaire définie par «X et Y sont en corrélation linéaire [parfaite]» est réflexive. De même, l'équation aX+bY+c=0 est symétrique en X et en Y, comme le calcul ρ(X,Y)=ρ(Y,X). Donc cette relation est symétrique. Enfin, si X et Y sont en corrélation linéaire parfaite et si Y et Z sont en corrélation linéaire parfaite, alors X et Z sont en corrélation linéaire parfaite. La relation est donc transitive, ce qu'on peut voir en remplaçant (un peu abusivement, et avec une légère perte de généralité) aX+bY+c=0 par Y=aX+b, car Z=cY+d aboutit à Z=(ac)X+(bc+d). La relation binaire définie par «être en corrélation linéaire parfaite» est donc ce qu'on nomme en mathématiques une relation d'équivalence, ce qui signifie que tout ce qu'on connait statistiquement sur une variable permet de déduire toutes les connaissances statistiques sur l'autre variable. Ainsi, Y=aX+b permet de conclure que moy(Y)=a.moy(X)+b et ect(Y)=|a|.ect(X). C'est pourquoi on peut se permettre de remplacer une variable X par toute combinaison linéaire aX+b.
Lorsque deux variables sont en corrélation linéaire parfaite, on n'a donc pas besoin de les conserver toutes les deux. Par contre, savoir laquelle garder est un problème non statistique, impossible à résoudre en dehors de tout contexte d'analyse.
Par contre, si X et Y ne sont pas en corrélation linéaire parfaite, et si Y et Z ne sont pas en corrélation linéaire parfaite, il peut quand même y avoir un "transfert" de ces liaisons linéaires entre X et Z, c'est ce qu'on nomme transitivité faible de la propriété de corrélation linéaire.
Pour le rappel sur les diverses ANOVA voir la solution de l'exercice 7 de la séance 3 du module I de biostatistique, ou le wiki anglais puis le wiki français. En deux mots : on compare des groupes via leur moyenne à l'aide de formules qui utilisent les variances induites par les groupes.
Si les liens entre régression linéaire et coefficient de corrélation linéaire semblent "flagrants", le rapport entre ANOVA et régression linéaire l'est peut-être moins. Il y a en fait au moins deux fortes ressemblances : les deux techniques utilisent la décomposition de la variance (variance inter et intra classes en ANOVA, variance expliquée et résiduelle en REGLIN) et elles utilisent un même formalisme, nommé modèle linéaire. On pourra consulter rapidement les pages module170 pour se rafraichir les idées sur ce modèle avec un petit exemple numérique. Pour plus de mathématiques, on pourra se référer aux cours de F. Bertrand sur l'estimation (surtout cours 6, 7 et 8) et vérifier que pour n1 = 1, la loi F de Fisher-Snedecor à (n1,n2) degrés de liberté est la loi de probabilité du carré d'une variable de Student à n2 degrés de liberté :
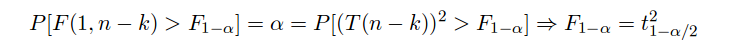
Analyser et décrire les variables se fait différemment pour les variables qualitatives et quantitatives. Le but de ces descriptions est de résumer les variables, notamment pour "connaitre un peu" les variables, mais aussi pour savoir si les conditions d'application des modèles, comme la normalité, sont respectées, si un déséquilibre de distribution ne va pas induire un biais dans le modèle...
Pour une variable qualitative, la description s'appuie sur les effectifs absolus et relatifs fournis par le tri à plat des modalités et sur la représentation en histogramme des fréquences. On vient alors conclure à une équirépartition (distribution homogène) ou à une disproportion, un déséquilibre entre les différents pourcentages. L'hétérogénéité associée peut parfois s'expliquer (faible pourcentage, faible prévalence dans le cas de maladies rares) ou forcer à remettre en question les données (parité homme/femme trop malmenée, par exemple, dans une étude où le sexe doit être pris en compte). Il est donc d'usage de faire un test du chi-deux d'adéquation entre les données observées et les valeurs théoriques attendues sous hypothèse d'équiprobabilité pour tester l'équirépartition.
