DECRA : Décomposition, Conception et Réalisation d'Applications
Cours 2 : Petites applications et langages ad hoc
Table des matières cliquable
1. Qu'est-ce qu'une petite application ?
2. Les langages de script en général
3. Les langages Awk, Perl, Php, Python et R
4. Quelques petites applications et les langages qui vont avec
1. Qu'est-ce qu'une petite application ?
Il n'est certainement pas facile de répondre à cette question car la limite entre une petite application et une "vraie" ou "grosse" application est difficile à quantifier. Il est clair qu'un petit pont en bois ou une petite cabane dans la forêt est plus facile à réaliser qu'un très grand immeuble ou qu'un immense viaduc, mais le point de départ est le même : il faut modéliser. De la même façon, cerner le "vrai" Big Data aujourd'hui (2017) et le distinguer de la simple accumulation de données n'est pas toujours très aisé.
Nous dirons ici qu'une petite application est une application dont la problématique est cernable en quelques minutes et dont la réalisation se situe dans un délai «raisonnable» inférieur à 10 heures de travail. Ce seuil maximal arbitraire n'a pour but ici que de fixer un ordre de grandeur. Le terme réalisation signifie ici conception, écriture, tests élémentaires. Il ne s'applique pas à la durée véritable de l'application lors de son utilisation. Cette distinction est très importante pour la bio-informatique par exemple lorsqu'on met au point un petit script d'une dizaine de lignes mais dont l'exécution prend plusieurs jours.
Voici donc quelques exemples de petites applications :
-
convertir une valeur de pouces en centimètres en ligne de commandes (ici) ou par page Web (là) ;
-
réaliser une C.A.H. (Classification Ascendante Hiérarchique) sur des données binaires comme sur la page Cabiq ;
-
produire à la volée des affichettes triangulaires de présentation.
Comme suite logique, voici quelques exemples d'applications qu'on ne peut pas considérer comme petites :
-
programmer la gestion des vols de l'aéroport de Chicago ;
-
écrire un programme qui évalue des réponses libres de lycéens (par exemple une rédaction, un devoir de philosophie) ;
-
réaliser un correcteur orthographique qui comprend «bien» la langue française ;
-
fournir un gestionnaire de réservation de salles simple et performant.
Pour réaliser une petite application, une fois la barrière des termes métiers franchie, on doit souvent se tourner vers un langage de programmation adapté. Même s'il est théoriquement possible de coder un site Web via le langage C, il n'y a pratiquement pas de tels sites.
Des questions à se poser mais qui ne relèvent pas de ce cours sont «l'application existe-t-elle déjà ? » «Est-elle payante ? » « Facile d'accès ? » « Est-elle adaptée à nos besoins ? » Par exemple, pour une proposition de rendez-vous à plusieurs, ce serait stupide de vouloir réinventer Doodle sauf à vouloir pouvoir y accéder par programme.
Une autre question à se poser mais qui ne relève pas non plus de ce cours est celle de l'intérêt de l'application. Ainsi, y a-t-il un sens aujourd'hui (2017) à vouloir inventer un nouveau moteur de recherche comme Google ?
Nous supposerons donc ici qu'on s'intéresse à de petites applications pour réaliser des tâches utiles, originales... Par exemple, on peut supposer qu'un bon programmeur met "suffisamment" de commentaires dans son code, qu'il définit des cartouches en haut de fichier comme pour le dessin technique... Une petite application en rapport avec ce thème est d'essayer de quantifier le pourcentages de commentaires dans le code-source d'une application.
2. Les langages de script en général
Programmer une petite application ne requiert pas en général de sortir une grosse artillerie avec 50 développeurs, des sites-miroirs, des serveurs de tests. Toutefois, elle nécessite autant de rigueur qu'une grande application, sans quoi elle ne sert à rien. Ainsi il vaut mieux ne pas utiliser un programme qui est censé convertir des pouces en centimètres si la fiabilité de la conversion n'est pas garantie.
Réaliser une petite application -- et ce peut être la maquette d'une grande application, histoire de dégrossir les besoins du client -- suppose de pouvoir développer rapidement et facilement, ce qui exclut sans doute les langages compilés. Un certain nombre de langages de scripts se sont peu à peu imposés pour réaliser ce genre de tâches au fil des années. Leur persistance au-delà d'une dizaine d'années est un gage de leur valeur. C'est pourquoi il nous semble important de les connaitre, au moins de nom, au moins au travers de petits exemples.
Nous retiendrons donc les langages Awk, Perl, Php, Python et R ; tant pis pour les langages APL, Rexx/Regina, SmallTalk, Tcl/Tk... qui, s'ils sont encore utilisés, relèvent d'une communauté particulière, induite par le type de machines (IBM), soit par le type d'application (calcul scientifique, interfaces utilisateurs...). Un lecteur curieux pourra consulter notre vision historique des langages de script via notre cours de master sur le sujet.

Nous avons aussi écarté les langages dédiés au calcul scientifique inclus dans les logiciels comme Maple, Mathematica, Matlab, Scilab pour rester généralistes. C'est par contre le manque de temps imposé par le format de ce cours qui nous empêche de présenter le langage Ruby, pour lequel nous avons une préférence, même si Python semble, dans l'air du temps, plus utilisé que Ruby. A ce sujet, on pourra consulter les pages burtchworks survey 2017, SPECTRUM, STACIFY, TIOBE et JAXENTER.
Pour éviter de retranscrire ici les rubriques de notre cours de master sur les langages de script, nous vous proposons à titre d'introduction les liens suivants :
3. Les langages Awk, Perl, Php, Python et R
Il n'est sans doute pas très difficile d'avoir un peu de culture sur les langages Awk, Perl, Php, Python et R. Ces langages sont gratuits, généralistes et disponibles partout. Pour vous éviter d'avoir à apprendre en détail tous ces langages, voici ce que nous avons préparé : des tutoriels et des petits problèmes qui montrent bien l'intérêt du langage. S'il est possible de résoudre tous ces problèmes avec tous ces langages, certains permettent de le faire plus aisément, ou de façon plus concise...
La première chose à faire est donc de survoler les langages, via nos tuteurs ou avec des pages synoptiques comme hyperpolyglot, rosetta code et repl.it.
