![]()
![]()
Utilisation de statgh.r
Chargement des fonctions :
source(https://gilles-hunault.leria-info.univ-angers.fr//wstat/statgh.r",encoding="latin1")
Présentation de statgh.r
Le fichier statgh.r (version 4.79 ou supérieure) contient des fonctions écrites pour le logiciel R afin de franciser les sorties et d'automatiser un certain nombre de calculs. Nous présentons ici succinctement quelques fonctions et leur utilisation, sachant qu'une interface avec des exemples d'appel et le code de la fonction est fournie par la page statgh.fns.
1. Voici tout d'abord les fonctions de lecture d'un fichier DBASE et d'analyse univariée :
- la lecture de fichiers DBF (qui garantit la présence des données et l'homégénéité du typage des données à l'intérieur d'une même colonne) est nommée lit.dbf ; le composant dbf contient alors les données et on en peut extraire la ou les colonnes voulues à l'aide de son numéro de colonne.
- la description d'une variable quantitative (QT) se fait avec decritQT ;
- celle d'une variable qualitative (QL) avec decritQL.
La fonction de lecture des fichiers Dbase nous a été fournie gracieusement par Ben Stabler, Copyright (C) 2003 Oregon Department of Transportation. Elle renvoie un "dataframe" et pour accèder à la matrice des données, il faut forcément utiliser le composant nommé dbf. On peut aussi utiliser la fonction read.dbf du "package" foreign mais cela oblige à installer ou à faire installer ce package... On trouvera des exemples d'utilisation sur cette page... Vous pouvez télécharger les fichiers Dbase utilisés dans cette page et leur descriptif en cliquant sur les liens suivants : elf.zip et vins.zip
Pour les fonctions de description, on indique dans cet ordre un titre de question, le nom de la variable puis l'unité (QT) ou les modalités (QL). Deux options permettent ensuite d'afficher ou non le graphique associé, de le sauvegarder ou non dans un fichier de type PNG. Pour les modalités, il est possible d'utiliser une seule chaine de caractères lorsque les modalités sont séparées seulement par des espaces soit ("a b c...") au lieu de c("a","b","c"...). Un exemple d'utilisation est :
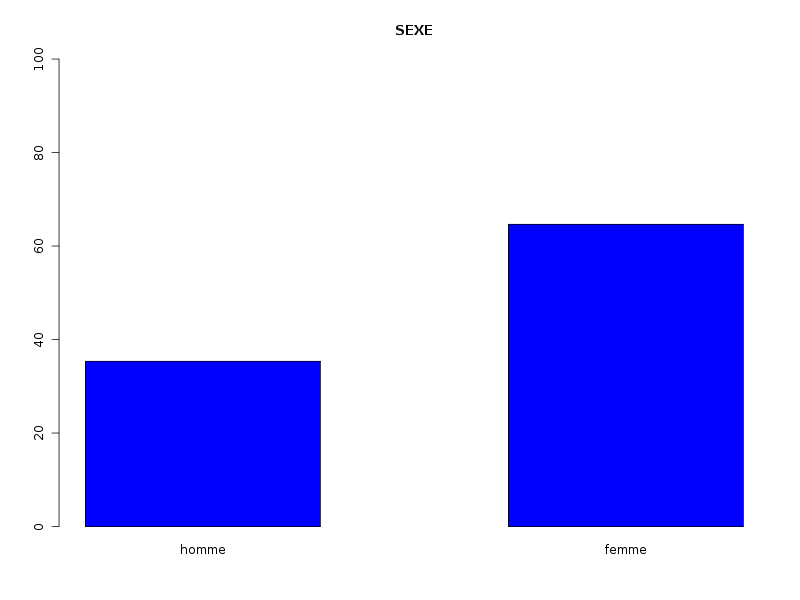