Pour une variable quantitative, la description s'appuie sur les indicateurs classiques comme la moyenne, la médiane, l'écart-type... mais aussi sur des indicateurs plus spécifiques de la dispersion comme le coefficient de dissymétrie (skewness en anglais), le coefficient d'aplatissement (kurtosis en anglais), et sur des tests de normalité. On utilise souvent des tracés comme l'histogramme des classes (avec éventuellement superposition de l'estimation de la densité par noyau, de la loi normale sous-jacente, d'un "peigne" de distribution sur l'axe des X), la boite à moustaches, la droite de Henry, et parfois des tracés en violon ou en haricot avant de conclure à une distribution symétrique ou non (la distribution est alors déséquilibrée à gauche ou à droite), à une distribution normale ou non. Lorsqu'une variable n'est pas unimodale, la description de la variable et son utilisation en régression se révèlent "délicates" et il faut alors peut-être recourir à la modélisation d'interactions.
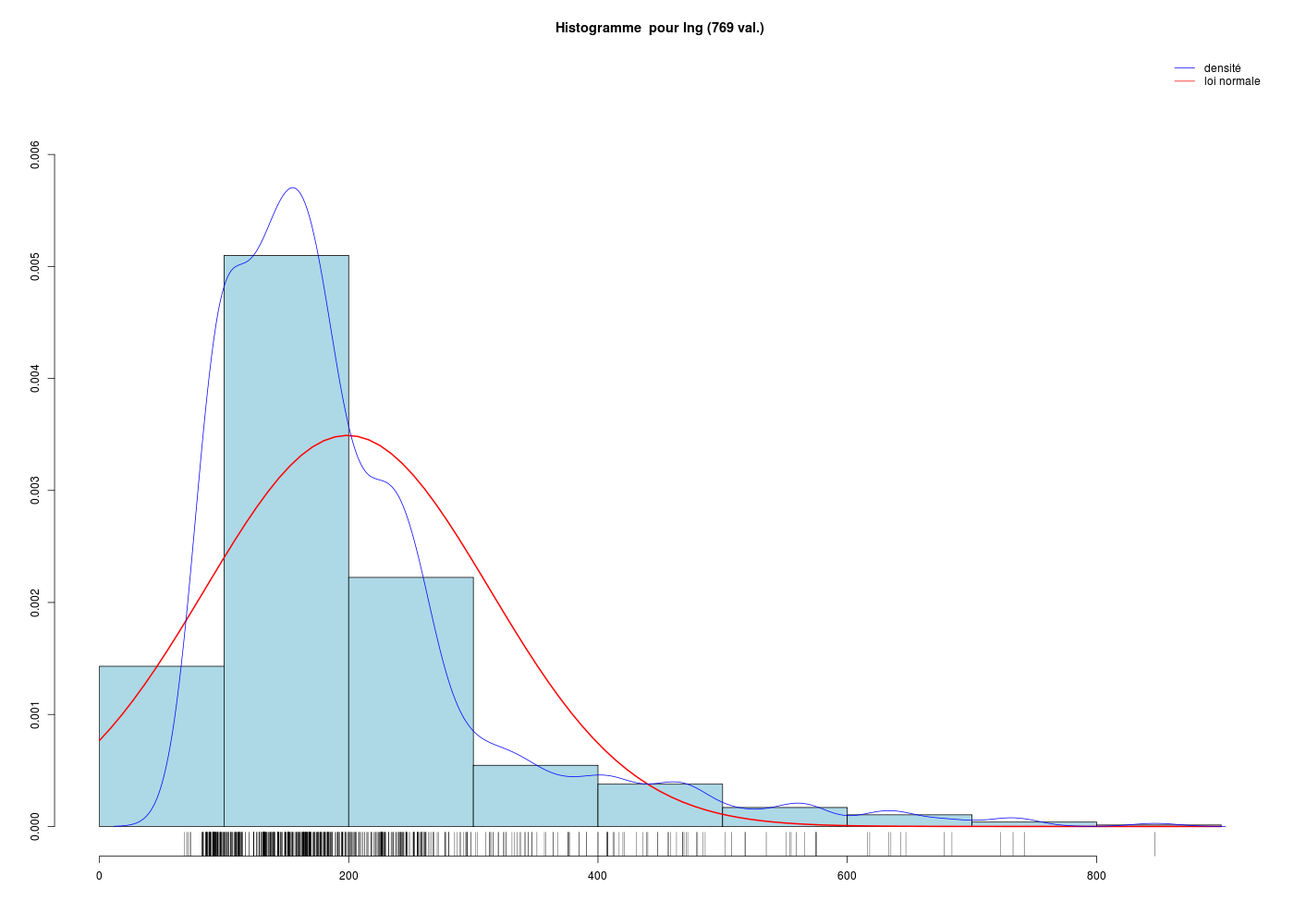
Il est classique aussi de s'intéresser à la taille n de l'échantillon, certains tests ayant peu de puissance statistique ou n'étant pas recommandés pour n<50. Il existe des tests pour la dissymétrie et l'aplatissement. Voir par exemple la page shape. Puisque «Google est notre ami», on pourra regarder les images des recherches right-skewed et left-skewed pour mémoriser à quoi correspondent ces termes de même que les pages Wiki pour kurtosis et skewness.
On notera que toute loi de probabilité classique, donc toute distribution traditionnelle est unimodale et que donc une distribution bimodale ou pire est forcément mal prise en compte dans les modèles...
La lecture des données en R via read.table() sur notre fichier sleep.txt ne pose pas de problème particulier : il faut sauter les premières lignes qui sont des commentaires, ne lire ensuite que 62 lignes, remplacer les -999.0 par des NA, convertir les trois dernières variables en "facteurs".
Si par contre on avait voulu lire le fichier original pour sommeil animal, il aurait fallu utiliser la fonction read.fwf() plutôt que la fonction read.table() et préciser les largeurs des colonnes.
Au bout du compte, voici les données à traiter :
> print(sleep) poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation predation exposition danger African_elephant 6654.000 5712.00 NA NA 3.3 38.6 645.0 IP3 IE5 ID3 African_giant_pouched_rat 1.000 6.60 6.3 2.0 8.3 4.5 42.0 IP3 IE1 ID3 Arctic_Fox 3.385 44.50 NA NA 12.5 14.0 60.0 IP1 IE1 ID1 Arctic_ground_squirrel 0.920 5.70 NA NA 16.5 NA 25.0 IP5 IE2 ID3 Asian_elephant 2547.000 4603.00 2.1 1.8 3.9 69.0 624.0 IP3 IE5 ID4 Baboon 10.550 179.50 9.1 0.7 9.8 27.0 180.0 IP4 IE4 ID4 Big_brown_bat 0.023 0.30 15.8 3.9 19.7 19.0 35.0 IP1 IE1 ID1 Brazilian_tapir 160.000 169.00 5.2 1.0 6.2 30.4 392.0 IP4 IE5 ID4 Cat 3.300 25.60 10.9 3.6 14.5 28.0 63.0 IP1 IE2 ID1 Chimpanzee 52.160 440.00 8.3 1.4 9.7 50.0 230.0 IP1 IE1 ID1 Chinchilla 0.425 6.40 11.0 1.5 12.5 7.0 112.0 IP5 IE4 ID4 Cow 465.000 423.00 3.2 0.7 3.9 30.0 281.0 IP5 IE5 ID5 Desert_hedgehog 0.550 2.40 7.6 2.7 10.3 NA NA IP2 IE1 ID2 Donkey 187.100 419.00 NA NA 3.1 40.0 365.0 IP5 IE5 ID5 Eastern_American_mole 0.075 1.20 6.3 2.1 8.4 3.5 42.0 IP1 IE1 ID1 Echidna 3.000 25.00 8.6 0.0 8.6 50.0 28.0 IP2 IE2 ID2 European_hedgehog 0.785 3.50 6.6 4.1 10.7 6.0 42.0 IP2 IE2 ID2 Galago 0.200 5.00 9.5 1.2 10.7 10.4 120.0 IP2 IE2 ID2 Genet 1.410 17.50 4.8 1.3 6.1 34.0 NA IP1 IE2 ID1 Giant_armadillo 60.000 81.00 12.0 6.1 18.1 7.0 NA IP1 IE1 ID1 Giraffe 529.000 680.00 NA 0.3 NA 28.0 400.0 IP5 IE5 ID5 Goat 27.660 115.00 3.3 0.5 3.8 20.0 148.0 IP5 IE5 ID5 Golden_hamster 0.120 1.00 11.0 3.4 14.4 3.9 16.0 IP3 IE1 ID2 Gorilla 207.000 406.00 NA NA 12.0 39.3 252.0 IP1 IE4 ID1 Gray_seal 85.000 325.00 4.7 1.5 6.2 41.0 310.0 IP1 IE3 ID1 Gray_wolf 36.330 119.50 NA NA 13.0 16.2 63.0 IP1 IE1 ID1 