Essayer en mode interactif avec tclsh de donner la ou les instructions qui répondent aux mêmes questions que pour Rexx en mode interactif, exercice 4 de la série 2.
Consulter le fichier tclsh.txt :
% set x [expr pow(16,4)]
65536.0
% set y [ expr 2012%128]
92
% set a [format %X [scan "A" %c]]
41
% set b [scan "FFF" %x ]
4095
% set c [format %d [scan "a" %c] ]
97
% set d [format %c 98]
b
% set cmd "prog --fmt tex --nbdec 4 --fichier demo.rex"
prog --fmt tex --nbdec 4 --fichier demo.rex
% set e [lindex $cmd [expr 1+[lsearch $cmd "--fmt"]]]
tex
% set phr "A2837 12 18 37 25"
A2837 12 18 37 25
% set f [lrange $phr 1 [llength $phr]]
12 18 37 25
% set f 1
% for { set i 1 } { $i <= 8 } { incr i } { set f [expr $f*$i] }
% puts $f
40320
% set h [ clock format [clock seconds] -format "Le %d/%m/%y a %H:%M" ]
Le 25/11/12 a 12:49
% set v "12 5 20 8 15"
12 5 20 8 15
% set s 0
0
% # mieux que : for { set i 0 } { $i < [llength $v] } { incr i } { set s [expr $s + [lindex $v $i]] }
% foreach x $v { set s [expr $s + $x] }
% set m [expr $s/[llength $v]]
12
Implémenter une version tcl de la sauvegarde incrémentale de fichiers XML comme pour l'exercice 7 de la série 2 .
Consulter le fichier archcd.tcl :
set numarchive 1
set nomarchive "lesxml[format "%03d" $numarchive].tar"
while { [file exists $nomarchive] } {
set numarchive [incr numarchive]
set nomarchive "lesxml[format "%03d" $numarchive].tar"
} ; # fin de tant que
# unix :
set specfic "*.xml"
set rc [exec echo tar -cvf $nomarchive $specfic > archauto ]
set rc [exec sh archauto ]
# dos :
# set specfic "*\\*.xml"
# set rc [exec tar -cvf $nomarchive $specfic ] set rc [exec echo tar -cvf $nomarchive $specfic > archauto ]
puts "\[tcl\] archivage des fichiers $specfic dans $nomarchive terminée."
label .okarch -text " archivage des fichiers $specfic dans $nomarchive terminée." \
-fg "blue" -bg "yellow" -font { Arial 20 bold }
pack .okarch
after 5000 exit
On veut mettre à disposition des utilisateurs un système de choix de répertoires à sauvegarder. Voici ce qu'on voudrait voir sous Linux :

Et sous Windows :
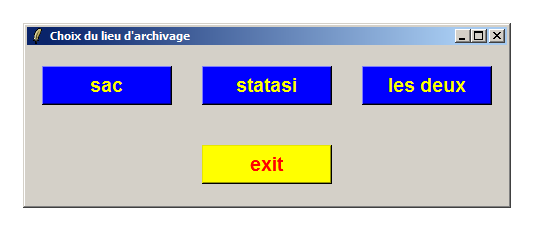
Ecrire un programme TK pour cela. Le programme devra s'exécuter tel quel aussi bien sous Linux que sous Windows.
