![]()
![]()
Cours CMI / L2 - séance 2
Résumé de la séance 2
1. Requêtes MySQL
2. La commande SELECT
3. MySQL par la pratique
Cliquer ici pour revenir à la page de départ des cours CMI / L2. |
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)


Cours CMI / L2 - séance 2
Résumé de la séance 2
Si la partie conception d'une base de données et de ses tables est une étape primordiale et parfois difficile ou délicate, savoir exécuter des requêtes pour consulter ces tables est une autre étape cruciale. Nous essaierons dans cette séance de nous entrainer à exploiter au mieux les commandes MySQL prévues à cet effet, dont la fameuse commande SELECT. On pourra consulter notre page base de données pour les aspects conceptuels des bases de données.
1. Requêtes MySQL
Il a plusieurs catégories de requêtes MySQL : celles qui permettent de créer, celles qui permettent de remplir, celles qui permettent de mettre à jour, celles qui permettent d'interroger...
Après avoir lu notre tuteur MySQL, on pourra consulter par exemple le wiki book MySQL ou la carte de référence MySQL (copie locale) pour avoir une bonne compréhension de l'ensemble des commandes MySQL, sachant que le site officiel pour la documentation se nomme http://dev.mysql.com/.
Comme indiqué sur la page française du Wiki pour MySQL, la version Open Source de MySQL se nomme désormais MariaDB.


2. La commande SELECT
La principale commande à savoir utiliser en SQL est SELECT dont le détail de la syntaxe est ici pour MySQL et que nous reproduisons ci-dessous :
SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [MAX_STATEMENT_TIME = N] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr ...] [FROM table_references [PARTITION partition_list] [WHERE where_condition] [GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] [ORDER BY {col_name | expr | position} [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}] [PROCEDURE procedure_name(argument_list)] [INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name]] [FOR UPDATE | LOCK IN SHARE MODE]]Comme indiqué sur la page française du Wiki pour SQL SELECT, la pratique courante de SELECT utilise -- et dans cet ordre -- les options F, W, GB, H, OB, L, à savoir FROM, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT. Comme indiqué au bas de la page anglaise du Wiki pour SQL SELECT, chaque implémentation de SQL a sa propre syntaxe étendue.
Le but de la commande SELECT est de fournir des valeurs de champs (SEXE, AGE...) ou des calculs sur champs (POUCES* 2.54, MIN(PRIX)... à partir d'enregistrements dans des tables (FROM) éventuellement filtrés par des conditions (WHERE), à l'aide d'options de regroupement (GROUP BY), groupes eux-aussi éventuellement sélectionnés (HAVING), et dont l'affichage peut être trié (ORDER BY). Enfin, au lieu d'afficher tous les résultats, on peut demander seulement l'affichage des lignes tant à tant (LIMIT).
SELECT peut aussi être une option de la commande INSERT, ce qui permet de remplir une table à partir d'autres tables.
Si les commandes SELECT pour des interrogations usuelles sur une table sont assez faciles à maitriser, de même que les interrogations pour plusieurs tables lorsqu'on croise des informations présentes, les options de "JOINTURE" pour trouver ce qui n'est pas présent demandent nettement plus d'expérience, ne serait-ce que parce que les jointures peuvent être effectuées sur les tables de gauche ou sur les tables de droite, ce qui n'aboutit pas forcément aux mêmes résultats. Par exemple avec une table de clients et une table de commandes, dans un cas on pourra trouver les clients qui n'ont pas commandé et dans l'autre, les commandes sans client courant (en supposant un filtrage par date notamment...).
