![]()
![]()
Mathématiques Finances Economie : Logiciels statistiquesCours 3
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Mathématiques Finances Economie : Logiciels statistiques
Cours 3
Table des matières cliquable
1. Comment décrire une seule QT ?
2. Comment décrire plusieurs QT ?
3. Comment décrire une seule QL ?
Réaliser la description d'une seule variable ou de plusieurs variables séparément, c'est effectuer une analyse univariée alors que les traiter deux à deux se nomme analyse bivariée. Enfin, une analyse multivariée prend toutes les variables en compte en même temps.
1. Comment décrire une seule QT ?
Pour décrire une seule variable QT on distingue les calculs toujours possibles, comme celle des quantiles ou percentiles comme la médiane, les quartiles, de ceux supposant une additivité des données, nommés moyenne, variance, écart-type, coefficient de variation. Il est souvent conseillé d'utiliser la médiane plutôt que la moyenne lorsque les données sont réparties sur plusieurs ordres de grandeur. Ces deux indicateurs permettent d'appréhender le centre ou la tendance centrale des données alors que l'écart-type ou l'écart inter-quartiles viennent décrire la dispersion absolue des données alors que la dispersion relative s'exprime par le coefficient de variation ou l'écart inter-quartiles relatif.
On peut aussi trier les données, les afficher en tige-et-feuilles (stem and leaf) pour comprendre comment elles sont distribuées, les découper en classes. Au niveau des représentations graphiques, on préfére tracer les valeurs quand elles sont peu nombreuses (disons jusqu'à une centaine) mais utiliser un histogramme des classes avec une approximation par densité au-delà. Il est parfois utile d'y superposer la courbe de la loi normale associée, l'intervalle de confiance à 95 %, d'en tracer la boite à moustaches avec ou sans encoche...
Attention : si on calcule et on affiche le minimum et le maximum d'une variable QT, on ne s'en sert pas au niveau statistique parce que ce ne sont pas des résumés globaux, mais plutôt des indicateurs locaux, car une seule valeur peut suffire à modifier ces extrema.
Code-source R :
# utilisation des fonctions usuelles de R appart <- read.table("appart.dar",head=TRUE,row.names=1) attach(appart) surf <- SURF detach(appart) cat("Etude de la SURFACE des appartements\n\n") print( summary(surf) ) cat("Nombre de valeurs ",length(surf)," appartements\n") cat("Moyenne ",mean(surf)," m2\n") cat("Médiane ",median(surf)," m2\n") cat("Etendue ",max(surf)-min(surf)," m2\n") cat("Variance ",var(surf)," m2 x m2\n") cat("Ecart-type ",sd(surf)," m2\n") cat("\n") # utilisation des fonctions de statgh.r source("statgh.r") appart <- lit.dar("appart.dar") surf <- appart$SURF decritQT("SURFACE (dossier appartements, Tenenhaus)",surf,"m2",TRUE) decritQT("SURFACE (dossier appartements, Tenenhaus)",surf,"m2",TRUE,"rcalcqt1_1.png")Résultats :
Etude de la SURFACE des appartements Min. 1st Qu. Median Mean 3rd Qu. Max. 20.00 46.00 62.50 82.32 105.20 260.00 Nombre de valeurs 28 appartements Moyenne 82.32143 m² Médiane 62.5 m² Etendue 240 m² Variance 3266.3 m² x m² Ecart-type 57.15156 m² [...] DESCRIPTION STATISTIQUE DE LA VARIABLE SURFACE (dossier appartements, Tenenhaus) Taille 28 individus Moyenne 82.3214 m² Ecart-type 56.1217 m² Coef. de variation 68 % 1er Quartile 46 m² Mediane 62.5 m² 3eme Quartile 105.2 m² iqr absolu 59.25 m² iqr relatif 95 % Minimum 20.0000 m² Maximum 260.0000 m² Tracé tige et feuilles The decimal point is 1 digit(s) to the right of the | 2 | 088025 4 | 080225 6 | 0050 8 | 060 10 | 05607 12 | 14 | 0 16 | 18 | 06 20 | 22 | 24 | 26 | 0Graphique généré :
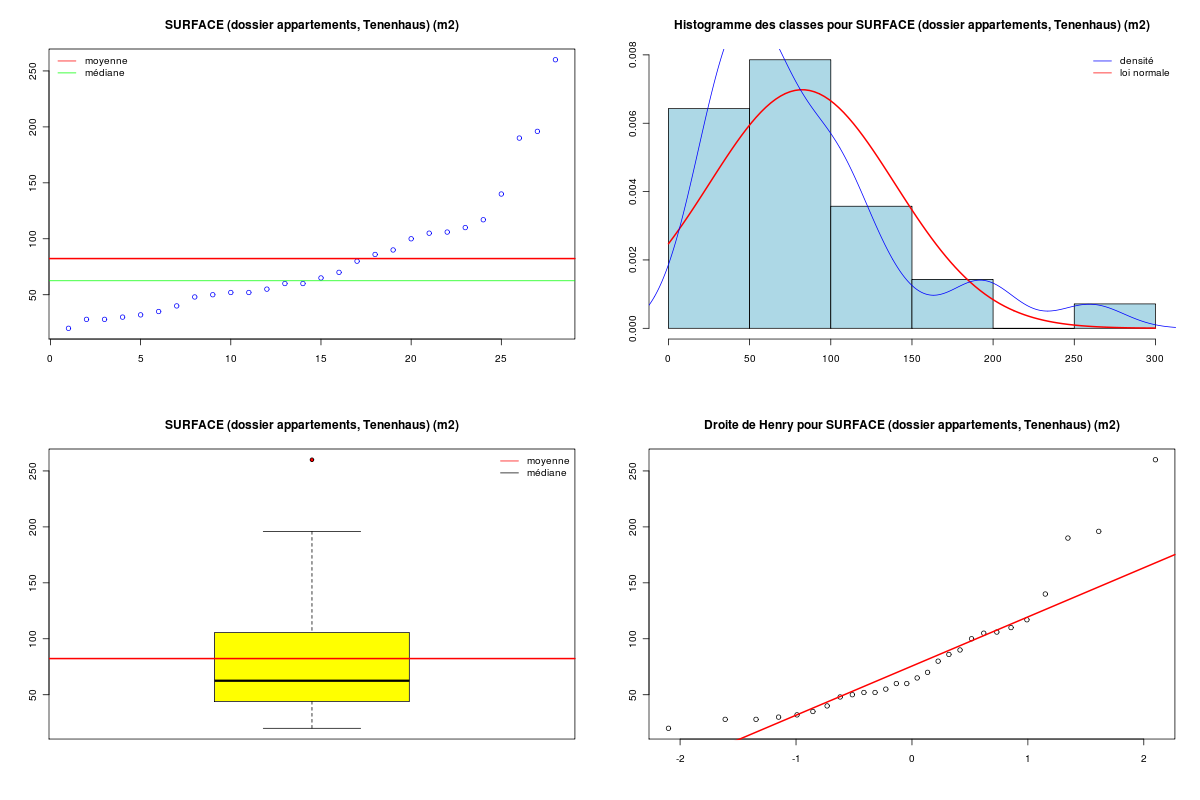
2. Comment décrire plusieurs QT ?
Pour décrire plusieurs variables QT séparément, on regroupe les indicateurs précédents (moyenne, médiane, écart-type, coefficient de variation...) dans un tableau résumé à raison d'une variable par ligne. Il est conseillé de fournir plusieurs affichages triés suivant différents critères : par ordre alphabétique des variables (si elles sont nombreuses), par coefficient de variation décroissant (si les unités sont différentes), par moyenne décroissante (si ce sont les mêmes unités)...
