Décomposition, Conception et Réalisation d'Applications
T.D. 4 : Expressions régulières, tests et nombres aléatoires
gilles.hunault "at" univ-angers.fr
1. Le paradigme "Expressions régulières"
Les expressions régulières sont un moyen souvent sous-estimé ou sous-utilisé de détecter, extraire et remplacer des blocs de chaines de caractères, blocs éventuellement non contigus. On pourra lire notre tuteur sur les expressions régulières pour se rafraichir les idées sur leur définition et leur utilisation. Pour maitriser le sujet, l'ouvrage suivant est parfait :

Voici donc des exercices pour ces trois types d'actions que fournissent les expressions régulières.
1.1 Paraphrases
Essayer de décrire par des phrases à quoi correspondent les expressions régulières suivantes :
-
[1-9][0-9]?|100
-
^[A-Z][a-z]*$
-
(^\s+)|(\s+$)
Expliquer ensuite la différence entre les commandes suivantes :
grep "%AB[^C]" *.txt
grep "%AB" *.txt | grep -v "%ABC"
1.2 Quelques expressions à trouver
Essayer de trouver des expressions régulières qui correspondent aux descriptions suivantes :
-
un nombre entier entre 0 et 23, avec éventuellement un 0 non significatif comme 08 pour les nombres inférieurs à 10 (de quoi s'agit-il ?) ;
-
les anciens et nouveaux numéros de plaques d'immatriculation des voitures en France ;
-
un email valide.
1.3 Détecter, extraire et remplacer avec des expressions régulières
Voici trois grands standards en expressions régulières :
-
tester si une chaine est un nombre entier strictement positif ;
-
extraire la valeur d'un élément input dans une page Web ;
-
convertir une date française JJ-MM-AAAA en une date internationalisée AAAA-MM-JJ.
Réaliser ces trois opérations dans les langages suivants : Perl, Php, Javascript, R et Python. Afin d'homogéniser le code informatique, on nommera inpAge la chaine censée contenir l'entier, entree l'ensemble de l'élément input (supposé bien formé au sens de XML), et dateFR la date.
Voici des exemples à tester :
|
Variable
|
Contenu
|
Résultat(s)
|
| inpAge |
25 / bof |
OK / Pas OK |
| entree |
<input id='pomme' type='text' value='5' class='demo' /> |
5 |
| dateFR |
31-08-1957 |
1957-08-31 |
On pourra utiliser les sites rubular et regex-tester pour tester les expressions régulières à utiliser, puis le site regex101 pour générer le code associé.
1.4 Un peu de culture sur les expressions régulières
Qu'affichent les commandes suivantes, basées sur Perl et une expression régulière ?
perl -le '$_=shift ; (1x$_) !~ /^1?$|^(11+?)\1+$/ && print "$_ OUI"' 7
perl -le '$_=shift ; (1x$_) !~ /^1?$|^(11+?)\1+$/ && print "$_ OUI"' 50
Que faut-il déduire de l'instruction MySQL suivante ?
select if( "ABC" REGEXP "^ABC", 1 , 0 ) ;
1.1 Paraphrases
La première expression régulière, soit [1-9][0-9]?|100 se décode en deux parties [1-9][0-9]? ou 100. Cette deuxième partie est juste le nombre 100. La première partie se décompose en une partie obligatoire [1-9] et une partie facultative [0-9]?. Comme la partie obligatoire correspond à un entier entre 1 et 9 et la partie facultative à un nombre entre 0 et 9, il s'agit d'un nombre entre 1 et 99. Au final, l'expression désigne un entier strictement positif inférieur ou égal à 100. Comme il n'y a ni ^ ni $, utiliser cette expression régulière en détection revient à savoir si une chaine de caractères contient un tel entier.
La deuxième expression régulière, soit ^[A_Z][a-z]*$ se décode en quatre parties, à savoir ^ et [A-Z] puis [a-z]* et enfin $. Comme [A_Z] signifie une lettre en majuscule et [a-z]* désigne la chaine vide ou un ou plusieurs caractères minuscules, on peut en déduire qu'il s'agit d'une chaine réduite à un seul mot composé d'une initiale majuscule puis éventuellement de minuscules.
La troisième expression régulière, soit (^\s+)|(\s+$) se décode en deux parties, à savoir (^\s+) ou (\s+$). La première partie signifie «qui commence par au moins un espace» et la seconde «qui finit par au moins un espace». Cette expression régulière permet de détecter des lignes qui contiennent des espaces en début ou en fin de ligne. Les parenthèses ne sont pas ici obligatoires.
La première commande vient afficher toutes les lignes qui contiennent %AB suivi de quelque chose qui n'est pas C. Donc si une ligne contient à la fois %ABC et %ABD elle sera affichée. La deuxième commande vient afficher toutes les lignes qui contiennent %AB mais pas %ABC en deux temps : on retient toutes les lignes qui contiennent %AB puis on retire celles qui contiennent %ABC. Une ligne qui contiendrait à la fois %ABC et %ABD ne serait alors pas affichée.
1.2 Quelques expressions à trouver
Pour la première expression, il s'agit d'une heure exprimée au format H ou HH à l'européenne, c'est-à-dire sur 24 heures. Les valeurs 0 à 9 sont décrites par l'expression [0-9], les valeurs 0 à 19 sont décrites par l'expression [0-1]?[0-9] et les valeurs 20 à 23 sont décrites par l'expression 2[0-3] donc une expression régulière solution est [0-1]?[0-9]|2[0-3]. Ce n'est bien sûr pas la seule solution. Ainsi [012]?[0-3]|[0-1]?[4-9] est aussi solution.