De façon schématique, nous recommandons d'utiliser :
-
Awk pour des applications ultra-courtes et/ou jetables, dès lors que les commandes Unix ou Dos enchainées sont insuffisantes à résoudre le problème ou inadaptées ;
-
Perl s'il y a beaucoup de traitement de données textes à réaliser ;
-
Php s'il faut disposer d'une interface Web ;
-
Python s'il s'agit de traitement scientifique en général ;
-
R lorsqu'il y a beaucoup de statistiques ou des représentations graphiques à produire.
4. Quelques petites applications et les langages qui vont avec
On notera que les applications présentées ici sont de vraiment petites applications. Sauf pour Awk, les langages proposés sont aussi capables de produire des applications moyennes ou grandes.
4.1 Numéroter les lignes d'un ou plusieurs fichiers avec Awk
Comme le titre de la rubrique l'indique, on veut pouvoir consulter un ou des fichiers avec leurs lignes numérotées.
N'hésitez pas à réfléchir pour obtenir ce qui suit, pour les fichiers fic1.txt et fic2.txt avant d'afficher la solution.
Au passage, on regardera ce que produit la commande grep --text "## [0-9]" ndl.sh ; le fichier utilisé est ici.
$gh> ndl
Pas de fichier à traiter, rien à faire, la vie est belle... EXITING. STOP
$gh> ndl -h
ndl, numéros de lignes pour les fichiers, (gH) version 1.35
syntaxe : gawk ndl.awk FICHIERS
exemples : gawk ndl.awk fic1.txt
gawk ndl.awk fic*.txt
$gh> gawk -f ndl.awk fic1.txt
-- Fichier numéro 1 : fic1.txt
0001 Ada
0002 Apl
0003 Assembleur
$gh> ndl fic*txt
-- Fichier numéro 1 : fic1.txt
0001 Ada
0002 Apl
0003 Assembleur
-- Fichier numéro 2 : fic2.txt
0001 Perl
0002 Python
0003 R
0004 Ruby
Solution
Les fichiers correspondant à la solution sont ndl.sh et ndl.awk.
#!/bin/bash
#####################################################################################
### ###
### ###
### (gH) -_- ndl.sh ; TimeStamp (unix) : 10 Juillet 2017 vers 14:03 ###
### ndl = numéros de lignes ###
### ###
### ###
#####################################################################################
## ne pas hésiter à passer par : alias 'ndl=sh ndl.sh $*'
VERSION=1.35
## 1. vérification des paramètres selon le principe "pas de bras, pas de chocolat !"
if [ -z $1 ]
then
echo "Pas de fichier à traiter, rien à faire, la vie est belle... EXITING. STOP\n"
exit
fi
## 2. aide minimaliste
if [ $1 = "-h" ]
then
echo "ndl, numéros de lignes pour les fichiers, (gH) version $VERSION\n\n "
echo "syntaxe : gawk -f ndl.awk FICHIERS"
echo "exemples : gawk -f ndl.awk fic1.txt"
echo " gawk -f ndl.awk fic*.txt"
echo ""
exit
fi
## 3. si on arrive ici, c'est qu'il y a du travail à faire
gawk -f ndl.awk $*
# fichier ndl.awk
BEGIN { nbfic = 0 }
(FNR==1) { nbfic++ ; print "\n-- Fichier numero " sprintf("%3d",nbfic) " : " FILENAME}
{ print sprintf("%04d",FNR) " " $0 }
4.2 Construire des dictionnaires alphabétiques et fréquentiels avec Perl
Il s'agit ici de construire les dictionnaire alphabétiques et fréquentiels d'un texte.
N'hésitez pas à réfléchir pour obtenir ce qui suit, pour les fichiers bush2dinvest.txt et beteZola.txt avant d'afficher la solution.
$gh > perl dico.pl bush2dinvest.txt
Analyse du fichier bush2dinvest.txt :
486 ligne(s), 2106 mot(s)
dont 772 mot(s) différent(s).
Vous pouvez consulter les fichiers dic_bush2dinvest.txt.mot et dic_bush2dinvest.txt.occ
dont voici le début :
fichier dic_bush2dinvest.txt.mot issu de dico.pl bush2dinvest.txt
- 17
2nd 1
A 1
Abraham 1
Across 1
Act 2
Advancing 1
After 1
All 2
America 20
American 2
Americans 8
And 7
At 1
Author 1
Bell 1
Bill 1
Bush 2
By 2
fichier dic_bush2dinvest.txt.occ issu de dico.pl bush2dinvest.txt
the 134
of 116
and 101
our 47
in 45
to 36
is 30
we 27
that 27
$gh> perl dico.pl beteZola.txt
Analyse du fichier beteZola.txt :
7377 ligne(s), 23418 mot(s)
dont 4426 mot(s) différent(s).
Vous pouvez consulter les fichiers dic_beteZola.txt.mot et dic_beteZola.txt.occ
dont voici le début :
fichier dic_beteZola.txt.mot issu de dico.pl beteZola.txt
# 2
- 32
153 1
1804 1
1830 1
1855 1
1869 1
293 1
? 96
A 24
Ah 30
Ainsi 1
Allons 2
Alors 25
Amsterdam 1
Anglais 1
Argenteuil 2
Assieds-toi 2
Au 2
fichier dic_beteZola.txt.occ issu de dico.pl beteZola.txt
de 966
la 642
il 477
le 476
à 386
l 381
un 368
d 326
Solution
Un seul fichier suffit, dico.pl.
