![]()
![]()
Mathématiques Finances Economie : Logiciels statistiquesCours 5
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Mathématiques Finances Economie : Logiciels statistiques
Cours 5
Table des matières cliquable
1. Qu'est-ce qu'une régression ?
2. Comment effectuer une régression ?
4. Un exemple de régression linéaire simple
1. Qu'est-ce qu'une régression ?
Il y a un certain nombre de situations où on cherche à modéliser les valeurs d'une variable, notée classiquement Y, en fonction d'une ou plusieurs autres variables notées Xi. Le modèle, soigneusement défini par des équations, peut servir soit à décrire les phénomènes, souvent dans une optique de causalité, soit à prédire de nouvelles valeurs, à condition de prendre certaines précautions. Ainsi, au vu de l'évolution de la population mondiale sur les dix dernières années, il serait stupide de vouloir prédire la taille de la population mondiale en l'an 3500.
Suivant la nature de Y, le nombre et la nature des Xi, cette modélisation porte différents noms dits de régression :
Modélisation Nature de la Régression avec un seul X régression simple avec plus d'un seul X régression multiple Plutôt que de parler de Xi et de Y, l'usage, parfois incorrect, veut qu'on parle de variables explicatives et de variable expliquée, de variables indépendantes et de variable dépendante, alors qu'il serait sans doute plus simple d'employer les termes de régresseurs et de régressée. On trouve aussi l'appellation de variables exogènes et variable endogène.
Lorsque Y et les Xi sont quantitatives, le modèle le plus simple, le plus connu et le plus étudié est nommé régression linéaire, en anglais linear regression.
Si Y est qualitative, le modèle est nommé régression logistique, logistic regression en anglais. Le cas le plus simple est la régression logistique binaire (Y n'a que deux modalités). Si ce n'est pas le cas, la régression logistique peut être multinomiale, polytomique, ordinale, nominale...
L'usage historique veut qu'on parle d'analyse de la variance, soit encore ANOVA en anglais (ANalysis Of VAriance) plutôt que de régression par analyse de la variance lorsqu'on étudie Y quantitative en fonction de Xi qualitatives.
Il n'y a pas à notre connaissance de terme réservé pour désigner l'étude de Y qualitative en fonction de Xi qualitatives, dont le cas le plus simple est l'analyse de tri croisé (via un test du χ² d'indépendance). Cela tient sans doute au fait que les calculs utilisés sont fort différents de toutes les autres régressions.
Modélisation Xi quantitatives Xi qualitatives Xi quantitatives et qualitatives Y quantitative linéaire analyse de la variance analyse de la covariance Y qualitative logistique régression quali-quali ? logistique 2. Comment effectuer une régression ?
Pour réaliser une «bonne» régression linéaire, il faut effectuer plusieurs étapes. Tout d'abord il faut choisir un modèle parmi les modèles possibles. Si on a plusieurs Xi, la sélection de variables, en régression multiple avec ou sans interaction (variables supplémentaires définies comme produits des variables de départ), est une étape souvent délicate. Il faut ensuite déterminer les paramètres du modèle, c'est-à-dire trouver les coefficients dans la ou les équations de régression. Après, il faut tester la qualité générale du modèle, tester la nullité des coefficients, et analyser l'ajustement du modèle aux données par l'analyse des résidus.
Chaque type de régression (linéaire, logistique...) a ses propres calculs et estimateurs pour la détermination du modèle via la sélection de variables, le ou les tests de qualité de la régression, l'analyse des résidus. De plus, les variables Xi doivent parfois vérifier certaines conditions (normalité, non colinéarité, non multi-colinéarité...) pour qu'on ait le droit d'utiliser le modèle.
3. Le modèle linéaire
Le modèle linéaire (copie locale) vient modéliser Y en fonction de X (un ou plusieurs Xi) par la relation matricielle Y = Xaβ + ε où Xa est X augmenté d'une colonne de 1, afin de prendre en compte une constante dans le modèle. Ainsi, en régression linéaire simple on cherche à relier les yi en fonction des xi par la relation yi = β1xi + β0 + εi où ε est la variable de bruit (modélisée par une vecteur aléatoire dans Rn de moyenne nulle et de variance σ2In). Bien sûr, en pratique on ne distingue pas X de Xa et on s'autorise à réécrire le modèle de régression linéaire simple en par la relation yi = axi + b + εi pour retrouver l'écriture d'une droite des «petites classes».
Pour résoudre Y = Xβ, c'est-à-dire pour trouver les βi, on pourrait penser qu'il suffit d'utiliser l'inverse matriciel de X. Mais en général on ne peut pas calculer l'inverse de la matrice X car X n'est pas forcément une matrice carrée. Toutefois, si on multiplie de part et d'autre par la transposée de X notée ici X' (car X' X est toujours une matrice carrée), alors on peut résoudre matriciellement le problème, ce qui se nomme estimateur MCO (moindres carrés ordinaires, ou OLS en anglais) car la solution (X' X)-1X'Y -- quand elle existe -- minimise la somme des carrés des distances euclidiennes entre les yi et les vecteurs (xβ)i. On peut montrer que cet estimateur est sans biais et les εi sont nommés résidus de la régression.
La qualité de la régression linéaire s'analyse au travers du R2 dit coefficient de corrélation multiple empirique ou encore coefficient de détermination, -- du R2a (R2 ajusté) dans le cas de régression linéaire multiple -- et de la statistique F de Fisher. Attention : une «bonne» valeur de ce R2 n'est pas suffisante pour garantir une «bonne» régression.
Si on ajoute l'hypothèse de normalité des résidus, on peut calculer des intervalles de confiance pour les paramètres βi et un intervalle de confiance pour la prédiction d'un point xj. Il est alors possible d'effectuer un test t de Student pour savoir si les coefficients de la régression peuvent être considérés comme nuls ou non.