Les anciennes plaques d'immatriculation françaises (de 1950 à 2009) comportaient de 1 à 4 chiffres, puis 2 lettres majuscules exactement, puis 2 chiffres exactement, soit \d{1,4}[A-Z]{2}\d{2}. Les nouvelles plaques se composent de 2 lettres majuscules, d'un tiret, de 3 chiffres, d'un tiret et enfin de 2 lettres majuscules. On peut donc les représenter par [A-Z]{2}-\d{3}-[A-Z]{2}.
Savoir si un email est valide ne peut pas se résoudre avec une expression régulière. Il faudrait pour cela savoir si l'adresse mail existe vraiment. Par contre on peut tester si une chaine correspond au format usuel des adresses mail, à savoir au moins une minuscule, suivie de minuscules, de chiffres, de points, de tirets ou de soulignés puis le symbole @ puis des lettres minuscules ou des tirets et enfin un point et deux lettres, soit de façon rapide [a-z][-._a-z0-9]+@[a-z][-._a-z0-9]+\.[a-z]{2}. On notera que la spécification officielle (voir les numéros de RFC dans la page wiki adresse électronique) autorise beaucoup plus de caractères, dont des caractères accentués et qu'il y a des restrictions sur le nombre de caractères.
1.3 Détecter, extraire et remplacer avec des expressions régulières
On trouvera ci-dessous des extraits de code réalisant ces actions dans les langages indiqués.
# ce script perl peut s'exécuter via perl -w regexp.pl
my $inpAge = 25 ; # mettre 25.2 ou "non" comme cas négatif
my $reAge = "^[1-9][0-9]" ;
if ($inpAge =~ m/$reAge/) { # if ($inpAge =~ m/^[1-9][0-9]/) était suffisant
print("il s'agit d'un entier strictement positif.\n") ;
} else {
print("il ne s'agit pas d'un entier strictement positif.\n") ;
} ; # fin si
my $entree = "<input id='pomme' type='text' value='5' class='demo' />" ;
my $reEntr = "<input .*?value='(.*?)'" ;
$entree =~ m/$reEntr/ ;
print("la valeur est ".$1."\n") ;
my $dateFR = "31-08-1957" ;
my $dateUS = $dateFR ;
$dateUS =~ s/([0-9]+?)-([0-9]+?)-([0-9]+)/$3-$2-$1/ ;
print($dateUS."\n") ;
<?php # ce script php s'exécute en ligne de commandes via php -f regexp.php
$inpAge = 25 ; # mettre 25.2 ou "non" comme cas négatif
$reAge = "^[1-9][0-9]*$" ;
if (preg_match("/$reAge/",$inpAge)) { # if (preg_match("/^[1-9][0-9]*$/",$inpAge)) était suffisant
echo "il s'agit d'un entier strictement positif.\n" ;
} else {
echo "il ne s'agit pas d'un entier strictement positif.\n" ;
} # fin si
$entree = "<input id='pomme' type='text' value='5' class='demo' />" ;
preg_match("/<input .*?value='(.*?)'/",$entree,$tabEnt) ;
echo "la valeur est $tabEnt[1].\n" ;
$dateFR = "31-08-1957" ;
$dateUS = preg_replace("/([0-9]+?)-([0-9]+?)-([0-9]+)/","$3-$2-$1",$dateFR) ;
echo $dateUS."\n" ;
?>
// ce script Javascript s'exécute en ligne de commandes via rhino -f regexp.js
// mettre console.log(*) au lieu de print(*) pour la version nodejs
var inpAge = 25 // mettre 25.2 ou "non" comme cas négatif
var reAge = new RegExp("^[1-9][0-9]*$")
if (reAge.test(inpAge)) {
print("il s'agit d'un entier strictement positif.")
} else {
print("il ne s'agit pas d'un entier strictement positif.")
} // fin si
var entree = "<input id='pomme' type='text' value='5' class='demo' />"
var reEntr = new RegExp("<input .*?value='(.*?)'")
var tabEnt = reEntr.exec(entree)
print("la valeur est "+tabEnt[1])
var dateFR = "31-08-1957"
var reDate = new RegExp("([0-9]+?)-([0-9]+?)-([0-9]+)")
var dateUS = dateFR.replace(reDate,"$3-$2-$1")
print(dateUS)
# ce script R s'exécute via Rscript --vanilla regexp.r
library("stringr")
inpAge <- 25 # mettre 25.2 ou "non" comme cas négatif
if (str_detect(pattern="^[1-9][0-9]*$",string=inpAge)) {
cat("il s'agit d'un entier strictement positif.\n")
} else {
cat("il ne s'agit pas d'un entier strictement positif.\n")
} # fin si
entree <- "<input id='pomme' type='text' value='5' class='demo' />"
reEntr <- "<input .*?value='(.*?)'"
tabEnt <- str_match(entree,reEntr)
cat("la valeur est ",tabEnt[2],"\n") ;
dateFR <- "31-08-1957"
dateUS <- str_replace("31-08-1957","([0-9]+?)-([0-9]+?)-([0-9]+)","\\3-\\2-\\1")
cat(dateUS,"\n")
# -*- coding:latin1 -*-
# ce script python s'exécute via python3 regexp.py
import re
inpAge = 25 # mettre 25.2 ou "non" comme cas invalide
reAge = r"^[1-9][0-9]*$"
if (re.search(reAge,str(inpAge))) :
print("il s'agit d'un entier strictement positif.")
else :
print("il ne s'agit pas d'un entier strictement positif.")
