Entrées, sorties, XML et statistiques
Partie 2/2 :
Statistiques : calculs, graphiques et automatisation
Table des matières cliquable
1. Pourquoi les statistiques ?
2. Les statistiques au secours de l'intuition
3. Les statistiques contre l'intuition
4. Vers une pratique rationnelle automatisée des statistiques
De nombreux chercheurs commettent l'erreur de croire que d'exécuter des programmes suffit pour décider si une méthode est meilleure qu'une autre, qu'un temps d'exécution moyen inférieur permet de conclure, qu'un meilleur pourcentage d'instances résolues sont un argument absolu. Ce que montrent les statistiques, c'est que la prise de décision est beaucoup plus complexe : 2 est toujours plus petit que 3, mais 2 n'est pas toujours plus petit que 3 de façon significative.
De plus, la moyenne n'est pas toujours le meilleur résumé de la tendance centrale : la médiane est parfois un indicateur plus adapté ; de même la dispersion absolue ou relative ne s'exprime pas systématiquement via l'écart-type et le coefficient de variation car on utilise également la distance inter-quartiles et l'écart inter-quartiles relatif.
Enfin, la comparaison (rigoureuse) de données suppose un modèle théorique de la distribution des différences. Suivant les données, le modèle est paramétrique ou non paramétrique. Utiliser un test statistique incorrect aboutit forcément à un résultat inacceptable scientifiquement.
On trouvera dans la page pourquoi.htm d'autres arguments en faveur d'une utilisation systématique des statistiques dans un cadre de recherche.
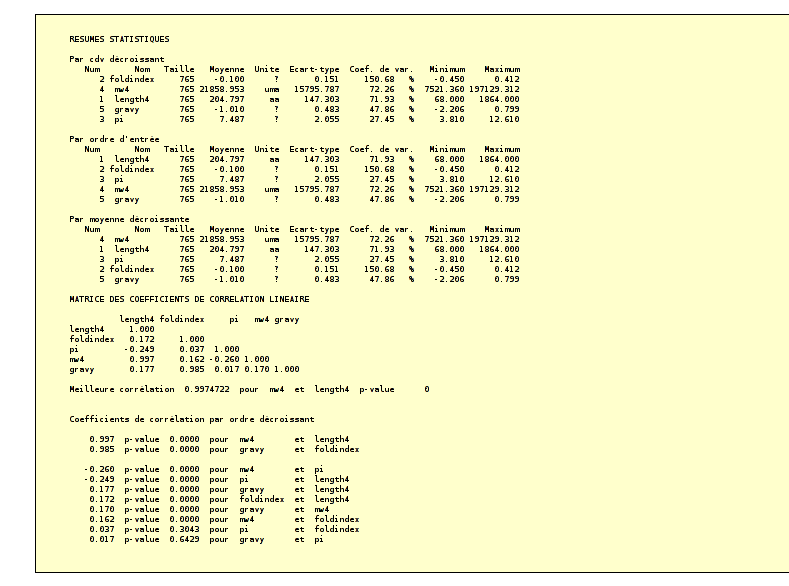
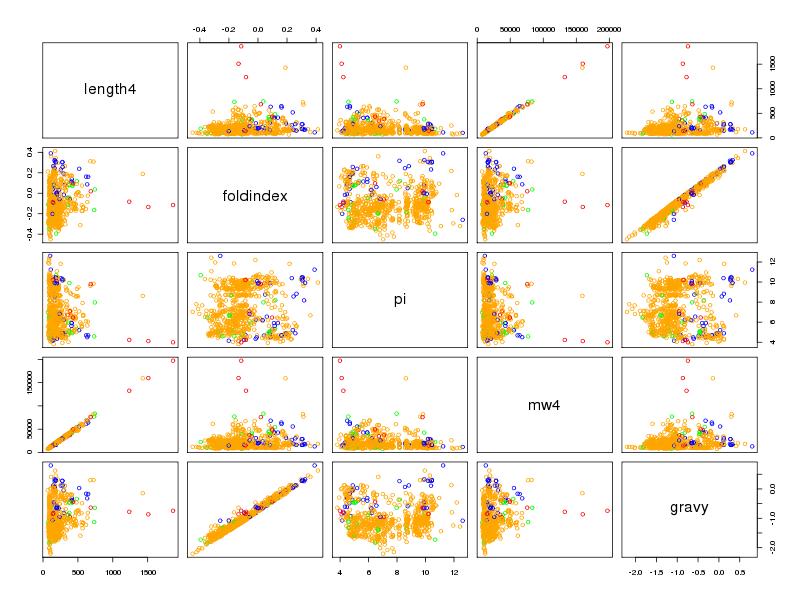
Une première utilisation des statistiques est la description des données. On pourra comparer le fichier de données brutes ralphv2.dac à sa description numérique, visuelle et graphique disponible à l'url ralsto_phv2_ccd.htm et réfléchir à l'intérêt du dendrogramme associé.
Les statistiques descriptives, avec leur lot d'indicateurs numériques et de représentations graphiques, forment un ensemble riche et cohérent d'outils pour synthétiser, résumer, schématiser les colonnes de données. Après avoir compris la notion de variable statistique et ses trois types principaux (les variables qualitatives, les variables quantitatives et les variables textuelles), il faut s'entrainer à produire rapidement les tableaux de caractéristiques et les «matrices» de graphiques afin de passer du temps à l'interprétation des résultats :
Nos exercices du cours numéro 1 pour l'ecole doctorale Biologie Santé et leurs solutions, bien qu'appliqués à des données biostatistiques, devraient être un rappel suffisant de ces statistiques descriptives et permettre de réaliser des analyses statistiques élémentaires.
