![]()
![]()
Cours CMI / L2 - séance 3
Résumé de la séance 3
1. But des bases et des sites
2. Mise en ligne de versions stables
|
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Cours CMI / L2 - séance 3
Résumé de la séance 3
Concevoir une base de données ne se fait pas en quelques minutes. Après avoir fixé les objectifs à atteindre via les deux bases de données LEAPdb et sHSPdb, nous retracerons en parallèle la construction de l'interface Web et le remplissage de la base de données ainsi que l'évolution et la mise à jour du site et des tables.
1. But des bases et des sites
1.1 Pourquoi créer les bases LEAPdb et sHSPdb ?
Les protéines LEA et sHSP font l'objet de thèmes de recherche développés au sein de l'équipe angevine de recherche nommée MITOSTRESS. Ces protéines sont impliquées dans la réponse à différents stress biotiques et abiotiques. Il existe plusieurs milliers de protéines LEA et de protéines sHSP, ce qui constitue dans les deux cas, ce que l'on appelle une famille de protéines. Une base de données spécialisée est le meilleur outil pour regrouper, classer, analyser et comparer l'ensemble des informations et des propriétés d'une famille de protéines. Les bases de données généralistes du NCBI regroupent l'ensemble des fichiers d'informations (notamment la séquence en acides aminés) des protéines LEA et sHSP. Nous avons créé les bases LEAPdb et sHSPdb qui contiennent des données curées et des outils d'affichage, d'analyse et de calcul adaptés aux besoins d'une partie de la communauté scientifique.
1.2 Pourquoi créer des sites LEAPdb et sHSPdb ?
Une base de données sans utilisateur n'est pas très utile car elle ne sert qu'à son créateur. De même une base de données sans interface n'est pas utilisable car il faut connaitre MySQL et le nom des champs et leur signification pour pourvoir interroger la base. De plus certains champs font référence à des informations situées sur d'autres sites, comme par exemple le code PFAM.
Il est donc "raisonnable" de fournir un site Web pour explorer la base de données. Et comme certaines opérations -- disons un blast local -- ne sont pas toujours simples à implémenter, il vaut mieux disposer d'un site qui met tout cela en oeuvre pour que l'utilisateur n'ait qu'à cliquer pour trouver ce dont il a besoin dans la base.
Enfin, MySQL ne produit pas de graphiques et ne sait pas réaliser des calculs statistiques. Nos sites Web fournissent de telles fonctionnalités.
1.3 Premières versions de démonstration
C'est avec ces idées que nous avons créé une première base, LEAPdb, en 2007, à l'aide d'un stagiaire. Après avoir décidé ce que nous voulions afficher (les séquences, les propriétés physico-chimiques), il a fallu implémenter un système de menus pour l'utilisateur.
Comme une base de données ne saurait vivre sans mise à jour, il a fallu trouver un moyen d'alimenter la base avec de nouvelles protéines et fournir aux administrateurs biologistes le moyen de gérer les tables sans passer par du code MySQL explicite. Cela a débouché sur une partie "Admin" avec des menus réservés à des utilisateurs particuliers.

Fort de l'expérience de LEAPdb, il a été décidé en 2012 de créer une seconde base, sHSPdb.

1.4 Différences entres les protéines de LEAPdb et de sHSPdb
La principale différence est que la plupart des protéines sHSP ont un domaine ACD, ce qui oblige à rajouter des champs dans la table proteins et à modifier l'affichage en mode Browse pour les informations Summary et Details.
2. Mise en ligne de versions stables
2.1 L'interface utilisateur
Cette interface, décrite succinctement dans l'article de BMC Genomics est complétée, pour sHSPdb d'un "guided tour" (visible guidée) accessible ici. En partie gauche, les options comme Home, Browse... sont les actions générales à exécuter et, sous les icones de validation, la possibilité pour l'administrateur de se connecter. Les actions générales correspondent à un mode d'utilisation du site (mode analyse, mode affichage...).


Chaque action a son propre menu, voire ses sous-menus, comme Search ou Blast...