# fin si
entree = "<input id='pomme' type='text' value='5' class='demo' />"
reEntr = r"<input .*?value='(?P<ent>.*?)'"
rep = re.search(reEntr,entree)
valEnt = rep.group('ent')
print("la valeur est ",valEnt)
dateFR = "31-08-1957"
reDate = r"([0-9]+?)-([0-9]+?)-([0-9]+)"
subst = "\\3-\\2-\\1"
dateUS = re.sub(reDate, subst, dateFR)
print(dateUS)
Voici les résultats d'exécution :
$gh> perl -w regexp.pl
il s'agit d'un entier strictement positif.
la valeur est 5
1957-08-31
$gh> php regexp.php
il s'agit d'un entier strictement positif.
la valeur est 5
1957-08-31
$gh> rhino regexp.js
il s'agit d'un entier strictement positif.
la valeur est 5
1957-08-31
$gh> Rscript --vanilla regexp.r
il ne s'agit pas d'un entier strictement positif.
la valeur est 5
1957-08-31
$gh> python3 regexp.py
il s'agit d'un entier strictement positif.
la valeur est 5
1957-08-31
1.4 Un peu de culture sur les expressions régulières
Le code proposé pour Perl affiche le nombre suivi de OUI si le nombre est premier mais il n'affiche rien si le nombre n'est pas premier.
Si vous n'avez pas tout compris, une explication est là.
Ce n'est sans doute pas très efficace, quoique... Cela montre la force des expressions régulières. Il est bien sûr possible de réutiliser cette expression régulière avec d'autres langages. Par exemple, il est possible de consulter la référence 1827 de wfr.tcl.tk pour en voir l'implémentation en Tcl.
La deuxième commande indiquée montre que MySQL sait utiliser les expressions régulières. Voir par exemple la page expreg-mysql. On notera qu'il existe une version plus légère des expressions régulières avec l'opérateur LIKE.
2. Programmation concise en Php
On cherche à trouver le nombre de fois où le mot ANGERS est écrit dans un fichier texte, sachant que le mot peut aussi être écrit Angers ou angers. Pour simplifier le problème, on admettra que ce mot Angers est toujours précédé d'un espace et suivi d'un espace, d'une virgule ou d'un point à moins que ce ne soit en début de ligne ou en fin de ligne.
Donner le code Php qui lit un fichier texte nommé villes.txt supposé présent et qui renvoie le nombre de fois où on trouve ce mot ANGERS. On n'utlisera que les fonctions suivantes : fopen(), fgets(), fclose(), str_replace(), strpos() et substr().
Voici le contenu du fichier villes.txt :
ANGERS et NANTES sont deux villes de l'ouest de la France.
Si Angers est dans le département 49, Nantes est dans le 44.
On peut dire que les universités à Angers, Nantes et le Mans sont des universités actives.
Il n'y a pas de dangers ni de risques à dire qu'angers est une ville où il fait bon vivre.
Angers, Nantes ou Nantes, Angers ? Difficile à dire.
Reprendre l'exercice en utilisant cette fois uniquement les fonctions file_get_contents() et str_replace(), preg_match_all().
Quel code est le plus concis ?
Comment fonctionnent les fonctions array_sum() et array_filter en Php ?
Est-ce que array_filter simplifie la résolution du problème du comptage des occurrences de "ANGERS" ?
Voici la solution 1 :
<?php
## lecture de villes.txt et comptages du mot Angers
$fn = "villes.txt" ;
if (!file_exists($fn)) {
echo "\nLe fichier $fn n'existe pas. Stop.\n" ;
exit(-1) ;
} ; # fin si
# lecture et remplacement des caractères spéciaux par espace
# au passage, on convertit en minuscule
$contenu = "" ;
$fh = fopen($fn,"r") ;
$symb = array(",",".","'","\n") ;
while ($lig = fgets($fh,4096)) {
$contenu .= " ".str_replace($symb," ",strtolower($lig))." " ;
} ; # fin tant que
fclose($fh) ;
# recherche des occurrences d'Angers
$nbAngers = 0 ;
$lngContenu = strlen($contenu) ;
$idc = 0 ;
while ($idc<=$lngContenu) {
$jdc = strpos($contenu," angers ",$idc) ;
if ($jdc>0) {
$nbAngers++ ;
$idc = $jdc + 1 ; # car angers a 6 lettres
} else {
$idc++ ;
} ; # fin si
} ; # fin tant que
echo " Angers est vu $nbAngers fois dans le fichier $fn.\n" ;
?>
Et la solution 2, plus concise :
<?php
## lecture de villes.txt et comptages du mot Angers
$fn = "villes.txt" ;
if (!file_exists($fn)) {
echo "\nLe fichier $fn n'existe pas. Stop.\n" ;
exit(-1) ;
} ; # fin si
$contenu = file_get_contents($fn) ;
$symb = array(",",".","'","\n") ;
$contenu = " ".str_replace($symb," ",$contenu)." " ;
$nbAngers = preg_match_all("/ angers /i",$contenu,$vu) ;
echo " Angers est vu $nbAngers fois dans le fichier $fn.\n" ;
?>
La solution 3, avec array_filter ci-dessous :
<?php
function angers($x="") {
return( strtolower($x)=="angers" ) ;
} ; # fin fonction angers
## lecture de villes.txt et comptages du mot Angers
$fn = "villes.txt" ;
if (!file_exists($fn)) {
echo "\nLe fichier $fn n'existe pas. Stop.\n" ;
exit(-1) ;
} ; # fin si
$contenu = file_get_contents($fn) ;
$symb = array(",",".","'","\n") ;
$contenu = " ".str_replace($symb," ",$contenu)." " ;
$mots = preg_split("/\s+/",$contenu) ;
$tangers = array_filter($mots,"angers") ; # c'est ici qu'on utilise la fonction angers
$nbAngers = count($tangers) ;
echo " Angers est vu $nbAngers fois dans le fichier $fn.\n" ;
?>
montre que dans le langage Php la notion de fonction "appelable" est implémentée. En fait, les fonctions anonymes existent aussi, comme le montre la page du manuel associée.
