Statistiques élémentaires avec le logiciel R
|
-- Session de formation continue pour l'université d'Angers --
|
Séance 1 : Introduction aux analyses statistiques et au logiciel R
|
1. Notions d'analyse statistique, d'enquête, de protocole et d'échantillon
1.1 Qu'est-ce qu'une analyse statistique ?
Une étude statistique, c'est d'abord l'étude de données en vue de la résolution d'un problème, qu'il s'agisse de synthétiser de nombreux chiffres, de modéliser en vue d'expliquer ou de prédire des phénomènes. Le point de départ est bien sûr des données, qu'il s'agisse de l'ensemble de la population ou seulement d'un échantillon. Après une vérification élémentaire des données (ce qui oblige à connaître et comprendre, au moins globalement, les codes et les unités utilisées) à l'aide d'indicateurs comme le minimum et le maximum ou la liste des valeurs distinctes, il faut souvent suivre un plan d'étude statistique défini à l'avance.
Si on ne s'intéresse qu'à la description des données, des tableaux résumés et des graphiques bien choisis doivent être accompagnés d'une rédaction soignée, précise, qui sépare les résultats objectifs («3 % de redoublants en plus») des commentaires subjectifs («ce qui est très peu») et des hypothèses d'interprétation («sans doute à cause du peu de changement de cours dans les nouvelles maquettes»). Par contre, dans le cas de statistiques inférentielles, un test ne devra être utilisé qu'après avoir montré que ses conditions d'applications sont vérifiées, il faudra préciser la probabilité critique (p-value) utilisée, etc. En cas de modélisation, il faudra justifier le choix des variables, détailler les coefficients du modèle, donner leur intervalle de confiance et leur p-value...
La rédaction pour un article de vulgarisation ou de recherche est en général tout aussi exigeante que la rédaction d'un simple rapport d'étude statistique pour un mémoire. Par contre elle est plus subtile par ce que plus concise et plus orientée vers un public ciblé. Le choix des adjectifs, des qualificatifs y est très important.
La réalisation et la rédaction d'une analyse statistique mettent en jeu deux domaines distincts de compétence :
-
le calcul statistique avec ses méthodes, ses modèles, ses termes techniques et ses formules, leurs conditions d'applications, l'utilisation des logiciels ad hoc et les conclusions mathématiques licites auxquelles il aboutit ;
-
l'écriture du rapport d'analyse via la présentation du protocole et des données (voire des hypothèses sous-jacentes), la mise en forme de tout ou partie des résultats et la rédaction des conclusions, interprétations et commentaires pour les spécialistes du domaine, pour l'équipe de recherche ou pour le grand public.
Une analyse statistique ne se réduit donc pas à une suite de calculs,
même justes et justifiés. La rédaction est un art difficile. Elle est souvent
bâclée par les [pseudo]scientifiques qui confondent phrases, littérature,
verbiage et production littéraire.
Or, la qualité d'un mémoire, d'un article de recherche, d'un rapport d'expérimentation transparaît
au fil des paragraphes. Le choix des termes employés renforce chez le lecteur
ou le correcteur la conviction que le travail fait a été bien fait, que les méthodes
statistiques sont maîtrisées, que le passage des chiffres (comme m = 12.3 jours d'apprentissage)
aux lettres ("une durée moyenne aussi faible qu'à l'habitude") est le fruit
d'un mûre réflexion...
1.2 Méthodologie, enquête, protocole, échantillon
Pour réaliser une étude statistique, il faut donc des données. Mais d'où viennent-elles et comment les obtenir ? C'est là où on a besoin de méthode et de méthodologie pour choisir des méthodes qualitatives ou quantitatives, pour déterminer avec soin un échantillon représentatif au sein d'une population soigneusement ciblée. Les questions de recherche posées doivent être écrites avec soin. Souhaite-on seulement décrire ou «expliquer» (au sens statistique du terme) ou veut-on aussi prédire ?
