XML en L2, université d'Angers
T.P. numéro 4 : transformation
Table des matières cliquable
1. Expressions XPATH
2. Comprendre la transformation vide
3. Réaliser une transformation minimale avec XSL
4. Une transformation XSL élémentaire
5. Une deuxième transformation XSL pour ajouter des informations
6. Une troisième transformation XSL pour un rendu en page Web
7. Transformations XSL avancées et statistiques
Il est possible d'afficher toutes les solutions via ?solutions=1 et de les masquer via ?solutions=0 .
On s'intéresse ici au document films2.xml qui contient des films et des artistes.
En voici la grammaire DTD :
<!ELEMENT FILMSETARTISTES (FILMS,ARTISTES) >
<!ELEMENT FILMS (FILM)* >
<!ELEMENT FILM (TITRE,GENRE?,PAYS,MES,ROLES,RESUME?) >
<!ELEMENT TITRE (#PCDATA) >
<!ELEMENT GENRE (#PCDATA) >
<!ELEMENT PAYS (#PCDATA) >
<!ELEMENT MES EMPTY >
<!ELEMENT ROLES (ROLE)* >
<!ELEMENT RESUME (#PCDATA) >
<!ELEMENT ROLE (PRENOM,NOM,INTITULE) >
<!ELEMENT PRENOM (#PCDATA) >
<!ELEMENT INTITULE (#PCDATA) >
<!ELEMENT NOM (#PCDATA) >
<!ELEMENT ARTISTES (ARTISTE)* >
<!ELEMENT ARTISTE (ARTNOM,ARTPRENOM,ANNEENAISS?) >
<!ELEMENT ARTNOM (#PCDATA) >
<!ELEMENT ARTPRENOM (#PCDATA) >
<!ELEMENT ANNEENAISS (#PCDATA) >
<!ATTLIST ARTISTE xmlns CDATA #FIXED '' id CDATA #REQUIRED >
<!ATTLIST FILM xmlns CDATA #FIXED '' Annee CDATA #REQUIRED >
<!ATTLIST MES xmlns CDATA #FIXED '' idref CDATA #REQUIRED >
On fournit aussi la structure explicite du fichier (éléments seulement) obtenue à l'aide de la commande xmlstarlet el -u films2.xml :
FILMSETARTISTES
FILMSETARTISTES/ARTISTES
FILMSETARTISTES/ARTISTES/ARTISTE
FILMSETARTISTES/ARTISTES/ARTISTE/ANNEENAISS
FILMSETARTISTES/ARTISTES/ARTISTE/ARTNOM
FILMSETARTISTES/ARTISTES/ARTISTE/ARTPRENOM
FILMSETARTISTES/FILMS
FILMSETARTISTES/FILMS/FILM
FILMSETARTISTES/FILMS/FILM/GENRE
FILMSETARTISTES/FILMS/FILM/MES
FILMSETARTISTES/FILMS/FILM/PAYS
FILMSETARTISTES/FILMS/FILM/RESUME
FILMSETARTISTES/FILMS/FILM/ROLES
FILMSETARTISTES/FILMS/FILM/ROLES/ROLE
FILMSETARTISTES/FILMS/FILM/ROLES/ROLE/INTITULE
FILMSETARTISTES/FILMS/FILM/ROLES/ROLE/NOM
FILMSETARTISTES/FILMS/FILM/ROLES/ROLE/PRENOM
FILMSETARTISTES/FILMS/FILM/TITRE
On liste également la liste des attributs uniques du fichier :
FILMSETARTISTES/ARTISTES/ARTISTE/@id
FILMSETARTISTES/FILMS/FILM/@Annee
FILMSETARTISTES/FILMS/FILM/MES/@idref
A l'aide de xmllint en mode «shell», essayer ensuite de répondre aux questions suivantes :
-
Quels sont tous les titres de films ?
-
Quel est le neuvième titre de film ?