# (gH) -_- dicopl.pl ; TimeStamp (unix) : 24 Juin 2008 vers 16:48
# test des paramètres
if ($ARGV[0] eq "") {
print " syntaxe : dicopl nom_de_fichier \n" ;
exit(-1) ;
} ; # fin de test sur les arguments
$fictxt = $ARGV[0] ; # récupération du nom du fichier
# ouverture du fichier
open( FICT ,"<$fictxt") || die "\n impossible d'ouvrir le fichier nommé $fictxt \n\n" ;
# parcours du fichier, remplissage du hachage au passage
$nbLig = 0 ; # nombre de lignes du fichier
$nbMot = 0 ; # nombre de mots en tout
$nbMdi = 0 ; # nombre de mots différents
while ($ligne=<FICT>) {
$nbLig++ ;
chop($ligne) ;
# on élimine la ponctuation
$ligne =~ tr/,.:!'"();/ / ;
# on élimine le double tiret
$ligne =~ s/--//g ;
@mots = split(/ /,$ligne) ;
foreach $m (@mots) {
if (length($m)>0) {
$nbMot++;
$cntMot{$m}++ ;
if ($cntMot{$m}==1) {
$nbMdi++ ;
} ; # finsi nouveau mot
} ; # finsi mot non vide
} ; # fin pour chaque mot
} ; # fin de tant que
print " Analyse du fichier $fictxt :\n" ;
print " $nbLig ligne(s), $nbMot mot(s) \n" ;
print " dont $nbMdi mot(s) différent(s).\n" ;
$dicNom = "dic_$fictxt.mot" ; # fichier alphabétique
$dicOcc = "dic_$fictxt.occ" ; # fichier fréquenciel
open(DICM,">$dicNom ") or die ("impossible d'écrire dans $dicNom") ;
print DICM "fichier $dicNom issu de $0 $fictxt\n" ;
foreach $m (sort keys(%cntMot)) {
print DICM sprintf(" %-20s",$m)
.sprintf("%4d",$cntMot{$m})."\n" ;
# on en profite pour remplir un tableau pour les occurences
$cle = sprintf("%04d",$cntMot{$m})."_$m" ;
$tabMot{$cle}=$m ;
} ; # fin pour chaque
close(DICM) ;
open(DICK,">$dicOcc ") or die ("impossible d'écrire dans $dicOcc") ;
print DICK "fichier $dicOcc issu de $0 $fictxt\n" ;
foreach $c (reverse sort keys(%tabMot)) {
# on sait comment Perl convertit les %s en %c, on en profite :
print DICK sprintf(" %-20s",$tabMot{$c})
.sprintf("%4d",$c)."\n" ;
} ; # fin pour chaque
close(DICK) ;
print " Vous pouvez consulter les fichiers $dicNom et $dicOcc \n" ;
print " dont voici le début : \n\n" ;
system("head -n 20 $dicNom") ;
system("head $dicOcc") ;
Fichiers résultats dic_bush2dinvest.txt.occ dic_bush2dinvest.txt.mot dic_beteZola.txt.occ dic_beteZola.txt.mot
Une interface plus agréable est à l'adresse Analexies.
4.3 Veille technologique avec Php
On veut comparer le nombre de hits renvoyés par Google sur des termes technologiques comme XML, JAVA...
N'hésitez pas à réfléchir pour produire un formulaire et une page de résultats comme ci-dessous avant d'afficher la solution.
 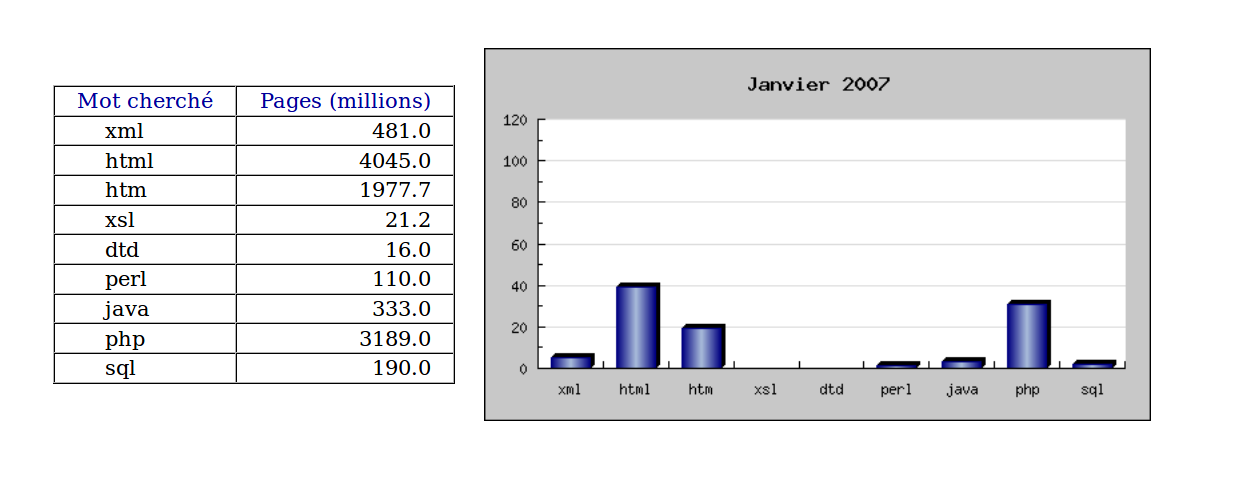
Au passage, quelle est la différence entre les deux commandes grep "## [0-9]" et grep "##\s\+S[0-9]" ? on pourra les appliquer au fichier PHP qui produit les résultats.
Solution
Le code du formulaire se nomme veille_formulaire.php et le programme qui utilise les données du formulaire est veille_resultats.php.
<?php
# # (gH) -_- veille_formulair.php ; TimeStamp (unix) : 18 Octobre 2017 vers 15:23
error_reporting(E_ALL | E_NOTICE | E_STRICT) ;
include("std.php") ;
debutPage("veille technologique","strict") ;
debutSection() ;
h1("Entrez les termes technologiques qui vous intéressent, à raison de un par ligne :") ;
blockquote() ;
## -------------------------------------------------------------------
form("veille_resultats.php","post") ;
p() ;
textarea("termes","cadrejaune",10,60,"termes") ;
fintextarea() ;
finp() ;
p() ;
nbsp(10) ;
$xmps = "XML\\nHTML\\nXHTML\\nXSL\\nDTD\\nPERL\\nJAVA\\nPHP\\nRUBY\\nPYTHON" ;
input_submit(" exemple ","exemple","bouton_fin nou bleu_pastel","onclick='window.document.getElementById(\"termes\").value=\"$xmps\" ; return false'") ;
nbsp(10) ;
input_submit(" vider ","vider","bouton_fin nou bleu_pastel","onclick='window.document.getElementById(\"termes\").value=\"\" ; return false'") ;
nbsp(10) ;
input_submit(" générer ","ok","bouton_fin nou vert_pastel") ;
finp() ;
finform() ;
pvide() ;
p() ;
echo em("Il faut en général attendre 15 secondes avant que Google ne renvoie tous les résultats.");
finp() ;
p() ;
echo em("Merci pour votre patience.");
finp() ;
## -------------------------------------------------------------------
finblockquote() ;
pvide() ;
p() ;
echo href("montresource.php?nomfic=veille_formulair.php","Code-source php de cette page","orange_stim nou").". " ;
finp() ;
finSection() ;
finpage() ;
?>
<?php
# # (gH) -_- veille_resultats.php ; TimeStamp (unix) : 18 Octobre 2017 vers 15:28
error_reporting(E_ALL | E_NOTICE | E_STRICT) ;
include("std.php") ; # fonctions classiques de gh
include("popular_inc.php") ; # fonctions urlGoog et nbHits
debutPage("veille technologique","strict") ;
debutSection() ;
h1("Nombre de hits renvoyés par Google pour des termes choisis en veille technologique") ;
blockquote() ;
