![]()
[petite] histoire des
(gH) gilles.hunault@univ-angers.fr
2. Même en informatique, il y a langage et langage
Un langage informatique se distingue d'une langue d'abord parce qu'il correspond à un besoin particulier de communication mettant en jeu un ou plusieurs ordinateurs ou se rattachant à un domaine informatique (comme les langages algorithmiques). Ce besoin peut être celui de piloter un ordinateur (langage de programmation), de décrire la composition d'un texte (langage Tex), la structuration des éléments du texte (langage XML), l'affichage du texte (langage HTML) ou son impression (langage Postscript), voire l'interrogation d'une base de données (langage SQL). De plus un langage informatique est en général écrit avec un alphabet spécialisé et, qui plus est, à l'aide d'un logiciel d'édition, que ce soit un éditeur simple, un traitement de textes général ou bien l'éditeur intégré à l'environnement de développement ("IDE" en anglais pour Integrated Development Environment).
Pour un langage informatique, les "mots" et "phrases" sont écrits via un clavier ou produits automatiquement par un ordinateur, ce qui en fait un langage "artificiel". L'alphabet sous-jacent, celui qui sert à composer ces mots et ces phrases est un alphabet différent de l'alphabet des langues disons "européenniques" à cause de certains symboles dit spéciaux comme le slash /, l'antislash \, les crochets droits [ et ] etc. qui le rend imprononçable sauf à séparer chaque symbole. De plus il n'utilise en principe que 26 lettres "standards", non accentuées, de A à Z. Pour que ces langages soient faciles à utiliser (par l'ordinateur) la syntaxe est souvent primaire, non ambigue et le sens est souvent contextuel avec des règles strictes d'interprétation du contexte.
Le codage des "phrases", composées de mots, eux-mêmes comportant des "caractères" suit aujourd'hui une norme internationale. Le codage ASCII (American Standard Code for Information Interchange) des caractères fut créé en 1964 et il fut normalisé en 1966 par l'ISO même si IBM a maintenu très longtemps sa norme propriétaire nommée EBCDIC (Extended Binary Coded Decimal Interchange Code) normalisée aussi dans les années 60. Avec 7 bits, le code ASCII définissait 128 caractères, ce qui était suffisant pour un alphabet américain (donc sans caractères accentués c'est à dire sans internationalisation). Avec 8 bits, ce code ASCII est passé à 256 caractères possibles, ce qui suffit pour les signes diacritiques d'une seule langue à la fois comme les divers a et e avec accents du français, le s-tset allemand, les lettres grecques, norvégiennes... Il est donc inadapté à un document multilangues.

Le système nommé Unicode est un système de codage des caractères écrits mis au point en 1991. Il permet de représenter n'importe quel caractère de n'importe quel pays par des codes sur 8, 16, 32... bits, indépendamment de tout système d'exploitation ou langage de programmation. Il regroupe ainsi la quasi-totalité des alphabets existants (arabe, arménien, cyrillique, grec, hébreu, latin, ...). De plus, il est compatible avec le code ASCII. En principe, c'est le système "d'aujourd'hui et de demain" prévu pour gérer toutes les langues à la fois.
Bien avant que les ordinateurs n'existent, les mathématicien[ne]s se sont intéressé[e]s aux langages dits "formels" pour les distinguer des langages dits "naturels" (sans doute à cause de l'absence de mots en anglais pour différencier langue et langage).
En mathématiques, la notion de langage formel se confond souvent avec celle de grammaire [formelle générative] : le langage est l'ensemble des mots qu'on peut construire à l'aide de régles de réécriture et de mots de départ nommés axiomes, la réécriture pouvant être séquentielle, parallèle... Ainsi la grammaire
Axiome : S Règles : 1. S -> () Règles : 2. S -> SS 3. S -> (S)définit les expressions correctement parenthésées, alors que la grammaire
Axiome : S Règles : 1. x -> A ou B ou C ou... Règles : 2. S -> x S x 3. S -> ^ (le caractère "vide")définit le langages des mots-miroir ou "palindromes" comme ICI, LAVAL...
Le "jeu" pour les mathématicien[ne]s est alors de savoir passer des mots aux grammaires, des grammaires aux mots, ce qui est parfois très compliqué.
Une ouverture au monde du graphisme se fait alors en donnant une interprétation géométrique aux lettres, comme par exemple G pour Gauche, H pour en Haut, B pour en Bas, A pour Avancer. On "voit" bien comment dessiner un rectangle de longueur 3 et de largeur 2 avec la phrase
H A A D A A A B A A G A A AVoici l'interprétation géométrique du début de la phrase sachant qu'on commence en bas à gauche avec la lettre H.
