![]()
![]()
|
Enoncés pour la séance numéro 3 (solutions)
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Programmer en R
Session de formation, décembre 2013
gilles.hunault "at" univ-angers.fr
Enoncés pour la séance numéro 3 (solutions)
Un de vos collègues vous a envoyé plein de fichiers dont la dernière ligne ne contient pas des données mais une indication du nombre de valeurs. Comment lire ces fichiers ? Vous pouvez tester votre fonction avec le fichier suivant nommé derniere.txt :
num accession length reign pfam cdd foldindex pi mw gravy genre espèce 35 ABS44867 200 Viridiplantae N/A N/A -0.0835869 6.1399999 20295.8008 -1.0180905 Oryza sativa 822 A2211386C 153 Viridiplantae N/A N/A -0.1659534 9.3100004 15909.3203 -1.2745098 Pseudotsuga menziesii 964 ABB55135 132 Viridiplantae N/A N/A -0.2853720 9.4399996 14103.7598 -1.5803030 Pinus yunnanensis 965 AAW59164 143 Viridiplantae N/A N/A -0.1855139 8.6999998 15209.6104 -1.3573427 Pinus taeda 966 AAW59168 144 Viridiplantae N/A N/A -0.2060405 9.3100004 15422.8604 -1.4013889 Pinus taeda 980 AAW59174 143 Viridiplantae N/A N/A -0.1803197 8.6999998 15237.6699 -1.3405594 Pinus taeda 981 AAW59176 143 Viridiplantae N/A N/A -0.2015961 9.3100004 15294.7100 -1.3867133 Pinus taeda total 7 7 7 0 0 7 7 7 7 7 7Certains fichiers de données contiennent des entiers en colonne 1 pour l'identification des lignes. Comment lire ces fichiers et au passage ajouter du texte, par exemple pour passer de 35, 822 à Lig035, Lig822 ? Dans le même genre d'idées, les colonnes 11 et 12 contiennent respectivement des indications de genre et d'espèce. Comment les utiliser pour construire des identifiants de ligne ? Et avec une numérotation intra genre/espèce ?
Comment lire un fichier de données qui contient des lignes vides comme videcmt.txt ? Et des lignes avec des commentaires qu'on repère par le symbole dièse (#) comme premier caractère non nul de la ligne ? Et s'il y a un nombre fixe connu de lignes en haut de fichier ? Au passage, peut-on, dans une phase de test, comme en SAS, ne lire que les mille premières lignes d'un très gros fichier ?
-- ## Entete standard (5 lignes) -- ## Projet -- ## Date -- ## Auteur -- ## Version # data manip 1 A35 617 552 1 A37 417 652 1 # sous-série 1A A38 410 565 1A A39 390 700 1A A40 500 540 1A # sous-série 1B A60 500 540 1B A61 480 408 1B # data manip 2 A92 480 408 2 A93 480 408 2 A94 480 408 2 A95 480 408 2 A96 480 408 2 A97 480 408 2 A98 480 408 2 A99 480 408 2Rappeler comment on affiche facilement les n premières ou dernières lignes et colonnes d'un data frame. Comment accéder à une colonne d'un data frame ? Et la supprimer rapidement ? Comment renommer une colonne ? Comment gérer des données transposées comme dans transp.txt ci-dessous ?
M001 M002 M003 M004 M005 M006 M007 M008 M009 M010 SEXE 1 0 1 1 0 1 1 1 0 1 AGE 62 60 31 27 22 70 19 53 62 63 PROF 1 9 9 8 8 4 8 6 16 16 ETUD 2 3 4 4 4 1 4 2 4 0 REGI 2 4 4 1 1 1 4 2 2 1 USAG 3 1 1 1 2 1 2 3 2 0Comment afficher les lignes dont l'identifiant ne se termine pas par _2 ou _3 dans le fichier suivant ?
Id Duree Bolus Serie A35 617 552 1 A37 417 652 1 A38_1 410 565 1A A39 390 700 1A A40_2 500 540 1A A60_2 500 540 1B A61 480 408 1B A92_3 480 408 2Comment n'afficher que les femmes de moins de 30 ans des données ELF ? Et les hommes ou les personnes de plus de 60 ans ?
Je voudrais récupérer avec R sans faire de copier/coller, le tableau des packages du cours 1 et la liste des centres de recherche de l'institut Pasteur (à jour ?) fournie par la page wiki_fr sur l'institut. Quelles fonctions faut-il utiliser et comment faire ?
