![]()
![]()
|
Solutions pour la séance numéro 2 (énoncés)
|




 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Programmer en R
Session de formation, décembre 2013
gilles.hunault "at" univ-angers.fr
Solutions pour la séance numéro 2 (énoncés)
Il y a trois types de boucles : la boucle pour (for), la boucle tant_que (while) et la boucle répéter_jusquà (repeat). break permet de quitter une boucle, c'est-à-dire d'aller à l'instruction qui suit la fin de boucle.
La boucle POUR est une boucle générale d'itération pour une suite de valeurs (vecteur, liste, matrice...). C'est donc plus une boucle POUR_CHAQUE qu'une simple boucle POUR classique. La syntaxe est for (ELEMENT in SEQUENCE) {...} avec comme cas particulier 1:n pour SEQUENCE. La boucle TANT_QUE requiert une condition à tester. Si le résultat est vrai, on repasse dans le corps de boucle qui est délimité par les accolades. La syntaxe est while ( CONDITION ) { ... }. La boucle REPETER_JUSQUA exécute le corps de boucle jusqu'à que ce break soit rencontré. La syntaxe est repeat { ... }.
Une boucle POUR utilise en général un nombre fixe de valeurs, parfois paramétré comme dans for (ind in 1:n). La valeur de la séquence est utilisée une fois pour toutes ; ainsi n<-3 ; for (i in 1:n) { print(i) ; n<-5} n'affichera que trois valeurs et en sortie de boucle, i vaudra 3. Une boucle REPETER est toujours exécutée au moins une fois et peut servir à implémenter un interpréteur de commandes. La boucle TANT_QUE peut ne pas exécuter de code si la condition est fausse dès le départ. Il est possible de forcer la machine à recommencer à exécuter le corps de boucle à partir du début à l'aide de next. L'instruction break quitte la boucle la plus interne en cas de boucles imbriquées.
Il ne faut pas écrire 1:n-1 mais 1:(n-1) ou (1:n) - 1 suivant ce que l'on veut obtenir à cause de la priorité de l'opérateur :. D'ailleurs, il est conseillé de mettre des parenthèses dès que cela se complique. Ainsi a/b/c n'est pas lisible, même si cela un sens (et une valeur). Pour retrouver l'aide sur le symbole :, il faut utiliser help(`:`) avec le symbole "antiquote" obtenu avec AltGr+è sur un clavier français ou plus simplement avec help(":").
1:length(v) est dangereux car si length(v) vaut 0, R exécutera une boucle en décroissant de 1 à 0. A la limite, on pourrait écrire 1:max(1,length(v)) mais seq(v) est plus concis. Donc il faut préferer for (elt in struct) si on n'a pas besoin des indices de boucle ou for (ind in seq(stru)) si on doit utiliser les indices.
Voici quelques exemples de boucles pour vérifier tout cela :
# boucle POUR sur vecteur explicite cat("vecteur :\n") vect <- c(1,8,3) for (elt in vect) { print(elt) } # boucle POUR sur séquence de 1 à n cat("séquence :\n") pdv <- 1:4 # plage de valeurs for (ind in pdv) { print(ind) } # boucle POUR sur liste cat("liste :\n") maListe <- list(a=1,b=c(2,3),c=4,d=NA,e="FIN") for (li in maListe) { print(li) } # boucle POUR sur matrice cat("matrice :\n") mdata <- outer(1:2,3:5) # vous connaissez outer ? print(mdata) for (elt in mdata) { print(elt) } # boucle POUR et NEXT somme <- 0 for (ind in 1:100) { somme <- somme + 1/ind if (ind==6) { cat("...\n") } if ( (ind>5) & (ind<95)) { next } cat(sprintf("%03d",ind),sprintf("%10.6f",somme),"\n") } # fin pour # boucle TANT_QUE nb <- 1 while (nb*nb<200) { nb <- nb + 1 } cat(" le premier entier dont le carré dépasse 200 est ",nb,"\n") # boucles imbriquées et BREAK cat("table des puissances inférieures à 1 million\n") indi <- 1 while (indi<10) { indj <- 1 while (indj<10) { puiss <- indi**indj if (puiss<=10**6) { cat(sprintf("%9d",puiss)) } else { break } # fin si indj <- indj + 1 } # fin tant que cat("\n") indi <- indi + 1 } # fin tant que # boucle infinie d'interpréteur repeat { cat("Donner un entier dont vous voulez le carré ou 0 pour arrêter : ") rep <- as.numeric(readline()) if (rep==0) { break } cat(" le carre de ",rep," est ",rep**2,"\n") } # fin répéter_jusquàvecteur : [1] 1 [1] 8 [1] 3 séquence : [1] 1 [1] 2 [1] 3 [1] 4 liste : [1] 1 [1] 2 3 [1] 4 [1] NA [1] "FIN" matrice : [,1] [,2] [,3] [1,] 3 4 5 [2,] 6 8 10 [1] 3 [1] 6 [1] 4 [1] 8 [1] 5 [1] 10 001 1.000000 002 1.500000 003 1.833333 004 2.083333 005 2.283333 ... 095 5.136346 096 5.146763 097 5.157072 098 5.167277 099 5.177378 100 5.187378 le premier entier dont le carré dépasse 200 est 15 table des puissances inférieures à 1 000 000 1 1 1 1 1 1 1 1 1 2 4 8 16 32 64 128 256 512 3 9 27 81 243 729 2187 6561 19683 4 16 64 256 1024 4096 16384 65536 262144 5 25 125 625 3125 15625 78125 390625 6 36 216 1296 7776 46656 279936 7 49 343 2401 16807 117649 823543 8 64 512 4096 32768 262144 9 81 729 6561 59049 531441 Donner un entier dont vous voulez le carré ou 0 pour arrêter : 5 le carre de 5 est 25 Donner un entier dont vous voulez le carré ou 0 pour arrêter : 8 le carre de 8 est 64 Donner un entier dont vous voulez le carré ou 0 pour arrêter : 0Pour les autres questions posées, nous fournissons le code suivant et son résultat d'exécution :
# boucles avec un pas variable nombre <- 0 for (ind in 1:10) { if (ind <= 5) { nombre <- nombre + 1 } else { if (nombre==5) { nombre = 1 } nombre <- nombre * 10 } # fin si cat(" étape ",sprintf("%2d",ind)," n = ",sprintf("%8d",nombre),"\n") } # fin pour ind # boucle pour un ensemble de valeurs particulières vect <- c(12,38,45,70,50) cat(" pour le vecteur ",vect,"\n") for (ind in 1:length(vect)) { cat(paste("V[",ind,"] = ",vect[ind],sep="","\n")) } # fin pour vect <- c(12,38,45,70,50) for (elt in vect) { cat("valeur ",elt,"\n") } # fin pour # calcul de la racine d'un nombre par récurence racine <- function(X,prec=10**(-4),debug=TRUE) { valp <- 0 valc <- 1 while (abs(valc-valp)>prec) { valp <- valc valc <- (X/(valc*2)) + (valc/2) # pour debug : cat(" valeur ",valc,"\n") } # fin tant que if (debug) { cat(" racine de ",X," vaut à peu prés : ",valc, " ; vraie valeur ",sqrt(X)," différence ",valc-sqrt(X),"\n") } return( valc ) } # fin de fonction racine(2) racine(3,0.1) rdt <- racine(3,0.1,debug=FALSE) # sans affichageétape 1 n = 1 étape 2 n = 2 étape 3 n = 3 étape 4 n = 4 étape 5 n = 5 étape 6 n = 10 étape 7 n = 100 étape 8 n = 1000 étape 9 n = 10000 étape 10 n = 100000 pour le vecteur 12 38 45 70 50 V[1] = 12 V[2] = 38 V[3] = 45 V[4] = 70 V[5] = 50 valeur 12 valeur 38 valeur 45 valeur 70 valeur 50 racine de 2 vaut à peu prés : 1.414214 ; vraie valeur 1.414214 différence 1.594724e-12 [1] 1.414214 racine de 3 vaut à peu prés : 1.732143 ; vraie valeur 1.732051 différence 9.204957e-05 [1] 1.732143Pour dichotomiser, il faut commencer par créer un vecteur de même longueur que V. Utiliser rep() pour cela est une bonne solution. Mettre des NA est prudent, mais non optimal. La solution avec une boucle est facile à suivre, car il n'y a qu'un test en si/alors/sinon dans la boucle. Pour faire plus simple, il faut se rappeler que R sait faire des tests sur tout un vecteur à la fois. On peut donc définir un filtre et mettre VRAI si le filtre s'applique, FAUX sinon. Enfin, pour optimiser, on peut tout initialiser à FAUX et remplacer avec des VRAI si la condition d'infériorité est vérifiée.
############################################################# dichotomiseVersion1 <- function(vecteur,seuil) { ############################################################# if (missing(seuil)) { cat("Paramètre seuil manquant.\n") cat("Rappel de la syntaxe de la fonction : \n") cat(" dichotomiseVersion1(vecteur,seuil) \n") cat("Exemple d'utilisation de la fonction : \n") cat(" dichotomiseVersion1(vecteur=1:20,seuil=5) \n") cat("La fonction renvoie un vecteur de TRUE et FALSE suivant \n") cat("que les éléments du vecteur sont STRICTEMENT inférieurs au seuil ou non.\n\n") return() } # fin de si # version avec une boucle et un test en si nbe <- length(vecteur) vectBin <- rep(NA,nbe) for (ide in 1:nbe) { if (vecteur[ide]<seuil) { vectBin[ide] <- TRUE } else { vectBin[ide] <- FALSE } # fin de si } # fin pour ide return( vectBin ) } # fin de fonction dichotomiseVersion1 ############################################################# dichotomiseVersion2 <- function(vecteur,seuil) { ############################################################# if (missing(seuil)) { cat("\nParamètre seuil manquant.\n") cat("Rappel de la syntaxe de la fonction : \n") cat(" dichotomiseVersion2(vecteur,seuil) \n") cat("Exemple d'utilisation de la fonction : \n") cat(" dichotomiseVersion2(vecteur=1:20,seuil=5) \n") cat("La fonction renvoie un vecteur de TRUE et FALSE suivant \n") cat("que les éléments du vecteur sont STRICTEMENT inférieurs au seuil ou non.\n\n") return() } # fin de si # version sans boucle et non optimisée nbe <- length(vecteur) vectBin <- rep(NA,nbe) filtre <- vecteur<seuil vectBin[ filtre ] <- TRUE vectBin[ !filtre ] <- FALSE return( vectBin ) } # fin de fonction dichotomiseVersion2 ############################################################# dichotomiseVersion3 <- function(vecteur,seuil) { ############################################################# if (missing(seuil)) { cat("\nParamètre seuil manquant.\n") cat("Rappel de la syntaxe de la fonction : \n") cat(" dichotomiseVersion3(vecteur,seuil) \n") cat("Exemple d'utilisation de la fonction : \n") cat(" dichotomiseVersion3(vecteur=1:20,seuil=5) \n") cat("La fonction renvoie un vecteur de TRUE et FALSE suivant \n") cat("que les éléments du vecteur sont STRICTEMENT inférieurs au seuil ou non.\n\n") return() } # fin de si # version optimisée et sans boucle vectBin <- rep(FALSE,length(vecteur)) vectBin[ vecteur<seuil ] <- TRUE return( vectBin ) } # fin de fonction dichotomiseVersion3> source("dichotomise.r",echo=TRUE) > dichotomiseVersion1() Paramètre seuil manquant. Rappel de la syntaxe de la fonction : dichotomiseVersion1(vecteur,seuil) Exemple d'utilisation de la fonction : dichotomiseVersion1(vecteur=1:20,seuil=5) La fonction renvoie un vecteur de TRUE et FALSE suivant que les éléments du vecteur sont STRICTEMENT inférieurs au seuil ou non. NULL > dichotomiseVersion1(1:20,5) [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [15] FALSE FALSE FALSE FALSE FALSE FALSE > dichotomiseVersion2() Paramètre seuil manquant. Rappel de la syntaxe de la fonction : dichotomiseVersion2(vecteur,seuil) Exemple d'utilisation de la fonction : dichotomiseVersion2(vecteur=1:20,seuil=5) La fonction renvoie un vecteur de TRUE et FALSE suivant que les éléments du vecteur sont STRICTEMENT inférieurs au seuil ou non. NULL > dichotomiseVersion2(vecteur=1:20,seuil=5) [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [15] FALSE FALSE FALSE FALSE FALSE FALSE > dichotomiseVersion3(vecteur=1:20,seuil=5) [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [15] FALSE FALSE FALSE FALSE FALSE FALSEUne fois les valeurs logiques obtenues, puisque FALSE vaut 0 et TRUE vaut 1, il suffit de leur ajouter 1 pour obtenir des indices utilisables. Il faut juste mettre les adjectifs ou les valeurs souhaitées dans le bon ordre, soit ici "vieux" avant "jeune" et "blue" avant "red" :
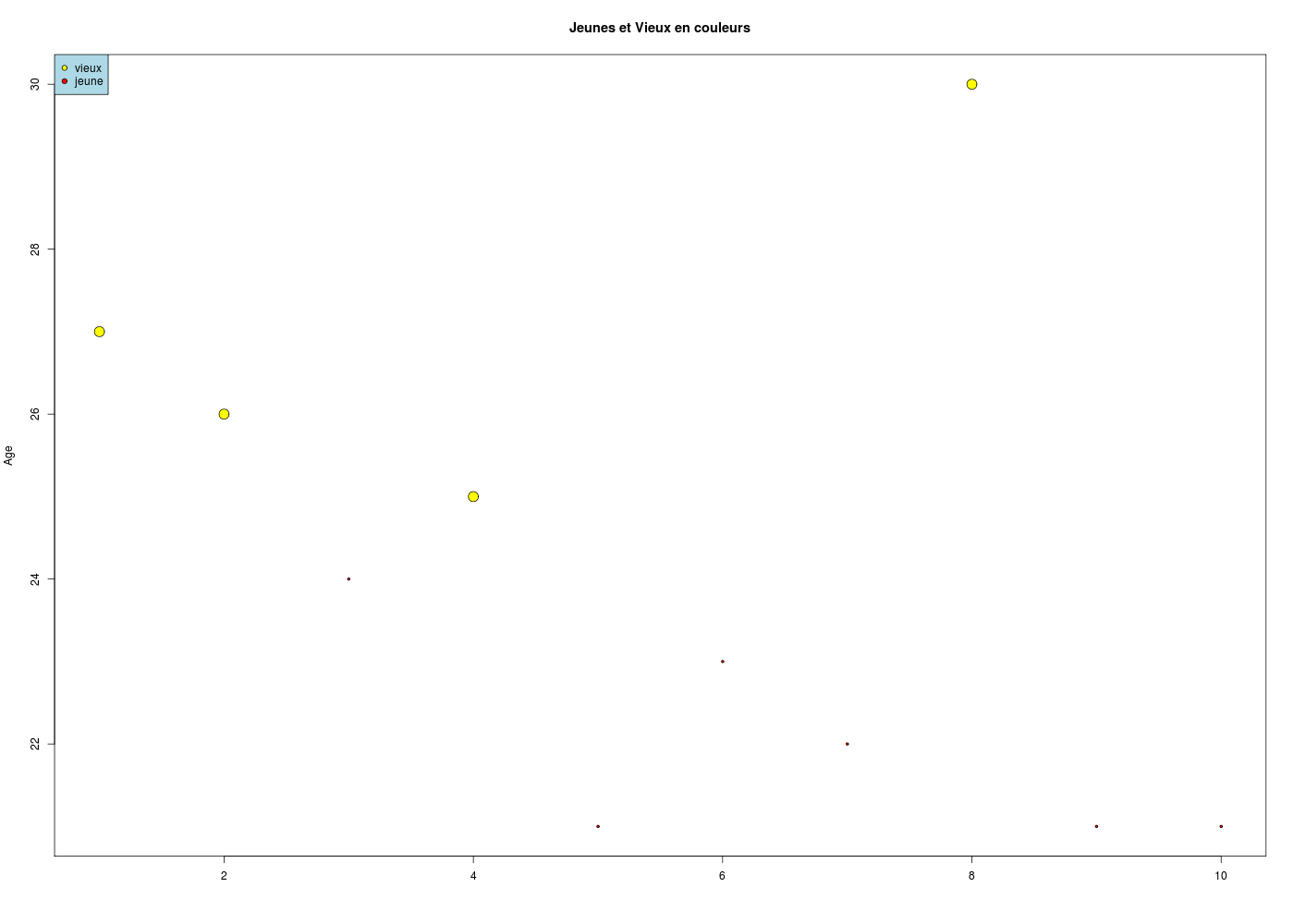
vectAges <- round( runif(10,20,30) ) cat(" les ages ") print(vectAges) vectLogi <- dichotomiseVersion3(vectAges,25) cat(" les valeurs logiques ") print(vectLogi) vectAdje <- c("vieux","jeune")[ 1+vectLogi ] cat(" les adjectifs ") print(vectAdje) coulAges <- c("blue","red") vectCoul <- coulAges[ 1+vectLogi ] cat(" les couleurs ") print(vectCoul) # utilisons cela pour tracer les ages en couleurs plot( vectAges, pch=19,col=vectCoul ) plot( vectAges, pch=21,bg=vectCoul,col="black" ) coulAges <- c("yellow","red") vectCoul <- coulAges[ 1+vectLogi ] vectCex <- c(2,0.5)[1 + vectLogi ] par( oma=rep(1,4) ) # pour ne pas être trop près des bords graphique <- "" # à permuter éventuellement graphique <- "png" # à permuter éventuellement if (graphique=="png") { nomgr <- "agesCoul.png" gr(nomgr) # fonction (gH) pour png() spécial "grands écrans" } # fin si plot( vectAges, pch=21,bg=vectCoul,col="black", cex=vectCex,main="Jeunes et Vieux en couleurs", xlab = "", ylab= "Age" ) # fin de plot legend(x="topleft",legend=c("vieux","jeune"),col="black", pt.bg=c("yellow","red"),pch=21,bg="lightblue" # attention à bg et pt.bg ) # de plot if (graphique!="") { dev.off() cat(" graphique ",nomgr," généré \n") } # fin siles ages [1] 27 26 24 25 21 23 22 30 21 21 les valeurs logiques [1] FALSE FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE les adjectifs [1] "vieux" "vieux" "jeune" "vieux" "jeune" "jeune" "jeune" "vieux" "jeune" "jeune" les couleurs [1] "blue" "blue" "red" "blue" "red" "red" "red" "blue" "red" "red" graphique agesCoul.png généré
Trouver les positions du minimum, c'est passer en revue tous les éléments et retenir leur position à chaque fois que l'élément est égal au minimum. Il n'est pas possible de prédire la longueur du vecteur des positions et une solution comme pdm <- c(pdm,position) dans une boucle est particulièrement inefficace. Une solution plus élégante consiste à retenir les indices correspondant au minimum via (1:length(vect))[vect==max(vect)] mais il est sans doute plus lisible de séparer et détailler la génération des indices, le filtre et l'extraction des indices en trois affectations, comme dans la fonction posMinV3(). Comme R dispose d'une fonction (sans doute vectorielle) nommée which(), le mieux est de l'utiliser.