Ground_squirrel 0.101 4.00 10.4 3.4 13.8 9.0 28.0 IP5 IE1 ID3 Guinea_pig 1.040 5.50 7.4 0.8 8.2 7.6 68.0 IP5 IE3 ID4 Horse 521.000 655.00 2.1 0.8 2.9 46.0 336.0 IP5 IE5 ID5 Jaguar 100.000 157.00 NA NA 10.8 22.4 100.0 IP1 IE1 ID1 Kangaroo 35.000 56.00 NA NA NA 16.3 33.0 IP3 IE5 ID4 Lesser_short-tailed_shrew 0.005 0.14 7.7 1.4 9.1 2.6 21.5 IP5 IE2 ID4 Little_brown_bat 0.010 0.25 17.9 2.0 19.9 24.0 50.0 IP1 IE1 ID1 Man 62.000 1320.00 6.1 1.9 8.0 100.0 267.0 IP1 IE1 ID1 Mole_rat 0.122 3.00 8.2 2.4 10.6 NA 30.0 IP2 IE1 ID1 Mountain_beaver 1.350 8.10 8.4 2.8 11.2 NA 45.0 IP3 IE1 ID3 Mouse 0.023 0.40 11.9 1.3 13.2 3.2 19.0 IP4 IE1 ID3 Musk_shrew 0.048 0.33 10.8 2.0 12.8 2.0 30.0 IP4 IE1 ID3 N._American_opossum 1.700 6.30 13.8 5.6 19.4 5.0 12.0 IP2 IE1 ID1 Nine-banded_armadillo 3.500 10.80 14.3 3.1 17.4 6.5 120.0 IP2 IE1 ID1 Okapi 250.000 490.00 NA 1.0 NA 23.6 440.0 IP5 IE5 ID5 Owl_monkey 0.480 15.50 15.2 1.8 17.0 12.0 140.0 IP2 IE2 ID2 Patas_monkey 10.000 115.00 10.0 0.9 10.9 20.2 170.0 IP4 IE4 ID4 Phanlanger 1.620 11.40 11.9 1.8 13.7 13.0 17.0 IP2 IE1 ID2 Pig 192.000 180.00 6.5 1.9 8.4 27.0 115.0 IP4 IE4 ID4 Rabbit 2.500 12.10 7.5 0.9 8.4 18.0 31.0 IP5 IE5 ID5 Raccoon 4.288 39.20 NA NA 12.5 13.7 63.0 IP2 IE2 ID2 Rat 0.280 1.90 10.6 2.6 13.2 4.7 21.0 IP3 IE1 ID3 Red_fox 4.235 50.40 7.4 2.4 9.8 9.8 52.0 IP1 IE1 ID1 Rhesus_monkey 6.800 179.00 8.4 1.2 9.6 29.0 164.0 IP2 IE3 ID2 Rock_hyrax_(Hetero._b) 0.750 12.30 5.7 0.9 6.6 7.0 225.0 IP2 IE2 ID2 Rock_hyrax_(Procavia_hab) 3.600 21.00 4.9 0.5 5.4 6.0 225.0 IP3 IE2 ID3 Roe_deer 14.830 98.20 NA NA 2.6 17.0 150.0 IP5 IE5 ID5 Sheep 55.500 175.00 3.2 0.6 3.8 20.0 151.0 IP5 IE5 ID5 Slow_loris 1.400 12.50 NA NA 11.0 12.7 90.0 IP2 IE2 ID2 Star_nosed_mole 0.060 1.00 8.1 2.2 10.3 3.5 NA IP3 IE1 ID2 Tenrec 0.900 2.60 11.0 2.3 13.3 4.5 60.0 IP2 IE1 ID2 Tree_hyrax 2.000 12.30 4.9 0.5 5.4 7.5 200.0 IP3 IE1 ID3 Tree_shrew 0.104 2.50 13.2 2.6 15.8 2.3 46.0 IP3 IE2 ID2 Vervet 4.190 58.00 9.7 0.6 10.3 24.0 210.0 IP4 IE3 ID4 Water_opossum 3.500 3.90 12.8 6.6 19.4 3.0 14.0 IP2 IE1 ID1 Yellow-bellied_marmot 4.050 17.00 NA NA NA 13.0 38.0 IP3 IE1 ID1Code R pour l'analyse des variables qualitatives :
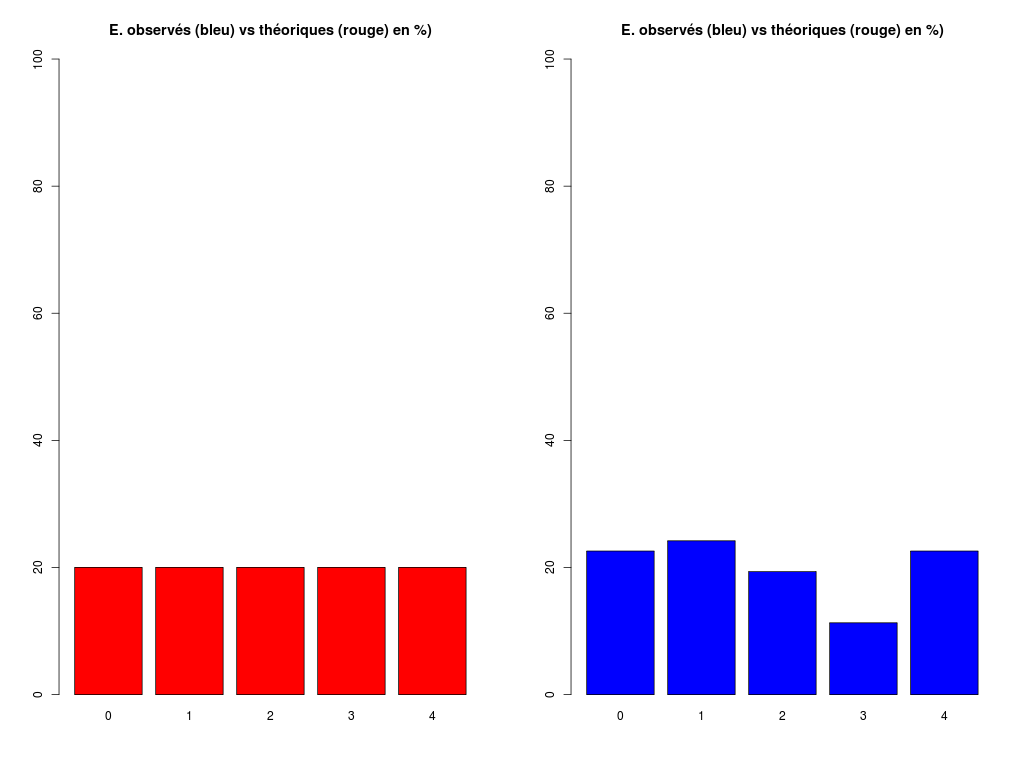
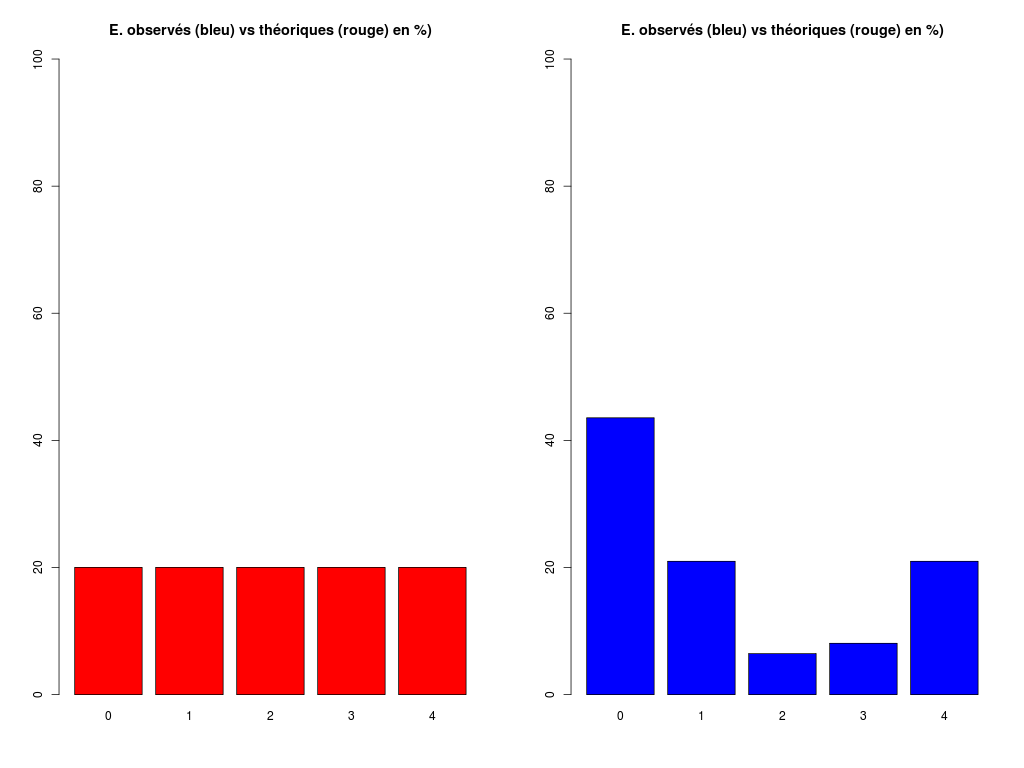
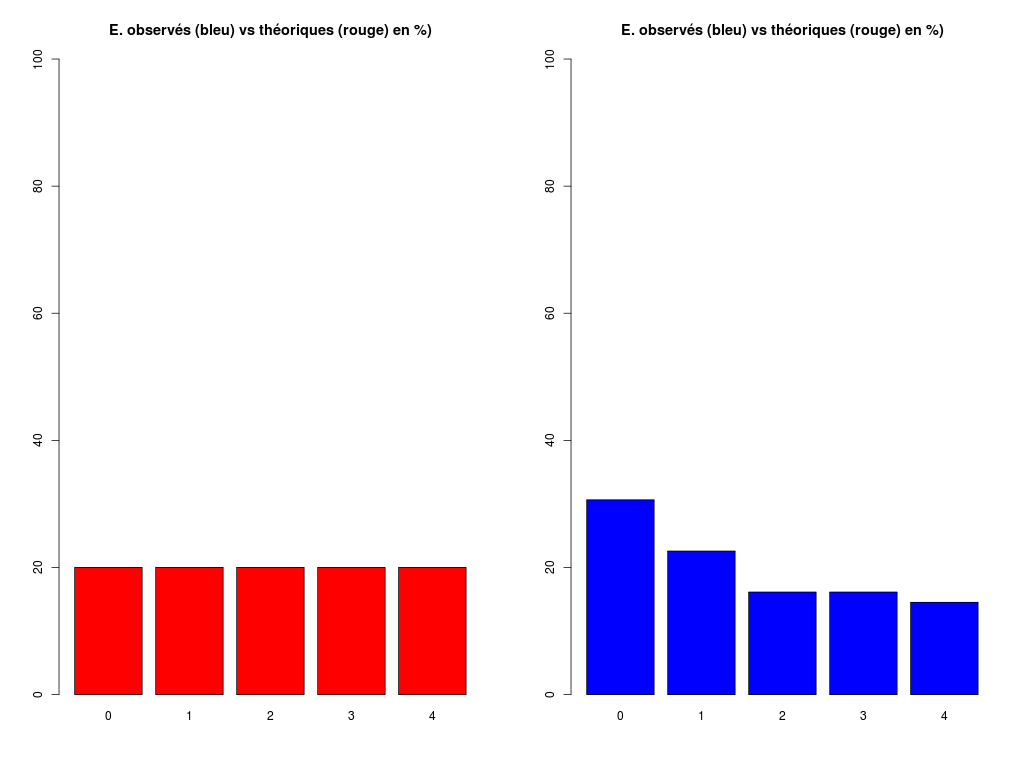
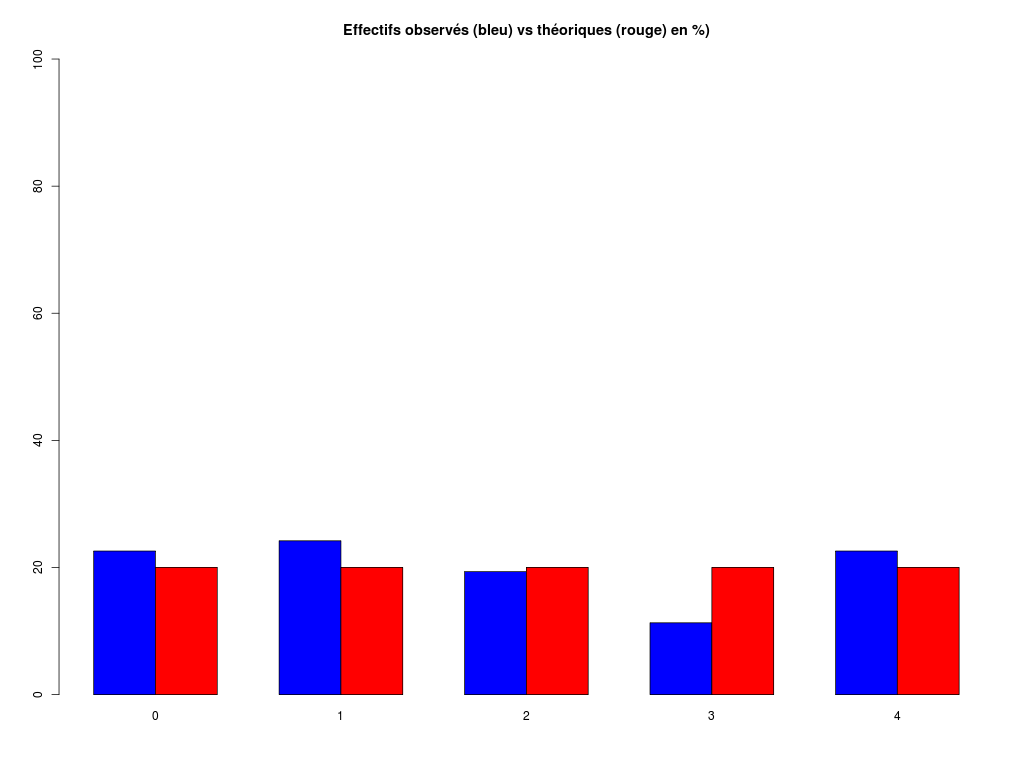
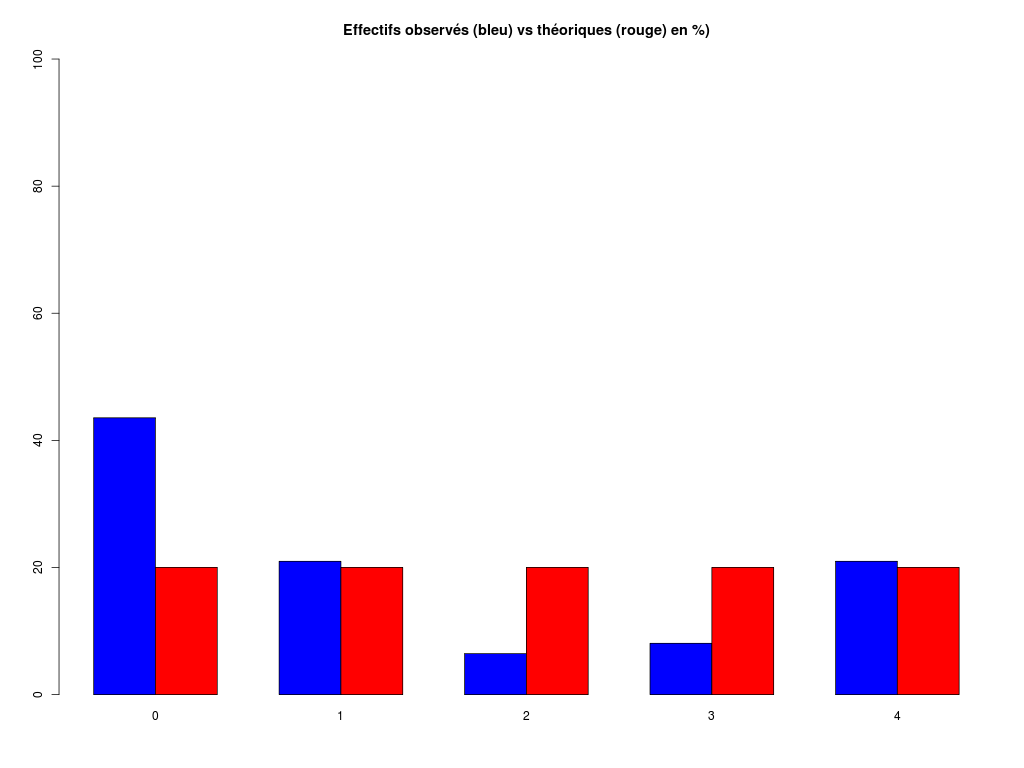
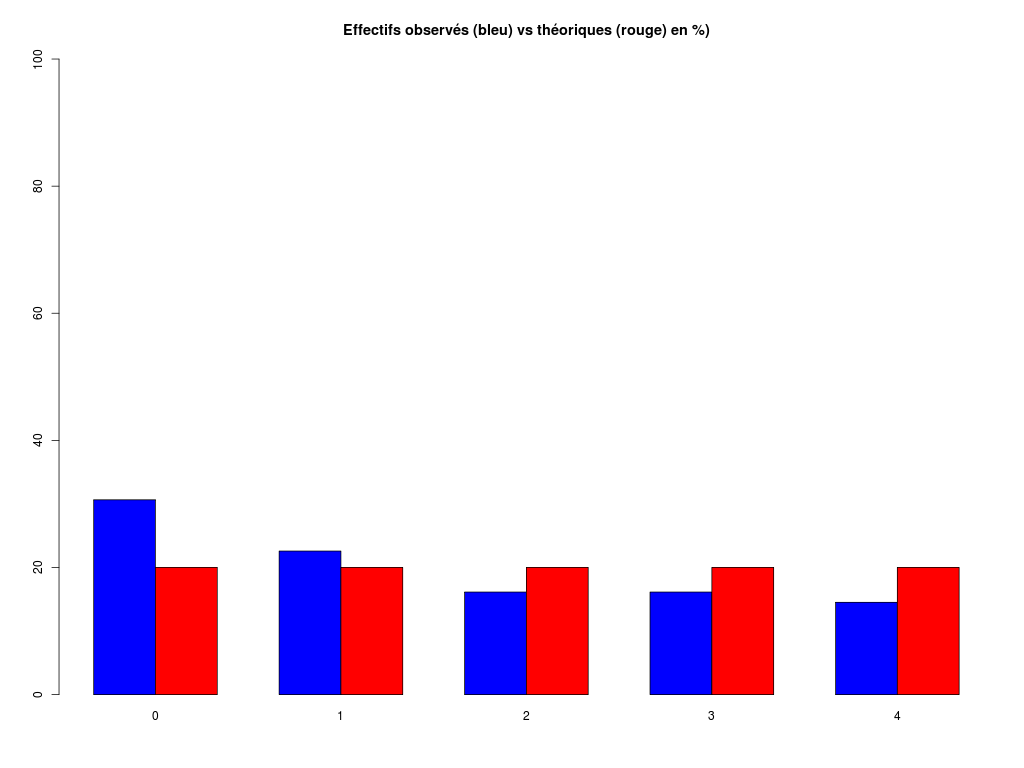
# analyse rapide des variables qualitatives # predation, exposition, danger # des données sleep decritQLf(titreQL="predation", nomFact=sleep$predation, graphique=TRUE, fichier_image="predation.png", testequi=TRUE ) # fin decritQLf decritQLf(titreQL="exposition", nomFact=sleep$exposition, graphique=TRUE, fichier_image="exposition.png", testequi=TRUE ) # fin decritQLf decritQLf(titreQL="danger", nomFact=sleep$danger, graphique=TRUE, fichier_image="danger.png", testequi=TRUE ) # fin decritQLfTRI A PLAT DE : predation (ordre des modalités) IP1 IP2 IP3 IP4 IP5 Total Effectif 14 15 12 7 14 62 Cumul Effectif 14 29 41 48 62 62 Frequence (en %) 23 24 19 11 23 100 Cumul fréquences 23 47 66 77 100 100 VARIABLE : predation (par fréquence décroissante) IP2 IP1 IP5 IP3 IP4 Total Effectif 15 14 14 12 7 62 Cumul Effectif 14 29 41 48 62 62 Frequence (en %) 24 23 23 19 11 100 Cumul fréquences 24 47 69 89 100 100 CALCUL DU CHI-DEUX D'ADEQUATION Valeurs théoriques 12.4 12.4 12.4 12.4 12.4 Valeurs observées 14 15 12 7 14 Valeur du chi-deux 3.322581 Chi-deux max (table) à 5 % 9.487729 pour 4 degrés de liberté ; p-value 0.5053625 décision : au seuil de 5 % on ne peut pas rejeter l'hypothèse que les données observées correspondent aux valeurs théoriques. Contributions au chi-deux Ind. The Obs Dif Cntr Pct Cumul 1 12.4 14 -1.6 0.20645161 6.2135922 0.2064516 2 12.4 15 -2.6 0.54516129 16.4077670 0.7516129 3 12.4 12 0.4 0.01290323 0.3883495 0.7645161 4 12.4 7 5.4 2.35161290 70.7766990 3.1161290 5 12.4 14 -1.6 