Ecrire une fonction qui demande un nombre entier au clavier et qui boucle tant que la valeur saisie n'est pas un nombre entier. On n'utilisera pas d'expression régulière dans un premier temps, mais on le fera dans un deuxième temps pour une fonction qui demande non pas un seul entier mais une liste non vide d'entiers séparés par des espaces. On utilisera alors l'argument perl=TRUE.
Aides à lire : readline() et grep().
Si la fonction c() est intéressante, elle n'est pas très agréable pour saisir des données car il faut écrire beaucoup de virgules. Ecrire une fonction qui teste si une chaine de caractères correspond à une liste de nombres (entiers ou réels, positifs ou négatifs) séparés par un ou plusieurs espaces et qui en fait alors un vecteur. On utilisera une expression régulière. Par exemple si l'utilisateur fournit comme paramètre 5 8.3 -12 7, on devra renvoyer le vecteur correspondant à c(5,8.3,-12,7). Et si on disposait de fractions, comme 2/3 4/5 3/11... ? Et si on voulait utiliser la virgule des français comme dans 5 8,3 -12 7 ?
A quoi sert le code lulu <<- lus de la solution précédente ?
On veut construire les dictionnaires (alphabétique et fréquentiel) d'un texte mis dans une chaine de caractères via une fonction. On ne demande aucune lemmatisation (qu'est-ce ?), juste l'élimination de la ponctuation et une conversion éventuelle en minuscules. On pourra utiliser notre fonction lit.texte() pour obtenir des textes sous forme de chaine. Il est conseillé d'utiliser le package hash, mais on peut aussi utiliser les listes. On veut aussi produire une matrice des occurences des mots les plus fréquents d'une liste de textes. Ecrire une fonction pour réaliser cela qui utilise la fonction précédente.
Exemple : avec le texte
Le chat et le chien sont des animaux avec quatre pattes. Le chat miaule, alors que le chien aboie.les dictionnaires produits sont
DICO ALPAHABETIQUE DICO FREQUENTIEL Mot Occ Mot Occ aboie 1 le 4 alors 1 chien 2 animaux 1 chat 2 avec 1 sont 1 chat 2 que 1 chien 2 quatre 1 des 1 pattes 1 et 1 miaule 1 le 4 et 1 miaule 1 des 1 pattes 1 avec 1 quatre 1 animaux 1 que 1 alors 1 sont 1 aboie 1Récursivité : que font les fonctions prem(), derns() et affRec() suivantes ?
prems <- function(vect) { return(vect[-length(vect)]) } # fin de fonction prems derns <- function(vect) { return(vect[-1]) } # fin de fonction derns affRec <- function(vect) { if(length(vect)==1) { return(vect) } else { return(paste(affRec(prems(vect))," + ",vect[length(vect)],sep="")) } # fin de si } # fin de fonction affRecEcrire une fonction sommeRecCrois() qui calcule récursivement la somme des éléments de son paramètre vect à partir du premier élément. Par exemple, si vect correspond à 10 20 30 40 50, on calculera 10 + (20 + (30 + (40 + (50)))). Modifier la fonction pour calculer à partir du dernier élément, c'est-à-dire pour calculer ((((10) + 20) + 30) + 40) + 50.
Sachant que trier par ordre croissant un tableau, c'est trouver le minimum de ce tableau, l'enlever du tableau puis trier ce qui reste, écrire une fonction triRec() pour trier un vecteur. Quelle est la différence si on utilise which(vect==minVec) ou si on utilise which.min(vect) pour enlever le minimum ?
Pour décrire une variable quantitative comme le poids (en kg) ou l'age (en années), R dispose de nombreuses fonctions indépendantes comme length(), mean(), sd(), plot(), hist() ou de fonctions regroupées comme summary(), fivenum() ; pourtant il manque des fonctions essentielles comme le coefficient de variation (cv()) ; de plus ces fonctions affichent leurs résultats en anglais et sans les unités.