###################################################################### posMinV1 <- function(vect) { ###################################################################### # lent : on part d'un vecteur vide et on lui ajoute chaque position vue du minimum if (missing(vect)) { cat("\nSyntax: posMinV1(vect).\n") } else { pdm <- c() # c() est la notation pour le vecteur vide nbe <- length(vect) vm <- min(vect) # valeur du Minimum for (ide in 1:nbe) { # pour debug : cat(" ide ",sprintf("%3d",ide)," x = ",vect[ide]," donc pdm " , pdm,"\n") if (vect[ide]==vm) { pdm <- c(pdm,ide) } } # fin pour ide return(pdm) } # fin si } # fin de fonction posMinV1 ###################################################################### posMinV2 <- function(vect) { ###################################################################### # rapide ? on utilise la comparaison vectorielle avec == if (missing(vect)) { cat("\nSyntax: posMinV2(vect).\n") } else { return( (1:length(vect))[vect==min(vect)] ) } # fin si } # fin de fonction posMinV2 ###################################################################### posMinV3 <- function(vect) { ###################################################################### # sans doute aussi rapide que posMinV2 mais plus lisible if (missing(vect)) { cat("\nSyntax: posMinV3(vect).\n") } else { pdv <- 1:length(vect) # plage de variation des indices flt <- vect==min(vect) # filtre pdm <- pdv[ flt ] return(pdm) } # fin si } # fin de fonction posMinV3 ###################################################################### posMinV4 <- function(vect) { ###################################################################### # sans doute aussi rapide que posMinV2 mais plus lisible if (missing(vect)) { cat("\nSyntax: posMinV4(vect).\n") } else { pdv <- 1:length(vect) # plage de variation des indices vmi <- min(vect) # valeur du min flt <- vect==vmi # filtre pdm <- pdv[ flt ] return(pdm) } # fin si } # fin de fonction posMinV4 ###################################################################### posMinV5 <- function(vect) { ###################################################################### # on utilise which if (missing(vect)) { cat("\nSyntax: posMinV5(vect).\n") } else { return( which(vect==min(vect)) ) } # fin si } # fin de fonction posMinV5 ###################################################################### posMinV6 <- function(vect) { ###################################################################### # on utilise which et on sort min(vect) du test if (missing(vect)) { cat("\nSyntax: posMinV6(vect).\n") } else { vmi <- min(vect) # valeur du min return( which(vect==vmi) ) } # fin si } # fin de fonction posMinV6> source("posmin.r") > (va <- rbinom(n=30,size=8,prob=0.2)) [1] 4 1 2 2 2 2 0 3 1 3 1 1 0 2 0 3 2 1 2 4 1 2 2 0 2 3 0 3 1 4 > posMinV1() Syntax: posMinV1(vect). > posMinV1(va) [1] 7 13 15 24 27 > posMinV2(va) [1] 7 13 15 24 27 > posMinV3(va) [1] 7 13 15 24 27 > posMinV4(va) [1] 7 13 15 24 27 > posMinV5(va) [1] 7 13 15 24 27 > posMinV6(va) [1] 7 13 15 24 27Si, pour une raison ou pour une autre, on ne peut pas prédire la taille du résultat et si on doit absolument passer par une boucle pour, l'optimisation consiste à ne PAS changer la taille du vecteur résultat à chaque passage dans la boucle mais à le faire «de temps en temps», quand la taille ne suffit plus. Si (par sondage, expertise, test...) on connait en gros l'augmentation de la taille, on peut en profiter pour ne pas trop augmenter à chaque fois la taille ; sinon on peut choisir de la doubler
###################################################################### posMinV1bis <- function(vect) { ###################################################################### # on alloue au départ 5 positions de minimum (variable alloc) # et on rajoute 5 NA quand on a rempli ces positions if (missing(vect)) { cat("\nSyntax: posMinV1bis(vect).\n") } else { alloc <- 5 pdm <- rep(NA,alloc) nbe <- length(vect) vm <- min(vect) # Valeur du Minimum nb <- 0 # nombre de positions vues du minimum for (ide in 1:nbe) { if (vect[ide]==vm) { nb <- nb + 1 # et une position de plus # si cela risque de déborder, on alloue plus de place if (nb>length(pdm)) { length(pdm) <- length(pdm) + alloc # mette ici 2*length(alloc) pour doubler la place } # fin si pdm[nb] <- ide } # fin si # pour debug : cat(" ide ",sprintf("%3d",ide)," x = ",vect[ide]," donc pdm " , pdm,"\n") } # fin pour ide # pour ne pas renvoyer de NA, soit pdm<- na.omit(pdm) # soit pdm <- pdm[ 1:nb ] return(pdm) } # fin si } # fin de fonction posMinV1bis # des 1 et des 2, avec en gros 2/3 de 1 vectAlea <- 1 + rbinom(n=30,size=1,p=2/3) cat("Vecteur") cat(vectAlea,"\n") posMinV1bis( vectAlea )Vecteur1 2 2 2 1 2 2 1 1 2 1 1 2 2 2 1 1 2 2 1 1 2 2 1 1 2 2 2 1 1 ide 1 x = 1 donc pdm 1 NA NA NA NA ide 2 x = 2 donc pdm 1 NA NA NA NA ide 3 x = 2 donc pdm 1 NA NA NA NA ide 4 x = 2 donc pdm 1 NA NA NA NA ide 5 x = 1 donc pdm 1 5 NA NA NA ide 6 x = 2 donc pdm 1 5 NA NA NA ide 7 x = 2 donc pdm 1 5 NA NA NA ide 8 x = 1 donc pdm 1 5 8 NA NA ide 9 x = 1 donc pdm 1 5 8 9 NA ide 10 x = 2 donc pdm 1 5 8 9 NA ide 11 x = 1 donc pdm 1 5 8 9 11 ide 12 x = 1 donc pdm 1 5 8 9 11 12 NA NA NA NA ide 13 x = 2 donc pdm 1 5 8 9 11 12 NA NA NA NA ide 14 x = 2 donc pdm 1 5 8 9 11 12 NA NA NA NA ide 15 x = 2 donc pdm 1 5 8 9 11 12 NA NA NA NA ide 16 x = 1 donc pdm 1 5 8 9 11 12 16 NA NA NA ide 17 x = 1 donc pdm 1 5 8 9 11 12 16 17 NA NA ide 18 x = 2 donc pdm 1 5 8 9 11 12 16 17 NA NA ide 19 x = 2 donc pdm 1 5 8 9 11 12 16 17 NA NA ide 20 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 NA ide 21 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 21 ide 22 x = 2 donc pdm 1 5 8 9 11 12 16 17 20 21 ide 23 x = 2 donc pdm 1 5 8 9 11 12 16 17 20 21 ide 24 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 21 24 NA NA NA NA ide 25 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 NA NA NA ide 26 x = 2 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 NA NA NA ide 27 x = 2 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 NA NA NA ide 28 x = 2 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 NA NA NA ide 29 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 29 NA NA ide 30 x = 1 donc pdm 1 5 8 9 11 12 16 17 20 21 24 25 29 30 NA [1] 1 5 8 9 11 12 16 17 20 21 24 25 29 30On peut utiliser la fonction duree() que nous avions définie dans la séance 1 et qui n'est pas exactement la même que celle définie dans statgh.r, ce qui peut se voir ici.
Voici des exemples de temps d'exécution pour la dichotomisation :
# chargement des trois fonctions source("dichotomise.r",encoding="latin1") # définition d'un même jeu de données aléatoire pour comparaison nbVal <- 5*10**6 vectAlea <- round( runif(n=nbVal,min=1,max=100) ) # vitesses d'exécution cat(" pour dichotomiseVersion1(vectAlea,seuil=50) : ") duree( v1 <- dichotomiseVersion1(vectAlea,seuil=50) ) # en gros 27.4 s cat(" pour dichotomiseVersion2(vectAlea,seuil=50) : ") duree( v2 <- dichotomiseVersion1(vectAlea,seuil=50) ) # environ 27.7 s cat(" pour dichotomiseVersion3(vectAlea,seuil=50) : ") duree( v3 <- dichotomiseVersion1(vectAlea,seuil=50) ) # à peu près 26.5 s # et si on comparait avec ifelse ? cat(" pour ifelse(vectAlea<seuil,TRUE,FALSE) : ") duree( v4 <- ifelse(vectAlea<50,TRUE,FALSE) ) # à peu près 3.8 s # et avec le simple test vectoriel ? cat(" pour vectAlea<seuil : ") duree( v5 <- vectAlea<50) # à peu près 0.17 spour dichotomiseVersion1(vectAlea,seuil=50) : durée = 28 s pour dichotomiseVersion2(vectAlea,seuil=50) : durée = 27 s pour dichotomiseVersion3(vectAlea,seuil=50) : durée = 26 s pour ifelse(vectAlea<seuil,TRUE,FALSE) : durée = 4 s pour vectAlea<seuil : durée = 0.2 set des exemples de temps d'exécution pour les positions du minimum :
# chargement des trois fonctions source("posmin.r",encoding="latin1") # définition d'un même jeu de données aléatoire pour comparaison nbVal <- 5*10**6 vectAlea <- round( runif(n=nbVal,min=1,max=100) ) # vitesses d'exécution cat(" pour posMinV1(vectAlea) : ") duree( posMinV1(vectAlea) ) cat(" pour posMinV2(vectAlea) : ") duree( posMinV2(vectAlea) ) cat(" pour posMinV3(vectAlea) : ") duree( posMinV3(vectAlea) ) cat(" pour posMinV4(vectAlea) : ") duree( posMinV4(vectAlea) ) cat(" pour posMinV5(vectAlea) : ") duree( posMinV5(vectAlea) ) cat(" pour posMinV6(vectAlea) : ") duree( posMinV6(vectAlea) )source("durees4.r",encoding="latin1") pour posMinV1(vectAlea) : durée = 10.980100 s pour posMinV2(vectAlea) : durée = 0.4090939 s pour posMinV3(vectAlea) : durée = 0.5339005 s pour posMinV4(vectAlea) : durée = 0.4145384 s pour posMinV5(vectAlea) : durée = 0.2373221 s pour posMinV6(vectAlea) : durée = 0.1609249 sComme le fichier .Rdata, le fichier .Rprofile est un fichier texte qui contient du code R que R consulte automatiquement. Il peut y en avoir un pour l'utilisateur (configuration générale) et un dans le sous-répertoire courant (configuration spécialisée). De plus R permet de définir des fonctions .First() et .Last() bien utiles, par exemple pour afficher un message de bienvenue, ou pour sauvegarder de façon incrémentale tout le travail effectué. Si on place le code de la fonction duree() dans .Rprofile, alors duree() est définie et donc utilisable dès que R est chargé.