4. Un exemple de régression linéaire simple
Nous reprenons ici les données food utilisées au chapitre 2 du manuel d'utilisation écrit par L. Adkins pour la prise en mains du logiciel d'analyse économétrique gretl en tant que logiciel adapté au fameux ouvrage Principles of Econometrics (4ème edition), de R. Carter Hill, William E. Griffiths, and Guay C. Lim, Wiley (2007, 608pp) et dont le site Web associé est
http://principlesofeconometrics.com/poe4/poe4.htm
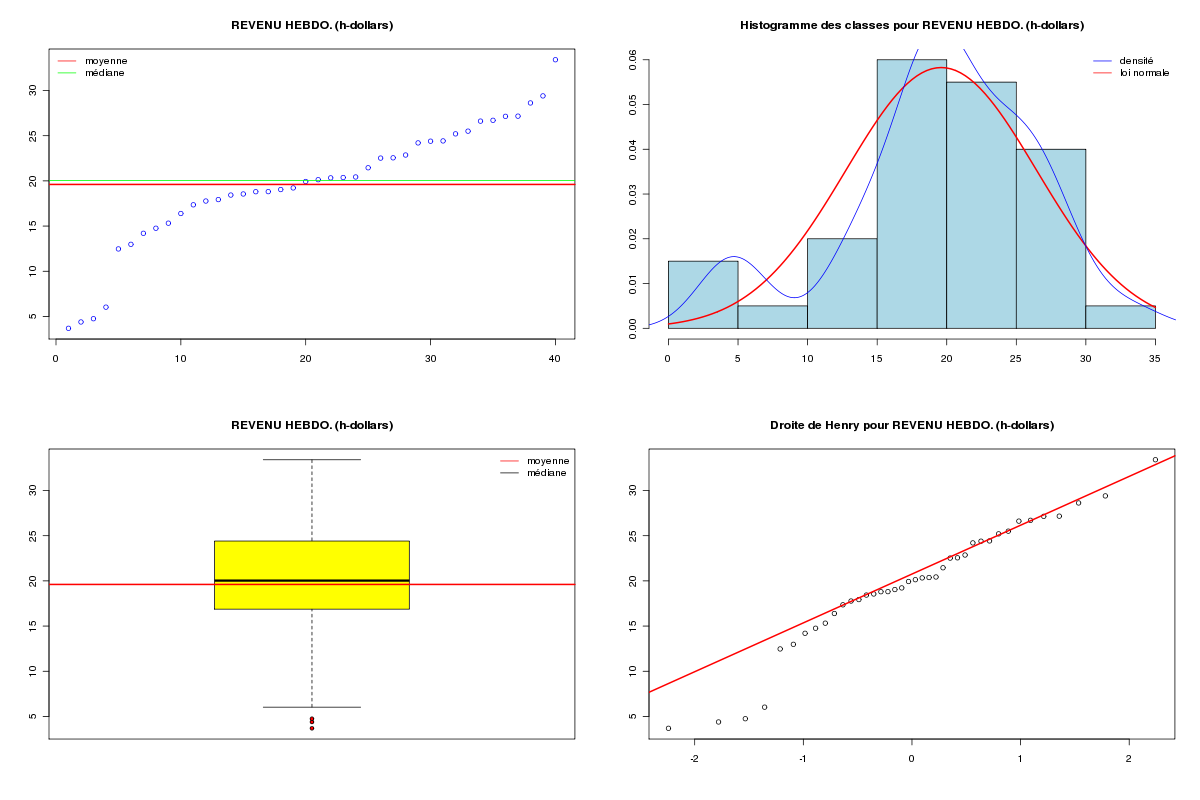
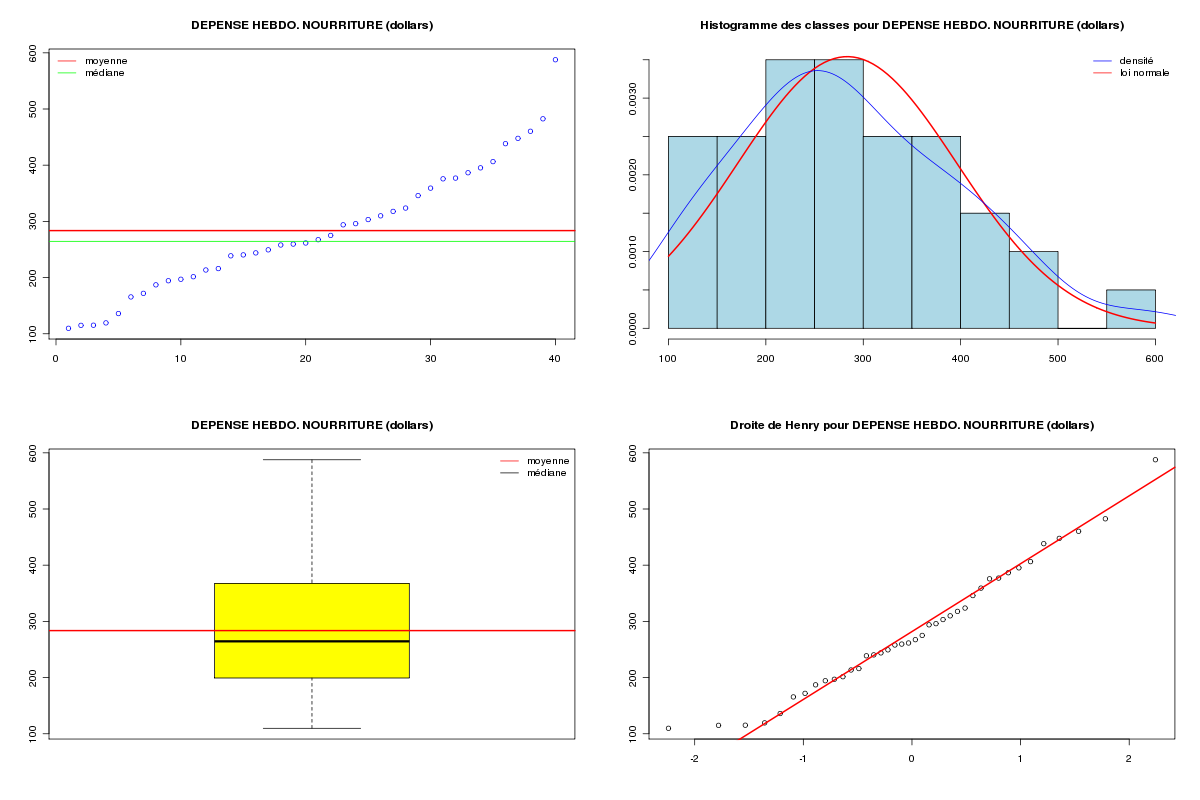
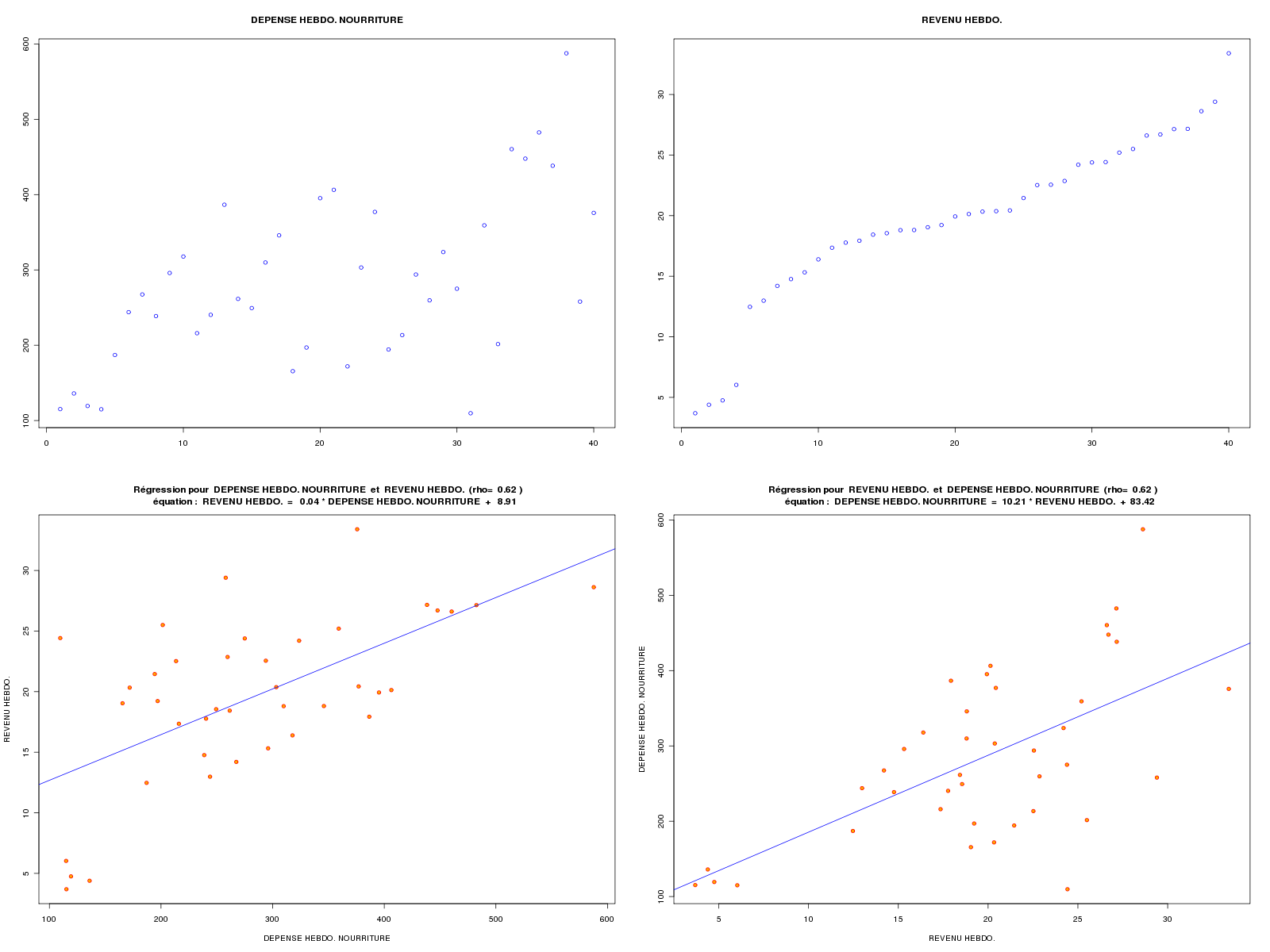
Les données food comprennent deux variables : wfoodexp et winc dont les noms anglais sont weekly food expenditure exprimée en dollars et weekly income exprimée en hecto dollars (un hecto dollar=100 dollars) comme on peut le lire sur le site des données de l'ouvrage de Carter et al. sur la page food.def.