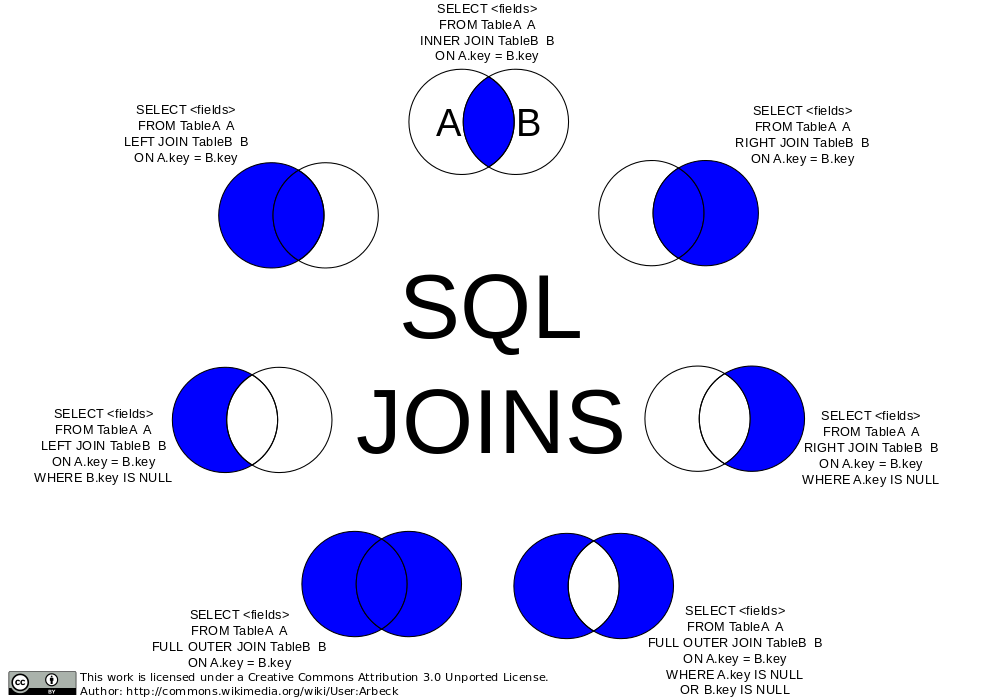
Sur le site de sqlpro, via l'URL sqlaz/select on trouvera une longue page en français sur cette fameuse commande SELECT. Pour comprendre les jointures en SQL, nous vous conseillons de lire dans cet ordre jointures 1 puis jointures 2.
3. MySQL par la pratique
Pour celles et ceux qui ont réussi à faire tous les exercices de notre tuteur MySQL, voici quelques questions dédiées aux bases LEAPdb et sHSPdb :
Rappel : la connexion MySQL se fait en local à la faculté des sciences d'Angers (dans un terminal sur forge) par
mysql --host=localhost --user=anonymous --password=anonymousVous pouvez tester vos réponses dans votre navigateur Web préféré via la page execute Mysql .
Question 3.1
Combien y a-t-il de tables dans la base LEA ?
Question 3.2
Quels sont les champs de la table proteins dans la base LEA et à quoi servent-ils ?
Question 3.3
Combien y a-t-il de protéines en tout dans la base LEA ? Et dans la classe 1 ? Et dans chaque classe ?
Question 3.4
Dans quelle(s) classe(s) se situent les cinq plus grandes séquences Fasta ? Et les cinq plus petites ? Et si on se restreint aux treize premières classes ?
Question 3.5
Quelle est la moyenne de l'indice de repliement pour chacune des classes 1 à 12 dans la base LEA ? Est-ce "raisonnable" ?
Question 3.6
Quel est le motif lié à chaque classe dans la base LEA ? Comment les motifs ont-ils été construits ?

Source : Li & He (2009)
Question 3.7
Quelle est la moyenne de l'indice de repliement pour chacune des classes 1 à 23 dans la base HSP ? Est-ce "raisonnable" ? Et est-ce très différent des moyennes pour la base LEA ?
Question 3.8
Est-ce que toutes les protéines des 24 premières classes des la base HSP ont un domaine ACD ? Est-ce "normal" ?
Question 3.9
Peut-on facilement afficher la taxonomie complète d'une protéine dans les bases LEA et HSP ?
Question 3.10
Y a-t-il une différence significative au niveau de longueurs pour les protéines des 24 premières classes de la base HSP ?
Question 3.11
Dans quelle mesure peut-on considérer que la plupart de ces résultats sont inexacts (et non pas faux) ?
