![]()
![]()
Les dates de formation sont ici.
Enoncés pour la séance numéro 5 solutions
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Module de Biostatistiques,
partie 2
Ecole Doctorale Biologie Santé
gilles.hunault "at" univ-angers.fr
Les dates de formation sont ici.
Enoncés pour la séance numéro 5 solutions
Il existe plusieurs types de corrélation en statistiques : la corrélation de Pearson, de Kendall, de Spearman, mais aussi la corrélation de Lin, la corrélation intraclasse (au sens de Shrout and Fleiss). A quoi servent et comment calcule-t-on avec R les divers coefficients de corrélation correspondants ? Faut-il utiliser des packages spéciaux ? Comment n'afficher que les «meilleures» corrélations ?
Quelles corrélations peut-on calculer dans les données sommeil animal ? Comment trouver les «meilleures» corrélations ?
On pourra utiliser notre copie locale des données qui est légèrement aménagée.
Remarque : il ne faut pas hésiter à interroger le site R site search pour trouver des fonctions, des packages...
Au passage, est-il facile de construire une série de 10 points (x,y) pour lesquels la corrélation de Pearson est inférieure à 0,53 mais avec une corrélation de Spearman de 1 ?
Qu'est-ce que la colinéarité ? Et la multicolinéarité ? En quoi est-ce «dangereux» ?
Dans ce contexte, qu'est-ce que les coefficients VIF ? Est-il possible de les calculer si on réalise la régression linéaire multiple de la variable NIDS (ou LN_NID ?) en fonction de toutes les autres variables dans le dossier CHENILLES ?
Une fois calculés, comment interprète-t-on ces coefficients ?
Comment calculer et afficher au mieux une mdc (matrice des coefficients de corrélation linéaire) ?
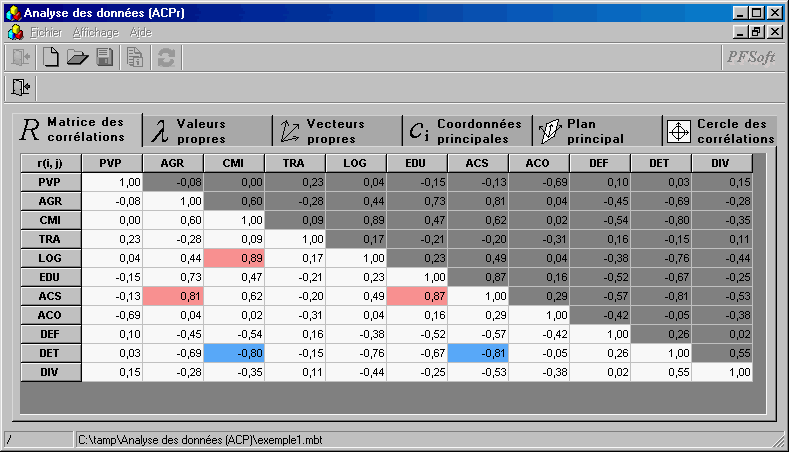
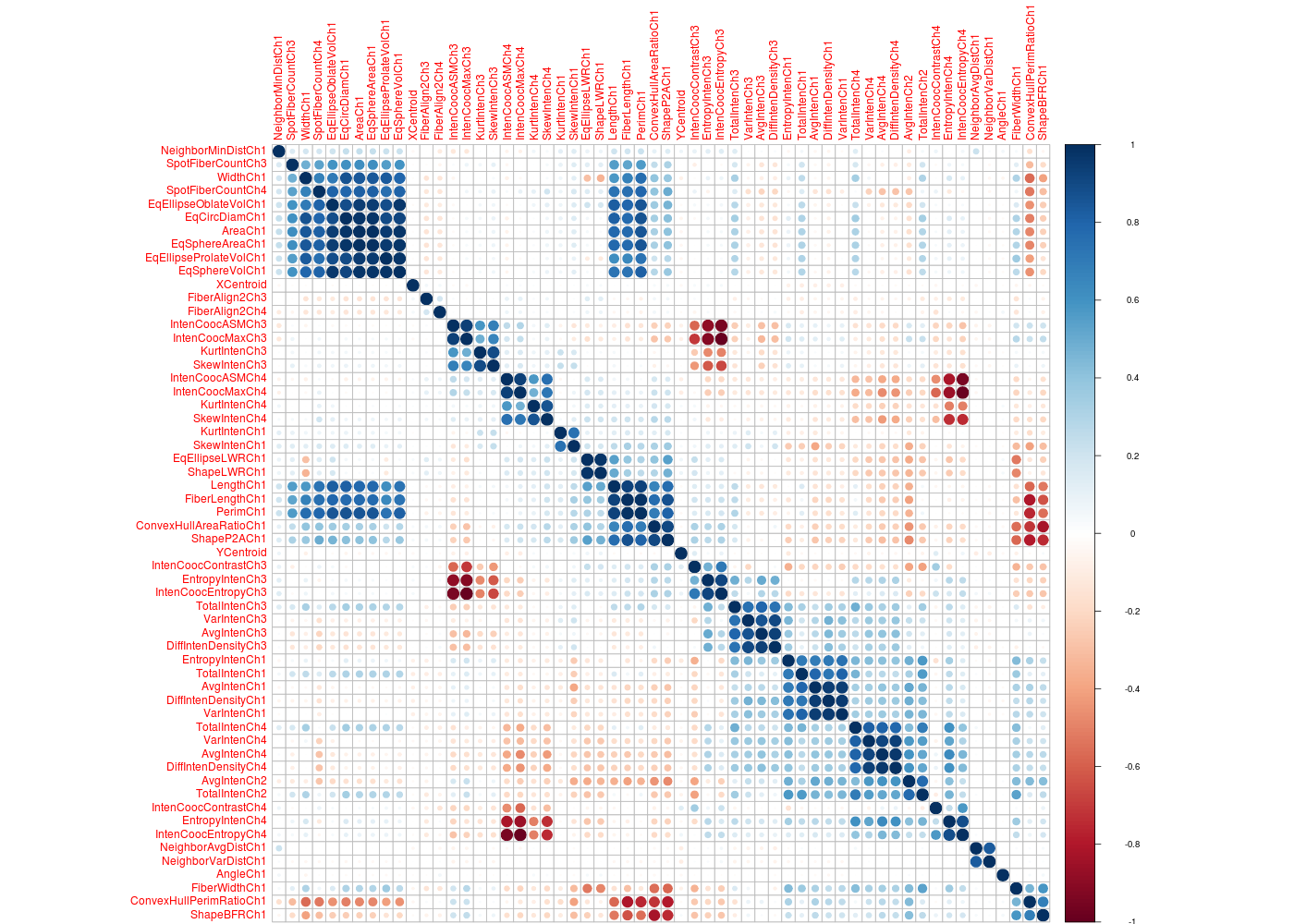