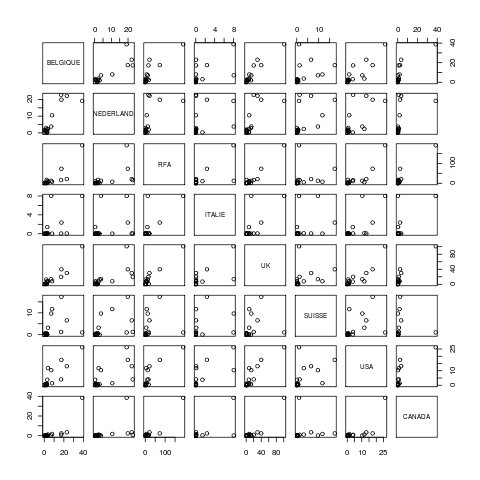
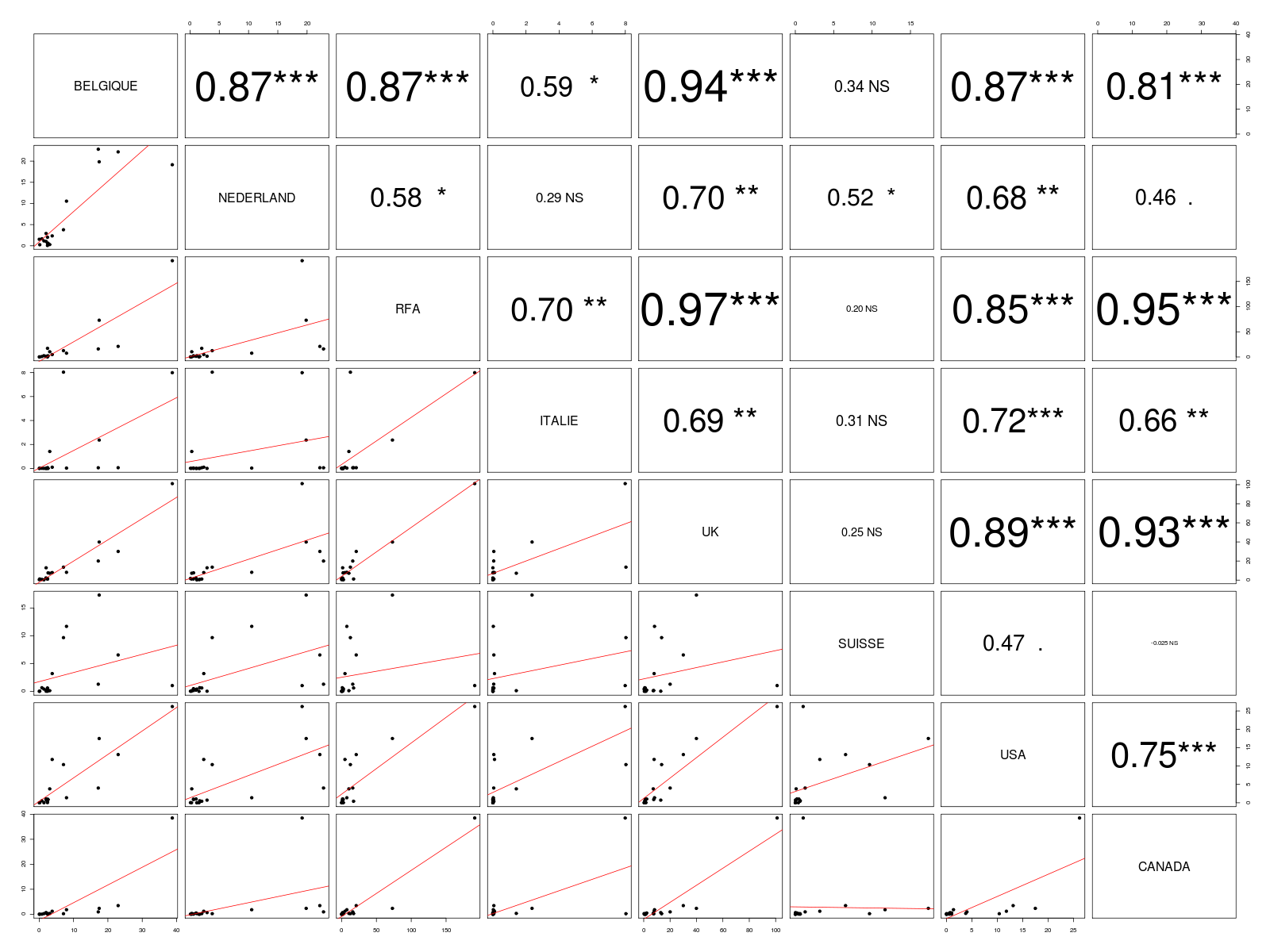
Par contre pour les décrire conjointement, c'est-à-dire ensemble deux à deux, on calcule pour chaque couple de variables QT un coefficient de corrélation, le plus souvent celui de la corrélation linéaire au sens de Pearson, et on présente l'ensemble de ces coefficients sous forme d'une matrice, nommée mdc ou, selon l'usage, « matrice de corrélation », là où il faudrait dire matrice des coefficients de corrélation. Il faut ensuite trier ces coefficients par valeur absolue décroissante avant de fournir éventuellement les coefficients du modèle linéaire sous-jacent. Il est conseillé de produire une grille ou mosaique des tracés deux à deux ou scatterplot afin de visualiser la distribution des différents couples de points.
Code-source R :
# utilisation des fonctions usuelles de R vins <- read.table("vins.dar",head=TRUE,row.names=1) attach(vins) cat("Analyse descriptive des données VINS\n\n") print(summary(vins)) cat("Matrice des corrélations\n") print(cor(vins)) cat("Tracé en scatterplot\n") pairs(vins) png("rcalcqt2_1.png") pairs(vins) dev.off() detach(vins) # utilisation des fonctions de statgh.r source("statgh.r") vins <- lit.dar("vins.dar") allQTdf(vins,rep("hhl",dim(vins)[2])) gr("rcalcqt2_2.png") pairsi(vins) dev.off()Résultats :
Analyse descriptive des données VINS BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA Min. : 0.024 Min. : 0.0740 Min. : 0.135 Min. :0.00000 Min. : 0.284 Min. : 0.0000 Min. : 0.0000 Min. : 0.0000 1st Qu.: 1.986 1st Qu.: 0.7073 1st Qu.: 1.392 1st Qu.:0.00150 1st Qu.: 1.187 1st Qu.: 0.1197 1st Qu.: 0.4415 1st Qu.: 0.0710 Median : 2.511 Median : 1.8235 Median : 3.671 Median :0.02700 Median : 7.398 Median : 0.5355 Median : 1.0070 Median : 0.2855 Mean : 7.470 Mean : 6.2614 Mean : 20.262 Mean :1.11906 Mean : 14.299 Mean : 2.9646 Mean : 5.1526 Mean : 2.8135 3rd Qu.: 7.730 3rd Qu.: 8.8492 3rd Qu.: 15.129 3rd Qu.:0.08775 3rd Qu.: 13.390 3rd Qu.: 2.7130 3rd Qu.: 8.7935 3rd Qu.: 1.1270 Max. :38.747 Max. :22.8060 Max. :191.140 Max. :8.03700 Max. :101.108 Max. :17.3270 Max. :26.1920 Max. :38.5030 Matrice des corrélations BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA BELGIQUE 1.0000000 0.8701664 0.8691718 0.5856241 0.9415832 0.33528874 0.8699177 0.81427399 NEDERLAND 0.8701664 1.0000000 0.5818483 0.2895147 0.6996565 0.51770352 0.6798547 0.45824505 RFA 0.8691718 0.5818483 1.0000000 0.6998400 0.9692588 0.19840491 0.8476578 0.94759822 ITALIE 0.5856241 0.2895147 0.6998400 1.0000000 0.6906419 0.30980099 0.7172391 0.65852485 UK 0.9415832 0.6996565 0.9692588 0.6906419 1.0000000 0.24620969 0.8935279 0.92562833 SUISSE 0.3352887 0.5177035 0.1984049 0.3098010 0.2462097 1.00000000 0.4680754 -0.02463488 USA 0.8699177 0.6798547 0.8476578 0.7172391 0.8935279 0.46807545 1.0000000 0.74694576 CANADA 0.8142740 0.4582450 0.9475982 0.6585248 0.9256283 -0.02463488 0.7469458 1.00000000 Tracé en scatterplot [...] Voici les 10 premières lignes de données (il y en a 18 en tout) BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA CHMP 7.069 3.786 12.578 8.037 13.556 9.664 10.386 0.206 MOS1 2.436 0.586 2.006 0.030 1.217 0.471 0.997 0.051 MOS2 3.066 0.290 10.439 1.413 7.214 0.112 3.788 0.330 ALSA 2.422 1.999 17.183 0.057 1.127 0.600 0.408 0.241 GIRO 22.986 22.183 21.023 0.056 30.025 6.544 13.114 3.447 BOJO 17.465 19.840 72.977 2.364 39.919 17.327 17.487 2.346 BORG 3.784 2.339 4.828 0.098 7.885 3.191 11.791 1.188 RHON 7.950 10.537 7.552 0.024 8.172 11.691 1.369 1.798 ANJO 2.587 0.600 2.101 0.000 7.582 0.143 0.872 0.131 AOCX 17.200 22.806 15.979 0.050 20.004 1.279 4.016 0.944 Par cdv décroissant Num Nom Taille Moyenne Unite Ecart-type Coef. de var. Minimum Maximum 8 CANADA 18 2.813 hhl 8.957 318.36 % 0.000 38.503 