Solutions : afficher les solutions
Réponse à la question 3.1
Il y a 14 tables dans la base LEA comme on peut le voir avec les commandes suivantes :
use LEA ; show tables ;Comme ne le montre pas le résultat de cette commande, il n'y a pas de moyen simple de compter ce nombre de tables sans afficher la liste des tables :
-------------- show tables -------------- +---------------+ | Tables_in_LEA | +---------------+ | cdd_nw | | fastas | | interpro_nw | | keywords | | membres | | motifs | | notes | | pfam_nw | | proteins | | rank | | submit | | taxonomy | | temp | | toul | +---------------+ 14 rows in set (0.00 sec) ByeRéponse à la question 3.2
On peut trouver qu'il y a 46 champs dans la table proteins dans la base LEA via les commandes suivantes :
use LEA ; describe proteins ;En voici le résultat :
-------------- describe proteins -------------- +-------------------+--------------+------+-----+------------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------------+--------------+------+-----+------------+-------+ | accession | varchar(30) | NO | PRI | | | | name | varchar(200) | NO | | | | | length | int(5) | NO | | 0 | | | reign | varchar(50) | NO | | | | | uniprot | text | NO | | NULL | | | authors | text | NO | | NULL | | | title | text | NO | | NULL | | | journal | text | NO | | NULL | | | function | varchar(200) | NO | | | | | tissue_type | varchar(50) | NO | | | | | dev_stage | varchar(30) | NO | | | | | product | text | NO | | NULL | | | protein_name | text | NO | | NULL | | | gene | text | NO | | NULL | | | region_name | text | NO | | NULL | | | region_note | text | NO | | NULL | | | putative_function | text | NO | | NULL | | | pfam | varchar(30) | NO | | | | | cdd | text | NO | | NULL | | | date | int(5) | NO | | 0 | | | GO_comp_id | varchar(7) | YES | | N/A | | | GO_comp | varchar(70) | YES | | N/A | | | GO_func_id | varchar(7) | YES | | N/A | | | GO_func | varchar(70) | YES | | N/A | | | GO_proc_id | varchar(7) | YES | | N/A | | | GO_proc | varchar(70) | YES | | N/A | | | organism_id | varchar(7) | YES | | N/A | | | organism | varchar(70) | YES | | N/A | | | foldindex | float(10,7) | YES | | -9.0000000 | | | pi | float(10,7) | YES | | -9.0000000 | | | mw | float(12,4) | YES | | -9.0000 | | | gravy | float(10,7) | YES | | -9.0000000 | | | gi | varchar(20) | YES | | N/A | | | interpro | varchar(20) | YES | | N/A | | | prodom | varchar(20) | YES | | N/A | | | unient | varchar(20) | YES | | N/A | | | netcharge | float(10,7) | YES | | -9.0000000 | | | hydrophi | float(10,7) | YES | | -9.0000000 | | | hydropho | float(10,7) | YES | | -9.0000000 | | | motif | int(2) | YES | | 99 | | | flexibility | float(10,7) | YES | | -9.0000000 | | | bulkiness | float(10,7) | YES | | -9.0000000 | | | buried | float(10,7) | YES | | -9.0000000 | | | transmembr | float(10,7) | YES | | -9.0000000 | | | accres | float(10,7) | YES | | -9.0000000 | | | maj | int(3) | NO | | -1 | | +-------------------+--------------+------+-----+------------+-------+ 46 rows in set (0.00 sec) ByeSavoir à quoi correspondent les champs est une autre histoire. En effet, il ne semble pas y avoir de champ nommé id ou key. Pour un(e) biologiste, biochimiste ou bioinformaticien(ne), certains noms sont quand même sans doute évocateurs. Ainsi GO doit certainement faire référence à Gene Ontology dont une présentation peut être trouvée sur le wiki français. De même pour les champs foldindex ou gravy, sous réserve que les valeurs dans les champs ne soient pas des qualifications liées aux valeurs quantitatives...
C'est toujours une mauvaise idée de croire qu'on connait un champ uniquement à partir de son nom...