Lors des enquêtes de terrain ou par questionnaire, notamment, il est important de s'assurer que les biais simples sont évités, notamment le biais de sélection, le biais d'influence et le biais de confirmation. Par exemple n'interroger que les personnes de plus de 70 ans induit un biais de sélection. Rédiger dans un questionnaire un item «Pensez-vous comme les spécialistes du domaine que...» c'est biaiser les réponses possibles. Ne s'intéresser qu'aux personnes correspondant à ce que l'on veut montrer fausse forcément les données d'entrée et donc tous les calculs qui en résulteront.
Il faut donc s'assurer que le phénomène à étudier a été bien cerné, que les variables afférentes ont bien été trouvées et incluses dans le protocole d'analyse, que la saisie des données est bien la même pour toutes les personnes interrogées... En particulier, lorsque la saisie doit se faire par questionnaire et entretien direct, il est important de former les enquêteurs et de leur fournir un protocole détaillé à suivre à la lettre pour garantir l'homogénéité de la saisie.
Lorsque c'est possible, la taille de l'échantillon (sample size en anglais) devrait être déterminée avec soin. Avoir un petit échantillon mal distribué (moins de 50 individus, pas de normalité) oblige à recourir des tests statistiques non paramétriques. En pratique, il peut arriver que la durée de l'enquête ou du sondage et le temps global imparti à l'étude statistique ne permettent pas d'avoir un échantillon suffisamment important pour que la portée généralisatrice des résultats soit satisfaisante. Il faut alors rédiger «plus prudemment» que pour une grande cohorte nationale...
Une attention particulière doit être apportée à ce qu'on nomme données appariées car leur traitement statistique diffère des données non appariées. Voici deux exemples de données appariées : des mesures avant et après prise de médicament ; des notes dans différentes matières pour les mêmes étudiant(e)s.
On trouvera sur le site DUMAS du CNRS des mémoires déposés après soutenance, dans divers domaines scientifiques. Par exemple, si on s'intéresse à l'orthophonie, on peut trouver une quarantaine de mémoires dont la première partie traite justement la plupart du temps de protocole et de données. Le lien correspondant est ici. Ainsi les 16 épreuves du protocole utilisé dans le mémoire de L. Mescam sont longuement décrites dans les pages 55 à 87. De même, la mise en pratique pour la validation de l'EDA dans le mémoire de M. Cavin et M. Cuisset est soigneusement explicitée pages 25 à 35.
Pour mémoire, les différentes façons d'aborder une étude dans le cadre de la recherche clinique sont assez bien recensées dans le wiki français sous la rubrique essai clinique. On y trouve en particulier le rappel de la notion de biais et de type d'étude (contrôlée, randomisée, en [double] aveugle...). La plupart du temps, dans un article de recherche, la section Materials and Methods rappelle le protocole. Voir par exemple l'article Ratziu (2006). De même, la rubrique Statistical Analysis contient souvent un rappel des méthodes, des choix (niveau de confiance...) et, plus récemment, du logiciel utilisé. Ainsi, le fichier analyses.txt recense ces rubriques pour des articles fournis par nos étudiants de l'école doctorale. Selon l'adage «l'usage fait loi» il est bon de s'inspirer des articles ou des présentations usuelles du domaine pour être reconnu par ses pairs... On apprend ainsi à parler comme les autres, à présenter et rédiger comme les autres, ce qui facilite l'évaluation et la transmission des savoirs.
2. Données QL (qualitatives) et QT (quantitatives), codages et unités
2.1 Les divers types de données
On distingue traditionnellement les variables à codes (ou QL) des variables à unités (ou QT). Pour les premières, seuls les comptages simples ou croisés sont autorisés. Pour les secondes, en fonction de la sommabilité des unités, on effectue soit des calculs simples de médiane, quartile, quantile ou des calculs plus compliqués de moyennes, écart-types, coefficient de variation... Enfin, des variables textuelles (ou QX) comme des listes de mots ou de phrases sont également envisageables mais demandent en général des pré-traitements linguistiques.