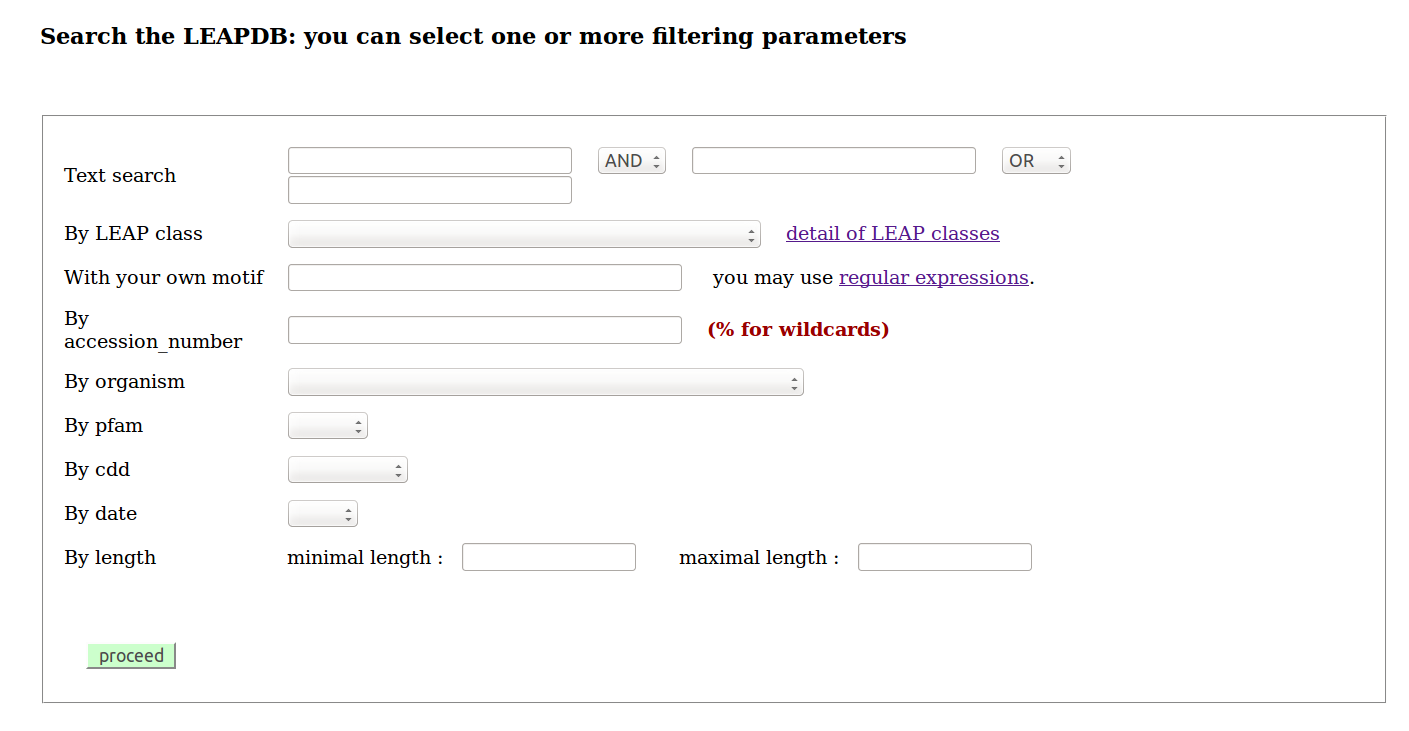
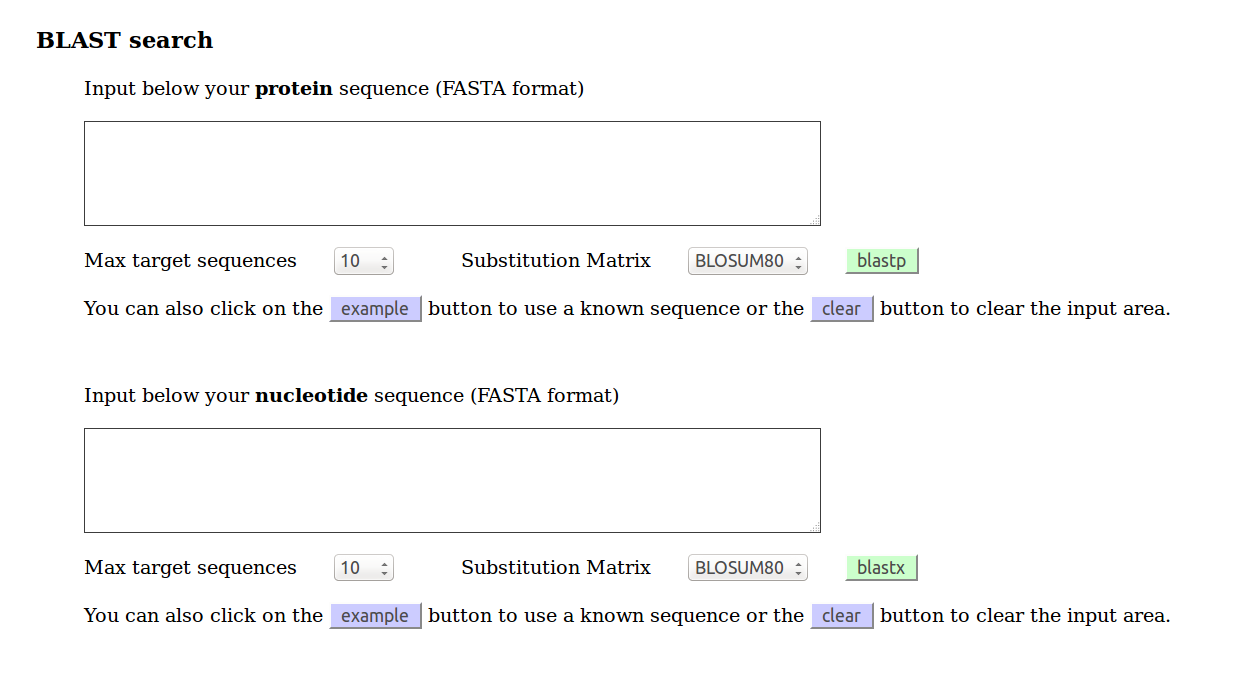
Il faut bien sûr du temps pour se familiariser avec cette interface, dont les nombreux menus sont riches de possibilités. La démonstration en sera faite en TP avec des manipulations pour chaque menu et sous-menu.
2.2 L'interface administrateur