0.20645161 6.2135922 3.3225806 TRI A PLAT DE : exposition (ordre des modalités) IE1 IE2 IE3 IE4 IE5 Total Effectif 27 13 4 5 13 62 Cumul Effectif 27 40 44 49 62 62 Frequence (en %) 44 21 6 8 21 100 Cumul fréquences 44 65 71 79 100 100 VARIABLE : exposition (par fréquence décroissante) IE1 IE2 IE5 IE4 IE3 Total Effectif 27 13 13 5 4 62 Cumul Effectif 27 40 44 49 62 62 Frequence (en %) 44 21 21 8 6 100 Cumul fréquences 44 65 85 94 100 100 CALCUL DU CHI-DEUX D'ADEQUATION Valeurs théoriques 12.4 12.4 12.4 12.4 12.4 Valeurs observées 27 13 4 5 13 Valeur du chi-deux 27.35484 Chi-deux max (table) à 5 % 9.487729 pour 4 degrés de liberté ; p-value 1.685086e-05 décision : au seuil de 5 % on peut rejeter l'hypothèse que les données observées correspondent aux valeurs théoriques. Contributions au chi-deux Ind. The Obs Dif Cntr Pct Cumul 1 12.4 27 -14.6 17.19032258 62.8419811 17.19032 2 12.4 13 -0.6 0.02903226 0.1061321 17.21935 3 12.4 4 8.4 5.69032258 20.8018868 22.90968 4 12.4 5 7.4 4.41612903 16.1438679 27.32581 5 12.4 13 -0.6 0.02903226 0.1061321 27.35484 TRI A PLAT DE : danger (ordre des modalités) ID1 ID2 ID3 ID4 ID5 Total Effectif 19 14 10 10 9 62 Cumul Effectif 19 33 43 53 62 62 Frequence (en %) 31 23 16 16 15 101 Cumul fréquences 31 53 69 85 100 101 VARIABLE : danger (par fréquence décroissante) ID1 ID2 ID3 ID4 ID5 Total Effectif 19 14 10 10 9 62 Cumul Effectif 19 33 43 53 62 62 Frequence (en %) 31 23 16 16 15 101 Cumul fréquences 31 53 69 85 100 101 CALCUL DU CHI-DEUX D'ADEQUATION Valeurs théoriques 12.4 12.4 12.4 12.4 12.4 Valeurs observées 19 14 10 10 9 Valeur du chi-deux 5.580645 Chi-deux max (table) à 5 % 9.487729 pour 4 degrés de liberté ; p-value 0.2327311 décision : au seuil de 5 % on ne peut pas rejeter l'hypothèse que les données observées correspondent aux valeurs théoriques. Contributions au chi-deux Ind. The Obs Dif Cntr Pct Cumul 1 12.4 19 -6.6 3.5129032 62.947977 3.512903 2 12.4 14 -1.6 0.2064516 3.699422 3.719355 3 12.4 10 2.4 0.4645161 8.323699 4.183871 4 12.4 10 2.4 0.4645161 8.323699 4.648387 5 12.4 9 3.4 0.9322581 16.705202 5.580645Pour celles et ceux qui savent programmer en R :
# analyse des variables qualitatives du dossier sleep_animal (df=sleep) varql <- c("predation","exposition","danger") # équivalent mais moins "parlant" : varql <- colnames(sleep)[8:10] for (iql in varql) { fgr <- paste(iql,".png",sep="") decritQLf(titreQL=iql, nomFact=sleep[,iql], graphique=TRUE, fichier_image=fgr, testequi=TRUE ) # fin decritQLf } # fin pour iqlL'analyse des résultats (fichier sleep2ql.res) montre que seules les variables predation et danger peuvent être considérées comme équi-distribuées. La variable exposition, par contre, a une répartition hétérogène, avec un effectif 27 très élevé, et deux effectifs 4 et 5 très faibles, respectivement pour les indices de danger IE1, IE3 et IE4, ce qui n'était pas forcément flagrant au vu de tous les graphiques.
Code R pour l'analyse des variables quantitatives :
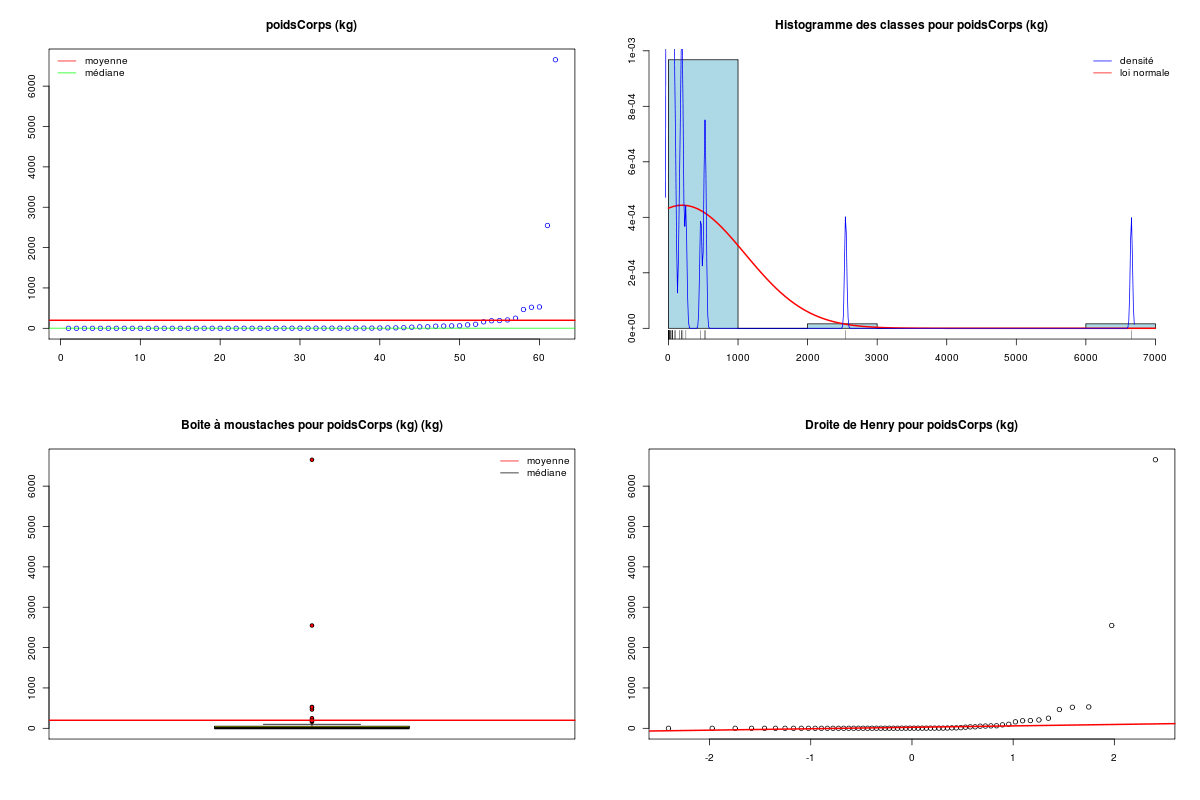
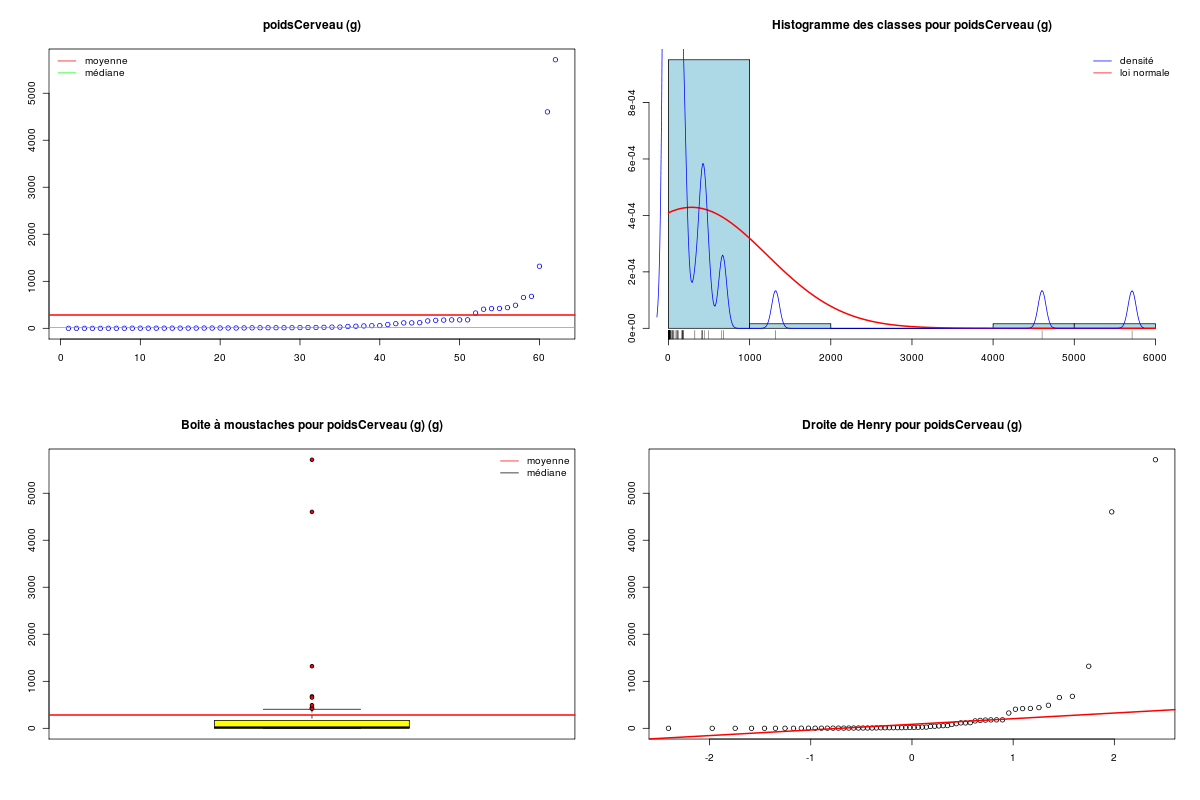
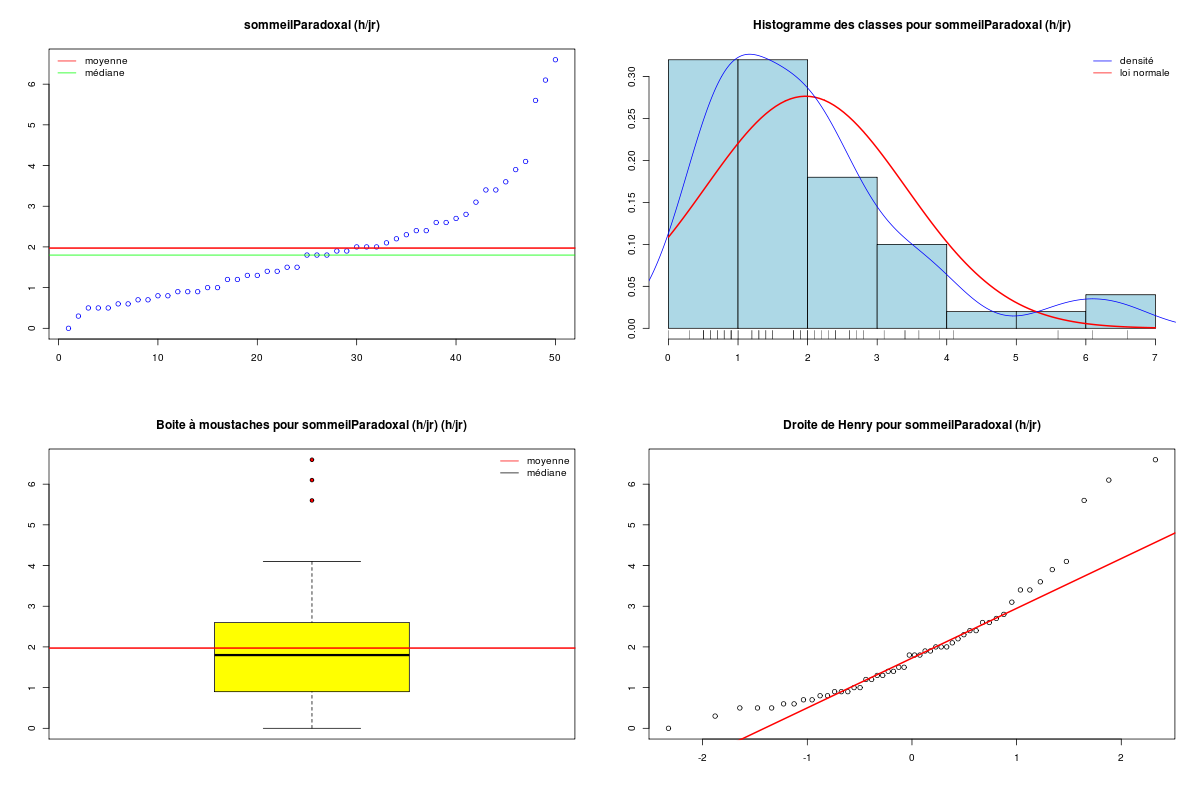
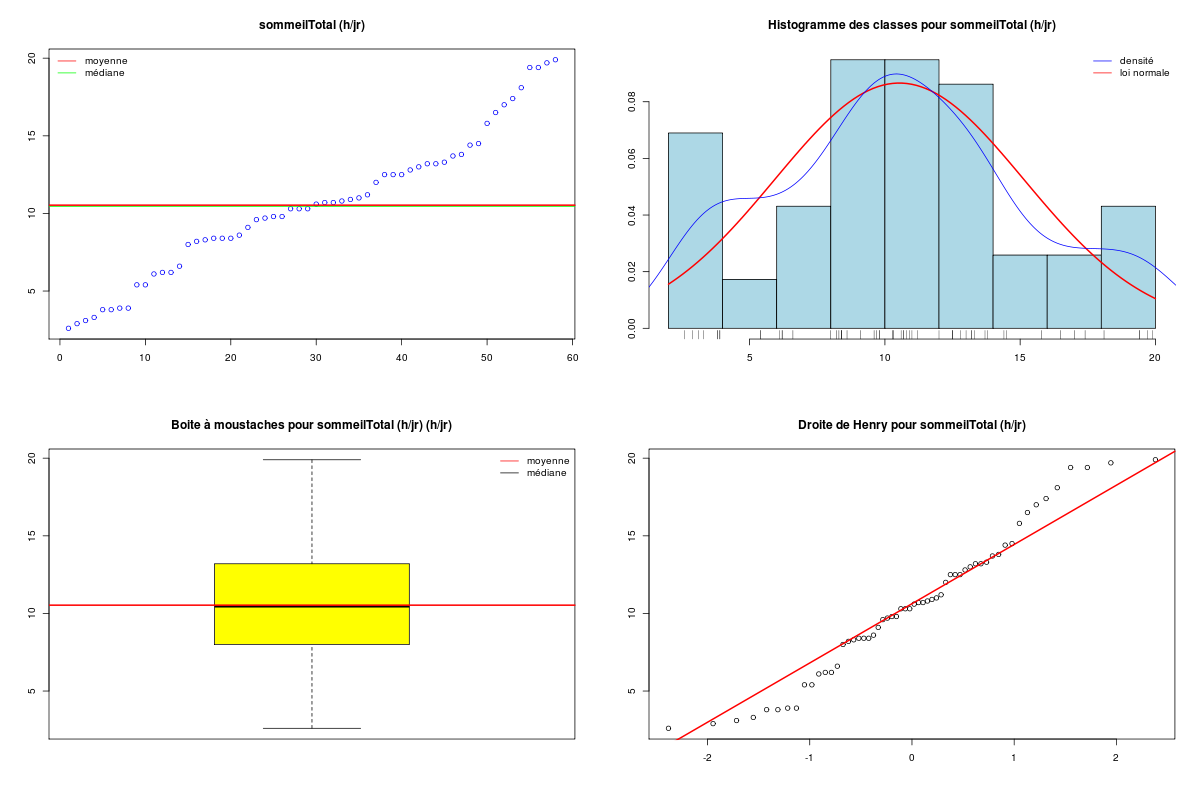
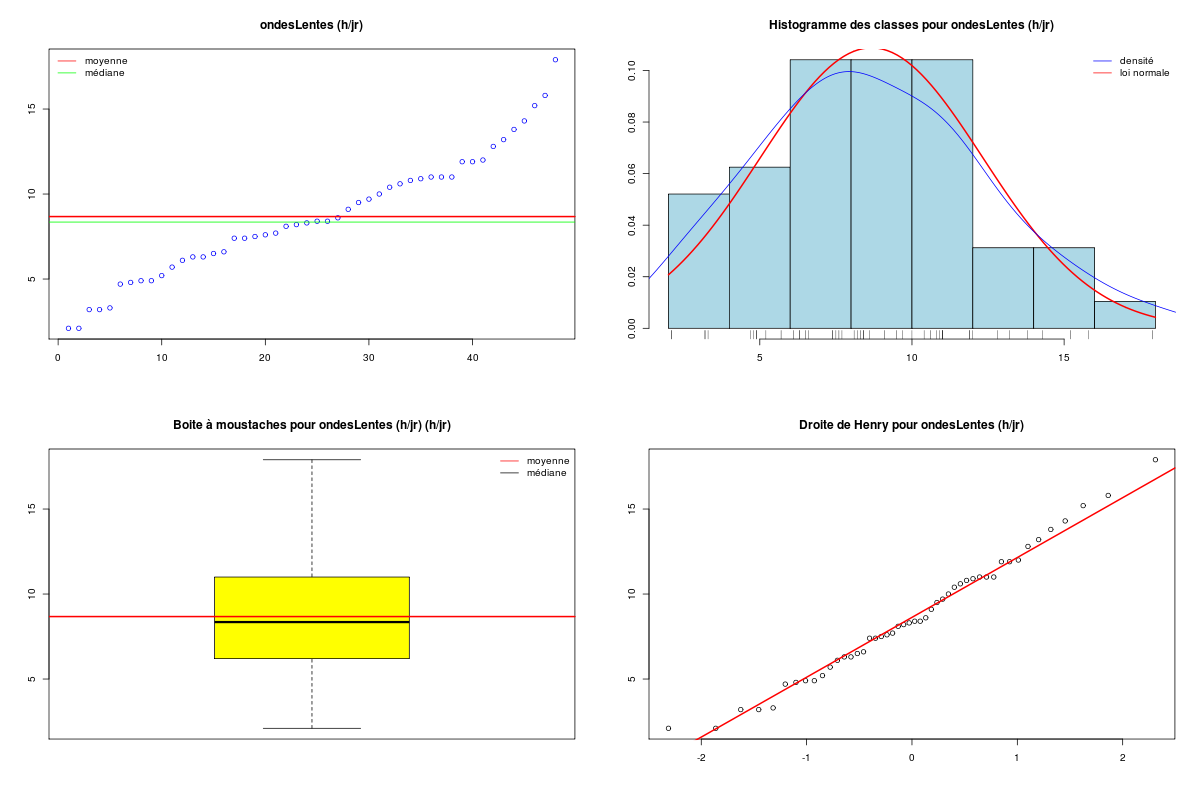
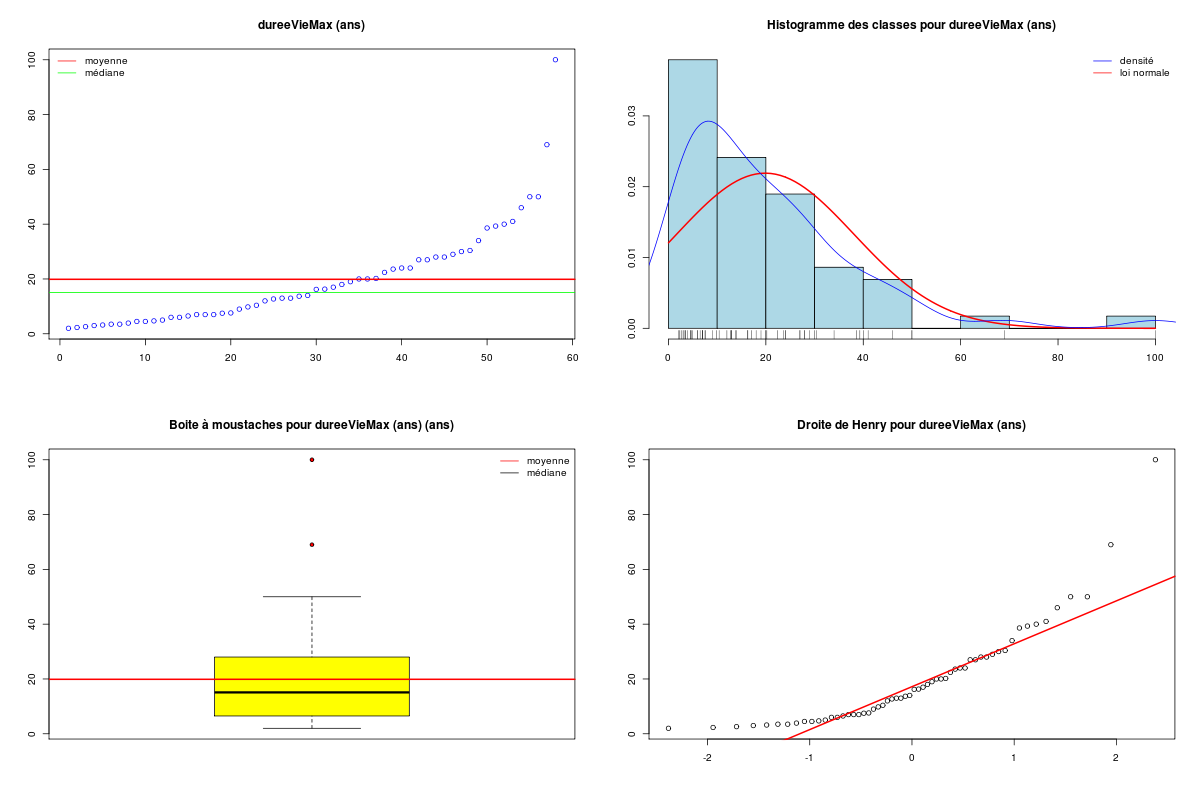
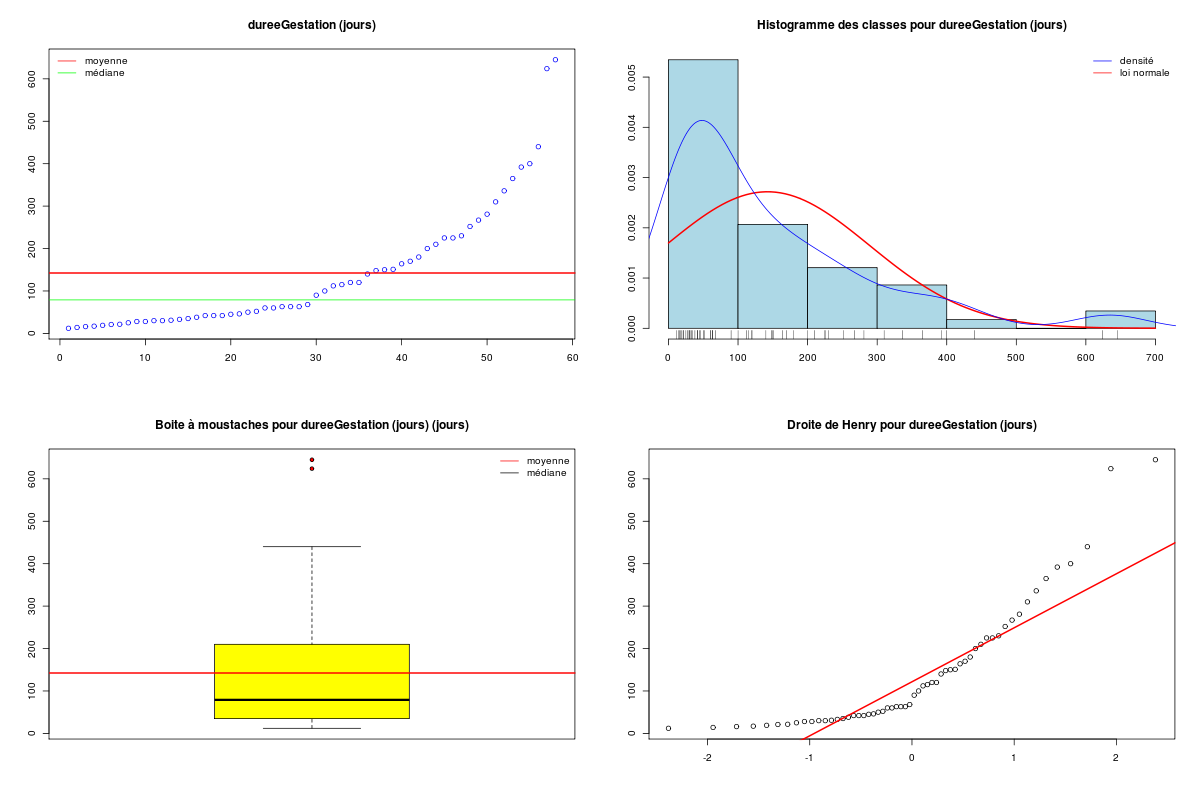
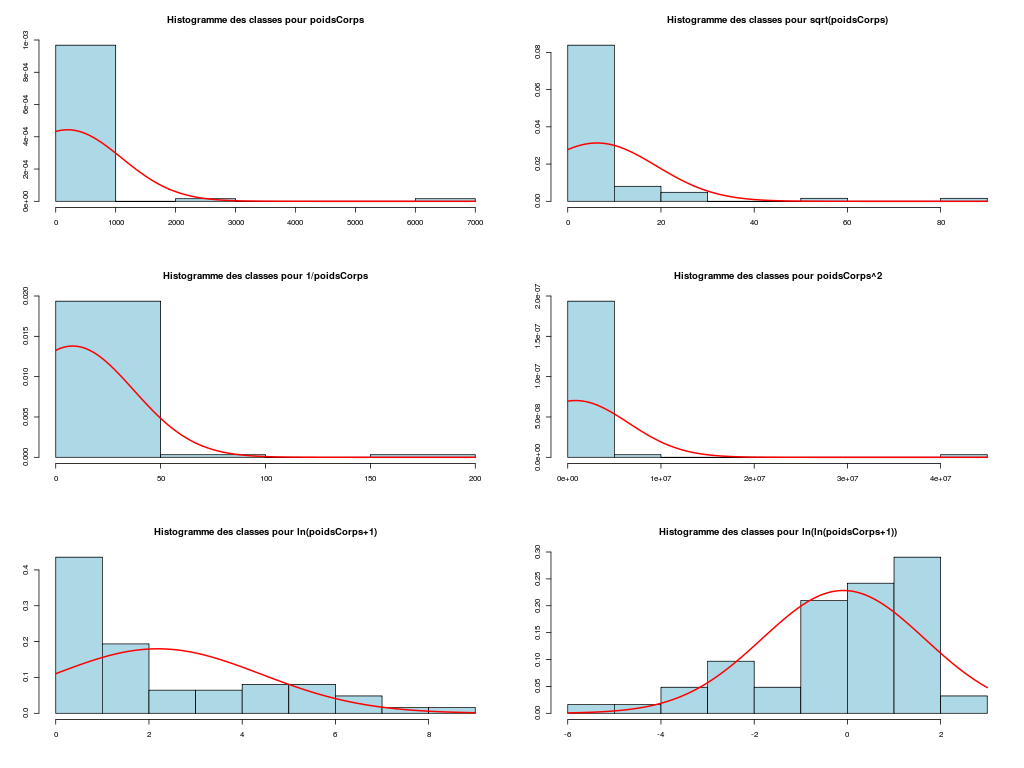
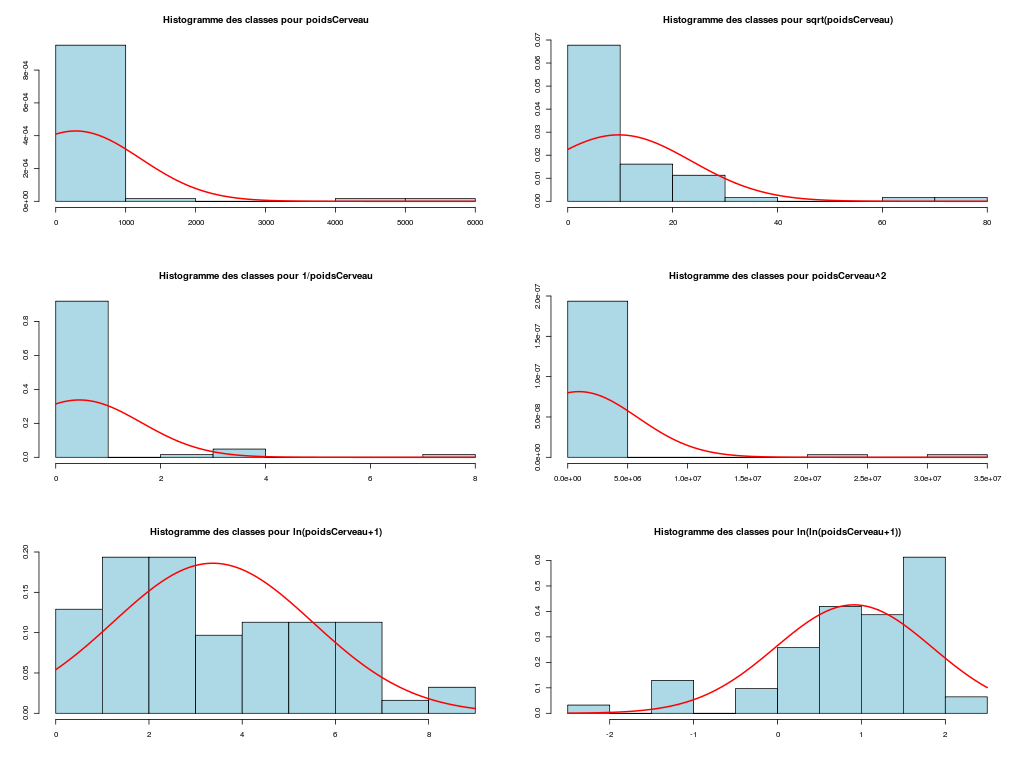
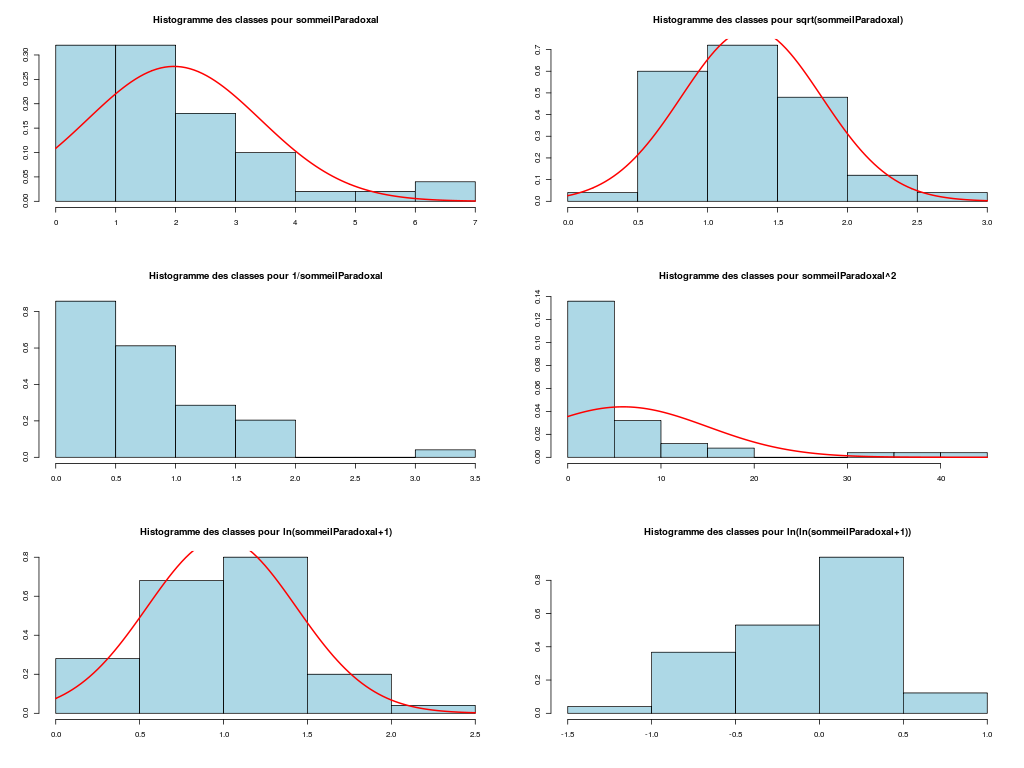
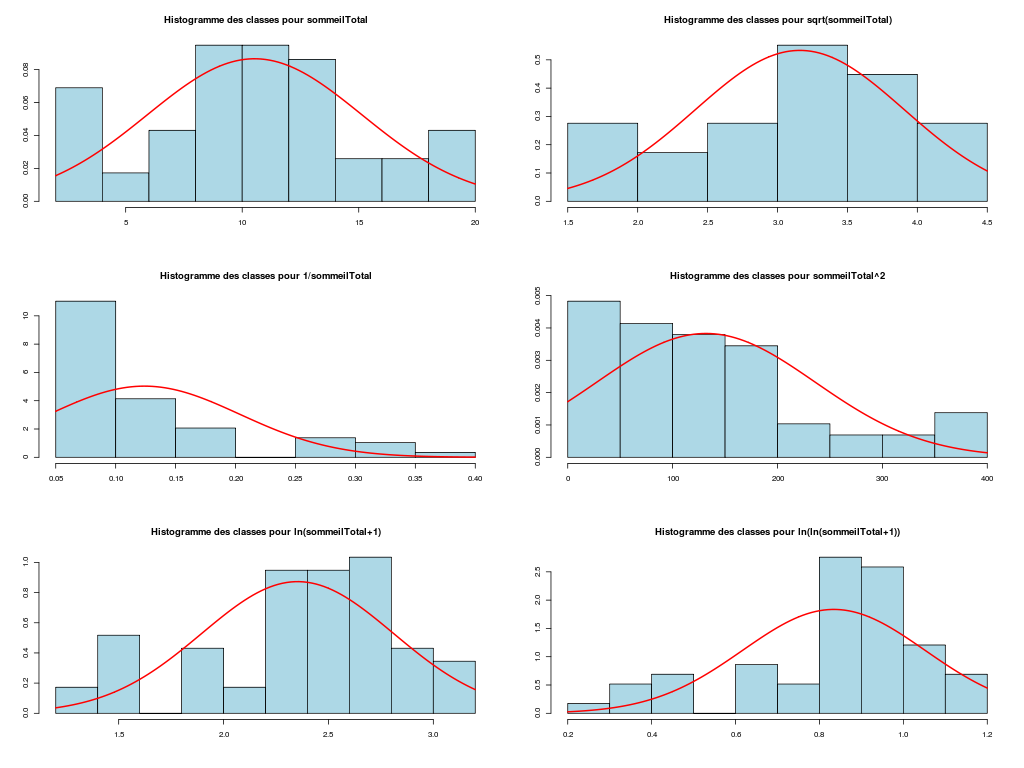