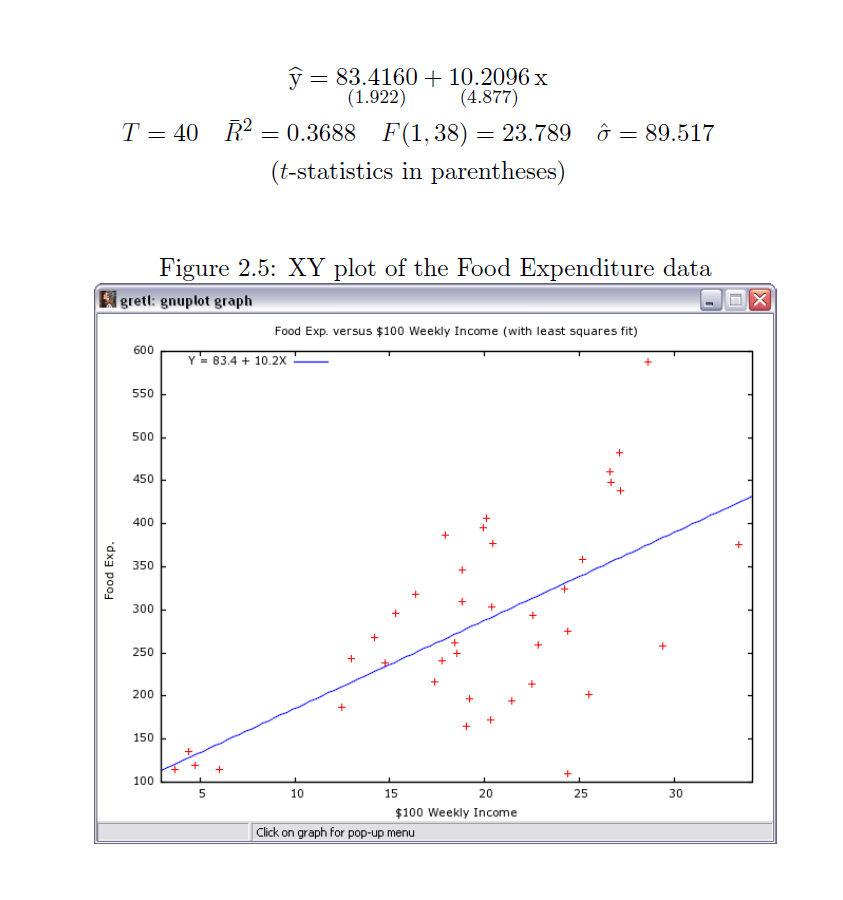
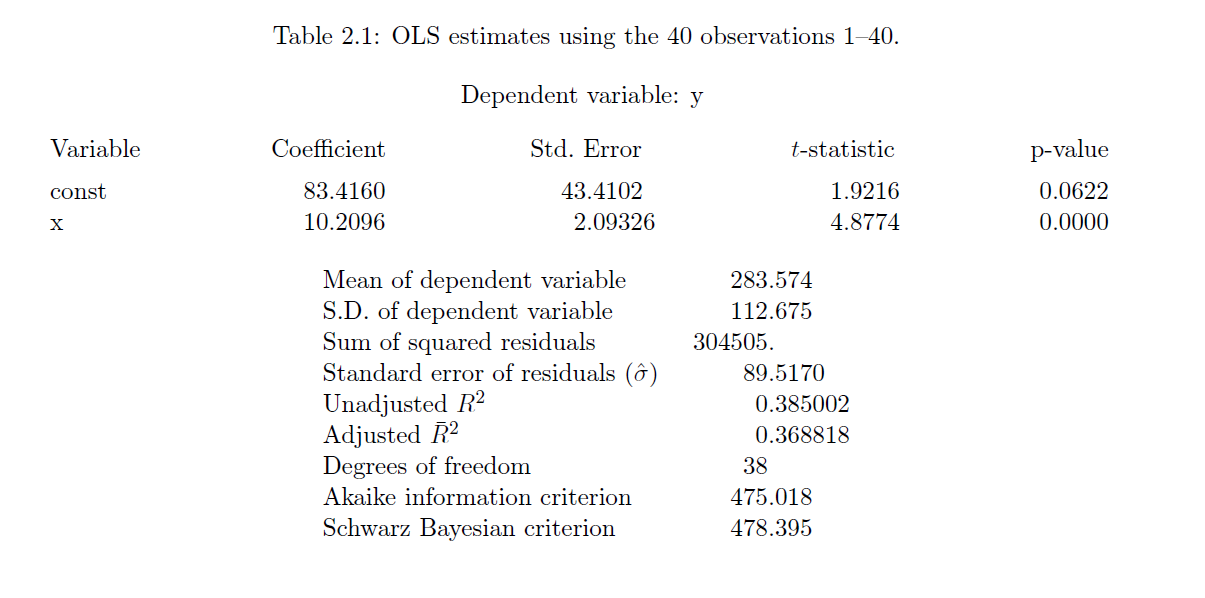
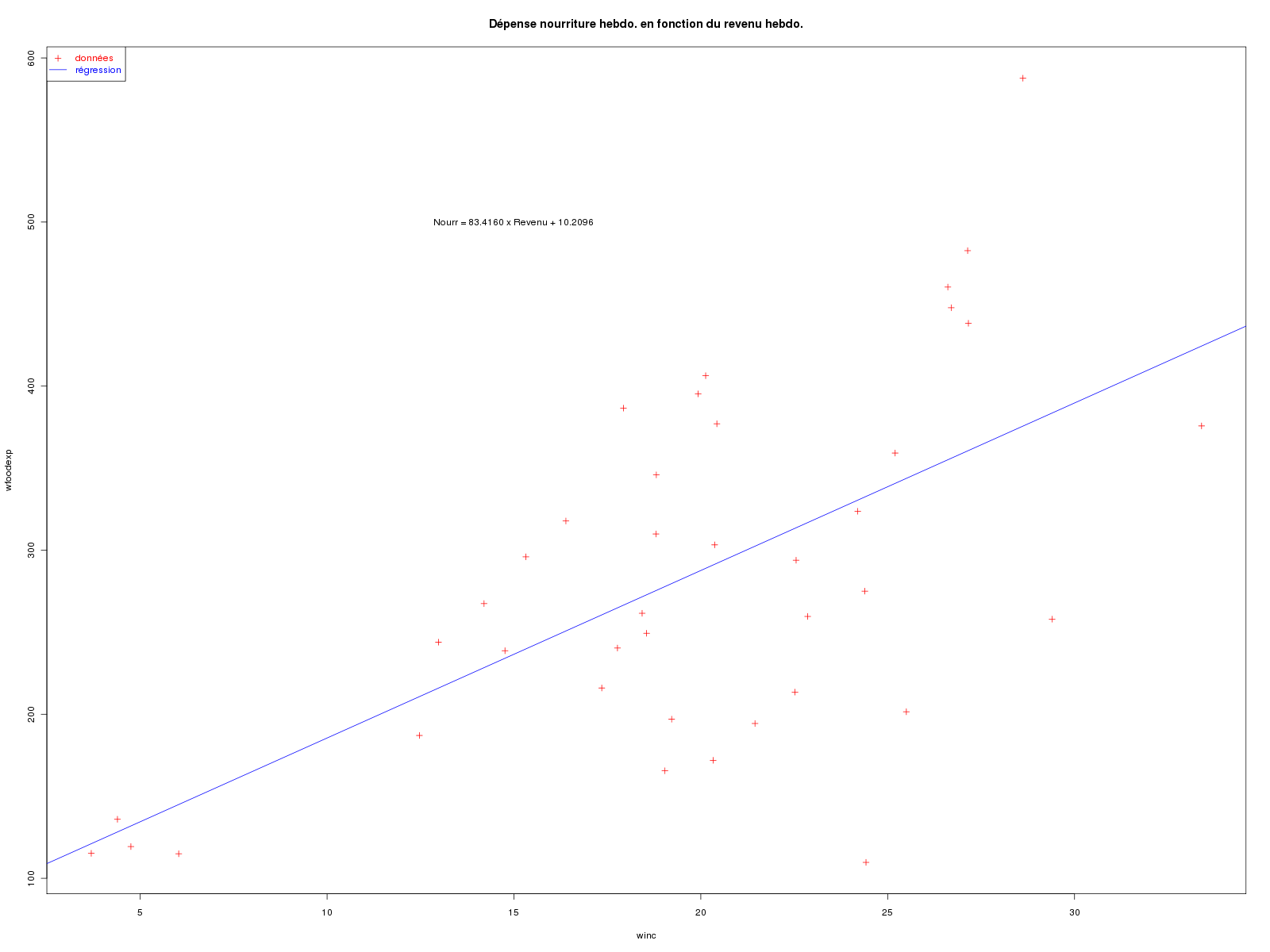
La modélisation consiste à exprimer la dépense hebdomadaire en nourriture en fonction du revenu hebdomadaire. Voici les calculs et les graphiques extraits des pages 19, 20 et 22 :
De plus, la prédiction de la dépense pour un revenu de 2000 dollars par semaine est indiqué page 23 :
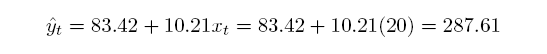
5. R et la régression
L'outil de base en R pour une régression linéaire est la fonction lm (Linear Model en anglais). Avec summary.lm que tout le monde abrège en summary à