Voici quelques liens pour approfondir cette notion de profil :
customizing R explications du site Quick-R configure R R for dummies Rprofile York Wiki for statistical consulting Comme déjà dit plus haut, les options se gèrent via la fonction options() du package base. Il est donc intéressant de mettre le paramétrage désiré des options dans un fichier .Rprofile.
Pour stopper l'exécution, on peut utiliser la fonction stop(). Pour poser une question à l'utilisateur, readline() est un bon choix. Notre fonction attends() montre comment utiliser ces deux fonctions ensemble. Sys.sleep(n) attend n secondes avant de continuer.
# démonstration de stop, Sys.sleep et attends demo1 <- function() { for (idv in 1:10) { cat("i = ",idv,"\n") if (idv==5) { stop("j'arrête à 5 !\n") } # fin si } # fin pour } # fin de fonction demo1 # ----------------------------------- demo2 <- function() { for (idv in 1:10) { cat("i = ",idv,"\n") if (idv==6) { stop("j'arrête à 6 !\n",call.=FALSE) } # fin si } # fin pour } # fin de fonction demo2 # ----------------------------------- demo3 <- function() { cat(Sys.time()," ou encore ",format(Sys.time(),"%a %d %b %Y à %X"),"\n") cat("(pause de 5 secondes : )\n") Sys.sleep( 5 ) cat(Sys.time()," ou encore ",format(Sys.time(),"%a %d %b %Y à %X"),"\n") } # fin de fonction demo3 # ----------------------------------- demo4 <- function() { for (idv in 1:10) { cat("\ni = ",idv) attends(" -- on continue ? ") } # fin pour } # fin de fonction demo4 # ----------------------------------- # à décommenter, mais demo1() et demo2() arrêtent l'éxécution # demo1() # demo2() # demo3() # demo4()# -- demo1() i = 1 i = 2 i = 3 i = 4 i = 5 Erreur dans demo1() : j'arrête à 5 ! # -- demo2() i = 1 i = 2 i = 3 i = 4 i = 5 i = 6 Erreur : j'arrête à 6 ! # -- demo3() 1328282464 ou encore ven. 03 févr. 2012 à 16:21:04 (pause de 5 secondes : ) 1328282469 ou encore ven. 03 févr. 2012 à 16:21:09 # -- demo4() : on a appuyé 3 fois sur entrée, puis on # a tapé non et "enter" i = 1 -- on continue ? i = 2 -- on continue ? i = 3 -- on continue ? i = 4 -- on continue ? nonVoici un exemple de fonction possible pour tester si un fichier existe basée sur file.exists() décrite dans files :
testeFichier <- function(nomDeFichier="") { while (nomDeFichier=="") { nomDeFichier <- readline("donner un nom de fichier : ") } # fin de si if (file.exists(nomDeFichier)) { cat(" le fichier ",nomDeFichier," existe.\n") } else { cat(" le fichier ",nomDeFichier," n'existe pas.\n") } # fin de si } # fin de fonction testeFichierLa fonction R qui permet de choisir interactivement est file.choose(). R renvoie alors le chemin d'accès complet au fichier.
Nous proposons deux façons de procéder, suivant que l'on veut juste un affichage ou un tableau de résultats. On remarquera qu'un fichier vide (comme vide.txt) a bien une ligne, vide, mais une ligne quand même.
actionFichier <- function(nomFichier) { #-------------------------------- if (!file.exists(nomFichier)) { cat(nomFichier," n'existe pas \n") } else { fh <- file(nomFichier,open="r") vlig <- readLines(fh,n=-1) nbl <- length(vlig) close(fh) cat(sprintf("%-15s",nomFichier)," contient ",sprintf("%6d",nbl)," ligne(s).\n") ; } # fin si } # fin de fonction actionFichier actionFichiers <- function(listeFichiers) { #---------------------------------------- for (fichier in listeFichiers) { actionFichier( fichier ) } # fin pour } # fin de fonction actionFichiers # ==================================== actionSurFichier <- function(nomFichier="") { #-------------------------------- # code -2 si nom de fichier vide if (nchar(nomFichier)==0) { return(-2) } # fin si # code -1 si fichier non vu if (!file.exists(nomFichier)) { return(-1) } # fin si # si on arrive ici, le fichier existe fh <- file(nomFichier,open="r") vlig <- readLines(fh,n=-1) nbl <- length(vlig) close(fh) return(nbl) } # fin de fonction actionSurFichier actionSurFichiers <- function(listeFichiers) { #---------------------------------------- mdr <- matrix(nrow=length(listeFichiers),ncol=1) colnames(mdr) <- c("Nb Lignes") vecteurFichiers <- listeFichiers row.names(mdr) <- listeFichiers for (ific in seq(listeFichiers)) { fichier <- listeFichiers[[ific]] # remarquer les doubles crochets mdr[ific,1] <- actionSurFichier( fichier ) } # fin pour return( mdr) } # fin de fonction actionSurFichiers # ==================================== cats("Liste des fichiers :") lstFic <- c("bete.txt","histoire.txt","simple.txt","vide.txt",paste("f",sprintf("%02d",5:6),".txt",sep="")) cat(lstFic,"\n") cats("Démonstration de actionFichiers") actionFichiers(lstFic) # remarque : on aurait aussi pu utiliser : null <- lapply(FUN=actionFichier,X=lstFic) cats("Démonstration de actionSurFichiers") res <- actionSurFichiers(lstFic) print(res)Liste des fichiers : ==================== bete.txt histoire.txt simple.txt f05.txt f06.txt Démonstration de actionFichiers =============================== bete.txt n'existe pas histoire.txt contient 1 ligne(s). simple.txt contient 58 ligne(s). f05.txt contient 5 ligne(s). f06.txt contient 6 ligne(s). Démonstration de actionSurFichiers ================================== Nb Lignes bete.txt -1 histoire.txt 1 simple.txt 58 f05.txt 5 f06.txt 6L'instruction paste("fic",1:3,".txt",sep="") est l'équivalent de c("fic1.txt","fic2.txt","fic3.txt").
"fic01.txt fic02.txt fic03.txt" s'obtient par paste("fic",sprintf("%02d",1:3),".txt",sep="",collapse=" "). Indéendamment du fait de savoir s'il faut produire une seule chaine ou un vecteur de chaines, cette deuxième écriture de chaque nom de fichier est sans doute meilleure que la première quand on a beaucoup de fichiers parce qu'on peut alors les avoir dans l'ordre facilement (sinon fic1.txt est suivi de fic10.txt au lieu de fic2.txt).