La page de manuel nommée ref.array montre que Php est très riche en fonctions, même s'il faut du temps pour toutes les connaitre et les maitriser, sachant que de nombreuses fonctions PCRE sont capables de remplir ou de renvoyer des tableaux...
3. Test d'une page Web par script
Il est assez facile d'écrire des tests pour une application qui s'exécute en ligne de commandes, ou pour tester une classe d'objets, par exe Php avec phpunit. Mais comment tester si une page Web s'affiche correctement ? Comment tester si appuyer sur le bouton Envoyer d'un formulaire Web envoie bien sur la bonne page ?
Essayer de décrire ce que fait le code Python suivant :
# fichier pythonSelenium.py
from selenium import webdriver
import time
browser = webdriver.Firefox()
time.sleep(3)
browser.maximize_window()
time.sleep(3)
browser.get("http://google.fr")
time.sleep(3)
search_field = browser.find_element_by_name("q")
search_field.clear()
search_field.send_keys("pomme")
search_field.submit()
time.sleep(5)
browser.quit()
Essayer ensuite de comprendre ce que fait le code Python suivant :
# -*- coding:latin1 -*-
import requests
import re
try :
page = "http://localhost/~gh/internet/Lte/processSignin07.php"
reponse = requests.post(url=page, data={"usernameSI": "admin","passwordSI": "admin","confirm_passwordSI": "admin"})
res = re.search("already taken",reponse.content.decode())
if (res) :
print(" OK test inscriptionIncorrectePOST SUCCESS ")
else :
print(" NO test inscriptionIncorrectePOST FAILED (2) ")
# fin de si
except :
print( " NO test inscriptionIncorrectePOST FAILED (1) ")
Quel livre cité en cours détaille ce genre de tests ?
Une solution classique pour tester et automatiser les manipulations dans les pages Web se nomme Selenium qui fonctionne de pair avec des "drivers" de navigateurs, comme geckodriver pour Firefox, ou chromedriver pour Chrome.
Le premier code Python fourni ouvre le navigateur Firefox, attend 3 secondes puis met la fenêtre de Firefox en grand. Ensuite le code interroge Google : il recherche la zone de saisie via son id et vide cette zone d'entrée avant de simuler la frappe du mot pomme et d'envoyer les données au moteur de recherche. Au bout de cinq secondes, ce qui est suffisant pour voir la réponse de Google s'afficher, le navigateur est fermé.
L'ouvrage recommandé en cours pour ce genre de tests est celui de H. J.W. Percival :

Le second code Python fourni dialogue avec le serveur Web et simule l'envoi de données en méthode POST comme si elles venaient d'un formulaire. On s'attend à ce que l'envoi des informations usernameSI=admin, mot de passe eponyme renvoie comme contenu already taken, ce qui correspond à un test réussi.
4. Qu'est-ce qu'un installeur local comme npm, gem/bundler, composer et sans doute pip ?
Pour installer des logiciels, il faut en général avoir des droits d'administrateur. Certains langages ont des installeurs locaux, comme npm, gem, composer et aussi sans doute pip. Pour quel langage ? Que font-ils exactement, quel en est l'intérêt ?
Voici les langages associés à ces installeurs locaux avec des liens pour savoir comment les utiliser :
Un installeur local est en général un gestionnaire de packages et de dépendances qui vient écrire dans le répertoire de l'utilisateur plutôt que dans des répertoires systèmes. Pour Linux, on ne les utilise donc pas avec sudo mais directement. Souvent ces installeurs créent un fichier de configuration nommé aussi fichier de dépendances dans le répertoire courant ou à la racine de l'utilisateur. Les noms de fichiers associés (nous vous laissons trouver pour quel installeur) sont nommés package.json, Gemfile, composer.json. Ce sont donc soit des fichiers textes légèrement structurés et formatés ou des fichiers JSON. Ils peuvent écrire des fichiers dans le répertoire courant, ou dans un répertoire spécial d'installation.
5. Génération de nombres aléatoires pour tests de charge
On voudrait remplir aléatoirement divers champs d'une base de données comme le champ VILLE, le champ AGE, le champ CODE-SEXE. On admettra pour l'instant qu'on se limite aux villes Angers, Paris et Nantes, que l'age est un entier entre 18 et 99, que le code-sexe est limité aux valeurs H et F.
5.1 Génération pseudo-aléatoire avec Php
De quelles fonctions dispose-t-on en Php pour générer de telles valeurs ?
Peut-on facilement générer des valeurs pour les villes avec des contraintes comme « on veut 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers » ?
Peut-on facilement générer des valeurs pour les ages avec des contraintes comme « la distribution des valeurs correspond à celle de la France, avec la même moyenne, la même médiane, et le même écart-type » ?