# analyse des variables quantitatives du dossier sleep_animal (df=sleep) # commençons par stocker les unités pour les variables unites <- c("kg","g","h/jr","h/jr","h/jr","ans","jours") names(unites) <- names(sleep)[1:length(unites)] for (iqt in names(unites)) { fgr <- paste(iqt,".png",sep="") decritQT(titreQT=iqt, nomVar=sleep[,iqt], unite=unites[iqt], graphique=TRUE, fichier_image=fgr ) # fin de decritQT } # fin pour iqtDESCRIPTION STATISTIQUE DE LA VARIABLE poidsCorps Taille 62 individus Moyenne 198.7900 kg Ecart-type 891.8773 kg Coef. de variation 449 % 1er Quartile 0.6000 kg Mediane 3.3425 kg 3eme Quartile 48.2025 kg iqr absolu 47.6025 kg iqr relatif 1424.0000 % Minimum 0 kg Maximum 6654 kg Tracé tige et feuilles The decimal point is 3 digit(s) to the right of the | 0 | 000000000000000000000000000000000000000000000011111122223555 1 | 2 | 5 3 | 4 | 5 | 6 | 7 DESCRIPTION STATISTIQUE DE LA VARIABLE poidsCerveau Taille 62 individus Moyenne 283.1342 g Ecart-type 922.7462 g Coef. de variation 326 % 1er Quartile 4.2500 g Mediane 17.2500 g 3eme Quartile 166.0000 g iqr absolu 161.7500 g iqr relatif 938.0000 % Minimum 0 g Maximum 5712 g Tracé tige et feuilles The decimal point is 3 digit(s) to the right of the | 0 | 00000000000000000000000000000000000001111111122222234444577 1 | 3 2 | 3 | 4 | 6 5 | 7 DESCRIPTION STATISTIQUE DE LA VARIABLE ondesLentes Taille 48 individus Moyenne 8.6729 h/jr Ecart-type 3.6281 h/jr Coef. de variation 42 % 1er Quartile 6.2500 h/jr Mediane 8.3500 h/jr 3eme Quartile 11.0000 h/jr iqr absolu 4.7500 h/jr iqr relatif 57.0000 % Minimum 2 h/jr Maximum 18 h/jr Tracé tige et feuilles The decimal point is at the | 2 | 11223 4 | 789927 6 | 1335644567 8 | 123446157 10 | 0468900099 12 | 0828 14 | 328 16 | 9 DESCRIPTION STATISTIQUE DE LA VARIABLE sommeilParadoxal Taille 50 individus Moyenne 1.9720 h/jr Ecart-type 1.4282 h/jr Coef. de variation 72 % 1er Quartile 0.9000 h/jr Mediane 1.8000 h/jr 3eme Quartile 2.5500 h/jr iqr absolu 1.6500 h/jr iqr relatif 92.0000 % Minimum 0 h/jr Maximum 7 h/jr Tracé tige et feuilles The decimal point is at the | 0 | 03555667788999 1 | 002233445588899 2 | 000123446678 3 | 14469 4 | 1 5 | 6 6 | 16 DESCRIPTION STATISTIQUE DE LA VARIABLE sommeilTotal Taille 58 individus Moyenne 10.5328 h/jr Ecart-type 4.5669 h/jr Coef. de variation 43 % 1er Quartile 8.0500 h/jr Mediane 10.4500 h/jr 3eme Quartile 13.2000 h/jr iqr absolu 5.1500 h/jr iqr relatif 49.0000 % Minimum 3 h/jr Maximum 20 h/jr Tracé tige et feuilles The decimal point is at the | 2 | 69138899 4 | 44 6 | 1226 8 | 023444616788 10 | 3336778902 12 | 05558022378 14 | 458 16 | 504 18 | 14479 DESCRIPTION STATISTIQUE DE LA VARIABLE dureeVieMax Taille 58 individus Moyenne 19.8776 ans Ecart-type 18.0486 ans Coef. de variation 91 % 1er Quartile 6.6250 ans Mediane 15.1000 ans 3eme Quartile 27.7500 ans iqr absolu 21.1250 ans iqr relatif 140.0000 % Minimum 2 ans Maximum 100 ans Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 0 | 223334445555667777889 1 | 0023334466789 2 | 000244477889 3 | 00499 4 | 016 5 | 00 6 | 9 7 | 8 | 9 | 10 | 0 DESCRIPTION STATISTIQUE DE LA VARIABLE dureeGestation Taille 58 individus Moyenne 142.3534 jours Ecart-type 145.5340 jours Coef. de variation 102 % 1er Quartile 35.7500 jours Mediane 79.0000 jours 3eme Quartile 207.5000 jours iqr absolu 171.7500 jours iqr relatif 217.0000 % Minimum 12 jours Maximum 645 jours Tracé tige et feuilles The decimal point is 2 digit(s) to the right of the | 0 | 112222233333334444455556666679 1 | 012224555678 2 | 01333578 3 | 1479 4 | 04 5 | 6 | 25Voici les graphiques associés :
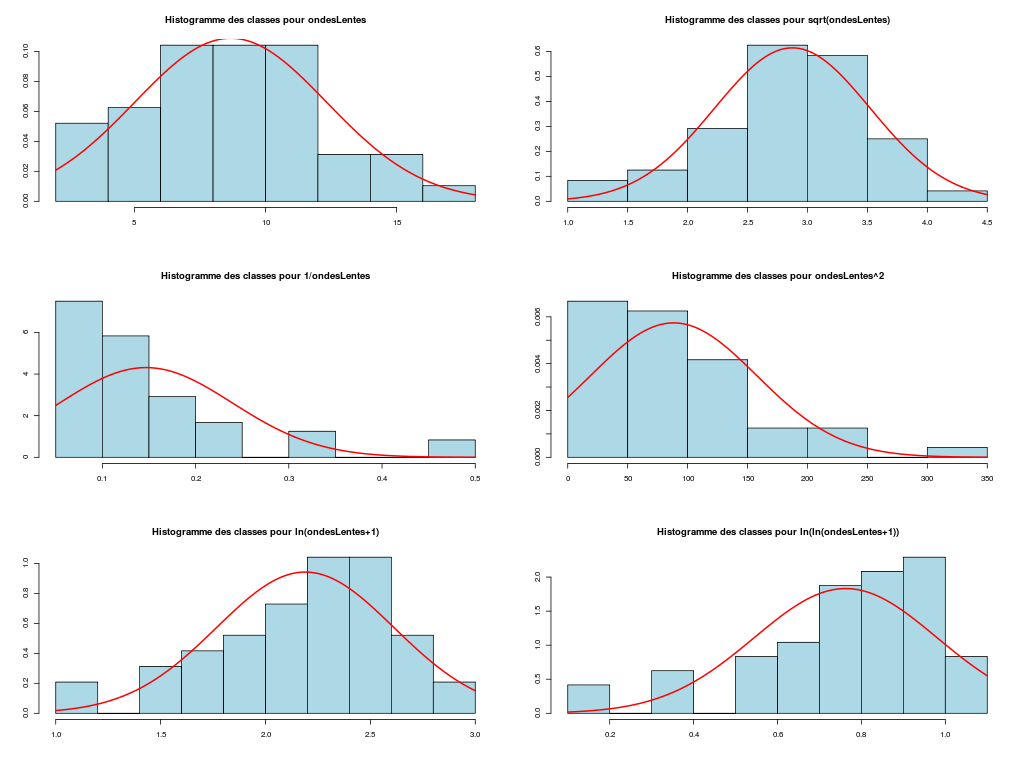
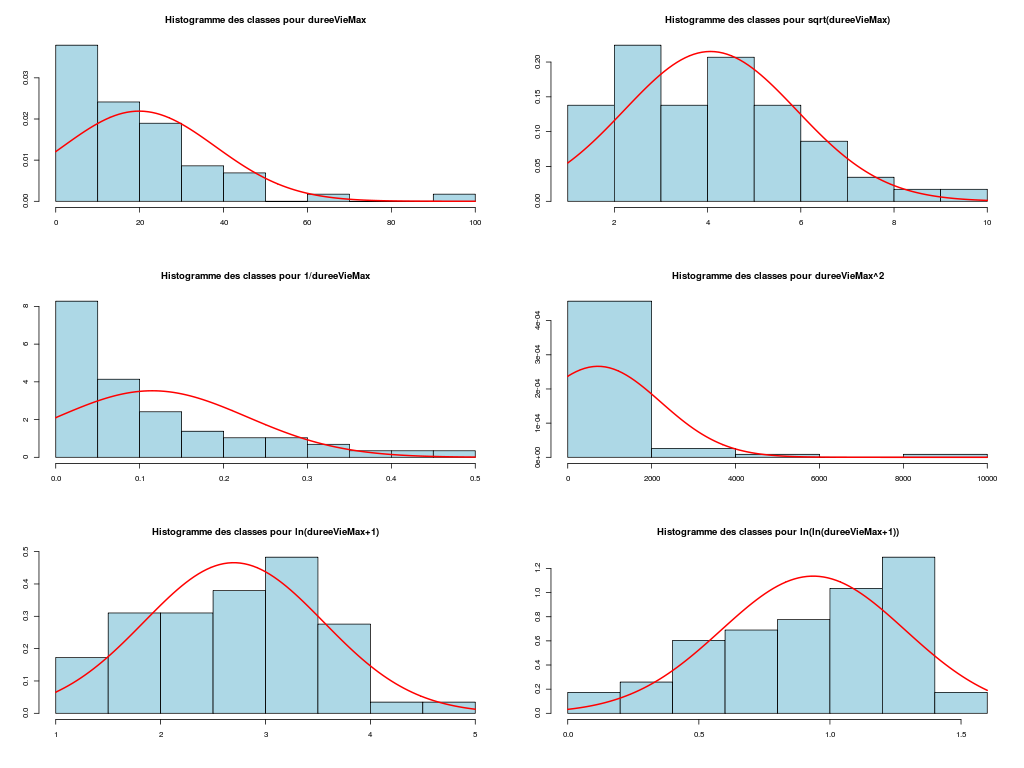
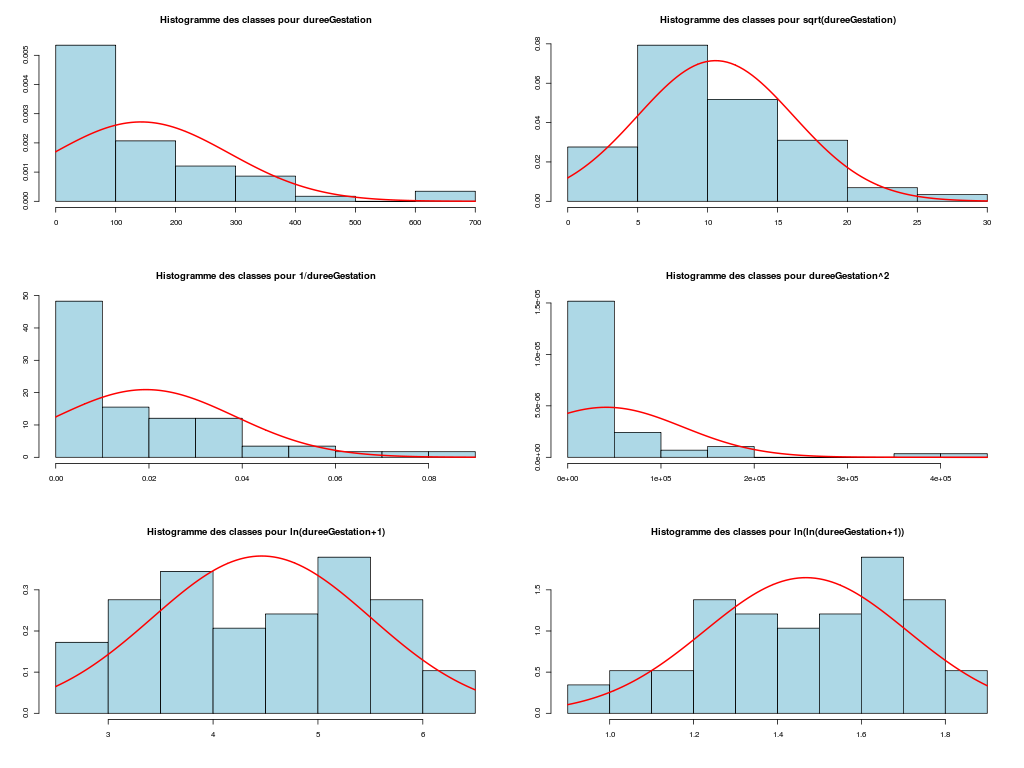
Il est clair qu'au vu de ces graphiques, les variables poidsCorps, poidsCerveau, dureeVieMax et dureeGestation sont non symétriques, avec plus de valeurs faibles que de valeurs importantes (moyenne et médianes très différentes, troisième quartile très éloigné de la médiane...). Leur distribution n'est donc sans doute pas normale. Par contre, les variables ondesLentes, sommeilParadoxal et sommeilTotal semblent un peu plus symétriques. Seule la distribution de la variable ondesLentes semble normale au vu de la droite de Henry. On pouvait s'attendre à ce genre de distribution dans la mesure où les données sont constituées d'espèces différentes et non pas d'individus de la même espèce.