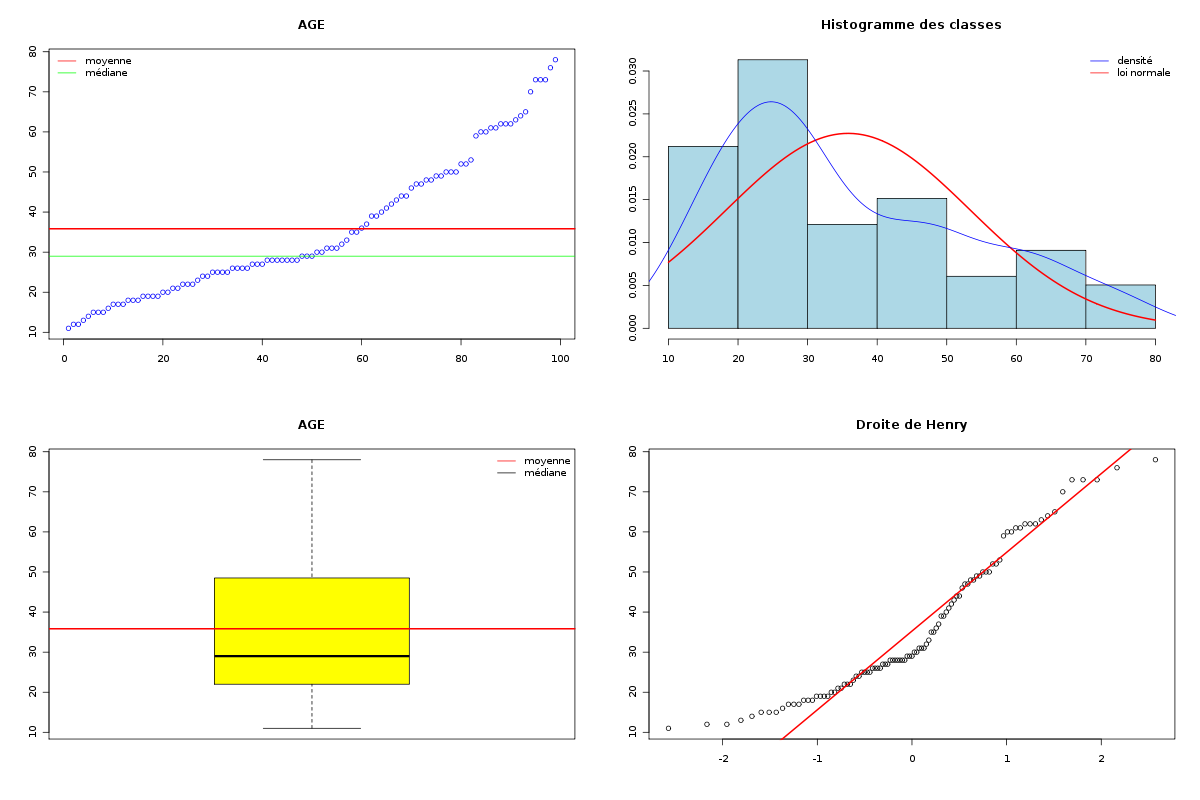
dont les résultats sont :source("statgh.r") elfdbf <- lit.dbf("elf.dbf") sx <- elfdbf$dbf[,2] decritQL(" SEXE ",sx,"homme femme") decritQL(" SEXE ",sx,"homme femme",graphique=TRUE) decritQL(" SEXE ",sx,"homme femme",graphique=TRUE,fichier_image="ELFsexe.png") ag <- elfdbf$dbf[,3] decritQT(" AGE ",ag,"ans") decritQT(" AGE ",ag,"ans",graphique=TRUE) decritQT(" AGE ",ag,"ans",graphique=TRUE,fichier_image="ELFage.png")et les deux graphiques générés sont (cliquer pour aggrandir) :QUESTION : SEXE homme femme Total Effectif 35 64 99 Fréquence (en %) 35 65 100 VARIABLE AGE Taille 99 individus Moyenne 35.828 ans Ecart-type 17.464 ans Coef. de variation 49 % 1er Quartile 22 ans Médiane 29 ans 3eme Quartile 48.5 ans Minimum 11 ans Maximum 78 ans TIGE ET FEUILLE 1 | 1223455567778889999 2 | 0011222344555566667778888888999 3 | 0011123556799 4 | 0123446778899 5 | 0002239 6 | 0011222345 7 | 033368Remarque : Il faut éventuellement préciser le chemin d'accès par défaut pour enregistrer les graphiques ou le changer globalement à l'aide la commande setwd(). La fonction lit.dar permet de lire un fichier texte contenant en ligne 1 le nom des colonnes et en colonne 1 le nom des lignes ; lit.dar(nomfic) est un synomyme de read.table(nomfic,head=TRUE,row.names=1). L'objet retourné est alors une matrice numérique. Voici une démonstration
> aaa <- read.table("elf10.dar") > aaa V1 V2 V3 V4 V5 V6 V7 1 IDEN SEXE AGE PROF ETUD REGI USAL 2 M001 1 62 1 2 2 3 3 M002 0 60 9 3 4 1 4 M003 1 31 9 4 4 1 5 M004 1 27 8 4 1 1 6 M005 0 22 8 4 1 2 7 M006 1 70 4 1 1 1 8 M007 1 19 8 4 4 2 9 M008 1 53 6 2 2 3 10 M009 0 62 16 4 2 2 11 M010 1 63 16 0 1 0 > dim(aaa) 11 7 > bbb <- lit.dar("elf10.dar") > bbb SEXE AGE PROF ETUD REGI USAL M001 1 62 1 2 2 3 M002 0 60 9 3 4 1 M003 1 31 9 4 4 1 M004 1 27 8 4 1 1 M005 0 22 8 4 1 2 M006 1 70 4 1 1 1 M007 1 19 8 4 4 2 M008 1 53 6 2 2 3 M009 0 62 16 4 2 2 M010 1 63 16 0 1 0 > dim(bbb) 10 62. Voici maintenant les fonctions pour une étude bivariée :
Un exemple d'utilisation est :
- l'analyse de la liaison (corrélation linéaire) entre deux QT se fait via analin ;
- l'étude de l'indépendance entre deux QL est réalisée par triCroise.