5.2 Modèles statistiques de génération
Quels sont les grands modèles statistiques de distribution de données ?
5.3 Génération pseudo-aléatoire avec R, Python, Php et Javascript
Comment fait-on informatiquement pour générer ces distributions avec les langages cités ?
5.1 Génération pseudo-aléatoire avec Php
En standard, Php dispose de fonctions capables de générer des entiers pseudo-aléatoires, comme les instructions suivantes le montrent :
$gh> php -a
Interactive mode enabled
php> echo rand()."\n" ;
408294454
php> echo rand()."\n" ;
835341261
php> echo mt_rand()."\n" ;
2109692948
php> echo random_int()."\n" ;
PHP Warning: Uncaught TypeError: random_int() expects exactly 2 parameters, 0 given in php shell code:1
php> echo random_int(0,123456)."\n" ;
8377
php> echo random_int(0,123456789)."\n" ;
72293708
php> exit
Mais à moins d'installer une extension statistique, comme PECL-stats Php ne sait pas générer de distribution statistiques avec des contraintes données. La liste des distributions statistiques fournies est ici.
Par contre, juste pour des tests, Php sait générer des identifiants et des tableaux pseudo-aléatoires, comme indiqué dans les pages uniqid() et array_rand().
Enfin, pour générer des valeurs liées à un pays, il faudrait disposer de ces informations (mais à quelle date ?). Ainsi, «la distribution des ages en France» est un terme trop vague pour pouvoir être utilisé.
La notion de nombre aléatoire et de nombre pseudo-aléatoire est assez facile à comprendre. On pourra lire pour s'en rendre compte la page Wiki française nommée pseudo-aléatoire avec ses deux corrélats, générateur pseudo-aléatoire et générateur aléatoire même si la page Wiki anglaise pseudorandomness est plus détaillée.
5.2 Modèles statistiques de génération
Il ne s'agit pas ici d'un problème informatique mais d'une question statistique. Disons pour simplifier qu'il y a
-
la loi binomiale pour modéliser des groupes de phénomènes à deux états, comme pour le code-sexe avec des proportions données ;
-
la loi normale pour des distributions comme celle de l'age ;
-
la loi de Poisson pour des distributions comme celle des temps d'attente ;
-
la loi multinomiale pour modéliser des phénomènes à plus de deux états avec des proportions données, comme pour nos trois villes.
Il y a beaucoup d'autres lois, comme le montre la page loi de probabilité. Les liens entre les lois peuvent être compris via le schéma suivant :
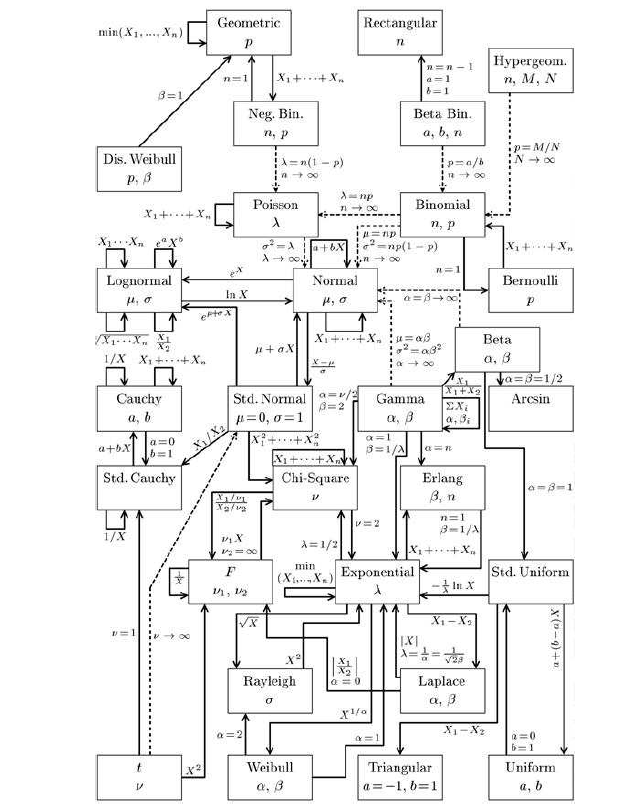
5.3 Génération pseudo-aléatoire avec R, Python et Javascript
Pour générer des valeurs pseudo-aléatoires par programme, il suffit de connaitre le nom des fonctions à utiliser et les paramètres des modèles. Par exemple, imaginons qu'on veuille générer n=1000 valeurs
-
de code-sexe H et F avec environ 60 % de femmes et 40 % d'hommes ;
-
d'ages entiers entre 18 et 99 ans avec environ une moyenne de 40 ans et un écart-type de 30 ans ;
-
de chaines Paris, Nantes, Angers avec environ 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers.