Voici, après réflexion, le code R pour lire les données, via read.table() ou read.fwf() suivant le fichier de données utilisé :
# (gH) -_- sleep1.r ; TimeStamp (unix) : 10 Décembre 2013 vers 13:47 # lecture des données dans sleep.txt : # il y a 50 lignes de commentaires puis 62 lignes de données # de "African elephant" à "Yellow-bellied marmot" sleep <- read.table("http://forge.info.univ-angers.fr/~gh/wstat/Eda/sleep.txt", row.names=1,header=FALSE,skip=50,nrows=62,blank.lines.skip=FALSE) colnames(sleep) <- c( "poidsCorps", "poidsCerveau", "ondesLentes", "sommeilParadoxal", "sommeilTotal", "dureeVieMax", "dureeGestation", "predation", "exposition", "danger" ) # fin de c # il faut remplacer les -999.0 par des NA (non disponible) sleep[ sleep==-999.0 ] <- NA # il faut indiquer que predation, exposition et danger sont des # variables qualitatives ordinales sleep$predation <- factor(sleep$predation, levels=1:5, ordered=TRUE, labels=paste("IP",1:5,sep="") ) # fn de factor sleep$exposition <- factor(sleep$exposition, levels=1:5, ordered=TRUE, labels=paste("IE",1:5,sep="") ) # fn de factor sleep$danger <- factor(sleep$danger, levels=1:5, ordered=TRUE, labels=paste("ID",1:5,sep="") ) # fn de factor print(sleep)# (gH) -_- sleep1fwf.r ; TimeStamp (unix) : 10 Décembre 2013 vers 14:17 # lecture des données dans ib.stat.cmu.edu/datasets/sleep # il y a 50 lignes de commentaires puis 62 lignes de données # de "African elephant" à "Yellow-bellied marmot" # il y a des mots séparés donc il faut utiliser des formats de longueur fixe sleep <- read.fwf("http://lib.stat.cmu.edu/datasets/sleep", header=FALSE,skip=50,nrows=62,blank.lines.skip=FALSE, width=c(25,8,9,rep(8,8)) ) # fin de read colnames(sleep) <- c( "espece", "poidsCorps", "poidsCerveau", "ondesLentes", "sommeilParadoxal", "sommeilTotal", "dureeVieMax", "dureeGestation", "predation", "exposition", "danger" ) # fin de c # on met espéce comme identifiant de ligne row.names(sleep) <- sleep[,1] sleep <- sleep[,-1] # il faut remplacer les -999.0 par des NA (non disponible) sleep[ sleep==-999.0 ] <- NA # il faut indiquer que predation, exposition et danger sont des # variables qualitatives ordinales sleep$predation <- factor(sleep$predation, levels=1:5, ordered=TRUE, labels=paste("IP",1:5,sep="") ) # fn de factor sleep$exposition <- factor(sleep$exposition, levels=1:5, ordered=TRUE, labels=paste("IE",1:5,sep="") ) # fn de factor sleep$danger <- factor(sleep$danger, levels=1:5, ordered=TRUE, labels=paste("ID",1:5,sep="") ) # fn de factor print(sleep)Il y a quelques transformations mathématiques usuelles dont le but est de rendre les distributions normales, symétriques, "normalisées"... dont les plus classiques sont les fonctions carré, logarithme, racine... Plus généralement, on utilise la transformation de Box-Cox pour Y et celle de Box-Tidwell pour les Xi qu'on nomme aussi transformation puissance même si certains auteurs dont Kuhn et Johnson conseillent d'utiliser systématiquement la transformation de Box-Cox pour toutes les variables. Aucun de ces fonctions n'est en corrélation linéaire parfaite avec la variable originale.
Par définition, une variable centrée est de moyenne nulle. Centrer la variable X, c'est passer de X à X-moy(X), qui est en corrélation parfaite avec X. Par définition, une variable réduite est d'écart-type égal à un. Réduire la variable X, c'est passer de X à X/ect(X), qui est en corrélation parfaite avec X. Pour obtenir une variable centrée réduite à partir de X, il faut utiliser (X-moy(X))/ect(X) et non X/ect(X)-moy(X). On obtient alors encore une variable en corrélation parfaite avec X. Voici le code des fonctions R possibles pour implémenter ces transformations :
# "centrage" d'une variable centrerVar <- function(x) { moy <- mean(x) varCentree <- x - moy return( varCentree ) } # fin de fonction centrerVar ######################################### # "réduction" d'une variable reduireVar <- function(x) { ect <- sd(x) varReduite <- x/ect return( varReduite ) } # fin de fonction reduireVar ######################################### # centrer et réduire : raté ! cr0 <- function(x) { moy <- mean(x) ect <- sd(x) cr <- x/ect-moy return( cr ) } # fin de fonction cr0 ######################################### # centrer et réduire : réussi ! cr1 <- function(x) { moy <- mean(x) ect <- sd(x) cr <- (x-moy)/ect return( cr ) } # fin de fonction cr1 cr2 <- function(x) { return( reduireVar(centrerVar(x)) ) } # fin de fonction cr2 cr3 <- function(x) { return( centrerVar(reduireVar(x)) ) } # fin de fonction cr3 ######################################### # vérification set.seed(1234) # tirage pseudo-aléatoire reproductible (!) x <- runif(10) print(x) print( mean(x) ) print( mean(centrerVar(x)) ) print( sd(x) ) print( sd(reduireVar(x)) ) print( c(mean(x),sd(x)) ) y0 <- cr0(x) print( c(mean(y0),sd(y0)) ) y1 <- cr1(x) print( c(mean(y1),sd(y1)) ) y2 <- cr2(x) print( c(mean(y2),sd(y2)) ) y3 <- cr3(x) print( c(mean(y3),sd(y3)) ) # on pouvait se dispenser d'écrire ces fonctions # car il existe la fonction scale : sum( centrerVar(x) - scale(x,center=TRUE, scale=FALSE) ) sum( reduireVar(x) - scale(x,center=FALSE,scale=TRUE ) ) sum( y0 - scale(x,center=TRUE, scale=TRUE ) ) sum( y1 - scale(x,center=TRUE, scale=TRUE ) ) sum( y2 - scale(x,center=TRUE, scale=TRUE ) ) sum( y3 - scale(x,center=TRUE, scale=TRUE ) )> # "centrage" d'une variable .... [TRUNCATED] > ######################################### > > # vérification > > set.seed(1234) # tirage pseudo-aléatoire reproductible (!) > x <- runif(10) > print(x) [1] 0.113703411 0.622299405 0.609274733 0.623379442 0.860915384 0.640310605 0.009495756 0.232550506 0.666083758 0.514251141 > print( mean(x) ) [1] 0.4892264 > print( mean(centrerVar(x)) ) [1] 2.220937e-17 > print( sd(x) ) [1] 0.2748823 > print( sd(reduireVar(x)) ) [1] 1 > print( c(mean(x),sd(x)) ) [1] 0.4892264 0.2748823 > y0 <- cr0(x) > print( c(mean(y0),sd(y0)) ) [1] 1.29054 1.00000 > y1 <- cr1(x) > print( c(mean(y1),sd(y1)) ) [1] 7.355905e-17 1.000000e+00 > y2 <- cr2(x) > print( c(mean(y2),sd(y2)) ) [1] 7.355905e-17 1.000000e+00 > y3 <- cr3(x) > print( c(mean(y3),sd(y3)) ) [1] 0 1 > # on pouvait se dispenser d'écrire ces fonctions > # car il existe la fonction scale : > > sum( centrerVar(x) - scale(x,center=TRUE, scale=FALSE) ) [1] 0 > sum( reduireVar(x) - scale(x,center=FALSE,scale=TRUE ) ) [1] 9.425908 > sum( y0 - scale(x,center=TRUE, scale=TRUE ) ) [1] 12.9054 > sum( y1 - scale(x,center=TRUE, scale=TRUE ) ) [1] 0 > sum( y2 - scale(x,center=TRUE, scale=TRUE ) ) [1] 0 > sum( y3 - scale(x,center=TRUE, scale=TRUE ) ) [1] -7.355228e-16Pour appliquer ces fonctions aux colonnes d'un data frame, il suffit d'utiliser apply() du package base aux variables quantitatives du data frame sleep :
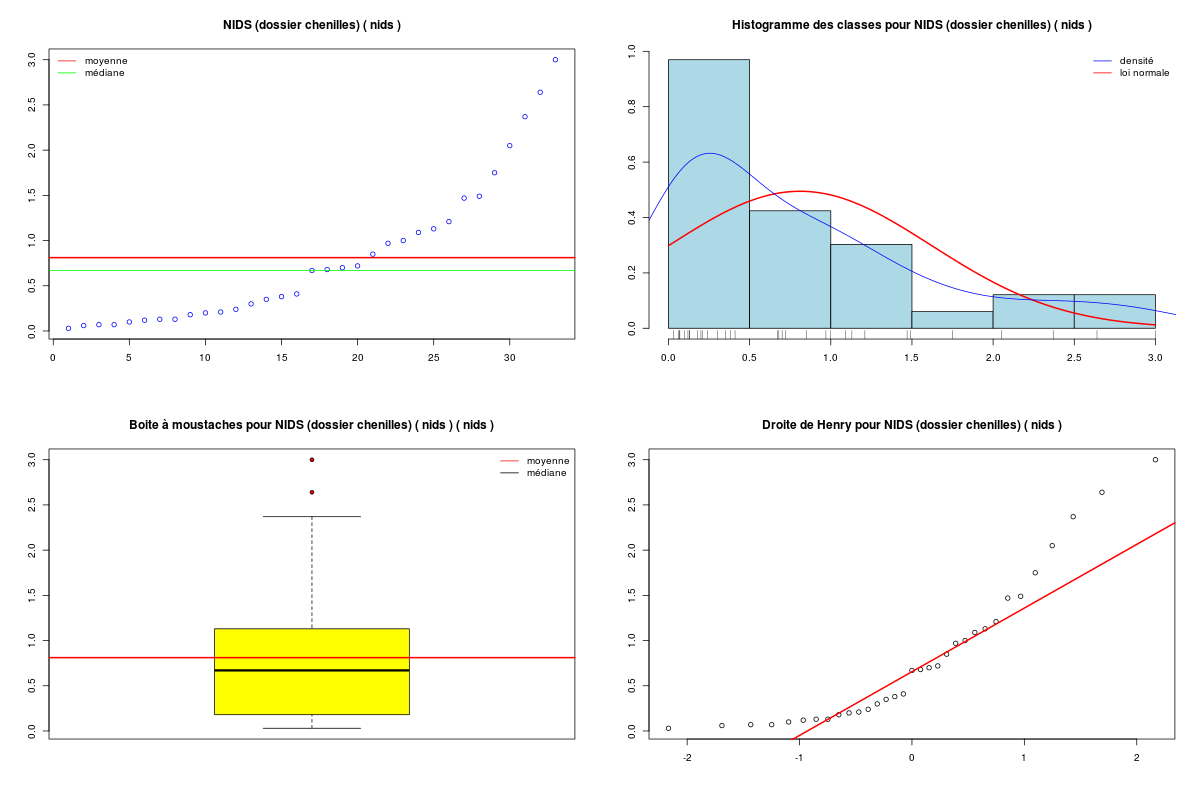
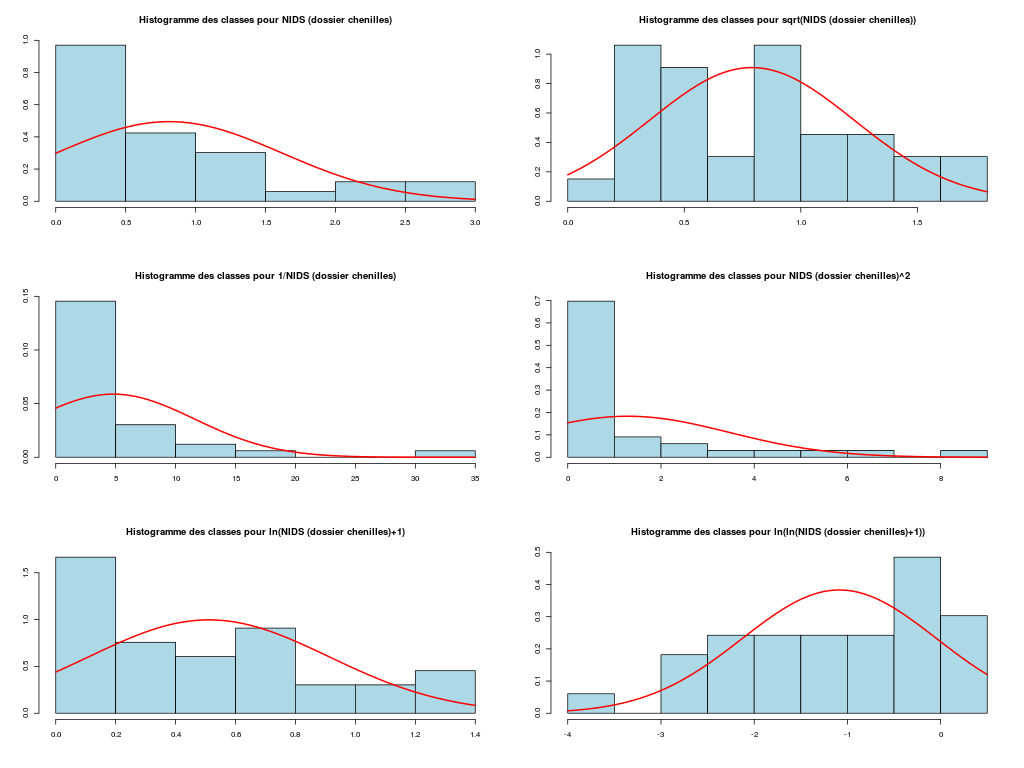
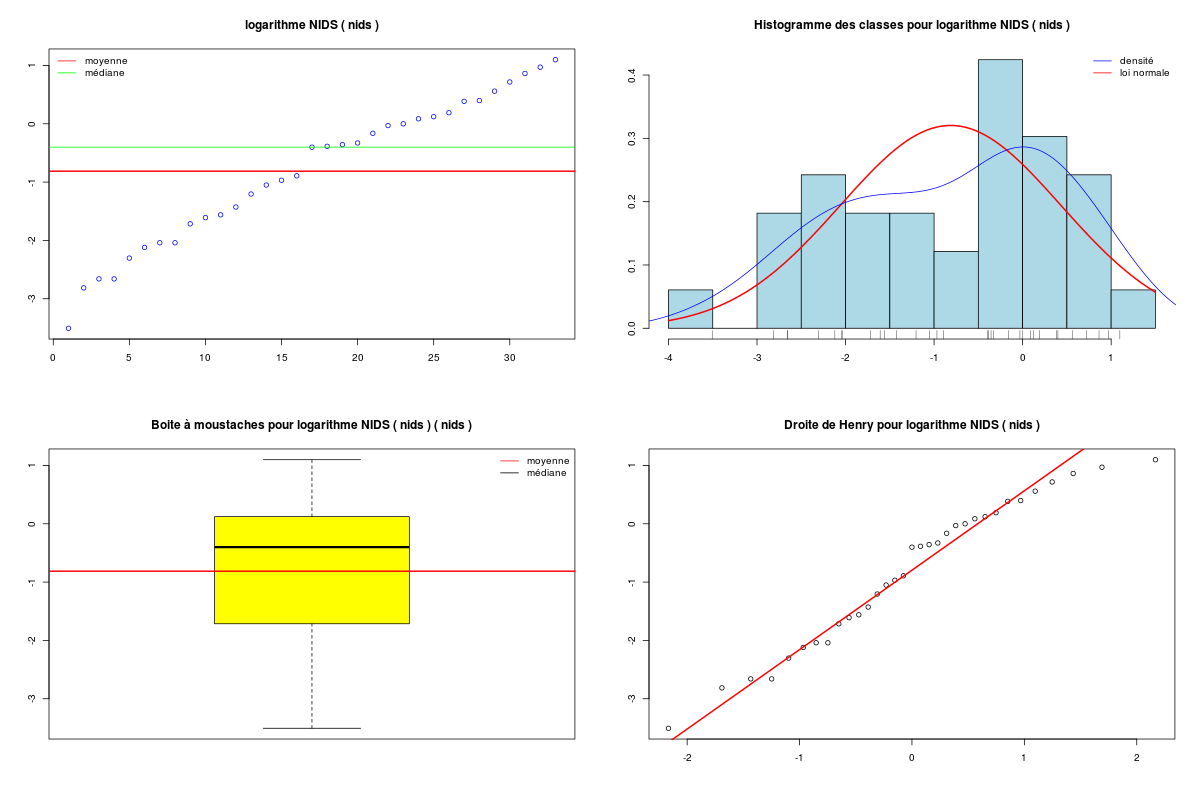
# on se restreint aux variables quantitatives sleepqt <- sleep[,(1:7)] cats("Variables originales") # on affiche en haut du data frame moyenne et # écart-type des colonnes moys <- apply(X=sleepqt,MARGIN=2,FUN=function(x) {mean(x,na.rm=TRUE) } ) ects <- apply(X=sleepqt,M=2,F=function(x) { sd(x,na.rm=TRUE) } ) mdr1 <- rbind(moys,ects,sleepqt) row.names(mdr1) <- c("Moy","Ect",row.names(sleepqt)) print( head(mdr1) ) catn() print( round(head(mdr1),2) ) # centrage et réduction des variables QT cats("Variables centrées réduites") mcr <- apply(X=sleepqt,M=2,FUN=scale) moys <- apply(X=mcr,MARGIN=2,FUN=function(x) {mean(x,na.rm=TRUE) } ) ects <- apply(X=mcr,M=2,F=function(x) { sd(x,na.rm=TRUE) } ) mdr2 <- rbind(moys,ects,mcr) row.names(mdr2) <- c("Moy","Ect",row.names(sleepqt)) print( head(mdr2) ) catn() print( round(head(mdr2),2) )Variables originales ==================== poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation Moy 198.790 283.1342 8.672917 1.972000 10.53276 19.87759 142.3534 Ect 899.158 930.2789 3.666452 1.442651 4.60676 18.20626 146.8050 African_elephant 6654.000 5712.0000 NA NA 3.30000 38.60000 645.0000 African_giant_pouched_rat 1.000 6.6000 6.300000 2.000000 8.30000 4.50000 42.0000 Arctic_Fox 3.385 44.5000 NA NA 12.50000 14.00000 60.0000 Arctic_ground_squirrel 0.920 5.7000 NA NA 16.50000 NA 25.0000 poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation Moy 198.79 283.13 8.67 1.97 10.53 19.88 142.35 Ect 899.16 930.28 3.67 1.44 4.61 18.21 146.81 African_elephant 6654.00 5712.00 NA NA 3.30 38.60 645.00 African_giant_pouched_rat 1.00 6.60 6.30 2.00 8.30 4.50 42.00 Arctic_Fox 3.38 44.50 NA NA 12.50 14.00 60.00 Arctic_ground_squirrel 0.92 5.70 NA NA 16.50 NA 25.00 Variables centrées réduites =========================== poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation Moy -2.158349e-18 6.016448e-18 -2.132784e-16 8.751680e-18 -7.191438e-17 -3.326398e-17 1.399182e-17 Ect 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 1.000000e+00 African_elephant 7.179172e+00 5.835740e+00 NA NA -1.570031e+00 1.028351e+00 3.423905e+00 African_giant_pouched_rat -2.199724e-01 -2.972594e-01 -6.471970e-01 1.940872e-02 -4.846700e-01 -8.446320e-01 -6.835831e-01 Arctic_Fox -2.173200e-01 -2.565190e-01 NA NA 4.270336e-01 -3.228333e-01 -5.609715e-01 Arctic_ground_squirrel -2.200614e-01 -2.982269e-01 NA NA 1.295323e+00 NA -7.993830e-01 poidsCorps poidsCerveau ondesLentes sommeilParadoxal sommeilTotal dureeVieMax dureeGestation Moy 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Ect 1.00 1.00 1.00 1.00 1.00 1.00 1.00 African_elephant 7.18 5.84 NA NA -1.57 1.03 3.42 African_giant_pouched_rat -0.22 -0.30 -0.65 0.02 -0.48 -0.84 -0.68 Arctic_Fox -0.22 -0.26 NA NA 0.43 -0.32 -0.56 Arctic_ground_squirrel -0.22 -0.30 NA NA 1.30 NA -0.80Au vu de la description statistique de la variable NIDS qui ne parait ni symétrique ni normale, une transformation en logarithme semble "raisonnable", si on utilise les résultats de notre fonction tdn() qui essaie des transformations usuelles pour obtenir une distribution normale.