L'usage veut qu'on nomme QUANTITATIVE une variable à unités et QUALITATIVE une variable à codes, avec des qualificatifs comme semi-quantitative, quantitative continue, quantitative discrète, quantitative-intervalle, quantitative rapport, qualitative nominale, qualitative ordinale... Pour plus de détails, consulter ma page sur les variables statistiques.
Attention aux données : un pays comme RDA, une unité comme le franc indiquent que les données datent. Il n'est peut-être pas conseillé de les utiliser pour une description actuelle...
Certains logiciels (dont le logiciel R) détectent les QT et les QL par le type des données lues : une variable numérique est alors forcément QT et une variable caractère est QL. Si ce n'est pas le bon type, il faut le préciser au logiciel pour forcer l'ordinateur à reconnaître le "bon" type des données. Par contre à notre connaissance aucun logiciel ne demande de spécifier les unités, sans doute parce que souvent les gens ne les connaissent pas et parce que certains calculs utilisent d'autres unités : la moyenne d'un poids exprimé en kg est aussi en kg alors que sa variance est en kg2, soit kg au carré (!) et son coefficient de variation en %. Ce serait pourtant bien utile, pour éviter d'additionner des moyennes et des variances, pour ne pas calculer des moyennes de codes numériques, etc. C'est pourquoi il faut mieux éviter Excel, qui n'est pas un logiciel de statistiques et qui ne connaît rien : ni QT, ni QL et ne teste rien !
Il faut aussi bien faire attention aux variables QL ordinales car contrairement aux variables QL nominales les modalités y sont ordonnées et il faut respecter cet ordre dans les affichages. Il est clair qu'il y a une gradation dans un peu, beaucoup, passionnément qu'on doit prendre en compte et qui ne se retrouve pas dans des simples oui/non.
De même, l'interprétation des résultats des variables QT entières/discrètes ne peut pas être aussi fine que pour les résultats sur les variables QT réelles/continues : un nombre d'enfants moyens de 2,674 -- même si rapporter 2,7 est plus adapté que rapporter grossièrement l'arrondi 3 -- n'a pas de sens alors que descendre à une perte de poids de 0,125 kg par jour se conçoit et se comprend bien. On affiche pourtant dans les deux cas le même nombre de décimales...
2.2 Les formats de fichiers
On peut utiliser de simples fichiers textes, bien cadrés ou seulement délimités par des virgules ou des points virgules mais rien n'interdit d'avoir saisi et géré les données avec un tableur ou un autre logiciel. Excel par exemple a ici tout son sens et son utilité. Il faut en général avoir visualisé (c'est-à-dire parcouru sans avoir édité) le fichier des données avant de lancer une commande de lecture ou d'import, car la première ligne de données est parfois une ligne de données et d'autres fois la liste des variables. De même la première colonne de données est parfois un identifiant et d'autres fois non. On a alors intérêt à créer un identifiant basé sur le numéro des lignes si on doit trier les données...
Les logiciels statistiques ont en général une extension dédiée, parfois propriétaire, comme les extensions .sav pour SPSS, .sasb7dat pour SAS, .sta pour STATISTICA, .Rdata pour R. Une conséquence pratique est qu'il est parfois impossible d'ouvrir un jeu de données sans avoir le logiciel, ce qui pose souci en cas de logiciel payant...
Par contre, pratiquement tous les logiciels statistiques savent lire des fichiers textes, des fichiers Excel et des fichiers CSV. Savoir importer et exporter de et vers ces formats en plus des formats propriétaires est très utile, voire quasi obligatoire.