Comme R, Python et Javascript disposent, directement ou dans des librairies, de fonctions pour la loi binomiale et pour la loi normale, les scripts à écrire pour générer les données sont simples à écrire car il suffit de suivre les étapes suivantes :
##
## 1. génération de n=1000 valeurs de code-sexe H et F
## avec environ 60 % de femmes et 40 % d'hommes
##
1.1 générer n codes 0/1 avec une loi binomiale B(n=1000,p=0.6)
1.2 convertir les codes 0 en "Homme" et les codes 1 en "Femme"
##
## 2. génération de n=1000 valeurs d'ages entiers entre 18 et 99
## avec environ une moyenne de 40 ans et un écart-type de 30 ans
##
2.1 générer n valeurs réelles avec une loi normale N(m=40,sd=30)
2.2 arrondir ces valeurs pour en faire des entiers
2.3 filtrer ces données (1) : on met à 18 les valeurs inférieures à 18
2.4 filtrer ces données (2) : on met à 99 les valeurs supérieures à 99
##
## 3. génération de n=1000 valeurs de chaines Paris, Nantes, Angers
## avec environ 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers
##
3.1 générer n codes 0/1/2 avec une fonction d'échantillonnage à pourcentages donnés
3.2 convertir les codes 0 en "Paris", les codes 1 en "Nantes" et les codes 2 en "Angers"
Voici les codes R, Python et Javascript correspondant :
## nombres et chaines aléatoires avec R
nbv <- 10**3 # nombre de valeurs à générer
# codes-sexe en proportion 60 % Femme et 40 % Homme
csNum <- rbinom(n=nbv,size=1,prob=0.6)
codesSexe <- ifelse(csNum==0,"Homme","Femme")
# autre solution : codesSexe <- c("Homme","Femme")[ 1 + csNum ]
print(100*prop.table(table(codesSexe))) # pour vérification
# ages entiers entre 18 et 99 avec environ une moyenne de 40 ans et un écart-type de 30 ans
ages <- rnorm(n=nbv,mean=40,sd=30)
ages <- round(ages)
ages <- ifelse(ages<18,18,ages)
ages <- ifelse(ages>99,99,ages)
res <- c(summary(ages),sd(ages))
names(res)[ length(names(res)) ] <- "Sd"
cat("ages\n") # pour vérification
print(res) # pour vérification
# chaines Paris, Nantes, Angers avec environ 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers
nomsVilles <- c("Paris","Nantes","Angers")
villes <- sample(x=nomsVilles, size=nbv, replace=TRUE, prob=c(0.80,0.15,0.05))
print(100*prop.table(table(villes))) # pour vérification
# -*- coding:latin1 -*-
## nombres et chaines aléatoires avec Python3
import numpy as np
import pandas as pd
nbv = 10**3 # nombre de valeurs à générer
# codes-sexe en proportion 60 % Femme et 40 % Homme
csNum = np.random.binomial(n=1,p=0.6,size=nbv)
csNumS = np.where(csNum==0,"Homme","Femme")
csNumD = pd.DataFrame(csNumS,columns=["code-sexe"])
csNumDc = pd.crosstab(index=csNumD["code-sexe"],columns="count")
print(100*csNumDc/csNumDc.sum()) # pour vérification
# ages entiers entre 18 et 99 avec environ une moyenne de 40 ans et un écart-type de 30 ans
ages = np.random.normal(loc=40,scale=30,size=nbv)
ages = ages.round()
ages = np.where(ages<18,18,ages)
ages = np.where(ages>99,99,ages)
agesD = pd.DataFrame(ages,columns=["age"])
print(agesD.describe()) # pour vérification
# chaines Paris, Nantes, Angers avec environ 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers
nomsVilles = ["Paris","Nantes","Angers"]
villes = np.random.choice(nomsVilles,nbv,replace=True,p=[0.80,0.15,0.05])
villesD = pd.DataFrame(villes,columns=["ville"])
villesDc = pd.crosstab(index=villesD["ville"],columns="count")
print(100*villesDc/villesDc.sum()) # pour vérification
// ## nombres et chaines aléatoires avec Javascript via nodejs
var Rands = require('rands') ; var r = new Rands()
var sprintf = require("sprintf-js").sprintf
var stats = require("stats-lite")
var shuffle = require('shuffle-array')
nbv = Math.pow(10,3) // # nombre de valeurs à générer
// # codes-sexe en proportion 60 % Femme et 40 % Homme
csNum = r.binomial(1, 0.6, nbv)
codesSexe = new Array(nbv)
for (idv=0;idv<csNum.length;idv++) {
if (csNum[idv]==0) { codesSexe[idv] = "Homme" } else { codesSexe[idv] = "Femme" }
} // fin pour idv
tap = [0,0]
for (idv=0;idv<csNum.length;idv++) { tap[ csNum[idv] ]++ }
console.log("Codes-sexe :")
sexe = ["Homme","Femme"]
for (idc=0;idc<tap.length;idc++) {
console.log(" ",sexe[idc],sprintf(" %3d",tap[idc]),":",
sprintf(" %6.2f",100*tap[idc]/nbv)," %")
} // fin pour idc
// ages entiers entre 18 et 99 avec environ une moyenne de 40 ans et un écart-type de 30 ans
agesR = r.normal(40,30,nbv)
ages = new Array(nbv)
ageMin = 99
ageMax = 18
for (idv=0;idv<ages.length;idv++) {
ages[idv] = Math.round(agesR[idv])
if (ages[idv]<18) { ages[idv] = 18 }
if (ages[idv]>99) { ages[idv] = 99 }