#############################################################################################
## 1. vérification de la présence de la variable "termes"
if (!isset($_POST["termes"])) {
p("grouge") ;
echo "Variable \"termes\" non renseignée. Stop." ;
finp() ;
finblockquote() ;
finSection() ;
finPage() ;
exit(-1) ;
} ; # fin si
## 2. vérification que cette variable "termes" est non vide
$termes = trim($_POST["termes"]) ;
if (strlen($termes)==0) {
p("grouge") ;
echo "Vous n'avez pas rempli le formulaire de la page ".href("veille_formulair.php").". Stop." ;
finp() ;
finblockquote() ;
finSection() ;
finPage() ;
exit(-1) ;
} ; # fin si
$tabTermes = preg_split("/\\n/",$termes) ;
## 3. recherche des résultats via Google et remplissage du tableau de sortie
table(0,'20',"",'courant') ;
tr() ;
td() ;
$nbm = count($tabTermes) ;
$data = "" ;
$xlab = "" ;
$idm = 0 ;
table(1,5,"collapse") ;
tr() ;
## 4. les chiffres
td() ; nbsp(3) ;
echo s_span("Terme","bleuf") ;
nbsp(3) ; fintd() ;
td() ; nbsp(3) ;
echo s_span("Pages (millions)","bleuf") ;
nbsp(3) ; fintd() ;
fintr() ;
foreach ($tabTermes as $mot) {
$idm++ ;
$lastc = substr($mot,strlen($mot)-1) ;
if (ord($lastc)==13) { $mot = substr($mot,0,-1) ; } ;
$nbp = nbhits($mot) ;
$mdp = ($nbp/1000.0)/1000.0 ;
$xlab .= urlencode($mot) ;
$data .= round($mdp) ;
if ($idm<$nbm) {
$xlab .= "_" ;
$data .= "_" ;
} ; # fin si
tr() ;
td() ; nbsp(7) ; echo urldecode($mot) ; nbsp(3) ; fintd() ;
td("r") ; nbsp(3) ; echo sprintf("%8.1f",$mdp) ; nbsp(3) ; fintd() ;
fintr() ;
} ; # fin pour chaque
fintable() ;
fintd() ;
td() ;
pvide() ;
fintd() ;
## 5. affichage de l'histogramme correspondant
td() ;
$an = date("Y") ;
$deburl = "http://forge.info.univ-angers.fr/~gh/jphistopct.php" ;
$finurl = "vdata=$data&titr=".urlencode("Hits pour $an")."&xmrks=$xlab" ;
## echo " pour histogramme : <pre>$finurl</pre>\n" ;
echo img("$deburl?taily=280&$finurl",'histogramme') ;
fintd() ;
fintr() ;
fintable() ;
###########################################################
p() ;
echo href("montresource.php?nomfic=veille_resultats.php","Code-source php de cette page","orange_stim nou").". " ;
finp() ;
#############################################################################################
finblockquote() ;
finSection() ;
finpage() ;
?>
Liens directs formulaire résultats.
4.4 Système de fichiers et tailles avec Python
On voudrait connaitre la taille des systèmes de fichier et l'espace disque restant sur chaque système de fichier via un script Python.
N'hésitez pas à réfléchir pour produire une page de résultats et d'options comme ci-dessous avant d'afficher la solution.
$gh> pydf
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p5 681G 242G 405G 35.5 [###########################................................................] /
/dev/nvme0n1p1 356M 83M 273M 23.5 [##################.........................................................] /boot/efi
$gh> pydf --help
Usage: pydf [options] arg
Options:
--help show this help message
-v, --version show version
-a, --all include filesystems having 0 blocks
-h, --human-readable print sizes in human readable format (e.g., 1K 234M
2G)
-H, --si likewise, but use powers of 1000 not 1024
-b BLOCKSIZE, --block-size=BLOCKSIZE
use BLOCKSIZE-byte blocks
-l, --local limit listing to local filesystems
-k, --kilobytes like --block-size=1024
-m, --megabytes like --block-size=1048576
-g, --gigabytes like --block-size=1073741824
--blocks use filesystem native block size
--bw do not use colours
--mounts=MOUNTS_FILE File to get mount information from. On normal Linux
systems only /etc/mtab or /proc/mounts make sense.
Some other Unices use /etc/mnttab. Use /proc/mounts
when /etc/mtab is corrupted or inaccessible (the
output looks a bit weird in this case).
-B, --show-binds show 'mount --bind' mounts
-i, --inodes show inode instead of block usage
Solution
Nous nous contentons ici de reproduire le code Python de l'utilitaire pydf qui est disponible sous Linux sous forme d'un package, installable par sudo apt-get install pydf. Le code source du fichier est accessible ici.
#! /usr/bin/python
import sys, os, re, string, struct, unicodedata
from optparse import OptionParser
from math import log
if not 'lexists' in dir(os.path):
# for python < 2.4
# will not give the same result for broken symbolic links, but who cares...
os.path.lexists = os.path.exists
if sys.version_info[0] < 3:
# getoutput() and getstatusoutput() methods have
# been moved from commands to the subprocess module
# with Python >= 3.x
import commands as my_subprocess
else:
import subprocess as my_subprocess
str_ljust = str.ljust
str_rjust = str.rjust
str_center = str.center
# again an ugly hack for python < 2.4
try:
str_ljust('dummy', 1, '.')