Consulter le fichier archglob.tcl :
wm title . " Choix du lieu d'archivage"
# tableau pour simuler une table de hachage
set courts "sac statasi"
set longs "~/public_html/Farcompr /home/info/gh/Crs/Stat/Asi"
for { set idm 0 } { $idm < [llength $courts] } { set idm [incr idm] } {
set racco [lindex $courts $idm]
set lieuc [lindex $longs $idm]
set lieu($racco) $lieuc
} ; # fin pour idm
# boutons
frame .choix
set cfgBout "-font { Arial 14 bold } -width 10 -fg \"yellow\" -bg \"blue\" "
eval "button .choix.lieu1 -text [lindex $courts 0] $cfgBout -command { specf [lindex $courts 0] } "
eval "button .choix.lieu2 -text [lindex $courts 1] $cfgBout -command { specf [lindex $courts 1] } "
eval "button .choix.lieux -text \"les deux\" $cfgBout -command { specf \"$courts\" } "
frame .exit
button .exit.bout -text "exit" -font { Arial 14 bold } -width 10 -fg "red" -bg "yellow" -command exit
pack .choix -side top
pack .exit -side bottom
pack .choix.lieu1 .choix.lieu2 .choix.lieux -padx 15 -pady 20 -side left
pack .exit.bout -padx 15 -pady 20
# touche rapide pour quitter
bind . <q> exit
# sous-programme pour exécution de l'archivage
proc specf { ligp } { global lieu
set specfi ""
foreach idp $ligp {
set specfi "$specfi $lieu($idp)"
} ; # fin de pour chaque
label .spec -text " specifications : $specfi " \
-fg "blue" -bg "yellow" -font { Courier 14 bold }
destroy .choix .exit
pack .spec
after 5000 exit
} ; # fin de procédure specf
En mode interactif, avec pt.pl donner la ou les instructions qui répondent aux mêmes questions que pour Rexx en mode interactif, exercice 4 de la série 2.
Consulter le fichier perl_pt.txt :
$gh> pt
(gH) 2001 -- cli.pl
## taper vos instructions perl sur une seule ligne
## il faut parfois utiliser 2 fois la touche "up"
## pour rappeler les commandes précédentes
## (on quitte par ^C, par <ENTER> ou par exit ;)
perl> 16**4 ;
65536
perl> 2012%128 ;
92
perl> sprintf("%x", ord("A") )
41
perl> hex("FFF")
4095
perl> ord("a")
97
perl> chr(98)
b
perl> $cmd = "prog --fmt tex --nbdec 4 --fichier demo.rex" ;
prog --fmt tex --nbdec 4 --fichier demo.rex
perl> $cmd = ~/--fmt (.*?) / ; print "$1 \n" ;
tex
1
perl> $phr = "A2837 12 18 37 25" ;
perl> @phr = split(" ",$phr) ;
perl> shift(@phr) ;
perl> print "phr @phr \n" ;
phr 12 18 37 25
perl> $f = 1 ; $f *= $_ for 1..8 ; # $f = 0 par défaut...
perl> print " factorielle 8 = $f \n" ;
factorielle 8 = 40320
perl> @tv= split(" ","12 5 20 8 15") ; foreach $v (@tv) { $s += $v } ; $s /= $#tv ;
perl> localtime() ;
Sat Dec 1 17:22:54 2012
Donner une expression perl en mode one liner qui indique si un nombre est premier ; on utilisera une expression régulière. Est-ce efficace pour des grands nombres ? Que peut-on en conclure sur les expressions régulières ? et sur Perl ?
Voici une solution qui n'affiche rien si le nombre n'est pas premier et qui écrit explicitement quand le nombre est premier :
$gh> perl -le '$_=shift ; (1x$_) !~ /^1?$|^(11+?)\1+$/ && print "$_ is prime"' 7
7 is prime
$gh> perl -le '$_=shift ; (1x$_) !~ /^1?$|^(11+?)\1+$/ && print "$_ is prime"' 50
Si vous n'avez pas tout compris, une explication est là.
Ce n'est sans doute pas très efficace, quoique... Cela montre la force des expressions régulières. On verra avec d'autres langages comment réutiliser cette expression régulière. Par exemple, il est possible de consulter la référence 1827 de wfr.tcl.tk pour en voir l'implémentation en Tcl.
Implémenter une version Perl de la sauvegarde incrémentale de fichiers XML comme pour l'exercice 7 de la série 2 .
Reprendre ensuite le script Perl en ajoutant use strict ; en haut du script. Que faut-il alors changer pour ne pas avoir d'erreurs d'interprétation ?