Cette interface, réservée aux développeurs du site et aux gestionnaires des données a elle aussi de nombreuses options que, pour des raisons de confidentialité, nous ne détaillerons pas.

2.3 Export des données
Afin que les utilisateurs puissent utiliser les données sélectionnée dans la base, il y a une option Export :
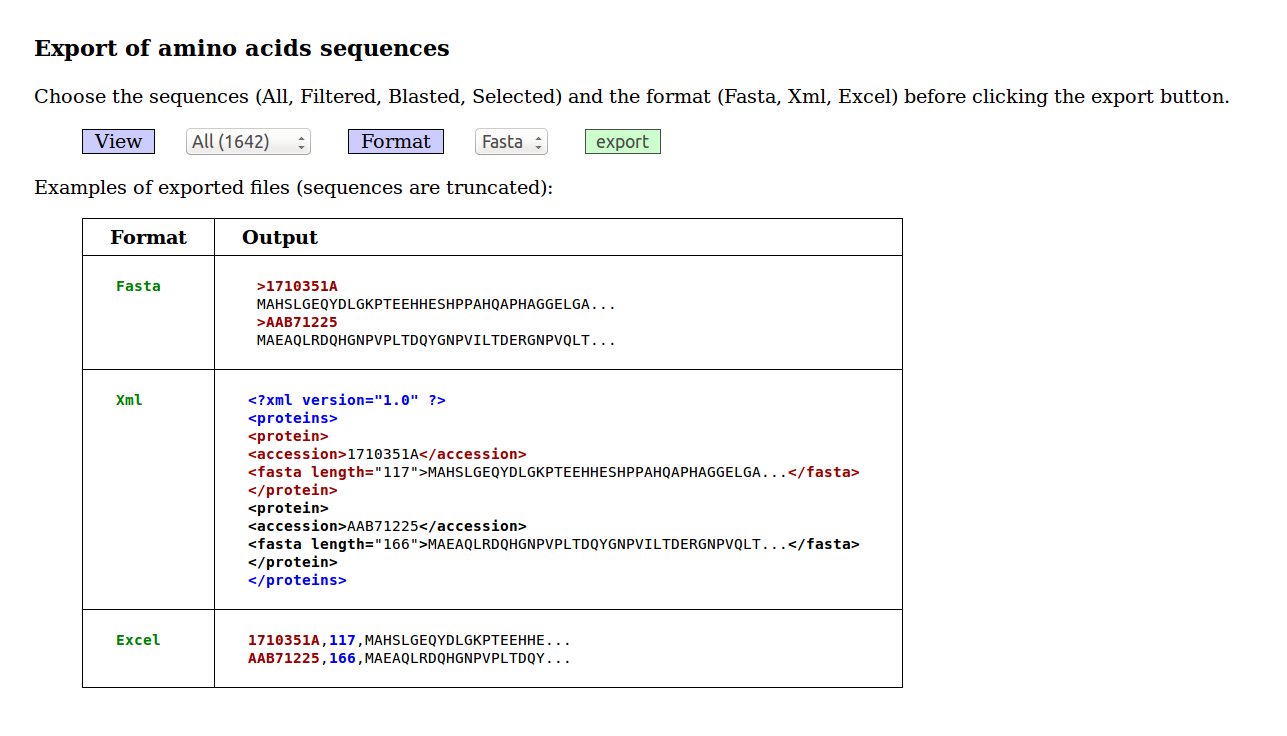