except TypeError:
str_ljust = lambda x, y, z: string.ljust (x, y).replace(' ', z)
str_rjust = lambda x, y, z: string.rjust (x, y).replace(' ', z)
str_center = lambda x, y, z: string.center (x, y).replace(' ', z)
class Bar:
def __init__(self, percentage=0, width=2, header=False):
self.percentage = percentage
self.width = width
self.header = header
def __len__(self):
return self.width
def __str__(self):
return self.format(self, 'l')
def format(self, pos):
if self.header:
return ' '*self.width
size = int(round(self.percentage*(self.width-2)))
return '['+manglestring(size*barchar, self.width-2, pos, bar_fillchar)+']'
def get_terminal_width_termios():
try:
import fcntl, termios
except ImportError:
return None
s = struct.pack("HHHH", 0, 0, 0, 0)
try:
lines, cols, xpixels, ypixels = \
struct.unpack(
"HHHH",
fcntl.ioctl(sys.stdout.fileno(),
termios.TIOCGWINSZ, s)
)
except (IOError, AttributeError):
return None
return cols
def get_terminal_width_resize():
status, output = my_subprocess.getstatusoutput('resize')
if status!=0: # error in running resize
return None
c = output.split('\n')
c = [x for x in c if x.startswith('COLUMNS=')]
if c:
c = c[0]
dummy, c = c.split('=', 1)
if c[-1] == ';':
c = c[:-1]
if c:
return int(c)
else:
return None
def get_terminal_width_dumb():
return 80
def get_terminal_width():
handlers = [get_terminal_width_termios, get_terminal_width_resize, get_terminal_width_dumb]
for handler in handlers:
width = handler()
if width:
return width
return 80 # fallback, should not happen
def find_mountpoint(path):
if not os.path.lexists(path):
sys.stderr.write('pydf: %s: No such file or directory\n' % repr(path))
return None
while not os.path.ismount(path):
path = os.path.dirname(path)
return path
#some default definitions
colours = {
'none' : "",
'default' : "\033[0m",
'bold' : "\033[1m",
'underline' : "\033[4m",
'blink' : "\033[5m",
'reverse' : "\033[7m",
'concealed' : "\033[8m",
'black' : "\033[30m",
'red' : "\033[31m",
'green' : "\033[32m",
'yellow' : "\033[33m",
'blue' : "\033[34m",
'magenta' : "\033[35m",
'cyan' : "\033[36m",
'white' : "\033[37m",
'on_black' : "\033[40m",
'on_red' : "\033[41m",
'on_green' : "\033[42m",
'on_yellow' : "\033[43m",
'on_blue' : "\033[44m",
'on_magenta' : "\033[45m",
'on_cyan' : "\033[46m",
'on_white' : "\033[47m",
'beep' : "\007"
}
normal_colour = 'default'
header_colour = 'yellow'
local_fs_colour = 'default'
remote_fs_colour = 'green'
special_fs_colour = 'blue'
readonly_fs_colour = 'cyan'
filled_fs_colour = 'red'
full_fs_colour = 'on_red'
custom_device_colour = {} #TODO
sizeformat = "-h"
column_separator = ' '
column_separator_colour = 'none'
row_separator = ''
hidebinds = True
stretch_screen = 0.3
do_total_sum = False
FILL_THRESH = 95.0
FULL_THRESH = 99.0
format = [
('fs', 10, "l"), ('size', 5, "r"),
('used', 5, "r"), ('avail', 5, "r"), ('perc', 4, "r"),
('bar', 0.1, "l"), ('on', 11, "l")
]
barchar = '#'
bar_fillchar = '.'
mountfile = ['/etc/mtab', '/etc/mnttab', '/proc/mounts']
#end of default definitions
# read configuration file
for conffile in ["/etc/pydfrc", os.environ['HOME']+"/.pydfrc"]:
if os.path.isfile(conffile):
exec(compile(open(conffile).read(), conffile, 'exec'))
header = {
'fs' : "Filesystem",
'size' : "Size",
'used' : "Used",
'avail' : "Avail",
'on' : "Mounted on",
'fstype' : "Type",
'perc' : "Use%",
'bar' : Bar(header=True),
}
def sanitize_output(s):
"sanitize nonprintable characters for printing"
r = ''
for c in s:
if ord(c)<32:
r += r'\x%02x' % ord(c)
# surrogate characters encoding non-decodable bytes in the names of mountpoints
elif 0xdc80 <= ord(c) <= 0xdcff:
r += r'\x%02x' % (ord(c)-0xdc00)
# in python2, we have str, not unicode here - just give up and do not test for strange unicode characters
elif sys.version_info[0] >= 3 and (unicodedata.category(c)[0]=='C' or unicodedata.category(c) in ('Zl', 'Zp')):
if ord(c) <= 0xffff:
r += r'\u%04X' % ord(c)
else:
r += r'\U%08X' % ord(c)
else:
r += c
return r
def out(s):
try:
sys.stdout.write(s)
except UnicodeEncodeError:
sys.stdout.write(s.encode('ascii', 'ignore').decode())
class DumbStatus:
"emulates statvfs results with only zero values"
f_bsize = f_frsize = f_blocks = f_bfree = f_bavail = f_files = f_ffree = f_favail = f_flag = f_namemax =0
def hfnum(size, base):
"human readable number"
if size == 0:
return "0"
if size < 0:
return "?"
if inodes:
units = [""]
else:
units = ["B"]
units += ["k", "M", "G", "T", "P", "Z", "Y"]
power = int(log(size)/log(base))
if power < 0:
power = 0
if power >= len(units):
power = len(units)-1
nsize = int(round(1.*size/(base**power)))
if nsize < 10 and power >= 1:
power -= 1
nsize = int(round(1.*size/(base**power)))
r = str(nsize) + units[power]
return r
def myformat(number, sizeformat, fs_blocksize):
"format number as file size. fs_blocksize here is a filesysem blocksize"
size = int(number)*fs_blocksize
if blocksize: # that is, blocksize was explicitly set up
sn = round(1.*size/blocksize)
sn = int(sn)
return str(sn)
if sizeformat == "-k":
sn = round(size/1024.)
sn = int(sn)
return str(sn)
elif sizeformat == "-m":
sn = round(size/(1024.*1024))
sn = int(sn)
return str(sn)
elif sizeformat == "-g":
sn = round(size/(1024.*1024*1024))
sn = int(sn)
return str(sn)
elif sizeformat == "-h":
return hfnum(size, 1024)
elif sizeformat == "-H":
return hfnum(size, 1000)
elif sizeformat == "--blocks":
return str(number)
else: # this should not happen
raise ValueError("Impossible error, contact the author, sizeformat="+repr(sizeformat))
def manglestring(s, l, pos, fillchar=' '):
"cut string to fit exactly into l chars"
if pos == "r":
ns = str_rjust(s, l, fillchar)
elif pos == "l":
ns = str_ljust(s, l, fillchar)
elif pos == "c":
ns = str_center(s, l, fillchar)
else:
raise ValueError('Error in manglestring')
if len(ns) > l:
ns = ns[:int(l/2)] + "~" + ns[-int(l/2)+1:]
return ns
def makecolour(clist):
"take list (or tuple or just one name) of colour names and return string of ANSI definitions"
s = ""
if type(clist) == str:
lclist = [clist]
else:
lclist = clist
for i in lclist:
s = s + colours[i]
return s
def version():
return '12'
def get_all_mountpoints():
"return all mountpoints in fs"
# fallback when nothing else works
dummy_result = {'/': ('/', '')}
if isinstance(mountfile, str):
f = open(mountfile,"rb")
else:
for i in mountfile:
if os.path.exists(i):
f = open(i,"rb")
break
else:
# fallback, first try to parse mount output
status, mout = my_subprocess.getstatusoutput('mount')
if status !=0:
return dummy_result
mlines = mout.split('\n')
r = {}
for line in mlines:
if not ' on ' in line:
continue
device, on = line.split(' on ', 1)
device = device.split()[0]
onparts = on.split()
on = onparts[0]