-
En quelle année est sorti le film Blade Runner ?
-
Quel en est le metteur en scène ?
-
Combien y a-t-il de films ?
-
Quels éléments contiennent le texte "Bruce" ?
Remarque : il faut peut-être utiliser la commande rlwrap xmllint --shell films2.xml au lieu de la simple commande xmllint --shell films2.xml si le terminal n'est pas bien configuré afin de pouvoir facilement éditer la ligne de commandes sous xmllint.
Voici les instructions à exécuter dans le shell de XMLLINT pour répondre aux questions posées :
# lancer xmllint en mode shell sur le fichier des films
xmllint --shell films2.xml
# tous les titres de films
ls //FILM/TITRE # meilleur que ls //TITRE
# le titre du neuvième film (on trouve Gladiator)
# on aurait pu écrire en ligne de commandes
# grep TITRE films2.xml | head -n 9 | tail -n 1
# attention : ls //TITRE[9] n'existe pas
ls //FILM[position()=9]/TITRE # plus "propre" que ls //FILM[9]/TITRE
# année de sortie du film Blade Runner (on trouve 1982)
ls //FILM[TITRE="Blade Runner"]/@Annee
## metteur en scène du film Blade Runner (Ridley SCOTT)
# solution 1, en deux temps : numéro du metteur en scène (on trouve 4)
ls //FILM[TITRE="Blade Runner"]//MES/@idref
# artiste associé
ls //ARTISTE[@id="4"]/ARTNOM # Scott
ls //ARTISTE[@id="4"]/ARTPRENOM # Ridley
# solution 2, tout en une seule fois
ls //ARTISTE[@id=//FILM[TITRE="Blade Runner"]//MES/@idref]/ARTNOM
# nombre de films (réponse 48)
xpath count(//FILM)
# quels éléments contiennent le texte Bruce (5 élements PRENOM et un élément ARTPRENOM)
grep Bruce
Que produit la transformation vide définie dans le fichier vide.xsl si on l'applique aux fichiers eau.xml, eau2.xml, trajets.xml et firefox.svg du T.P. 1 ?
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:output method="text" encoding="UTF-8" />
</xsl:stylesheet>
Quelle est, pour ces fichiers, la différence avec la transformation minimaliste nommée minimaliste.xsl ?
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:output method="text" encoding="UTF-8" />
<xsl:template match="/"><xsl:apply-templates /></xsl:template>
</xsl:stylesheet>
La transformation vide affiche les contenus textuels des éléments et ignore les attributs. Pour le fichier eau.xml on récupère donc trois lignes pratiquement vides (en fait on récupère les espaces d'indentation et les sauts de ligne, ce qui fait qu'à l'écran on ne voit rien. Pour le fichier eau2.xml on récupère les noms et les nombres d'atomes. Au niveau de trajets.xml, le type de train, le nom des gares de départ et d'arrivée sont affichés.
Pour le dessin du renard, il y a beaucoup de lignes vides affichées, ce qui fait qu'on risque de manquer le début de l'affichage. Heureusement, grep est notre ami ! On récupère donc comme seules lignes de texte le contenu des éléments title et desc.
$gh> xsltproc vide.xsl eau.xml # (3 lignes presque vides)
$gh> xsltproc vide.xsl eau2.xml
Oxygene
1
Hydrogene
2
$gh> xsltproc vide.xsl trajets.xml
TGV
Angers
Paris Montparnasse
Micheline
Troyes
Dijon
$gh> xsltproc vide.xsl firefox.svg # on ne voit rien
$gh> xsltproc vide.xsl firefox.svg | wc -l # 422 lignes, quand même !
$gh> xsltproc vide.xsl firefox.svg | grep "[a-z]" | wc -l # 2 lignes non vides
Il n'y a en principe aucune différence entre les transformations vide.xsl et minimaliste.xsl parce que la transformation vide applique toutes les règles par défaut à partir de la racine.