Mais les administrateurs disposent d'options d'export supplémentaires :
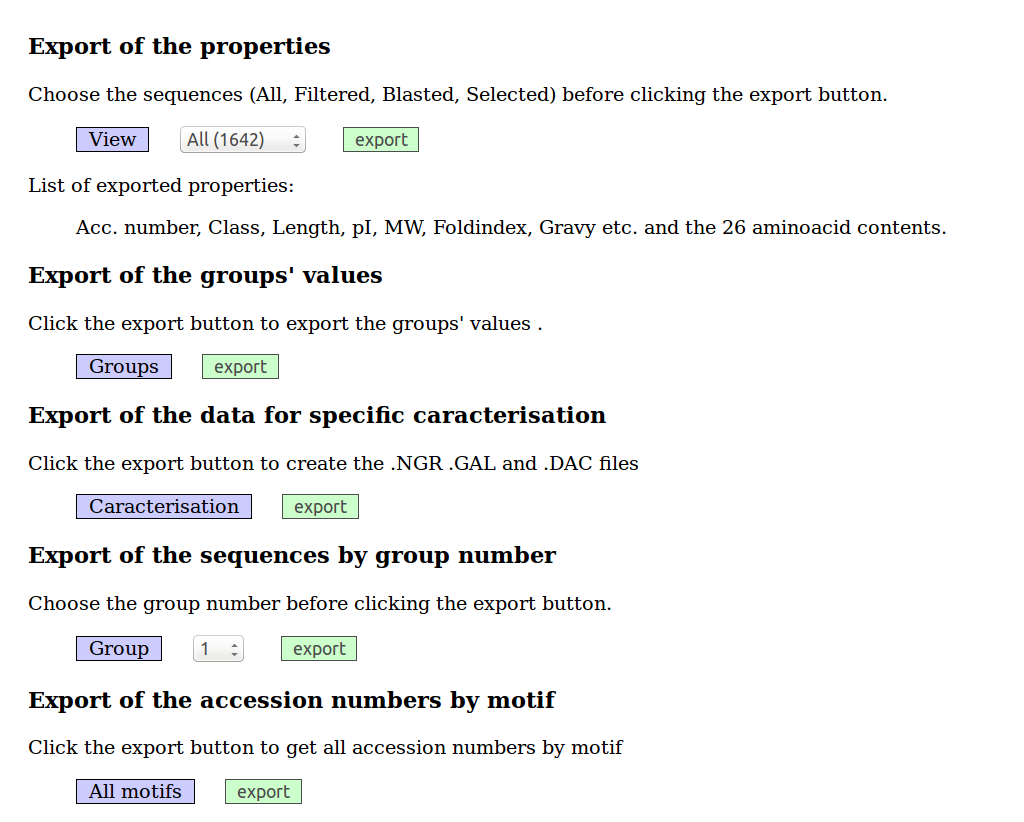
Il est également possible, pour tous les utilisateurs, de produire un fichier Fasta des séquences éventuellement filtrées ou sélectionnées en cliquant sur le champ Fasta dans la liste de sélection Information du mode Browse.