# option format: (a,b,..)
opts = onparts[-1][1:-1].split(',')
r[on] = (device, '', opts)
if r:
return r
else:
return dummy_result
mountlines = f.readlines() # bytes in python3
# convert to representable strings (for python3)
# unfortunately, we cannot keep it as bytes, because of a known bug
# in python3 forcing us to use string, not bytes as filename for os.statvfs
if sys.version_info[0]>=3:
errhandler = 'surrogateescape'
# surrogateescape works in statvfs only since python3.3
if sys.version_info[1]<3:
errhandler = 'replace'
mountlines = [x.decode(sys.stdin.encoding, errhandler) for x in mountlines]
r = {}
for l in mountlines:
spl = l.split()
if len(spl)<4:
print("Error in", mountfile)
print(repr(l))
continue
device, mp, typ, opts = spl[0:4]
opts = opts.split(',')
r[mp] = (device, typ, opts)
return r
def niceprint_fs(fs):
"print LVM as nice symlink"
matchObj = re.search( r'^\/dev\/mapper\/(.*)-(.*)', str(fs)) # will fail in python3if fs canot be converted to unicode
if matchObj:
return "/dev/" + matchObj.group(1) + "/" + matchObj.group(2)
else:
return fs
def get_row_mp(mp):
# for python3, mp is bytes, not str
if mp:
if mp in mountpoints:
device, fstype, opts = mountpoints[mp]
device = niceprint_fs(device)
else:
# oops, the mountpoint is not in /etc/mtab or equivalent
# return dummy values
device, fstype, opts = '-', '-', '-'
rdonly = 'ro' in opts or fstype in ("iso9660", "udf")
bind = 'bind' in opts or 'rbind' in opts
try:
status = os.statvfs(mp)
except (OSError, IOError):
status = DumbStatus()
fs_blocksize = status.f_bsize
if fs_blocksize == 0:
fs_blocksize = status.f_frsize
free = status.f_bfree
size = status.f_blocks
avail = status.f_bavail
inodes_free = status.f_ffree
inodes_size = status.f_files
inodes_avail = status.f_favail
if (size==0 or is_special_fs(fstype)) and not allfss:
return
if bind and hidebinds:
return
used = size-free
inodes_used = inodes_size - inodes_free
if inodes:
size_f = myformat(inodes_size, sizeformat, 1)
used_f = myformat(inodes_used, sizeformat, 1)
avail_f = myformat(inodes_avail, sizeformat, 1)
try:
perc = round(100.*inodes_used/inodes_size, 1)
perc_f = str(perc)
except ZeroDivisionError:
perc = 0
perc_f = '-'
else:
size_f = myformat(size, sizeformat, fs_blocksize)
used_f = myformat(used, sizeformat, fs_blocksize)
avail_f = myformat(avail, sizeformat, fs_blocksize)
try:
perc = round(100.*used/size, 1)
perc_f = str(perc)
except ZeroDivisionError:
perc = 0
perc_f = '-'
info = {
'fs' : device,
'size' : size_f,
'used' : used_f,
'avail' : avail_f,
'on' : mp,
'fstype' : fstype,
'perc' : perc_f,
'bar' : None,
}
current_colour = local_fs_colour
if is_remote_fs(fstype):
current_colour = remote_fs_colour
elif size == 0 or is_special_fs(fstype):
current_colour = special_fs_colour
else: # header
current_colour = header_colour
row = []
for j in format:
if j[0]=='bar':
width = j[1]
if 0<width<1: # i.e. percentage
width = int(width*terminal_width)-1
if mp:
if j[0] in ['perc', 'avail', 'bar']:
if rdonly:
current_colour = readonly_fs_colour
elif perc > FULL_THRESH:
current_colour = full_fs_colour
elif perc > FILL_THRESH:
current_colour = filled_fs_colour
if j[0]=='bar':
info['bar'] = Bar(perc/100., width)
text = info[j[0]]
# if there are control or invalid unicode characters in mountpoint names
if not isinstance(text, Bar):
text = sanitize_output(text)
else:
text = header[j[0]]
if j[0]=='bar':
text.width = width
column = [current_colour, text]
row.append(column)
return row
def is_remote_fs(fs):
"test if fs (as type) is a remote one"
fs = fs.lower()
return fs in [ "nfs", "smbfs", "cifs", "ncpfs", "afs", "coda",
"ftpfs", "mfs", "sshfs", "fuse.sshfs", "nfs4" ]
def is_special_fs(fs):
"test if fs (as type) is a special one"
"in addition, a filesystem is special if it has number of blocks equal to 0"
fs = fs.lower()
return fs in [ "tmpfs", "devpts", "devtmpfs", "proc", "sysfs", "usbfs", "devfs", "fdescfs", "linprocfs" ]
def get_table(mps):
"table is a list of rows"
"row is a list of columns"
"column is a list of [colour code, content]"
"content is a string, unless it is a Bar() instance"
rows = [get_row_mp(None)]
for mp in mps:
row = get_row_mp(mp)
if row is not None:
rows.append(row)
return rows
def squeeze_table(table, desired_width):
"squeeze table to fit into width characters"
cols = len(table[0])
# build a row of minimal (possible, from format) cell sizes
minrow = []
for j in format:
width = j[1]
if 0 < width < 1: # i.e. percentage
width = int(width*terminal_width)-1
minrow.append(width)
# row of maximal cell sizes
maxrow = [0]*cols
for row in table:
for col in range(cols):
colsize = len(row[col][1])
maxrow[col] = max(maxrow[col], colsize)
# maximal differences between (real cell size - minimal possible cell size)
deltarow = [maxrow[i]-minrow[i] for i in range(cols)]
deltas = list(zip(deltarow, list(range(cols))))
deltas.sort()
deltas.reverse()
# how many characters we need to cut off from table width
to_reduce = sum(maxrow) + (cols-1)*len(column_separator) - desired_width
to_stretch = 0
# if there is free space
if to_reduce < 0 and stretch_screen:
# -to_reduce is now number of spare characters
to_stretch = int(-to_reduce * stretch_screen)
new_maxrow = maxrow[:] # new sizes
for delta, i in deltas:
if to_reduce < 0:
# we have finished
break