Dans le cas de fichier-textes, nous conseillons de mettre comme extension .dat tout fichier de données dont la première ligne n'est pas la liste des variables, et de mettre comme extension .dar tout fichier de données dont la première ligne donne le nom des variables et dont la première colonne est un identifiant de ligne. Voici ce que cela donne en pratique :
Un exemple de fichier .dat
63 10% 15 4 2 89,66 36
66 18% 20 20 5,5 97,06 50
69 2% 18 0 1,5 95,78 57
69 4% 22 7 4 97,19 21
70 22% 14 13 1 88,91 35
70 6% 19 16 5 94,99 56
72 32% 24 20 1,5 102,24 57
72 28% 26 7 2 107,5 46
72 26% 28 0 3,5 101,43 33
73 4% 18 20 3,5 79,42 41
74 10% 21 18 4 100,21 40
75 24% 22 20 5 92,14 59
75 14% 18 10 3,5 69,47 52
81 22% 24 14 2 84,3 54
81 26% 27 20 3 101,97 46
53 26% 21 20 -2 112,47 57
57 42% 17 20 6 103,13 60
Un exemple de fichier .dar
ID AGE TED L30 Htrr MLD Baddeley PASAT
P01 63 10% 15 4 2 89,66 36
P02 66 18% 20 20 5,5 97,06 50
P03 69 2% 18 0 1,5 95,78 57
P04 69 4% 22 7 4 97,19 21
P05 70 22% 14 13 1 88,91 35
P06 70 6% 19 16 5 94,99 56
P07 72 32% 24 20 1,5 102,24 57
P08 72 28% 26 7 2 107,5 46
P09 72 26% 28 0 3,5 101,43 33
P10 73 4% 18 20 3,5 79,42 41
P11 74 10% 21 18 4 100,21 40
P12 75 24% 22 20 5 92,14 59
P13 75 14% 18 10 3,5 69,47 52
P14 81 22% 24 14 2 84,3 54
P15 81 26% 27 20 3 101,97 46
P16 53 26% 21 20 -2 112,47 57
P17 57 42% 17 20 6 103,13 60
Un exemple de fichier avec identifiant explicite
Ini AGE TED L30 Htrr MLD Baddeley PASAT
YD 63 10% 15 4 2 89,66 36
MR 66 18% 20 20 5,5 97,06 50
AR 69 2% 18 0 1,5 95,78 57
PL 69 4% 22 7 4 97,19 21
MC 70 22% 14 13 1 88,91 35
GC 70 6% 19 16 5 94,99 56
FV 72 32% 24 20 1,5 102,24 57
JB 72 28% 26 7 2 107,5 46
JC 72 26% 28 0 3,5 101,43 33
JL 73 4% 18 20 3,5 79,42 41
MD 74 10% 21 18 4 100,21 40
GG 75 24% 22 20 5 92,14 59
AB 75 14% 18 10 3,5 69,47 52
AS 81 22% 24 14 2 84,3 54
EG 81 26% 27 20 3 101,97 46
AnB 53 26% 21 20 -2 112,47 57
CM 57 42% 17 20 6 103,13 60
Un exemple de fichier .csv (lisible par Excel et R, le séparateur est le point-virgule)
Ini;AGE;TED;L30;Htrr;MLD;Baddeley;PASAT
YD;63;10%;15;4;2;89,66;36
MR;66;18%;20;20;5,5;97,06;50
AR;69;2%;18;0;1,5;95,78;57
PL;69;4%;22;7;4;97,19;21
MC;70;22%;14;13;1;88,91;35
GC;70;6%;19;16;5;94,99;56
FV;72;32%;24;20;1,5;102,24;57
JB;72;28%;26;7;2;107,5;46
JC;72;26%;28;0;3,5;101,43;33
JL;73;4%;18;20;3,5;79,42;41
MD;74;10%;21;18;4;100,21;40
GG;75;24%;22;20;5;92,14;59
AB;75;14%;18;10;3,5;69,47;52
AS;81;22%;24;14;2;84,3;54
EG;81;26%;27;20;3;101,97;46
AnB;53;26%;21;20;-2;112,47;57
CM;57;42%;17;20;6;103,13;60
Dans la mesure où la plupart des ordinateurs disposent de tableurs comme Excel ou Open/Libre Office Calc (qui savent lire des fichiers Excel), il est fortement conseillé d'utiliser des fichiers .xls ou .xlsx mais attention : un fichier .xls est limité en termes de nombre de colonnes. Une bonne pratique consiste à créer un onglet nommé dictionnaire des variables où sont recensées -- et parfois détaillées -- les variables, avec leurs unités et leur codage.