4 ITALIE 18 1.119 hhl 2.584 230.93 % 0.000 8.037 3 RFA 18 20.261 hhl 45.910 226.59 % 0.135 191.140 5 UK 18 14.299 hhl 24.301 169.95 % 0.284 101.108 6 SUISSE 18 2.965 hhl 5.024 169.45 % 0.000 17.327 7 USA 18 5.153 hhl 7.550 146.52 % 0.000 26.192 1 BELGIQUE 18 7.470 hhl 10.284 137.66 % 0.024 38.747 2 NEDERLAND 18 6.261 hhl 8.466 135.21 % 0.074 22.806 Par ordre d'entrée Num Nom Taille Moyenne Unite Ecart-type Coef. de var. Minimum Maximum 1 BELGIQUE 18 7.470 hhl 10.284 137.66 % 0.024 38.747 2 NEDERLAND 18 6.261 hhl 8.466 135.21 % 0.074 22.806 3 RFA 18 20.261 hhl 45.910 226.59 % 0.135 191.140 4 ITALIE 18 1.119 hhl 2.584 230.93 % 0.000 8.037 5 UK 18 14.299 hhl 24.301 169.95 % 0.284 101.108 6 SUISSE 18 2.965 hhl 5.024 169.45 % 0.000 17.327 7 USA 18 5.153 hhl 7.550 146.52 % 0.000 26.192 8 CANADA 18 2.813 hhl 8.957 318.36 % 0.000 38.503 Par moyenne décroissante Num Nom Taille Moyenne Unite Ecart-type Coef. de var. Minimum Maximum 3 RFA 18 20.261 hhl 45.910 226.59 % 0.135 191.140 5 UK 18 14.299 hhl 24.301 169.95 % 0.284 101.108 1 BELGIQUE 18 7.470 hhl 10.284 137.66 % 0.024 38.747 2 NEDERLAND 18 6.261 hhl 8.466 135.21 % 0.074 22.806 7 USA 18 5.153 hhl 7.550 146.52 % 0.000 26.192 6 SUISSE 18 2.965 hhl 5.024 169.45 % 0.000 17.327 8 CANADA 18 2.813 hhl 8.957 318.36 % 0.000 38.503 4 ITALIE 18 1.119 hhl 2.584 230.93 % 0.000 8.037 Matrice des corrélations au sens de Pearson BELGIQUE NEDERLAND RFA ITALIE UK SUISSE USA CANADA BELGIQUE 1.000 NEDERLAND 0.870 1.000 RFA 0.869 0.582 1.000 ITALIE 0.586 0.290 0.700 1.000 UK 0.942 0.700 0.969 0.691 1.000 SUISSE 0.335 0.518 0.198 0.310 0.246 1.000 USA 0.870 0.680 0.848 0.717 0.894 0.468 1.000 CANADA 0.814 0.458 0.948 0.659 0.926 -0.025 0.747 1.000 Meilleure corrélation 0.9692588 pour UK et RFA p-value 3.64e-11 Formules RFA = 1.831 * UK -5.921 et UK = 0.513 * RFA + 3.904 Coefficients de corrélation par ordre décroissant 0.969 p-value 0.0000 pour UK et RFA 0.948 p-value 0.0000 pour CANADA et RFA 0.942 p-value 0.0000 pour UK et BELGIQUE 0.926 p-value 0.0000 pour CANADA et UK 0.894 p-value 0.0000 pour USA et UK 0.870 p-value 0.0000 pour USA et BELGIQUE 0.870 p-value 0.0000 pour NEDERLAND et BELGIQUE 0.869 p-value 0.0000 pour RFA et BELGIQUE 0.848 p-value 0.0000 pour USA et RFA 0.814 p-value 0.0000 pour CANADA et BELGIQUE 0.747 p-value 0.0004 pour CANADA et USA 0.717 p-value 0.0008 pour USA et ITALIE 0.700 p-value 0.0012 pour UK et NEDERLAND 0.700 p-value 0.0012 pour ITALIE et RFA 0.691 p-value 0.0015 pour UK et ITALIE 0.680 p-value 0.0019 pour USA et NEDERLAND 0.659 p-value 0.0030 pour CANADA et ITALIE 0.586 p-value 0.0107 pour ITALIE et BELGIQUE 0.582 p-value 0.0113 pour RFA et NEDERLAND 0.518 p-value 0.0278 pour SUISSE et NEDERLAND 0.468 p-value 0.0501 pour USA et SUISSE 0.458 p-value 0.0558 pour CANADA et NEDERLAND 0.335 p-value 0.1738 pour SUISSE et BELGIQUE 0.310 p-value 0.2109 pour SUISSE et ITALIE 0.290 p-value 0.2439 pour ITALIE et NEDERLAND 0.246 p-value 0.3247 pour SUISSE et UK 0.198 p-value 0.4300 pour SUISSE et RFA -0.025 p-value 0.9227 pour CANADA et SUISSEGraphiques générés :
3. Comment décrire une seule QL ?
Pour décrire une seule variable QL, le comptage des différentes modalités se nomme tri à plat et doit se doubler du calcul des pourcentages correspondants, qu'on affiche souvent par ordre décroissant. Il va de soi qu'on affiche les labels mais qu'en aucun cas les code ne doivent apparaitre. La représentation graphique associée préférée est l'histogramme des fréquences, plus apte à montrer les différences qu'un diagramme circulaire en secteurs (camemberts ou parts de gateaux). On peut y faire figurer les comptages, les fréquences, mais les barres doivent de toutes façons être séparées ; l'échelle des hauteurs doit de préférence correspondre aux pourcentages.