if delta >= to_reduce:
new_maxrow[i] -= to_reduce
# and we finished
to_reduce = 0
break
else:
new_maxrow[i] -= delta # now it contains the minimal possible width
to_reduce -= delta
if to_reduce > 0:
# we were not able to reduce the size enough
# since it will wrap anywway, we might as well display
# complete long lines
new_maxrow = maxrow
for row in table:
for col in range(cols):
cell_content = row[col][1]
if isinstance(cell_content, Bar):
cell_content.width += to_stretch
formatted_cell_content = cell_content.format(format[col][2])
else:
formatted_cell_content = manglestring(cell_content, new_maxrow[col], format[col][2])
row[col][1] = formatted_cell_content
def display_table(table, terminal_width):
"display our internal output table"
squeeze_table(table, terminal_width-1)
colsepcol = makecolour(column_separator_colour)
for row in table:
firstcol = True
for colourcode, text in row:
if firstcol:
firstcol = False
else:
out(colsepcol)
out(column_separator)
out(makecolour(colourcode))
out(text)
out(row_separator)
out(makecolour(normal_colour))
out('\n')
# the fun begins here
parser = OptionParser(usage="usage: %prog [options] arg", add_help_option=False)
parser.version = '%prog version ' + version()
parser.add_option("", "--help", action="help", help="show this help message")
parser.add_option("-v", "--version", action="version", help="show version")
parser.add_option("-a", "--all",
action="store_true", dest="show_all", default=False,
help="include filesystems having 0 blocks")
parser.add_option("-h", "--human-readable",
action="store_const", const='-h', dest="sizeformat",
help="print sizes in human readable format (e.g., 1K 234M 2G)")
parser.add_option("-H", "--si",
action="store_const", const='-H', dest="sizeformat",
help="likewise, but use powers of 1000 not 1024")
parser.add_option("-b", "--block-size",
action="store", dest="blocksize", default=0, type="int",
help="use BLOCKSIZE-byte blocks")
parser.add_option("-l", "--local",
action="store_true", dest="local_only", default=False,
help="limit listing to local filesystems")
parser.add_option("-k", "--kilobytes",
action="store_const", const='-k', dest="sizeformat",
help="like --block-size=1024")
parser.add_option("-m", "--megabytes",
action="store_const", const='-m', dest="sizeformat",
help="like --block-size=1048576")
parser.add_option("-g", "--gigabytes",
action="store_const", const='-g', dest="sizeformat",
help="like --block-size=1073741824")
parser.add_option("", "--blocks",
action="store_const", const='--blocks', dest="sizeformat",
help="use filesystem native block size")
parser.add_option("", "--bw",
action="store_true", dest="b_w", default=False,
help="do not use colours")
#parser.add_option("", "--sum",
# action="store_true", dest="do_total_sum", default=False,
# help="display sum of all the displayed sizes")
parser.add_option("", "--mounts",
action="store", dest="mounts_file", type="string",
help="""File to get mount information from.
On normal Linux systems only /etc/mtab or /proc/mounts make sense.
Some other Unices use /etc/mnttab.
Use /proc/mounts when /etc/mtab is corrupted or inaccessible
(the output looks a bit weird in this case).""")
parser.add_option("-B", "--show-binds",
action="store_false", dest="hidebinds", default=hidebinds,
help="show 'mount --bind' mounts")
parser.add_option("-i", "--inodes",
action="store_true", dest="inodes", default=False,
help="show inode instead of block usage")
(options, args) = parser.parse_args()
blocksize = options.blocksize
allfss = options.show_all
localonly = options.local_only
hidebinds = options.hidebinds
inodes = options.inodes
if inodes:
header["size"] = "Nodes"
if options.sizeformat:
sizeformat = options.sizeformat
#if options.do_total_sum:
# do_total_sum = True
if options.b_w:
normal_colour = header_colour = local_fs_colour = remote_fs_colour = special_fs_colour = filled_fs_colour = full_fs_colour = 'none'
if options.mounts_file:
mountfile = options.mounts_file
terminal_width = get_terminal_width()
mountpoints = get_all_mountpoints()
if args:
mp_to_display = [find_mountpoint(os.path.realpath(x)) for x in args]
mp_to_display = [x for x in mp_to_display if x is not None]
else:
mp_to_display = list(mountpoints.keys())
if localonly:
mp_to_display = [x for x in mp_to_display if not is_remote_fs(mountpoints[x][1])]
mp_to_display.sort()
table = get_table(mp_to_display)
display_table(table, terminal_width)
4.5 Réaliser des histogrammes de classes avec R
On voudrait décrire une colonne quantitative d'un fichier de données en R.
N'hésitez pas à réfléchir pour produire une page de résultats et d'options comme ci-dessous avant d'afficher la solution.
@ghchu5~/public_html/Decra|(~gH) > sh decritqt.sh
Pas de fichier à traiter, rien à faire, la vie est belle... EXITING. STOP
@ghchu5~/public_html/Decra|(~gH) > sh decritqt.sh elf.data
Nombre de paramètres incorrect.
Vous devez fournir un nom de fichier de données, un nom de colonne et une unité.
Exemple : Rscript --vanilla decritqt.r elf.data AGE ans
Erreur : -1
Exécution arrêtée
@ghchu5~/public_html/Decra|(~gH) > sh decritqt.sh elf.data2 AGE ans
Fichier de données elf.data2 non vu.
Erreur : -2
Exécution arrêtée
@ghchu5~/public_html/Decra|(~gH) > sh decritqt.sh elf.data AGE3 ans
Il n'y a pas de colonne nommée AGE3 dans les données.