if (ages[idv]<ageMin) { ageMin = ages[idv] }
if (ages[idv]>ageMax) { ageMax = ages[idv] }
} // fin pour idv
console.log("Ages :")
console.log(" minimum ",sprintf("%7.2f",ageMin))
console.log(" moyenne ",sprintf("%7.2f",stats.mean(ages)))
console.log(" ecart-type ",sprintf("%7.2f",stats.stdev(ages)))
console.log(" maximum ",sprintf("%7.2f",ageMax))
// # chaines Paris, Nantes, Angers avec environ 80 % de valeurs Paris, 15 % de valeurs Nantes, 5 % de valeurs Angers
villes = new Array(nbv)
nbParis = nbv*0.80
nbNantes = nbv*0.15
nbAngers = nbv*0.05
indg = -1
for (idv=0;idv<nbParis;idv++) { indg++ ; villes[ indg ] = "Paris" }
for (idv=0;idv<nbNantes;idv++) { indg++ ; villes[ indg ] = "Nantes" }
for (idv=0;idv<nbAngers;idv++) { indg++ ; villes[ indg ] = "Angers" }
villes = shuffle(villes)
console.log("Villes :")
nomsVilles = ["Paris","Nantes","Angers"]
tap = new Array(3)
for (idc=0;idc<tap.length;idc++) { tap[ idc ] = 0 }
for (idv=0;idv<villes.length;idv++) {
for (idc=0;idc<tap.length;idc++) {
if (villes[idv]==nomsVilles[idc]) { tap[idc]++ }
} // fin pour idc
} // fin pour idv
for (idc=0;idc<tap.length;idc++) {
console.log(" ",sprintf("%-8s",nomsVilles[idc]),sprintf(" %3d",tap[idc]),
":",sprintf(" %6.2f",100*tap[idc]/nbv)," %")
} // fin pour idc
Voici à titre d'exemple deux résultats d'exécution du code R :
$gh> R --vanilla --quiet --slave --encoding=latin1 --file=nbaleat.r
codesSexe
Femme Homme
59.2 40.8
ages
Min. 1st Qu. Median Mean 3rd Qu. Max. Sd
18.00000 18.75000 39.00000 42.67200 58.00000 99.00000 23.29272
villes
Angers Nantes Paris
5.74 14.98 79.28
$gh> R --vanilla --quiet --slave --encoding=latin1 --file=nbaleat.r
codesSexe
Femme Homme
58.7 41.3
ages
Min. 1st Qu. Median Mean 3rd Qu. Max. Sd
18.00000 20.00000 42.00000 44.14700 60.00000 99.00000 23.29635
villes
Angers Nantes Paris
4.90 15.22 79.88
Voici aussi à titre d'exemple deux résultats d'exécution du code Python :
$gh> python3 nbaleat.py
col_0 count
code-sexe
Femme 58.0
Homme 42.0
age
count 1000.000000
mean 44.763000
std 24.104935
min 18.000000
25% 19.000000
50% 42.000000
75% 61.000000
max 99.000000
col_0 count
ville
Angers 4.5
Nantes 16.5
Paris 79.0
$gh> python3 nbaleat.py
col_0 count
code-sexe
Femme 62.0
Homme 38.0
age
count 1000.000000
mean 43.427000
std 23.410569
min 18.000000
25% 19.000000
50% 39.500000
75% 60.000000
max 99.000000
col_0 count
ville
Angers 5.6
Nantes 15.4
Paris 79.0
Et enfin deux résultats d'exécution du code Javascript :
$gh> nodejs nbaleat.js
Codes-sexe :
Homme 411 : 41.10 %
Femme 589 : 58.90 %
Ages :
minimum 18.00
moyenne 43.98
ecart-type 23.58
maximum 99.00
Villes :
Paris 800 : 80.00 %
Nantes 150 : 15.00 %
Angers 50 : 5.00 %
$gh> nodejs nbaleat.js
Codes-sexe :
Homme 415 : 41.50 %
Femme 585 : 58.50 %
Ages :
minimum 18.00
moyenne 43.06
ecart-type 22.89
maximum 99.00
Villes :
Paris 800 : 80.00 %
Nantes 150 : 15.00 %
Angers 50 : 5.00 %
6. Mais que fait ce programme Perl ?
Indiquer ce que produit et ce que calcule le programme Perl ci-dessous :
0001 die(" il en faut trois.") unless ($#ARGV>1) ; # faut ce qu'il faut !
0002
0003 ($nbobs,$nbtos,$href) = ($ARGV[0],$ARGV[1],$ARGV[2]) ;
0004 $iobs = 1 ;
0005
0006 while ($iobs<=$nbobs) {
0007 $som = 0 ;
0008 $itos = 1 ;
0009 while ($itos<=$nbtos) {
0010 $x = rand() ;
0011 if ($x>0.5) {
0012 $x = 1 ;
0013 } else {
0014 $x = 0 ;
0015 } ; # fin de si
0016 $som += $x ;
0017 $itos++ ;
0018 } ; # fin tant que
0019 $haut = $href ;
0020 while ($som>$haut) { $haut += $href ; } ;
0021 $tclass{$haut}++;
0022 $iobs++ ;
0023 } ; # fin tant que
0024
0025 foreach $v (sort keys %tclass) {
0026 print sprintf("%05.2f",$v) ;
0027 print " ".sprintf("%4d",$tclass{$v})." \n" ;
0028 } ; # fin pour
Que peut-on en conclure sur la lecture de code d'autres programmeurs ?
Visiblement ce programme fait des calculs ! L'instruction en ligne 1 vérifie
qu'il y a au moins trois arguments car en Perl on commence à compter à partir de 0.
Les paramètres sont respectivement le nombre de valeurs ou "nombre d'observations",
le nombre de "toss" c'est à dire le nombre de répétitions et la hauteur de référence.
Le programme effectue ensuite une première boucle de simulation (lignes 6 à 23)
pour produire nbobs résultats. Chaque résultat est construit de la valeur suivante :
on effectue nbtos tirages aléatoires entre 0 et 1 grâce à la fonction rand() et
pour chaque tirage on compte 0 si le nombre est strictement inférieur à 0.5 et 1 s'il est
supérieur ou égal à 0.5 ; le résultat est la somme des nbtos valeurs 0 ou 1 nommé som.