Code-source R :
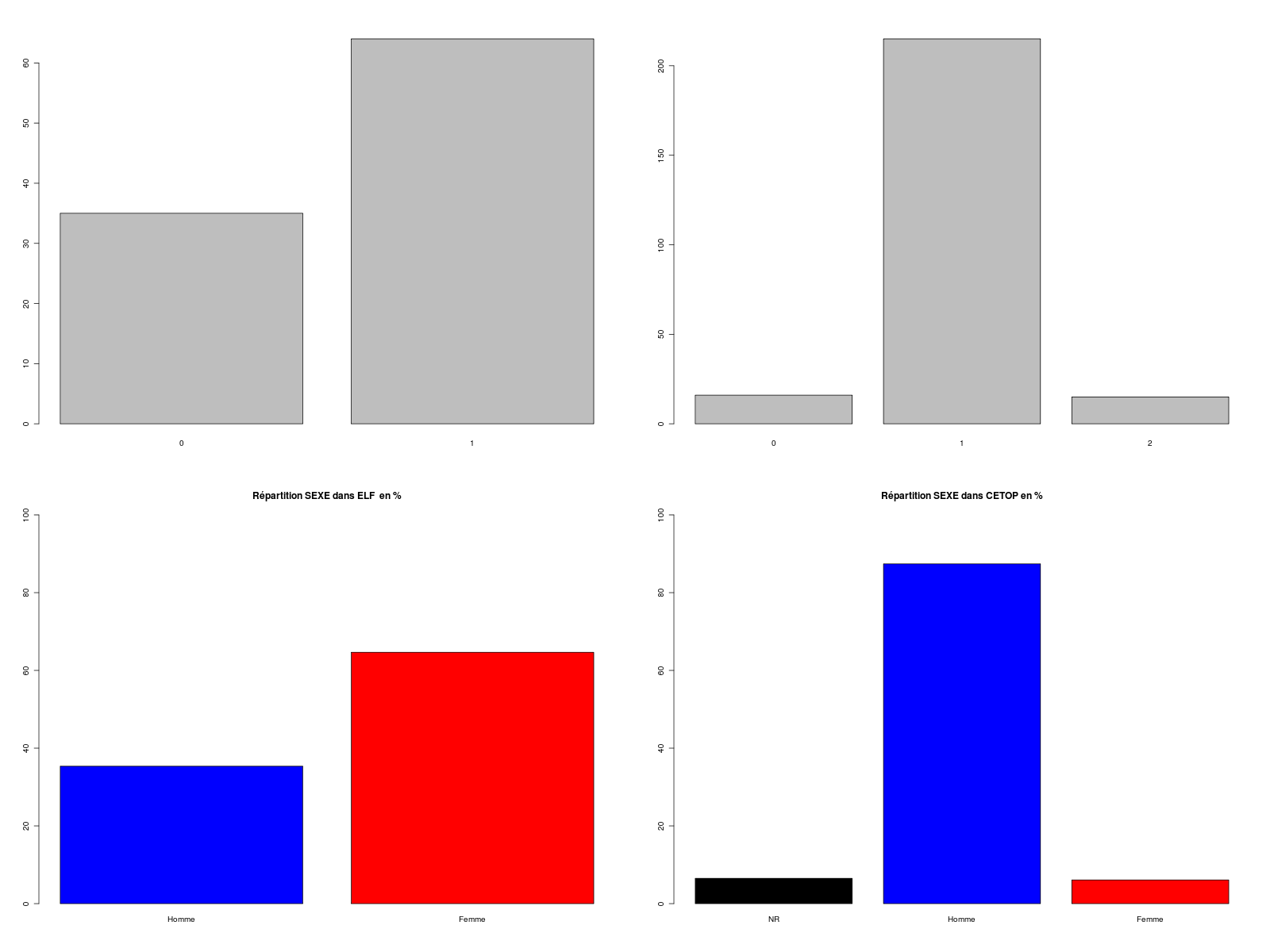
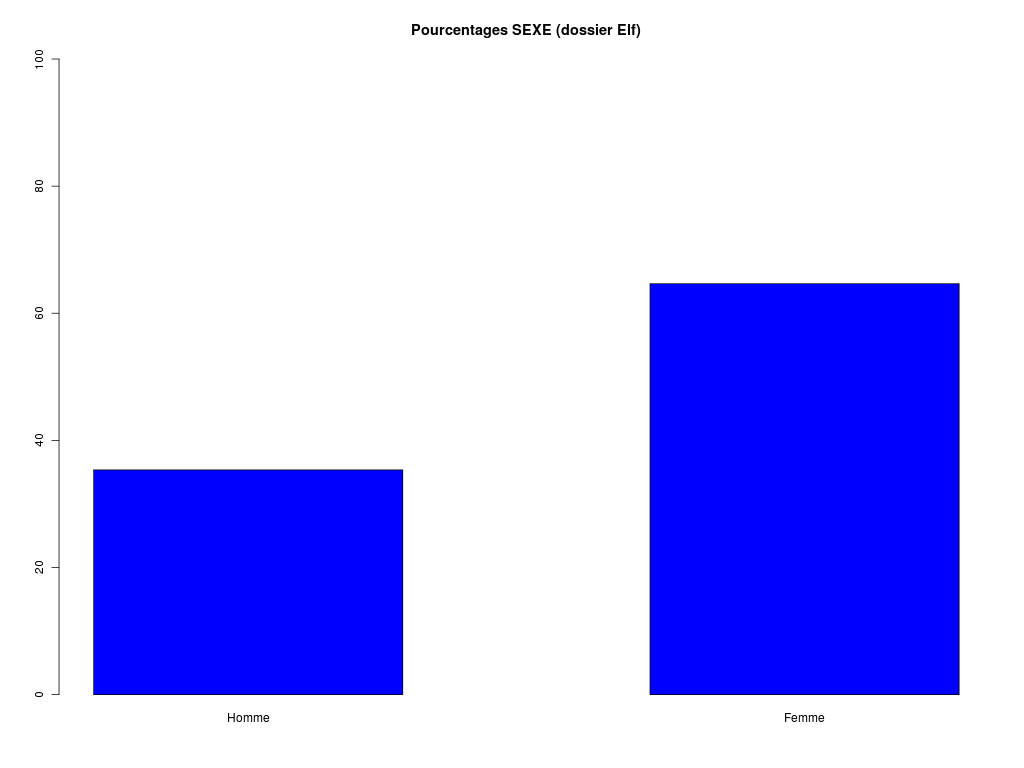
# lecture de données numériques en 0/1 pour le code-sexe elfdata <- read.table("elf.dar",head=TRUE,row.names=1) sx <- elfdata$SEXE # ou elfdata[,"SEXE"] # liste des modalités rencontrées print( unique(sx) ) # comptage des modalités print( table(sx) ) # en pourcentage (noter la différence avec le comptage) print( round(table(sx)*100/length(sx)) ) # ce qu'on tape souvent en R mais qui ne convient pas ici print( summary(sx) ) # construisons et analysons une vraie QL nbind <- length(sx) sxql <- factor(sx,levels=c(0,1), labels=c("Homme","Femme")) print( summary(sxql) ) cat("\nTri à à plat du code-sexe dans ELF (en % pour ",nbind," personnes)\n\n") print( round(table(sxql)*100/length(sxql)) ) # surtout pas png("rcalcql3_1.png",width=1600,height=1200) barplot(sx,main="Surtout pas") dev.off() # un peu mieux barplot( table(sx) ) # nettement peu mieux png("rcalcql3_2.png",width=1600,height=1200) barplot( table(sxql),main="Nettement mieux" ) dev.off() # un graphique nommé et normalisé pcts <- table(sxql)*100/length(sxql) barplot( pcts, ylim=c(0,100) ) # exemple de ce qu'il ne faut pas faire # et ce qu'il faut faire cetopdata <- read.table("cetop2010.dar",head=TRUE,row.names=1) sx2 <- cetopdata$SEXE # ou cetopdata[,"SEXE"] sxql2 <- factor(sx2,levels=c(0,1,2), labels=c("NR","Homme","Femme")) pcts2 <- table(sxql2)*100/length(sxql2) png("rcalcql3_3.png",width=1600,height=1200) par(mfrow=c(2,2)) barplot( table(sx) ) barplot( table(sx2) ) cc1 <- c("blue","red") # pas de couleurs communes cc2 <- c("black","blue","red") # à,cause des NR (non réponses) barplot( pcts , ylim=c(0,100), main="Répartition SEXE dans ELF en %", col=cc1) barplot( pcts2 , ylim=c(0,100), main="Répartition SEXE dans CETOP en %",col=cc2) dev.off() # avec les fonctions de statgh.r elfdata <- lit.dar("elf.dar") decritQL("Pourcentages SEXE (dossier Elf)",elfdata$SEXE,"Homme Femme",TRUE,"rcalcql3_4.png")Résultats :
[1] 1 0 sx 0 1 35 64 sx 0 1 35 65 Min. 1st Qu. Median Mean 3rd Qu. Max. 0.0000 0.0000 1.0000 0.6465 1.0000 1.0000 Homme Femme 35 64 Tri à à plat du code-sexe dans ELF (en % pour 99 personnes) sxql Homme Femme 35 65 TRI A PLAT DE : Pourcentages SEXE (dossier Elf) (ordre des modalités) Homme Femme Total Effectif 35 64 99 Frequence (en %) 35 65 100 Cumul fréquences 35 100 100 QUESTION : Pourcentages SEXE (dossier Elf) (par fréquence décroissante) Femme Homme Total Effectif 64 35 99 Frequence (en %) 65 35 100 Cumul fréquences 65 100 100 [1] "Homme" "Femme" vous pouvez utiliser rcalcql3_4.pngGraphiques générés :