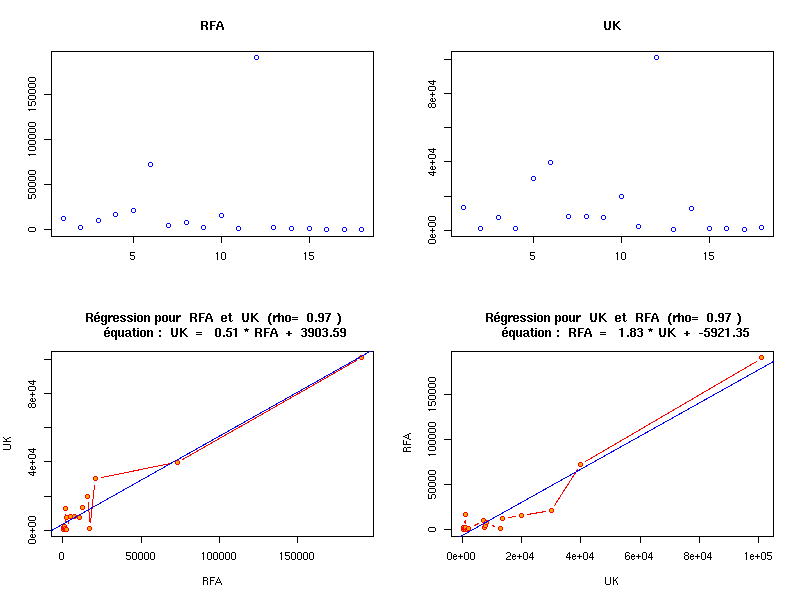
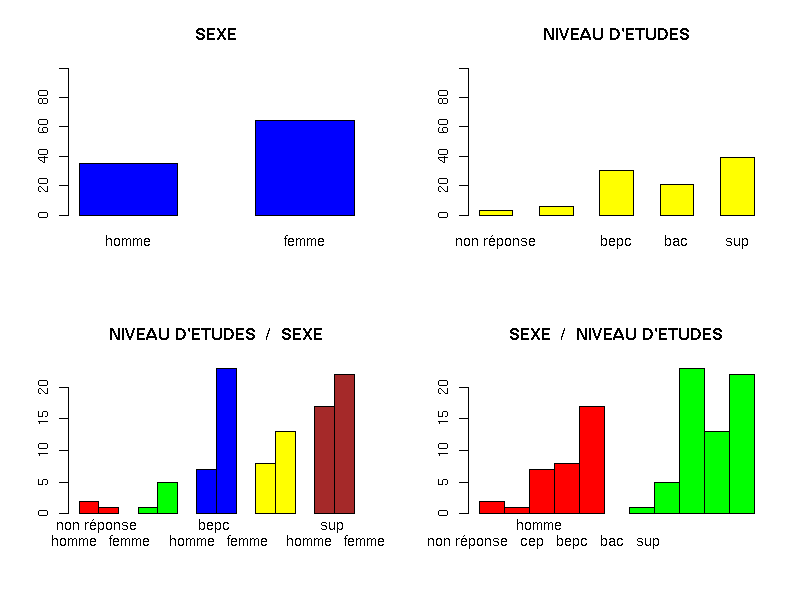
dont les résultats sont :source("statgh.r") vins <- lit.dbf("vins.dbf") rfa <- vins$dbf[,4] ; uk <- vins$dbf[,6] ; anaLin("RFA",rfa,"hl","UK",uk,"hl") anaLin("RFA",rfa,"hl","UK",uk,"hl",graphique=TRUE) anaLin("RFA",rfa,"hl","UK",uk,"hl",graphique=TRUE,grfile="VINSrfauk.png") elfdbf <- lit.dbf("elf.dbf") sx <- elfdbf$dbf[,2] et <- elfdbf$dbf[,5] msx <- "homme femme" met <- c("non réponse","cep","bepc","bac","sup") triCroise("SEXE",sx,msx,"NIVEAU D'ETUDES",et,met) triCroise("SEXE",sx,msx,"NIVEAU D'ETUDES",et,met,graphique=TRUE) triCroise("SEXE",sx,msx,"NIVEAU D'ETUDES",et,met,graphique=TRUE,grfile="ELFsxet.png")et les deux graphiques générés sont (cliquer pour aggrandir) :ANALYSE DE LA LIAISON LINEAIRE ENTRE RFA ET UK coefficient de corrélation : 0.9692588 donc R2 = 0.9394626 équation : UK = 0.51 * RFA + 3903.59 équation : RFA = 1.83 * UK + -5921.35 TRI CROISE DES QUESTIONS : SEXE (en ligne) NIVEAU D'ETUDES (en colonne) Effectifs non réponse cep bepc bac sup homme 2 1 7 8 17 femme 1 5 23 13 22 Valeurs en % du total non réponse cep bepc bac sup Total homme 2 1 7 8 17 35 femme 1 5 23 13 22 65 Total 3 6 30 21 39 100 CALCUL DU CHI-DEUX D'INDEPENDANCE ================================= TABLEAU DES DONNEES homme femme Total non réponse 2 1 3 cep 1 5 6 bepc 7 23 30 bac 8 13 21 sup 17 22 39 Total 35 64 99 VALEURS ATTENDUES et MARGES homme femme Total non réponse 1.1 1.9 3 cep 2.1 3.9 6 bepc 10.6 19.4 30 bac 7.4 13.6 21 sup 13.8 25.2 39 Total 35.0 64.0 99 CONTRIBUTIONS SIGNEES homme femme non réponse + 0.832 - 0.455 cep - 0.593 + 0.324 bepc - 1.226 + 0.671 bac + 0.045 - 0.024 sup + 0.748 - 0.409 Valeur du chi-deux 5.326981 Le chi-deux max (table) à 5 % est 9.487729 ; p-value 0.2553618 pour 4 degrés de liberté Décision : au seuil de 5 % on ne peut pas rejeter l'hypothèse qu'il y a indépendance entre ces deux variables qualitatives. PLUS FORTES CONTRIBUTIONS AVEC SIGNE DE DIFFERENCE Signe Valeur Pct Mligne Mcolonne Ligne Colonne Obs Th - 1.226 23.02 % bepc homme 3 1 7 10.6 + 0.832 15.62 % non réponse homme 1 1 2 1.1 + 0.748 14.05 % sup homme 5 1 17 13.8 + 0.671 12.59 % bepc femme 3 2 23 19.4 - 0.593 11.13 % cep homme 2 1 1 2.1 - 0.455 8.54 % non réponse femme 1 2 1 1.9 - 0.409 7.68 % sup femme 5 2 22 25.2 + 0.324 6.08 % cep femme 2 2 5 3.9 + 0.045 0.84 % bac homme 4 1 8 7.4 - 0.024 0.46 % bac femme 4 2 13 13.6 Warning message: l'approximation du Chi-2 est peut-être incorrecte in: chisq.test(tcr, correct = TRUE)
3. Le calcul automatique pour toutes les analyses descriptives univariées et bivariées se fait à l'aide de
Ainsi, pour les variables qualitatives de notre fichier ELF on peut utiliser
- allQT pour des variables QT ;
- allQL pour des variables QL.
dont voici les résultats :# analyse systématique de toutes les variables ###################################################################### # # Analyse du dossier ELF à partir du fichier-texte des données # ###################################################################### # # voir http://www.info.univ-angers.fr/pub/gh/Datasets/elf.htm # pour la description et la récupération des données # chargement des fonctions GH source("statgh.r") # lecture des données elfDATA <- read.table("elf.dar",header=TRUE) # définition des matrices de modalités elfCOLQL <- c(2,5,6,7) elfQLm <- matrix(nrow=length(elfCOLQL),ncol=3) # col 1 : intitulé court # col 2 : texte de la question # col 3 : modalités concaténées avec le symbole | via la fonction lstMod # remplissage des matrices de modalités elfQLm[1,1] <- c(" SEXE ") elfQLm[1,2] <- c(" Sexe de la personne ?") elfQLm[1,3] <- lstMod(c("homme","femme")) elfQLm[2,1] <- c(" ETUD ") elfQLm[2,2] <- c(" Niveau d'études ") elfQLm[2,3] <- lstMod(c("non réponse","cep","bepc","bac","sup")) elfQLm[3,1] <- c(" REGIONALITE ") elfQLm[3,2] <- c(" Force de l'actiorégionalité linquistique ") elfQLm[3,3] <- lstMod(c("non réponse","très faible","faible","moyenne","forte")) elfQLm[4,1] <- c(" USAGE ") elfQLm[4,2] <- c(" Quel usage de la langue ?") elfQLm[4,3] <- lstMod(c('non réponse',"faible","normal","fort")) # analyse univariée et bivariée allQL(elfDATA,elfQLm,elfCOLQL) ################################################### # décommenter ce qui suit pour une étude particulière # analyse univariée : récapitulatif #allQLrecap(elfDATA,elfQLm,elfCOLQL) # analyse