Que faut-il ajouter à la transformation minimaliste définie dans le fichier minimaliste.xsl pour qu'elle n'affiche que les noms d'atome si on l'applique au fichier eau2.xml ?
Une première solution consiste à définir deux règles, l'une pour l'élément nom et l'autre pour l'élément nombre. Pour nom on veut afficher le contenu alors que pour nombre on ne veut rien faire (puisqu'on ne veut pas afficher). Voici donc la solution dans mineau2.xsl :
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:output method="text" encoding="UTF-8" />
<xsl:template match="/"><xsl:apply-templates /></xsl:template>
<xsl:template match="nom"><xsl:value-of select="." /></xsl:template>
<xsl:template match="nombre" />
</xsl:stylesheet>
Une meilleure solution est sans doute de ne demander que de déclencher les règles pour les éléments noms, soit le code du fichier mineau3.xsl :
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:output method="text" encoding="UTF-8" />
<xsl:template match="/"><xsl:apply-templates select="//nom" /></xsl:template>
<xsl:template match="nom"><xsl:value-of select="." /><xsl:text> </xsl:text></xsl:template>
</xsl:stylesheet>
Enfin, la solution la plus courte est d'intercepter la règle sur l'élément nombre, soit le code du fichier mineau4.xsl :
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:output method="text" encoding="UTF-8" />
<xsl:template match="nombre" />
</xsl:stylesheet>
On voudrait compter le nombre de protéines du fichier leadb880.xml et vérifier que chaque protéine a bien un attribut length. Trouver une solution en ligne de commandes puis à l'aide d'une transformation XSL.
Comment peut-on trouver la plus petite longueur de protéine et la plus grande via XSL ?
Une protéine correspond à un élément protein donc il suffit de compter les chaines <protein> pour les dénombrer. L'attribut length, lui, peut se repérer grâce à l'expression <fasta length=. Dans les deux cas, on trouve 880 lignes correspondantes, mais cela ne prouve sans doute pas que chaque protéine a bien un attribut length dans un sous-élément fasta sauf à valider le fichier pour la grammaire leadb.dtd du T.P. numéro 1 (ou à savoir bien compter, car 3521 = 1 + 4x880). Par contre rechercher toutes les expressions proteins/protein/fasta/@length dans la sortie de xmlstarlet el -a peut le prouver. Voici les commandes à utiliser :
grep "<protein>" leadb880.xml | wc -l # 880 protéines
grep "<fasta length=" leadb880.xml | wc -l # 880 longueurs
xmlstarlet el -a leadb880.xml | grep "proteins/protein/fasta/@length" | wc -l # 880 longueurs
# on peut aussi utiliser xmllint :
xmllint --shell leadb880.xml
/ > xpath count(//fasta/@length)
exit
Pour effectuer une transformation XSL qui réalise les mêmes comptages, il suffit de mettre une seule règle sur la racine du document et d'utiliser la fonction XPATH nommée count().
Transformation proteines.xsl :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" />
<xsl:template match="/">
Il y a <xsl:value-of select="count(//protein)" /> protéines
et <xsl:value-of select="count(//protein/fasta/@length)" /> longueurs.
</xsl:template>
</xsl:stylesheet>
Pour exécuter cette transformation, on peut utiliser xsltproc :
$gh> xsltproc proteines.xsl leadb880.xml
Il y a 880 protéines
et 880 longueurs.
mais ce n'est pas le seul choix possible. Par exemple on peut utiliser xmlstarlet :
$gh> xmlstarlet tr proteines.xsl leadb880.xml
Il y a 880 protéines
et 880 longueurs.
On peut aussi mettre l'appel du fichier XSL dans l'en-tête du fichier XML et faire exécuter la transformation par le navigateur, comme ici.