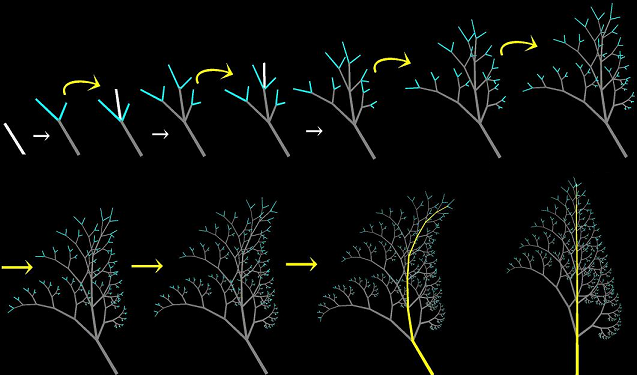
D A A A B A A A A H GOn peut aller encore plus loins avec ce qu'on nomme les langages L (ou plus précisément les systèmes L) dus à Aristid Lindenmayer qui permettent de tracer des arbres très réalistes comme

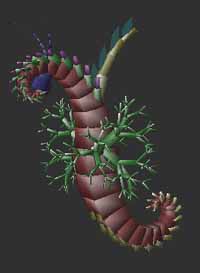

à l'aide de règles relativement simples et d'un programme (par exemple lsys ou lgrammar) pour appliquer ces règles. Avec un peu de programmation autour, on obtient ainsi des paysages assez réalistes, des jolies images :
Un langage informatique qui n'est pas un langage de programmation peut être un langage de mise en forme, que ce soit pour l'écran ou l'imprimante. Le langage HTML par exemple qui permet d'écrire les pages Web en est un représentant typique. Dans ce langage, on utilise des balises (ou "tags" ou marqueurs") d'où le nom HTML (Hyper Text Markup Language). Une balise, c'est par exemple <b>pour dire qu'on vu écrire en gras (bold, en anglais). On lui associe une balise fermante à savoir </b>.
Souvent on ne connait pas le "code" de la balise car il y plusieurs façons de la définir sans avoir à l'écrire explicitement : ce peut être à la souris, en sélectionnant le texte puis l'icone qui force le passage en gras comme avec Word, ce peut être à l'aide d'un menu, d'une "touche de fonction" ou d'une "touche-macro" comme "Controle-G". Le codage de l'action, repéré par la balise est unique. Il se code en interne différemment suivant le langage de mise en forme. Ainsi, comme indiqué précédemment, en HTML on utilise <b> pour indiquer le passage en gras, alors qu'en LATEX on dit \textbf{ et qu'en RTF on met {\bf. Pour terminer l'action, sans quoi le reste du texte est aussi en gras, comme cette partie de phrase il faut aussi un codage de fin d'action, à savoir respectivement </b> en HTML } en LATEX et } en RTF.
Si HTML décrit l'affichage, la mise en forme, il ne dit rien sur le contenu, la structure du texte. De plus il n'est prévu que pour l'écran : il n'y a aucune balise pour dire "passer à la page d'après" d'où parfois des textes pas très beaux quand on les imprime. Le texte suivant (qui est un extrait de page Web, d'où la faute d'orthographe)
Les Histoires extraordinaires de Poe fures traduites en français en 1848 par Baudelaire qui publia les Fleurs du Mal en 1857 et trois ans plus tard les Paradis artificiels.
correspond à l'interprétation du code HTML
Les <b><font color="#880000">Histoires extraordinaires</font></b> de <b><font color="#880000">Poe</font></b> furent traduites en français en 1848 par <b><font color="#880000">Baudelaire</font></b> qui publia <b><font color="#880000">les Fleurs du Mal</font></b> en 1857 et trois ans plus tard <b><font color="#880000">les Paradis artificiels </font></b>.
Ce code ne dit rien quant à qui est auteur, qui est oeuvre, qui est date. XML, quant à lui, permet d'écrire l'extrait de texte suivant :
Les <oeuvre>Histoires extraordinaires</oeuvre> de <auteur>Poe</auteur> furent traduites en français en <date>1848</date> par <auteur>Baudelaire</auteur> qui publia <oeuvre>les Fleurs du Mal</oeuvre> en <date>1857</date> et trois ans plus tard <oeuvre>les Paradis artificiels</oeuvre>.