univariée globale avec récapitulatif #allQLtriap(elfDATA,elfQLm,elfCOLQL) # analyse bivariée #allQLtricr(elfDATA,elfQLm,elfCOLQL)De même, pour les variables quantitatives de notre fichier VINS on peut utiliser(gH) version 2.52 TABLEAU RECAPITULATIF DES VARIABLES QUALITATIVES Intitulé Question -------- -------- SEXE Sexe de la personne ? ETUD Niveau d'études REGIONALI Force de l'actiorégionalité linquistique USAGE Quel usage de la langue ? Affichage par mode décroissant puis par effectifs décroissants USAGE 67 % non réponse 18 % faible 13 % normal SEXE 65 % femme 35 % homme REGIONALITE 43 % forte 35 % très faible 14 % faible ETUD 39 % sup 30 % bepc 21 % bac ANALYSE DE TOUTES LES VARIABLES QUALITATIVES QUESTION : SEXE -- Sexe de la personne ? homme femme Total Effectif 35 64 99 Fréquence (en %) 35 65 100 QUESTION : ETUD -- Niveau d'études non réponse cep bepc bac sup Total Effectif 3 6 30 21 39 99 Fréquence (en %) 3 6 30 21 39 99 QUESTION : REGIONALITE -- Force de l'actiorégionalité linquistique non réponse très faible faible moyenne forte Total Effectif 2 35 14 5 43 99 Fréquence (en %) 2 35 14 5 43 99 QUESTION : USAGE -- Quel usage de la langue ? non réponse faible normal fort Total Effectif 66 18 13 2 99 Fréquence (en %) 67 18 13 2 100 ORDRE CONSEILLE POUR LIRE LES 6 TRIS CROISES Variable 1 Variable 2 Chi2 Chi2Table p-value Signif. Ddl 6 REGIONALI 7 USAGE 18.09 21.03 0.1130464 12 5 ETUD 6 REGIONALI 20.78 26.30 0.1872738 16 5 ETUD 7 USAGE 15.51 21.03 0.2147301 12 2 SEXE 5 ETUD 5.33 9.49 0.2553618 4 2 SEXE 6 REGIONALI 4.21 9.49 0.3789154 4 2 SEXE 7 USAGE 1.21 7.81 0.7505345 3 TRI CROISE DES QUESTIONS : SEXE (en ligne) ETUD (en colonne) Effectifs nomVar2 nomVar1 non réponse cep bepc bac sup homme 2 1 7 8 17 femme 1 5 23 13 22 Valeurs en % du total non réponse cep bepc bac sup TOTAL homme 2 1 7 8 17 35 femme 1 5 23 13 22 65 TOTAL 3 6 30 21 39 100 TRI CROISE DES QUESTIONS : SEXE (en ligne) REGIONALITE (en colonne) Effectifs nomVar2 nomVar1 non réponse très faible faible moyenne forte homme 0 10 4 3 18 femme 2 25 10 2 25 Valeurs en % du total non réponse très faible faible moyenne forte TOTAL homme 0 10 4 3 18 35 femme 2 25 10 2 25 65 