Il est possible d'obtenir des listes de fichiers de fichiers avec les fonctions list.files() et list.dirs(). Attention : pour list.files il faut nommer impérativement le paramètre pattern. Ainsi list.files(pattern="*.txt") est correct, alors que list.files("*.txt") est incorrect. Comme notre fonction accepte une structure en entrée, on peut exécuter actionSurFichiers(list.files(pattern="*.txt")). Il est possible de choisir interactivement un nom de fichier si on utilise file.choose() dont l'aide est dans files et on dispose alors du chemin d'accès complet au fichier, pas seulement de son nom et de son extension.
Telle que nous avons écrit la fonction actionSurFichiers() avec les doubles crochets, les appels avec une vecteur et une liste sont acceptés, mais si on a mis tous les noms de fichier dans une seule chaine, il faut «splitter»la chaine :
actionSurFichiers( c("f05.txt","simple.txt") ) actionSurFichiers( list("f05.txt","simple.txt") ) # not run : actionSurFichiers( "f05.txt simple.txt" ) actionSurFichiers( unlist( strsplit(x="f05.txt simple.txt",split=" ") ) ) actionSurFichiers( unlist( strsplit(x="f05.txt simple.txt",split="\\s+") ) )Nb Lignes f05.txt 5 simple.txt 58 Nb Lignes f05.txt 5 simple.txt 58 Nb Lignes f05.txt 5 simple.txt 58 Nb Lignes f05.txt 5 simple.txt 58R dispose d'un vecteur letters des 26 lettres minuscules et du vecteur LETTERS pour les majuscules. Couplé à paste() ce vecteur permet de générer des noms de fichier. Pour tester si une chaine correspond à un modèle, on peut utiliser les expressions régulières via regexpr() mais attention : le point a alors un sens spécial, celui de n'importe quel caractère. Un «vrai» point doit se noter \. mais comme on est dans une chaine de caractères, le slash doit être doublé. Par contre, le caractère * des noms de fichiers classiques doit s'écrire .* car * seul n'est qu'un facteur de répétition signifiant 0 fois ou plus.
Voir notre tuteur à titre de rappel sur les expressions régulières.
Comme regexpr renvoie entre autres la position entière positive où on trouve l'expression régulière ou -1 si elle n'est pas trouvée, il suffit d'utiliser v > 0 comme filtre si v est le vecteur résultat de regexpr pour gérer les éléments qui correspondent. Comme on peut le voir ci-dessous, regexpr traite aussi bien les vecteurs que les listes car les listes peuvent être assimilées à des vecteurs via l'indexation avec des crochets...
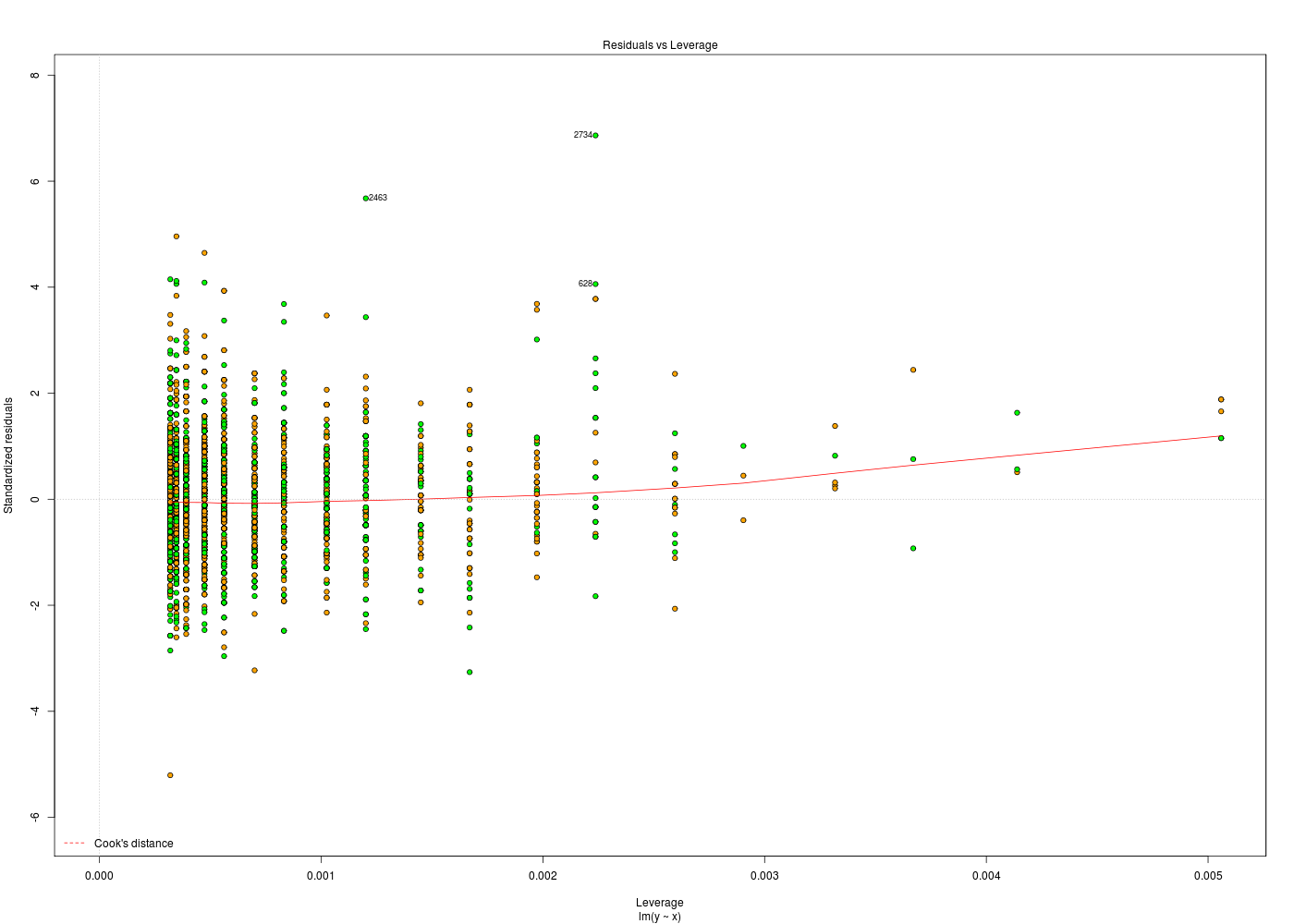
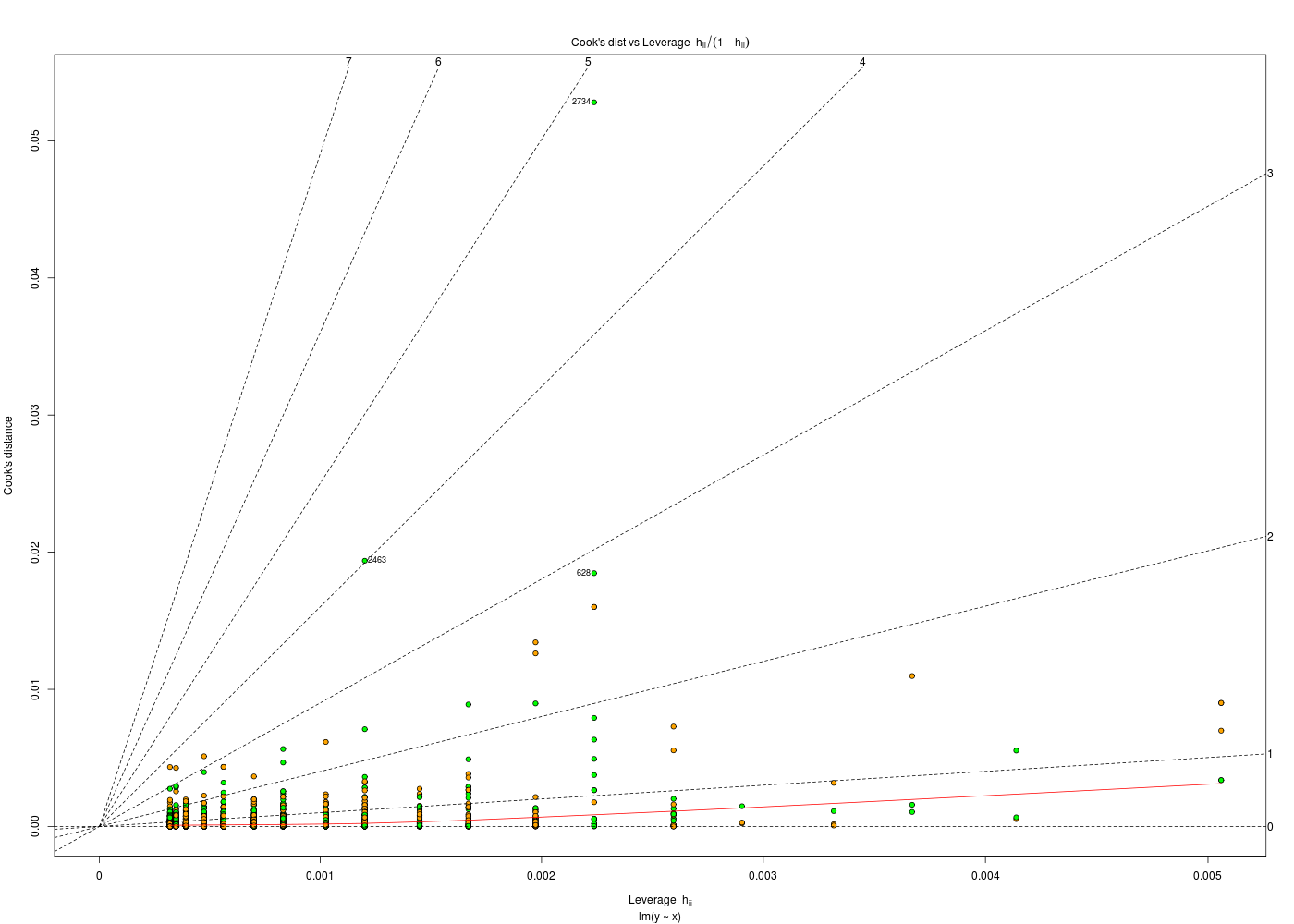
nbf <- 6 listeFic1 <- paste("Comp", LETTERS[1:nbf], "liste.txt", sep="") listeFic1 <- c("fic44abcnum.pair.txt",listeFic1, "fic44d38num.pair.txt") listeFic2 <- as.list( listeFic1 ) cat("Voici tous les fichiers :\n") print(cbind(listeFic1),quote=FALSE) cat("\nCeux qui correspondent au modèle fic44*num.pair.txt (mode vecteur): \n") ficFlt1 <- regexpr("fic44.*num\\.pair\\.txt",listeFic1,perl=TRUE) > 0 print(cbind( listeFic1[ ficFlt1 ] ) ) cat("\nCeux qui correspondent au modèle fic44*num.pair.txt (mode liste) : \n") ficFlt2 <- regexpr("fic44.*num\\.pair\\.txt",listeFic2,perl=TRUE) > 0 print(cbind( listeFic2[ ficFlt2 ] ) ) cat("\nlisteFic1 ") if (is.vector(listeFic1)) { cat("est") } else { cat("n'est pas") } # fin si cat(" un vecteur. " ) cat("listeFic1 ") if (is.list(listeFic1)) { cat("est") } else { cat("n'est pas") } # fin si cat(" une liste.\n\n" ) if (is.vector(listeFic2)) { cat("listeFic2 est un vecteur. ") } else { cat("listeFic2 n'est pas un vecteur. ") } # fin si if (is.list(listeFic2)) { cat("listeFic2 est une liste.\n") } else { cat("listeFic2 n'est pas une liste.\n") } # fin siVoici tous les fichiers : listeFic1 [1,] fic44abcnum.pair.txt [2,] CompAliste.txt [3,] CompBliste.txt [4,] CompCliste.txt [5,] CompDliste.txt [6,] CompEliste.txt [7,] CompFliste.txt [8,] fic44d38num.pair.txt Ceux qui correspondent au modèle fic44*num.pair.txt (mode vecteur): [,1] [1,] "fic44abcnum.pair.txt" [2,] "fic44d38num.pair.txt" Ceux qui correspondent au modèle fic44*num.pair.txt (mode liste) : [,1] [1,] "fic44abcnum.pair.txt" [2,] "fic44d38num.pair.txt" listeFic1 est un vecteur. listeFic1 n'est pas une liste. listeFic2 est un vecteur. listeFic2 est une liste.y~x est une formule, (de classe formula), de type langage et de mode appel (call). L'afficher avec print se contente d'afficher la formule alors que son tracé aboutit aux points de y en fonction de x. Son résumé est des plus succincts ! lm(y~x) est une liste assez compliquée de 12 éléments, certains étant des vecteurs. Son affichage ne fournit que les coefficients du modèle linéaire alors que son tracé fournit 4 graphiques de diagnostic (par défaut, sur les 6 possibles). Son résumé affiche des statistiques sur les résidus, sur les coefficients et sur la qualité d'ajustement du modèle.
anova( lm(y~x) ) est un objet encore plus complexe, qui participe de deux classes (anova et data.frame). Son affichage fournit le tableau classique d'analyse de la variance, son tracé est celui d'un data.frame, il s'agit donc de pairs(obj3) et son résumé est ici assez peu intéressant (c'est celui, usuel, des variables quantitatives) car il s'applique au tableau 5x2 des résultats.
summary( anova(lm(y~x)) ) est justement ce tableau de résultats, de classe tableau, et en format caractère. Donc vouloir le tracer ou en demander un résumé provoque une erreur.
