![]()
![]()
Les dates de formation sont ici.
Enoncés pour la séance numéro 2 solutions
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Enoncés pour la séance numéro 2 solutions
Après avoir vu la documentation de la fonction lm() du package stats essayer de réaliser la modélisation par une relation linéaire la dépendance entre la variable consommation d'essence et la variable distance parcourue dans le jeu de données km.dar (sans transformation des données).
Dans quel ordre doit-on lire les résultats ? Faut-il regarder en premier le R2, la p-value de F, les coefficients ?
Y a-t-il des représentations graphiques associées ? Pourquoi y a-t-il 4 graphiques produits avec plot(lm(modele)) alors qu'on pourrait en avoir 6 ? Comment obtenir les 6 tracés ? A quoi correspondent-ils ?
Faut-il envisager une relation de causalité ? Quelles sont les valeurs prédites par le modèle pour 100 et 250 km ? Quelle est l'augmentation de la consommation si la distance augmente de 1 km ?

Qu'est-ce qu'un outlier ? Y en a-t-il dans le jeu de données km.dar ? Si oui, que faut-il en faire ? Qu'est-ce que cela change pour la régression ?
Faut-il transformer les variables ? Si oui, quelles transformations utiliser ? Qu'est-ce que cela change pour la régression ?
Les conditions d'application des calculs d'une régression sont-elles respectées ?
Quel serait le modèle si on enlevait le point trajet6 (50,12) ?
Effectuer maintenant une régression linéaire simple de SBP en fonction de age dans les données hersdata.xls de l'ouvrage Regression Methods in Biostatistics. On essaiera d'être exhaustif. En particulier, on discutera de la qualité de la régression, on tracera les intervalles de confiance associés.
Obtient-on de meilleurs résultats si on se restreint aux moyennes de SBP par décile d'AGE ?
Références pour HERS :
design, methods, and baseline characteristics of the HERS study
Essayer de régresser la variable AGE en fonction de la variable MYST pour les données noml.dar reproduites ci-dessous. Où est le problème ?
iden age myst p1 18 10 p2 19 20 p3 20 30 p4 18 40 p5 19 50 p6 20 60 p7 18 70 p8 19 80 p9 20 90Comment calcule-t-on les coefficients a et b du modèle linéaire Y = a * X + b ? Quelle conséquence cela a-t-il pour le point M(moyenne de X, moyenne de Y) ? Quelles conséquences cela a-t-il sur le modèle de régression linéaire simple ?
Voici les «célèbres données d'Anscombe» (fichier anscombe.dar) :
ID X Y1 Y2 Y3 X4 Y4 a 4 4.26 3.10 5.39 19 12.50 b 5 5.68 4.74 5.73 8 6.89 c 6 7.24 6.13 6.08 8 5.25 d 7 4.82 7.26 6.42 8 7.91 e 8 6.95 8.14 6.77 8 5.76 f 9 8.81 8.77 7.11 8 8.84 g 10 8.04 9.14 7.46 8 6.58 h 11 8.33 9.26 7.81 8 8.47 i 12 10.84 9.13 8.15 8 5.56 j 13 7.58 8.74 12.74 8 7.71 k 14 9.96 8.10 8.84 8 7.04Analyser les liaisons linéaires de Y1, Y2, Y3 en fonction de X et de Y4 en fonction de X4.
Que nous apprennent ces données d'Anscombe sur les calculs et les graphiques en régression linéaire simple ?

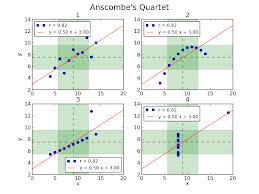
Quelles sont les limites de prédiction d'une régression linéaire simple ? Peut-on «extrapoler», «généraliser» ?
Quelle serait la consommation en essence pour 1 000 km, 3 000 km pour le modèle linéaire de l'exercice 1 ?
On veut modéliser par une régression linéaire simple la variable NIDS dans le dossier chenilles. Quelle est la meilleure régression si on utilise les 10 premières variables, de ALT à MELAN ?
On pourra commencer par écrire une fonction pour extraire le critère de qualité de la régression.