Ecrire une fonction decritQT() qui calcule et qui trace, dont les paramètres sont
(titreQT,nomVar,unite,graphique,fichierImage)
et qui a le comportement suivant :
- par défaut on affiche les résumés statistiques de base (en français et avec le cv) mais pas les graphiques
- si graphique vaut TRUE on affiche les 4 graphiques usuels
- si fichierImage est non vide, on produit un affichage en tige et feuilles et on crée fichier .PNG avec le nom fourni
- le titre est obligatoire
Voici des exemples d'utilisation, les résultats et le graphique généré pour la variable AGE du dossier ELF :
# chargement des fonctions (gH) > source("http://www.info.univ-angers.fr/~gh/wstat/statgh.r",encoding="latin1") ; (gH) version 4.47 fonctions d'aides : lit() fqt() fql() ic() fapprox() chi2() fcomp() datagh() taper aide() pour revoir cette liste > # lecture d'un fichier de données sur le web > elf <- lit.dar.wd("elf.dar") > age <- elf$AGE # ou age <- elf[,"AGE"] ou age <- elf[,2] > # rappel de l'aide > decritQT() syntaxe : decritQT(titreQT,nomVar [ ,unite="?",graphique=FALSE,fichier_image="" ] ) exemples d'utilisation : decritQT("AGE dans ELF",ag,"ans") decritQT("POIDS dans Ronfle",poi,"kg",graphique=TRUE,fichier_image="RON_poi.png") > # calculs seulement > decritQT("Variable AGE, dossier ELF",age,"ans") DESCRIPTION STATISTIQUE DE LA VARIABLE Variable AGE, dossier ELF Taille 99 individus Moyenne 35.8283 ans Ecart-type 17.4640 ans Coef. de variation 49 % 1er Quartile 22 ans Mediane 29 ans 3eme Quartile 48 ans iqr absolu 26 ans iqr relatif 91 % Minimum 11 ans Maximum 78 ans > # calculs et graphiques à l'écran > decritQT("Variable AGE, dossier ELF",age,"ans",TRUE) DESCRIPTION STATISTIQUE DE LA VARIABLE Variable AGE, dossier ELF Taille 99 individus Moyenne 35.8283 ans Ecart-type 17.4640 ans Coef. de variation 49 % 1er Quartile 22 ans Mediane 29 ans 3eme Quartile 48 ans iqr absolu 26 ans iqr relatif 91 % Minimum 11 ans Maximum 78 ans Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 1 | 1223455567778889999 2 | 0011222344555566667778888888999 3 | 0011123556799 4 | 0123446778899 5 | 0002239 6 | 0011222345 7 | 033368 > # calculs à l'écran, graphiques dans le fichier PNG > decritQT("Variable AGE, dossier ELF",age,"ans",TRUE,"elf_age.png") [...] vous pouvez utiliser elf_age.png
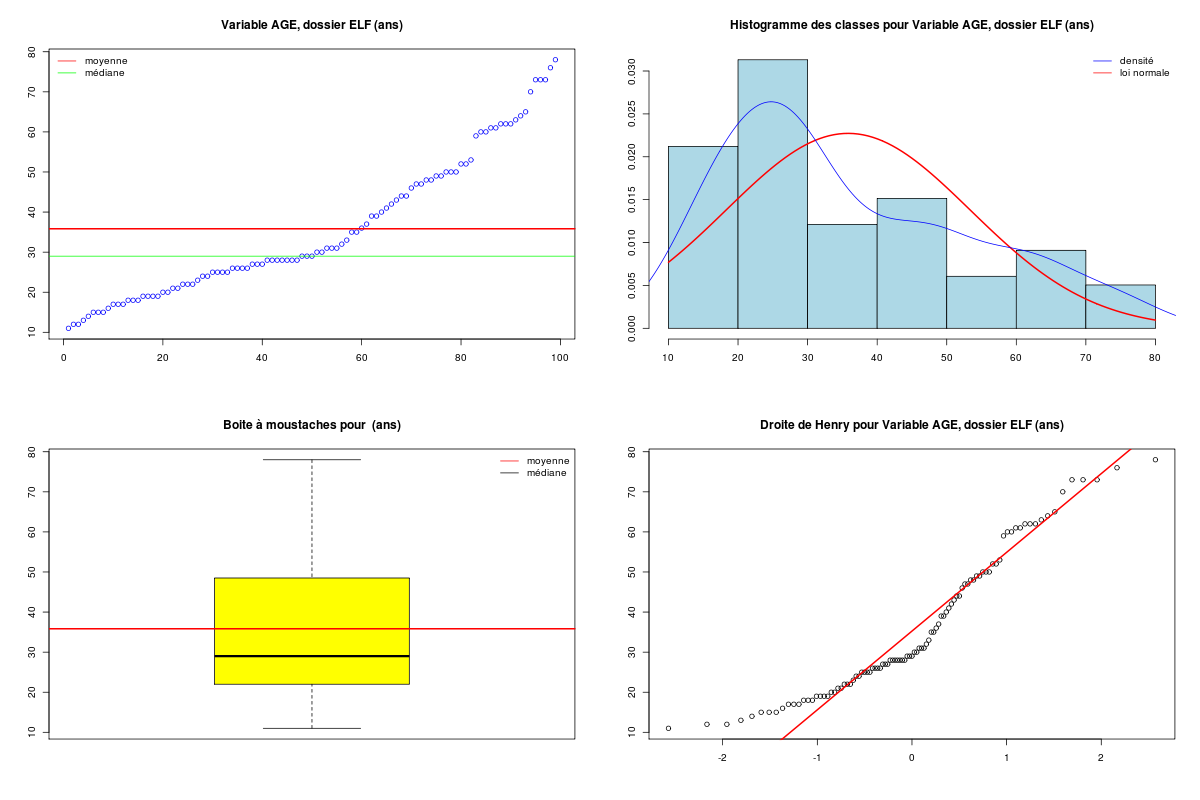
Aides à lire : sd(), median() et quantile() ainsi que stem(), plot(), hist() et qqplot.