her <- lit.dar.wd("her.dar") attach(her) # plus pratique ici que her$taille ou her[,"taille"] # et plus sûr que her[,3] # -------------------------------------- obj1 <- poids ~ taille # plus "sensé" que taille~poids obj2 <- lm( obj1 ) obj3 <- anova( obj2 ) obj4 <- summary( obj3 ) # -------------------------------------- analyseObjet <- function(x) { return( c( paste(class(x),collapse=" "), typeof(x), mode(x), storage.mode(x) ) ) } # fin de fonction analyseObjet mdr <- rbind( # matrice des résultats analyseObjet(obj1) , analyseObjet(obj2) , analyseObjet(obj3) , analyseObjet(obj4) ) # fin de rbind colnames(mdr) <- c("class()","typeof()","mode()","storage.mode()") row.names(mdr) <- paste("obj",sprintf("%02d",1:nrow(mdr)),sep="") cat("\nVoici les caractéristiques des objets\n") print( mdr, quote=FALSE ) cat("\nUne façon courte de voir les objets et leur type utilise ls.str() :\n") ls.str(pattern="^obj[0-9]*$") # -------------------------------------- pps <- function(x) { obj <- get(x) cats(paste("print de",x)) print(obj) ; cats(paste("plot de",x),"-") plot(obj,main=paste("OBJET ",x)) ; cat("... ok\n") cats(paste("summary de",x),"-") print(summary(obj) ) } # fin de fonction pps sapply(FUN=pps, X=c("obj1","obj2","obj3","obj4") ) detach(her) # à ne pas oublier !Voici les caractéristiques des objets class() typeof() mode() storage.mode() obj01 formula language call language obj02 lm list list list obj03 anova data.frame list list list obj04 table character character character Une façon courte de voir les objets et leur type utilise ls.str() : obj1 : Class 'formula' length 3 poids ~ taille obj2 : List of 12 $ coefficients : Named num [1:2] -74.464 0.879 $ residuals : Named num [1:80] -6.803 -7.824 -4.224 0.853 -7.187 ... $ effects : Named num [1:80] -646.6 76.56 -4.67 1.03 -6.78 ... $ rank : int 2 $ fitted.values: Named num [1:80] 83.5 73.2 85.5 78.8 76.4 ... $ assign : int [1:2] 0 1 $ qr :List of 5 $ df.residual : int 78 $ xlevels : Named list() $ call : language lm(formula = obj1) $ terms :Classes 'terms', 'formula' length 3 poids ~ taille $ model :'data.frame': 80 obs. of 2 variables: obj3 : Classes 'anova' and 'data.frame': 2 obs. of 5 variables: $ Df : int 1 78 $ Sum Sq : num 5861 13902 $ Mean Sq: num 5861 178 $ F value: num 32.9 NA $ Pr(>F) : num 1.77e-07 NA obj4 : 'table' chr [1:7, 1:5] "Min. : 1.00 " "1st Qu.:20.25 " ... print de obj1 ============= poids ~ taille plot de obj1 ------------ ... ok summary de obj1 --------------- Length Class Mode 3 formula call print de obj2 ============= Call: lm(formula = obj1) Coefficients: (Intercept) taille -74.4636 0.8786 plot de obj2 ------------ Tapez <Entrée> pour voir le graphique suivant Tapez <Entrée> pour voir le graphique suivant Tapez <Entrée> pour voir le graphique suivant Tapez <Entrée> pour voir le graphique suivant ... ok summary de obj2 --------------- Call: lm(formula = obj1) Residuals: Min 1Q Median 3Q Max -22.349 -8.107 -1.220 7.307 49.114 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -74.4636 25.6353 -2.905 0.00478 ** taille 0.8786 0.1532 5.734 1.77e-07 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 13.35 on 78 degrees of freedom Multiple R-squared: 0.2966, Adjusted R-squared: 0.2875 F-statistic: 32.88 on 1 and 78 DF, p-value: 1.771e-07 print de obj3 ============= Analysis of Variance Table Response: poids Df Sum Sq Mean Sq F value Pr(>F) taille 1 5861 5861.0 32.884 1.771e-07 *** Residuals 78 13902 178.2 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 plot de obj3 ------------ ... ok summary de obj3 --------------- Df Sum Sq Mean Sq F value Min. : 1.00 Min. : 5861 Min. : 178.2 Min. :32.88 1st Qu.:20.25 1st Qu.: 7871 1st Qu.:1598.9 1st Qu.:32.88 Median :39.50 Median : 9882 Median :3019.6 Median :32.88 Mean :39.50 Mean : 9882 Mean :3019.6 Mean :32.88 3rd Qu.:58.75 3rd Qu.:11892 3rd Qu.:4440.3 3rd Qu.:32.88 Max. :78.00 Max. :13902 Max. :5861.0 Max. :32.88 NA's : 1.00 Pr(>F) Min. :1.771e-07 1st Qu.:1.771e-07 Median :1.771e-07 Mean :1.771e-07 3rd Qu.:1.771e-07 Max. :1.771e-07 NA's :1.000e+00 print de obj4 ============= Df Sum Sq Mean Sq F value Min. : 1.00 Min. : 5861 Min. : 178.2 Min. :32.88 1st Qu.:20.25 1st Qu.: 7871 1st Qu.:1598.9 1st Qu.:32.88 Median :39.50 Median : 9882 Median :3019.6 Median :32.88 Mean :39.50 Mean : 9882 Mean :3019.6 Mean :32.88 3rd Qu.:58.75 3rd Qu.:11892 3rd Qu.:4440.3 3rd Qu.:32.88 Max. :78.00 Max. :13902 Max. :5861.0 Max. :32.88 NA's : 1.00 Pr(>F) Min. :1.771e-07 1st Qu.:1.771e-07 Median :1.771e-07 Mean :1.771e-07 3rd Qu.:1.771e-07 Max. :1.771e-07 NA's :1.000e+00 plot de obj4 ------------ Erreur dans tabulate(Ind[, dimd]) : 'bin' must be numeric or a factorPour voir en détail le contenu d'un objet un peu complexe, on peut utiliser la fonction unclass(), mais cela est parfois très long :
her <- lit.dar.wd("her.dar") attach(her) # plus pratique ici que her$taille ou her[,"taille"] # et plus sûr que her[,3] # -------------------------------------- obj1 <- poids ~ taille # plus "sensé" que taille~poids obj2 <- lm( obj1 ) obj3 <- anova( obj2 ) obj4 <- summary( obj3 ) # -------------------------------------- unclassGH <- function(x) { obj <- get(x) cats(paste("unclass de",x)) print( unclass(obj) ) } # fin de fonction unclassGH sapply(FUN=unclassGH, X=c("obj1","obj2","obj3","obj4") ) detach(her) # à ne pas oublier !unclass de obj1 =============== poids ~ taille attr(,".Environment") <environment: R_GlobalEnv> unclass de obj2 =============== $coefficients (Intercept) taille -74.4636321 0.8785688 $residuals 1 2 3 4 5 6 7 8 9 [...] -6.8030379 -7.8237829 -4.2237461 0.8533768 -7.1866306 -4.2887627 -12.7266380 15.8919382 1.5319456 42 43 44 45 46 47 48 49 50 -6.0509242 -15.6259518 8.0740482 -0.8516840 -11.6252289 -8.2909684 4.0897693 22.1105144 -12.5931005 $effects (Intercept) taille -646.6037771 76.5574385 -4.6655445 1.0326892 -6.7784878 -4.2156928 -12.0896648 16.3818061 [...] -0.5070168 -4.3095178 -15.8120189 -5.3976060 -14.1145199 9.5854801 1.2154788 -10.3834898 -5.6621672 -15.4387817 -15.4380469 -4.4465814 $rank [1] 2 $fitted.values 1 2 3 4 5 6 7 8 9 10 11 [...] 83.50304 73.22378 85.52375 78.84662 76.38663 79.98876 73.92664 75.50806 77.96805 71.90593 66.10738 56 57 58 59 60 61 62 63 64 65 66 69.88522 70.85165 63.64738 69.00665 66.98594 61.01168 66.98594 65.22881 60.74811 67.24952 56.26741 $assign [1] 0 1 $qr $qr (Intercept) taille 1 -8.9442719 -1.494051e+03 2 0.1118034 8.713881e+01 3 0.1118034 -1.581023e-01 4 0.1118034 -7.088517e-02 5 0.1118034 -3.875253e-02 6 0.1118034 -8.580390e-02 7 0.1118034 -6.619889e-03 8 0.1118034 -2.727659e-02 9 0.1118034 -5.940923e-02 10 0.1118034 1.977478e-02 [...] 