TOTAL 2 35 14 5 43 100 TRI CROISE DES QUESTIONS : SEXE (en ligne) USAGE (en colonne) Effectifs nomVar2 nomVar1 non réponse faible normal fort homme 24 6 5 0 femme 42 12 8 2 Valeurs en % du total non réponse faible normal fort TOTAL homme 24 6 5 0 35 femme 42 12 8 2 65 TOTAL 67 18 13 2 100 TRI CROISE DES QUESTIONS : ETUD (en ligne) REGIONALITE (en colonne) Effectifs nomVar2 nomVar1 non réponse très faible faible moyenne forte non réponse 0 2 0 0 1 cep 0 4 1 0 1 bepc 0 14 4 2 10 bac 1 9 0 2 9 sup 1 6 9 1 22 Valeurs en % du total non réponse très faible faible moyenne forte TOTAL non réponse 0 2 0 0 1 3 cep 0 4 1 0 1 6 bepc 0 14 4 2 10 30 bac 1 9 0 2 9 21 sup 1 6 9 1 22 39 TOTAL 2 35 14 5 43 100 TRI CROISE DES QUESTIONS : ETUD (en ligne) USAGE (en colonne) Effectifs nomVar2 nomVar1 non réponse faible normal fort non réponse 3 0 0 0 cep 1 3 2 0 bepc 18 6 4 2 bac 17 2 2 0 sup 27 7 5 0 Valeurs en % du total non réponse faible normal fort TOTAL non réponse 3 0 0 0 3 cep 1 3 2 0 6 bepc 18 6 4 2 30 bac 17 2 2 0 21 sup 27 7 5 0 39 TOTAL 67 18 13 2 100 TRI CROISE DES QUESTIONS : REGIONALITE (en ligne) USAGE (en colonne) Effectifs nomVar2 nomVar1 non réponse faible normal fort non réponse 2 0 0 0 très faible 22 6 7 0 faible 7 3 2 2 moyenne 3 2 0 0 forte 32 7 4 0 Valeurs en % du total non réponse faible normal fort TOTAL non réponse 2 0 0 0 2 très faible 22 6 7 0 35 faible 7 3 2 2 14 moyenne 3 2 0 0 5 forte 32 7 4 0 43 TOTAL 67 18 13 2 100dont voici les résultats :############################################### # # Etude du dossier vins # ############################################### # # voir http://www.info.univ-angers.fr/pub/gh/Datasets/vins.htm # pour la description et la récupération des données # chargement des fonctions gh source("statgh.r") # affichage d'un titre cat("\n Analyse du dossier VINS \n\n") cat(" -- ; ",date(),"\n") # lecture du fichier Dbase vins <- lit.dbf("vins.dbf") nbl <- dim(vins$dbf)[1] ; nbc <- dim(vins$dbf)[2] ; # préparation d'une matrice de données numériques seulement laMat <- vins$dbf[1:nbl,2:nbc]/1000 ; # appel de la fonction gh nomcol <- c("BELGIQUE","NEDERLAND","RFA","ITALIE","UK","SUISSE","USA","CANADA") unites <- rep("hl",length(nomcol)) allQT(laMat,nomcol,unites)Analyse du dossier VINS -- ; Mon Oct 9 12:30:07 2006 (gH) version 2.52 Données BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA 1 7.069 3.786 12.578 8.037 13.556 9.664 10.386 0.206 2 2.436 0.586 2.006 0.030 1.217 0.471 0.997 0.051 3 3.066 0.290 10.439 1.413 7.214 0.112 3.788 0.330 4 2.422 1.999 17.183 0.057 1.127 0.600 0.408 0.241 5 22.986 22.183 21.023 0.056 30.025 6.544 13.114 3.447 6 17.465 19.840 72.977 2.364 39.919 17.327 17.487 2.346 7 3.784 2.339 4.828 0.098 7.885 3.191 11.791 1.188 8 7.950 10.537 7.552 0.024 8.172 11.691 1.369 1.798 9 2.587 0.600 2.101 0.000 7.582 0.143 0.872 0.131 10 17.200 22.806 15.979 0.050 20.004 1.279 4.016 0.944 11 1.976 1.029 1.346 0.000 2.258 0.212 1.017 0.487 12 38.747 19.151 191.140 7.992 101.108 1.029 26.192 38.503 13 1.375 1.150 2.514 0.000 0.284 0.401 0.009 0.236 14 2.016 2.908 1.529 0.000 12.891 0.018 0.716 0.653 15 0.785 1.648 1.009 0.006 0.775 0.643 0.542 0.035 16 0.160 0.246 0.135 0.008 1.177 0.026 0.007 0.000 17 0.024 1.533 0.160 0.000 0.480 0.000 0.000 0.000 18 2.415 0.074 0.208 0.008 1.705 0.012 0.036 0.047 Par cdv décroissant Nom Num Taille Moyenne Unité Ecart-type Coef. de var. Minimum Maximum 8 CANADA 18 2.813 hl 8.705 309.39 % 0.000 38.503 4 ITALIE 18 1.119 hl 2.511 224.42 % 0.000 8.037 3 RFA 18 20.261 hl 44.616 220.20 % 0.135 191.140 5 UK 18 14.299 hl 23.616 165.16 % 0.284 101.108 6 SUISSE 18 2.965 hl 4.882 164.68 % 0.000 17.327 7 USA 18 5.153 hl 7.337 142.39 % 0.000 26.192 1 BELGIQUE 18 7.470 hl 9.994 133.78 % 0.024 38.747 2 NEDERLAND 18 6.261 hl 8.228 131.40 % 0.074 22.806 Par ordre d'entrée Nom Num Taille Moyenne Unité Ecart-type Coef. de var. Minimum Maximum 1 BELGIQUE 18 7.470 hl 9.994 133.78 % 0.024 38.747 2 NEDERLAND 18 6.261 hl 8.228 131.40 % 0.074 22.806 3 RFA 18 20.261 hl 44.616 220.20 % 0.135 191.140 4 ITALIE 18 1.119 hl 2.511 224.42 % 0.000 8.037 5 UK 18 14.299 hl 23.616 165.16 % 0.284 101.108 6 SUISSE 18 2.965 hl 4.882 164.68 % 0.000 17.327 7 USA 18 5.153 hl 7.337 142.39 % 0.000 26.192 8 CANADA 18 2.813 hl 8.705 309.39 % 0.000 38.503 Par moyenne décroissante Nom Num Taille Moyenne Unité Ecart-type Coef. de var. Minimum Maximum 3 RFA 18 