Erreur : -3
Exécution arrêtée
@ghchu5~/public_html/Decra|(~gH) > sh decritqt.sh elf.data AGE ans
DESCRIPTION STATISTIQUE DE LA VARIABLE AGE
Taille 49 individus
Moyenne 40.5918 ans
Ecart-type 20.1183 ans
Coef. de variation 49 %
1er Quartile 22.0000 ans
Mediane 41.0000 ans
3eme Quartile 60.0000 ans
iqr absolu 38.0000 ans
iqr relatif 93.0000 %
Minimum 11.000 ans
Maximum 78.000 ans
Tracé tige et feuilles
The decimal point is 1 digit(s) to the right of the |
1 | 124556799
2 | 00122346789
3 | 179
4 | 012346789
5 | 0239
6 | 01122345
7 | 03368
vous pouvez utiliser demoDecritQt.png
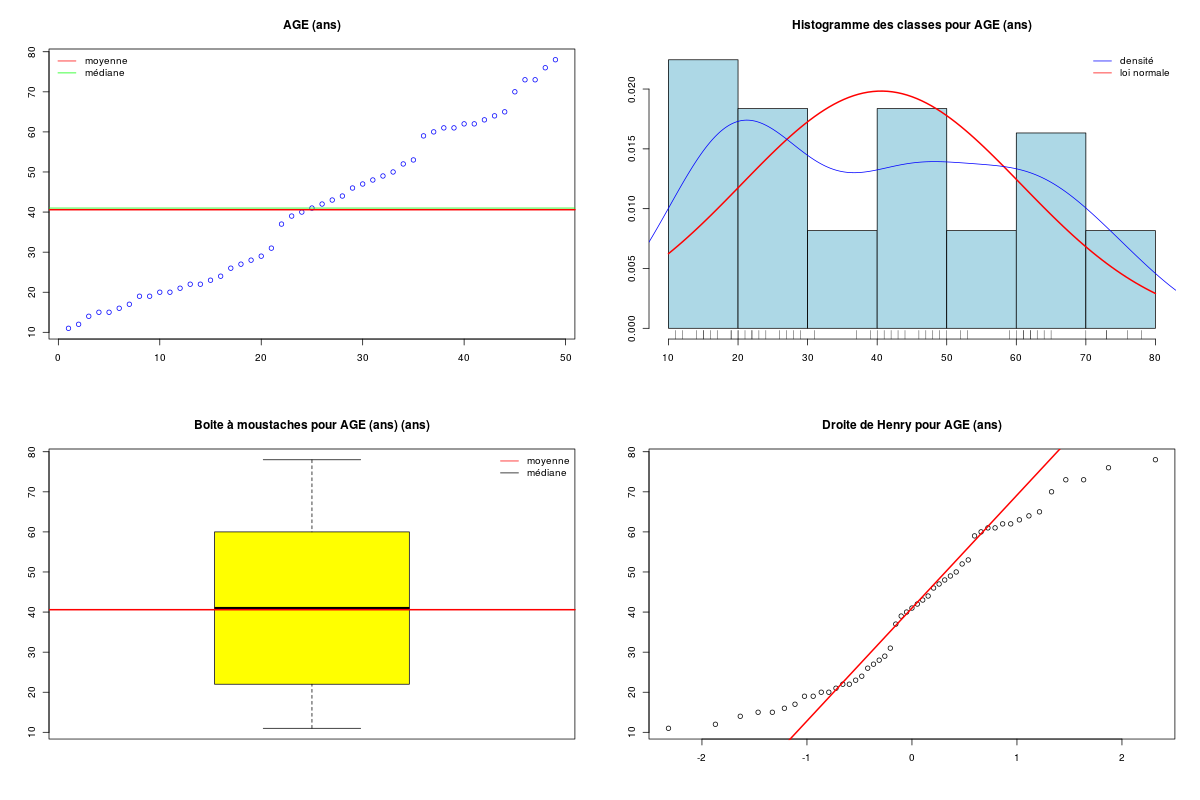
Solution
Cette solution met en oeuvre les deux fichiers decritqt.sh et decritqt.r.
#!/bin/bash
#####################################################################################
### ###
### ###
### (gH) -_- decritqt.sh ; TimeStamp (unix) : 10 Juillet 2017 vers 14:03 ###
### ###
### Description d'une variable quantitative via R ###
### ###
#####################################################################################
## ne pas hésiter à passer par : alias 'decritqt=sh decritqt.sh $*'
VERSION=0.17
## 1. vérification des paramètres selon le principe "pas de bras, pas de chocolat !"
if [ -z $1 ]
then
echo "Pas de fichier à traiter, rien à faire, la vie est belle... EXITING. STOP\n"
exit
fi
## 2. aide minimaliste
if [ $1 = "-h" ]
then
echo "decritqt, description d'une variable quantitative via R, (gH) version $VERSION\n\n "
echo "syntaxe : decritqt FICHIER nomDeLaColonne [unité]"
echo "exemples : decritqt elf.data AGE "
echo " decritqt elf.data AGE ans"
echo " decritqt leadb.txt LNG aa"
echo ""
exit
fi
## 3. si on arrive ici, c'est qu'il y a du travail à faire
Rscript decritqt.r $*
# # (gH) -_- decritqt.r ; TimeStamp (unix) : 25 Octobre 2017 vers 12:21
## 1. test des arguments, aide éventuelle
args <- commandArgs(trailingOnly = TRUE)
argc <- length(args)
if (argc<3) {
cat("\n")
cat("Nombre de paramètres incorrect.\n")
cat("Vous devez fournir un nom de fichier de données, un nom de colonne et une unité.\n\n")
cat("Exemple : Rscript --vanilla decritqt.r elf.data AGE ans\n\n")
cat("\n")
stop(-1)
} # fin si sur argc
dataFile <- args[1]
variable <- args[2]
unite <- args[3]
## 2. vérification de l'existence des fichiers
if (!file.exists(dataFile)) {
cat("\n")
cat("Fichier de données",dataFile,"non vu.\n")
stop(-2)
} # fin de si sur dataFile
## 3. lecture des données et vérificaton de l'existence de la colonne
data <- read.table(dataFile,header=TRUE)
lesVars <- names(data)
if (!variable %in% lesVars) {
cat("Il n'y a pas de colonne nommée",variable,"dans les données.\n") ;
stop(-3)
} # fin si sur variable
## 4. traitement des données via les fonctions (gH) de statgh.r
source("statgh.r",encoding="latin1")
nomPng <- "demoDecritQt.png"
decritQT(
variable,data[,variable],unite,
graphique="TRUE",
fichier_image=nomPng
) # fin de decrit QT
if (file.exists(nomPng)) {
cat("vous pouverz consulter",nomPng)
} # fin si
Pour des explications sur les graphiques générés, on pourra consulter les sections 2, 5 et 6 de notre cours 3 de notre introduction non élémentaire au logiciel R.
retour au plan de cours
|





 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)