# fonctions GH source("http://www.info.univ-angers.fr/~gh/statgh.r",encoding="latin1") # lecture des données chen <- lit.dar("chenilles.dar") # description de la variable NIDS decritQT("NIDS (dossier chenilles)",chen$NIDS," nids ",TRUE,"chenNIDS.png") # test de normalité et transformations tdn("NIDS (dossier chenilles)",chen$NIDS," nids ",TRUE,"chenNIDS_T.png") # une transformation possible : log decritQT("logarithme NIDS",log(chen$NIDS)," nids ",TRUE,"chen_ln_NIDS.png")DESCRIPTION STATISTIQUE DE LA VARIABLE NIDS (dossier chenilles) Taille 33 individus Moyenne 0.8112 nids Ecart-type 0.7939 nids Coef. de variation 98 % 1er Quartile 0.1800 nids Mediane 0.6700 nids 3eme Quartile 1.1300 nids iqr absolu 0.9500 nids iqr relatif 142.0000 % Minimum 0 nids Maximum 3 nids Tracé tige et feuilles The decimal point is at the | 0 | 0111111122223444 0 | 77779 1 | 00112 1 | 558 2 | 14 2 | 6 3 | 0 TESTS DE NORMALITE POUR LA VARIABLE y = NIDS (dossier chenilles) Variable Test p-value sqrt(y) Kolmogorov-Smirnov 0.7445409555 ln(y+1) Kolmogorov-Smirnov 0.4707968678 ln(ln(y+1)) Kolmogorov-Smirnov 0.2883073940 y Kolmogorov-Smirnov 0.2614654789 sqrt(y) Shapiro 0.0802992428 ln(ln(y+1)) Shapiro 0.0599220649 1/y Kolmogorov-Smirnov 0.0271139743 ln(y+1) Shapiro 0.0127728964 y^2 Kolmogorov-Smirnov 0.0126027258 y Shapiro 0.0003362189 1/y Shapiro 0.0000001855 y^2 Shapiro 0.0000001076 DESCRIPTION STATISTIQUE DE LA VARIABLE logarithme NIDS Taille 33 individus Moyenne -0.8133 nids Ecart-type 1.2259 nids Coef. de variation -151 % 1er Quartile -1.7148 nids Mediane -0.4005 nids 3eme Quartile 0.1222 nids iqr absolu 1.8370 nids iqr relatif -459.0000 % Minimum -4 nids Maximum 1 nids Tracé tige et feuilles The decimal point is at the | -3 | 5 -3 | -2 | 877 -2 | 3100 -1 | 766 -1 | 4200 -0 | 9 -0 | 444320 0 | 011244 0 | 679 1 | 01
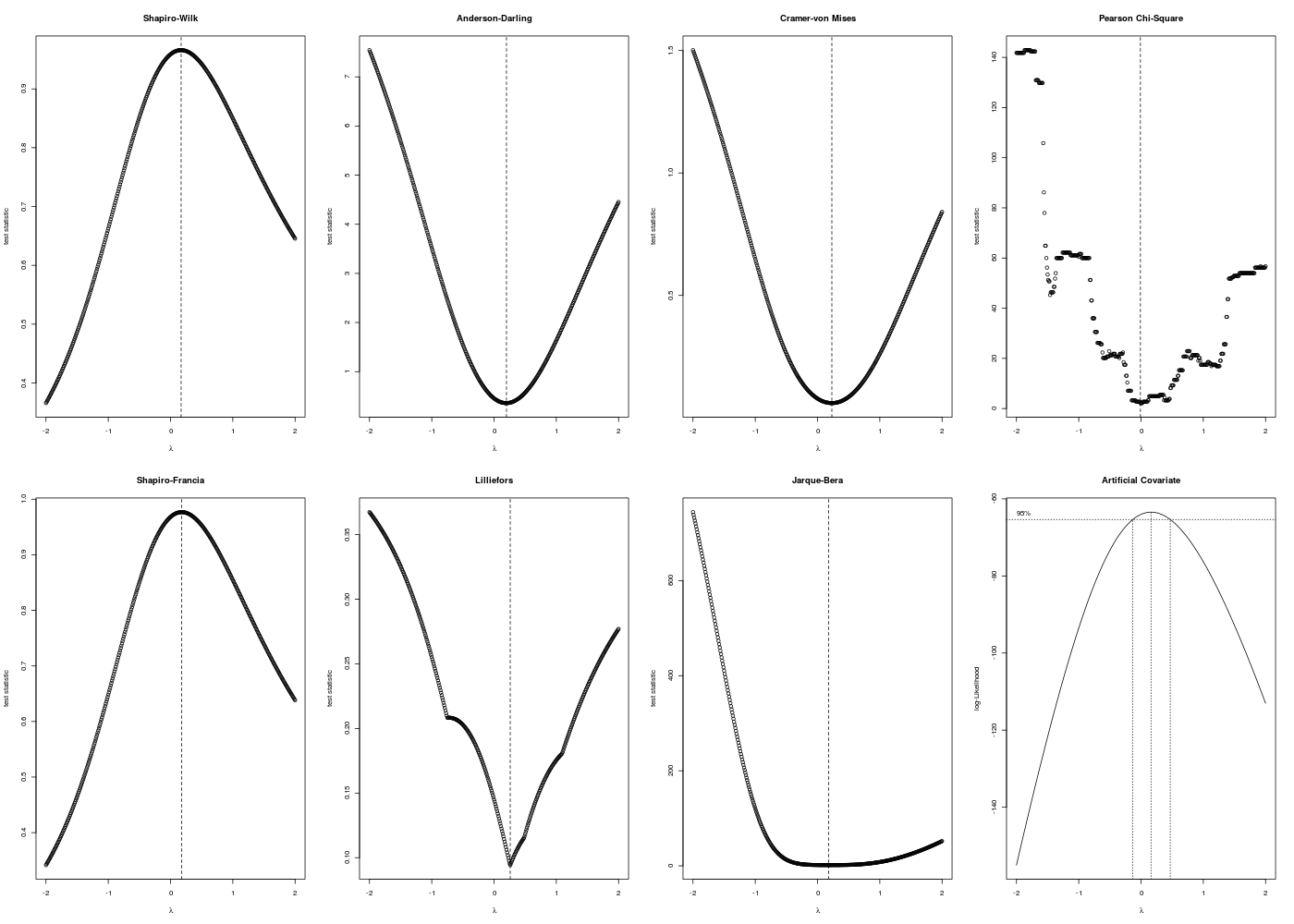
Que donnerait la transformation de Box-Cox-Tidwell pour cette variable NIDS ? Voici le code R qui détermine la valeur de λ et qui affiche la distributions de la variable transformée :
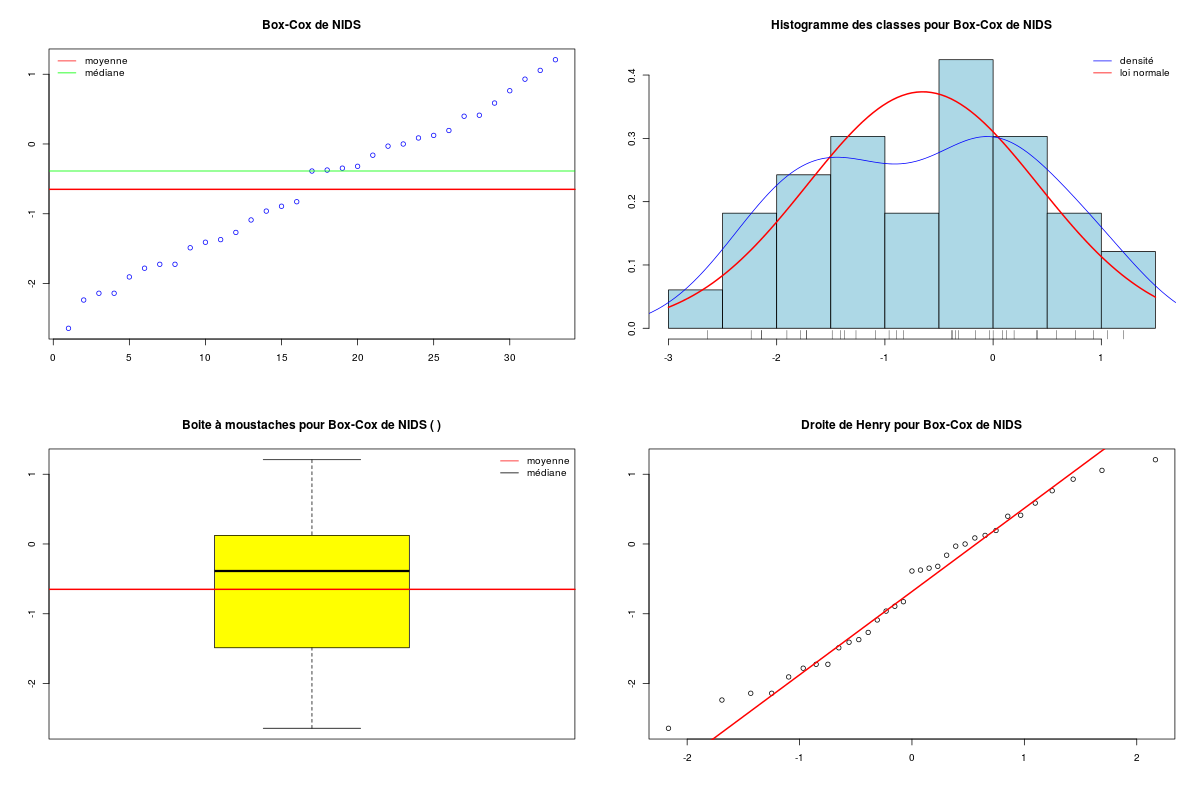
require("AID") # pour boxcoxnc() require("sae") # pour bxcx() chen <- lit.dar("http://forge.info.univ-angers.fr/~gh/wstat/Eda/chenilles.dar.txt") nids <- chen$NIDS lambda <- boxcoxnc(nids)[[4]][1,1] cat("pour la variable nids du dossier chenilles, lambda vaut ",lambda,"\n") nidsT <- bxcx(nids,lambda) decritQT("Box-Cox de NIDS",nidsT," ",TRUE) # production du fichier imgae decritQT("Box-Cox de NIDS",nidsT," ",TRUE,"transfBoxCox.png")pour la variable nids du dossier chenilles, lambda vaut 0.17 DESCRIPTION STATISTIQUE DE LA VARIABLE Box-Cox de NIDS Taille 33 individus Moyenne -0.6501 Ecart-type 1.0679 Coef. de variation -162 % 1er Quartile -1.4875 Mediane -0.3871 3eme Quartile 0.1235 iqr absolu 1.6110 iqr relatif -416.0000 % Minimum -3 Maximum 1 Tracé tige et feuilles The decimal point is at the | -2 | 6 -2 | 211 -1 | 98775 -1 | 44310 -0 | 98 -0 | 443320 0 | 011244 0 | 689 1 | 12
Voici maintenant l'analyse des variables du dossier SLEEP :
# analyse de la normalité pour les variables quantitatives du dossier sleep_animal (df=sleep) # (on teste chaque variable et ses transformations usuelles) for (iqt in names(unites)) { fgr <- paste(iqt,"_N.png",sep="") tdn(titreQT=iqt, nomVar=sleep[,iqt], unite=unites[iqt], graphique=TRUE, fichier_image=fgr ) # fin de tdn } # fin pour iqtTESTS DE NORMALITE POUR LA VARIABLE y = poidsCorps pour 62 valeurs (0 valeurs NA) Variable Test p-value ln(ln(y+1)) Kolmogorov-Smirnov 0.2383747021 ln(y+1) Kolmogorov-Smirnov 0.0042969871 ln(ln(y+1)) Shapiro 0.0001142669 sqrt(y) Kolmogorov-Smirnov 0.0000105902 ln(y+1) Shapiro 0.0000036480 1/y Kolmogorov-Smirnov 0.0000000135 y Kolmogorov-Smirnov 0.0000000014 y^2 Shapiro 0.0000000000 y^2 Kolmogorov-Smirnov 0.0000000000 1/y Shapiro 0.0000000000 sqrt(y) Shapiro 0.0000000000 y Shapiro 0.0000000000 TESTS DE NORMALITE POUR LA VARIABLE y = poidsCerveau pour 62 valeurs (0 valeurs NA) Variable Test p-value ln(y+1) Kolmogorov-Smirnov 0.4690690724 ln(ln(y+1)) Kolmogorov-Smirnov 0.2749174294 ln(y+1) Shapiro 0.0347516802 sqrt(y) Kolmogorov-Smirnov 0.0008959233 ln(ln(y+1)) Shapiro 0.0000402632 1/y Kolmogorov-Smirnov 0.0000001237 y Kolmogorov-Smirnov 0.0000000320 y^2 Shapiro 0.0000000000 y^2 Kolmogorov-Smirnov 0.0000000000 1/y Shapiro 0.0000000000 sqrt(y) Shapiro 0.0000000000 y Shapiro 0.0000000000 TESTS DE NORMALITE POUR LA VARIABLE y = ondesLentes pour 48 valeurs (14 valeurs NA) Variable Test p-value y Kolmogorov-Smirnov 0.9675199094 sqrt(y) Kolmogorov-Smirnov 0.9598382649 sqrt(y) Shapiro 0.7899018229 y Shapiro 0.7703636429 ln(y+1) Kolmogorov-Smirnov 0.6178041980 y^2 Kolmogorov-Smirnov 0.2672136845 ln(ln(y+1)) Kolmogorov-Smirnov 0.2070706784 ln(y+1) Shapiro 0.0875750348 1/y Kolmogorov-Smirnov 0.0218124145 y^2 Shapiro 0.0005959456 ln(ln(y+1)) Shapiro 0.0005027199 1/y Shapiro 0.0000000895 TESTS DE NORMALITE POUR LA VARIABLE y = sommeilParadoxal pour 50 valeurs (12 valeurs NA) Variable Test p-value ln(ln(y+1)) Shapiro NaN 1/y Shapiro NaN ln(ln(y+1)) Kolmogorov-Smirnov NA 1/y Kolmogorov-Smirnov NA ln(y+1) Kolmogorov-Smirnov 0.9790848943 sqrt(y) Kolmogorov-Smirnov 0.9508316261 ln(y+1) Shapiro 0.7966175635 sqrt(y) Shapiro 0.4812279747 y Kolmogorov-Smirnov 0.3460031094 y^2 Kolmogorov-Smirnov 0.0027495706 y Shapiro 0.0000873132 y^2 Shapiro 0.0000000004 TESTS DE NORMALITE POUR LA VARIABLE y = sommeilTotal pour 58 valeurs (4 valeurs NA) Variable Test p-value y Kolmogorov-Smirnov 0.9750078586 sqrt(y) Kolmogorov-Smirnov 0.7590632393 ln(y+1) Kolmogorov-Smirnov 0.3032090141 y^2 Kolmogorov-Smirnov 0.1743230884 y Shapiro 0.1396327049 sqrt(y) Shapiro 0.0928241083 ln(ln(y+1)) Kolmogorov-Smirnov 0.0609241305 ln(y+1) Shapiro 0.0043643764 1/y Kolmogorov-Smirnov 0.0011621188 y^2 Shapiro 0.0000991266 ln(ln(y+1)) Shapiro 0.0000557890 1/y Shapiro 0.0000000354 TESTS DE NORMALITE POUR LA VARIABLE y = dureeVieMax pour 58 valeurs (4 valeurs NA) Variable Test p-value ln(y+1) Kolmogorov-Smirnov 0.8216244503 sqrt(y) Kolmogorov-Smirnov 0.5568839994 ln(ln(y+1)) Kolmogorov-Smirnov 0.3500083112 ln(y+1) Shapiro 0.2908944695 y Kolmogorov-Smirnov 0.0915078562 ln(ln(y+1)) Shapiro 0.0152878830 sqrt(y) Shapiro 0.0151757989 1/y Kolmogorov-Smirnov 0.0099194172 y^2 Kolmogorov-Smirnov 0.0000184808 y Shapiro 0.0000005076 1/y Shapiro 0.0000001654 y^2 Shapiro 0.0000000000 TESTS DE NORMALITE POUR LA VARIABLE y = dureeGestation pour 58 valeurs (4 valeurs NA) Variable Test p-value ln(y+1) Kolmogorov-Smirnov 0.6403926293 ln(ln(y+1)) Kolmogorov-Smirnov 0.5614638724 ln(y+1) Shapiro 0.1082411025 sqrt(y) Kolmogorov-Smirnov 0.0877352491 ln(ln(y+1)) Shapiro 0.0799921933 1/y Kolmogorov-Smirnov 0.0570826653 y Kolmogorov-Smirnov 0.0257092778 sqrt(y) Shapiro 0.0007488714 y^2 Kolmogorov-Smirnov 0.0000347596 1/y Shapiro 0.0000009913 y Shapiro 0.0000002010 y^2 Shapiro 0.0000000000
Tester si la moyenne vaut 0 peut se faire avec un test de Student et tester si la variance vaut 1 peut se faire avec un test de Fisher.
Pour réaliser une régression linéaire en R, on utilise la fonction lm avec l'opérateur ~ (tilde) alors qu'une régression logistique passe par la fonction glm.
La fonction lm renvoie une liste avec entre autres les variables suivantes :