Pour trouver la longueur minimale et la longueur maximale, on peut se contenter de trier par ordre croissant ou décroissant et de garder la première valeur, soit le code XSL suivant :
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:variable name="lngMin">
<xsl:for-each select="//@length">
<xsl:sort select="." data-type="number" order="ascending"/>
<xsl:if test="position() = 1"><xsl:value-of select="."/></xsl:if>
</xsl:for-each>
</xsl:variable>
<xsl:variable name="lngMax">
<xsl:for-each select="//@length">
<xsl:sort select="." data-type="number" order="descending"/>
<xsl:if test="position() = 1"><xsl:value-of select="."/></xsl:if>
</xsl:for-each>
</xsl:variable>
<xsl:template match="/">
Longueur minimale <xsl:value-of select="$lngMin" /> aa.
Longueur maximale <xsl:value-of select="$lngMax" /> aa.
</xsl:template>
</xsl:stylesheet>
dont le rendu est
# résultat de xsltproc prot_max.xsl leadb880.xml
Longueur minimale 66 aa.
Longueur maximale 843 aa.
Ecrire des transformations ajouteAge qui calculent et ajoutent l'age aux personnes dont on connait la date de naissance. On ajoutera un élément age lorsque la ddn est un élément, un attribut age si la ddn est un attribut. Effectuez ensuite les transformations inverses, à savoir mettre un attribut quand on a un élément et réciproquement. On utilisera les fichiers pers01.xml et pers02.xml pour tester les transformations.
Nous avons vu dans la série d'exercices sur la structuration des fichiers XML qu'un attribut tout numérique ne pouvait pas servir d'ID et donc d'IDREF non plus. Ecrire une transformation ajouteArt qui modifie les attributs id et idref des éléments MES (metteurs en scène) et ARTISTES de films2.xml par l'ajout de "art". Ainsi au lieu de <MES idref="3"></MES> et <ARTISTE id="51">, on devra avoir : <MES idref="art3"></MES> et <ARTISTE id="art51">.
Il n'y a aucune difficuté à ajouter des éléments ou des attributs à un document XML. On commence par préciser dans xsl:output que la sortie est du XML, puis on se sert de la fonction xsl:copy-of pour recopier chaque élément personne avec son sous-arbre. Au passage, on crée un nouvel élément age ou on rajoute un attribut age.
5.1 Ajout de l'age
Commençons par ajouter un élément age pour pers01.xml :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- fichier aea1.xsl -->
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" />
<xsl:template match="/">
<xsl:text>
</xsl:text>
<personnes>
<xsl:text>
</xsl:text>
<xsl:apply-templates select="//personne" />
</personnes>
</xsl:template>
<xsl:template match="personne">
<personne>
<xsl:copy-of select="./*" />
<age><xsl:value-of select="2020-ddn"/></age>
</personne>
<xsl:text>
</xsl:text>
</xsl:template>
</xsl:stylesheet>
Résultat :
<?xml version="1.0" encoding="UTF-8"?>
<personnes>
<personne><nom>DUPUIS</nom><prénom>Isabelle</prénom><ddn>1965</ddn><age>48</age></personne>
<personne><nom>DUPONT</nom><prénom>Jean</prénom><ddn>1963</ddn><age>50</age></personne>
<personne><nom>DUPONT</nom><prénom>Jack</prénom><ddn>1968</ddn><age>45</age></personne>
</personnes>
Ajoutons maintenant un attribut age pour pers02.xml :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- fichier aea2.xsl -->
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" />
<xsl:template match="/">
<xsl:text>
</xsl:text>
<personnes>
<xsl:apply-templates select="//personne" />
<xsl:text>
</xsl:text>
</personnes>
</xsl:template>
<xsl:template match="personne">
<xsl:text>
</xsl:text>
<personne>
<xsl:copy-of select="@*" />
<xsl:attribute name="age">
<xsl:value-of select="2020-@ddn"/>
</xsl:attribute>
</personne>
</xsl:template>
</xsl:stylesheet>
Résultat :
<?xml version="1.0" encoding="UTF-8"?>
<personnes>