Comme en France on utilise des virgules pour les nombres décimaux, le format des données doit plutot s'apparenter au format CSV2 qu'au format CSV, c'est-à-dire avec des points-virgules comme séparateur. De plus certaines versions de R ont des soucis de conversion automatique des accents et il faut parfois préciser le paramètre encoding dans la lecture de fichiers. Sachant qu'Excel distingue les valeurs, les formules et le texte affiché via des formats, il est en général prudent d'exporter les données dans un format CSV et de les regarder avec un éditeur de texte (comme Geany ou Notepad++) afin de voir ce que R va lire.
3. Présentation du logiciel R, installation et manipulations élémentaires
3.1 Présentation de R
Contrairement à Excel, R est un "vrai" logiciel statistique, avec toutes les fonctions élémentaires dont on a besoin en statistiques. Ainsi, Excel ne permet pas de tracer un boxplot ou graphique en boite à moustaches, alors que c'est un tracé élémentaire en statistiques. R fournit aussi des données réelles prêtes à l'emploi et des «examples» automatiques d'utilisation des fonctions afin de voir par l'exemple comment utiliser les fonctions sans avoir à saisir des données au clavier.
Si on veut profiter de toute la richesse des fonctions et de leurs options, il vaut mieux utiliser R en ligne de commande, au clavier ou par redirection.
Il existe aussi des interfaces avec des menus et des boutons. Le logiciel Rstudio et le package Rcmdr (on dit «R-commandeur») fournissent de telles interfaces, respectivement pour gérer l'environnement d'exécution de R et pour exécuter des analyses statistiques simples.
3.2 Installation de R et Rstudio
R et Rstudio sont des logiciels gratuits téléchargeables sur Internet, respectivement aux adresses cran.r-project.org et www.rstudio.com. Il sont disponibles pour tous les systèmes d'exploitation (Windows, Linux, MacOS). Les fichiers à télécharger (en 2016) font environ de 70 à 80 Mo, ce qui est un peu long à charger avec un wifi peu puissant. L'installation est en principe très simple : un double clic sur l'exécutable suffit en général pour installer le logiciel.
Si cela peut vous rassurer, une vidéo en français sur YouTube vous guide pas à pas : https://www.youtube.com/watch?v=DIV2ld666Jc.
3.3 Utilisation élémentaire de R
En ligne de commande, dans la console R ou celle de Rstudio, écrire x <- calcul puis appuyer sur la touche "Entrée" effectue le calcul et stocke le résultat dans la variable x. Les variables peuvent être des scalaires (une seule valeur), un vecteur (plusieurs valeurs de même type), une matrice (plusieurs vecteurs de même dimension et de même type), une liste (ensemble de diverses variables nommées), un cadre de données ou data frame (plusieurs vecteurs de même dimension et mais pouvant être de types différents).
Tout ce qui suit le symbole dièse (#) est un commentaire et est ignoré par R, ce qui est bien pratique pour expliquer les calculs et se relire.
De nombreuses fonctions s'appliquent tout autant à un scalaire qu'à un vecteur qu'à une matrice (via apply) et même à une liste (via lapply). On peut construire des vecteurs avec l'opérateur de séquence : (le symbole deux points) et la fonction collect qui s'écrit c(). Voici quelques exemples à copier/coller :
x <- 5.8
y <- 1:10
z <- y**1/2
print(x)
round(x)
round(z)
c( mean(z), sd(z) )
troisval <- c(1,12,24)
attention <- c(1,2,"a")
plot( y, z)
plot( y, z, pch=19, col="red", main="un essai" )
fausseQT <- c(0,0,1,0,1,0)
mean(fausseQT) # stupide !