$coefficients estimation des coefficients $fitted.values les valeurs calculées pour chaque y $residuals les résidus (différences entre valeurs originales et valeurs estimées) Si on écrit print(ml) où ml est le résultat d'une fonction lm ou glm, on n'obtient que les coefficients de la régression. Pour avoir le détail de la régression, il faut utiliser summary(ml) et confint(ml) pour avoir les intervalles de confiance des coefficients de la régression. Les fonctions correspondantes sont : summary.lm et summary.glm car summary est une fonction générique qui peut s'appliquer à de nombreux objets. On peut ensuite prédire de nouvelles valeurs avec la fonction predict qui est une aussi fonction générique qui se décline en predict.lm et predict.glm.
La partie graphique est très importante pour les régressions. Après un plot élémentaire des données, un abline du modèle trace la droite de régression. A la suite d'une régression, la fonction plot.lm produit 6 graphiques pour analyser la qualité de la régression, dont seuls 4 sont affichés par défaut, repérés ci-dessous par une étoile :
x y 1 * Fitted values Residuals 2 * Theoretical quantiles Standardized residuals 3 * Fitted values Root of standardized residuals 4 Observation number Cook's distance 5 * Leverage Standardized residuals 6 Leverage hn Cook's distance Enfin, signalons qu'avec predict et matlines il est possible de tracer l'intervalle de confiance de la droite et l'intervalle de confiance des prévisons.
Réaliser une régression, c'est modéliser Y = f(X) avec Y quantitative ou qualitative et X quantitative. Une ANOVA à un facteur étudie Y = f(X) avec Y quantitative et X qualitative. Une ANCOVA, c'est étudier Y=f(X1,X2,...) avec Y quantitative et au moins une variable X quantitative et une variable X qualitative. En simplifiant beaucoup, si on n'utilise que deux variables, alors on peut résumer ainsi les analyses :
Y=f(X) X quantitative X qualitative Y quantitative régression linéaire ANOVA à un facteur Y qualitative régression logistique régression logistique Réaliser une ANOVA Y = f(X) avec deux modalités pour X revient à effectuer un test t de Student pour les deux sous-populations sous hypothèse d'égalité des variances. On peut le vérifier sur le dossier ELF si on analyse l'AGE par SEXE à l'aide du programme suivant :
# données source("http://www.info.univ-angers.fr/~gh/statgh.r",encoding="latin1") elf <- lit.dar("http://www.info.univ-angers.fr/~gh/Datasets/elf.dar") age <- elf$AGE sexe <- elf$SEXE # anova de AGE en fonction de SEXE print( anova(lm(age~sexe)) ) # test t de Student de l'AGE des HOMMES et des FEMMES # sous hypothèse d'égalité des variances print( t.test(age~sexe,var.equal=TRUE) ) # on aurait aussi pu utiliser : ageh <- age[sexe==0] agef <- age[sexe==1] print( t.test(ageh,agef,var.equal=TRUE) )dont voici les résultats
Analysis of Variance Table Response: age Df Sum Sq Mean Sq F value Pr(>F) sexe 1 17.7 17.696 0.0569 0.812 Residuals 97 30176.4 311.097 Two Sample t-test data: ageh and agef t = 0.2385, df = 97, p-value = 0.812 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -6.475006 8.243756 sample estimates: mean of x 36.40000, mean of y 35.51562On réalise une analyse de la variance (anova) en R avec la fonction anova, une analyse de la variance par strate (aov) avec la fonction aov et une analyse de la covariance (ancova) avec la fonction ancova du package nommé HH.
La fonction de base en R pour calculer des corrélations se nomme cor() et fait partie du package stats. Le paramètre method permet de choisir entre Pearson, Spearman et Kendall. Le test associé se nomme cor.test() et fait partie du package stats. Il utilise le même paramètre method. La fonction cor() est vectorielle et permet donc de calculer la mdc (matrice des coefficients de corrélation).
# chargement des données data(iris) # on enlève la variable qualitative irisQT <- iris[,-5] # voyons le début des données head(irisQT) # coefficient de corrélation linéaire cor(iris[,1],iris[,2]) # équivalent à cor(iris[,1],iris[,2],method="pearson") # coefficient de corrélation "monotone" cor(iris[,1],iris[,2],method="spearman") # coefficient de corrélation/concordance cor(iris[,1],iris[,2],method="kendall") # test statistique associé cor.test(iris[,1],iris[,2]) # matrice des coefficients de corrélation linéaire cor(irisQT) # à comparer avec la fonction (gH) nommée mdc mdc(irisQT)> # chargement des données > > data(iris) > # on enlève la variable qualitative > > irisQT <- iris[,-5] > # voyons le début des données > > head(irisQT) Sepal.Length Sepal.Width Petal.Length Petal.Width 1 5.1 3.5 1.4 0.2 2 4.9 3.0 1.4 0.2 3 4.7 3.2 1.3 0.2 4 4.6 3.1 1.5 0.2 5 5.0 3.6 1.4 0.2 6 5.4 3.9 1.7 0.4 > # coefficient de corrélation linéaire > > cor(iris[,1],iris[,2]) # équivalent à cor(iris[,1],iris[,2],method="pearson") [1] -0.1175698 > # coefficient de corrélation "monotone" > > cor(iris[,1],iris[,2],method="spearman") [1] -0.1667777 > # coefficient de corrélation/concordance > > cor(iris[,1],iris[,2],method="kendall") [1] -0.07699679 > # test statistique associé > > cor.test(iris[,1],iris[,2]) Pearson's product-moment correlation data: iris[, 1] and iris[, 2] t = -1.4403, df = 148, p-value = 0.1519 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.27269325 0.04351158 sample estimates: cor -0.1175698 > # matrice des coefficients de corrélation linéaire > > cor(irisQT) Sepal.Length Sepal.Width Petal.Length Petal.Width Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411 Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259 Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654 Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000 > # à comparer avec la fonction (gH) nommée mdc > > mdc(irisQT) Matrice des corrélations au sens de Pearson pour 150 lignes et 4 colonnes Sepal.Length Sepal.Width Petal.Length Petal.Width Sepal.Length 1.000 Sepal.Width -0.118 1.000 Petal.Length 0.872 -0.428 1.000 Petal.Width 0.818 -0.366 0.963 1.000Montrer sur un exemple que la corrélation de Spearman entre X et Y est égale à la corrélation de Pearson appliquée aux rangs de X et de Y s'écrit très facilement en R :
# chargement des données data(iris) # X et Y sont les colonnes 1 et 2 du "dataframe" x <- iris[,1] y <- iris[,1] # calcul des rangs rgx <- rank(x) rgy <- rank(y) # la corrélation de spearman entre X et Y est égale à # la corrélation de pearson appliquée aux rangs de X et de Y identical( cor(x,y,method="spearman"), cor(rgx,rgy,method="pearson") )> # chargement des données > > data(iris) > # X et Y sont les colonnes 1 et 2 du "dataframe" > > x <- iris[,1] > y <- iris[,1] > # calcul des rangs > > rgx <- rank(x) > rgy <- rank(y) > # la corrélation de spearman entre X et Y est égale à > # la corrélation de pearson appliquée aux rangs de X et de Y > > identical( cor(x,y,method="spearman"), cor(rgx,rgy,method="pearson") ) [1] TRUEEn français, nous conseillons les 3 ouvrages suivant :
Initiation à la statistique avec R Statistiques avec R (3 ème édition) Régression avec R (Bertrand et Maumy-Bertrand) (Cornillon et al.) (Cornillon et Matzner-Lober) En anglais, les trois références suivantes devraient suffire :
Linear Models with R Regression Modeling Strategies Regression Methods in Biostatistics (Faraway) (Harrell) (Vittinghoff et al.) Comme les liens de la question précédente l'ont montré, les trois packages généraux de R nommés base, stats et graphics sont les premiers packages à bien connaitre.
Il faut noter que le package faraway permet de retrouver les données, les calculs et les présentations de la version en ligne de l'ouvrage de Faraway (copie locale) et que le package rms fournit les données et les programmes de l'ouvrage de Farrell (le lien RmS fournit des compléments utiles). Pour l'ouvrage de Vittinghof et al., on peut trouver les données à l'adresse vgsm et et le code R pour reproduire les résultats est là.
Un livre récent (2017) nommé Handbook of Regression Methods de Derek Scott YOUNG traite en détail et avec le même plan (régression linéaire simple, multiple puis régression logistique) les notions présentées ici.

Exercice volontairement non corrigé sur le site. Nous fournissons juste le code R :
# lecture du fichier excel des données library(gdata) #hers <- read.xls("hersdata.xls") # on se restreint aux variables indiquées lstVar <- c("SBP","glucose","exercise","drinkany","BMI","diabetes","age") varql <- c("exercise","drinkany","diabetes") varqt <- c("SBP","glucose","BMI","age") hersVar <- hers[,lstVar] print(head(hersVar)) # analyse des variables qualitatives for (iql in varql) { fgr <- paste("hers_",iql,".png",sep="") decritQLf(titreQL=iql, nomFact=hersVar[,iql], graphique=TRUE, fichier_image=fgr, testequi=TRUE ) # fin decritQLf } # fin pour iql unites <- c("?","?","?","?") names(unites) <- varqt for (iqt in names(unites)) { fgr <- paste("hers_",iqt,".png",sep="") decritQT(titreQT=iqt, nomVar=hersVar[,iqt], unite=unites[iqt], graphique=TRUE, fichier_image=fgr ) # fin de decritQT } # fin pour iqt