Réponse à la question 3.3
De simples SELECT permettent de trouver les comptages demandés :
use LEA ; SELECT COUNT(*) FROM proteins ; SELECT COUNT(*) FROM proteins WHERE motif=1 ; SELECT "Classe ",motif," avec ",COUNT(*)," proteines " FROM proteins GROUP BY motif ;En voici le résultat :
-------------- SELECT COUNT(*) FROM proteins -------------- +----------+ | COUNT(*) | +----------+ | 5142 | +----------+ 1 row in set (0.00 sec) -------------- SELECT COUNT(*) FROM proteins WHERE motif=1 -------------- +----------+ | COUNT(*) | +----------+ | 267 | +----------+ 1 row in set (0.00 sec) -------------- SELECT "Classe ",motif," avec ",COUNT(*)," proteines " FROM proteins GROUP BY motif -------------- +---------+-------+--------+----------+-------------+ | Classe | motif | avec | COUNT(*) | proteines | +---------+-------+--------+----------+-------------+ | Classe | 1 | avec | 267 | proteines | | Classe | 2 | avec | 124 | proteines | | Classe | 3 | avec | 36 | proteines | | Classe | 4 | avec | 99 | proteines | | Classe | 5 | avec | 75 | proteines | | Classe | 6 | avec | 363 | proteines | | Classe | 7 | avec | 127 | proteines | | Classe | 8 | avec | 336 | proteines | | Classe | 9 | avec | 78 | proteines | | Classe | 10 | avec | 92 | proteines | | Classe | 11 | avec | 72 | proteines | | Classe | 12 | avec | 41 | proteines | | Classe | 13 | avec | 122 | proteines | | Classe | 99 | avec | 3310 | proteines | +---------+-------+--------+----------+-------------+ 14 rows in set (0.00 sec) ByeRéponse à la question 3.4
Dans la mesure où la table proteins ne contient pas les séquences FASTA (elles sont dans la table fastas), il faut effectuer une jointure entre les tables. La longueur des séquences n'est pas stockée dans un champ, il faut la calculer au passage et lui associer un alias afin de pouvoir l'utiliser comme critère de tri, soit :
use LEA ; /* toutes classes confondues */ SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession ORDER BY longueur DESC LIMIT 5 ; SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession ORDER BY longueur LIMIT 5 ; /* si on se limite aux treize premières classes */ SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession AND motif <=13 ORDER BY longueur DESC LIMIT 5 ; SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession AND motif <=13 ORDER BY longueur LIMIT 5 ;Les résultats (volontairement non commentés) sont alors :
-------------- SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession ORDER BY longueur DESC LIMIT 5 -------------- +--------------+----------+--------+ | proteine | longueur | classe | +--------------+----------+--------+ | AAF63342 | 2282 | 99 | | XP_001938142 | 1864 | 99 | | EDU50729 | 1864 | 99 | | NP_178413 | 1805 | 99 | | AAC34488 | 1805 | 99 | +--------------+----------+--------+ 5 rows in set (0.00 sec) -------------- SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession ORDER BY longueur LIMIT 5 -------------- +----------+----------+--------+ | proteine | longueur | classe | +----------+----------+--------+ | ABO31097 | 1 | 99 | | ABN14360 | 1 | 99 | | ABQ12737 | 8 | 99 | | CAA46770 | 8 | 99 | | CAA46769 | 8 | 99 | +----------+----------+--------+ 5 rows in set (0.00 sec) -------------- SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession AND motif <=13 ORDER BY longueur DESC LIMIT 5 -------------- +--------------+----------+--------+ | proteine | longueur | classe | +--------------+----------+--------+ | XP_003116340 | 843 | 6 | | XP_003116339 | 821 | 6 | | CCF23418 | 805 | 6 | | KCW47312 | 763 | 6 | | BAE92616 | 742 | 6 | +--------------+----------+--------+ 5 rows in set (0.00 sec) -------------- SELECT p.accession AS proteine, LENGTH(fasta) AS longueur, motif AS classe FROM proteins AS p, fastas AS f WHERE p.accession=f.accession AND motif <=13 ORDER BY longueur LIMIT 5 -------------- +-----------+----------+--------+ | proteine | longueur | classe | +-----------+----------+--------+ | ADQ91839 | 66 | 6 | | NP_180925 | 71 | 12 | | O23658 | 71 | 12 | | AAC69143 | 71 | 12 | | ADQ91836 | 71 | 6 | +-----------+----------+--------+ 5 rows in set (0.00 sec) ByeRéponse à la question 3.5