<personne ddn="1965" nom="DUPUIS" prénom="Isabelle" age="48"/>
<personne ddn="1963" nom="DUPONT" prénom="Jean" age="50"/>
<personne ddn="1968" nom="DUPONT" prénom="Jack" age="45"/>
</personnes>
Sur le même pricipe; ajoutons maintenant un attribut age pour pers01.xml :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- fichier aea3.xsl -->
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" />
<xsl:template match="/">
<xsl:text>
</xsl:text>
<personnes>
<xsl:text>
</xsl:text>
<xsl:apply-templates select="//personne" />
</personnes>
</xsl:template>
<xsl:template match="personne">
<personne>
<xsl:attribute name="age"><xsl:value-of select="2013-ddn"/></xsl:attribute>
<xsl:copy-of select="./*" />
</personne>
<xsl:text>
</xsl:text>
</xsl:template>
</xsl:stylesheet>
Résultat :
<?xml version="1.0" encoding="UTF-8"?>
<personnes>
<personne age="48"><nom>DUPUIS</nom><prénom>Isabelle</prénom><ddn>1965</ddn></personne>
<personne age="50"><nom>DUPONT</nom><prénom>Jean</prénom><ddn>1963</ddn></personne>
<personne age="45"><nom>DUPONT</nom><prénom>Jack</prénom><ddn>1968</ddn></personne>
</personnes>
Et enfin voici un élément age pour pers02.xml :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- fichier aea4.xsl -->
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" />
<xsl:template match="/">
<xsl:text>
</xsl:text>
<personnes>
<xsl:apply-templates select="//personne" />
<xsl:text>
</xsl:text>
</personnes>
</xsl:template>
<xsl:template match="personne">
<xsl:text>
</xsl:text>
<personne>
<xsl:copy-of select="@*" />
<xsl:element name="age">
<xsl:value-of select="2013-@ddn"/>
</xsl:element>
</personne>
</xsl:template>
</xsl:stylesheet>
Résultat :
<?xml version="1.0" encoding="UTF-8"?>
<personnes>
<personne ddn="1965" nom="DUPUIS" prénom="Isabelle"><age>48</age></personne>
<personne ddn="1963" nom="DUPONT" prénom="Jean"><age>50</age></personne>
<personne ddn="1968" nom="DUPONT" prénom="Jack"><age>45</age></personne>
</personnes>
5.2 Ajout de "art" pour les id et idrefs
Attention : ici, il ne faut pas ajouter un élément ou un attribut, mais le modifier, en lui concaténant les trois lettres art en début de chaine. Heureusement, il y a une fonction XSL nommée xsl:concat.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!-- fichier ajoutart.xsl -->
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" />
<xsl:template match="/">
<xsl:text>
</xsl:text>
<FILMSETARTISTES>
<xsl:text>
</xsl:text>
<xsl:apply-templates select="//FILM" />
<xsl:apply-templates select="//ARTISTE" />
</FILMSETARTISTES>
</xsl:template>
<xsl:template match="ARTISTE">
<ARTISTE>
<xsl:attribute name="id">
<xsl:value-of select='concat("art",@id)' />
</xsl:attribute>
<xsl:copy-of select="*" />
</ARTISTE>
<xsl:text>
</xsl:text>
</xsl:template>
<xsl:template match="FILM">
<FILM>
<xsl:for-each select="*">
<xsl:choose>
<xsl:when test="position()=4">
<xsl:element name="MES">
<xsl:attribute name="idref">
<xsl:value-of select='concat("art",@idref)' />
</xsl:attribute>
</xsl:element>
<xsl:text>
</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:copy-of select="." />
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</FILM>
<xsl:text>
</xsl:text>
</xsl:template>
<xsl:template match="MES">
<MES>
<xsl:attribute name="idref">
<xsl:value-of select='concat("art",@idref)' />
</xsl:attribute>
</MES>
</xsl:template>
</xsl:stylesheet>
Dans le document films2.xml, combien y a-t-il de films ? Et d'artistes ? Combien de références pour combien de metteurs en scène ? On écrira une transformation XSL qui affichera ces résultats en mode texte qu'on exécutera avec xmlstarlet avant de modifier le document pour avoir un rendu dans une page Web valide pour la grammaire XHTML Strict.