Les balises XML définies pour ce document ne décrivent pas la forme mais le contenu. Ainsi le titre d'une oeuvre est contenu entre le début de balise <oeuvre> et la fin de balise </oeuvre> ; de même les balises <date> et <auteur> permettent de dresser une liste des auteurs et des dates.
XML permet de convertir les balises définies pour effectuer la mise en forme avec XSLT ; cela va plus loin que ce que vous pensez : si on peut naturellement convertir les balises en code HTML, il est également possible d'en faire des expressions rich text, acrobat, ou encore postscript. Un même document XML associé à des fichiers XSLT différents sera donc automatiquement converti en un document HTML, RTF, PDF ou PS. Voici un exemple de conversion pour passer en gras en HTML le nom de l'auteur : les mots template match indiquent quelle balise il faut détecter et le mot apply-template signifie qu'il faut mettre le contenu de la balise à cet endroit.
<xsl:template match="auteur"> <b> <xsl:apply-templates/> </b> </xsl:template>
XML est l'abbréviation de eXtensible Markup Language. C'est un sous-langage de SGML qui est beaucoup plus général mais aussi beaucoup plus complexe. XML ne sert pas à indiquer comment présenter le texte (en bleu, en gras, à droite, etc.) mais à décrire. Contrairement à HTML, il est eXtensible (doù le X de XML) ce qui signifie qu'il permet d'inventer ses propres balises et qu'elles peuvent donc tout décrire : les contenus, les protocoles, les transformations de balises en affichage, le codage de sécurité, le langage des nouvelles balises etc. Comme XML permet d'écrire les grammaires qui définissent les documents, XML est en fait un auto-méta-langage (sic) car il peut se définir lui même !
On trouve du XML partout en 2006
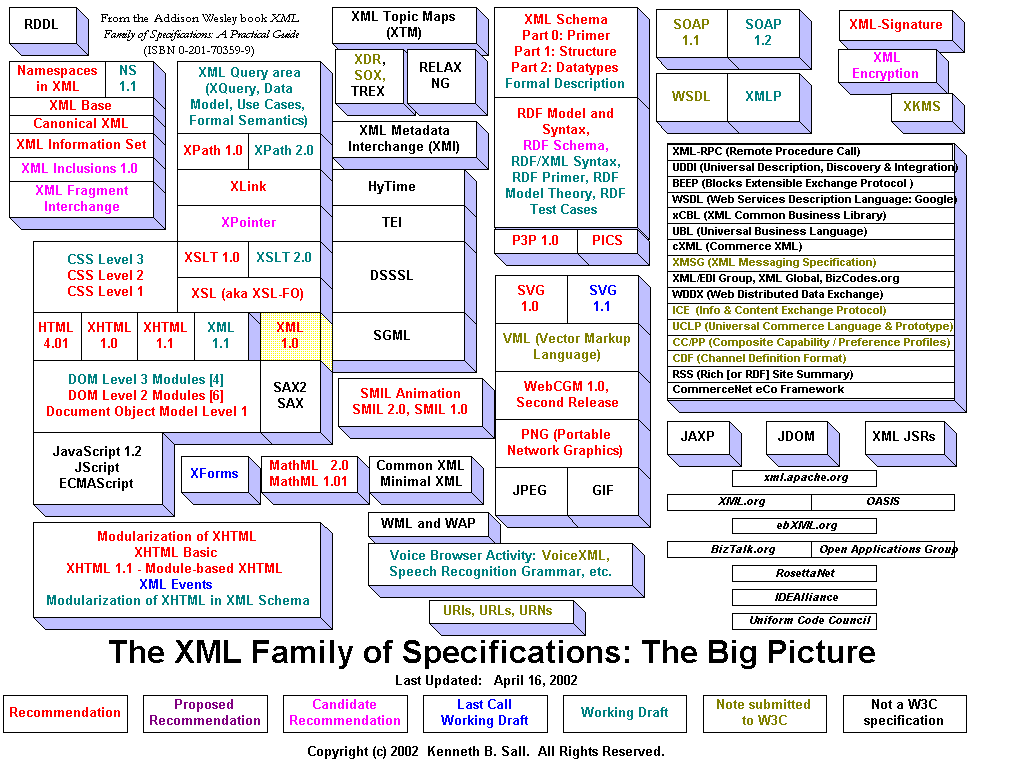
- dans le graphisme 2D avec SVG - dans le multimedia avec SMIL - en chimie avec avec CML - en biologie avec BSML - en mathématiques avec MathML Pour ceux et celles qui en auraient le courage, l'image ci-dessous est cliquable et chaque rectangle renvoie à un domaine fondamental de XML :
Le langage Tex (prononcé "tèque") et ses variantes comme Latex permet de faire du traitement de textes, comme Word mais en qualité imprimerie. Il utilise des commandes, généralement repérées par des antislash. Ces commandes servent à dire ce qu'on veut et non pas comment le faire. Ainsi \newsection indique qu'on veut une nouvelle section. Latex viendra automatiquement incrémenter le numéro de section, voire passer à la page suivante s'il estime que ce n'est pas beau... (en principe en Tex, on n'a pas à dire quand il faut changer de page et forcer la machine à passer la page suivante est considérée comme une "faute pénalisante"). Latex est beaucoup plus général que Word (et en cela il ne s'y oppose pas). La commande \input permet d'inclure un fichier juste au moment de produire le document final ; ce fichier peut être produit au dernier moment par exemple par un programme serveur informatique, ce qui autorise un document à être "dynamique". Latex permet