On utilisera les données sommeil animal qui est un exemple "facile" car "de petite taille", avant de traiter les données chenilles.txt puis les données hersdata.xls de l'ouvrage Regression Methods in Biostatistics et enfin les «grosses» données segmentationOriginal du package AppliedPredictiveModeling.
Comment faire pour supprimer des variables «trop» corrélées entre elles ? Lesquelles choisir ?
On utilisera les données sommeil animal pour définir et tester les stratégies à utiliser avant de passer aux jeux de données des applications suivantes.
Application 1 :
Essayer de réduire les variables des données LEA de façon à n'avoir aucune corrélation supérieure à 0,7.

Application 2 :
Essayer de réduire les variables des données hersdata.xls de l'ouvrage Regression Methods in Biostatistics de façon à n'avoir aucune corrélation supérieure à 0,7 si on doit faire une régression linéaire de la variable SBP en fonction de toutes les autres variables.
Application 3 :
Essayer de réduire les variables des données segmentationOriginal du package AppliedPredictiveModeling de façon à n'avoir aucune corrélation supérieure à 0,7 si on doit faire une régression logistique de la variable Class en fonction de toutes les autres variables.
On s'intéresse à la reproductibilité d'une mesure. Quelle corrélation faut-il utiliser ?
Application :
Dans le fichier reproduct.data, les données originales sont dans la colonne X, les données suivantes, censées reproduire X sont nommées Y1, Y2, Y3.
Quelle série Yi peut être considérée comme reproduisant X ?
Si on ajoute qu'il s'agit de valeurs de transaminase (ASAT) mesurée par automates dans différents laboratoires centralisés, que peut-on en conclure ?
Que contient l'ouvrage Applied Predictive Modeling de Kuhn et Johnson ?