Remarque : on pourra utiliser le fichier stdWeb2.xsl qui contient des sous-programmes XSL adaptés à la production de pages Web.
Fichier stdWeb2.xsl
Compter avec XSL se fait à l'aide de la fonction count() dans un attribut select d'un élément xsl:value-of. Encore faut-il trouver les noeuds correspondants. Pour les films et les artistes, c'est assez simple car les éléments FILM et ARTISTE identifient de façon unique ce qu'on cherche donc il suffit de compter //FILM et //ARTISTE.
Pour trouver les metteurs en scène, il faut retenir les attributs id de ARTISTE qui correspondent à un attribut idref de MES, soit le filtre ARTISTE[@id=//MES/@idref] -- bien noter le double slash devant MES. Nous avons rajouté dans la solution des xsl:text pour rendre les affichages plus lisibles (avec des indications de solution XSL 2) :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="ISO8859-15" />
<!-- fichier nbfa1.xsl, s'applique à films2.xml -->
<xsl:template match="/">
<xsl:text>Il y a </xsl:text>
<xsl:value-of select="count(//FILM)" />
<xsl:text> films dans films2.xml</xsl:text>
<xsl:text> et </xsl:text>
<xsl:value-of select="count(//ARTISTE)" />
<xsl:text> artistes.
</xsl:text>
<xsl:value-of select="count(//MES)" />
<xsl:text> références de metteurs en scènes sont utilisées pour </xsl:text>
<!-- ceci est du XSL 2 :
<xsl:value-of select="count(distinct-values(//MES))" />
-->
<xsl:value-of select="count(//ARTISTE[./@id=//MES/@idref])" />
<xsl:text> metteurs en scène distincts.
</xsl:text>
</xsl:template>
<!-- fin de document -->
</xsl:stylesheet>
$gh> xmlstarlet tr nbfa1.xsl films2.xml
Il y a 48 films dans films2.xml et 117 artistes.
48 références de metteurs en scènes sont utilisées pour 32 metteurs en scène distincts.
Produire une page Web résultat est un peu plus compliqué car il faut aussi produire du code HTML ce qui signifie qu'il faut sans doute utiliser deux espaces de noms distincts.
Voici la solution :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform' version="1.0">
<xsl:import href="stdWeb2.xsl" />
<xsl:output method="xml" encoding="ISO-8859-1"/>
<!-- fichier films2.xsl, s'applique à films2.xml,
exemple de résultat : films2_xsl.html
forcé en xml dans : films2_xsl.html.xml
-->
<xsl:template match="/">
<xsl:call-template name="debutPage">
<xsl:with-param name="leTitre">Films et artistes avec table des matières</xsl:with-param>
<xsl:with-param name="h1redite">no</xsl:with-param>
</xsl:call-template>
<xsl:call-template name="debutSection" />
<blockquote>
<h1>Comptages dans le fichier <a href="films2.xml">films2.xml</a></h1>
<p>
Il y a <b><xsl:value-of select="count(//FILM)" /></b> films dans ce fichier
et <strong><xsl:value-of select="count(//ARTISTE)" /></strong> artistes.
</p>
<p>
<span class="grougef"><xsl:value-of select="count(//MES)" /></span>
références de metteurs en scènes sont utilisées pour
<!-- ceci est du XSL 2 :
<xsl:value-of select="count(distinct-values(//MES))" />
-->
<span class="gbleuf"><xsl:value-of select="count(//ARTISTE[./@id=//MES/@idref])" /></span>
metteurs en scène distincts.