cause du modèle objet on peut connaitre l'ensemble des résultats de la régression, bien que d'autres fonctions comme coef et residuals permettent d'accéder aux différents résultats séparément et dont la liste est fournie par la fonction names.
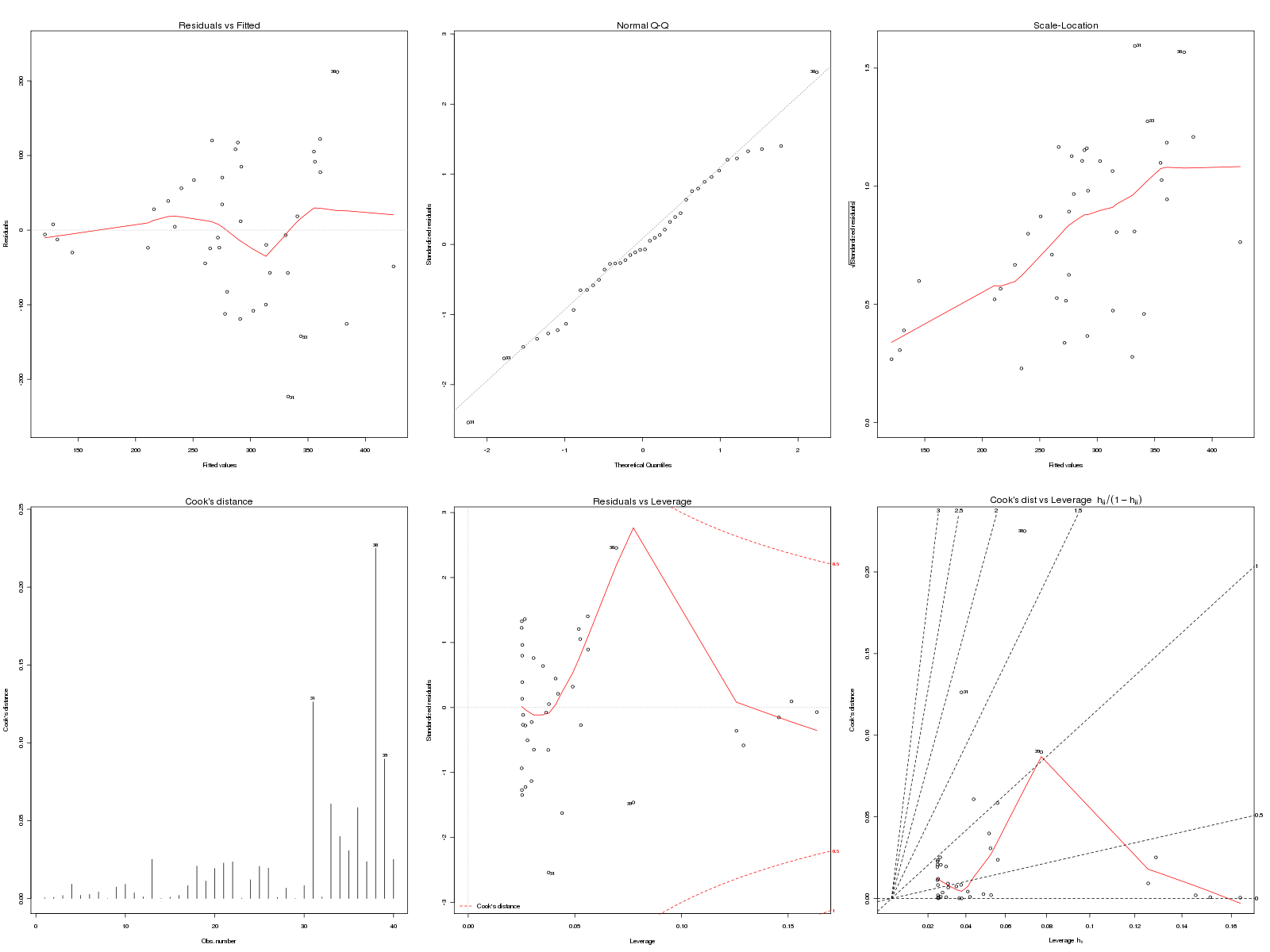
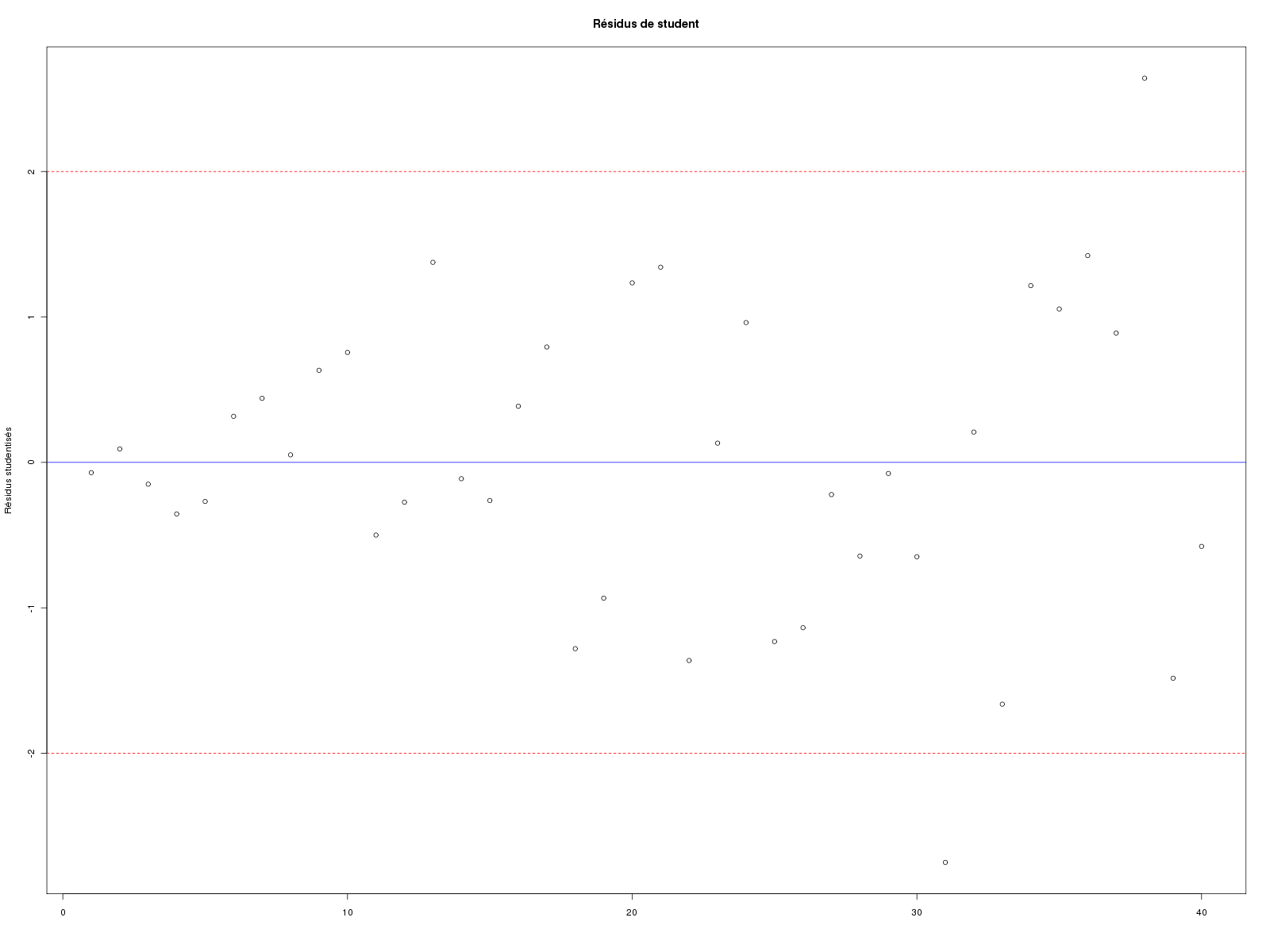
A l'aide de plot et abline, on peut rapidement reproduire le graphique d'Adkins mais attention : réaliser un «plot» du modèle utilise plot.lm ce qui en standard produit des graphiques interactifs pour étudier les résidus, quoiqu'il soit assez facile en R de calculer les résidus normalisés (on dit aussi studentisés) à l'aide de la fonction rstudent avant de les tracer avec leurs bornes -2 et +2.
Enfin, predict permet d'effectuer des prévisions à condition d'utiliser avec l'argument xnew un dataframe construit comme les données.
La fonction lm utilise la notation ~ (tilde) pour indiquer la formule de liaison entre Y et les Xi dans le modèle. Ainsi le modèle de régression linéaire simple Y = βX + ε se réduit à la formule Y ~ X alors que la régression de Y en fonction de X1 et de X2 se modélise par Y ~ X1 + X2. On notera que cette notation est pratique, mais difficile à comprendre pour un(e) débutant(e).