3. Mise à jour des tables et des sites
Les tables sont mises à jour pour tout nouvel ajout de protéines (ajout découlant de la veille technologique). Plus récemment (debut mars 2016), les bases ont été enrichies de deux nouvelles tables, rank et taxonomy afin de mieux prendre en compte la taxonomie.
L'interface initiale a été très fortement enrichie. Ainsi, depuis la création en 2007, les actions globales Blast, Statistical analysis, Submit ont été ajoutées. De même, certains sous-menus ont été dotés de fonctionnalités supplémentaires, comme par exemple Fasta ou Align sequences du mode Browse, les comparaisons par classe de combinaison d'acides aminés...
Certaines actions sont expérimentales et non disponibles pour le public, comme Predict, d'autres sont en cours de mise au point, comme Taxonomy (mars 2016) pour une intégration prévue au printemps 2016... Là encore, des manipulations ou des démonstrations en ligne sur la nouvelle version du site en beta test sont prévues dans le cadre des TP.
4. Connaissance des tables
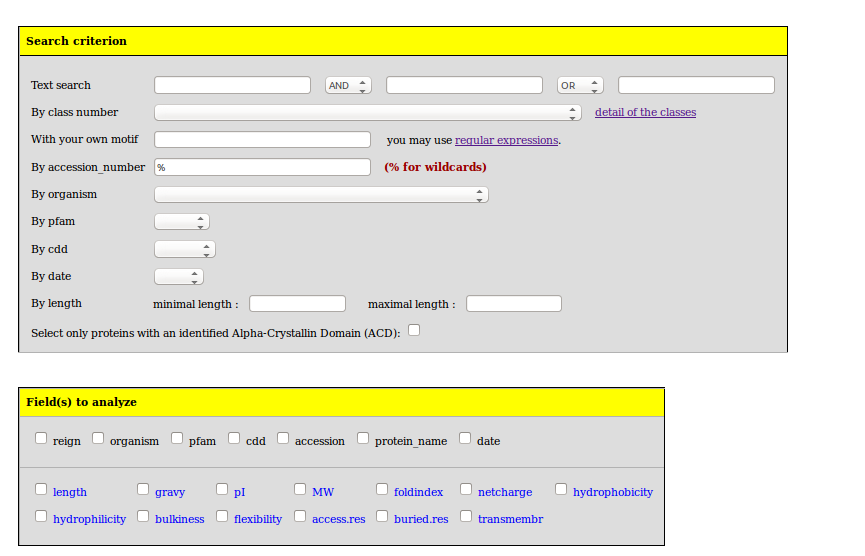
Afin de vérifier si vous maitrisez l'interface des tables, voici quelques questions dédiées aux bases LEAPdb et sHSPdb dont les réponses tiennent en quelques clics et saisie, sachant qu'aucune justification biologique n'est demandée.
Question 4.1
Combien y a-t-il de protéines dans la classe 1 de la base LEA ? Et dans la classe 2 de la base sHSP ?