Afin de comparer scientifiquement de moyennes, des médianes, des fréquences, voire des distributions, il faut maitriser la théorie et surtout la pratique des tests statistiques, ce qui permet d'éviter l'erreur suivante : 2 est proche de 3 et 3 est proche de 4, donc 2 est proche de 4. Si c'était vrai, alors par transitivité, 2 serait proche de l'infini ! Seul un chercheur naïf peut penser que 15 % est proche de 20 % sans faire référence à la taille de l'échantillon ou à celle de la population sous-jacente. Ce que permet la la théorie des tests statistiques, c'est de quantifier de telles différentes et d'utiliser non seulement les moyennes (respectivement les pourcentages) mais aussi les variances (respectivement les tailles d'échnatillon. Ce qui explique les conclusions des formules : 5 % de différence pour une taille de 40, ce n'est pas la même chose que pour une taille de 2000. De même, deux moyennes proches de 50 et séparées de 2 avec des variances de l'ordre de 3 ne sont pas «proches» de la même façon que si leur variances valent 30.
On trouvera ici et là des formulaires pour tester ces affirmations, le détail des formules étant fourni par le document nommé formules.pdf ; un ensemble de calculs statistiques classiques par page Web est ici et, plus généralement, notre page statgen contient de nombreux liens et documents pour les statistiques.
Une fois passé le cap de l'apprentissage de base pour les statistiques descriptives et inférentielles, l'automatisation des calculs, de la gestion des entrées et des sorties ne pose aucun problème pour un programmeur : le logiciel R par exemple se compose principalement d'un langage de programmation facile à apprendre et très complet : les objets, définis par des classes «S4» et les nombreux packages fournissent tout ce dont un chercheur en informatique a besoin (gratuitement). R s'interface facilement avec un serveur Web. On peut par exemple essayer de copier/coller le texte suivant dans Rweb pour s'en rendre compte :
# calculs R classiques
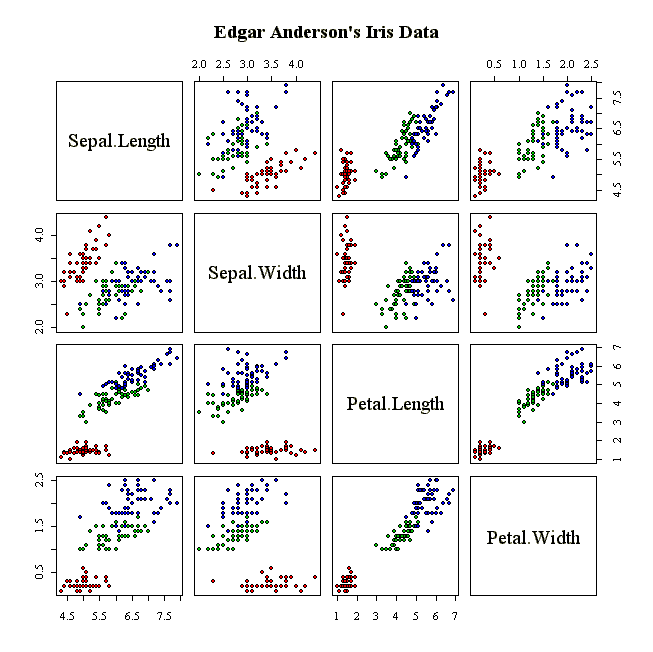
data(iris)
head(iris)
summary(iris)
attach(iris)
pairs(iris[1:4], main="Edgar Anderson's Iris Data", pch=21,
bg = c("red", "green3", "blue")[unclass(iris$Species)])
# fonctions et graphiques gh
source("http://forge.info.univ-angers.fr/~gh/statgh.r")
irisqt <- iris[,(1:4)]
allQT(irisqt,colnames(irisqt),rep("cm",4))
# des graphiques explicites
decritQT("sepal.len",irisqt[,1],"cm",TRUE)
decritQTparFacteurTexte("sepal.length",Sepal.Length,unite="cms",
"espece",Species,levels(Species),TRUE,"")
R peut aussi être appelé par un programme Php, comme dans le cas de notre page aqt_det.php. Enfin, la liaison dynamique avec LaTeX est assurée par Sweave. Pourquoi s'en priver ? Utilisez le formulaire ci-dessous pour une démonstration :
Dans le cadre de programmes de recherche orientés déduction ou ne nécessitant pas de calculs statistiques sophistiqués, la production automatique de documents (à défaut d'être dynamique comme avec Sweave) est souvent réalisée à l'aide de scripts, le plus souvent en perl ou en php. Voici quatre exemples de script :
- titre.pl
- création d'une page de titre (PS) ; exemple de résultat : titre.pdf
- alldsc.pl
- génération de listes triées de fichiers en RTF pour Word ; exemple de résultat : alldsc.rtf
- lesdsc.php
- génération de listes triées de fichiers en CSV pour Excel ; exemple de résultat : alldsc.csv
- emarge.pl
- liste d'émargement ; exemple de résultat : lstemarge.pdf ; fichier d'entrée : eda.txt
Codes-sources : de cette page ; de aqt_det.php ; de progstat.php ; de statuno.php ; du code Sweave.
Liens : retour à l'exposé ; partie 1/2 (entrées, sorties, XML et statistiques).
| 
 Retour à la page principale de
(gH)
Retour à la page principale de
(gH)