![]()
![]()
|
Projet de programmation en Licence informatique(année 2015/2016)
Recherche optimisée de palindromesdans des séquences protéiques et nucléotidiques
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Projet de programmation en Licence informatique
(année 2015/2016)
Recherche optimisée de palindromes
dans des séquences protéiques et nucléotidiques
Présentation du projet
Les biologistes utilisent des séquences d'acides aminés stockées dans des fichiers-texte au format Fasta pour décrire les protéines. Ces séquences de molécules peuvent être vues de façon très grossière comme des chaines de caractères, chaque molécule étant représentée par sa lettre dans la nomenclature IUPAC.
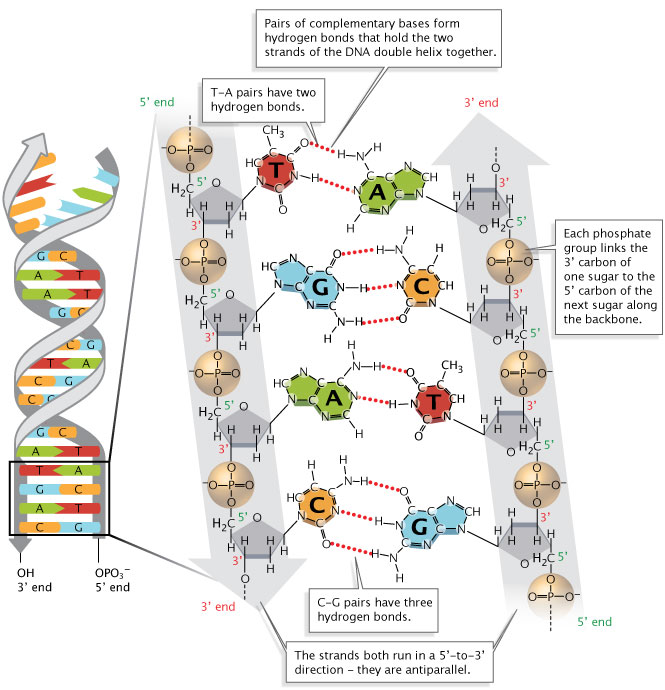
Les biologistes utilisent également des séquences d'ADN, stockées aussi informatiquement sous forme de chaines de caractères au format FASTA à l'aide des 4 lettres A, T, G et C.
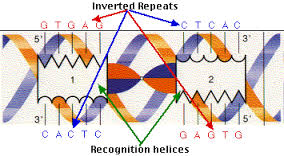
Un palindrome non constant est une chaine de caractères qui peut se lire de la droite vers la gauche ou de la gauche vers la droite, comme ici ou laval.
Il serait intéressant de détecter de tels palindromes et de disposer, pour des séquences des protéines ou d'ADN, d'indications de présence et de position des palindromes, soit individuels soit communs à une classe de protéines. On ne s'intéresse pas ici aux palindromes de 2, 3, 4... lettres mais aux plus grands palindromes présents dans les séquences.
Détails du projet
On viendra écrire en PHP un programme qui s'exécute en ligne de commandes pour effectuer ce type de recherche. Il y aura sans doute deux paramètres : le nom du fichier contenant les séquences Fasta, une indication du mode (global, par classe, individuel). Les résultats seront renvoyés dans un fichier-texte au format CSV. On veillera à ce que le programme s'exécute rapidement. On pourra par exemple s'amuser à déterminer théoriquement la complexité ou le nombre de sous-chaines de caractères à explorer avec une version naive de recherche de palindrome.
Il n'est pas sans doute pas indispensable de construire des classes d'objets PHP pour réaliser le projet. On respectera le style de codage de G. HUNAULT pour la syntaxe des fonctions PHP (voir par exemple http://www.info.univ-angers.fr/~gh/internet/stdphp.php) et on essaiera de fournir des indications sur le profil d'exécution (temps passé dans chaque étape, chaque fonction importante).
Exemples de Données
Deux chercheurs de l'université d'Angers, E. Jaspard et G. Hunault ont créé et maintiennent deux bases de données de protéines, nommées LEAPdb et sHSPdb. Pour accéder aux données à traiter dans ces bases, il suffit de cliquer sur le bouton export des pages Export des deux bases de données. Un identifiant comme A2XG55_cl_6 indique qu'il s'agit de la protéine A2XG55 et qu'elle est en classe 6. On pourra admettre que la classe 0 (qui n'existe pas) correspond à l'ensemble de toutes les protéines de la base de données -- ce qui simplifiera l'appel du programme en ligne de commandes.
Le fichier 2015_xmp1.txt contient une seule chaine (protéine). Le fichier 2015_xmp2.fasta contient une ensemble de chaines "homogènes" (protéines) pour lesquelles il faut trouver des palindromes communs. Le fichier 2015_xmp3.zip contient une ensemble de chaines "homogènes" (ADN) pour lesquelles il faut trouver des palindromes communs.
On trouvera sur la page 1055genomes.php des fichiers qui contiennent des séquences d'ADN bactériens et qui peuvent aussi servir de jeux d'essais (mais plus difficiles à manipuler).
Attention : ce projet demande de fortes compétences en algorithmique.