</p>
</blockquote>
<xsl:call-template name="finSection" />
<xsl:call-template name="finPage" />
</xsl:template>
<!-- fin de document -->
</xsl:stylesheet>
Le rendu correspondant est ici.
On voudrait effectuer des calculs statistiques et tracer des graphiques pour étudier statistiquement la longueur des protéines du fichier leadb880.xml. Que peut-on calculer et tracer via XSL ?
Est-ce qu'écrire un script PHP est ici adapté ?
XSL ne peut pas grand chose pour nous ici car XSL est conçu pour transformer du texte, pas pour calculer. PHP n'est pas vraiment non plus prévu pour réaliser des traitements statistiques. Par contre XSL peut nous aider à produire un fichier CSV utilisable par Excel, le logiciel R ou tout autre logiciel statistique. Pour cela, il suffit d'exporter le nom de chaque protéine, sa classe et sa longueur. C'est ce que fait la transformation suivante :
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" />
<xsl:template match="/">
<xsl:text>Protein ; Classe ; Longueur</xsl:text>
<xsl:apply-templates match="protein" />
</xsl:template>
<xsl:template match="protein">
<xsl:value-of select="accession" />;<xsl:value-of select="class" />;<xsl:value-of select="fasta/@length" />
</xsl:template>
</xsl:stylesheet>
On pourra vérifier que les données obtenues par la commande xsltproc prot_export.xsl leadb880.xml | grep -v "^$" | head soit le fichier prot_export.csv est utilisable par Microsoft Office Excel ou par Libre Office Calc :
On peut alors analyser ces données via le script R suivant
## lecture du fichier de longueurs de protéines et analyse univariée
source("http://forge.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1")
prot <- read.csv("prot_export.csv",sep=";",head=TRUE)
gr("protLng.png")
decritQT("Longueur",prot$Longueur,"aa",TRUE)
dev.off()