Si on sait que l''indice de repliement correspond au champ foldindex dans la table proteins, alors ce n'est pas très difficile d'en calculer la moyenne :
use LEA ; SELECT motif AS classe, AVG(foldindex) AS moyenne FROM proteins WHERE motif <=12 GROUP BY classe ORDER BY classe ;Malheureusement les résultats ne sont pas très lisibles à cause du grand nombre de décimales :
-------------- SELECT motif AS classe, AVG(foldindex) AS moyenne FROM proteins WHERE motif <=12 GROUP BY classe ORDER BY classe -------------- +--------+----------------+ | classe | moyenne | +--------+----------------+ | 1 | -0.13553213460 | | 2 | -0.24749346282 | | 3 | -0.32894496247 | | 4 | -0.17441781712 | | 5 | -0.20638285776 | | 6 | -0.09028592268 | | 7 | 0.20449773052 | | 8 | 0.21318739812 | | 9 | 0.06352151900 | | 10 | -0.09814941755 | | 11 | 0.09758181923 | | 12 | -0.15041698724 | +--------+----------------+Il vaut mieux arrondir les moyennes, soit les commandes :
use LEA ; SELECT motif AS classe, round(AVG(foldindex),3) AS moyenne FROM proteins WHERE motif <=12 GROUP BY classe ORDER BY classe ;Et les résultats sont plus faciles à lire :
-------------- SELECT motif AS classe, round(AVG(foldindex),3) AS moyenne FROM proteins WHERE motif <=12 GROUP BY classe ORDER BY classe -------------- +--------+---------+ | classe | moyenne | +--------+---------+ | 1 | -0.136 | | 2 | -0.247 | | 3 | -0.329 | | 4 | -0.174 | | 5 | -0.206 | | 6 | -0.090 | | 7 | 0.204 | | 8 | 0.213 | | 9 | 0.064 | | 10 | -0.098 | | 11 | 0.098 | | 12 | -0.150 | +--------+---------+ 12 rows in set (0.00 sec) ByeSavoir si ces valeurs moyennes sont "raisonnables" ne relève pas de compétences en MySQL et il n'est pas possible d'y répondre sans une certaine expertise en bioinformatique.
Réponse à la question 3.6
Les motifs sont décrits dans la table motifs :
use LEA ; DESCRIBE motifs ; SELECT * FROM motifs ORDER BY id_motif ;Voici l'affichage de cette table, légèrement reformaté :
-------------- DESCRIBE motifs -------------- +----------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+--------------+------+-----+---------+-------+ | id_motif | int(2) | NO | PRI | 0 | | | nom | varchar(70) | NO | | NULL | | | motif | varchar(500) | YES | | NULL | | +----------+--------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) -------------- SELECT * FROM motifs ORDER BY id_motif -------------- +----------+---------+----------------------------------------------------------------------+ | id_motif | nom | motif | +----------+---------+----------------------------------------------------------------------+ | 1 | PF00257 | [AGPS][GS][ST][ST]E[DEGST][DEG] | | 2 | PF00257 | [IS]S{2,}[IS][ADGV][DES][DEGK]. | | 3 | PF00257 | DSD$ | | 4 | PF00257 | STTAPGHY|HKTGTTTS|GGGGIGTG|HS[DR]N?K$|[DG]VE$|LH(TRASHEES)? | | $|C?TGH$|DKLPGQH$|QQN(KTGCD)?$|RGD$|KEGY$|GHRPQI$|GHNN$|SFKS$ | | |GTHKGL$|SSRDNY$|GQS[KN]$|HRDV$|GRHE$ | | | 5 | PF00477 | G[AG][ENQT].R[AKR][DEQ] | | 6 | PF02987 | [^LNP][^G][ADEGILMQRSTVY][AEKQRSTY].[KR][AT].[ADENT][^DP] | | [EGIKLMQST].{1,67}[^DER][^AS]K[AD][^IL][^N].[^E]?.{1,6}G? | | 7 | PF03168 | NPY.{4,}P[IV].[ADEQ] | | 8 | PF03168 | P.{12,31}[AILV].NP[LN] | | 9 | PF03242 | W.{1,3}DP.{1,3}G | | 10 | PF03760 | [AS].{0,3}[EG][HK].{6,6}[AHQRS].{3,3}[DEKQ][EKRQ].{2,2}[AT] | | 11 | PF04927 | (T.GEAL[EH]A)|(PGGVA) | | 12 | PF10714 | T[DE]APT | | 13 | PF03168 | [EKPRS][NS].{1,2}[HKNR].G.[FY][EKN]?[FY] | +----------+---------+----------------------------------------------------------------------+ 13 rows in set (0.00 sec) ByeSavoir à quoi correspondent les motifs demande une certaine expertise en informatique car ce sont des expressions régulières. Savoir comment ils ont été construits est une autre histoire, qui sera racontée plus tard dans cette formation... comme la présence du champ nom qui correspond à un numéro PFAM.