Code-source R :
cat("\nETUDE DES DONNEES food \n\n") # lecture des données food <- lit.dar("food.dar") attach(food) cat("\nDonnées lues en dimension ",dim(food),"\n\n") # étude de la variable WFOODEXP decritQT("DEPENSE HEBDO. NOURRITURE",wfoodexp,"dollars",TRUE,"food_wfe.png") # étude de la variable WINC decritQT("REVENU HEBDO.",winc,"h-dollars",TRUE,"food_winc.png") # étude de WFOODEXP en fonction de WINC anaLin("DEPENSE HEBDO. NOURRITURE",wfoodexp,"dollars","REVENU HEBDO.",winc,"h-dollars",TRUE,"food_wfe_winc.png") ###################################### # # étude détaillée en R # ###################################### # définition du modèle ml <- lm(wfoodexp~winc) # affichage du modèle txt <- "Voici le modèle linéaire associé" cat(txt,"\n",rep("-",nchar(txt)),"\n",sep="") print(ml) # paramètres et tests du modèle txt <- " avec summary( lm(wfoodexp~winc) )" cat(txt,"\n",rep("-",nchar(txt)),"\n",sep="") print( summary(ml) ) # anova du modèle txt <- " avec anova( lm(wfoodexp~winc) )\n" cat(txt) cat(rep("-",nchar(txt)),"\n",sep="") print( anova(ml) ) # résultats calculés print( names(ml) ) # tracé des points et de la droite de régression gr("food_reg.png") titre <- "Dépense nourriture hebdo. en fonction du revenu hebdo." plot(wfoodexp~winc,type="p",col="red",pch=3,main=titre) abline( lm(wfoodexp~winc), col="blue") rb <- c("red","blue") # Rouge Bleu legend("topleft",legend=c("données","régression"), col=rb,pch=c(3,-1),text.col=rb,lty=0:1) a <- coef(ml)[1] b <- coef(ml)[2] eqn <- paste("Nourr = ",sprintf("%7.4f",a)," x Revenu + ",sprintf("%7.4f",b),sep="") text(15,500,eqn) dev.off() # valeurs des résidus cat("\nRésidus (début)\n") print(head( residuals(ml) )) # analyse graphique des résidus gr("food_res.png") par(mfrow=c(2,3)) plot(ml,which=1:6) dev.off() # résidus studentisés "à la main" avec les bornes -2 et +2 gr("food_res_stu.png") res <- rstudent( ml ) plot(res,ylab="Résidus studentisés",xlab="",main="Résidus de student") abline(h=c(-2,0,2),lty=c(2,1,2),col=c("red","blue","red")) dev.off() # prédiction vap <- 20 # valeur à prédire vap_df <- as.data.frame(vap) # conversion colnames(vap_df) <- "winc" # meme nom que pour les données cat("\nPrévision pour une valeur winc de 20 :\n") print( predict(ml,newdata=vap_df,interval="pred") ) # libération des données detach(food)Résultats :
ETUDE DES DONNEES food Données lues en dimension 40 2 DESCRIPTION STATISTIQUE DE LA VARIABLE DEPENSE HEBDO. NOURRITURE Taille 40 individus Moyenne 283.5735 dollars Ecart-type 111.2578 dollars Coef. de variation 39 % 1er Quartile 200.4 dollars Mediane 264.5 dollars 3eme Quartile 363.3 dollars iqr absolu 162.9 dollars iqr relatif 62 % Minimum 109.7100 dollars Maximum 587.6600 dollars Tracé tige et feuilles The decimal point is 2 digit(s) to the right of the | 1 | 11224 1 | 7799 2 | 0012444 2 | 5666789 3 | 00122 3 | 56889 4 | 014 4 | 568 5 | 5 | 9 vous pouvez utiliser food_wfe.png DESCRIPTION STATISTIQUE DE LA VARIABLE REVENU HEBDO. Taille 40 individus Moyenne 19.6047 h-dollars Ecart-type 6.7616 h-dollars Coef. de variation 34 % 1er Quartile 17.11 h-dollars Mediane 20.03 h-dollars 3eme Quartile 24.4 h-dollars iqr absolu 7.288 h-dollars iqr relatif 36 % Minimum 3.6900 h-dollars Maximum 33.4000 h-dollars Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 0 | 44 0 | 56 1 | 234 1 | 556788899999 2 | 000001333444 2 | 56777799 3 | 3 vous pouvez utiliser food_winc.png ANALYSE DE LA LIAISON LINEAIRE ENTRE DEPENSE HEBDO. NOURRITURE ET REVENU HEBDO. coefficient de corrélation : 0.6204855 donc R2 = 0.3850022 p-value associée : 1.945862e-05 équation : REVENU HEBDO. = 0.04 * DEPENSE HEBDO. NOURRITURE + 8.91 équation : DEPENSE HEBDO. NOURRITURE = 10.21 * REVENU HEBDO. + 83.42 vous pouvez utiliser food_wfe_winc.png Voici le modèle linéaire associé -------------------------------- Call: lm(formula = wfoodexp ~ winc) Coefficients: (Intercept) winc 83.42 10.21 avec summary( lm(wfoodexp~winc) ) ---------------------------------- Call: lm(formula = wfoodexp ~ winc) Residuals: Min 1Q Median 3Q Max -223.025 -50.816 -6.324 67.879 212.044 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 83.416 43.410 1.922 0.0622 . winc 10.210 2.093 4.877 1.95e-05 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 89.52 on 38 degrees of freedom Multiple R-squared: 0.385, Adjusted R-squared: 0.3688 F-statistic: 23.79 on 1 and 38 DF, p-value: 1.946e-05 avec anova( lm(wfoodexp~winc) ) --------------------------------- Analysis of Variance Table Response: wfoodexp Df Sum Sq Mean Sq F value Pr(>F) winc 1 190627 190627 23.789 1.946e-05 *** Residuals 38 304505 8013 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Résidus (début) 1 2 3 4 5 6 -5.869585 7.743665 -12.571806 -30.020149 -23.680250 27.982832 Prévision pour une valeur winc de 20 : fit lwr upr 287.6089 104.1323 471.0854Graphiques générés :
6. Un exemple minimaliste de régression linéaire multiple
Cette section s'inspire librement de l'exercice 1 du chapitre 2 de l'ouvrage Econométrie de E. Dor, paru dans la collection Synthex, Synthèse de cours et exercices corrigés aux éditions Pearson, page 45 et suivantes. Les données originales sont nommées usa.xls transformées en usa.dar La régression proposée a pour but de relier le taux de croissance de la consommation réelle (DLC) en fonction du taux de croissance du revenu réel (DLY) et du taux d'inflation (DLP) de 1960 à 1994.