Consulter le fichier archcd.pl :
$numarchive = 1 ;
$nomarchive = "lesxml".sprintf("%03d",$numarchive).".tar" ;
while (-s $nomarchive) {
$numarchive++ ;
$nomarchive = "lesxml".sprintf("%03d",$numarchive).".tar" ;
} ; # fin de tant que
$specfic = "*.xml" ;
system("tar -cf $nomarchive $specfic") ;
print "[perl] archivage des fichiers $specfic dans $nomarchive terminée\n" ;
Avec use strict ; toute variable locale doit être déclarée à l'aide de my. Il faut donc ajouter trois my au script :
use strict ;
my $numarchive = 1 ;
my $nomarchive = "lesxml".sprintf("%03d",$numarchive).".tar" ;
while (-s $nomarchive) {
$numarchive++ ;
$nomarchive = "lesxml".sprintf("%03d",$numarchive).".tar" ;
} ; # fin de tant que
my $specfic = "*.xml" ;
system("tar -cf $nomarchive $specfic") ;
print "[perl] archivage des fichiers $specfic dans $nomarchive terminée\n" ;
Expliquer ce que fait le programme striphtml.pl dont la partie importante est listée ci-dessous avec des numéros de ligne :
0022 require 5.002;
0023
0024 #########################################################
0025 # first we'll shoot all the <!-- comments -->
0026 #########################################################
0027
0028 s{ <! # comments begin with a `<!'
0029 # followed by 0 or more comments;
0030
0031 (.*?) # this is actually to eat up comments in non
0032 # random places
0033
0034 ( # not suppose to have any white space here
0035
0036 # just a quick start;
0037 -- # each comment starts with a `--'
0038 .*? # and includes all text up to and including
0039 -- # the *next* occurrence of `--'
0040 \s* # and may have trailing while space
0041 # (albeit not leading white space XXX)
0042 )+ # repetire ad libitum XXX should be * not +
0043 (.*?) # trailing non comment text
0044 > # up to a `>'
0045 }{
0046 if ($1 || $3) { # this silliness for embedded comments in tags
0047 "<!$1 $3>";
0048 }
0049 }gesx; # mutate into nada, nothing, and niente
0050
0051 #########################################################
0052 # next we'll remove all the <tags>
0053 #########################################################
0054
0055 s{ < # opening angle bracket
0056
0057 (?: # Non-backreffing grouping paren
0058 [
0059 | # or else
0060 ".*?" # a section between double quotes (stingy match)
0061 | # or else
0062 '.*?' # a section between single quotes (stingy match)
0063 ) + # repetire ad libitum
0064 # hm.... are null tags <> legal? XXX
0065 > # closing angle bracket
0066 }{}gsx; # mutate into nada, nothing, and niente
0067
0068 #########################################################
0069 # finally we'll translate all &valid; HTML 2.0 entities
0070 #########################################################
0071
0072 s{ (
0073 & # an entity starts with a semicolon
0074 (
0075 \x23\d+ # and is either a pound (#) and numbers
0076 | # or else
0077 \w+ # has alphanumunders up to a semi
0078 )
0079 ;? # a semi terminates AS DOES ANYTHING ELSE (XXX)
0080 )
0081 } {
0082
0083 $entity{$2} # if it's a known entity use that
0084 || # but otherwise
0085 $1 # leave what we'd found; NO WARNINGS (XXX)
0086
0087 }gex; # execute replacement -- that's code not a string
On pourra l'appliquer aux deux fichiers f1.html et f2.html qui sont des portions HTML -- non nécessairement valides -- pour tester ce qui se passe.
Le programme Perl enlève toutes les balises HTML et convertit les entités. Ainsi, pour f1.html on passe de
<body class="beige_jpg">
<blockquote>
<p class='align_right'>
Mon premier paragraphe commence par <p>.
</p>
<p><!-- un piège </p> -->
Et un second paragraphe, sans doute.
<p>
</body>
au fichier texte tout simple (mais avec tous les retours-charriot)
Mon premier paragraphe commence par <p>.
Et un second paragraphe, sans doute.
Ce programme prend en compte les commentaires via la première substitution. Sans cela, pour notre fichier on obtiendrait
Mon premier paragraphe commence par <p>.
-->
Et un second paragraphe, sans doute.
Une solution ultra-courte mais incorrecte est ici.
Essayer de réaliser l'exercice 3 de la série 2 (création des dictionnaires) en PERL.
Consulter le fichier dico.pl. On appréciera la concision des tris.