Réponse à la question 3.7
Calculer l'indice de repliement dans la base HSP se fait de la même façon que dans la base LEA car les deux bases ont presque totalement la même structure (encore fallait-il le savoir) :
use HSP ; SELECT motif AS classe, round(AVG(foldindex),3) AS "repliement moyen" FROM proteins WHERE motif <=23 GROUP BY classe ORDER BY classe ;Savoir si les résultats sont comparables à ceux de la base LEA ne peut se faire à l'aide de seules connaissances en MySQL.
-------------- SELECT motif AS classe, round(AVG(foldindex),3) AS "repliement moyen" FROM proteins WHERE motif <=23 GROUP BY classe ORDER BY classe -------------- +--------+------------------+ | classe | repliement moyen | +--------+------------------+ | 0 | 0.016 | | 1 | 0.086 | | 2 | 0.085 | | 3 | 0.090 | | 4 | 0.098 | | 5 | 0.037 | | 6 | 0.055 | | 7 | 0.039 | | 8 | 0.102 | | 9 | -0.006 | | 10 | 0.069 | | 11 | 0.027 | | 12 | 0.045 | | 13 | 0.018 | | 14 | 0.116 | | 15 | 0.051 | | 16 | 0.125 | | 17 | -0.017 | | 18 | 0.162 | | 19 | 0.006 | | 20 | 0.113 | | 21 | 0.098 | | 22 | -0.127 | | 23 | -0.120 | +--------+------------------+ 24 rows in set (0.02 sec) ByeOn pourra toutefois remarquer qu'il y beaucoup plus de moyennes positives...
Réponse à la question 3.8
Là encore, en recherchant dans les champs de la table proteins de la base HSP, on peut réussir à trouver des informations liées à ACD. Par contre savoir ce que cela représente est une autre «paire de manches».
use HSP ; DESCRIBE proteins ; SELECT IF(lengthACD>0,"avec","sans") AS acd, COUNT(*) AS proteines FROM proteins GROUP BY acd ;Voici un extrait des résultats.
-------------- DESCRIBE proteins -------------- +-------------------+--------------+------+-----+------------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------------+--------------+------+-----+------------+-------+ | accession | varchar(15) | NO | PRI | | | | name | varchar(200) | NO | | | | | length | int(5) | NO | | 0 | | | reign | varchar(50) | NO | | | | | uniprot | text | NO | | NULL | | ... | accres | float(10,7) | YES | | -9.0000000 | | | checkprot | int(2) | YES | | -1 | | | lengthCter | int(5) | NO | | 0 | | | lengthNter | int(5) | NO | | 0 | | | debutACD | int(5) | NO | | 0 | | | finACD | int(5) | NO | | 0 | | | lengthACD | int(5) | NO | | 0 | | | maj | int(3) | NO | | -1 | | +-------------------+--------------+------+-----+------------+-------+ 52 rows in set (0.00 sec) -------------- SELECT IF(lengthACD>0,"avec","sans") AS acd, COUNT(*) AS proteines FROM proteins GROUP BY acd -------------- +------+-----------+ | acd | proteines | +------+-----------+ | avec | 3813 | | sans | 13517 | +------+-----------+ 2 rows in set (0.00 sec) ByeOn peut peut-être en déduire que toutes les protéines de la base n'ont pas toutes un domaine ACD.