Voici le code-source R pour retrouver ces résultats :
# lecture des données usa <- lit.dar("usa.dar") cat("Données USA, dimension ",dim(usa),"\n\n") cat("Début des données originales\n") print(head(usa)) # transformation des données nbl <- nrow(usa) idl1 <- 2:(nbl) idl2 <- 1:(nbl-1) dlc <- log(usa$CT[idl1]) - log(usa$CT[idl2]) dly <- log(usa$Y[idl1] ) - log(usa$Y[idl2] ) dlp <- log(usa$P[idl1] ) - log(usa$P[idl2] ) newusa <- as.data.frame(cbind(dlc,dly,dlp)) cat("\nNouvelles Données USA, dimension ",dim(newusa),"\n\n") cat("Début des données utilisées\n") rownames(newusa) <- paste("An",1960+(1:(nrow(newusa))),sep="") print(head(newusa)) # régression de DLC en fonction de DLY et DLP rlm <- lm(dlc ~ dly + dlp ) print(rlm) print(summary(rlm)) print(anova(rlm))Et ses résultats :
Données USA, dimension 35 5 Début des données originales CT R UR Y P A0001 1210.75 4.117 5.539 35309.79 27.456 A0002 1238.36 3.883 6.679 36844.78 27.736 A0003 1293.25 3.946 5.588 39034.73 28.177 A0004 1341.87 4.003 5.643 40890.50 28.633 A0005 1417.18 4.187 5.167 44402.59 29.105 A0006 1496.98 4.283 4.506 47908.09 29.697 Nouvelles Données USA, dimension 34 3 Début des données utilisées dlc dly dlp An1961 0.02254792 0.04255372 0.01014649 An1962 0.04337051 0.05773769 0.01577483 An1963 0.03690573 0.04644615 0.01605386 An1964 0.05460482 0.08239997 0.01635008 An1965 0.05478076 0.07598666 0.02013605 An1966 0.05004969 0.07794873 0.02992130 Call: lm(formula = dlc ~ dly + dlp) Coefficients: (Intercept) dly dlp 0.01628 0.69602 -0.83280 Call: lm(formula = dlc ~ dly + dlp) Residuals: Min 1Q Median 3Q Max -0.0178745 -0.0059783 0.0001085 0.0039196 0.0182381 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 0.016282 0.006425 2.534 0.0165 * dly 0.696018 0.112156 6.206 6.84e-07 *** dlp -0.832802 0.104016 -8.006 4.86e-09 *** --- Residual standard error: 0.009755 on 31 degrees of freedom Multiple R-squared: 0.6757, Adjusted R-squared: 0.6548 F-statistic: 32.29 on 2 and 31 DF, p-value: 2.631e-08 Analysis of Variance Table Response: dlc Df Sum Sq Mean Sq F value Pr(>F) dly 1 0.0000456 4.56e-05 0.4797 0.4937 dlp 1 0.0061000 6.10e-03 64.1039 4.856e-09 *** Residuals 31 0.0029499 9.52e-05 ---7. Un exemple minimaliste de régression logistique
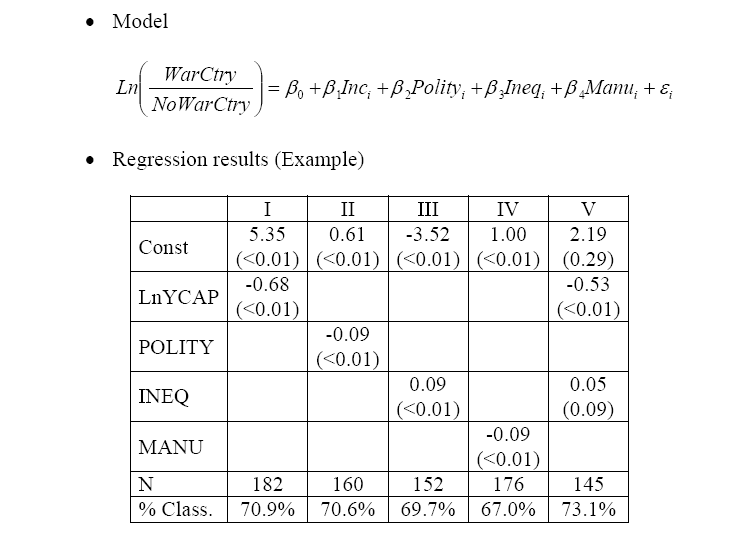
Cette section s'inspire librement du chapitre 5 du site Applied_Econometrics de M. Tanner, et dont les données, nommées initialement war.xls ont été transformées en war.dar. Pour ces données, un pays est considéré comme «guerrier» s'il a eu au moins une année de conflit armé entre 1960 et 2005.
Les régressions logistiques proposées page 78 et leurs résultats sont reproduits ci-dessous :
Voici le code-source R pour les reproduire :
# lecture des données war <- lit.dar("war.dar") # régressions logistiques rlb1 <- glm(WARCTRY ~ LnYCAP ,data=war,family="binomial") rlb2 <- glm(WARCTRY ~ POLITY ,data=war,family="binomial") rlb3 <- glm(WARCTRY ~ INEQ ,data=war,family="binomial") rlb4 <- glm(WARCTRY ~ MANU ,data=war,family="binomial") # affichage de la première régression print(rlb1) print( summary(rlb1) )Et ses résultats :
Call: glm(formula = WARCTRY ~ LnYCAP, family = "binomial", data = war) Coefficients: (Intercept) LnYCAP 5.3463 -0.6824 Degrees of Freedom: 181 Total (i.e. Null); 180 Residual (26 observations deleted due to missingness) Null Deviance: 249.6 Residual Deviance: 213 AIC: 217 Call: glm(formula = WARCTRY ~ LnYCAP, family = "binomial", data = war) Deviance Residuals: Min 1Q Median 3Q Max -2.0491 -0.9824 0.5878 0.9160 1.8979 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 5.3463 0.9565 5.589 2.28e-08 *** LnYCAP -0.6824 0.1254 -5.441 5.29e-08 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 249.64 on 181 degrees of freedom Residual deviance: 212.99 on 180 degrees of freedom (26 observations deleted due to missingness) AIC: 216.99 Number of Fisher Scoring iterations: 4