# (gH) -_- dicopl.pl ; TimeStamp (unix) : 24 Juin 2008 vers 16:48
# test des paramètres
if ($ARGV[0] eq "") { # aide en mode here-doc
print <<AIDE;
dico.pl ; création des dictionnaires alphabétiques et fréquentiels d'un texte
syntaxe : perl dico.pl FICHIER
exemple : perl dico.pl texte.txt
les fichiers produits sont dico.tpm et dico.tpo
dico.tpm : tri par mot croissant
dico.tpo : tri par fréquence décroissante
puis par mot croissant an cas d'égalité
AIDE
exit(-1) ;
} ; # fin de test sur les arguments
$fictxt = $ARGV[0] ; # récupération du nom du fichier
# ouverture du fichier
open( FICT ,"<$fictxt") || die "\n impossible d'ouvrir le fichier nommé $fictxt \n\n" ;
# parcours du fichier, remplissage du hachage au passage
$nbLig = 0 ; # nombre de lignes du fichier
$nbMot = 0 ; # nombre de mots en tout
$nbMdi = 0 ; # nombre de mots différents
while ($ligne=<FICT>) {
$nbLig++ ;
chop($ligne) ;
# on élimine la ponctuation
$ligne =~ tr/-,.:!'"();/ / ;
# on élimine le double tiret
$ligne =~ s/--//g ;
@mots = split(/ /,$ligne) ;
foreach $m (@mots) {
if (length($m)>0) {
$nbMot++;
$cntMot{$m}++ ;
if ($cntMot{$m}==1) {
$nbMdi++ ;
} ; # finsi nouveau mot
} ; # finsi mot non vide
} ; # fin pour chaque mot
} ; # fin de tant que
print " Analyse du fichier $fictxt :" ;
print " on a vu $nbMot mot(s) sur $nbLig ligne(s)" ;
print " et $nbMdi mot(s) différent(s).\n" ;
$dicNom = "dico.tpm" ; # fichier alphabétique
$dicOcc = "dico.tpo" ; # fichier fréquenciel
open(DICM,">$dicNom ") or die ("impossible d'écrire dans $dicNom") ;
foreach $m (sort keys(%cntMot)) {
print DICM sprintf(" %-20s",$m).sprintf("%4d",$cntMot{$m})."\n" ;
# on en profite pour remplir un tableau pour les occurences
# concaténées avec les mots pour préparer le tri multicritères
$cle = sprintf("%06d",$cntMot{$m})."_$m" ;
$tabMot{$cle}=$m ;
} ; # fin pour chaque
close(DICM) ;
print "le fichier $dicNom contient les mots par ordre alphabétique.\n" ;
open(DICK,">$dicOcc ") or die ("impossible d'écrire dans $dicOcc") ;
foreach $c (reverse sort occPuisMot keys(%tabMot)) {
# on sait comment Perl convertit les %s en %c, on en profite :
print DICK sprintf(" %-20s",$tabMot{$c}).sprintf("%4d",$c)."\n" ;
} ; # fin pour chaque
close(DICK) ;
print "le fichier $dicOcc contient les mots par ordre décroissant d'occurrences.\n" ;
sub occPuisMot {
$a =~ /(.*?)_(.*)/ ; ($mota,$occa) = ($2,$1) ;
$b =~ /(.*?)_(.*)/ ; ($motb,$occb) = ($2,$1) ;
local($test_num) = $occa <=> $occb ;
if ($test_num) {return $test_num ;}
return $motb cmp $mota ;
} # fin du sous-programme de tri multicritères
On voudrait disposer d'un convertisseur cm/pouces et pouces/cm sachant qu'un pouce fait 2,54 cm. Réaliser l'implémentation en ligne de commandes avec paramètres en Rexx, Tcl et Perl puis réaliser une implémentation avec interface graphique en Tcl/Tk puis en Rexx/Tk et Perl/Tk.
On commencera par vérifier l'installation de Tk et l'exemple élémentaire fourni en bas de la page tkdocs-install.
Solution volontairement non communiquée.
Code-source php de cette page ; code javascript utilisé. Retour à la page principale du cours.
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)