Un de vos collègues qui ne sait pas utiliser R aurait besoin d'effectuer toujours les mêmes calculs pour des fichiers qui sont toujours formatés de la même façon. Que pouvez-vous mettre en place pour l'aider ? On pourra imaginer que les calculs sont des descriptions univariées et bivariées classiques de QT, comme par exemple pour les dossiers vins et iris et que les données sont au format DAR.
Quelle est la meilleure façon d'afficher les résultats pour votre collègue ? Saura-t-il faire un fichier Word (oh !) des résultats ? Peut-on se convaincre avec le code suivant
library(hwriter) hwriter:::showExample()que le package hwriter est une bonne solution ? Que peut-on en déduire sur la visualisation des résultats de "grandes structures" avec R ?
Quand on lit un fichier de données avec R, il y a conversion automatique des colonnes de valeurs caractères en facteurs. Pour éviter cela, il est classique de fournir les codes plutôt que les labels. Comment peut-on alors reconnaitre les QT des QL ? On essaiera de fournir une solution qui permet d'améliorer la fonction lesColonnes() suivante :
################################################################################################ lesColonnes <- function(df,envar=FALSE,print=TRUE,order=TRUE) { ################################################################################################ nbc <- ncol(df) nbl <- nrow(df) cat("Voici les ",nbc,"colonnes (stat. sur ",nbl," lignes en tout)\n\n") noms <- names(df) nbvs <- rep(NA,nbc) mins <- rep(NA,nbc) maxs <- rep(NA,nbc) ddc <- cbind((1:nbc),nbvs,mins,maxs) row.names(ddc) <- noms colnames(ddc) <- c("Num","NbVal","Min","Max") pdc <- 1:nbc for (idc in pdc) { laCol <- as.numeric(df[,idc]) laCol <- laCol[!is.na(laCol)] ddc[idc,2] <- length(laCol) ddc[idc,3] <- min(laCol) ddc[idc,4] <- max(laCol) } # fin pour if (order) { # tri par ordre alphabétique des noms de variables idx <- order(noms) ddc <- ddc[idx,] } # fin si print.data.frame(as.data.frame(ddc),quote=FALSE,row.names=TRUE) cat("\n") if (envar) { return(as.data.frame(ddc)) } else { return() } # fin de si } # fin de fonction lesColonnesA partir d'un data.frame(), on veut retirer toutes les variables fortement corrélées entre elles. Essayer d'écrire un programme R rapide pour le faire. On pourra utiliser les données leadb710x46.dar.txt issues de la base de données LEA à condition de retirer la variable de classe (en colonne 1).
Quelle corrélation faut-il utiliser ici ?
Des variables fortement corrélées sont considérées comme redondantes. Comment déterminer des paquets de variables corrélées entre elles et ne conserver qu'un représentant par paquet ? On pourra comparer avec le programme de la question précédente. Là encore, on pourra utiliser les données leadb710x46.dar.txt issues de la base de données LEA à condition de retirer la variable de classe (en colonne 1).
Si on admet que les variables sont des candidats potentiels pour une régression (linéaire, logistique...), comment choisir le meilleur représentant par paquet ?
Vous êtes dans un lieu avec un ordinateur qui a accès à Internet mais sur lequel R n'est pas installé. Y a-t-il un moyen d'exécuter "quelque part" votre code R ?
Faut-il vraiment apprendre à utiliser Sweave ? Est-ce compliqué ?
Est-ce facile d'interfacer R et php ?