vraieQL <- as.factor( fausseQT )
levels(vraieQL) <- c("oui","non")
mean( vraieQL ) # ah, quand même !
table( vraieQL ) # cela se nomme <<tri à plat>>
Pour apprendre R, il suffit donc de s'entraîner à utiliser les différentes commandes, comprendre comment fonctionne le système d'aide, lire les programmes des autres... Les liens fournis à la fin de notre page tuteur R devraient constituer un bon point de départ. Sous R, l'aide s'obtient avec la fonction help() qui affiche en ligne des explications, avec example() qui montre l'utilisation standard de la fonction, ainsi que help.start() et help.search() qui utilisent le navigateur web par défaut pour afficher l'aide :
> help(mean)
mean package:base R Documentation
Arithmetic Mean
Description:
Generic function for the (trimmed) arithmetic mean.
Usage:
mean(x, ...)
## Default S3 method:
mean(x, trim = 0, na.rm = FALSE, ...)
Arguments:
x: An R object. Currently there are methods for numeric/logical
vectors and date, date-time and time interval objects, and
for data frames all of whose columns have a method. Complex
vectors are allowed for 'trim = 0', only.
trim: the fraction (0 to 0.5) of observations to be trimmed from
each end of 'x' before the mean is computed. Values of trim
outside that range are taken as the nearest endpoint.
na.rm: a logical value indicating whether 'NA' values should be
stripped before the computation proceeds.
...: further arguments passed to or from other methods.
Value:
For a data frame, a named vector with the appropriate method being
applied column by column.
If 'trim' is zero (the default), the arithmetic mean of the values
in 'x' is computed, as a numeric or complex vector of length one.
If 'x' is not logical (coerced to numeric), numeric (including
integer) or complex, 'NA' is returned, with a warning.
If 'trim' is non-zero, a symmetrically trimmed mean is computed
with a fraction of 'trim' observations deleted from each end
before the mean is computed.
References:
Becker, R. A., Chambers, J. M. and Wilks, A. R. (1988) _The New S
Language_. Wadsworth & Brooks/Cole.
See Also:
'weighted.mean', 'mean.POSIXct', 'colMeans' for row and column
means.
Examples:
x <- c(0:10, 50)
xm <- mean(x)
c(xm, mean(x, trim = 0.10))
mean(USArrests, trim = 0.2)
> example(mean)
mean> x <- c(0:10, 50)
mean> xm <- mean(x)
mean> c(xm, mean(x, trim = 0.10))
[1] 8.75 5.50
mean> mean(USArrests, trim = 0.2)
Murder Assault UrbanPop Rape
7.42 167.60 66.20 20.16
Si on tape le début d'une fonction, la touche TABulation complète soit avec les noms de fonctions possibles, soit avec les paramètres si on a déjà écrit la parenthèse, comme ci-dessous :
> plotTOUCHE_TABULATION (sans parenthèse)
plot plot.design plot.mlm plot.spec.coherency plot.ts plot.xy
plot.default plot.ecdf plot.new plot.spec.phase plot.TukeyHSD
plot.density plot.lm plot.spec plot.stepfun plot.window
> plot(TOUCHE-TABULATION (juste après la parenthèse ouvrante qui suit le "t de plot)
...= cex.points= cook.levels= label.pos= mar.multi= range.bars= xval=
absVal= ci= data= labels= max.mfrow= separator= xy.labels=
add= ci.col= density= labels.id= mgp= set.pars= xy.lines=
add.smooth= ci.lty= dLeaf= leaflab= nc= sub= y=
angle= ci.type= do.points= legend.text= nodePar= sub.caption= yax.flip=
ann= col= edgePar= levels= oma= subset= yaxt=
ask= col.01line= edge.root= log= oma.multi= type= ylab=
asp= col.hor= formula= lty= panel= verbose= ylim=
axes= col.intervals= frame.plot= lty.intervals= panel.first= verticals= zero.line=
border= col.points= freq= lty.predicted= panel.last= which=
caption= col.predicted= grid= lty.separator= par.fit= x=
center= col.range= hang= lwd= pch= xaxt=
cex.caption= col.separator= horiz= main= plot.type= xlab=
cex.id= col.vert= id.n= main2= predicted.values= xlim=
cex.main= conf= intervals= mar= qqline= xpd=
3.4 Installation de Rcommander
Utiliser la ligne de commandes n'est pas toujours facile au début, car l'oubli d'une simple parenthèse ou d'un guillemet aboutit à une erreur. De plus pour taper des commandes, il faut déjà connaître le nom des fonctions à utiliser. Dans une optique d'initiation aux calculs statistiques, nous conseillons d'une part d'utiliser le logiciel Rstudio pour gérer l'environnement de R et nous conseillons surtout d'utiliser le package Rcmdr (on dit «R-commandeur») afin de profiter des menus d'analyse le temps d'être à l'aise avec les commandes.