70 0.1118034 6.338336e-02 71 0.1118034 1.035492e-01 72 0.1118034 1.448626e-01 73 0.1118034 2.355225e-01 74 0.1118034 8.977803e-02 75 0.1118034 1.678144e-01 76 0.1118034 3.698869e-02 77 0.1118034 1.299438e-01 78 0.1118034 -5.022847e-02 79 0.1118034 -2.153861e-02 80 0.1118034 2.699503e-01 attr(,"assign") [1] 0 1 $qraux [1] 1.111803 1.002561 $pivot [1] 1 2 $tol [1] 1e-07 $rank [1] 2 attr(,"class") [1] "qr" $df.residual [1] 78 $xlevels named list() $call lm(formula = obj1) $terms poids ~ taille attr(,"variables") list(poids, taille) attr(,"factors") taille poids 0 taille 1 attr(,"term.labels") [1] "taille" attr(,"order") [1] 1 attr(,"intercept") [1] 1 attr(,"response") [1] 1 attr(,".Environment") <environment: R_GlobalEnv> attr(,"predvars") list(poids, taille) attr(,"dataClasses") poids taille "numeric" "numeric" $model poids taille 1 76.7 179.8 2 65.4 168.1 3 81.3 182.1 4 79.7 174.5 5 69.2 171.7 6 75.7 175.8 7 61.2 168.9 8 91.4 170.7 9 79.5 173.5 10 63.0 166.6 [...] 70 81.6 162.8 71 67.0 159.3 72 51.2 155.7 73 88.7 147.8 74 56.3 160.5 75 61.2 153.7 76 64.1 165.1 77 56.2 157.0 78 61.5 172.7 79 59.1 170.2 80 45.7 144.8 unclass de obj3 =============== $Df [1] 1 78 $`Sum Sq` [1] 5861.041 13902.074 $`Mean Sq` [1] 5861.0414 178.2317 $`F value` [1] 32.88439 NA $`Pr(>F)` [1] 1.770625e-07 NA attr(,"row.names") [1] "taille" "Residuals" attr(,"heading") [1] "Analysis of Variance Table\n" "Response: poids" unclass de obj4 =============== Df Sum Sq Mean Sq F value Pr(>F) "Min. : 1.00 " "Min. : 5861 " "Min. : 178.2 " "Min. :32.88 " "Min. :1.771e-07 " "1st Qu.:20.25 " "1st Qu.: 7871 " "1st Qu.:1598.9 " "1st Qu.:32.88 " "1st Qu.:1.771e-07 " "Median :39.50 " "Median : 9882 " "Median :3019.6 " "Median :32.88 " "Median :1.771e-07 " "Mean :39.50 " "Mean : 9882 " "Mean :3019.6 " "Mean :32.88 " "Mean :1.771e-07 " "3rd Qu.:58.75 " "3rd Qu.:11892 " "3rd Qu.:4440.3 " "3rd Qu.:32.88 " "3rd Qu.:1.771e-07 " "Max. :78.00 " "Max. :13902 " "Max. :5861.0 " "Max. :32.88 " "Max. :1.771e-07 " NA NA NA "NA's : 1.00 " "NA's :1.000e+00 " $obj1 poids ~ taille attr(,".Environment") <environment: R_GlobalEnv> $obj2 $obj2$coefficients (Intercept) taille -74.4636321 0.8785688 $obj2$residuals 1 2 3 4 5 6 7 8 9 10 [...] -6.8030379 -7.8237829 -4.2237461 0.8533768 -7.1866306 -4.2887627 -12.7266380 15.8919382 1.5319456 -8.9059297 42 43 44 45 46 47 48 49 50 51 -6.0509242 -15.6259518 8.0740482 -0.8516840 -11.6252289 -8.2909684 4.0897693 22.1105144 -12.5931005 11.0340776 $obj2$effects (Intercept) taille -646.6037771 76.5574385 -4.6655445 1.0326892 -6.7784878 -4.2156928 -12.0896648 16.3818061 1.7929832 [...] -0.5070168 -4.3095178 -15.8120189 -5.3976060 -14.1145199 9.5854801 1.2154788 -10.3834898 -6.2646682 -5.6621672 -15.4387817 -15.4380469 -4.4465814 $obj2$rank [1] 2 $obj2$fitted.values 1 2 3 4 5 6 7 8 9 10 11 12 13 [...] 83.50304 73.22378 85.52375 78.84662 76.38663 79.98876 73.92664 75.50806 77.96805 71.90593 66.10738 77.96805 88.68659 56 57 58 59 60 61 62 63 64 65 66 67 68 69.88522 70.85165 63.64738 69.00665 66.98594 61.01168 66.98594 65.22881 60.74811 67.24952 56.26741 59.86954 76.38663 $obj2$assign [1] 0 1 $obj2$qr $qr (Intercept) taille 1 -8.9442719 -1.494051e+03 2 0.1118034 8.713881e+01 3 0.1118034 -1.581023e-01 4 0.1118034 -7.088517e-02 5 0.1118034 -3.875253e-02 6 0.1118034 -8.580390e-02 7 0.1118034 -6.619889e-03 8 0.1118034 -2.727659e-02 9 0.1118034 -5.940923e-02 10 0.1118034 1.977478e-02 [...] 70 0.1118034 6.338336e-02 71 0.1118034 1.035492e-01 72 0.1118034 1.448626e-01 73 0.1118034 2.355225e-01 74 0.1118034 8.977803e-02 75 0.1118034 1.678144e-01 76 0.1118034 3.698869e-02 77 0.1118034 1.299438e-01 78 0.1118034 -5.022847e-02 79 0.1118034 -2.153861e-02 80 0.1118034 2.699503e-01 attr(,"assign") [1] 0 1 $qraux [1] 1.111803 1.002561 $pivot [1] 1 2 $tol [1] 1e-07 $rank [1] 2 attr(,"class") [1] "qr" $obj2$df.residual [1] 78 $obj2$xlevels named list() $obj2$call lm(formula = obj1) $obj2$terms poids ~ taille attr(,"variables") list(poids, taille) attr(,"factors") taille poids 0 taille 1 attr(,"term.labels") [1] "taille" attr(,"order") [1] 1 attr(,"intercept") [1] 1 attr(,"response") [1] 1 attr(,".Environment") <environment: R_GlobalEnv> attr(,"predvars") list(poids, taille) attr(,"dataClasses") poids taille "numeric" "numeric" $obj2$model poids taille 1 76.7 179.8 2 65.4 168.1 3 81.3 182.1 4 79.7 174.5 5 69.2 171.7 6 75.7 175.8 7 61.2 168.9 8 91.4 170.7 9 79.5 173.5 10 63.0 166.6 [...] 70 81.6 162.8 71 67.0 159.3 72 51.2 155.7 73 88.7 147.8 74 56.3 160.5 75 61.2 153.7 76 64.1 165.1 77 56.2 157.0 78 61.5 172.7 79 59.1 170.2 80 45.7 144.8 $obj3 $obj3$Df [1] 1 78 $obj3$`Sum Sq` [1] 5861.041 13902.074 $obj3$`Mean Sq` [1] 5861.0414 178.2317 $obj3$`F value` [1] 32.88439 NA $obj3$`Pr(>F)` [1] 1.770625e-07 NA attr(,"row.names") [1] "taille" "Residuals" attr(,"heading") [1] "Analysis of Variance Table\n" "Response: poids" $obj4 Df Sum Sq Mean Sq F value Pr(>F) "Min. : 1.00 " "Min. : 5861 " "Min. : 178.2 " "Min. :32.88 " "Min. :1.771e-07 " "1st Qu.:20.25 " "1st Qu.: 7871 " "1st Qu.:1598.9 " "1st Qu.:32.88 " "1st Qu.:1.771e-07 " "Median :39.50 " "Median : 9882 " "Median :3019.6 " "Median :32.88 " "Median :1.771e-07 " "Mean :39.50 " "Mean : 9882 " "Mean :3019.6 " "Mean :32.88 " "Mean :1.771e-07 " "3rd Qu.:58.75 " "3rd Qu.:11892 " "3rd Qu.:4440.3 " "3rd Qu.:32.88 " "3rd Qu.:1.771e-07 " "Max. :78.00 " "Max. :13902 " "Max. :5861.0 " "Max. :32.88 " "Max. :1.771e-07 " NA NA NA "NA's : 1.00 " "NA's :1.000e+00 "On peut vérifier avec notre fonction analyseObjet() que unclass() a enlevé une partie de la structure des données :
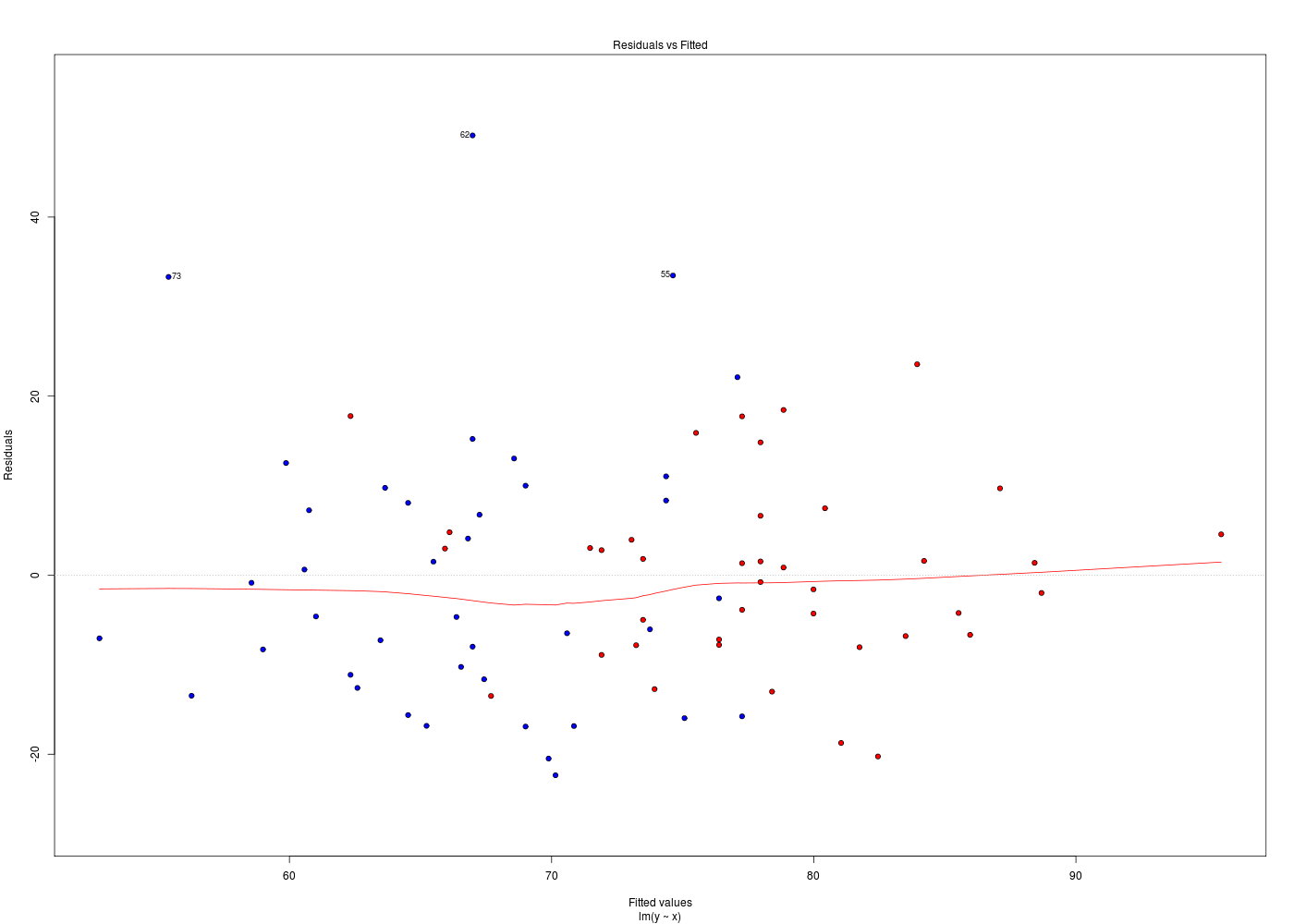
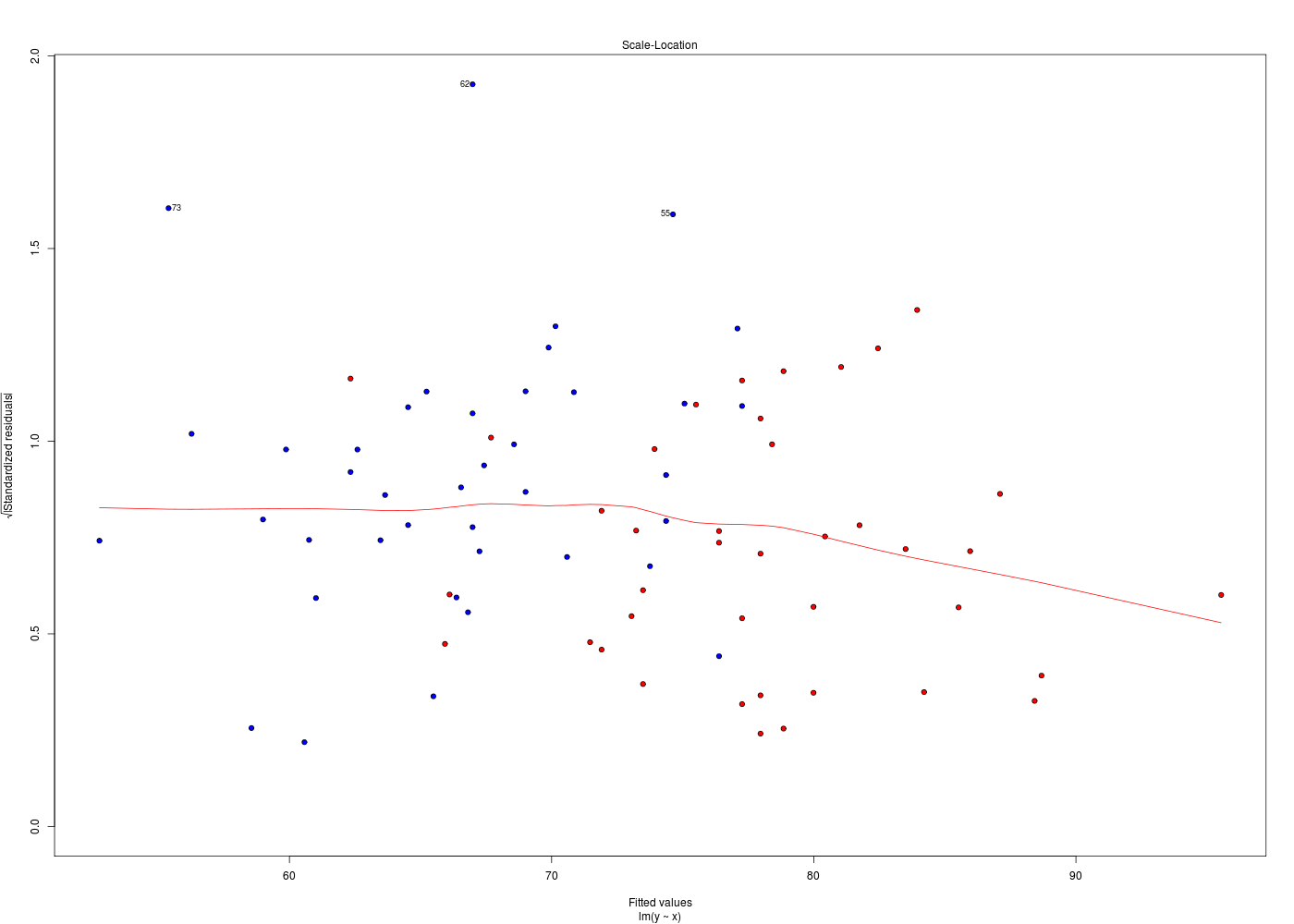
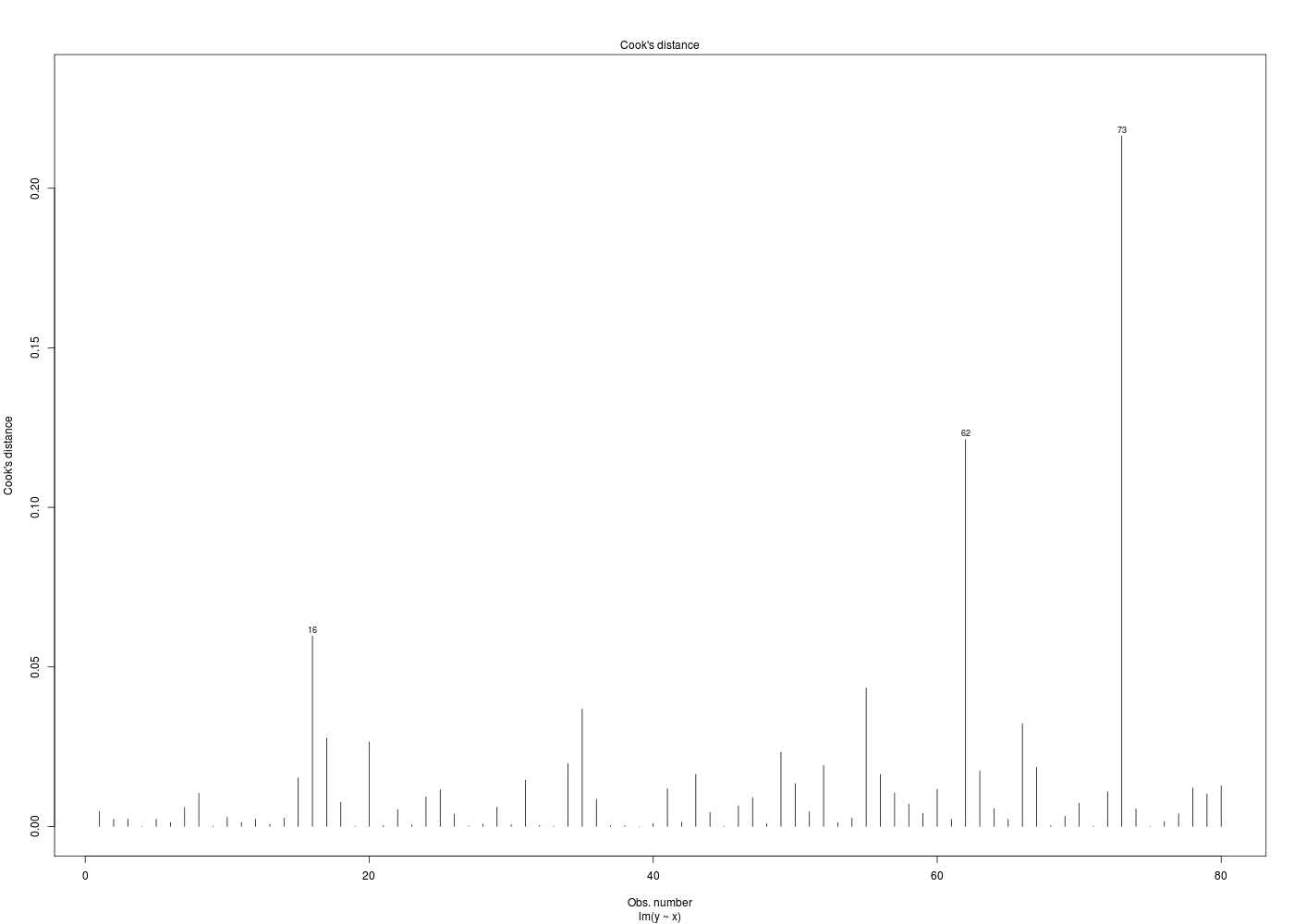
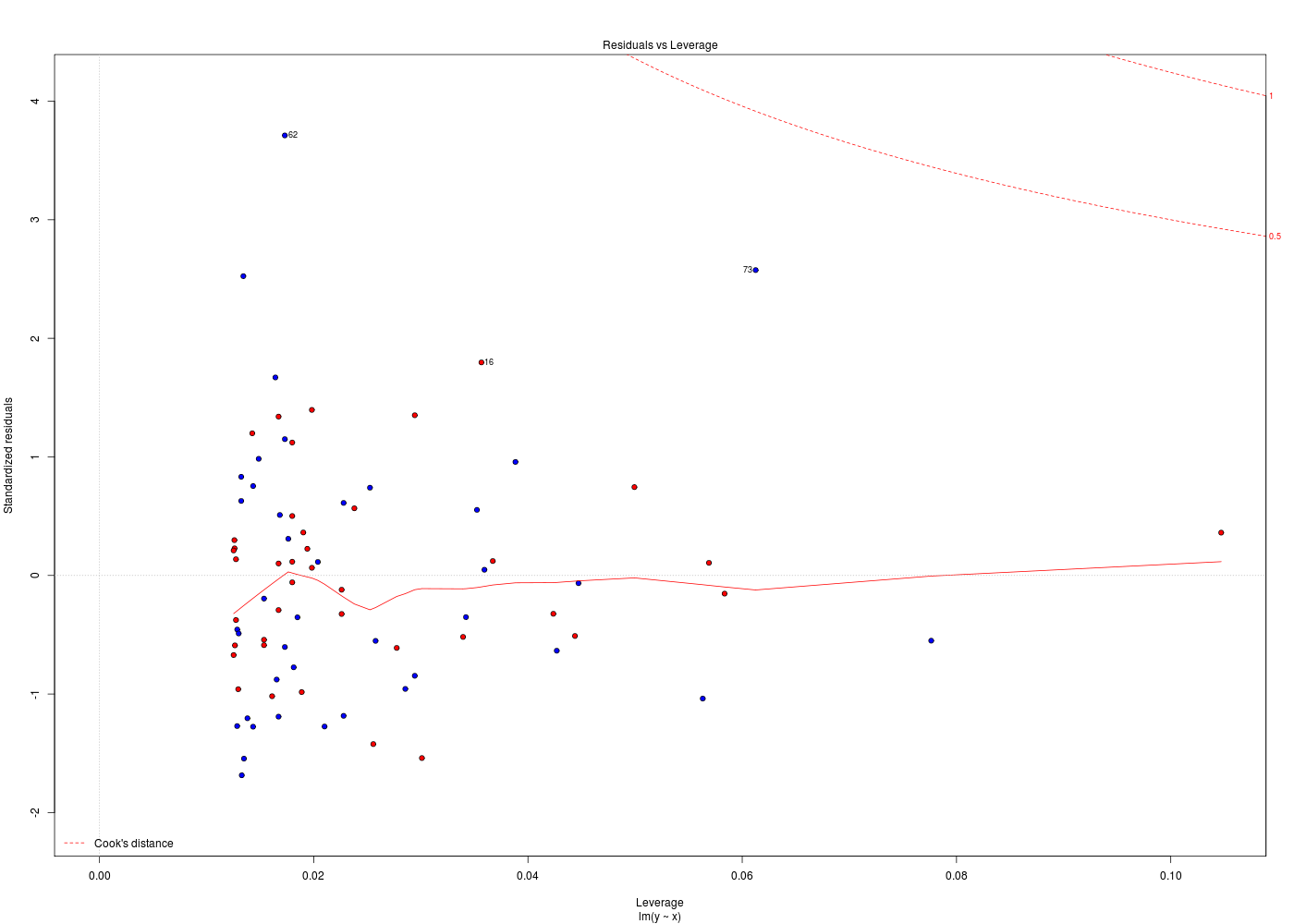