A chaque valeur som on associe une hauteur notée haut grâce à la boucle des lignes 19 et 20 ;
pour associer une hauteur, on incrémente la hauteur de base par pas de href (qui avait
été fourni en paramètre) jusqu'à dépasser la valeur de som. On utilise ensuite en ligne 21
un tableau associatif pour comptabiliser combien de valeurs ont la même hauteur.
La dernière boucle du programme (lignes 25 à 28) vient afficher les hauteurs trouvées et
leurs effectifs respectifs.
Voici 4 exemples d'exécution correspondant à perl binom.pl 1000 6 0.5 :
00.50 17 00.50 16
01.00 89 01.00 93
02.00 236 02.00 249
03.00 336 03.00 306
04.00 232 04.00 234
05.00 83 05.00 92
06.00 7 06.00 10
00.50 14 00.50 15
01.00 98 01.00 93
02.00 219 02.00 233
03.00 308 03.00 294
04.00 260 04.00 236
05.00 84 05.00 115
06.00 17 06.00 14
Pour un(e) statisticien(ne), il est clair que ce programme simule nbobs fois
l'addition de nbtos tirages d'une loi de bernoulli de paramètre 0.5 ; ce programme
fournit donc une simulation de la binomiale $\mathcal{B}(nbtos,0.5)$ sur un effectif total de $nbobs$ valeurs.
Si on remplace la valeurs 0.5 de la ligne 11 par une autre valeur $p$ entre 0 et 1, c'est la loi
binomiale $\mathcal{B}(n,p)$ qui est alors simulée.
On pourra consulter la page wiki de la loi binomiale à ce sujet.
7. Mais que fait ce programme Java ?
Indiquer ce que produit et ce que calcule le programme Java ci-dessous :
0001 // auteur (gH)
0002
0003 //#-# Fichier simj.java issu de galg -a simj.alg -o java
0004 //#-# ===================================================
0005
0006 class simj {
0007
0008 import java.io.* ;
0009 class simja {
0010
0011 public static void main(String args[]) {
0012
0013 int nbobs, nbtos ;
0014 int mclass, iobs, itos, clas ;
0015 double href, haut, x,som ;
0016 int[] tclass ;
0017
0018
0019 ///////////////////////////////////////////////////////////////
0020
0021 ... lignes pour initialiser le tableau et gérer les paramétres
0022
0023 ///////////////////////////////////////////////////////////////
0024
0025
0026 mclass = 0 ;
0027 iobs = 1 ;
0028
0029 while ((iobs <= nbobs)) {
0030 som = 0 ;
0031 itos = 1 ;
0032 while ((itos <= nbtos)) {
0033 x = randNorm() ;
0034 som = som + x * x ;
0035 itos = itos + 1 ;
0036 } ; // sur itos
0037 haut = href ;
0038 clas = 0 ;
0039 while ((som > haut)) {
0040 haut = haut + href ;
0041 clas = clas + 1 ;
0042 } ; // sur som>haut
0043 tclass[clas] = tclass[clas] + 1 ;
0044 if (clas > mclass) {
0045 mclass = clas ;
0046 } ; // clas > mclass
0047 iobs = iobs + 1 ;
0048 } ; // sur iobs
0049
0050 for (int indi=1; indi<=mclass; indi++) {
0051 System.out.println(format( indi, 3 )+" : "+format( tclass[indi], 5 )) ;
0052 } ; // indi
0053
0054 } // fin de la méthode main()
0055
0056 } // fin de la classe simj
0057
0058 //#-# Fin de traduction pour simj.java via de galg -a simj.alg -o java
Ce nouveau programme
effectue la simulation de $\textbf{nbObs}$ valeurs pour une loi définie comme suit : on fait la somme
du carré de $\textbf{nbTos}$ valeurs de la loi normale.
On apprend, dans un cours de statistiques classiques, que la somme des carrés de $\textbf{n}$ lois normales
indépendantes est nommée $\chi^2$. Ce programme simule donc le tirage de valeurs du
$\chi^2$ à $\textbf{nbTos}$ degrés de liberté pour un effectif total de $\textbf{nbObs}$ valeurs.
On pourra consulter la page wiki de la loi du ki2 à ce sujet.
Voici trois exemples d'éxécution, sachant que le programme complet est simulechi2.java :
$gh> javac simulechi2.java
$gh> java simulechi2 1000 10 10
0 : 560
1 : 404
2 : 35
3 : 1
$gh> java simulechi2 1000 10 10
0 : 545
1 : 422
2 : 31
3 : 2
$gh> java simulechi2 1000 10 5
0 : 106
1 : 447
2 : 315
3 : 97
4 : 31
8. Tester la qualité d'un générateur de nombres aléatoires
Comment tester la qualité d'un générateur de nombres aléatoires ? Peut-on garantir qu'un générateur de nombres aléatoires fournit de "bons" nombres pour la cryptographie ?
Ceci est un problème difficile, à la limite entre les mathématiques et l'informatique. Il existe quelques tests classiques pour montrer qu'un générateur n'est pas "suffisamment aléatoire", mais pour prouver qu'il l'est, c'est moins évident. On pourra consulter la page Wiki anglaise Cryptographically secure pseudorandom number generator pour plus de détails ainsi que les pages analysis et statistics du site random.org dont les services sont très intéressants.
retour au plan de cours
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)