Il y a fort à parier qu'après avoir pratiqué Rcmdr pendant quelque temps, l'utilisation de R en ligne de commandes s'imposera d'elle-même.
Pour installer le package Rcmdr via Rstudio, (cette installation se fait une fois pour toutes), il faut aller dans le panneau en bas à droite et cliquer sur l'onglet Packages puis sur le sous-onglet Install. Il ne reste plus ensuite qu'à taper Rcmdr dans la zone de saisie et valider via le bouton Install comme ci-dessous :
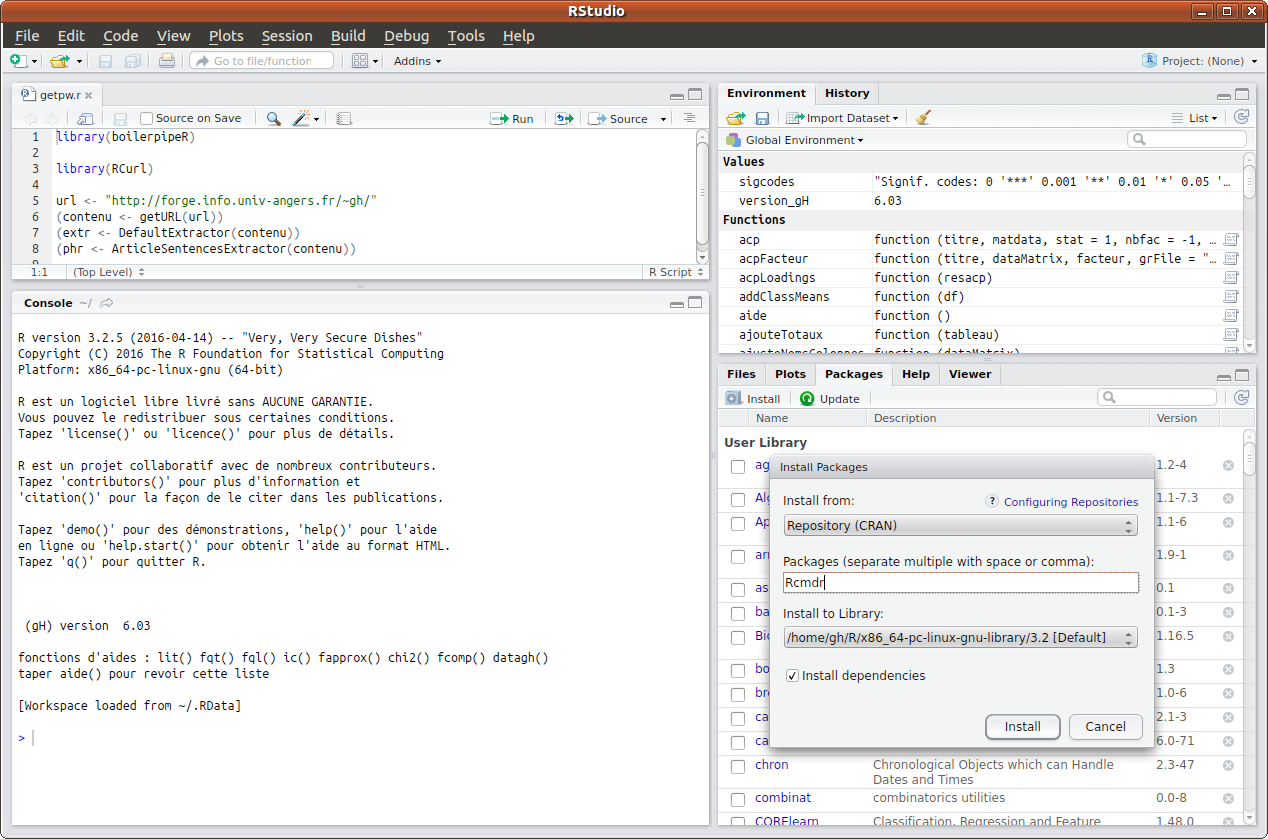
Pour installer le package Rcmdr, Il est également possible de taper directement dans la console la commande
install.packages("Rcmdr")
mais il se peut qu'il faille fournir des paramètres supplémentaires comme le chemin d'accès au site-miroir de R. C'est pourquoi passer par le panneau et le menu de Rstudio est une méthode plus simple et sans doute plus efficace. Le document installation_XP, même s'il date, explique en détail l'installation de R et Rcmdr pour Windows (copie locale).
Une fois le package Rcmdr installé, il faut le charger en mémoire lorsqu'on veut l'utiliser. Cette opération est à exécuter une et une seule fois par session. Pour cela, sous Rstudio, il suffit de cocher la case à gauche du nom du package dans le panneau inférieur droit, onglet Packages.
On peut aussi taper directement dans la console la commande
library("Rcmdr")
pour charger ce package Rcmdr.
Une fois le package Rcmdr chargé, on dispose d'un menu en principe en français et il suffit de cliquer sur les "bons" termes pour réaliser les analyses statistiques souhaitées.
Afin de se faire une idée des possibilités offertes par Rcmdr, on lira avec profit le PDF RCmdr21 (copie locale) et la page Web introRcmdr.