her <- lit.dar.wd("her.dar") attach(her) # plus pratique ici que her$taille ou her[,"taille"] # et plus sûr que her[,3] # -------------------------------------- obj1 <- poids ~ taille # plus "sensé" que taille~poids obj2 <- lm( obj1 ) obj3 <- anova( obj2 ) obj4 <- summary( obj3 ) uobj1 <- unclass( obj1 ) uobj2 <- unclass( obj2 ) uobj3 <- unclass( obj3 ) uobj4 <- unclass( obj4 ) # -------------------------------------- analyseObjet <- function(x) { return( c( paste(class(x),collapse=" "), typeof(x), mode(x), storage.mode(x) ) ) } # fin de fonction analyseObjet mdr <- rbind( # matrice des résultats analyseObjet(uobj1) , analyseObjet(uobj2) , analyseObjet(uobj3) , analyseObjet(uobj4) ) # fin de rbind colnames(mdr) <- c("class()","typeof()","mode()","storage.mode()") row.names(mdr) <- paste("obj",sprintf("%02d",1:nrow(mdr)),sep="") cat("\nVoici les caractéristiques des objets après unclass\n") print( mdr, quote=FALSE ) cat("\nUne façon courte de voir les objets et leur type utilise ls.str() :\n") ls.str(pattern="^uobj[0-9]*$")Voici les caractéristiques des objets après unclass class() typeof() mode() storage.mode() obj01 call language call language obj02 list list list list obj03 list list list list obj04 matrix character character character Une façon courte de voir les objets et leur type utilise ls.str() : uobj1 : length 3 poids ~ taille uobj2 : List of 12 $ coefficients : Named num [1:2] -74.464 0.879 $ residuals : Named num [1:80] -6.803 -7.824 -4.224 0.853 -7.187 ... $ effects : Named num [1:80] -646.6 76.56 -4.67 1.03 -6.78 ... $ rank : int 2 $ fitted.values: Named num [1:80] 83.5 73.2 85.5 78.8 76.4 ... $ assign : int [1:2] 0 1 $ qr :List of 5 $ df.residual : int 78 $ xlevels : Named list() $ call : language lm(formula = obj1) $ terms :Classes 'terms', 'formula' length 3 poids ~ taille $ model :'data.frame': 80 obs. of 2 variables: uobj3 : List of 5 $ Df : int [1:2] 1 78 $ Sum Sq : num [1:2] 5861 13902 $ Mean Sq: num [1:2] 5861 178 $ F value: num [1:2] 32.9 NA $ Pr(>F) : num [1:2] 1.77e-07 NA uobj4 : chr [1:7, 1:5] "Min. : 1.00 " "1st Qu.:20.25 " "Median :39.50 " "Mean :39.50 " "3rd Qu.:58.75 " "Max. :78.00 " NA "Min. : 5861 " "1st Qu.: 7871 " "Median : 9882 " "Mean : 9882 " [...]Pour un «bel» affichage des résidus, il faut d'abord enlever le mode ASK qui demande d'appuyer sur <Entrée> pour passer au graphique suivant. Comme c'est un paramètre graphique, il suffit d'écrire par(ask=FALSE). Nous avions vu, dans la correction de l'exercice 4 du cours 1, qu'il y avait une fonction nommée plot.lm(). La lecture de son fichier d'aide montre que son paramètre which permet de choisir le graphique voulu. Il suffit donc d'exécuter une boucle POUR de 1 à 6 pour tracer les diagnostics de résidus :
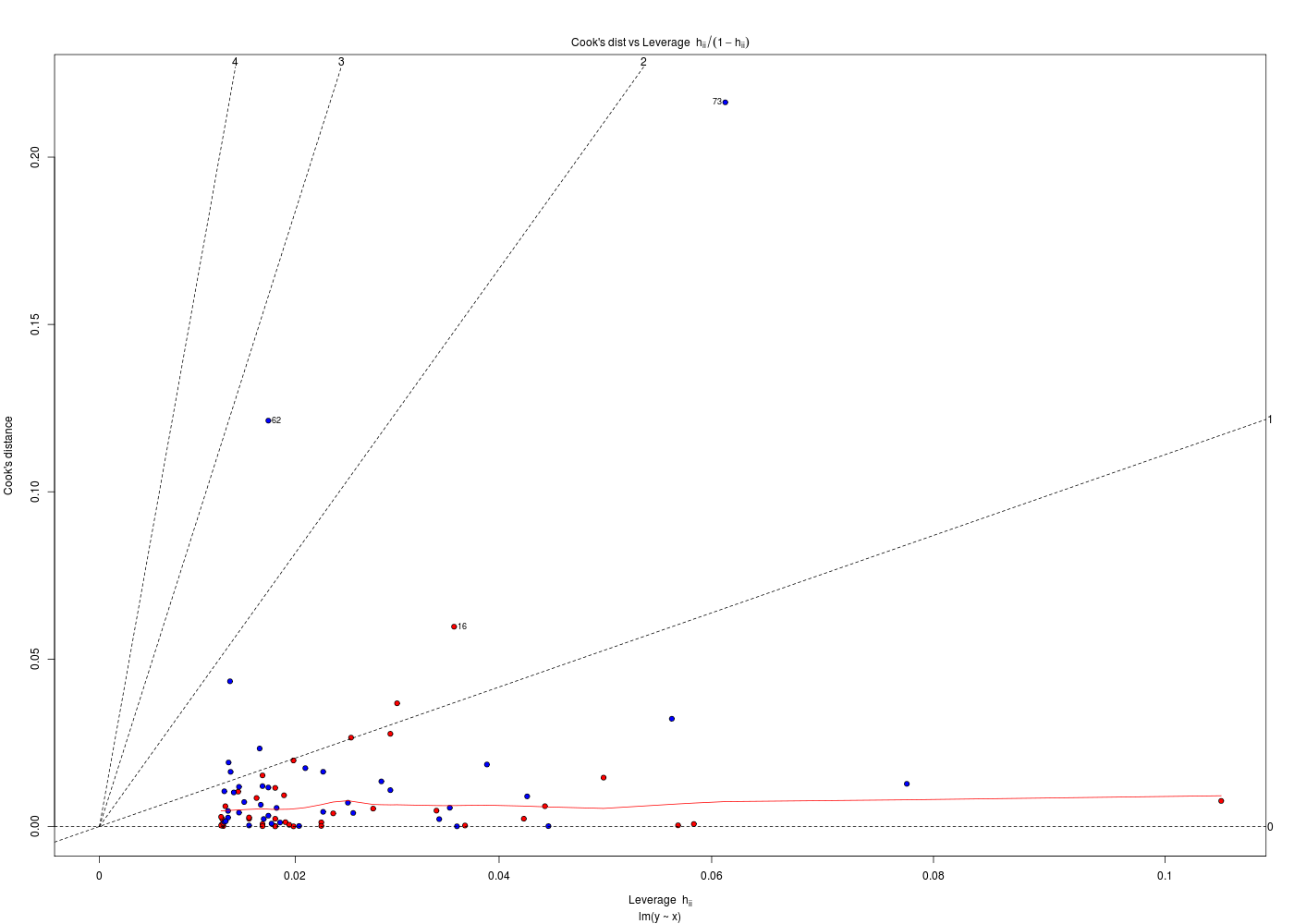
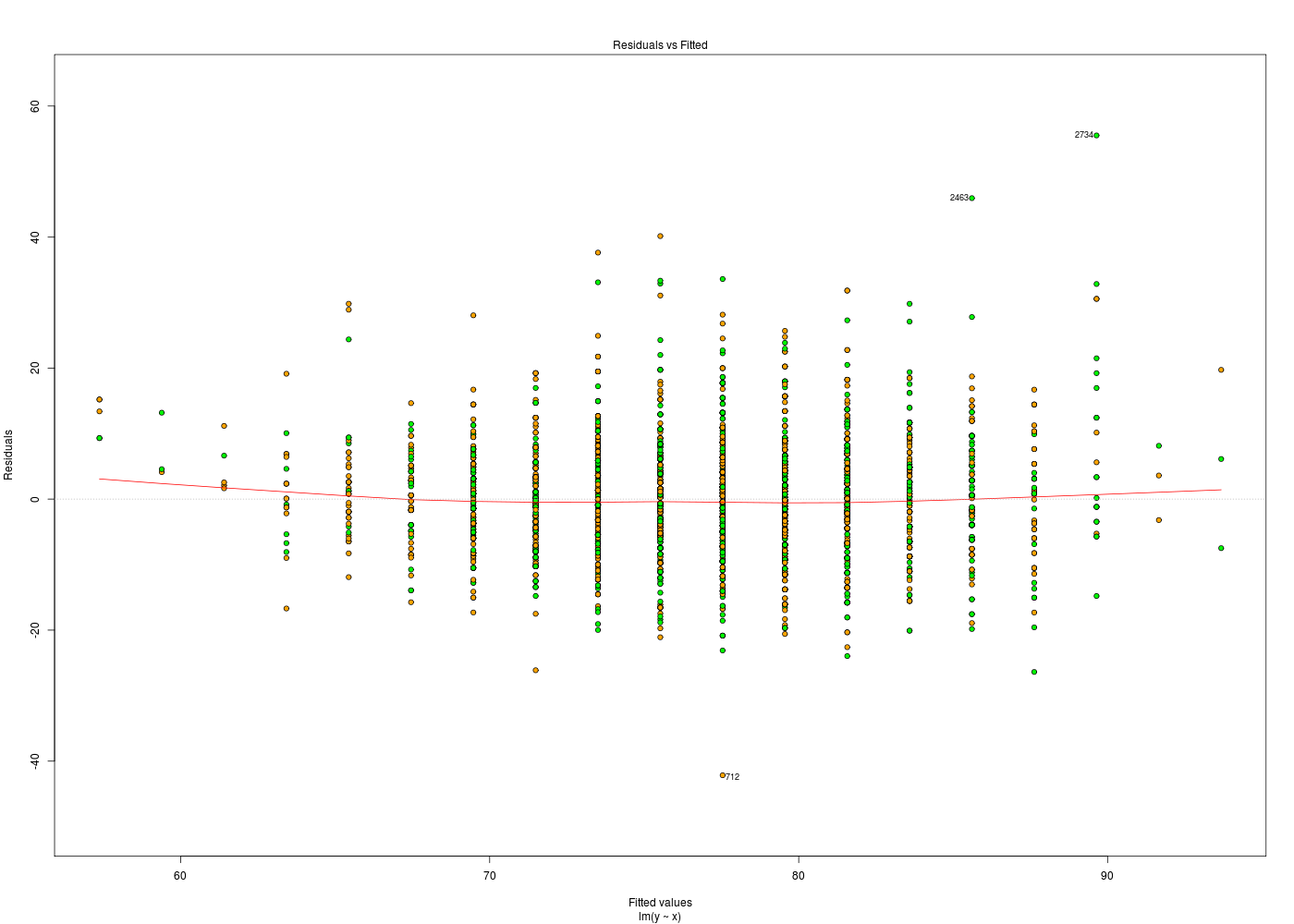
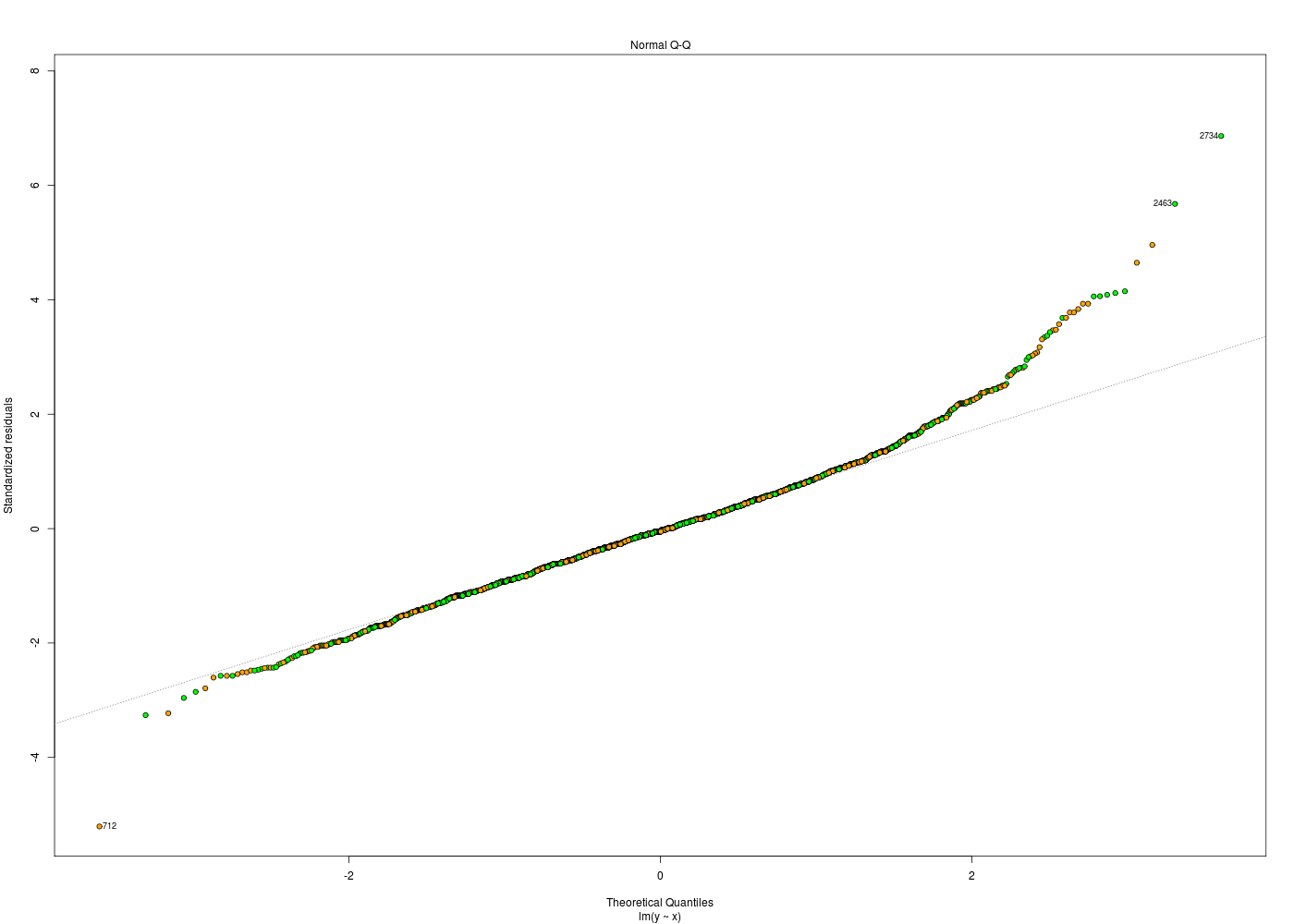
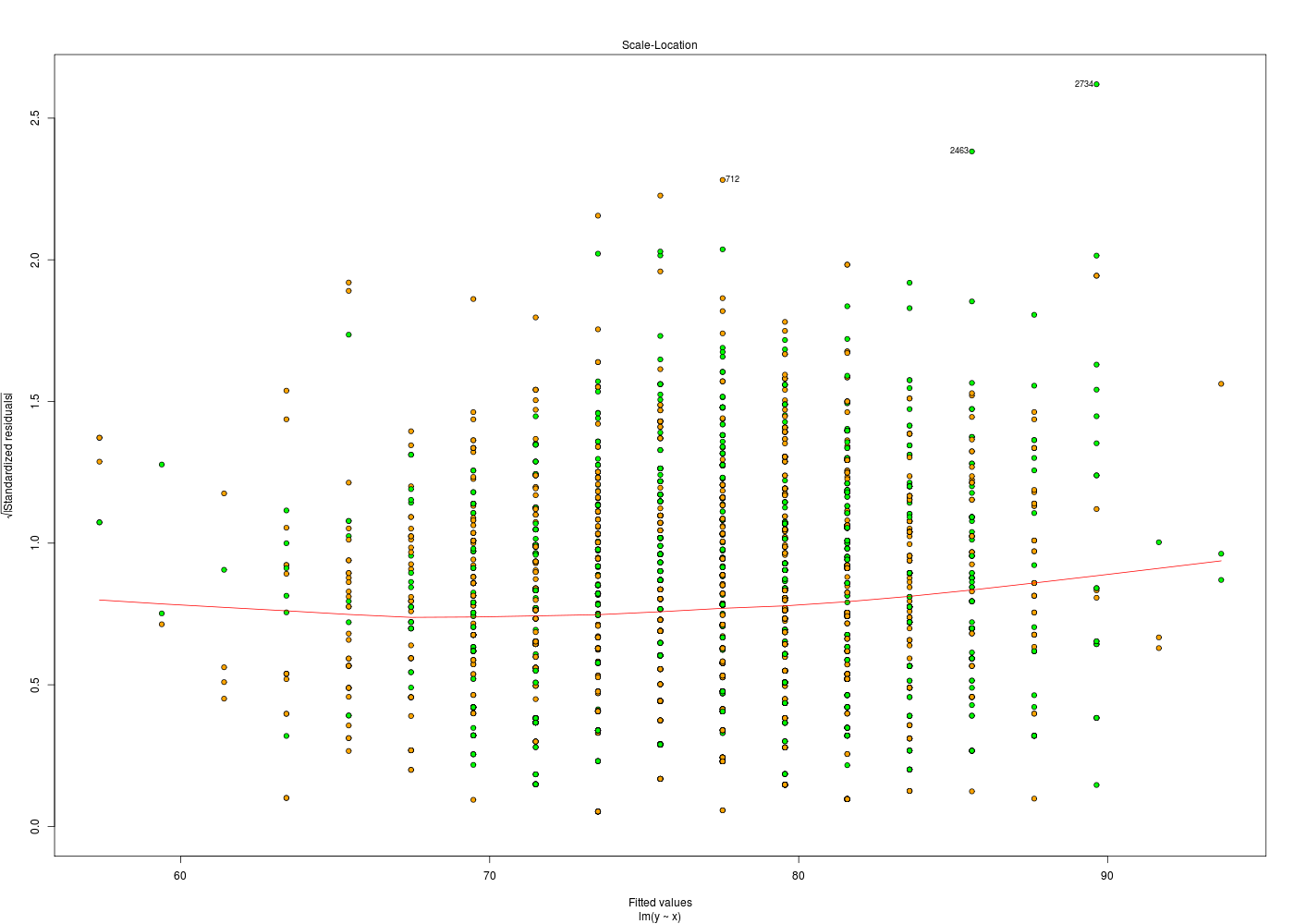
plotResidus <- function(x,y,fichier="") { pdv <- 1:6 # plage de variation des 6 graphiques par(ask=FALSE) ml <- lm( y~x) if (fichier!="") { fichiers <- paste(fichier,pdv,".png",sep="") } # fin si for (idt in 1:6) { if (fichier!="") { gr( fichiers[idt] ) # gr() est une fonction (gH) } # fin si plot.lm(ml,which=idt) if (fichier!="") { dev.off() cat("Fichier",fichiers[idt],"généré.\n") } # fin si } # fin pour idt } # fin de fonction plotResidus # exemples d'utilisation : her <- lit.dar.wd("her.dar") plotResidus(her$taille,her$poids,fichier="") plotResidus(her$taille,her$poids,fichier="residusHer")Fichier residusHer1.png généré. Fichier residusHer2.png généré. Fichier residusHer3.png généré. Fichier residusHer4.png généré. Fichier residusHer5.png généré. Fichier residusHer6.png généré.
Les graphiques ci-dessus utilisent des couleurs différentes pour les hommes et les femmes. Cela a été obtenu à l'aide de l'ellipse ajoutée en fin de fonction plotResidus(x,y,f) :
plotResidus <- function(x,y,fichier="",...) { # ajouter l'ellipse permet de peaufiner le graphique, # par exemple de mettres des couleurs pour les hommes # et les femmes, pour les moins de 45 ans... pdv <- 1:6 # plage de variation des 6 graphiques par(ask=FALSE) ml <- lm( y~x) if (fichier!="") { fichiers <- paste(fichier,pdv,".png",sep="") } # fin si for (idt in 1:6) { if (fichier!="") { gr( fichiers[idt] ) # gr() est une fonction (gH) } # fin si plot.lm(ml,which=idt,...) # c'est ici qu'on utilise l'ellipse if (fichier!="") { dev.off() cat("Fichier",fichiers[idt],"généré.\n") } # fin si } # fin pour idt } # fin de fonction plotResidus # exemples d'utilisation : her <- lit.dar.wd("her.dar") couleurSexe <- c("red","blue") couleurSexeHer <- couleurSexe[ her$sexe + 1 ] plotResidus(x=her$taille,y=her$poids,fichier="her",bg=couleurSexeHer,pch=21) # attention : legend ne s'applique qu'au dernier tracé, APRES la fonction legend(x="topleft",legend=c("femme","homme"),pt.bg=couleurSexe,pch=21) url <- "http://forge.info.univ-angers.fr/~gh/wstat/Mef/wcgs.dar" wcgs <- lit.dar(url) # il est prudent de convertir les données en valeurs compréhensibles # pour la France ; on rajoute aussi une classe d'age wcgs2 <- transform(wcgs, taille = HEIGHT*2.54, poids = WEIGHT*0.453592, clage = ifelse(AGE<45,0,1) ) # fin de transform couleurAge <- c("green","orange") couleurAgeWcgs <- couleurAge[ wcgs2$clage + 1 ] # vérification de la transformation et tracé print(tail(round( wcgs2[,c("HEIGHT","taille","WEIGHT","poids","AGE","clage")],1 ))) plotResidus(wcgs2$taille,wcgs2$poids,fichier="residusWcgs",pch=21,bg=couleurAgeWcgs)Fichier her1.png généré. Fichier her2.png généré. Fichier her3.png généré. Fichier her4.png généré. Fichier her5.png généré. Fichier her6.png généré. HEIGHT taille WEIGHT poids AGE clage P02076 72 182.9 180 81.6 45 1 P06045 71 180.3 154 69.9 47 1 P03091 74 188.0 195 88.5 41 0 P10013 71 180.3 185 83.9 53 1 P13033 67 170.2 150 68.0 54 1 P10219 69 175.3 205 93.0 48 1 Fichier residusWcgs1.png généré. Fichier residusWcgs2.png généré. Fichier residusWcgs3.png généré. Fichier residusWcgs4.png généré. Fichier residusWcgs5.png généré. Fichier residusWcgs6.png généré.