4. Comment décrire plusieurs QL ?
Pour décrire plusieurs variables QL séparément, il faut recourir à un tableau résumé des fréquences et pourcentages, que nous conseillons de construire comme suit : ce tableau contient sur chaque ligne les plus forts pourcentages des modalités d'une même variable ; les lignes du tableau sont triés par ordre décroissant suivant le mode c'est-à-dire suivant la valeur du plus fort pourcentage (voir l'exemple ci-dessous pour mieux comprendre comment est constitué le tableau). S'il est licite et conseillé de tracer tous les histogrammes de fréquence, on prendra soin à utiliser les mêmes échelles afin de permettre une comparaison visuelle des comptages.
Par contre pour les décrire conjointement, c'est-à-dire ensemble deux à deux, on calcule pour chaque couple de variables QT les comptages de couples de modalités, ce qui se nomme tri croisé et on affiche des histogrammes de comptages groupés, empilés ou superposés suivant ce qui est le plus « flagrant ».
Code-source R :
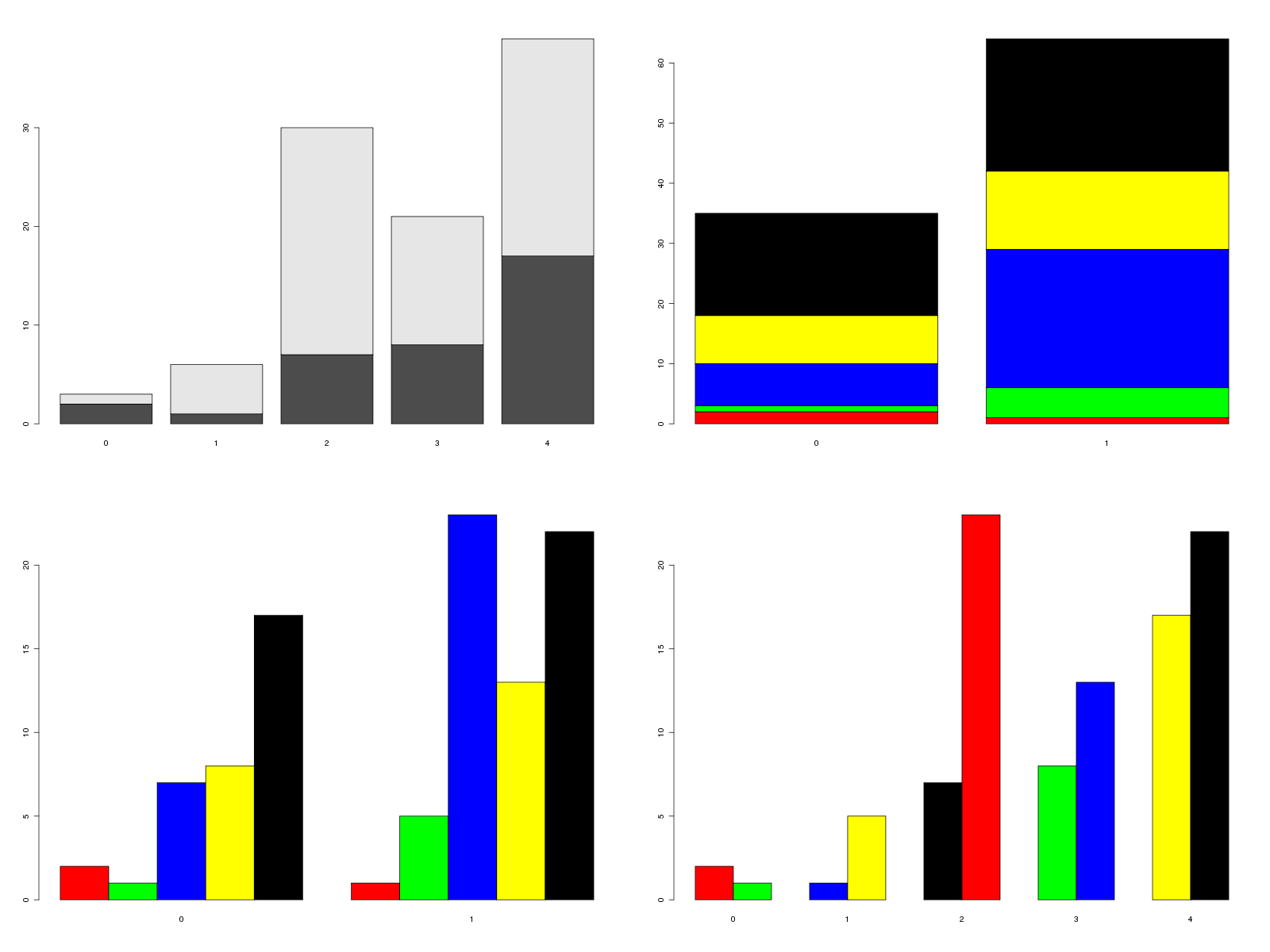
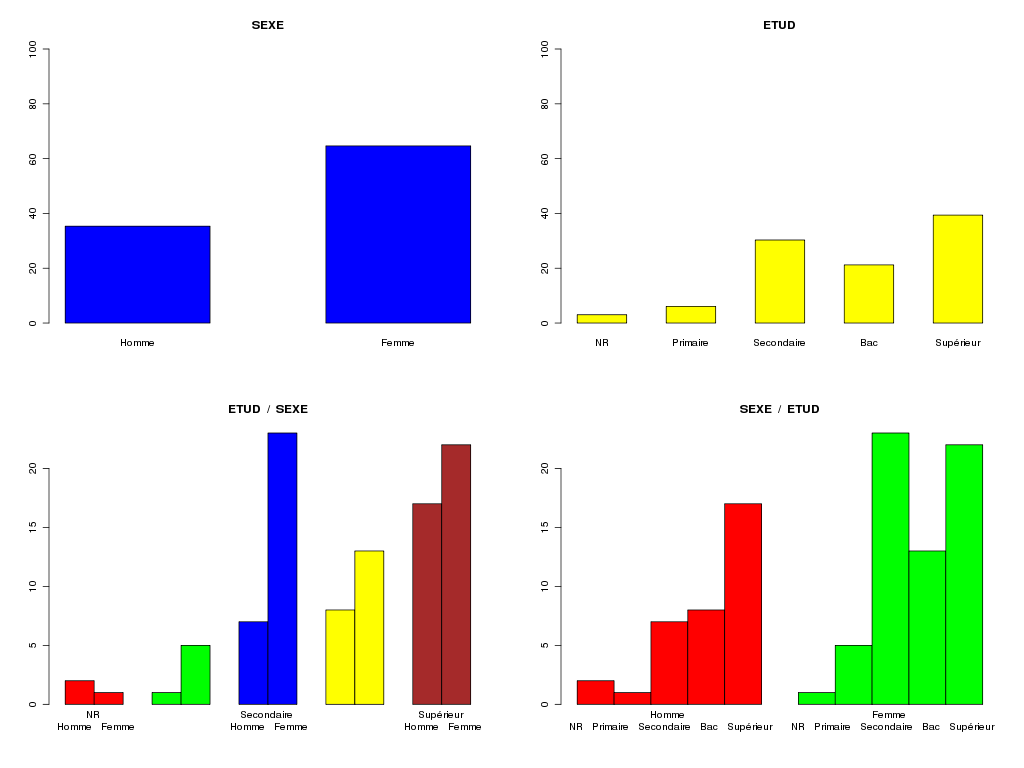
# lecture des données elfdata <- lit.dar("elf.dar") # tri croisé minimaliste cat("Ce qu'il ne faut pas afficher\n") print( table(elfdata$SEXE) ) print( table(elfdata$ETUD) ) print( table(elfdata$SEXE,elfdata$ETUD) ) # et ses graphiques possibles png("rcalcql4_1.png",width=1600,height=1200) par( mfrow=c(2,2)) cinqcouleurs <- c("red","green","blue","yellow","black") barplot(table(elfdata$SEXE,elfdata$ETUD)) barplot(table(elfdata$ETUD,elfdata$SEXE),col=cinqcouleurs) barplot(table(elfdata$ETUD,elfdata$SEXE),col=cinqcouleurs,beside=TRUE) barplot(table(elfdata$SEXE,elfdata$ETUD),col=cinqcouleurs,beside=TRUE) dev.off() # mieux : avec des modalités m_sexe <- c("Homme","Femme") m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur") sexe <- factor(elfdata$SEXE,levels=0:1,labels=m_sexe) etud <- factor(elfdata$ETUD,levels=0:4,labels=m_etud) cat("[ce qu'il faut afficher]\n") titre1 <- "Tri à plat de SEXE dans le dossier ELF" cat(titre1,"\n") print( table(sexe) ) titre2 <- "Tri à plat de ETUD dans le dossier ELF" cat(titre2,"\n") print( table(etud) ) titre3 <- "Tri croisé SEXExETUD dans le dossier ELF" cat("\n",titre3,"\n") print( table(sexe,etud) ) png("rcalcql4_2.png",width=1600,height=1200) par( mfrow=c(2,1)) barplot(table(etud,sexe),col=cinqcouleurs,beside=TRUE, legend.text=m_etud,args.legend=list(x="topleft"),main=titre3 ) barplot(table(sexe,etud),col=cinqcouleurs,beside=TRUE) dev.off()Résultats :
Ce qu'il ne faut pas afficher 0 1 35 64 0 1 2 3 4 3 6 30 21 39 0 1 2 3 4 0 2 1 7 8 17 1 1 5 23 13 22 [ce qu'il faut afficher] Tri à plat de SEXE dans le dossier ELF sexe Homme Femme 35 64 Tri à plat de ETUD dans le dossier ELF etud NR Primaire Secondaire Bac Supérieur 3 6 30 21 39 Tri croisé SEXExETUD dans le dossier ELF etud sexe NR Primaire Secondaire Bac Supérieur Homme 2 1 7 8 17 Femme 1 5 23 13 22Graphiques générés :
Si on utilise statgh.r :
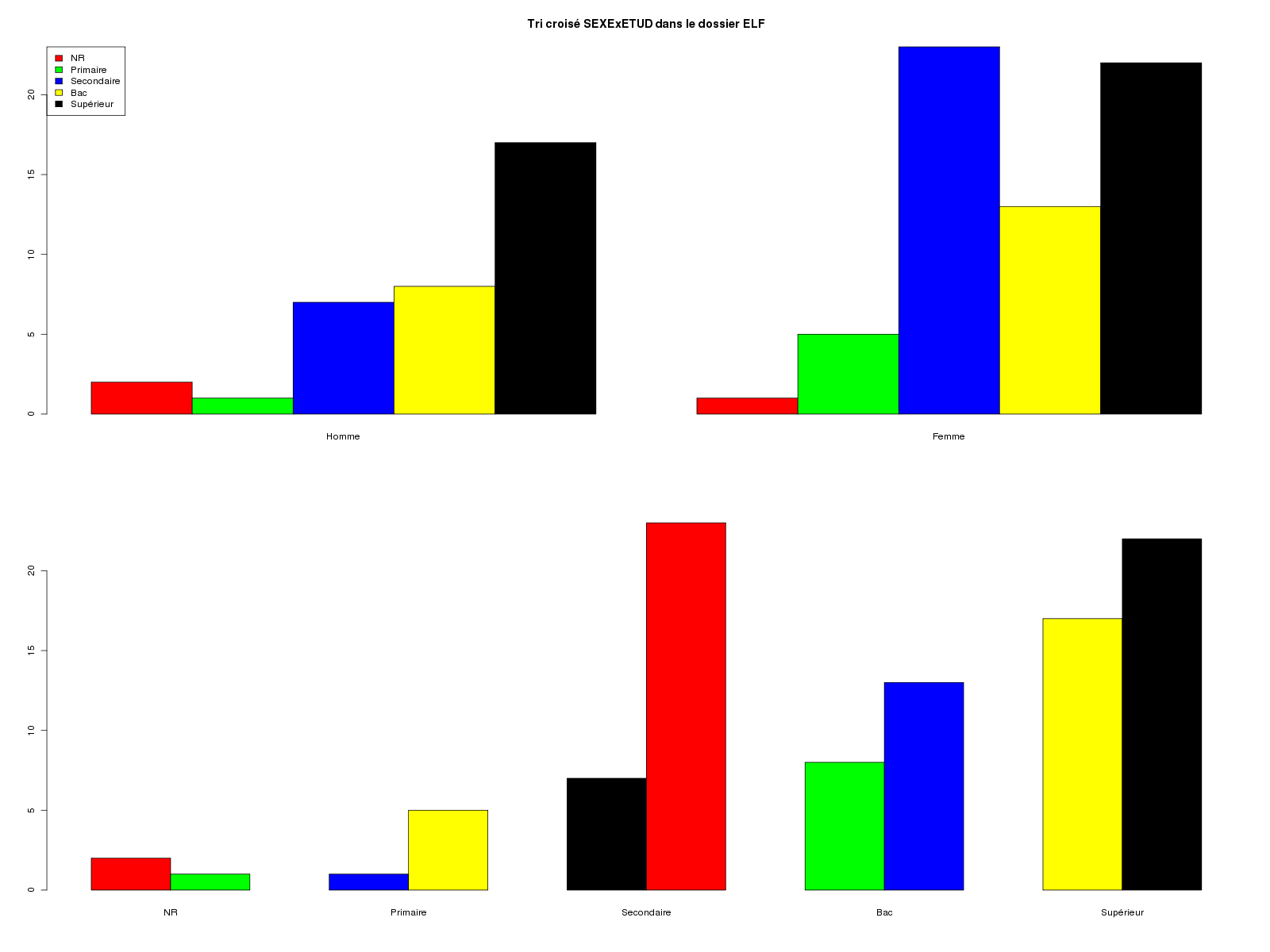
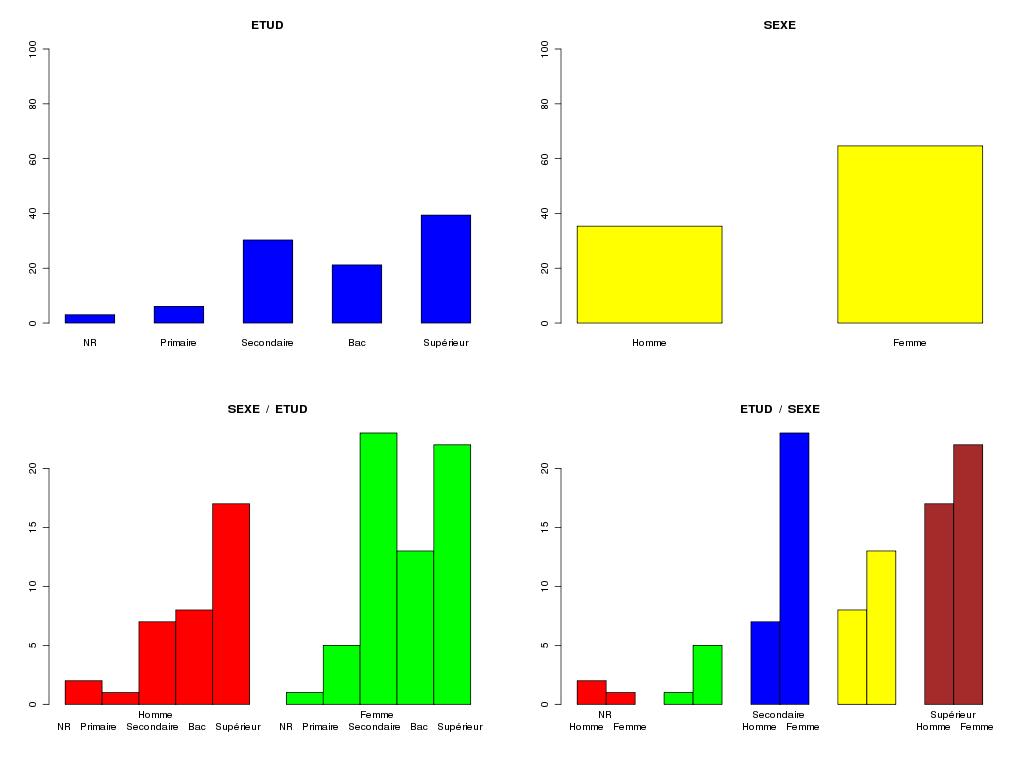
# lecture de statgh.r source("statgh.r") # lecture des données elfdata <- lit.dar("elf.dar") # conversion en variables qualitatives m_sexe <- c("Homme","Femme") m_etud <- c("NR","Primaire","Secondaire","Bac","Supérieur") sexe <- factor(elfdata$SEXE,levels=0:1,labels=m_sexe) etud <- factor(elfdata$ETUD,levels=0:4,labels=m_etud) # tri croisé triCroise("SEXE",sexe,m_sexe,"ETUD",etud,m_etud,TRUE,"rcalcql5_1.png") # analyse avec tableau récapitulatif bien structuré # définition des matrices de modalités elfCOLQL <- c(2,5) elfQLm <- matrix(nrow=length(elfCOLQL),ncol=3) # col 1 : intitulé court # col 2 : texte de la question # col 3 : modalités concaténées avec le symbole | via la fonction lstMod # remplissage des matrices de modalités elfQLm[1,1] <- c(" SEXE ") elfQLm[1,2] <- c(" Sexe de la personne") elfQLm[1,3] <- lstMod( m_sexe ) elfQLm[2,1] <- c(" ETUD ") elfQLm[2,2] <- c(" Niveau d'études ") elfQLm[2,3] <- lstMod( m_etud ) allQL(elfdata,elfQLm,elfCOLQL)Résultats :
TRI CROISE DES QUESTIONS : SEXE (en ligne) ETUD (en colonne) Effectifs NR Primaire Secondaire Bac