Remarque : il y a de fortes chances que le premier chargement de Rcmdr affiche un message comme
Le package XLConnect n'est pas installé. Voulez-vous l'installer ?
ou un panneau comme
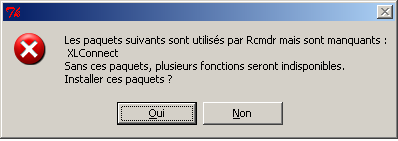
Il faut alors répondre OUI afin de pouvoir lire les fichiers Excel avec Rcmdr qui, vous l'avez compris, utilise le package XLConnect pour ces lectures. XLConnect utilise lui-même Java à travers le package rJava, mais vous n'avez bien sûr absolument pas besoin de connaitre Java, il doit simplement être installé.
4. Les points essentiels à retenir
-
Il ne faut pas confondre calculs statistiques et analyse statistique, car la rédaction est une partie importante de l'analyse.
-
Il faut distinguer statistiques descriptives et statistiques inférentielles ; ces dernières permettent de comparer les résultats, par exemple pour des sous-groupes, et de définir des modèles statistiques, notamment de régression.
-
On ne doit jamais commencer une analyse sans maitriser le type des données, la nature des unités pour les QT et le sens des codes des modalités pour les QL.
-
Il est sans doute utile d'avoir un exemplaire des données au format Excel et d'avoir consulté au moins une fois les données avant de commencer le moindre calcul. Les exporter au format CSV2 avant de lire avec R est "prudent".
-
R, à utiliser sous Rstudio, et Rcmdr sont complémentaires : Rcmdr est facile à utiliser via les menus, mais est incomplet ; R est plus fin mais plus difficile à utiliser à cause de la ligne de commandes.
exercices : énoncés solutions liens : lexique des fonctions vues retour au plan de cours
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)