qui produit les résultats ci-dessous
DESCRIPTION STATISTIQUE DE LA VARIABLE Longueur
Taille 880 individus
Moyenne 193.4989 aa
Ecart-type 102.3758 aa
Coef. de variation 53 %
1er Quartile 130.0000 aa
Mediane 167.0000 aa
3eme Quartile 229.0000 aa
iqr absolu 99.0000 aa
iqr relatif 59.0000 %
Minimum 66.000 aa
Maximum 843.000 aa
Tracé tige et feuilles
The decimal point is 2 digit(s) to the right of the |
0 | 77777888888899999999999999999999999999999999999999999999999999999999
1 | 00000000000000000000000000000000000000000000000000000000000111111111+142
1 | 55555555555555555555555555555555555555555555555555555555555555555566+177
2 | 00000000000000000000000000000000000000000111111111111111111112222222+64
2 | 55555555555555555555666666666666666666666666666666777777777788888888
3 | 00000000000111111222222222222333333333344444444
3 | 5555555566667889999
4 | 0111223
4 | 556677777889
5 | 00124
5 | 566888
6 | 1234
6 |
7 | 344
7 |
8 | 24
ainsi que le graphique suivant :
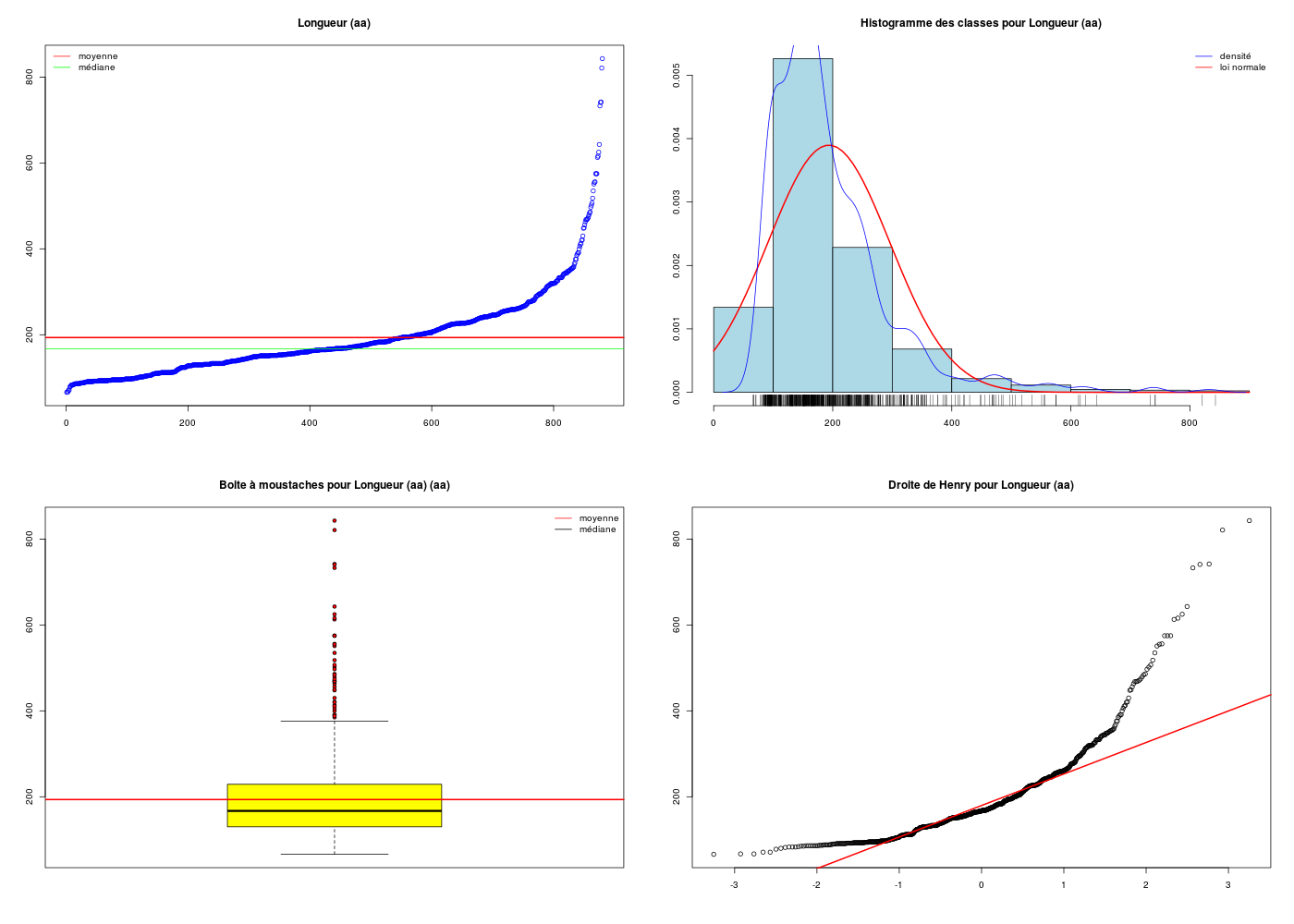
Nous laissons le soin au lecteur de rédiger le commentaire statistique associé. Le script R utilise notre fonction decritQT() décrite ici.
Questions sans réponse affichée dans le navigateur (donc venez en TP !)
-
Pourquoi est-ce difficile de construire une grammaire XSD fine et précise pour les protéines LEA si on n'est pas biologiste ?
-
Comment faire pour trouver les attributs uniques si on ne connait pas l'option -u de la commande sort ?
-
Peut-on compter des "non-éléments" ou des éléments sans attributs ? Par exemple, pour films2.xml combien manque-t-il de résumés ? et de dates de naissance ?
-
Pourquoi faut-il compter les attributs avec /@ plutôt qu'avec seulement @ ?
Code-source php de cette page.
|
{kind=link}
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)