Supérieur Homme 2 1 7 8 17 Femme 1 5 23 13 22 Valeurs en % du total NR Primaire Secondaire Bac Supérieur TOTAL Homme 2 1 7 8 17 35 Femme 1 5 23 13 22 65 TOTAL 3 6 30 21 39 100 CALCUL DU CHI-DEUX D'INDEPENDANCE ================================= TABLEAU DES DONNEES Homme Femme Total NR 2 1 3 Primaire 1 5 6 Secondaire 7 23 30 Bac 8 13 21 Supérieur 17 22 39 Total 35 64 99 VALEURS ATTENDUES et MARGES Homme Femme Total NR 1.1 1.9 3 Primaire 2.1 3.9 6 Secondaire 10.6 19.4 30 Bac 7.4 13.6 21 Supérieur 13.8 25.2 39 Total 35.0 64.0 99 CONTRIBUTIONS SIGNEES Homme Femme NR + 0.832 - 0.455 Primaire - 0.593 + 0.324 Secondaire - 1.226 + 0.671 Bac + 0.045 - 0.024 Supérieur + 0.748 - 0.409 Valeur du chi-deux 5.326981 Le chi-deux max (table) à 5 % est 9.487729 ; p-value 0.2553618 pour 4 degrés de liberte décision : au seuil de 5 % on ne peut pas rejeter l'hypothèse qu'il y a indépendance entre ces deux variables qualitatives. PLUS FORTES CONTRIBUTIONS AVEC SIGNE DE DIFFERENCE Signe Valeur Pct Mligne Mcolonne Ligne Colonne Obs Th - 1.226 23.02 % Secondaire Homme 3 1 7 10.6 + 0.832 15.62 % NR Homme 1 1 2 1.1 + 0.748 14.05 % Supérieur Homme 5 1 17 13.8 + 0.671 12.59 % Secondaire Femme 3 2 23 19.4 - 0.593 11.13 % Primaire Homme 2 1 1 2.1 - 0.455 8.54 % NR Femme 1 2 1 1.9 - 0.409 7.68 % Supérieur Femme 5 2 22 25.2 + 0.324 6.08 % Primaire Femme 2 2 5 3.9 + 0.045 0.84 % Bac Homme 4 1 8 7.4 - 0.024 0.46 % Bac Femme 4 2 13 13.6 TABLEAU RECAPITULATIF DES VARIABLES QUALITATIVES Intitulé Question -------- -------- SEXE Sexe de la personne ETUD Niveau d'études Affichage par mode décroissant puis par effectifs décroissants SEXE 65 % Femme 35 % Homme ETUD 39 % Supérieur 30 % Secondaire 21 % BacGraphiques générés :
5. Comment décrire QT et QL ensemble ?
Pour décrire une variable QT et une QT ensemble, il suffit de décrire la variable QT pour chaque modalité de la QL et de mettre ensemble tous les résultats et graphiques. Pour savoir il y a une différence significative entre ces résultats, il faut réaliser une ANOVA, ce qui est décrit dans le cours suivant.