Question 4.2
Combien y a-t-il de protéines dans LEA liées à Mus musculus ? Et dans la base sHSP ?
Question 4.3
Combien y a-t-il de protéines dans LEA de 500 acides aminés ou plus ? Et dans la base sHSP ?
Question 4.4
Quelle est la plus petite valeur de pI dans la classe 1 de la base LEA ? Et dans la base sHSP ?
Question 4.5
Est-ce que la classe 4 de la base LEA est comparable à la classe 4 de la base sHSP ?
Question 4.6
Comment comparer au niveau des classes dans la base sHSP les valeurs de Fraction amide residues ?
Question 4.7
Quelles protéines de la base LEA ressemblent le plus à la séquence ci-dessous ?
ASHDQSFKAGEAKGQTQEKTNQMMRNIGDKAQSAKDKTAQTAQAAKDKTQQAAQAAKERTTGDNVKSTQSolutions : afficher les solutions
Réponse à la question 4.1
Il y a 253 protéines dans la classe 1 de la base LEA, ce qu'on trouve via Search à l'aide du menu déroulant By LEAP class. De même, il y a 115 protéines dans la classe 2 de la base sHSP via Search et By class number.
Réponse à la question 4.2
Aucune protéine pour Mus musculus dans la base LEA, ce qui est sans doute assez attendu et 120 dans la base sHSP. Utiliser Search avec Text search.
Réponse à la question 4.3
Là, c'est l'inverse : aucune protéine pour sHSP de 500 aminés ou plus (ce qui est sans doute assez attendu aussi ) et 23 dans la base LEA. Utiliser Search avec By length.
Réponse à la question 4.4
La plus petite valeur de pI pour la classe 1 de la base LEA est 3,47. Utiliser Search, sélectionner la classe 1, afficher 250 protéines par classe, choisir comme information Physico-chemical properties puis cliquer sur pI pour forcer le tri. Il ne faut pas passer par Statistical analysis puisque les données analysées n'y sont pas à jour.
Pour sHSP il y a plus simple car il y a un mode Analyze. Si on sélectionne la classe 1 et si on coche la propriété pI alors la page Web des résultats donne -0,013 comme minimum.
Réponse à la question 4.5
Il n'y a aucun rapport entre la classe 4 de la base LEA et la classe 4 de la base sHSP à part le numéro de classe.
Réponse à la question 4.6
Pour comparer au niveau des classes dans la base sHSP les valeurs de Fraction amide residues, on peut utiliser le mode Statistical analysis avec le dernier panneau Class comparison: parce que Fraction amide residues correspond à N+Q. Ce qu'on obtient -- l'ANOVA paramétrique et l'ANOVA non paramétrique -- est en dehors du champ de compétences biologiques ou informatiques et relève des statistiques.
Réponse à la question 4.7
A l'aide du mode BLAST, si on coupe/colle la séquence proposée dans le panneau de saisie du formulaire, on trouve que la seule protéine très ressemblante est ADQ91836 qui est en classe 6. Voici l'extrait des résultats de ce BLAST local qui le montre :
> ADQ91836 Length = 71 Score = 136 bits (307), Expect = 2e-42, Method: Compositional matrix adjust. Identities = 69/69 (100%), Positives = 69/69 (100%) Query: 1 ASHDQSFKAGEAKGQTQEKTNQMMRNIGDKAQSAKDKTAQTAQAAKDKTQQAAQAAKERT 60 ASHDQSFKAGEAKGQTQEKTNQMMRNIGDKAQSAKDKTAQTAQAAKDKTQQAAQAAKERT Sbjct: 2 ASHDQSFKAGEAKGQTQEKTNQMMRNIGDKAQSAKDKTAQTAQAAKDKTQQAAQAAKERT 61 Query: 61 TGDNVKSTQ 69 TGDNVKSTQ Sbjct: 62 TGDNVKSTQ 70
Cliquer ici pour revenir à la page de départ des cours CMI / L2.