d'inclure des règles ou d'inhiber des règles par des commandes, comme les règles de ponctuation. Ainsi les français écrivent xxx ; avec un espace avant et après le point-virgule (comme pour tous les symboles doubles de ponctuation) alors que les anglais et les américains écrivent xxx; en collant le point virgule. Seul un langage évolué comme [La]tex permet d'appliquer finement ces règles (de peur de se voir refuser un article, ou d'être considéré comme ne sachant pas "bien" écrire...). Tex est aussi un spécialiste de la typographie et des mathématiques :
Les polices de caractères sont gérées sous Tex/latex en fonction du document selon des règles beaucoup plus évoluées qu'avec Word : ainsi le passage de l'écriture italique à l'écriture droite est automatiquement géré pour éviter que certaines lettres (dont le "f") ne "débordent" :
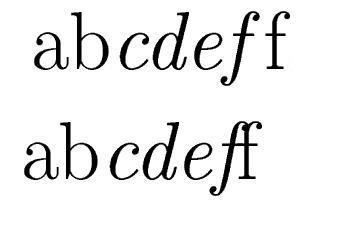
Tex/Latex gère bien évidemment les tables de matières, les index, la recomposition automatique des indices et des exposants en fonction de la taille de base des caractères pour le document...
Certains langages comme SQL ne sont pas considérés comme des langages de programmation par tout le monde car ils sont plus «déclaratifs» qu'«impératifs». Les instructions
USE mesVentes ; CREATE TABLE fournisseurs ( code INT, nom CHAR ) ;créent une "table" fournisseurs dans la "base de données" mesVentes sans que l'on sache où est la table, ni la base ni comment elle est codée en interne. La ligne
INSERT INTO fournisseurs VALUES (10,"peper","Et mémère en bateau",12) ; INSERT INTO fournisseurs VALUES (1,"Jean","AYMAR",12) ;rajoute des données dans la base. On ne sait toujours pas si le code est la colonne 1 de la table ou si c'est la colonne 2, ce qui est normal car la notion de numéro de colonne est inutile pour une base de données relationnelle (l'absence de "S" se justifie par le fait que c'est la base qui est relationnelle). Pour afficher les noms suivis des codes on écrit
SELECT nom, code FROM fournisseur ;alors que pour afficher les codes suivis des noms on écrit
SELECT code, nom FROM fournisseur ;Une requête ("query" en anglais, d'où le Q dans SQL) peut être très compliquée comme :
SELECT LEFT(CONCAT(nom,"................."),24), AVG(qt*15.0) AS moyQt FROM decode,tuteur WHERE user=usr GROUP BY user ORDER by moyQt ;Cette requête utilise deux tables : la table tuteur et la table decode, elle calcule la moyenne par utilisateur des commandes multipliées par 15 (le prix unitaire), l'affichage étant trié par ordre croissant de moyenne, soit un affichage comme
Bill Vesée............ 55.00000 Gérard Manvussa......... 75.00000 Hubert Hubert........... 75.00000 Andrée Tarkowsky........ 90.00000si les tables contiennent par exemple
Table decode | Table tuteur ------------- | ------------- | usr nom | qt user AA Andrée Tarkowsky | 1 BV GG Gérard Manvussa | 2 GG BV Bill Vesée | 3 HU HU Hubert Hubert | 4 BV | 5 BV | 3 AA | 5 BV | 8 GG | 7 HU | 2 BV | 5 BV | 9 AA
Suite de l'exposé : les langages de programmation.
Retour à la page principale de (gH)