Réponse à la question 3.9
Deux tables semblent liées à la taxonomie dans les bases étudiées, à savoir les tables rank et taxonomy :
use LEA ; DESCRIBE rank ; DESCRIBE taxonomy ; SELECT * FROM rank ; SELECT * FROM taxonomy LIMIT 5 ; SELECT id, LPAD(id,3,"0") AS idFmt, name_taxon, parent_id, rank_id FROM taxonomy ORDER BY idFmt LIMIT 10 ; SELECT id, LPAD(id,3,"0") AS idFMT, name_taxon, parent_id, rank_id, LPAD(parent_id,3,"0") AS pFMT FROM taxonomy ORDER BY pFMT LIMIT 10 ; SELECT * FROM taxonomy WHERE id=10 OR id=1706371 OR id=1706369 OR id=1236 OR id=1224 OR id=2 ORDER BY rank_id DESC ; # fin de SELECTSi la table rank sert juste à désigner les rangs taxonomiques, la table taxonomy est plus complexe et contient des informations hiérarchiques (récursives ?) sur les valeurs taxonomiques.
-------------- DESCRIBE rank -------------- +-----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+----------------+ | id | tinyint(2) | NO | PRI | NULL | auto_increment | | rank_name | varchar(15) | NO | | NULL | | +-----------+-------------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) -------------- DESCRIBE taxonomy -------------- +------------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+--------------+------+-----+---------+-------+ | id | varchar(7) | NO | PRI | NULL | | | name_taxon | varchar(255) | NO | | NULL | | | parent_id | varchar(7) | YES | MUL | NULL | | | rank_id | tinyint(2) | NO | MUL | NULL | | +------------+--------------+------+-----+---------+-------+ 4 rows in set (0.00 sec) -------------- SELECT * FROM rank -------------- +----+--------------+ | id | rank_name | +----+--------------+ | 1 | superkingdom | | 2 | kingdom | | 3 | phylum | | 4 | class | | 5 | order | | 6 | family | | 7 | genus | | 8 | species | | 9 | final-org | +----+--------------+ 9 rows in set (0.00 sec) -------------- SELECT * FROM taxonomy LIMIT 5 -------------- +---------+-------------------------------------------------------+-----------+---------+ | id | name_taxon | parent_id | rank_id | +---------+-------------------------------------------------------+-----------+---------+ | 10 | Cellvibrio | 1706371 | 7 | | 100053 | Leptospira alexanderi | 171 | 8 | | 1001585 | Pseudomonas mendocina NK-01 | 300 | 9 | | 1001586 | Leptospira interrogans serovar Bulgarica str. Mallika | 173 | 9 | | 1001590 | Leptospira interrogans str. 2006001854 | 173 | 9 | +---------+-------------------------------------------------------+-----------+---------+ 5 rows in set (0.00 sec) -------------- SELECT id, LPAD(id,3,"0") AS idFmt, name_taxon, parent_id, rank_id FROM taxonomy ORDER BY idFmt LIMIT 10 -------------- +----+-------+--------------------+-----------+---------+ | id | idFmt | name_taxon | parent_id | rank_id | +----+-------+--------------------+-----------+---------+ | 2 | 002 | Bacteria | NULL | 1 | | 10 | 010 | Cellvibrio | 1706371 | 7 | | 18 | 018 | Pelobacter | 213423 | 7 | | 22 | 022 | Shewanella | 267890 | 7 | | 29 | 029 | Myxococcales | 28221 | 5 | | 31 | 031 | Myxococcaceae | 29 | 6 | | 32 | 032 | Myxococcus | 31 | 7 | | 33 | 033 | Myxococcus fulvus | 32 | 8 | | 34 | 034 | Myxococcus xanthus | 32 | 8 | | 39 | 039 | Cystobacteraceae | 29 | 6 | +----+-------+--------------------+-----------+---------+ 10 rows in set (0.00 sec) -------------- SELECT id, LPAD(id,3,"0") AS