Code-source R :
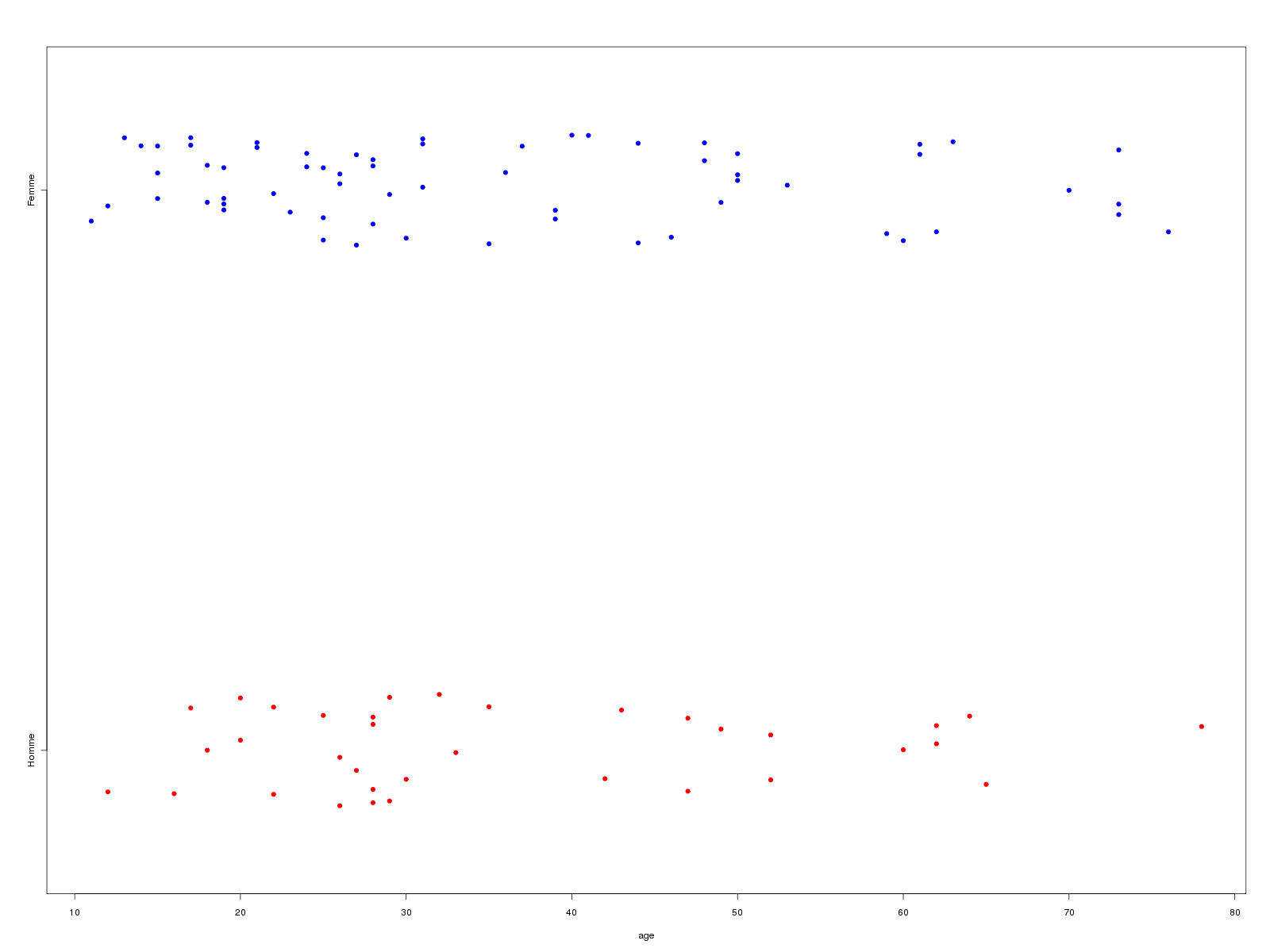
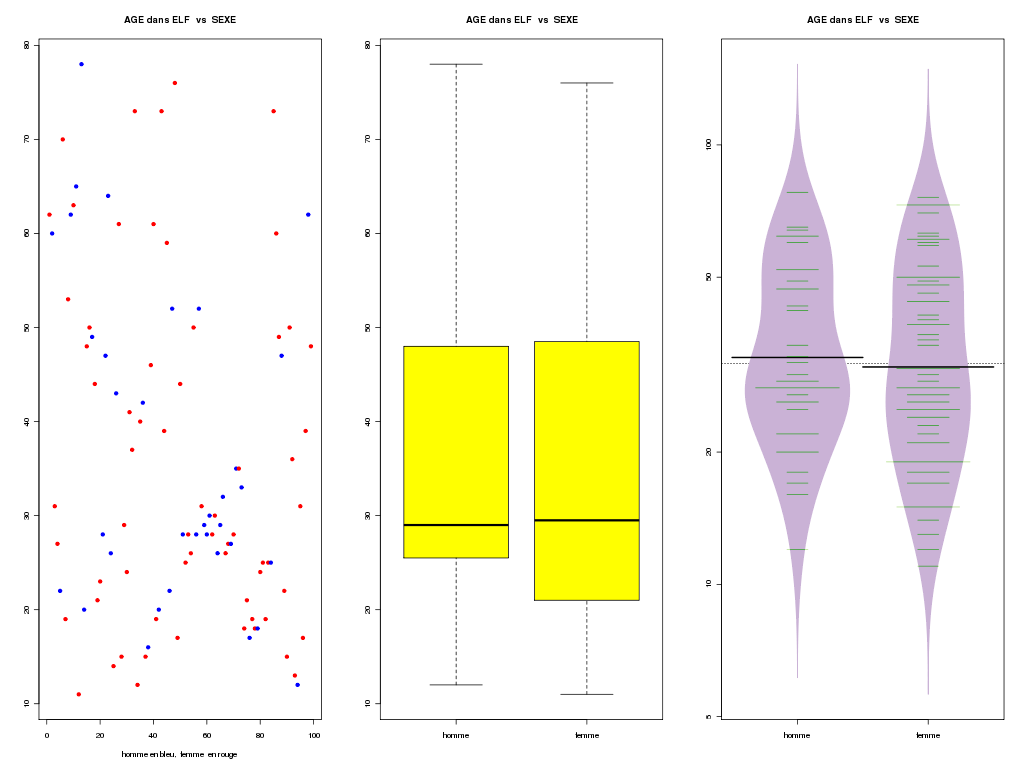
elfdata <- lit.dar("elf.dar") age <- elfdata$AGE m_sexe <- c("Homme","Femme") sexe <- elfdata$SEXE sexeql <- factor(elfdata$SEXE,levels=0:1,labels=m_sexe) agehom <- age[sexe==0] agefem <- age[sexe==1] mres <- rbind(summary(agehom),summary(agefem),summary(age)) row.names(mres) <- c("Hommes","Femmes","Tous") print( mres ) #png("rcalc5_1.png",width=1600,height=1200) stripchart(age~sexeql,col=c("red","blue"),pch=19,method="jitter") #dev.off() # avec les fonction de statgh.r : # attention, il faut installer le package beanplot # par install.packages("beanplot") # ou par # après avoir téléchargé le fichier .zip # à l'adresse decritQTparFacteur("AGE dans ELF",age,"ans","SEXE",sexe,"homme femme",TRUE,"rcalc5.png")Résultats :
Min. 1st Qu. Median Mean 3rd Qu. Max. Hommes 12 25.5 29.0 36.40 48.00 78 Femmes 11 21.0 29.5 35.52 48.25 76 Tous 11 22.0 29.0 35.83 48.50 78 VARIABLE QT AGE dans ELF (unité=ans) VARIABLE QL SEXE labels : homme femme N Moy Unite Ect Cdv Q1 Med Q3 EIQ Min Max Global 99 35.8283 ans 17.4640 49 22 29 48.5 26.5 11 78 homme 35 36.4000 ans 16.6497 46 25.5 29 48 22.5 12 78 femme 64 35.5156 ans 17.8859 50 21 29.5 48.25 27.25 11 76 Analysis of Variance Table Response: nomVarQT Df Sum Sq Mean Sq F value Pr(>F) nomVarQL 1 17.7 17.696 0.0569 0.812 Residuals 97 30176.4 311.097Graphiques générés :