20.261 hl 44.616 220.20 % 0.135 191.140 5 UK 18 14.299 hl 23.616 165.16 % 0.284 101.108 1 BELGIQUE 18 7.470 hl 9.994 133.78 % 0.024 38.747 2 NEDERLAND 18 6.261 hl 8.228 131.40 % 0.074 22.806 7 USA 18 5.153 hl 7.337 142.39 % 0.000 26.192 6 SUISSE 18 2.965 hl 4.882 164.68 % 0.000 17.327 8 CANADA 18 2.813 hl 8.705 309.39 % 0.000 38.503 4 ITALIE 18 1.119 hl 2.511 224.42 % 0.000 8.037 Matrice des corrélations BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA BELGIQUE 1.000 NEDERLAND 0.870 1.000 RFA 0.869 0.582 1.000 ITALIE 0.586 0.290 0.700 1.000 UK 0.942 0.700 0.969 0.691 1.000 SUISSE 0.335 0.518 0.198 0.310 0.246 1.000 USA 0.870 0.680 0.848 0.717 0.894 0.468 1.000 CANADA 0.814 0.458 0.948 0.659 0.926 -0.025 0.747 1.000 Meilleure corrélation 0.9692588 pour UK et RFA Formules RFA = 1.831 * UK -5.921 et UK = 0.513 * RFA + 3.904 Coefficients de corrélation par ordre décroissant 0.969 pour 5 et 3 soit UK RFA 0.948 pour 8 et 3 soit CANADA RFA 0.942 pour 5 et 1 soit UK BELGIQUE 0.926 pour 8 et 5 soit CANADA UK 0.894 pour 7 et 5 soit USA UK 0.870 pour 7 et 1 soit USA BELGIQUE 0.870 pour 2 et 1 soit NEDERLAND BELGIQUE 0.869 pour 3 et 1 soit RFA BELGIQUE 0.848 pour 7 et 3 soit USA RFA 0.814 pour 8 et 1 soit CANADA BELGIQUE 0.747 pour 8 et 7 soit CANADA USA 0.717 pour 7 et 4 soit USA ITALIE 0.700 pour 5 et 2 soit UK NEDERLAND 0.700 pour 4 et 3 soit ITALIE RFA 0.691 pour 5 et 4 soit UK ITALIE 0.680 pour 7 et 2 soit USA NEDERLAND 0.659 pour 8 et 4 soit CANADA ITALIE 0.586 pour 4 et 1 soit ITALIE BELGIQUE 0.582 pour 3 et 2 soit RFA NEDERLAND 0.518 pour 6 et 2 soit SUISSE NEDERLAND 0.468 pour 7 et 6 soit USA SUISSE 0.458 pour 8 et 2 soit CANADA NEDERLAND 0.335 pour 6 et 1 soit SUISSE BELGIQUE 0.310 pour 6 et 4 soit SUISSE ITALIE 0.290 pour 4 et 2 soit ITALIE NEDERLAND 0.246 pour 6 et 5 soit SUISSE UK 0.198 pour 6 et 3 soit SUISSE RFA -0.025 pour 8 et 6 soit CANADA SUISSENous encourageons les utilisateurs et les utilisatrices du fichier statgh.r à lire soigneusement le texte de ce fichier afin de profiter pleinement des autres fonctions non détaillées ici.
Une interface pour découvrir ces fonctions est ici.
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)