idFMT, name_taxon, parent_id, rank_id, LPAD(parent_id,3,"0") AS pFMT FROM taxonomy ORDER BY pFMT LIMIT 10 -------------- +--------+-------+---------------------+-----------+---------+------+ | id | idFMT | name_taxon | parent_id | rank_id | pFMT | +--------+-------+---------------------+-----------+---------+------+ | 10239 | 102 | Viruses | NULL | 1 | NULL | | 2 | 002 | Bacteria | NULL | 1 | NULL | | 2157 | 215 | Archaea | NULL | 1 | NULL | | 2759 | 275 | Eukaryota | NULL | 1 | NULL | | 1090 | 109 | Chlorobi | 2 | 3 | 002 | | 1117 | 111 | Cyanobacteria | 2 | 3 | 002 | | 1224 | 122 | Proteobacteria | 2 | 3 | 002 | | 1239 | 123 | Firmicutes | 2 | 3 | 002 | | 1297 | 129 | Deinococcus-Thermus | 2 | 3 | 002 | | 142182 | 142 | Gemmatimonadetes | 2 | 3 | 002 | +--------+-------+---------------------+-----------+---------+------+ 10 rows in set (0.00 sec) -------------- SELECT * FROM taxonomy WHERE id=10 OR id=1706371 OR id=1706369 OR id=1236 OR id=1224 OR id=2 ORDER BY rank_id DESC -------------- +---------+---------------------+-----------+---------+ | id | name_taxon | parent_id | rank_id | +---------+---------------------+-----------+---------+ | 10 | Cellvibrio | 1706371 | 7 | | 1706371 | Cellvibrionaceae | 1706369 | 6 | | 1706369 | Cellvibrionales | 1236 | 5 | | 1236 | Gammaproteobacteria | 1224 | 4 | | 1224 | Proteobacteria | 2 | 3 | | 2 | Bacteria | NULL | 1 | +---------+---------------------+-----------+---------+ 6 rows in set (0.00 sec) ByeIl faut apprendre à utiliser le NCBI Taxonomy Browser afin de comprendre comment pouvoir utiliser ces informations, sans doute par programme informatique, car sous cette forme, ce n'est pas très exploitable.
Réponse à la question 3.10
Oulalah, c'est une question difficile ! Calculer les moyennes des longueurs est simple :
use HSP ; SELECT motif AS classe, round(AVG(length),3) AS "longueur moyenne" FROM proteins WHERE motif <=23 GROUP BY classe ORDER BY classe ;La preuve :
-------------- SELECT motif AS classe, round(AVG(length),3) AS "longueur moyenne" FROM proteins WHERE motif <=23 GROUP BY classe ORDER BY classe -------------- +--------+------------------+ | classe | longueur moyenne | +--------+------------------+ | 0 | 163.050 | | 1 | 179.102 | | 2 | 153.618 | | 3 | 197.556 | | 4 | 140.319 | | 5 | 197.154 | | 6 | 213.560 | | 7 | 233.120 | | 8 | 145.268 | | 9 | 164.293 | | 10 | 158.851 | | 11 | 159.981 | | 12 | 181.117 | | 13 | 199.926 | | 14 | 149.646 | | 15 | 169.710 | | 16 | 147.976 | | 17 | 112.364 | | 18 | 171.381 | | 19 | 214.280 | | 20 | 239.070 | | 21 | 294.479 | | 22 | 370.000 | | 23 | 97.333 | +--------+------------------+ 24 rows in set (0.00 sec) ByeSavoir s'il y a une différence significative relève du domaine des statistiques, et demande des compétences supplémentaires. On trouvera dans la rubrique Statistical analysis du site dédié aux sHSP les résultats des calculs associés. Avec un peu d'aide, vous devriez en déduire la réponse...
Réponse à la question 3.11
Tous ces résultats sont inexacts -- et non pas faux -- dans la mesure où les bases de données sont régulièrement mises à jour. Sauf à disposer de programmes informatiques qui seraient exécutés en temps réel, ces résultats ne sont donc valables que pour le jour et l'heure où ils ont été exécutés.
Cliquer ici pour revenir à la page de départ des cours CMI / L2.