Il est en général utile d'ajouter l'ellipse à la fin de la liste des paramètres lorsqu'on définit une fonction qui produit un graphique, car cela permet d'ajouter des paramètres graphiques "à la volée".
Voici une fonction d'affichage en colonnes possible :
enColonnes <- function(vecteur,nbCol=4,largeur=7,nbDec=3) { cat("Affichage des",length(vecteur)," valeurs de \"V\" sur",nbCol, " colonnes, largeur=",largeur," avec",nbDec,"décimales\n") format <- paste(" %",largeur,".",nbDec,"f",sep="") v <- sprintf(format,vecteur) for (ide in seq(v)) { cat(v[ide]," ") if ((ide%%nbCol)==0) { cat("\n") } } # fin pour ide cat("\n") } # fin de fonction enColonnesPour un vecteur, on peut certainement s'en dispenser car avec options(width) et round() on peut faire tout aussi bien et même mieux puisqu'alors R affiche les indices de début de ligne :
> options(width=80) > print( round(va,3) ) [1] 0.073 0.676 0.691 0.069 0.257 0.701 0.919 0.260 0.019 0.937 0.470 0.598 [13] 0.842 0.954 0.275 0.742 0.112 0.597 0.234 0.655 0.943 0.306 0.282 0.680 [25] 0.049 0.750 0.318 0.100 0.536 0.057 0.132 0.095 0.090 0.806 0.500 0.538 [37] 0.624 0.855 0.916 0.437 0.068 0.454 0.307 0.004 0.439 0.163 0.569 0.524 [49] 0.023 0.847 0.803 0.277 0.440 0.694 0.467 0.936 0.469 0.934 0.163 0.310 [61] 0.477 0.754 0.608 0.844 0.134 0.102 0.622 0.496 0.486 0.010 0.614 0.796 [73] 0.231 0.877 0.333 0.665 0.660 0.108 0.937 0.615 0.761 0.330 0.394 0.990 [85] 0.290 0.192 0.805 0.489 0.797 0.018 0.747 0.712 0.241 0.122 0.936 0.795 [97] 0.326 0.971 0.933 0.878 0.314 0.518 0.021 0.505 0.240 0.999 0.744 0.284 [109] 0.125 0.807 0.361 0.361 0.137 0.150 0.210 0.493 0.651Attention quand même au fait que R n'accepte pas d'afficher des milliers de lignes par défaut (voir options(max.print), message [getOption("max.print") est atteint --- n lignes omises]) mais ce peut être intéressant pour gagner de la place à l'affichage pour des «dataframes» avec peu de colonnes, comme nos données personnes.dar.
Voici une implémentation d'une fonction pour visualiser tous les paramètres graphiques et son affichage complet :
parPrint <- function() { # mieux que : print( par() ) # sachant que ni sort( par() ) ni order( par() ) ne fonctionnent lesPg <- par() nomPg <- names(lesPg) idx <- order(nomPg) nbElt <- length(lesPg) matPg <- matrix(nrow=nbElt,ncol=3) colnames(matPg) <- c("Paramètre","Longueur","Valeur") for (idp in 1:nbElt) { jdp <- idx[idp] matPg[idp,1] <- nomPg[jdp] eltPg <- lesPg[[jdp]] lngElt <- length(eltPg) matPg[idp,2] <- lngElt if (lngElt==1) { if (is.na(eltPg)) { eltPg <- "<<NA>>" } # finsi if (is.null(eltPg)) { eltPg <- "<<nul>>" } # finsi if (eltPg=="") { eltPg <- "<<vide>>" } # finsi matPg[idp,3] <- eltPg } else { if (is.numeric(eltPg)) { eltPg <- round(eltPg,2) } # finsi strValeurPg <- ghtrim(paste(eltPg,collapse=" ")) matPg[idp,3] <- strValeurPg } # fin si } # fin pour idp print(matPg,quote=FALSE) } # fin de fonction parPrintParamètre Longueur Valeur [1,] adj 1 0.5 [2,] ann 1 TRUE [3,] ask 1 FALSE [4,] bg 1 white [5,] bty 1 o [6,] cex 1 1 [7,] cex.axis 1 1 [8,] cex.lab 1 1 [9,] cex.main 1 1.20000004768372 [10,] cex.sub 1 1 [11,] cin 2 0.15 0.2 [12,] col 1 black [13,] col.axis 1 black [14,] col.lab 1 black [15,] col.main 1 black [16,] col.sub 1 black [17,] cra 2 10.8 14.4 [18,] crt 1 0 [19,] csi 1 0.2 [20,] cxy 2 0.01 0.02 [21,] din 2 14 12.26 [22,] err 1 0 [23,] family 1 <<vide>> [24,] fg 1 black [25,] fig 4 0 1 0 1 [26,] fin 2 14 12.26 [27,] font 1 1 [28,] font.axis 1 1 [29,] font.lab 1 1 [30,] font.main 1 2 [31,] font.sub 1 1 [32,] lab 3 5 5 7 [33,] las 1 0 [34,] lend 1 round [35,] lheight 1 1 [36,] ljoin 1 round [37,] lmitre 1 10 [38,] lty 1 solid [39,] lwd 1 1 [40,] mai 4 1.02 0.82 0.82 0.42 [41,] mar 4 5.1 4.1 4.1 2.1 [42,] mex 1 1 [43,] mfcol 2 1 1 [44,] mfg 4 1 1 1 1 [45,] mfrow 2 1 1 [46,] mgp 3 3 1 0 [47,] mkh 1 0.001 [48,] new 1 FALSE [49,] oma 4 0 0 0 0 [50,] omd 4 0 1 0 1 [51,] omi 4 0 0 0 0 [52,] pch 1 1 [53,] pin 2 12.76 10.42 [54,] plt 4 0.06 0.97 0.08 0.93 [55,] ps 1 12 [56,] pty 1 m [57,] smo 1 1 [58,] srt 1 0 [59,] tck 1 <<NA>> [60,] tcl 1 -0.5 [61,] usr 4 0 1 0 1 [62,] xaxp 3 0 1 5 [63,] xaxs 1 r [64,] xaxt 1 s [65,] xlog 1 FALSE [66,] xpd 1 FALSE [67,] yaxp 3 0 1 5 [68,] yaxs 1 r [69,] yaxt 1 s [70,] ylbias 1 0.1 [71,] ylog 1 FALSEComme code d'une fonction qui affiche toutes les options de la configuration de R, nous vous proposons
optionsPrint <- function(triType=FALSE) { # mieux que options() # sachant que ni sort( options() ) ni order( options() ) ne fonctionnent lesOpt <- options() leso <- options() nomOpt <- names(lesOpt) typOpt <- lapply(X=lesOpt,FUN=typeof) if (triType) { idx <- order(unlist(unname(as.vector(typOpt))),nomOpt) } else { idx <- order(nomOpt) } # finsi nbElt <- length(lesOpt) matOpt <- matrix(nrow=nbElt,ncol=4) colnames(matOpt) <- c("Option","Type","Longueur","Valeur") for (idp in 1:nbElt) { jdp <- idx[idp] matOpt[idp,1] <- nomOpt[jdp] eltOpt <- lesOpt[[jdp]] lngElt <- length(eltOpt) matOpt[idp,2] <- typeof(eltOpt) matOpt[idp,3] <- lngElt if (typeof(eltOpt)=="closure") { matOpt[idp,4] <- "<<function...>>" } else if (typeof(eltOpt)=="list") { matOpt[idp,4] <- paste(names(eltOpt),eltOpt,sep="=",collapse=" ") } else { if (lngElt==1) { if (is.na(eltOpt)) { eltOpt <- "<<NA>>" } # finsi if (is.null(eltOpt)) { eltOpt <- "<<nul>>" } # finsi if (eltOpt=="") { eltOpt <- "<<vide>>" } # finsi matOpt[idp,4] <- eltOpt } else { if (is.numeric(eltOpt)) { eltOpt <- round(eltOpt,2) } # finsi strValeurPg <- ghtrim(paste(eltOpt,collapse=" ")) matOpt[idp,4] <- strValeurPg } # fin si } # fin si } # fin pour idp print(matOpt,quote=FALSE) } # fin de fonction optionsPrintToutes les options par ordre alphabétique ========================================= Option Type Longueur Valeur [1,] add.smooth logical 1 TRUE [2,] bitmapType character 1 cairo [3,] browser closure 1 <<function...>> [4,] browserNLdisabled logical 1 FALSE [5,] check.bounds logical 1 FALSE [6,] continue character 1 + [7,] contrasts character 2 contr.treatment contr.poly [8,] defaultPackages character 6 datasets utils grDevices graphics stats methods [9,] demo.ask character 1 default [10,] device character 1 RStudioGD [11,] device.ask.default logical 1 FALSE [12,] digits integer 1 7 [13,] dvipscmd character 1 dvips [14,] echo logical 1 TRUE [15,] editor character 1 vi [16,] encoding character 1 native.enc [17,] example.ask character 1 default [18,] expressions integer 1 5000 [19,] help.ports integer 1 34298 [20,] help.search.types character 3 vignette demo help [21,] help.try.all.packages logical 1 FALSE [22,] help_type character 1 html [23,] HTTPUserAgent character 1 R (2.14.1 x86_64-pc-linux-gnu x86_64 linux-gnu) [24,] internet.info double 1 2 [25,] keep.source logical 1 TRUE [26,] keep.source.pkgs logical 1 FALSE [27,] locatorBell logical 1 TRUE [28,] mailer character 1 mailto [29,] max.print double 1 10000 [30,] menu.graphics logical 1 FALSE [31,] na.action character 1 na.omit [32,] OutDec character 1 . [33,] pager character 1 /usr/lib64/R/bin/pager [34,] papersize character 1 a4 [35,] pdfviewer character 1 /usr/bin/xdg-open [36,] pkgType character 1 source [37,] printcmd character 1 /usr/bin/lpr [38,] prompt character 1 > [39,] repos character 1 http://cran.univ-lyon1.fr/ [40,] rl_word_breaks character 1 \t\n"\\'`><=%;,|&{()} [41,] scipen double 1 0 [42,] show.coef.Pvalues logical 1 TRUE [43,] show.error.messages logical 1 TRUE [44,] show.signif.stars logical 1 TRUE [45,] str list 3 strict.width=no digits.d=3 vec.len=4 [46,] stringsAsFactors logical 1 TRUE [47,] texi2dvi character 1 /usr/bin/texi2dvi [48,] timeout double 1 60 [49,] ts.eps double 1 1e-05 [50,] ts.S.compat logical 1 FALSE [51,] unzip character 1 /usr/bin/unzip [52,] useFancyQuotes logical 1 TRUE [53,] verbose logical 1 FALSE [54,] warn double 1 0 [55,] warning.length integer 1 1000 [56,] width integer 1 150 Toutes les options par type puis par ordre alphabétique ======================================================= Option Type Longueur Valeur [1,] bitmapType character 1 cairo [2,] continue character 1 + [3,] contrasts character 2 contr.treatment contr.poly [4,] defaultPackages character 6 datasets utils grDevices graphics stats methods [5,] demo.ask character 1 default [6,] device character 1 RStudioGD [7,] dvipscmd character 1 dvips [8,] editor character 1 vi [9,] encoding character 1 native.enc [10,] example.ask character 1 default [11,] help.search.types character 3 vignette demo help [12,] help_type character 1 html [13,] HTTPUserAgent character 1 R (2.14.1 x86_64-pc-linux-gnu x86_64 linux-gnu) [14,] mailer character 1 mailto [15,] na.action character 1 na.omit [16,] OutDec character 1 . [17,] pager character 1 /usr/lib64/R/bin/pager [18,] papersize character 1 a4 [19,] pdfviewer character 1 /usr/bin/xdg-open [20,] pkgType character 1 source [21,] printcmd character 1 /usr/bin/lpr [22,] prompt character 1 > [23,] repos character 1 http://cran.univ-lyon1.fr/ [24,] rl_word_breaks character 1 \t\n"\\'`><=%;,|&{()} [25,] texi2dvi character 1 /usr/bin/texi2dvi [26,] unzip character 1 /usr/bin/unzip [27,] browser closure 1 <<function...>> [28,] internet.info double 1 2 [29,] max.print double 1 10000 [30,] scipen double 1 0 [31,] timeout double 1 60 [32,] ts.eps double 1 1e-05 [33,] warn double 1 0 [34,] digits integer 1 7 [35,] expressions integer 1 5000 [36,] help.ports integer 1 34298 [37,] warning.length integer 1 1000 [38,] width integer 1 150 [39,] str list 3 strict.width=no digits.d=3 vec.len=4 [40,] add.smooth logical 1 TRUE [41,] browserNLdisabled logical 1 FALSE [42,] check.bounds logical 1 FALSE [43,] device.ask.default logical 1 FALSE [44,] echo logical 1 TRUE [45,] help.try.all.packages logical 1 FALSE [46,] keep.source logical 1 TRUE [47,] keep.source.pkgs logical 1 FALSE [48,] locatorBell logical 1 TRUE [49,] menu.graphics logical 1 FALSE [50,] show.coef.Pvalues logical 1 TRUE [51,] show.error.messages logical 1 TRUE [52,] show.signif.stars logical 1 TRUE [53,] stringsAsFactors logical 1 TRUE [54,] ts.S.compat logical 1 FALSE [55,] useFancyQuotes logical 1 TRUE [56,] verbose logical 1 FALSEA notre connaissance, il n'y a que deux ouvrages qui traitent de R et SAS :
Kleinman & Horton Muenchen La programmation en R et en Sas est très différente. En particulier, le langage de base de Sas ne travaille que sur des datasets et on n'a pas accès à des variables en mémoire comme sous R. Il n'y a pas de boucle ni de tests en Sas, sauf dans la "proc data" ou sauf à utiliser le langage des macros. Et encore, on ne dispose pas de listes ni de vecteurs, sauf à passer systématiquement par du découpage de chaines de caractères... Depuis SAS 9.0, on peut utiliser ODS pour accéder à tous les objets (variables et tableaux) produits, mais cela reste assez rigide et "lourd" à exécuter, voire fastidieux.
Voir par exemple code SAS et macros SAS.